মেশিন লার্নিংয়ের তিনটি প্রধান বিভাগ এবং ছয়টি প্রধান অ্যালগরিদমের সুবিধা এবং অসুবিধাগুলির একটি সম্পূর্ণ ব্যাখ্যা
 0
3331
0
3331
মেশিন লার্নিংয়ের তিনটি প্রধান বিভাগ এবং ছয়টি প্রধান অ্যালগরিদমের সুবিধা এবং অসুবিধাগুলির একটি সম্পূর্ণ ব্যাখ্যা
মেশিন লার্নিং-এ, লক্ষ্য হয় পূর্বাভাস বা ক্লাস্টারিং। এই নিবন্ধটি মূলত পূর্বাভাসের উপর দৃষ্টি নিবদ্ধ করে। পূর্বাভাস হ’ল একটি ইনপুট ভেরিয়েবলের একটি সেট থেকে আউটপুট ভেরিয়েবলের মান অনুমান করার প্রক্রিয়া। উদাহরণস্বরূপ, একটি বাড়ির বৈশিষ্ট্যগুলির একটি সেট দেওয়া হলে আমরা এর বিক্রয় মূল্যের পূর্বাভাস দিতে পারি। পূর্বাভাস প্রশ্নগুলি দুটি প্রধান বিভাগে বিভক্ত করা যেতে পারেঃ এখন আমরা মেশিন লার্নিং এর সবচেয়ে জনপ্রিয় এবং ব্যবহৃত অ্যালগরিদমগুলো নিয়ে আলোচনা করব। আমরা এই অ্যালগরিদমগুলোকে তিনটি শ্রেণীতে বিভক্ত করেছিঃ লিনিয়ার মডেল, ট্রি-ভিত্তিক মডেল এবং নিউরাল নেটওয়ার্ক।
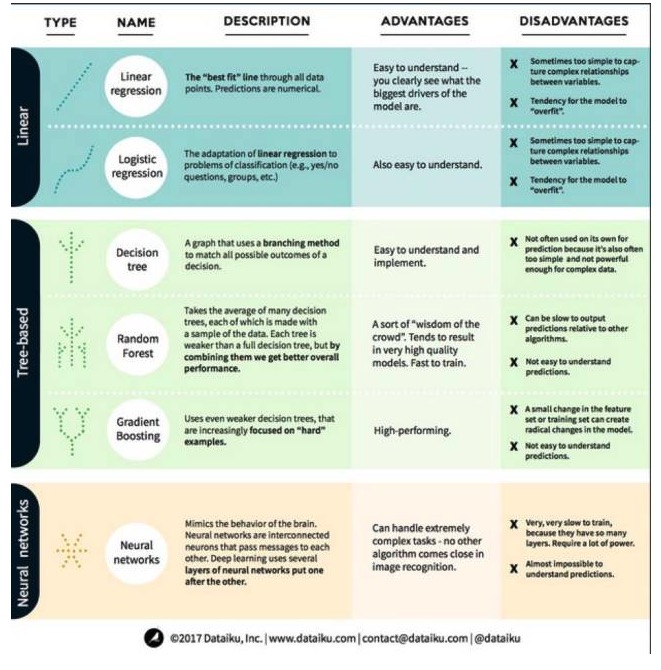
১. লিনিয়ার মডেল অ্যালগরিদমঃ একটি লিনিয়ার মডেল একটি সহজ সূত্র ব্যবহার করে একটি ডাটা পয়েন্টের একটি সেট থেকে একটি সর্বোত্তম ফিট লাইন খুঁজে বের করে। এই পদ্ধতিটি ২০০ বছরেরও বেশি সময় ধরে রয়েছে এবং এটি পরিসংখ্যান এবং মেশিন লার্নিং উভয় ক্ষেত্রেই ব্যাপকভাবে ব্যবহৃত হয়। এর সরলতার কারণে এটি পরিসংখ্যানের জন্য দরকারী। আপনি যে পরিবর্তনশীলটি (কারণ পরিবর্তনশীল) ভবিষ্যদ্বাণী করতে চান তা আপনার ইতিমধ্যে জানা পরিবর্তনশীল (কারণ পরিবর্তনশীল) এর সমীকরণ হিসাবে উপস্থাপিত হয়, তাই ভবিষ্যদ্বাণী করা কেবলমাত্র একটি ইনপুট থেকে পরিবর্তনশীল এবং তারপরে সমীকরণের উত্তর গণনা করা।
- #### ১. লিনিয়ার রিগ্রেশন
লিনিয়ার রিগ্রেশন, বা আরো সঠিকভাবে বলা যায়, সর্বনিম্ন দ্বিগুণ রিগ্রেশন, লিনিয়ার মডেলের সবচেয়ে আদর্শ রূপ। রিগ্রেশন সমস্যার জন্য, লিনিয়ার রিগ্রেশন হল সবচেয়ে সহজ লিনিয়ার মডেল। এর অসুবিধা হল যে মডেলটি ওভারফ্যাটেড হয়, অর্থাৎ, মডেলটি পুরোপুরি প্রশিক্ষিত ডেটাতে অভিযোজিত হয়, নতুন ডেটাতে প্রসারণের ক্ষমতার বিনিময়ে। অতএব, মেশিন লার্নিংয়ের লিনিয়ার রিগ্রেশন (এবং আমরা পরবর্তী সময়ে কথা বলব লজিক্যাল রিগ্রেশন) প্রায়শই ক্রমাগত ক্রমাগত ক্রমাগত হয়, যার অর্থ হল মডেলটি ওভারফ্যাটেড হতে বাধা দেওয়ার জন্য কিছু শাস্তি রয়েছে।
লিনিয়ার মডেলের আরেকটি ত্রুটি হল যে, তারা খুবই সহজ, তাই যখন ইনপুট ভেরিয়েবল স্বাধীন নয়, তখন তারা সহজেই আরো জটিল আচরণ পূর্বাভাস দিতে পারে না।
- #### ২. লজিক্যাল রিগ্রেশন
লজিক্যাল রিগ্রেশন হল শ্রেণিবিন্যাস সমস্যার জন্য লিনিয়ার রিগ্রেশনের একটি অভিযোজন। লজিক্যাল রিগ্রেশনের ত্রুটিগুলি লিনিয়ার রিগ্রেশনের মতোই। লজিক্যাল ফাংশনগুলি শ্রেণিবিন্যাস সমস্যার জন্য খুব ভাল কারণ এটি থ্রেশহোল্ড প্রভাব প্রবর্তন করে।
২, গাছের মডেলিং
- #### ১, সিদ্ধান্ত গাছ
একটি সিদ্ধান্ত গাছ হল একটি গ্রাফ যা একটি সিদ্ধান্তের প্রতিটি সম্ভাব্য ফলাফলকে দেখায়। উদাহরণস্বরূপ, আপনি একটি সালাদ অর্ডার করার সিদ্ধান্ত নিয়েছেন, আপনার প্রথম সিদ্ধান্তটি সম্ভবত সবজির জাত, তারপরে ডিশ, তারপরে সালাদের জাত। আমরা একটি সিদ্ধান্ত গাছের মধ্যে সমস্ত সম্ভাব্য ফলাফল প্রদর্শন করতে পারি।
সিদ্ধান্ত গাছের প্রশিক্ষণের জন্য, আমাদের প্রশিক্ষণ ডেটাসেট ব্যবহার করতে হবে এবং লক্ষ্যের জন্য সবচেয়ে উপযোগী বৈশিষ্ট্যটি খুঁজে বের করতে হবে। উদাহরণস্বরূপ, জালিয়াতি সনাক্তকরণ ব্যবহারের ক্ষেত্রে, আমরা দেখতে পারি যে জালিয়াতি ঝুঁকির পূর্বাভাস দেওয়ার ক্ষেত্রে সবচেয়ে বেশি প্রভাব ফেলবে এমন বৈশিষ্ট্যটি দেশ। প্রথম বৈশিষ্ট্যটির সাথে শাখা করার পরে, আমরা দুটি উপসেট পাই, যা আমরা যদি কেবল প্রথম বৈশিষ্ট্যটি জানি তবে সবচেয়ে সঠিকভাবে পূর্বাভাস দিতে পারি। তারপরে, আমরা এই দুটি উপসেটের সাথে শাখা করার জন্য দ্বিতীয় ভাল বৈশিষ্ট্যটি খুঁজে বের করি, আবারও বিভক্ত করি, এবং যতক্ষণ না পর্যাপ্ত সংখ্যক বৈশিষ্ট্য ব্যবহার করে লক্ষ্যের চাহিদা পূরণ করা হয় ততক্ষণ আমরা পুনরাবৃত্তি করি।
- #### ২, এলোমেলো বন
একটি র্যান্ডম বন হল অনেকগুলি সিদ্ধান্ত গাছের গড়, যার মধ্যে প্রতিটি সিদ্ধান্ত গাছকে একটি র্যান্ডম ডেটা নমুনার সাথে প্রশিক্ষণ দেওয়া হয়। র্যান্ডম বনের প্রতিটি গাছ একটি সম্পূর্ণ সিদ্ধান্ত গাছের চেয়ে দুর্বল, তবে সমস্ত গাছকে একসাথে রাখা, আমরা বৈচিত্র্যের সুবিধার কারণে আরও ভাল সামগ্রিক পারফরম্যান্স পেতে পারি।
র্যান্ডম ফরেস্ট (Random Forest) হল একটি অ্যালগরিদম যা বর্তমানে মেশিন লার্নিংয়ের জন্য খুবই জনপ্রিয়। র্যান্ডম ফরেস্টের প্রশিক্ষণ সহজ এবং এর পারফরম্যান্সও বেশ ভাল। এর অসুবিধা হল যে অন্য অ্যালগরিদমের তুলনায় র্যান্ডম ফরেস্টের আউটপুট পূর্বাভাস খুব ধীর হতে পারে, তাই যখন দ্রুত পূর্বাভাসের প্রয়োজন হয় তখন র্যান্ডম ফরেস্টকে বেছে নেওয়া হয় না।
- #### ৩। উচ্চতা বৃদ্ধি
গ্রেডিয়েন্ট বুস্টিং, র্যান্ডম ফরেস্টের মতো, সিদ্ধান্তের গাছের দ্বারা গঠিত। গ্রেডিয়েন্ট বুস্টিং এবং র্যান্ডম ফরেস্টের মধ্যে সবচেয়ে বড় পার্থক্য হল, গ্রেডিয়েন্ট বুস্টিংয়ে গাছগুলি একের পর এক প্রশিক্ষিত হয়। প্রতিটি পিছনের গাছকে মূলত পূর্ববর্তী গাছের ভুল তথ্য সনাক্তকরণের মাধ্যমে প্রশিক্ষিত করা হয়। এটি গ্রেডিয়েন্ট বুস্টিংকে সহজেই অনুমান করা যায় এমন পরিস্থিতিতে কম মনোনিবেশ করে এবং কঠিন পরিস্থিতিতে বেশি মনোনিবেশ করে।
ক্রমবর্ধমান প্রশিক্ষণ দ্রুত এবং খুব ভাল কাজ করে। তবে, প্রশিক্ষণ ডেটাসেটের ছোট পরিবর্তনগুলি মডেলটিকে মৌলিকভাবে পরিবর্তন করতে পারে, তাই এটির ফলাফলগুলি সম্ভবত সবচেয়ে কার্যকর নাও হতে পারে।
তৃতীয়, নিউরাল নেটওয়ার্ক অ্যালগরিদমঃ নিউরাল নেটওয়ার্ক হল একটি জীববিজ্ঞানীয় ঘটনা যা মস্তিষ্কের মধ্যে পরস্পরের সাথে তথ্য বিনিময় করার জন্য সংযুক্ত নিউরনগুলির সমন্বয়ে গঠিত। এই ধারণাটি এখন মেশিন লার্নিংয়ের ক্ষেত্রে প্রয়োগ করা হয়েছে এবং এটিকে এএনএন (আর্টিফিশিয়াল নিউরাল নেটওয়ার্ক) বলা হয়। গভীর শিক্ষণ হ’ল একাধিক স্তরযুক্ত নিউরাল নেটওয়ার্ক।
বিগ ডেটা প্ল্যাটফর্ম থেকে পুনর্নির্দেশিত