发明者量化PINE语言入门教程
 0
11375
0
11375
[TOC]
发明者量化PINE语言入门教程
配套视频教程: 【量化交易入门太难?使用trading view Pine语言从小白到Quant大神–Pine语言初探】
发明者量化交易平台支持Pine语言编写策略,支持回测、实盘运行Pine语言策略,兼容Pine语言的较低版本。在发明者量化交易平台(FMZ.COM)上的策略广场中有搜集、移植的众多Pine策略(脚本)。
FMZ不仅支持了Pine语言,同时也支持Pine语言强大的画图功能。FMZ平台上的各项功能、丰富实用的工具、高效便捷的管理,也进一步增强了Pine策略(脚本)的实用性。FMZ基于对Pine语言的兼容,同时也对Pine语言进行了一定程度的扩展、优化、裁剪。在正式进入教程之前,我们一起来看下FMZ上的Pine语言和原版的Pine有哪些改动。
简单概述一些比较明显的不同:
- 1、FMZ上的Pine策略,代码开头的版本标识
//@version和代码开始的strategy、indicator语句并不强制要求编写,FMZ暂时不支持import导入library的功能。
可能看到有些策略是这样写的:
//@version=5
indicator("My Script", overlay = true)
src = close
a = ta.sma(src, 5)
b = ta.sma(src, 50)
c = ta.cross(a, b)
plot(a, color = color.blue)
plot(b, color = color.black)
plotshape(c, color = color.red)
或者是这样写的:
//@version=5
strategy("My Strategy", overlay=true)
longCondition = ta.crossover(ta.sma(close, 14), ta.sma(close, 28))
if (longCondition)
strategy.entry("My Long Entry Id", strategy.long)
shortCondition = ta.crossunder(ta.sma(close, 14), ta.sma(close, 28))
if (shortCondition)
strategy.entry("My Short Entry Id", strategy.short)
在FMZ上可以简化为:
src = close
a = ta.sma(src, 5)
b = ta.sma(src, 50)
c = ta.cross(a, b)
plot(a, color = color.blue, overlay=true)
plot(b, color = color.black, overlay=true)
plotshape(c, color = color.red, overlay=true)
或者:
longCondition = ta.crossover(ta.sma(close, 14), ta.sma(close, 28))
if (longCondition)
strategy.entry("My Long Entry Id", strategy.long)
shortCondition = ta.crossunder(ta.sma(close, 14), ta.sma(close, 28))
if (shortCondition)
strategy.entry("My Short Entry Id", strategy.short)
2、策略(脚本)一些交易相关的设置由FMZ策略界面上的「Pine语言交易类库」参数设置。
- 收盘价模型与实时价模型
在trading view上,我们可以通过
strategy函数的calc_on_every_tick参数去设置策略脚本在价格每次变动时实时执行策略逻辑,此时calc_on_every_tick参数应当设置为true。默认calc_on_every_tick参数是false,即在策略当前K线BAR完全走完时才去执行策略逻辑。 在FMZ上则是通过,「Pine语言交易类库」模板的参数去设置。
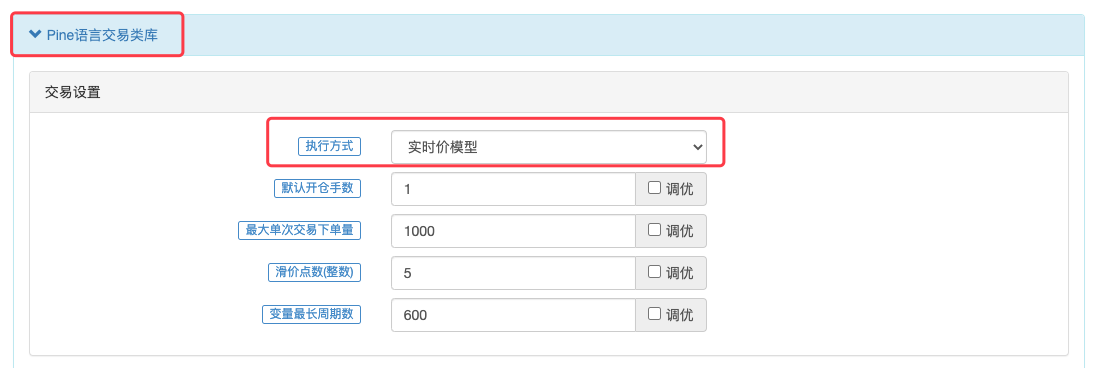
策略执行时的价格、下单量等数值精度控制在FMZ上是需要指定的 在trading view上因为只能模拟测试,所以没有实盘下单时的精度问题。在FMZ上是可以实盘运行Pine策略的。那么就需要策略可以灵活指定交易品种的价格精度、下单数量精度。这些精度设置即控制相关数据的小数位数,避免数据不符合交易所报单要求从而无法下单。
期货合约代码 在FMZ上交易品种如果是合约,是有2个属性的。分别为「交易对」、「合约代码」,在实盘和回测时除了需要明确设置交易对,也需要在「Pine语言交易类库」模板的参数「品种代码」中设置具体的合约代码。例如永续合约就填写
swap,合约代码要具体看操作的交易所是否有这种合约。例如有的交易所有季度合约,这里就可以填写quarter。这些合约代码和FMZ的Javascript/python/c++语言API文档上定义的期货合约代码一致。
- 收盘价模型与实时价模型
在trading view上,我们可以通过
其它设置例如,最小下单量、默认下单量等可以参看Pine语言文档中关于「Pine语言交易类库」参数的介绍。
- 3、
runtime.debug、runtime.log、runtime.errorFMZ扩展的函数,用于调试。
FMZ平台上增加了3个函数用于调试。
runtime.debug:在控制台打印变量信息,一般来说用不到该函数。-
```pine runtime.log(1, 2, 3, close, high, ...),可以传多个参数。 -
```pine runtime.error(message) 4、部分画图函数中扩展了
overlay参数
在FMZ上的Pine语言,画图函数plot、plotshape、plotchar等增加了overlay参数支持,允许指定画在主图或者副图。overlay设置true画在主图,设置为false画在副图。使得FMZ上的Pine策略运行时可以主图、副图同时画图。
- 5、
syminfo.mintick内置变量的取值
- 6、FMZ PINE Script中的均价均为包含手续费的价格
例如:下单价格为8000,卖出方向,数量1手(个、张),成交后均价不是8000,低于8000(成本中包含了手续费)。
## Pine语言基础
开始学习Pine语言基础时,可能有些例子中的指令、代码语法我们并不熟悉。看不懂没关系,我们可以先熟悉概念,理解测试目的,也可以查询FMZ的Pine语言文档查看说明。然后跟随教程一步一步循序渐进熟悉各种语法、指令、函数、内置变量。
### 模型执行
在入门学习Pine语言时,是非常有必要了解Pine语言脚本程序执行过程等相关概念的。Pine语言策略是基于图表运行的,可以理解为Pine语言策略为一系列的计算和操作,在图表上以时间序列的先后顺序从图表已经加载的最早数据开始执行。图表初始加载的数据量是有限的。实盘时通常这个数据量上限是基于交易所接口返回的最大数据量决定,回测时数据量上限是基于回测系统数据源提供的数据决定。图表上最左边的第一个K线Bar,即图表数据集的第一个数据,其索引值为0。可以通过Pine语言的内置变量```bar_index```引用到Pine脚本执行时当前的K线Bar的索引值。
```pine
plot(bar_index, "bar_index")
根据策略的设置不同,策略的模型执行方式也不同,分为```收盘价模型```和```实时价模型```。收盘价模型、实时价模型的概念在之前我们也简单介绍过。
- 收盘价模型
策略代码执行时,当前K线Bar的周期完全执行完成,K线闭合时即K线周期已经走完。此时执行一遍Pine策略逻辑,触发的交易信号将在下一根K线Bar开始时执行。
- 实时价模型
策略代码执行时,当前K线Bar不论是否闭合,每次行情变动就执行一遍Pine策略逻辑,触发的交易信号立即执行。
当Pine语言策略在图表上从左至右执行时,图表上的K线Bar是分为```历史Bar```和```实时Bar```的:
- 历史Bar
策略设置为「实盘价模型」开始执行时,图表上除了最右侧的那一根K线Bar之外所有K线Bar都是```历史Bar```。策略逻辑在每根```历史Bar```上仅执行一次。
策略设置为「收盘价模型」开始执行时,图表上所有Bar都是```历史Bar```。策略逻辑在每根```历史Bar```上仅执行一次。
基于历史Bar的计算:
策略代码在历史Bar收盘状态下执行一次,然后策略代码继续在下一个历史Bar执行,直到所有历史Bar都执行一次。
- 实时Bar
当策略执行到最右边的最后一根K线Bar上时,该Bar为实时Bar。当实时Bar闭合之后,这根Bar就变成了一个经过的实时Bar(变成了历史Bar)。图表最右侧会产生新的实时Bar。
策略设置为「实时价模型」开始执行时,在实时Bar上每次行情变动都会执行一次策略逻辑。
策略设置为「收盘价模型」开始执行时,图表上不显示实时Bar。
基于实时Bar的计算:
如果设置策略为「收盘价模型」图表不显示实时Bar,策略代码只在当前Bar收盘时执行一次。
如果设置策略为「实盘价模型」在实时Bar上的计算和历史Bar就完全不同了,在实盘Bar上每次行情变动都会执行一次策略代码。例如内置变量```high```、```low```、```close```在历史Bar上是确定的,在实时Bar上可能每次行情变动时这些值是会发生变化的。所以基于这些值计算的指标等数据也是会实时变动的。在实时Bar上```close```始终代表当前最新价格,```high```和```low```始终代表自当前实时Bar开始以来达到的最高高点和最低低点。这些内置变量代表实时Bar最后一次更新时的最终值。
实时Bar上执行策略时的回滚机制(实时价模型):
在实时Bar执行时,策略的每次新迭代执行前重置用户定义的变量称为回滚。我们来以一个例子理解回滚机制,如下测试代码。
注意:
/*backtest … .. . */
包裹的内容为FMZ平台上以代码形式保存的回测配置信息。
```pine
/*backtest
start: 2022-06-03 09:00:00
end: 2022-06-08 15:00:00
period: 1m
basePeriod: 1m
exchanges: [{"eid":"Bitfinex","currency":"BTC_USD"}]
*/
var n = 0
if not barstate.ishistory
runtime.log("n + 1之前, n:", n, " 当前bar_index:", bar_index)
n := n + 1
runtime.log("n + 1之后, n:", n, " 当前bar_index:", bar_index)
plot(n, title="n")
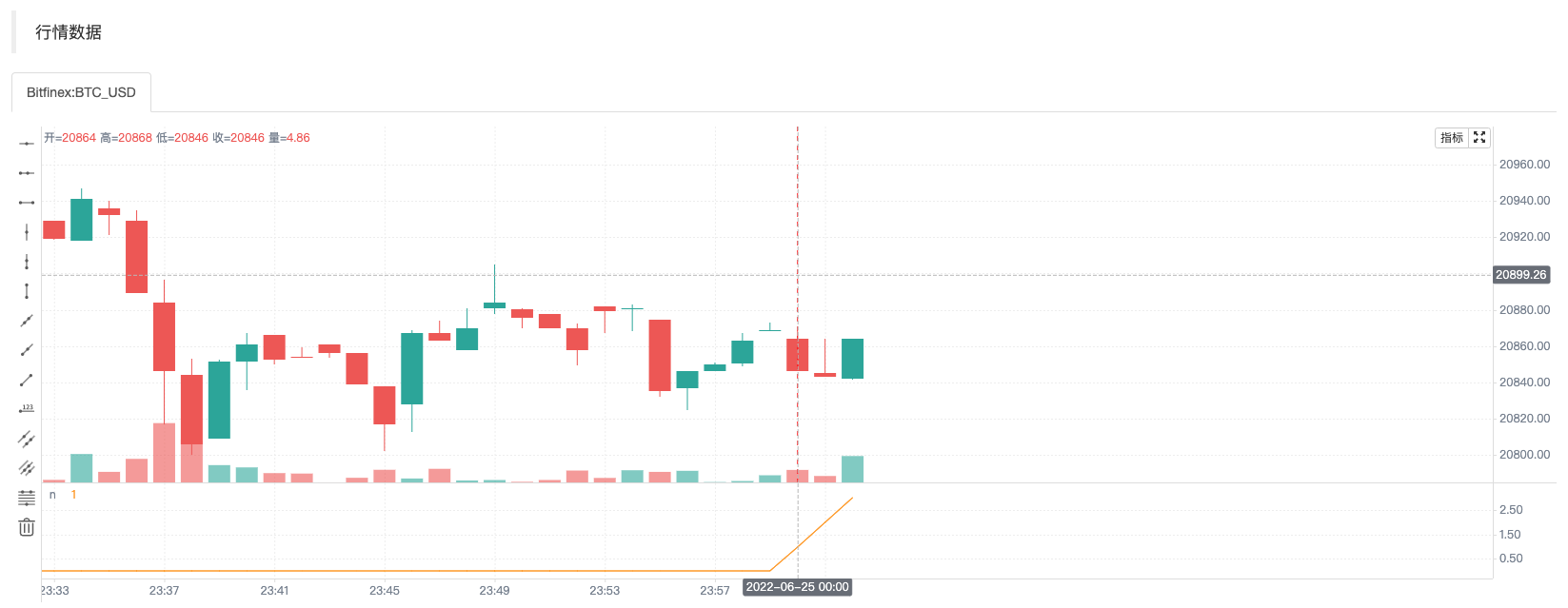
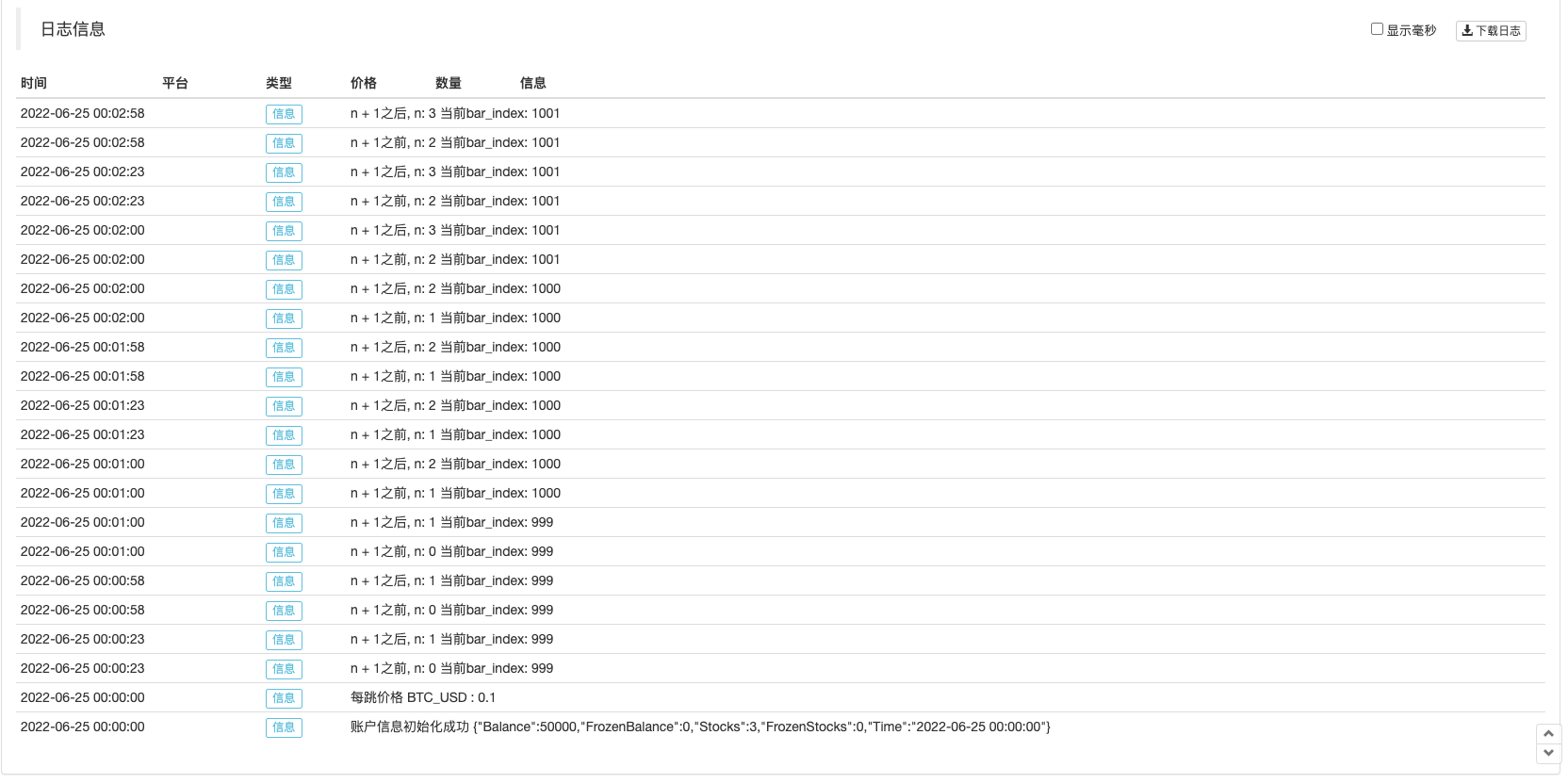
我们只考察在实时Bar时执行的场景,所以用了not barstate.ishistory表达式限制只在实时Bar时对变量n累加,并且在执行累加操作前后使用runtime.log函数输出信息在策略日志中。从使用画图函数plot画出的曲线n可以看到在策略处于历史Bar运行时n一直是0。当执行到实时Bar时触发了n累加1的操作,并且在实时Bar上每轮执行策略时都执行了n累加1的操作。可以从日志信息中观察到每轮重新执行策略代码时n都被重置为前一个Bar执行策略最终提交的值。当实时Bar上最后一次执行策略代码时会提交n值更新,所以可以看到图表上从实时Bar开始,曲线n随着每次Bar增加时曲线n的值增加1。
总结一下: 1、策略在实时Bar开始执行时,每次行情更新就执行一次策略代码。 2、在实时Bar上执行时,每次执行策略代码之前都会回滚变量。 3、在实时Bar上执行时,变量在收盘更新时提交一次。
由于数据回滚,所以图表上的曲线等画图操作也是可能引起重绘的,例如我们修改一下刚才的测试代码,实盘测试:
var n = 0
if not barstate.ishistory
runtime.log("n + 1之前, n:", n, " 当前bar_index:", bar_index)
n := open > close ? n + 1 : n
runtime.log("n + 1之后, n:", n, " 当前bar_index:", bar_index)
plot(n, title="n")
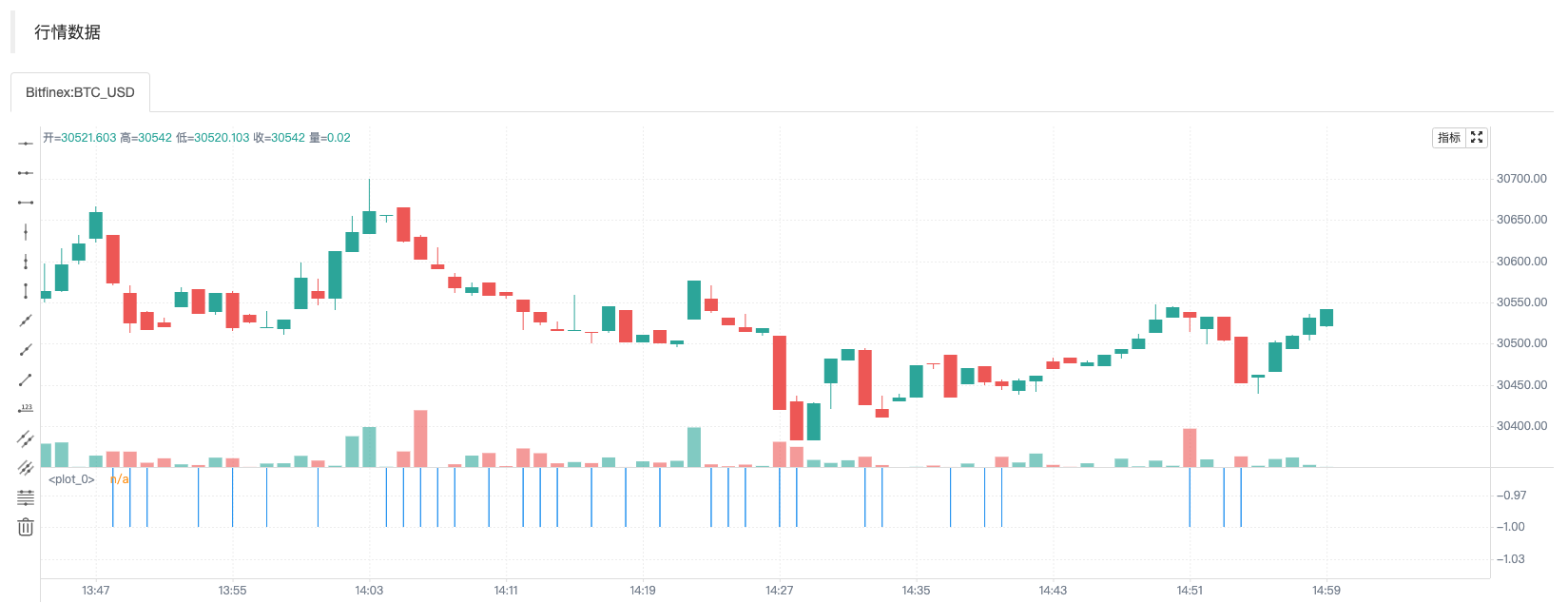
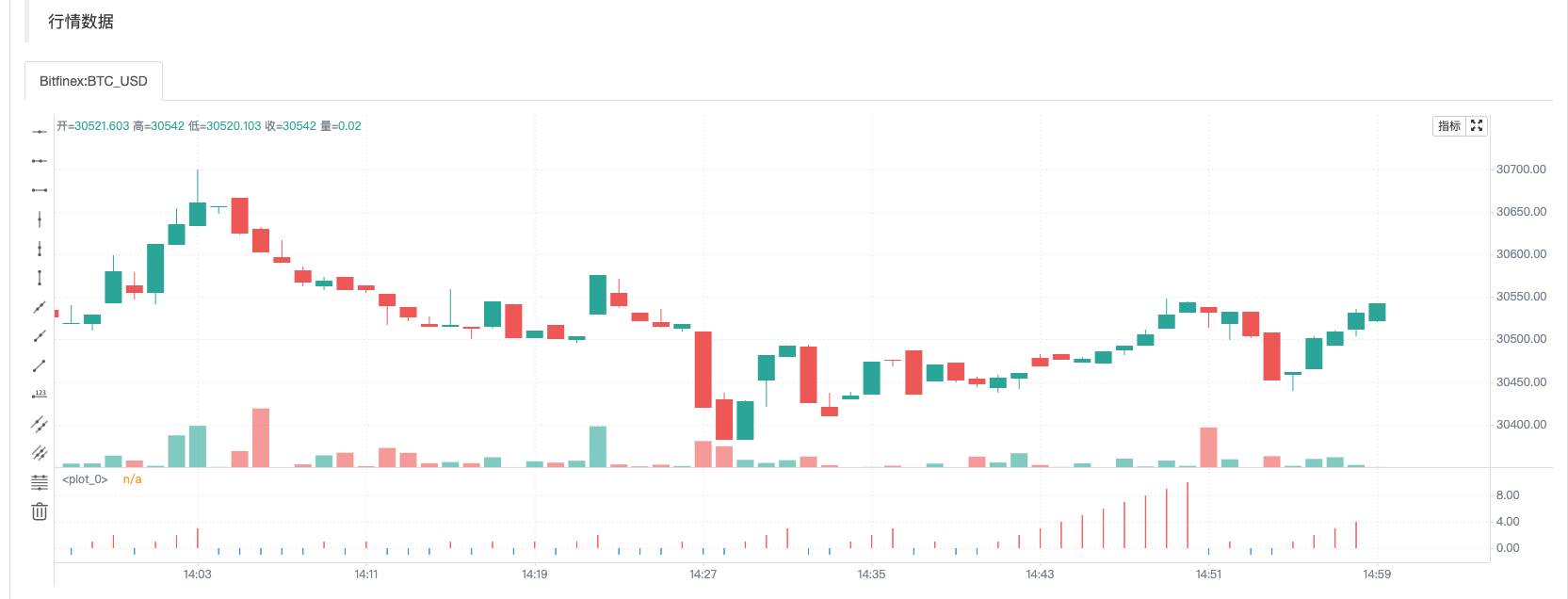
时刻A的截图
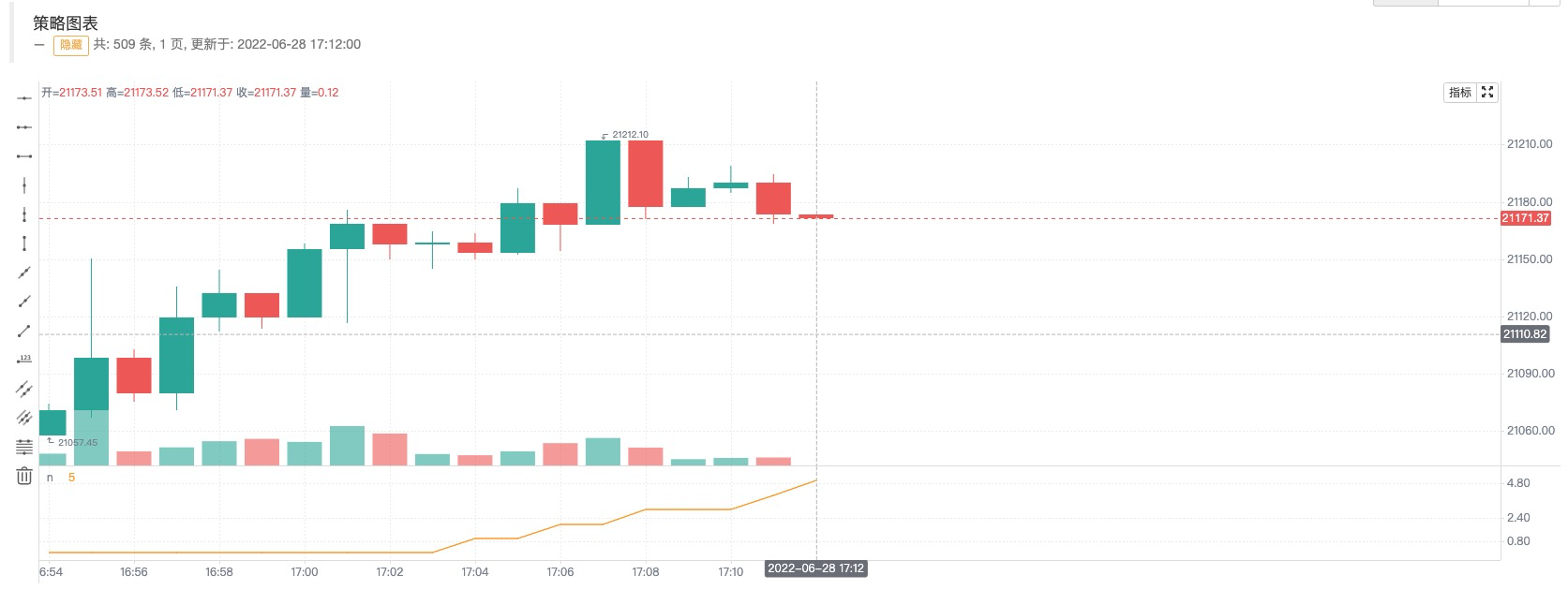
时刻B的截图
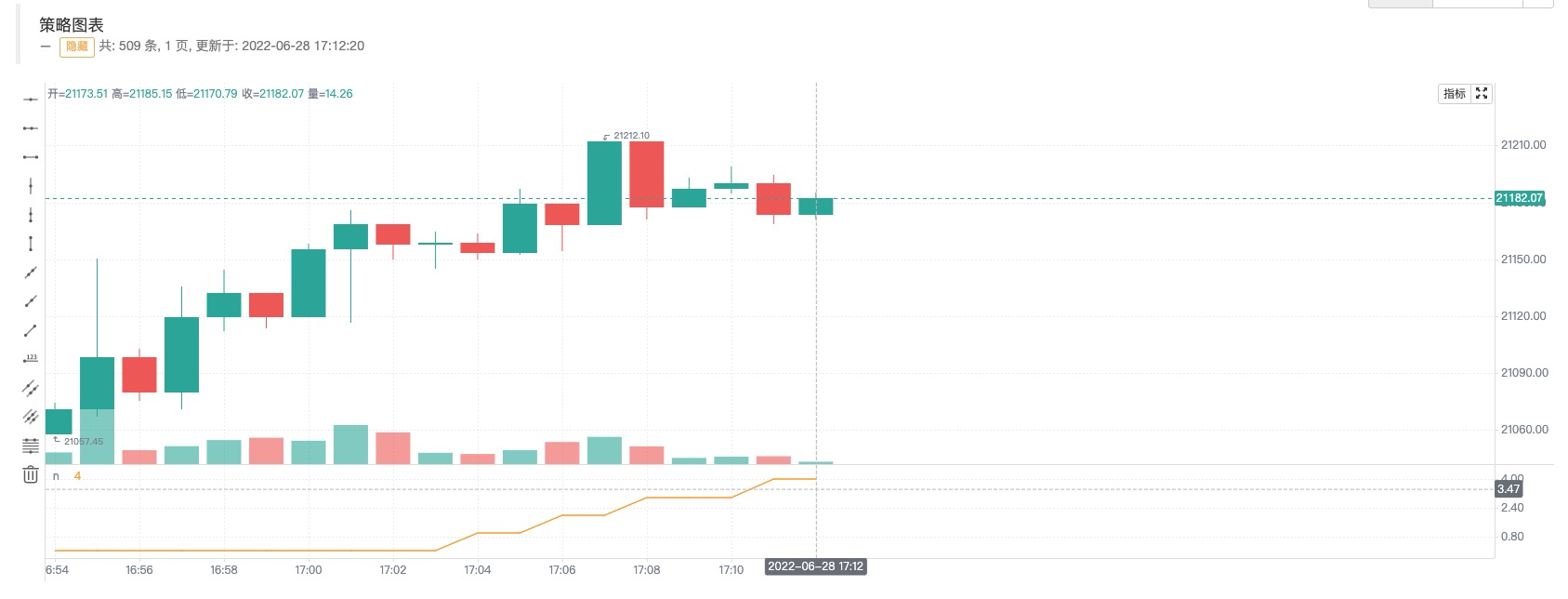
我们只修改了这句:n := open > close ? n + 1 : n,当前实时Bar为阴线(即开盘价高于收盘价)时才给n累加1。可以看到在第一张图(时刻A)中由于当时开盘价格高于收盘价格(阴线)所以n累加了1,图表曲线n显示的值为5。然后行情变动、价格更新如同第二张图(时刻B)中显示。此时开盘价格低于收盘价格(阳线),n值回滚并且也没有累加1。图表中曲线n也立即重绘,此时曲线上的n值为4。所以在实时Bar上显示的金叉、死叉等信号都是不确定的,有可能会变化的。
- 函数中的变量上下文
下面我们来一起研究一下Pine语言函数中的变量。根据一些Pine教程上的描述,函数中的变量与函数外的变量有这样的差异:
Pine函数中使用的系列变量的历史是通过对函数的每次连续调用创建的。如果没有在脚本运行的每个柱上调用函数,这将导致函数本地块内部与外部系列的历史值之间存在差异。因此,如果没有在每个柱上调用函数,则使用相同索引值在函数内部和外部引用的系列将不会引用相同的历史点。
是不是有些难以读懂?没关系,我们通过一个在FMZ上运行的测试代码来弄明白这个问题:
/*backtest
start: 2022-06-03 09:00:00
end: 2022-06-08 15:00:00
period: 1m
basePeriod: 1m
exchanges: [{"eid":"Bitfinex","currency":"BTC_USD"}]
*/
f(a) => a[1]
f2() => close[1]
oneBarInTwo = bar_index % 2 == 0
plotchar(oneBarInTwo ? f(close) : na, title = "f(close)", color = color.red, location = location.absolute, style = shape.xcross, overlay = true, char = "A")
plotchar(oneBarInTwo ? f2() : na, title = "f2()", color = color.green, location = location.absolute, style = shape.circle, overlay = true, char = "B")
plot(close[2], title = "close[2]", color = color.red, overlay = true)
plot(close[1], title = "close[1]", color = color.green, overlay = true)
回测运行截图
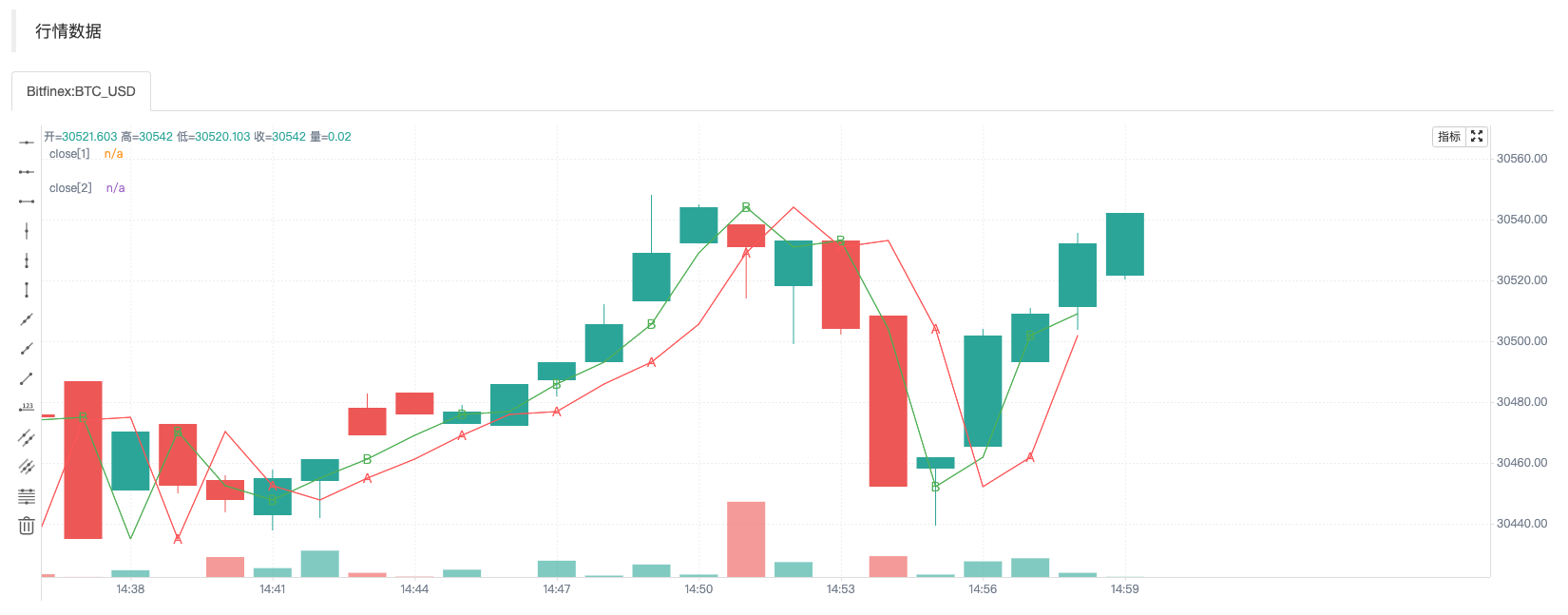
测试代码比较简单,主要是来考察两种方式引用的数据,即:f(a) => a[1]和f2() => close[1]。
f(a) => a[1]:使用传参数的方式,函数最后返回a[1]。f2() => close[1]:直接使用内置变量close,函数最后返回close[1]。
- ```plotchar(oneBarInTwo ? f(close) : na, title = "f(close)", color = color.red, location = location.absolute, style = shape.xcross, overlay = true, char = "A")```
画一个字符“A”,颜色为红色,当oneBarInTwo为真时才画出,画出的位置(Y轴上)为:```f(close)```返回的值。
- ```plotchar(oneBarInTwo ? f2() : na, title = "f2()", color = color.green, location = location.absolute, style = shape.circle, overlay = true, char = "B")```
画一个字符“B”,颜色为绿色,当oneBarInTwo为真时才画出,画出的位置(Y轴上)为:```f2()```返回的值。
- ```plot(close[2], title = "close[2]", color = color.red, overlay = true)```
画线,颜色为红色,画出的位置(Y轴上)为:```close[2]```即当前Bar前数第2根(向左数2根)Bar上的收盘价。
- ```plot(close[1], title = "close[1]", color = color.green, overlay = true)```
画线,颜色为绿色,画出的位置(Y轴上)为:```close[1]```即当前Bar前数第1根(向左数1根)Bar上的收盘价。
通过策略回测运行截图可以看到,虽然画A标记使用的函数```f(a) => a[1]```和画B标记使用的函数```f2() => close[1]```都是使用[1]来引用数据系列上的历史数据,但是图表上"A"和"B"的标记位置是完全不同的。"A"标记的位置总是落在红色的线上,也就是策略中代码```plot(close[2], title = "close[2]", color = color.red, overlay = true)```画出的线上,其画线使用的数据是```close[2]```。
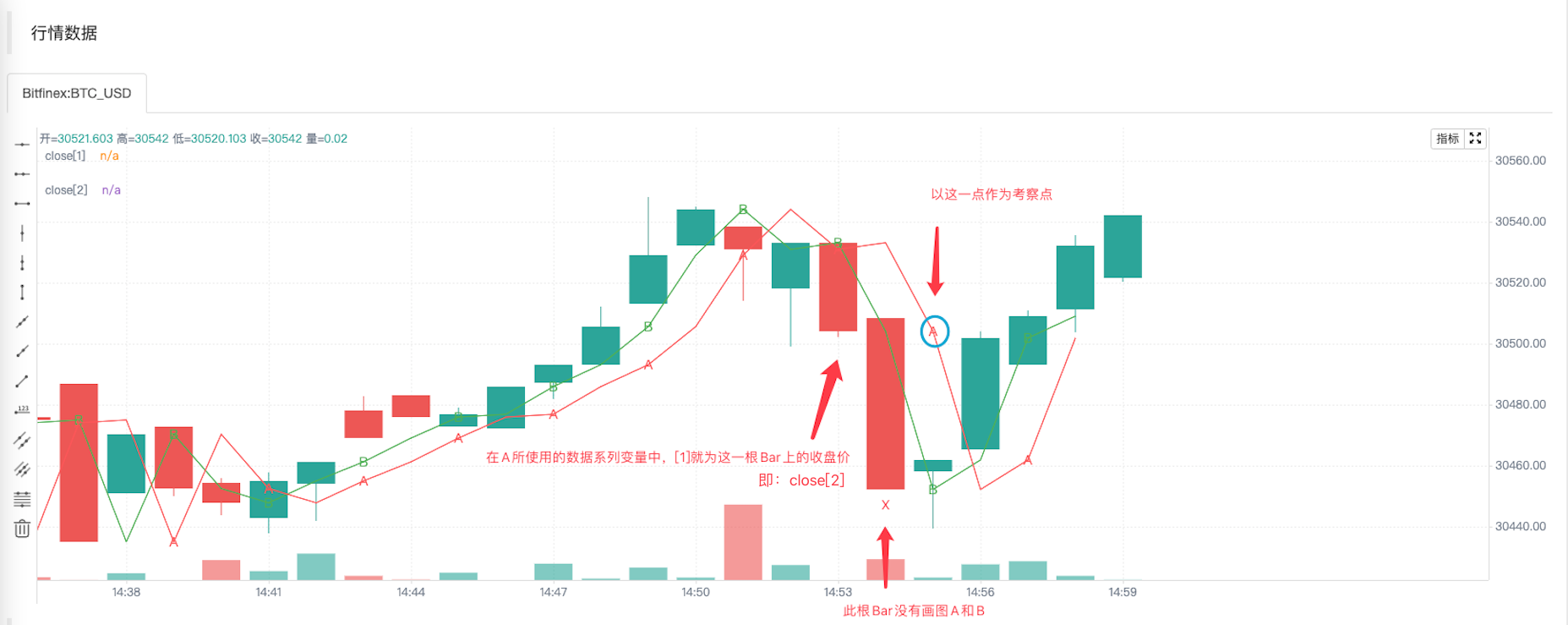
原因就是通过K线Bar的索引,即内置变量```bar_index```计算是否画"A"和"B"标记。"A"和"B"标记并不是在每根K线Bar上都画图(画图时调用函数计算)。函数```f(a) => a[1]```这种方式引用的值,如果函数不是每根Bar上都调用就会与函数```f2() => close[1]```这种方式引用的值不相同(即使都使用[1]这样相同的索引)。
- 一些内置函数需要在每个Bar上计算才能正确计算其结果
以一个简单例子说明这种情况:
```pine
res = close > close[1] ? ta.barssince(close < close[1]) : -1
plot(res, style = plot.style_histogram, color=res >= 0 ? color.red : color.blue)
我们将函数调用代码ta.barssince(close < close[1])写在一个三元操作符condition ? value1 : value2中。这就导致了只在close > close[1]时去调用ta.barssince函数。可偏偏ta.barssince函数是计算从最近一次close < close[1]成立时的K线数量。调用ta.barssince函数时都是close > close[1],即当前收盘价大于上一根Bar的收盘价,函数ta.barssince被调用时其条件close < close[1]都不成立,也就没有最近一次成立的位置。
ta.barssince : 调用时,如果在当前K线之前从未满足该条件,则该函数返回na。
如图:
所以画图时,只画出了res变量有值时的数据(-1)。
要避免这个问题,我们只用把ta.barssince(close < close[1])函数调用从三元操作符中拿出来,写在任何可能的条件分支外部。使其在每根K线Bar上都执行计算。
a = ta.barssince(close < close[1])
res = close > close[1] ? a : -1
plot(res, style = plot.style_histogram, color=res >= 0 ? color.red : color.blue)
时间序列
时间序列这个概念在Pine语言中非常重要,是我们学习Pine语言时必须要弄明白的一个概念。时间序列不是一种类型而是用于随时间存储变量的连续值的基本结构,我们知道Pine脚本是基于图表的,图表中展示的最基本的内容就是K线图。时间序列其中每个值都与一个K线Bar的时间戳关联。open是一个Pine语言的内置变量(built-in),其结构为储存每根K线Bar开盘价的时间序列。可以理解为open这个时间序列结构代表了当前K线图从开始的第一根Bar到当前脚本执行的这根Bar时所有K线Bar的开盘价。如果当前K线图是5分钟周期,那么我们在Pine策略代码中引用(或者使用)open时就是在使用策略代码当前执行时的K线Bar的开盘价。如果要引用时间序列中的历史值需要使用[]操作符。当Pine策略在某根K线Bar上执行时,使用open[1]表示引用open时间序列上当前脚本执行的这根K线Bar的前一根K线Bar的开盘价(即上一个K线周期的开盘价)。
- 时间序列上的变量非常方便用于计算
我们以内置函数
ta.cum举例子:
ta.cum
Cumulative (total) sum of `source`. In other words it's a sum of all elements of `source`.
ta.cum(source) → series float
RETURNS
Total sum series.
ARGUMENTS
source (series int/float)
SEE ALSO
math.sum
测试代码:
v1 = 1
v2 = ta.cum(v1)
plot(v1, title="v1")
plot(v2, title="v2")
plot(bar_index+1, title="bar_index")
有很多类似ta.cum这样的内置函数可以直接处理时间序列上的数据,例如ta.cum就是把传入的变量在每个K线Bar上对应的值累加起来,接下来我们使用一个图表来方便理解。
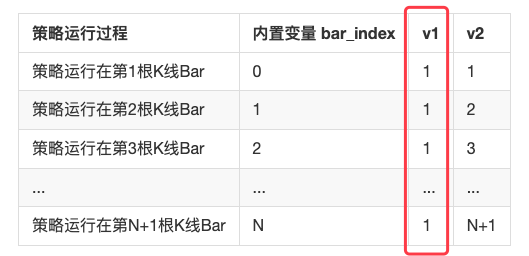
|策略运行过程|内置变量 bar_index|v1|v2| | - | - | - | - | |策略运行在第1根K线Bar|0|1|1| |策略运行在第2根K线Bar|1|1|2| |策略运行在第3根K线Bar|2|1|3| |…|…|…|…| |策略运行在第N+1根K线Bar|N|1|N+1|
可以看到,其实v1、v2甚至bar_index都是时间序列结构,在每根Bar上都有对应的数据。这个测试代码不论用「实时价模型」还是「收盘价模型」区别仅仅为图表上是否显示实时Bar。为了回测速度我们使用「收盘价模型」回测测试。
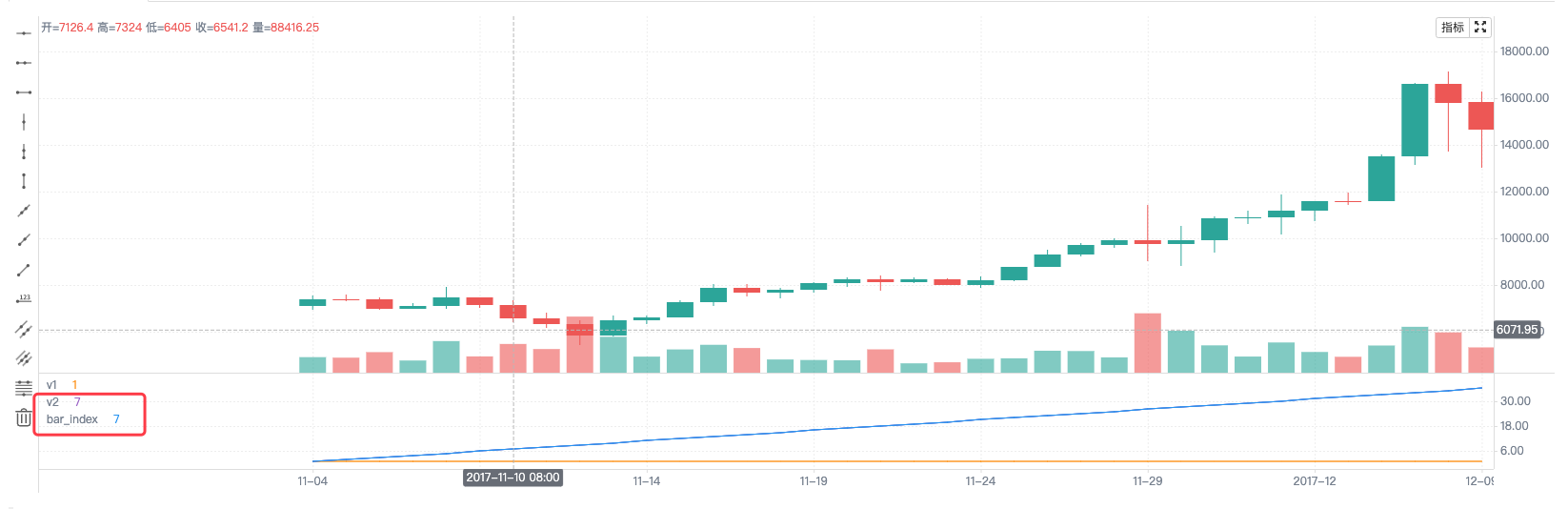
因为v1这个变量在每一根Bar上都是1,ta.cum(v1)函数在第一根K线Bar上执行时由于只有第一根Bar,所以计算结果为1,赋值给变量v2。
当ta.cum(v1)在第二根K线Bar上执行时,已经有2根K线Bar了(第一根对应的内置变量bar_index是0,第二根对应的内置变量bar_index是1),所以计算结果为2,赋值给变量v2,以此类推。实际上可以观察到v2就是图表中K线Bar的数量,由于K线的索引bar_index是从0开始递增,那么bar_index + 1实际上也就是K线Bar的数量。观察图表也可以看到线v2和bar_index确实是重合的。
同样我也可以用ta.cum内置函数计算当前图表上所有Bar的收盘价之和,那么只用这样写就可以了:ta.cum(close),当策略运行到最右侧的实时Bar时ta.cum(close)计算出的结果就是图表上所有Bar的收盘价之和了(没有运行到最右侧时,只是累加到了当前Bar而已)。
时间序列上的变量也可以使用运算符进行运算,例如代码:ta.sma(high - low, 14),把内置变量high(K线Bar最高价)减去low(K线Bar最低价),最后使用ta.sma函数求平均值。
- 函数调用结果也会在时间序列中留下值的痕迹
v1 = ta.highest(high, 10)[1]
v2 = ta.highest(high[1], 10)
plot(v1, title="v1", overlay=true)
plot(v2, title="v2", overlay=true)
该测试代码在回测时测试运行,可以观察到v1和v2的值是相同的,图表上画出的线也是完全重合的。函数调用计算出的结果在时间序列中会留下值的痕迹,例如代码ta.highest(high, 10)[1]其中的ta.highest(high, 10)函数调用计算出的结果也是可以用[1]来引用其历史值的。基于当前Bar的上一根Bar对应的ta.highest(high, 10)计算结果就是ta.highest(high[1], 10)。所以ta.highest(high[1], 10)和ta.highest(high, 10)[1]完全等价。
使用另一种画图函数输出信息验证:
a = ta.highest(close, 10)[1]
b = ta.highest(close[1], 10)
plotchar(true, title="a", char=str.tostring(a), location=location.abovebar, color=color.red, overlay=true)
plotchar(true, title="b", char=str.tostring(b), location=location.belowbar, color=color.green, overlay=true)
可以看到时间序列中变量a和变量b的值显示在对应的Bar的上方和下方。在学习过程中可以保留这个画图代码,因为在测试、试验时可能经常需要在图表上输出信息用于观察。
脚本结构
一般结构
在教程开始部分我们总结过一些FMZ上的Pine和Trading View上的Pine语言使用方面的不同点,FMZ上的Pine代码编写时可以省略版本号、indicator()、strategy()、并且暂时不支持library()。当然为了兼容较早版本的Pine脚本,策略编写时写上诸如://@version=5,indicator(),strategy()也是可以的。一些策略设置也可以在strategy()函数中传参设置。
<version>
<declaration_statement>
<code>
#### 注释
Pine语言使用```//```作为单行注释符,由于Pine语言没有多行注释符。FMZ扩展了注释符```/**/```用于多行注释。
#### 代码
脚本中不是注释或编译器指令的行是语句,它实现了脚本的算法。一个语句可以是这些内容之一。
- 变量声明
- 变量的重新赋值
- 函数声明
- 内置函数调用,用户定义的函数调用
- ```if```,```for```,```while```或```switch```等结构
**语句可以以多种方式排列**
- 有些语句可以用一行来表达,比如大多数变量声明、只包含一个函数调用的行或单行函数声明。其他的,像结构,总是需要多行,因为它们需要一个局部的块。
- 脚本的全局范围内的语句(即不属于局部块的部分)不能以```空格```或```制表符```(tab键)开始。它们的第一个字符也必须是该行的第一个字符。在行的第一个位置开始的行,根据定义成为脚本的全局范围的一部分。
- 结构或多行函数声明总是需要一个```local block```。一个本地块必须缩进一个制表符或四个空格(否则,会被解析为上一行的串联代码,即被判定为上一行代码的连续内容),每个局部块定义了一个不同的局部范围。
- 多个单行语句可以通过使用逗号(,)作为分隔符在一行中串联起来。
- 一行中可以包含注释,也可以只是注释。
- 行也可以被包起来(在多行上继续)。
例如,包括三个局部块,一个在自定义函数声明中,两个在变量声明中使用if结构,如下代码:
```pine
indicator("", "", true) // 声明语句(全局范围),可以省略不写
barIsUp() => // 函数声明(全局范围)
close > open // 本地块(本地范围)
plotColor = if barIsUp() // 变量声明 (全局范围)
color.green // 本地块 (本地范围)
else
color.red // 本地块 (本地范围)
runtime.log("color", color = plotColor) // 调用一个内置函数输出日志 (全局范围)
换行代码
长行可以被分割在多行上,或被 “包裹 “起来。被包裹的行必须缩进任何数量的空格,只要它不是4的倍数(这些边界用于缩进局部块)。
a = open + high + low + close
可以被包装成(注意每行缩进的空格数量都不是4的倍数):
a = open +
high +
low +
close
一个长的plot()调用可以被包装成。
close1 = request.security(syminfo.tickerid, "D", close) // syminfo.tickerid 当前交易对的日线级别收盘价数据系列
close2 = request.security(syminfo.tickerid, "240", close) // syminfo.tickerid 当前交易对的240分钟级别收盘价数据系列
plot(ta.correlation(close, open, 100), // 一行长的plot()调用可以被包装
color = color.new(color.purple, 40),
style = plot.style_area,
trackprice = true)
用户定义的函数声明中的语句也可以被包装。但是,由于局部块在语法上必须以缩进开始(4个空格或1个制表符),当把它分割到下一行时,语句的延续部分必须以一个以上的缩进开始(不等于4个空格的倍数)。比如说:
test(c, o) =>
ret = c > o ?
(c > o+5000 ?
1 :
0):
(c < o-5000 ?
-1 :
0)
a = test(close, open)
plot(a, title="a")
标识符和运算符
标识符
在认识变量之前,我们首先要了解“标识符”的概念。通俗的讲“标识符”是用来当做函数和变量的名称的(用于命名变量、函数)。函数在我们之后的教程中会了解到,我们首先学习一下“标识符”。
- 1、标识符必须以大写
(A-Z)或小写(a-z)字母或下划线(_)开头,作为标识符的第一个字符。 - 2、标识符第一个字符之后的下一个字符可以是字母、下划线或数字。
- 3、标识符的命名是区分大小写的。
例如以下命名的标识符:
fmzVar
_fmzVar
fmz666Var
funcName
MAX_LEN
max_len
maxLen
3barsDown // 错误的命名!使用了数字字符作为标识符的开头字符
如同大部分的编程语言一样,Pine语言也有书写建议。通常建议对标识符的命名时:
- 1、全部字母大写用于命名常量。
- 2、使用小驼峰规则用于其它标识符命名。
// 命名变量、常量
GREEN_COLOR = #4CAF50
MAX_LOOKBACK = 100
int fastLength = 7
// 命名函数
zeroOne(boolValue) => boolValue ? 1 : 0
运算符
运算符是编程语言中用于构建表达式的一些运算符号,而表达式则是我们编写策略时为了某种计算目的设计的计算规则。Pine语言中的运算符按照功能分类为:
赋值运算符、算数运算符、比较运算符、逻辑运算符、? :三元运算符、[]历史引用运算符。
以算数运算符*为例,区别于Trading View 上的Pine语言运算符返回结果导致的类型问题,有以下测试代码:
//@version=5
indicator("")
lenInput = input.int(14, "Length")
factor = year > 2020 ? 3 : 1
adjustedLength = lenInput * factor
ma = ta.ema(close, adjustedLength) // Compilation error!
plot(ma)
在Trading View上执行这个脚本时会编译报错,原因是adjustedLength = lenInput * factor相乘之后结果为series int类型(系列),然而ta.ema函数的第二个参数不支持这种类型。但是在FMZ上没有此类的严格限制,以上代码是可以正常运行的。
下面我们来一起看看各种运算符的使用。
赋值运算符
赋值运算符有2种:=、:=,我们在教程开始部分的几个例子里也见过了。
a = close // 使用内置变量赋值给a b = 10000 // 使用数值赋值 c = “test” // 使用字符串赋值 d = color.green // 使用颜色值赋值 plot(a, title=“a”) plot(b, title=“b”) plotchar(true, title=“c”, char=str.tostring©, color=d, overlay=true)
注意```a = close```赋值语句,在每个Bar上变量a都是当前该Bar的收盘价(close)。其它的变量```b```、```c```、```d```是不变的,可以在FMZ上的回测系统中测试,由画图可以看出结果。
```:=```用于将值重新赋值给现有变量,可以简单理解为使用```:=```操作符是用来修改已经声明过、初始化过的变量值。
如果使用```:=```操作符给未初始化或者声明的变量赋值会引发错误,例如:
```pine
a := 0
所以,:=赋值操作符一般是用于已有变量的重新赋值,例如:
a = close > open
b = 0
if a
b := b + 1
plot(b)
判断如果close > open(即当前BAR是阳线),a变量就是真值(true)。就会执行if语句的本地块中的代码b := b + 1,使用赋值操作符:=给b重新赋值,累加一个1。然后再使用plot函数在图表上画出变量b在时间序列各个BAR上的值,连成线。
我们是不是认为出现一个阳线BAR,b就会持续累加1呢?当然不是,这里我们给变量b声明、初始化为0的时候没有使用任何关键字指定。这句b=0是在每个BAR上都执行的,所以可以看到这个代码的运行结果是每次都把b变量重置为0,如果a变量为真值,即符合close > open那么本轮执行代码时b是会累加1,plot函数画图的时候b为1,但是下一轮执行代码的时候b就重新赋值为0了。这里也是Pine语言初学者容易踩坑的地方。
讲到赋值运算符,这里就必须扩展讲解两个关键字:var、varip
- var
其实这个关键字,我们在之前的教程中也已经见过、用过,只不过当时都没有详细探讨。我们先来看下这个关键字的描述:
var 是用于分配和一次性初始化变量的关键字。通常,不包含关键字var的变量赋值语法会导致每次更新数据时都会覆盖变量的值。 与此相反,当使用关键字var分配变量时,尽管数据更新,它们仍可以“保持状态”
我们还是使用这个例子,只不过我们给b赋值时使用var关键字。
a = close > open
var b = 0
if a
b := b + 1
plot(b)
var声明的变量不仅可以写在全局范围,也可以写在代码块中,例如这个例子:
```pine
strategy(overlay=true)
var a = close
var b = 0.0
var c = 0.0
var green_bars_count = 0
if close > open
var x = close
b := x
green_bars_count := green_bars_count + 1
if green_bars_count >= 10
var y = close
c := y
plot(a, title = "a")
plot(b, title = "b")
plot(c, title = "c")
变量’a’保持系列中第一根柱线的收盘价。 变量’b’保持系列中第一个“绿色”价格棒的收盘价。 变量’c’保持系列中第十个“绿色”条的收盘价。
- varip
> varip(var intrabar persist)是用于分配和一次性初始化变量的关键词。它与var关键词相似,但是使用varip声明的变量在实时K线更新之间保留其值。
是不是比较难以理解?没关系,我们通过例子来讲解,就很容易明白了。
strategy(overlay=true)
// 测试 var varip var i = 0 varip ii = 0
// 将策略逻辑每轮改变的i、ii打印在图上 plotchar(true, title=“ii”, char=str.tostring(ii), location=location.abovebar, color=color.red) plotchar(true, title=“i”, char=str.tostring(i), location=location.belowbar, color=color.green)
// 每轮逻辑执行都给i、ii递增1 i := i + 1 ii := ii + 1
这个测试代码在「收盘价模型」、「实时价模型」上有不同表现:
实时价模型:
还记得我们之前讲解的策略执行时分为历史BAR阶段,实时BAR阶段吗?当在实时价模型,历史K线阶段时```var```、```varip```声明的变量```i```、```ii```在策略代码每轮执行时都会执行递增操作。所以可以看到回测结果K线BAR上显示的数字逐个都是递增1的。当历史K线阶段结束,开始实时K线阶段。var、varip声明的变量则开始发生不同的变化。因为是实时价模型,在一根K线BAR内每次价格变动都会执行一遍策略代码,```i := i + 1```和```ii := ii + 1```都会执行一次。区别是ii每次都修改。i虽然每次也修改,但是下一轮执行策略逻辑时会恢复之前的值(记得之前「模型执行」章节我们讲解的回滚机制吗?),直到当前K线BAR走完才更新确定i的值(即下一轮执行策略逻辑时不再恢复之前的值)。所以可以看到变量i依然是每根BAR增加1。但是变量ii每根BAR就累加了好几次。
收盘价模型:
由于收盘价模型是每根K线BAR走完时才执行一次策略逻辑。所以在收盘价模型时,历史K线阶段和实时K线阶段,var、varip声明的变量在以上例子中递增表现完全一致,都是每根K线BAR递增1。
---------------------------
##### 算数运算符
|运算符|说明|
|-|-|
|+|加法|
|-|减法|
|*|乘法|
|/|除法|
|%|求模|
```+```、```-```操作符可以用作二元操作符,也可以当做一元操作符。其它的算数运算符只能用作二元操作符,如果用作一元操作符会报错。
1、算数运算符两侧都是数值类型,结果为数值类型,整型还是浮点数具体看运算结果。
2、如果其中有操作数是字符串,操作符是```+```,则计算结果为字符串,数值会转换成字符串形式,然后字符串拼接在一起。如果是其它算数运算符,则会尝试将字符串转换为数值,然后运算。
3、如果其中有操作数是na,则计算结果为空值na,在FMZ上打印的时候会显示NaN。
```pine
a = 1 + 1
b = 1 + 1.1
c = 1 + "1.1"
d = "1" + "1.1"
e = 1 + na
runtime.log("a:", a, ", b:", b, ", c:", c, ", d:", d, ", e:", e)
// a: 2 , b: 2.1 , c: 11.1 , d: 11.1 , e: NaN
FMZ上的Pine语言这里和Trading View上的Pine语言有一点差别,FMZ上的Pine语言对于变量类型要求并不是十分苛刻、严格。例如:
a = 1 * "1.1"
b = "1" / "1.1"
c = 5 % "A"
plot(a)
plot(b)
plot(c)
在FMZ上是可以运行的,但是在trading view上就会报类型错误。对于算数运算符两边的操作数都是字符串时,系统会把字符串转换为数值之后计算。如果是非数值字符串无法计算时,系统运算结果就为空值na。
比较运算符
比较操作符都是二元操作符。
| 运算符 | 说明 |
|---|---|
| < | 小于 |
| > | 大于 |
| <= | 小于等于 |
| >= | 大于等于 |
| == | 相等 |
| != | 不相等 |
测试例子:
a = 1 > 2
b = 1 < 2
c = "1" <= 2
d = "1" >= 2
e = 1 == 1
f = 2 != 1
g = open > close
h = na > 1
i = 1 > na
runtime.log("a:", a, ", b:", b, ", c:", c, ", d:", d, ", e:", e, ", f:", f, ", g:", g, ", h:", h, ", i:", i)
// a: false , b: true , c: true , d: false , e: true , f: true , g: false , h: false , i: false
可以看到,比较运算符使用是很简单的,不过这个也是我们在编写策略时用的最多的操作符。既可以比较数值,也可以比较内置变量,例如close、open等。
和运算操作符一样,在FMZ上与Trading View的Pine是有区别的,FMZ没有特别严苛的要求类型,所以此类语句d = "1" >= 2在FMZ上不会报错,执行时会先将字符串转换为数值,然后比较运算。在Trading View上会报错。
逻辑运算符
| 运算符 | 代码符号 | 说明 |
|---|---|---|
| 非 | not | 一元操作符,非运算 |
| 与 | and | 二元操作符,与(且)运算 |
| 或 | or | 二元操作符,或运算 |
讲到逻辑运算符,那么一定就要讲讲真值表了。和我们高中时学习的一样,只不过这里我们在回测系统进行测试、学习:
a = 1 == 1 // 使用比较运算符构成的表达式,结果为布尔值
b = 1 != 1
c = not b // 逻辑非操作符
d = not a // 逻辑非操作符
runtime.log("测试逻辑操作符:and", "#FF0000")
runtime.log("a:", a, ", c:", c, ", a and c:", a and c)
runtime.log("a:", a, ", b:", b, ", a and b:", a and b)
runtime.log("b:", b, ", c:", c, ", b and c:", b and c)
runtime.log("d:", d, ", b:", b, ", d and b:", d and b)
runtime.log("测试逻辑操作符:or", "#FF0000")
runtime.log("a:", a, ", c:", c, ", a or c:", a or c)
runtime.log("a:", a, ", b:", b, ", a or b:", a or b)
runtime.log("b:", b, ", c:", c, ", b or c:", b or c)
runtime.log("d:", d, ", b:", b, ", d or b:", d or b)
runtime.error("stop")
为了不让回测系统一直不停的打印信息影响观察,我们使用runtime.error("stop")语句在执行一遍打印之后,就抛出异常错误让回测停止,之后就可以观察输出的信息了,可以发现打印的内容和真值表其实是一样的。
三元运算符
使用三元运算符? :和操作数组合起来的三元表达式condition ? valueWhenConditionIsTrue : valueWhenConditionIsFalse我们在之前的课程上也已经熟悉过了。所谓三元表达式、三元运算符意思是其中的操作数一共有三个。
虽然没什么实际用途,但是方便演示的例子:
```pine
a = close > open
b = a ? "阳线" : "阴线"
c = not a ? "阴线" : "阳线"
plotchar(a, location=location.abovebar, color=color.red, char=b, overlay=true)
plotchar(not a, location=location.belowbar, color=color.green, char=c, overlay=true)
如果碰到十字星怎么办,没关系!三元表达式也是可以嵌套的,在之前的教程里我们也这么干过了。
a = close > open
b = a ? math.abs(close-open) > 30 ? "阳线" : "十字星" : math.abs(close-open) > 30 ? "阴线" : "十字星"
c = not a ? math.abs(close-open) > 30 ? "阴线" : "十字星" : math.abs(close-open) > 30 ? "阳线" : "十字星"
plotchar(a, location=location.abovebar, color=color.red, char=b, overlay=true)
plotchar(not a, location=location.belowbar, color=color.green, char=c, overlay=true)
其实就是相当于把condition ? valueWhenConditionIsTrue : valueWhenConditionIsFalse中的valueWhenConditionIsTrue、valueWhenConditionIsFalse,也使用另外的三元表达式代替。
历史运算符
使用历史运算符[],引用时间序列上的历史值。这些历史值是变量在脚本运行时当前K线BAR之前的K线BAR上的值。[]运算符用于变量、表达式、函数调用之后。[]这个方括号中的数值就是我们要引用的历史数据距离当前K线BAR的偏移量。例如我要引用上一根K线BAR的收盘价,就书写为:close[1]。
我们在之前的课程中都已经见过类似这样的写法:
high[10]
ta.sma(close, 10)[1]
ta.highest(high, 10)[20]
close > nz(close[1], open)
```pine
a = close[1][2] // 错误
可能看到这里,有些同学会说,操作符[]就是用于系列结构的,看起来系列结构(series)和数组差不多嘛!
下面我们来通过一个例子来说明一下Pine语言中的系列(series)和数组并不同。
strategy("test", overlay=true)
a = close
b = close[1]
c = b[1]
plot(a, title="a")
plot(b, title="b")
plot(c, title="c")
虽然说a = close[1][2]这样写会报错,但是:
b = close[1]
c = b[1]
分开写就不会报错了,如果按照通常的数组来理解,b = close[1]赋值之后,b应该是一个数值,然而c = b[1],b依然可以再次被使用历史操作符引用历史值。可见Pine语言中的系列(series)概念并不是数组那么简单。可以理解为close的上一根Bar上的历史值(赋值给b),b也是一个时间序列结构(time series),可以继续引用其历史值。所以我们看到画出的三条线a、b、c中,b线慢于a线一个BAR,c线慢于b线一个BAR。c线慢于a线2个BAR。
我们可以把图表拉倒最左侧,观察发现在第一根K线上,b和c的值均为空值(na)。那是因为当脚本在第一根K线BAR上执行时,向前引用一个、两个周期的历史值时是没有的,其不存在。所以我们在编写策略时需要经常注意,引用历史数据时是否会引用到空值,如果不加小心使用了空值会引起一系列的计算差别,甚至可能影响到实时BAR。通常我们会在代码中使用na、nz内置函数加以判断(其实我们之前的学习中也接触过nz、na函数,还记得在哪个章节吗?)具体处理空值的情况,例如:
close > nz(close[1], open) // 当引用close内置变量前一个BAR的历史值时,如果不存在,则使用open内置变量
这便是一种对于可能引用到空值(na)的处理。
运算符优先级
我们已经学习了很多Pine语言的运算符,这些运算符通过和操作数各种各样的组合就形成了表达式。那么在表达式中计算的时候,这些运算的优先级是怎么样的呢?好比我们上学的时候学习的四则运算,有乘除法优先计算乘除法,再计算加减法。Pine语言中表达式也是一样的。
| 优先级 | 运算符 |
|---|---|
| 9 | [] |
| 8 | 一元运算符时的+ 、-和not |
| 7 | *、/、% |
| 6 | 二元运算符时的+、- |
| 5 | >、<、>=、<= |
| 4 | ==、!= |
| 3 | and |
| 2 | or |
| 1 | ?: |
优先级高的表达式部分先进行运算,如果优先级相同则从左到右运算。如果要强制先运算某个部分,可以使用()包裹住强制先进行运算该部分表达式。
变量
变量声明
我们之前已经学习过了“标识符”的概念,“标识符”就是作为变量的名称来给变量命名的。所以也说:变量是保存值的标识符。那么如何声明一个变量呢?声明变量又有哪些规则?
- 声明模式:
在声明变量时最先写的就是「声明模式」,变量的声明模式有三种即:
1、使用关键字
var。 2、使用关键字varip。 3、什么都不写。
- 类型
FMZ上的Pine语言对于类型要求并不严苛,一般可以省略。不过为了兼容Trading View上的脚本策略,声明变量时也是可以带类型的。例如:
int i = 0 float f = 1.1
在Trading View上的类型是要求比较严苛的,如果使用以下代码在Trading View上则会报错:
baseLine0 = na // compile time error!
- 标识符
标识符即变量名称,标识符的命名在之前章节已经讲过,可以回看:https://www.fmz.com/bbs-topic/9390#%E6%A0%87%E8%AF%86%E7%AC%A6
总结一下,声明一个变量可以写作:
// [] [] = value 声明模式 类型 标识符 = 值
这里使用赋值运算符:```=```在变量声明时给变量赋值。赋值时,值可以是字符串、数值、表达式、函数调用、```if```、 ```for```、```while```或```switch```等结构(这些结构关键字、语句用法我们后续课程中会详细讲解,其实我们已经在之前的课程里学会了简单的if语句赋值,可以回顾看看)。
这里我们着重讲解一下input函数,这个函数是我们在设计编写策略时会很频繁用到的一个函数。也是设计策略时非常关键的函数。
**input函数:**
input函数,参数defval、title、tooltip、inline、group
在FMZ上的input函数和在Trading View上的有些不同,不过该函数都是作为策略参数的赋值输入使用。下面我们来通过一个例子详细说明input函数在FMZ上的使用:
```pine
param1 = input(10, title="参数1名称", tooltip="参数1的描述信息", group="分组名称A")
param2 = input("close", title="参数2名称", tooltip="参数2的描述信息", group="分组名称A")
param3 = input(color.red, title="参数3名称", tooltip="参数3的描述信息", group="分组名称B")
param4 = input(close, title="参数4名称", tooltip="参数4的描述信息", group="分组名称B")
param5 = input(true, title="参数5名称", tooltip="参数5的描述信息", group="分组名称C")
ma = ta.ema(param4, param1)
plot(ma, title=param2, color=param3, overlay=param5)
在声明变量时给变量赋值,经常使用的就是input函数,在FMZ上input函数会在FMZ策略界面自动画出用于设置策略参数的控件。FMZ上支持的控件目前有数值输入框、文本输入框、下拉框、布尔值勾选。并且可以设置策略参数分组、设置参数的提示文本信息等功能。
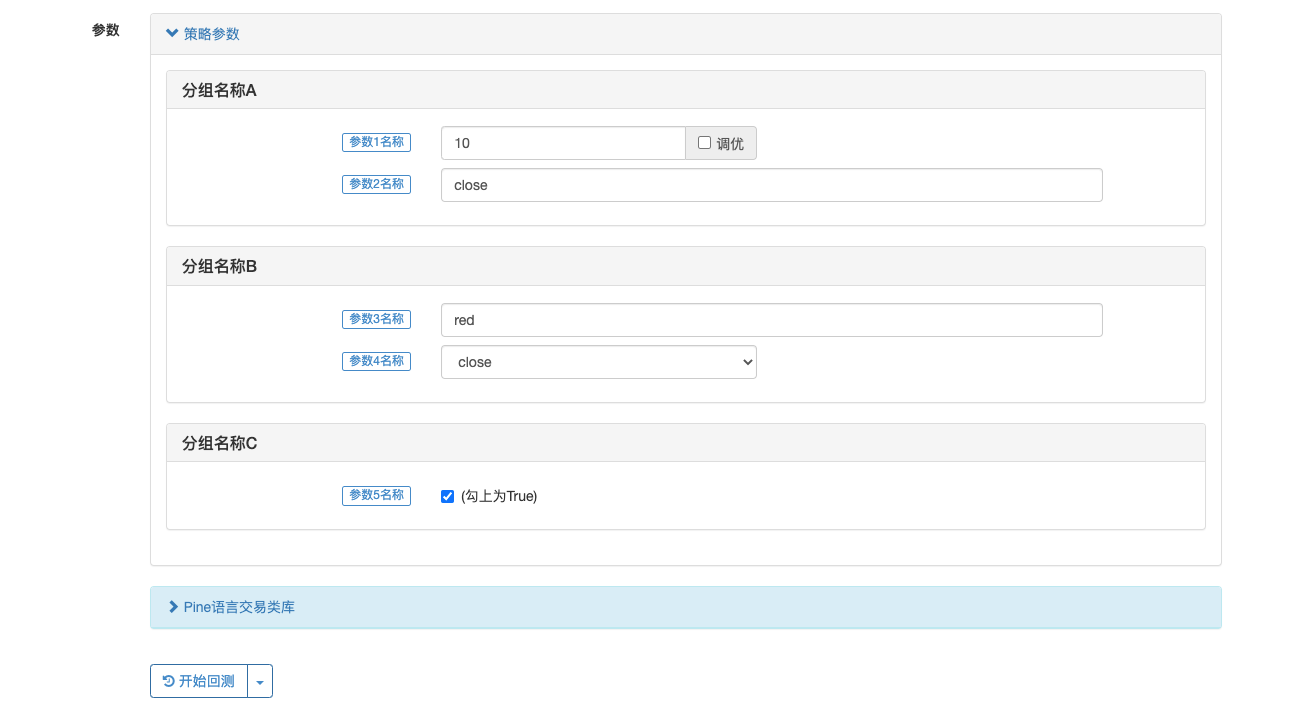
我们介绍input函数的几个主要参数:
- defval :作为input函数设置的策略参数选项的默认值,支持Pine语言的内置变量、数值、字符串
- title :策略在实盘/回测的策略界面上显示的参数名称。
- tooltip :策略参数的提示信息,当鼠标悬停在策略参数上会显示出这个参数设置的文本信息。
- group :策略参数分组名称,可以给参数分组。
除了单独的变量声明、赋值,Pine语言中还有声明一组变量并且赋值的写法:
[变量A,变量B,变量C] = 函数 或者 ```if```、 ```for```、```while```或```switch```等结构
最常见的就是我们使用ta.macd函数计算MACD指标时,由于MACD指标是一个多线的指标,计算出三组数据。所以就可以写为:
[dif,dea,column] = ta.macd(close, 12, 26, 9)
plot(dif, title="dif")
plot(dea, title="dea")
plot(column, title="column", style=plot.style_histogram)
我们使用以上代码就很容易画出MACD图表,不止是内置函数可以返回多个变量,编写的自定义函数也可以返回多个数据。
twoEMA(data, fastPeriod, slowPeriod) =>
fast = ta.ema(data, fastPeriod)
slow = ta.ema(data, slowPeriod)
[fast, slow]
[ema10, ema20] = twoEMA(close, 10, 20)
plot(ema10, title="ema10", overlay=true)
plot(ema20, title="ema20", overlay=true)
使用if等结构作为多个变量赋值的写法也和上面的自定义函数方式类似,有兴趣也可以试下。
[ema10, ema20] = if true
fast = ta.ema(close, 10)
slow = ta.ema(close, 20)
[fast, slow]
plot(ema10, title="ema10", color=color.fuchsia, overlay=true)
plot(ema20, title="ema20", color=color.aqua, overlay=true)
条件结构
一些函数是无法写在条件分支的本地代码块里的,主要有以下几个函数:
barcolor(), fill(), hline(), indicator(), plot(), plotcandle(), plotchar(), plotshape()
Trading View上会编译报错。FMZ上限制不是那么严苛,但是也建议遵循Trading View上的规范书写。例如这样虽然在FMZ上不报错,不过不建议这样写。
strategy("test", overlay=true)
if close > open
plot(close, title="close")
else
plot(open, title="open")
if语�
- 用什么接口能获取各币种的市值?
- 有好心人帮帮忙嘛?
- 分享一个趋势策略
- 适合普通人的期现套利
- 希望FMZ官方出代写项目活动
- 什么是套利?
- 币安千团大战策略申请
- 下单精度问题
- table 表格移除行,有什么办法吗
- 回测一直都没有信号 能解决吗?谢谢
- 请问多币种该如何画收益图表
- 数字货币
- 币本位
- 小小梦能看看吗,麦语言的策略 回测和实盘都是可以正常运行的 ,就是手机实盘那里 点进去显示错误,这什么情况
- 回测可视化不显示买卖点图标
- 延迟
- 公用回测服务器不能用了吗?
- 服务器不在线 回测不了了
- GetOrder id获取不到订单信息
- 收盘价模型和实时价模型有什么区别呢?比如我是15分钟K线实盘,收盘价模型会不会导致成交价格偏差很大?上下影线部分会形成成交吗?