Quantitative Analyse des Marktes für digitale Währungen
Schriftsteller:FMZ~Lydia, Erstellt: 2023-01-06 10:28:01, aktualisiert: 2023-09-20 10:27:27
Quantitative Analyse des Marktes für digitale Währungen
Ein datenbasierter Ansatz für die spekulative Analyse digitaler Währungen
Was ist mit dem Preis von Bitcoin? Was sind die Gründe für den steigenden und sinkenden Preis der digitalen Währung? Sind die Marktpreise verschiedener Altcoins untrennbar miteinander verbunden oder weitgehend unabhängig? Wie können wir vorhersagen, was als nächstes passieren wird?
Artikel über digitale Währungen, wie Bitcoin und Ethereum, sind jetzt voller Spekulationen. Hunderte selbsternannte Experten befürworten den Trend, den sie erwarten. Was vielen dieser Analysen fehlt, ist eine solide Grundlage für grundlegende Daten und statistische Modelle.
Ziel dieses Artikels ist es, eine kurze Einführung in die Analyse digitaler Währungen mit Python zu geben. Wir verwenden ein einfaches Python-Skript, um die Daten verschiedener digitaler Währungen abzurufen, zu analysieren und zu visualisieren. In diesem Prozess finden wir interessante Trends im Marktverhalten dieser Schwankungen und wie sie sich entwickeln.
Dies ist kein Artikel, der digitale Währungen erklärt, noch ist es eine Meinung darüber, welche spezifischen Währungen steigen und welche sinken werden. Im Gegenteil, was wir in diesem Tutorial konzentrieren, ist es, die ursprünglichen Daten zu erhalten und die Geschichte zu finden, die in den Zahlen verborgen ist.
Schritt 1: Einrichtung unserer Datenarbeitsumgebung
Dieses Tutorial richtet sich an Enthusiasten, Ingenieure und Datenwissenschaftler aller Fähigkeiten. Ob Sie ein Branchenführer oder ein Programmierbeginner sind, die einzige Fähigkeit, die Sie benötigen, ist ein grundlegendes Verständnis der Python-Programmiersprache und ausreichende Kenntnisse der Befehlszeilenoperationen (ein Datenwissenschaftliches Projekt einzurichten ist ausreichend).
1.1 Installieren Sie den FMZ Quant Docker und installieren Sie Anaconda
- Docker System der FMZ Quant-Plattform Die FMZ Quant-PlattformFMZ.COMDiese Anwendungen bieten nicht nur qualitativ hochwertige Datenquellen für die wichtigsten Mainstream-Börsen, sondern bieten auch eine Reihe von API-Schnittstellen, die uns helfen, automatische Transaktionen nach Abschluss der Datenanalyse durchzuführen.
Alle oben genannten Funktionen sind in einem Docker-ähnlichen System eingekapselt. Was wir tun müssen, ist, unsere eigenen Cloud-Computing-Dienste zu kaufen oder zu leasen und das Docker-System zu implementieren.
In der offiziellen Bezeichnung der FMZ Quant-Plattform wird dieses Docker-System das Docker-System genannt.
Bitte beachten Sie meinen vorherigen Artikel über die Bereitstellung eines Dockers und eines Roboters:https://www.fmz.com/bbs-topic/9864.
Leser, die ihren eigenen Cloud-Computing-Server kaufen möchten, um Dockers zu implementieren, können sich auf diesen Artikel beziehen:https://www.fmz.com/digest-topic/5711.
Nachdem wir den Cloud-Computing-Server und das Docker-System erfolgreich bereitgestellt haben, installieren wir als nächstes das derzeit größte Artefakt von Python: Anaconda.
Um alle relevanten Programmumgebungen (Abhängigkeitsbibliotheken, Versionsmanagement usw.) zu realisieren, die in diesem Artikel erforderlich sind, ist es am einfachsten, Anaconda zu verwenden.
Da wir Anaconda auf dem Cloud-Service installieren, empfehlen wir, dass der Cloud-Server das Linux-System und die Befehlszeilenversion von Anaconda installiert.
Für die Installationsmethode von Anaconda lesen Sie bitte den offiziellen Anleitungsbericht zu Anaconda:https://www.anaconda.com/distribution/.
Wenn Sie ein erfahrener Python-Programmierer sind und wenn Sie das Gefühl haben, dass Sie Anaconda nicht verwenden müssen, ist das überhaupt kein Problem. Ich nehme an, dass Sie keine Hilfe bei der Installation der notwendigen abhängigen Umgebung benötigen. Sie können diesen Abschnitt direkt überspringen.
1.2 Erstellen Sie eine Datenanalyse-Projektumgebung für Anaconda
Sobald Anaconda installiert ist, müssen wir eine neue Umgebung erstellen, um unsere abhängigen Pakete zu verwalten.
conda create --name cryptocurrency-analysis python=3
um eine neue Anaconda-Umgebung für unser Projekt zu schaffen.
Nächste Eingabe:
source activate cryptocurrency-analysis (linux/MacOS operating system)
or
activate cryptocurrency-analysis (windows operating system)
Um die Umwelt zu aktivieren.
Nächste Eingabe:
conda install numpy pandas nb_conda jupyter plotly
die für dieses Projekt erforderlichen verschiedenen abhängigen Pakete zu installieren.
Hinweis: Warum die Anaconda-Umgebung verwenden? Wenn Sie viele Python-Projekte auf Ihrem Computer ausführen möchten, ist es hilfreich, die abhängigen Pakete (Softwarebibliotheken und Pakete) verschiedener Projekte zu trennen, um Konflikte zu vermeiden.
1.3 Erstellen Sie ein Jupyter-Notebook
Nach der Installation der Umgebung und der abhängigen Pakete laufen:
jupyter notebook
um den iPython-Kernel zu starten, dann besuchenhttp://localhost:8888/mit Ihrem Browser ein neues Python-Notebook erstellen, um sicherzustellen, dass es die verwendet:
Python [conda env:cryptocurrency-analysis]
Kernel

1.4 Importabhängige Pakete
Erstellen Sie ein leeres Jupyter-Notebook, und das Erste, was wir tun müssen, ist die erforderlichen abhängigen Pakete zu importieren.
import os
import numpy as np
import pandas as pd
import pickle
from datetime import datetime
Wir müssen auch Plotly importieren und Offline-Modus aktivieren:
import plotly.offline as py
import plotly.graph_objs as go
import plotly.figure_factory as ff
py.init_notebook_mode(connected=True)
Schritt 2: Erhalten Sie Preisinformationen über digitale Währungen
Die Vorbereitung ist abgeschlossen, und nun können wir beginnen, die zu analysierenden Daten zu erhalten.
Für die Verwendung dieser beiden Funktionen, wenden Sie sich bitte an:https://www.fmz.com/api.
2.1 Schreiben Sie eine Quandl-Datenerfassungsfunktion
Um die Datenerfassung zu erleichtern, müssen wir eine Funktion schreiben, um Daten von Quandl herunterzuladen und zu synchronisieren (quandl.com) ist eine kostenlose Finanzdatenoberfläche, die im Ausland einen hohen Ruf genießt. Die FMZ Quant-Plattform bietet auch eine ähnliche Datenoberfläche, die hauptsächlich für echte Bot-Transaktionen verwendet wird. Da sich der Artikel hauptsächlich auf Datenanalyse konzentriert, verwenden wir hier immer noch Quandl-Daten.
Während der echten Bot-Transaktion können Sie die GetTicker- und GetRecords-Funktionen in Python direkt aufrufen, um Preisdaten zu erhalten.https://www.fmz.com/api.
def get_quandl_data(quandl_id):
# Download and cache data columns from Quandl
cache_path = '{}.pkl'.format(quandl_id).replace('/','-')
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(quandl_id))
except (OSError, IOError) as e:
print('Downloading {} from Quandl'.format(quandl_id))
df = quandl.get(quandl_id, returns="pandas")
df.to_pickle(cache_path)
print('Cached {} at {}'.format(quandl_id, cache_path))
return df
Hier wird die Pickle-Bibliothek verwendet, um die Daten zu serialisieren und die heruntergeladenen Daten als Datei zu speichern, so dass das Programm nicht jedes Mal, wenn es ausgeführt wird, die gleichen Daten herunterlädt. Diese Funktion gibt Daten im Pandas Dataframe-Format zurück. Wenn Sie nicht mit dem Konzept des Datenrahmens vertraut sind, können Sie es sich als ein leistungsstarkes Excel vorstellen.
2.2 Zugang zu den Preisen für digitale Währungen der Börse Kraken
Nehmen wir die Kraken Bitcoin Exchange als Beispiel, beginnend mit dem Erhalt ihres Bitcoin-Preises.
# Get prices on the Kraken Bitcoin exchange
btc_usd_price_kraken = get_quandl_data('BCHARTS/KRAKENUSD')
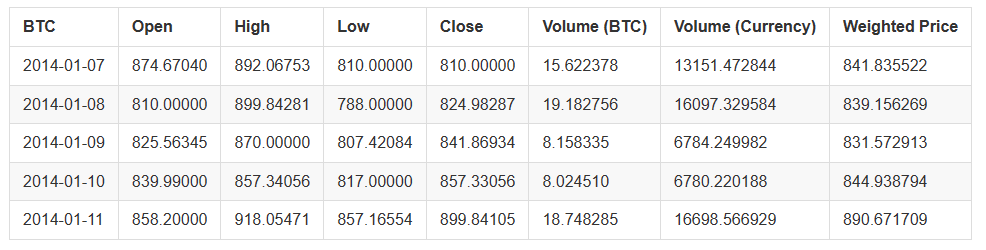
Verwenden Sie die Methode head (((), um die ersten fünf Zeilen des Datenfeldes anzuzeigen.
btc_usd_price_kraken.head()
Das Ergebnis ist:
Als nächstes werden wir eine einfache Tabelle erstellen, um die Richtigkeit der Daten durch Visualisierung zu überprüfen.
# Make a table of BTC prices
btc_trace = go.Scatter(x=btc_usd_price_kraken.index, y=btc_usd_price_kraken['Weighted Price'])
py.iplot([btc_trace])
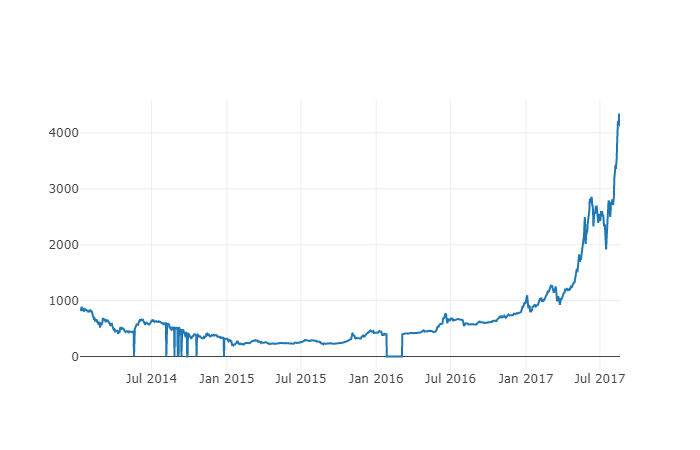
Hier verwenden wir Plotly, um den Visualisierungsteil zu vervollständigen. Im Vergleich zu einigen ausgereifteren Python-Datenvisualisierungsbibliotheken wie Matplotlib ist Plotly eine weniger verbreitete Wahl, aber es ist wirklich eine gute Wahl, weil es vollständig interaktive Diagramme von D3.js
Tipps: Das generierte Diagramm kann mit dem Bitcoin-Preisdiagramm von Mainstream-Börsen (z. B. dem Diagramm auf OKX, Binance oder Huobi) verglichen werden, um schnell zu überprüfen, ob die heruntergeladenen Daten im Allgemeinen konsistent sind.
2.3 Erhalten Sie Preisdaten von gängigen Bitcoin-Börsen
Aufmerksame Leser haben vielleicht bemerkt, dass in den oben genannten Daten Daten fehlen, insbesondere Ende 2014 und Anfang 2016. Besonders bei Kraken Exchange ist diese Art von Datenverlust besonders offensichtlich. Wir hoffen sicherlich nicht, dass diese fehlenden Daten die Preisanalyse beeinflussen werden.
Das Merkmal des digitalen Währungsaustauschs ist, dass das Angebot und die Nachfrage das Währungspreis bestimmen. Daher kann kein Transaktionspreis zum
Lassen Sie uns damit beginnen, die Daten jedes Austauschs in den Datenrahmen zu laden, der aus Wörterbuchtypen besteht.
# Download price data from COINBASE, BITSTAMP and ITBIT
exchanges = ['COINBASE','BITSTAMP','ITBIT']
exchange_data = {}
exchange_data['KRAKEN'] = btc_usd_price_kraken
for exchange in exchanges:
exchange_code = 'BCHARTS/{}USD'.format(exchange)
btc_exchange_df = get_quandl_data(exchange_code)
exchange_data[exchange] = btc_exchange_df
2.4 Alle Daten in einen Datenrahmen integrieren
Als nächstes definieren wir eine spezielle Funktion, um die Spalten, die für jeden Datenrahmen gemeinsam sind, in einen neuen Datenrahmen zu verschmelzen.
def merge_dfs_on_column(dataframes, labels, col):
'''Merge a single column of each dataframe into a new combined dataframe'''
series_dict = {}
for index in range(len(dataframes)):
series_dict[labels[index]] = dataframes[index][col]
return pd.DataFrame(series_dict)
Nun werden alle Datenrahmen basierend auf der Spalte
# Integrate all data frames
btc_usd_datasets = merge_dfs_on_column(list(exchange_data.values()), list(exchange_data.keys()), 'Weighted Price')
Schließlich verwenden wir die
btc_usd_datasets.tail()
Die Ergebnisse sind wie folgt dargestellt:
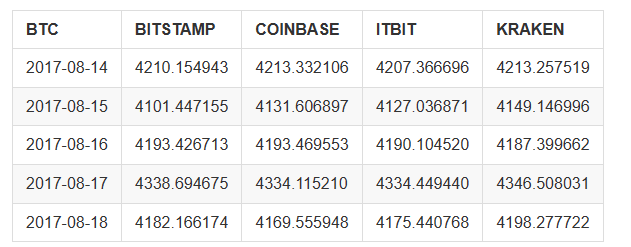
Aus der obigen Tabelle können wir sehen, dass diese Daten unseren Erwartungen entsprechen, mit ungefähr demselben Datenbereich, aber leicht unterschiedlich basierend auf der Verzögerung oder den Eigenschaften jedes Austauschs.
2.5 Visualisierung von Preisdaten
Aus der Perspektive der Analyse Logik ist der nächste Schritt, diese Daten durch Visualisierung zu vergleichen. Um dies zu tun, müssen wir zuerst eine Hilfsfunktion definieren.
def df_scatter(df, title, seperate_y_axis=False, y_axis_label='', scale='linear', initial_hide=False):
'''Generate a scatter plot of the entire dataframe'''
label_arr = list(df)
series_arr = list(map(lambda col: df[col], label_arr))
layout = go.Layout(
title=title,
legend=dict(orientation="h"),
xaxis=dict(type='date'),
yaxis=dict(
title=y_axis_label,
showticklabels= not seperate_y_axis,
type=scale
)
)
y_axis_config = dict(
overlaying='y',
showticklabels=False,
type=scale )
visibility = 'visible'
if initial_hide:
visibility = 'legendonly'
# Table tracking for each series
trace_arr = []
for index, series in enumerate(series_arr):
trace = go.Scatter(
x=series.index,
y=series,
name=label_arr[index],
visible=visibility
)
# Add a separate axis to the series
if seperate_y_axis:
trace['yaxis'] = 'y{}'.format(index + 1)
layout['yaxis{}'.format(index + 1)] = y_axis_config
trace_arr.append(trace)
fig = go.Figure(data=trace_arr, layout=layout)
py.iplot(fig)
Für ein einfaches Verständnis wird dieser Artikel das Logikprinzip dieser Hilfsfunktion nicht zu sehr diskutieren.
Jetzt können wir leicht Bitcoin-Preisdaten-Diagramme erstellen!
# Plot all BTC transaction prices
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
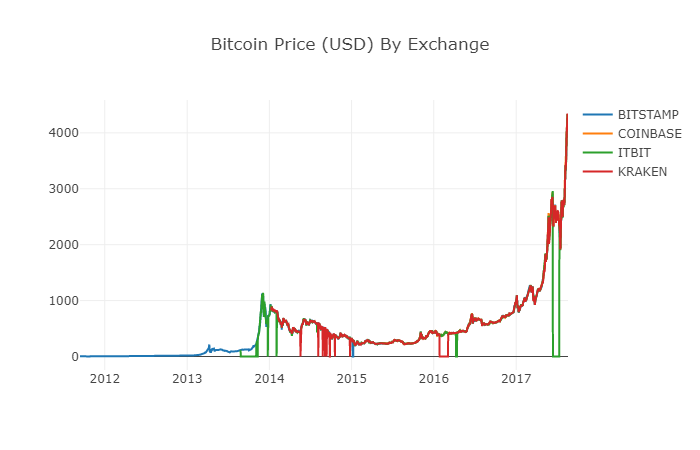
2.6 Übersichtliche und aggregierte Preisdaten
Wie aus dem obigen Diagramm hervorgeht, sind die vier Datenreihen zwar in etwa auf demselben Weg, doch gibt es noch einige unregelmäßige Veränderungen.
In der Zeit von 2012-2017 wissen wir, dass der Preis von Bitcoin nie gleich Null war, also entfernen wir zuerst alle Nullwerte im Datenrahmen.
# Clear the "0" value
btc_usd_datasets.replace(0, np.nan, inplace=True)
Nach der Rekonstruktion der Datenrahmen können wir ein klareres Diagramm sehen, ohne dass mehr Daten fehlen.
# Plot the revised data frame
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
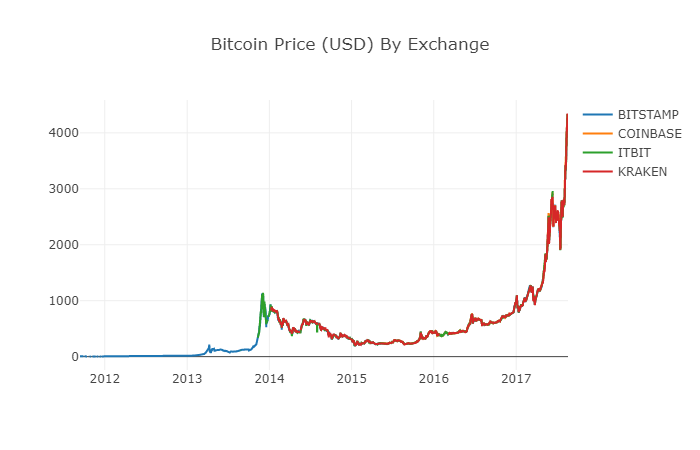
Wir können jetzt eine neue Spalte berechnen: den täglichen durchschnittlichen Bitcoin-Preis aller Börsen.
# Calculate the average BTC price as a new column
btc_usd_datasets['avg_btc_price_usd'] = btc_usd_datasets.mean(axis=1)
Die neue Spalte ist der Preisindex von Bitcoin! Lasst uns ihn noch einmal zeichnen, um zu überprüfen, ob die Daten falsch aussehen.
# Plot the average BTC price
btc_trace = go.Scatter(x=btc_usd_datasets.index, y=btc_usd_datasets['avg_btc_price_usd'])
py.iplot([btc_trace])
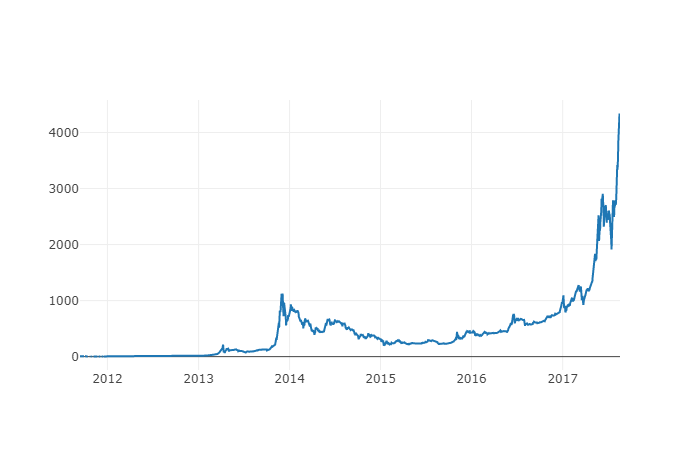
Später werden wir diese aggregierten Preisserien-Daten weiter verwenden, um den Wechselkurs zwischen anderen digitalen Währungen und dem USD zu bestimmen.
Schritt 3: Sammeln Sie den Preis von Altcoins
Bisher haben wir die Zeitreihendaten des Bitcoin-Preises. Als nächstes werfen wir einen Blick auf einige Daten von nicht-Bitcoin-digitalen Währungen, dh Altcoins. Natürlich mag der Begriff
3.1 Definition von Hilfsfunktionen über die API der Poloniex-Börse
Zuerst verwenden wir die API der Poloniex-Börse, um die Dateninformationen von digitalen Währungstransaktionen zu erhalten. Wir definieren zwei Hilfsfunktionen, um die Daten zu Altcoins zu erhalten. Diese beiden Funktionen laden hauptsächlich JSON-Daten über APIs herunter und speichern sie.
Zuerst definieren wir die Funktion get_json_data, die JSON-Daten von der angegebenen URL herunterlädt und speichert.
def get_json_data(json_url, cache_path):
'''Download and cache JSON data, return as a dataframe.'''
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(json_url))
except (OSError, IOError) as e:
print('Downloading {}'.format(json_url))
df = pd.read_json(json_url)
df.to_pickle(cache_path)
print('Cached {} at {}'.format(json_url, cache_path))
return df
Als nächstes definieren wir eine neue Funktion, die die HTTP-Anfrage der Poloniex API generiert und die gerade definierte Funktion get_json_data aufruft, um die Datenergebnisse des Aufrufs zu speichern.
base_polo_url = 'https://poloniex.com/public?command=returnChartData¤cyPair={}&start={}&end={}&period={}'
start_date = datetime.strptime('2015-01-01', '%Y-%m-%d') # Data acquisition since 2015
end_date = datetime.now() # Until today
pediod = 86400 # pull daily data (86,400 seconds per day)
def get_crypto_data(poloniex_pair):
'''Retrieve cryptocurrency data from poloniex'''
json_url = base_polo_url.format(poloniex_pair, start_date.timestamp(), end_date.timestamp(), pediod)
data_df = get_json_data(json_url, poloniex_pair)
data_df = data_df.set_index('date')
return data_df
Die obige Funktion extrahiert den passenden Zeichencode der digitalen Währung (z. B.
3.2 Herunterladen von Transaktionspreisdaten von Poloniex
Die überwiegende Mehrheit der Altcoins kann nicht direkt in USD gekauft werden. Um diese digitalen Währungen zu erhalten, müssen Einzelpersonen normalerweise zuerst Bitcoin kaufen und sie dann nach ihrem Preisverhältnis in Altcoins umwandeln. Daher müssen wir den Wechselkurs jeder digitalen Währung in Bitcoin herunterladen und dann die vorhandenen Bitcoin-Preisdaten verwenden, um ihn in USD umzuwandeln. Wir werden die Wechselkursdaten für die Top-9-digitalen Währungen herunterladen: Ethereum, Litecoin, Ripple, EthereumClassic, Stellar, Dash, Siacoin, Monero und NEM.
altcoins = ['ETH','LTC','XRP','ETC','STR','DASH','SC','XMR','XEM']
altcoin_data = {}
for altcoin in altcoins:
coinpair = 'BTC_{}'.format(altcoin)
crypto_price_df = get_crypto_data(coinpair)
altcoin_data[altcoin] = crypto_price_df
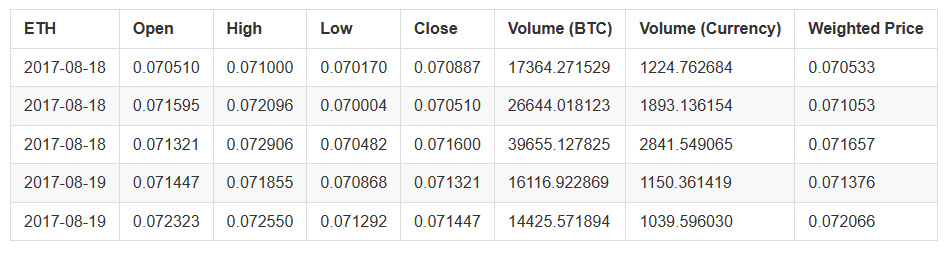
Jetzt haben wir ein Wörterbuch mit 9 Datenrahmen, von denen jeder historische tägliche Durchschnittspreisdaten zwischen Altcoins und Bitcoin enthält.
Wir können feststellen, ob die Daten korrekt sind, durch die letzten Zeilen der Ethereum-Preistabelle.
altcoin_data['ETH'].tail()
3.3 Vereinheitlichung der Währungseinheit aller Preisdaten in USD
Jetzt können wir BTC- und Altcoins-Wechselkursdaten mit unserem Bitcoin-Preisindex kombinieren, um den historischen Preis jedes Altcoins (in USD) direkt zu berechnen.
# Calculate USD Price as a new column in each altcoin data frame
for altcoin in altcoin_data.keys():
altcoin_data[altcoin]['price_usd'] = altcoin_data[altcoin]['weightedAverage'] * btc_usd_datasets['avg_btc_price_usd']
Hier fügen wir eine neue Spalte für jeden Altcoin Datenrahmen hinzu, um den entsprechenden USD-Preis zu speichern.
Als nächstes können wir die zuvor definierte Funktion merge_dfs_on_column wiederverwenden, um einen kombinierten Datenrahmen zu erstellen und den USD-Preis jeder digitalen Währung zu integrieren.
# Combine the USD price of each Altcoin into a single data frame
combined_df = merge_dfs_on_column(list(altcoin_data.values()), list(altcoin_data.keys()), 'price_usd')
Das war's.
Jetzt fügen wir den Bitcoin-Preis als letzte Spalte zum fusionierten Datenrahmen hinzu.
# Add BTC price to data frame
combined_df['BTC'] = btc_usd_datasets['avg_btc_price_usd']
Jetzt haben wir einen einzigartigen Datenrahmen, der die täglichen USD-Preise von zehn digitalen Währungen enthält, die wir überprüfen.
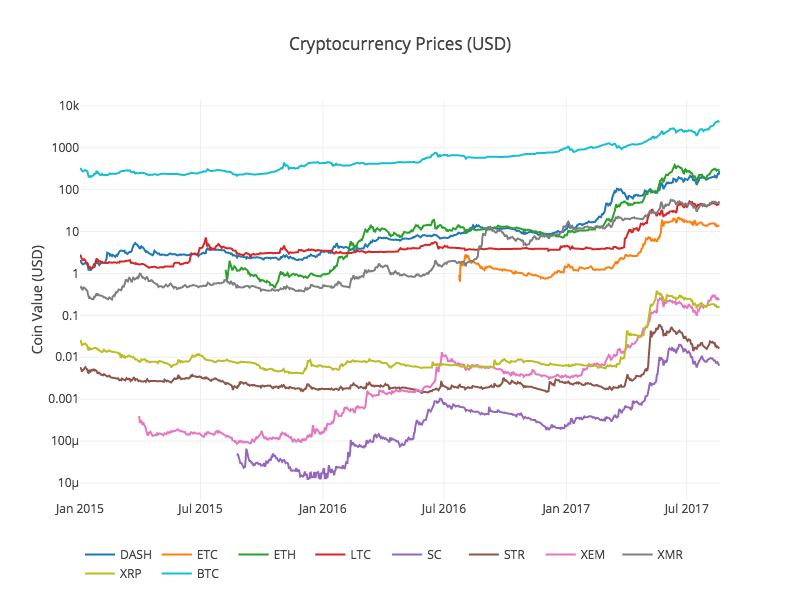
Wir nennen die vorherige Funktion df_scatter wieder und zeigen die entsprechenden Preise aller Altcoins in Form eines Diagramms.
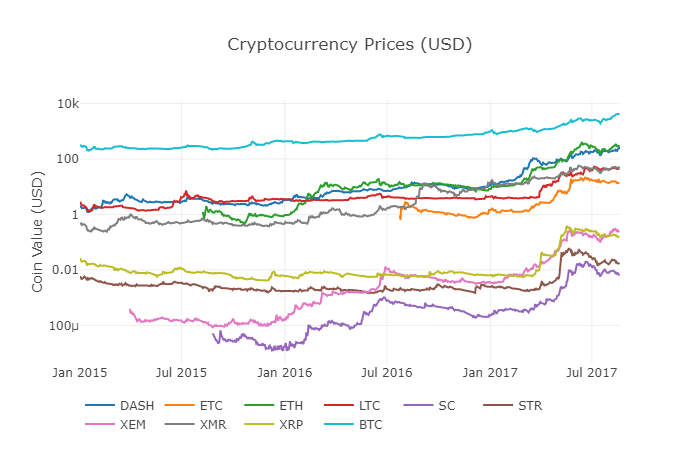
Dieses Diagramm zeigt uns ein vollständiges Bild der Veränderung des Wechselkurses für jede digitale Währung in den letzten Jahren.
Hinweis: Hier verwenden wir die y-Achse der logarithmischen Spezifikation, um alle digitalen Währungen auf demselben Diagramm zu vergleichen.
3.4 Beginn der Korrelationsanalyse
Aufmerksame Leser haben vielleicht bemerkt, dass die Preise für digitale Währungen relevant zu sein scheinen, obwohl ihre Währungswerte stark variieren und sehr volatil sind. Besonders seit dem schnellen Anstieg im April 2017 scheinen sogar viele kleine Schwankungen gleichzeitig mit den Schwankungen des gesamten Marktes zu auftreten.
Selbstverständlich sind Schlussfolgerungen, die von Daten unterstützt werden, überzeugender als Intuitionen, die auf Bildern beruhen.
Wir können die Funktion Pandas corr() verwenden, um die obige Korrelationshypothese zu überprüfen. Diese Testmethode berechnet den Pearson-Korrelationskoeffizienten jeder Spalte des Datenrahmens, die der anderen Spalte entspricht.
Anmerkung zur Revision vom 22.8.2017: Dieser Abschnitt wurde geändert, um bei der Berechnung des Korrelationskoeffizienten die Tagesrendite anstelle des absoluten Preises zu verwenden.
Eine direkte Berechnung auf der Grundlage einer nicht soliden Zeitreihe (z. B. Rohpreisdaten) kann zu einer Abweichung des Korrelationskoeffizienten führen. Um dieses Problem zu lösen, besteht unsere Lösung darin, die pct_change() -Methode zu verwenden, um den absoluten Wert jedes Preises im Datenrahmen in die entsprechende Tagesrendite umzuwandeln.
Zum Beispiel berechnen wir den Korrelationskoeffizienten im Jahr 2016.
# Calculating the Pearson correlation coefficient for digital currencies in 2016
combined_df_2016 = combined_df[combined_df.index.year == 2016]
combined_df_2016.pct_change().corr(method='pearson')
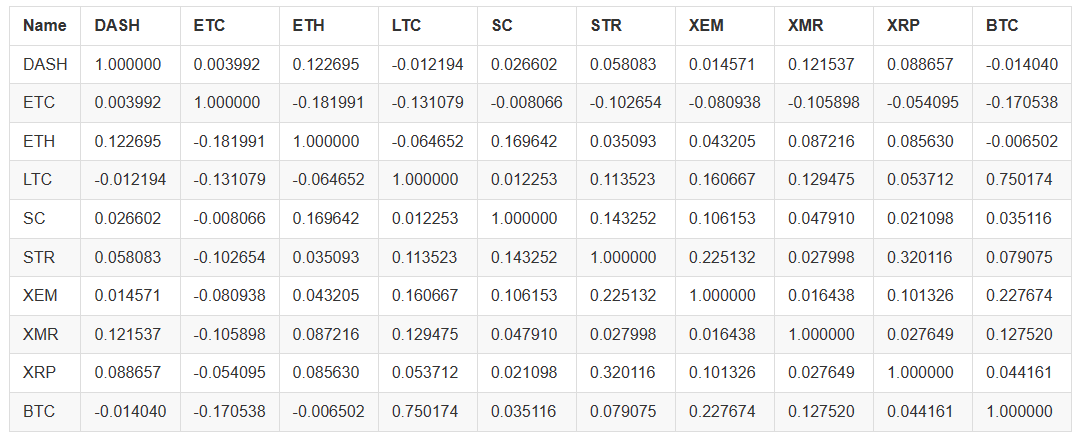
Die obige Grafik zeigt den Korrelationskoeffizienten. Wenn der Koeffizient nahe an 1 oder -1 liegt, bedeutet dies, dass diese Reihe positiv oder negativ korreliert ist. Wenn der Korrelationskoeffizient nahe an 0 liegt, bedeutet dies, dass die entsprechenden Objekte nicht korreliert sind und ihre Schwankungen unabhängig voneinander sind.
Um die Ergebnisse besser zu visualisieren, erstellen wir eine neue visuelle Hilfsfunktion.
def correlation_heatmap(df, title, absolute_bounds=True):
'''Plot a correlation heatmap for the entire dataframe'''
heatmap = go.Heatmap(
z=df.corr(method='pearson').as_matrix(),
x=df.columns,
y=df.columns,
colorbar=dict(title='Pearson Coefficient'),
)
layout = go.Layout(title=title)
if absolute_bounds:
heatmap['zmax'] = 1.0
heatmap['zmin'] = -1.0
fig = go.Figure(data=[heatmap], layout=layout)
py.iplot(fig)
correlation_heatmap(combined_df_2016.pct_change(), "Cryptocurrency Correlations in 2016")
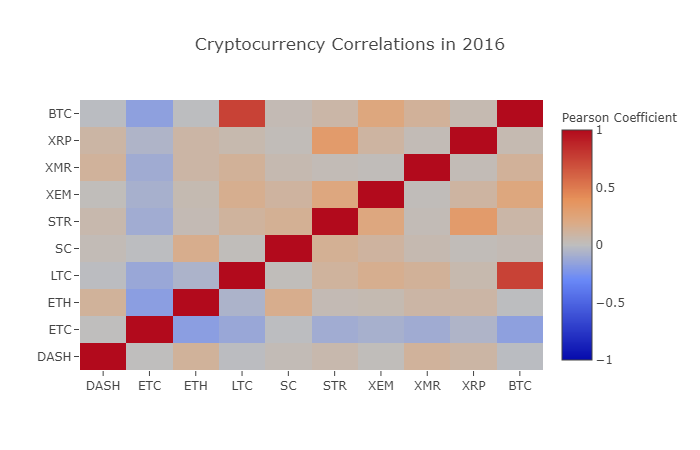
Hier stellt der dunkelrote Wert eine starke Korrelation dar (jede Währung ist offensichtlich stark mit sich selbst korreliert), und der dunkelblaue Wert stellt eine umgekehrte Korrelation dar. Alle Farben in der Mitte - hellblau/orange/grau/tauny - haben Werte, die unterschiedliche Grade schwacher Korrelation oder Nichtkorrelation darstellen.
Was sagt uns dieses Diagramm? Grundsätzlich zeigt es die Schwankungen der Preise verschiedener digitaler Währungen im Jahr 2016, mit wenig statistisch signifikanten Korrelationen.
Um unsere Hypothese zu überprüfen, dass
combined_df_2017 = combined_df[combined_df.index.year == 2017]
combined_df_2017.pct_change().corr(method='pearson')
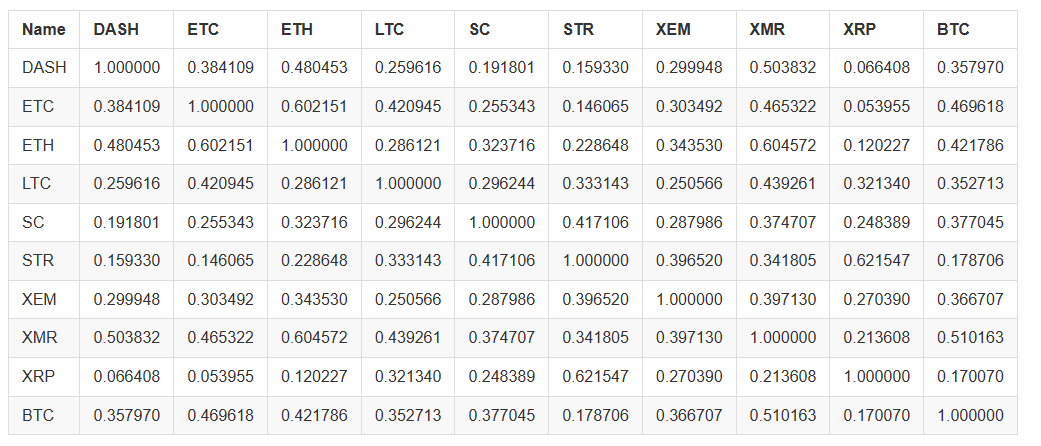
Sind die vorstehenden Daten relevanter und ausreichend, um sie als Bewertungsanalyse für Investitionen zu verwenden?
Es ist jedoch erwähnenswert, dass fast alle digitalen Währungen zunehmend miteinander verbunden sind.
correlation_heatmap(combined_df_2017.pct_change(), "Cryptocurrency Correlations in 2017")
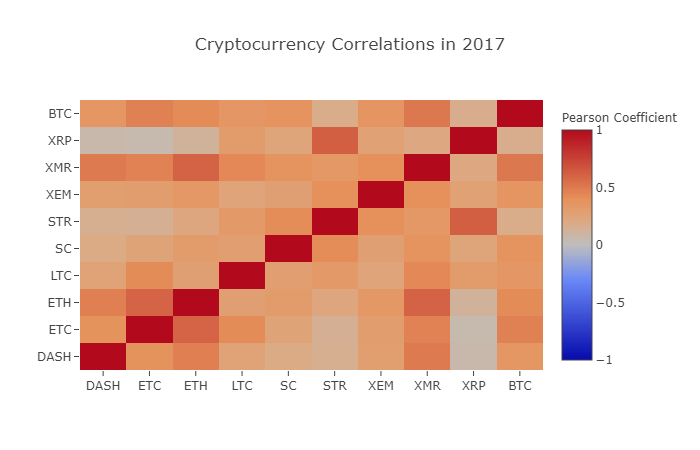
Wie wir aus der obigen Tabelle sehen können, werden die Dinge immer interessanter.
Warum passiert das?
Gute Frage, aber ich bin mir nicht sicher...
Meine erste Reaktion ist, dass Hedgefonds kürzlich begonnen haben, öffentlich auf dem digitalen Währungsmarkt zu handeln. Diese Fonds halten viel mehr Kapital als gewöhnliche Händler. Wenn ein Fonds sein investiertes Kapital zwischen mehreren digitalen Währungen absichert, verwendet er ähnliche Handelsstrategien für jede Währung entsprechend unabhängigen Variablen (wie der Börse). Aus dieser Perspektive ist es sinnvoll, dass dieser Trend der zunehmenden Korrelation auftritt.
Ein tieferes Verständnis von XRP und STR
Zum Beispiel ist es aus der obigen Grafik offensichtlich, dass XRP (Ripple
Interessanterweise sind Stellar und Ripple sehr ähnliche Finanztechnologieplattformen, die beide darauf abzielen, die mühsamen Schritte der grenzüberschreitenden Überweisung zwischen Banken zu reduzieren.
Nun, jetzt bist du dran!
Die obigen Erklärungen sind weitgehend spekulativ, und Sie können es besser machen.
Die Leser können sich auf die Forschung in folgenden Richtungen beziehen:
- Fügen Sie mehr Daten über digitale Währungen zur gesamten Analyse hinzu.
- Anpassung des Zeitrahmens und der Granularität der Korrelationsanalyse, um eine optimierte oder grobe Trendansicht zu erhalten.
- Im Vergleich zu den ursprünglichen Preisdaten, wenn Sie zukünftige Preisschwankungen vorhersagen möchten, benötigen Sie möglicherweise mehr Daten zur Kauf-/Verkaufsmenge.
- Fügen Sie Preisdaten zu Aktien, Rohstoffen und Fiat-Währungen hinzu, um festzustellen, welche von ihnen für digitale Währungen relevant sind (aber vergessen Sie nicht das alte Sprichwort
Korrelation impliziert keine Kausalität ). - Verwenden Sie Event Registry, GDELT und Google Trends, um die Anzahl der
heißen Wörter zu quantifizieren, die eine bestimmte digitale Währung umgeben. - Wenn Sie ehrgeiziger sind, können Sie sogar das recurrent neural network (RNN) für das oben genannte Training in Betracht ziehen.
- Verwenden Sie Ihre Analyse, um einen automatischen Handelsroboter zu erstellen, der über die entsprechende Anwendungsprogrammierschnittstelle (API) auf der Börsenwebsite von
Poloniex FMZ.COM) wird hier empfohlen.oder Coinbase angewendet werden kann. Bitte achten Sie darauf: Ein Roboter mit schlechter Leistung kann Ihre Vermögenswerte leicht sofort zerstören.
Das Beste an Bitcoin und der digitalen Währung im Allgemeinen ist ihre dezentrale Natur, die sie freier und demokratischer macht als jedes andere Asset. Sie können Ihre Analyse Open-Source teilen, an der Community teilnehmen oder einen Blog schreiben! Ich hoffe, Sie haben die für die Selbstanalyse erforderlichen Fähigkeiten und die Fähigkeit, dialektisch zu denken, beherrscht, wenn Sie in Zukunft spekulative Artikel über digitale Währungen lesen, insbesondere solche Vorhersagen ohne Datenunterstützung. Vielen Dank für das Lesen. Wenn Sie Kommentare, Vorschläge oder Kritik an diesem Tutorial haben, hinterlassen Sie bitte eine Nachricht aufhttps://www.fmz.com/bbs.
- DEX-Börsen Quantitative Praxis ((1)-- dYdX v4 Benutzerhandbuch
- Einführung der Lead-Lag-Suite in der Kryptowährung (3)
- Einführung in Lead-Lag-Arbitrage in Kryptowährungen (2)
- Einführung der Lead-Lag-Suite in der digitalen Währung (2)
- Diskussion über den externen Signalempfang der FMZ-Plattform: Eine Komplettlösung für den Empfang von Signalen mit integriertem Http-Service in der Strategie
- FMZ-Plattform: Erforschung von Signalempfangsstrategien für externe Netzwerke
- Einführung in Lead-Lag-Arbitrage in Kryptowährungen (1)
- Einführung der Lead-Lag-Suite in der Kryptowährung (1)
- Diskussion über den externen Signalempfang der FMZ-Plattform: Erweiterte API VS Strategie eingebauter HTTP-Service
- FMZ-Plattform-External Signal Reception: Erweiterung der API vs. Strategien für den eingebauten HTTP-Dienst
- Diskussion über die Strategie-Testmethode auf Basis eines Zufalls-Ticker-Generators
- Spätes Teilen: Bitcoin-Hochfrequenz-Roboter mit täglicher Rendite von 5% im Jahr 2014
- Neuronale Netzwerke und Quantitative Trading in digitaler Währung (2) - Intensives Lernen und Schulen Bitcoin Trading Strategie
- Neuronale Netzwerke und digitale Währung Quantitative Trading Series (1) - LSTM prognostiziert Bitcoin Preis
- Anwendung der Kombinationsstrategie von SMA und RSI Relative Strength Index
- Entwicklung der CTA-Strategie und der Standardklassenbibliothek der FMZ Quant-Plattform
- Quantitative Handelsstrategie mit Preisdynamikanalyse in Python
- Implementieren Sie eine Dual-Push-Quantitative Trading-Strategie für digitale Währungen in Python
- Der beste Weg zum Installieren und Upgrade für Linux Docker
- Erreichung einer ausgewogenen Eigenkapitalstrategie mit einer ordnungsgemäßen Ausrichtung von Long-Short-Positionen
- Zeitreihendatenanalyse und Tick-Daten-Backtesting
- Paarhandel auf Basis datengetriebener Technologie
- Anwendung der Maschinellen Lerntechnologie im Handel
- Nutzung des Forschungsumfelds zur Analyse der Einzelheiten der dreieckigen Absicherung und der Auswirkungen der Abwicklungsgebühren auf die abgesicherten Preisdifferenzen
- Reform der Deribit-Futures-API zur Anpassung an den quantitativen Handel mit Optionen
- Bessere Werkzeuge machen gute Arbeit - lernen Sie, die Forschungsumgebung zu verwenden, um Handelsprinzipien zu analysieren
- Währungsübergreifende Absicherungsstrategien beim quantitativen Handel mit Blockchain-Assets
- Erwerben Sie den Leitfaden zur Digitalwährungsstrategie von FMex auf FMZ Quant
- Ich lehre Sie Strategien zu schreiben - eine MyLanguage-Strategie transplantieren (Advanced)
- Sie lernen, Strategien zu schreiben -- transplantieren Sie eine MyLanguage-Strategie
- Sie lernen, Multi-Chart-Unterstützung der Strategie hinzuzufügen