Erstellen Sie einen Bitcoin-Handelsroboter, der kein Geld verliert
Schriftsteller:FMZ~Lydia, Erstellt: 2023-02-01 11:52:21, Aktualisiert: 2024-12-24 20:25:11
Erstellen Sie einen Bitcoin-Handelsroboter, der kein Geld verliert
Lassen Sie uns Verstärkungslernen in KI nutzen, um einen digitalen Währungshandelsroboter zu bauen.
In diesem Artikel werden wir eine erweiterte Lernrahmennummer erstellen und anwenden, um zu lernen, wie man einen Bitcoin-Handelsroboter erstellt.
Vielen Dank für die Open-Source-Software, die OpenAI und DeepMind in den letzten Jahren für die Forscher des Deep Learning bereitgestellt haben.
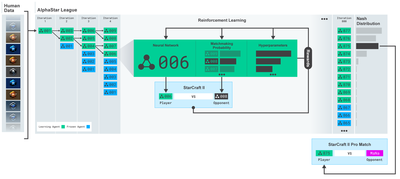
AlphaStar-Ausbildung:https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
Obwohl wir nichts beeindruckendes schaffen werden, ist es immer noch nicht einfach, Bitcoin-Roboter in täglichen Transaktionen zu handeln.
Es gibt keinen Wert in etwas, das zu einfach ist.
Deshalb sollten wir nicht nur lernen, selbst zu handeln, sondern auch Roboter für uns handeln lassen.
Planung

Erstellen Sie eine Fitness-Umgebung für unseren Roboter, um maschinelles Lernen durchzuführen
Ein einfaches und elegantes visuelles Umfeld erstellen
Trainieren Sie unseren Roboter, um eine profitable Handelsstrategie zu lernen.
Wenn Sie nicht mit dem Erstellen von Fitness-Umgebungen von Grund auf vertraut sind, oder wie Sie einfach die Visualisierung dieser Umgebungen rendern. Bevor Sie fortfahren, können Sie einen Artikel dieser Art auf Google suchen. Diese beiden Aktionen werden nicht schwierig sein, auch für die am meisten Junior-Programmierer.
Wie man anfängt
In diesem Tutorial verwenden wir den von Zielak generierten Kaggle Datensatz. Wenn Sie den Quellcode herunterladen möchten, wird er in meinem Github-Repository bereitgestellt, zusammen mit der.csv-Datendatei. Ok, fangen wir an.
Zuerst müssen wir alle notwendigen Bibliotheken importieren.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
Als nächstes erstellen wir unsere Klasse für die Umgebung. Wir müssen eine Pandas Datenrahmennummer und eine optionale initial_balance und eine lookback_window_size einreichen, die die Anzahl der vergangenen Zeitschritte anzeigen, die der Roboter in jedem Schritt beobachtet hat. Wir setzen die Provision jeder Transaktion standardmäßig auf 0.075%, dh den aktuellen Wechselkurs von Bitmex, und setzen den Serienparameter standardmäßig auf false, was bedeutet, dass unsere Datenrahmennummer standardmäßig von zufälligen Fragmenten durchquert wird.
Wir rufen auch dropna() und reset_index() auf die Daten an, löschen zuerst die Zeile mit NaN-Wert und setzen dann den Index der Bildnummer zurück, weil wir die Daten gelöscht haben.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
Unser action_space wird hier als eine Gruppe von 3 Optionen (Kaufen, Verkaufen oder Halten) und eine weitere Gruppe von 10 Beträgen (1⁄10, 2⁄10, 3⁄10Wenn wir uns entscheiden, zu kaufen, werden wir Menge * selbst.Balance Wort von BTC kaufen. Für den Verkauf, werden wir Menge * selbst.btc_held Wert von BTC verkaufen. Natürlich, halten wird den Betrag ignorieren und nichts tun.
Unsere observation_space ist definiert als ein kontinuierlicher Schwenkpunkt zwischen 0 und 1, und seine Form ist (10, lookback_window_size+1). + 1 wird verwendet, um den aktuellen Zeitschritt zu berechnen. Für jeden Zeitschritt im Fenster werden wir den OHCLV-Wert beobachten. Unser Nettowert ist gleich der Anzahl der BTCs, die wir kaufen oder verkaufen, und der Gesamtmenge an Dollar, die wir für diese BTCs ausgeben oder erhalten.
Als nächstes müssen wir die Reset-Methode schreiben, um die Umgebung zu initialisieren.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
Hier verwenden wir self._reset_session und self._next_observation, die wir noch nicht definiert haben.
Handelssitzung
Ein wichtiger Bestandteil unserer Umgebung ist das Konzept der Handelssitzungen. Wenn wir diesen Roboter außerhalb des Marktes einsetzen, werden wir ihn möglicherweise nie länger als ein paar Monate laufen lassen. Aus diesem Grund werden wir die Anzahl der aufeinanderfolgenden Frames in self.df begrenzen, die die Anzahl der Frames ist, die unser Roboter gleichzeitig sehen kann.
In unserer _reset_session-Methode setzen wir zuerst den aktuellen_Schritt auf 0. Als nächstes setzen wir steps_left auf eine zufällige Zahl zwischen 1 und MAX_TRADING_SESSIONS, die wir oben im Programm definieren.
MAX_TRADING_SESSION = 100000 # ~2 months
Als nächstes, wenn wir die Anzahl der Frames nacheinander durchqueren wollen, müssen wir sie so einstellen, dass sie die gesamte Anzahl von Frames durchquert, sonst setzen wir frame_start auf einen zufälligen Punkt in self.df und erstellen einen neuen Datenrahmen namens active_df, der nur ein Stückchen von self.df ist und von frame_start zu frame_start + steps_left kommt.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
Ein wichtiger Nebeneffekt der Durchforstung der Anzahl der Datenräume im zufälligen Slice ist, dass unser Roboter mehr einzigartige Daten für die Verwendung im Langzeittraining haben wird. Zum Beispiel, wenn wir nur die Anzahl der Datenräume seriell durchqueren (dh von 0 bis len(df), haben wir nur so viele einzigartige Datenpunkte wie die Anzahl der Datenräume. Unser Beobachtungsraum kann nur eine diskrete Anzahl von Zuständen in jedem Zeitschritt verwenden.
Durch das zufällige Durchqueren der Datensätze können wir jedoch für jeden Zeitschritt des ursprünglichen Datensatzes einen sinnvolleren Satz von Handelsergebnissen erstellen, dh die Kombination von Handelsverhalten und Preisverhalten, die zuvor gesehen wurde, um einzigartige Datensätze zu erstellen.
Wenn der Zeitschritt nach dem Zurücksetzen der seriellen Umgebung 10 beträgt, wird unser Roboter immer gleichzeitig im Datensatz laufen, und nach jedem Zeitschritt gibt es drei Optionen: kaufen, verkaufen oder halten. Für jede der drei Optionen benötigen Sie eine weitere Option: 10%, 20%,... oder 100% des spezifischen Implementierungsbetrags. Dies bedeutet, dass unser Roboter einen der 10 Zustände von 103 Fällen, insgesamt 1030 Fälle, begegnen kann.
Wenn der Zeitschritt 10 ist, kann sich unser Roboter in einem beliebigen len(df) Zeitschritt innerhalb der Anzahl der Datenrahmen befinden. Unter der Annahme, dass nach jedem Zeitschritt die gleiche Wahl getroffen wird, bedeutet dies, dass der Roboter den einzigartigen Zustand eines beliebigen len(df) bis zur 30. Potenz in den gleichen 10 Zeitschritten erleben kann.
Obwohl dies zu erheblichem Lärm für große Datensätze führen kann, glaube ich, dass Roboter mehr aus unseren begrenzten Daten lernen dürfen. Wir werden unsere Testdaten immer noch seriell durchlaufen, um die frischesten und scheinbar
Durch die Augen eines Roboters beobachtet
Durch eine effektive visuelle Umgebungsbeobachtung ist es oft hilfreich, die Art der Funktionen zu verstehen, die unser Roboter verwenden wird.
Beobachtung der OpenCV-Visualisierungsumgebung
Jede Zeile im Bild repräsentiert eine Zeile in unserem Observation_space. Die ersten vier rote Linien mit ähnlichen Frequenzen repräsentieren OHCL-Daten, und die orangefarbenen und gelben Punkte direkt darunter repräsentieren das Handelsvolumen. Der schwankende blaue Balken darstellt den Nettowert des Roboters, während der helleren Balken darstellt die Transaktion des Roboters.
Wenn Sie sorgfältig beobachten, können Sie sogar selbst eine Kerzenkarte erstellen. Unterhalb der Handelsvolumenleiste befindet sich eine Morse-Code-Schnittstelle, die die Handelsgeschichte anzeigt. Es scheint, dass unser Roboter ausreichend aus den Daten in unserem Observation_space lernen kann, also lasst uns weitermachen. Hier definieren wir die _next_observation-Methode, wir skalieren die beobachteten Daten von 0 bis 1.
- Es ist wichtig, nur die bisher vom Roboter beobachteten Daten zu erweitern, um eine führende Abweichung zu verhindern.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
Handeln
Wir haben unseren Beobachtungsraum eingerichtet, und jetzt ist es Zeit, unsere Leiterfunktion zu schreiben, und dann die geplante Aktion des Roboters auszuführen. Wann immer self.steps_left == 0 für unsere aktuelle Handelssitzung ist, werden wir unsere BTC verkaufen und _reset_session rufen. Ansonsten setzen wir die Belohnung auf den aktuellen Nettowert. Wenn uns die Mittel ausgehen, setzen wir auf True.
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
Das Erstellen einer Handelsaktion ist so einfach wie das Erhalten des aktuellen Preises, die Bestimmung der zu ausführenden Aktionen und die Menge zum Kaufen oder Verkaufen.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
Schließlich werden wir die Transaktion mit derselben Methode an Self.trades anknüpfen und unseren Nettowert und die Kontohistorie aktualisieren.
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
Unser Roboter kann jetzt eine neue Umgebung starten, die Umgebung schrittweise vervollständigen und Maßnahmen ergreifen, die die Umwelt beeinflussen.
Sehen Sie sich unseren Roboterhandel an.
Unsere Rendering-Methode kann so einfach sein, wie Print (self.net_word) anzurufen, aber es ist nicht interessant genug. Stattdessen zeichnen wir ein einfaches Kerzendiagramm, das ein separates Diagramm der Spalte Handelsvolumen und unseres Nettowertes enthält.
Wir werden den Code in StockTrackingGraph.py aus meinem letzten Artikel bekommen und ihn neu gestalten, um sich an die Bitcoin-Umgebung anzupassen.
Die erste Änderung, die wir vornehmen müssen, ist die Aktualisierung von self.df [
from datetime import datetime
Zuerst importieren wir die Datumszeitbibliothek, und dann verwenden wir die utcfromtimestampmethod, um die UTC-String von jedem Zeitstempel und strftime zu erhalten, so dass sie als String formatiert wird: Y-m-d H:M-Format.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
Schließlich ändern wir self. df[
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
Wir können unsere Roboter jetzt beim Bitcoin-Handel beobachten.
Visualisieren Sie unseren Roboter mit Matplotlib
Das grüne Phantom-Label repräsentiert den Kauf von BTC, und das rote Phantom-Label repräsentiert den Verkauf. Das weiße Etikett in der oberen rechten Ecke ist der aktuelle Nettowert des Roboters, und das Etikett in der unteren rechten Ecke ist der aktuelle Preis von Bitcoin. Es ist einfach und elegant. Jetzt ist es Zeit, unsere Roboter zu trainieren und zu sehen, wie viel Geld wir verdienen können!
Ausbildungszeit
Eine der Kritikpunkte, die ich im vorherigen Artikel erhielt, war der Mangel an Quervalidierung und das Versagen, die Daten in Trainings- und Testsätze zu teilen. Der Zweck ist es, die Genauigkeit des endgültigen Modells auf neue Daten zu testen, die noch nie zuvor gesehen wurden. Obwohl dies nicht der Schwerpunkt dieses Artikels ist, ist es wirklich sehr wichtig. Weil wir Zeitreihendaten verwenden, haben wir bei der Quervalidierung nicht viele Möglichkeiten.
Bei dieser Validierung teilen Sie die Daten in k gleiche Gruppen, eine nach der anderen, einzeln, als Testgruppe und verwenden den Rest der Daten als Trainingsgruppe. Zeitreihendaten sind jedoch sehr zeitabhängig, was bedeutet, dass nachfolgende Daten stark von früheren Daten abhängen. Also wird k-fold nicht funktionieren, weil unser Roboter vor dem Handel aus zukünftigen Daten lernt, was ein unfairer Vorteil ist.
Bei Anwendung auf Zeitreihendaten gilt der gleiche Fehler für die meisten anderen Kreuzvalidierungsstrategien. Daher müssen wir nur einen Teil der vollständigen Datenrahmennummer als Trainingssatz von der Rahmennummer zu einigen willkürlichen Indizes verwenden und den Rest der Daten als Testsatz verwenden.
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
Als nächstes, da unsere Umgebung nur so eingerichtet ist, dass sie eine einzige Anzahl von Datenrahmen verarbeitet, werden wir zwei Umgebungen erstellen, eine für die Trainingsdaten und eine für die Testdaten.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
Nun, unser Modell zu trainieren ist so einfach wie einen Roboter mit unserer Umgebung zu erstellen und model.learn anzurufen.
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
Hier verwenden wir Tensorplatten, so dass wir unsere Tensorflussdiagramme leicht visualisieren und einige quantitative Indikatoren über unseren Roboter anzeigen können.
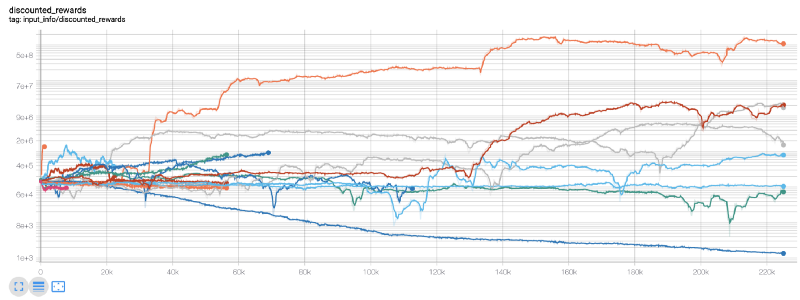
Wow, es scheint, dass unser Roboter sehr profitabel ist! Unser bester Roboter kann sogar 1000x Gleichgewicht in 200.000 Schritten erreichen, und der Rest wird sich im Durchschnitt mindestens 30-mal erhöhen!
Als ich den Fehler reparierte, wurde mir klar, dass es einen Fehler in der Umgebung gab.
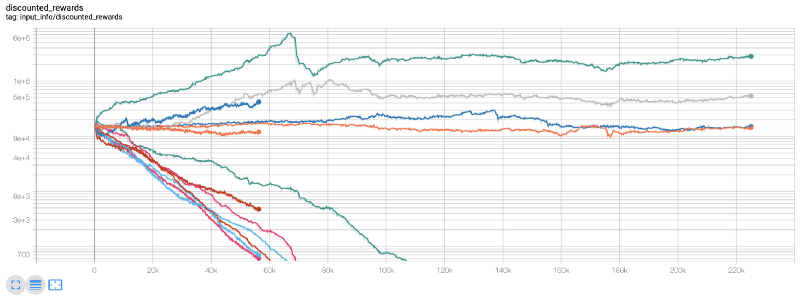
Wie Sie sehen können, machen einige unserer Roboter gut, während andere bankrott gehen. Roboter mit guter Leistung können jedoch höchstens das 10-fache oder sogar das 60-fache des Ausgangssaldos erreichen. Ich muss zugeben, dass alle profitablen Maschinen ohne Provisionen ausgebildet und getestet werden, so dass es unrealistisch ist, dass unsere Roboter echtes Geld verdienen. Aber zumindest haben wir den Weg gefunden!
Lassen Sie uns unsere Roboter in der Testumgebung testen (mit neuen Daten, die sie noch nie gesehen haben), um zu sehen, wie sie sich verhalten werden.
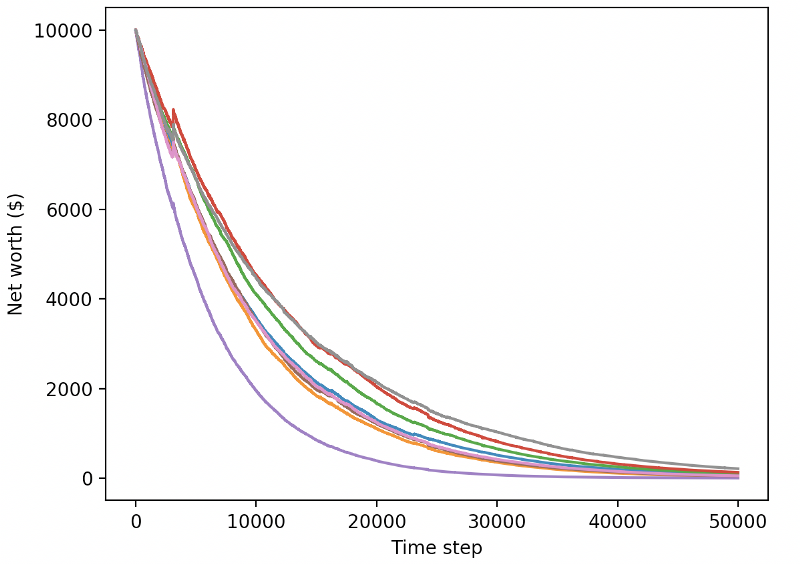
Unsere gut ausgebildeten Roboter werden pleite gehen, wenn sie neue Testdaten handeln.
Natürlich haben wir noch viel zu tun. Indem wir einfach die Modelle wechseln, um A2C mit stabiler Basislinie anstelle des aktuellen PPO2-Robot zu verwenden, können wir unsere Leistung auf diesem Datensatz erheblich verbessern. Schließlich können wir laut Sean O
reward = self.net_worth - prev_net_worth
Allein diese beiden Änderungen können die Leistung des Testdatensatzes erheblich verbessern, und wie Sie unten sehen können, konnten wir endlich von neuen Daten profitieren, die im Trainings-Set nicht verfügbar waren.
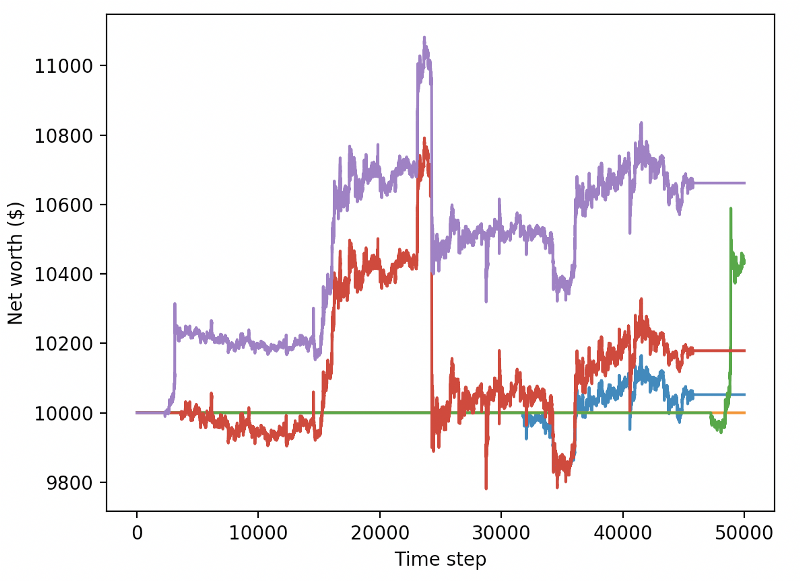
Aber wir können es besser machen. Um diese Ergebnisse zu verbessern, müssen wir unsere Superparameter optimieren und unsere Roboter länger trainieren.
In dem nächsten Artikel werden wir Bayesische Optimierung verwenden, um die besten Hyperparameter für unseren Problemraum zu partitionieren und uns auf das Training / Testen auf GPU mit CUDA vorzubereiten.
Schlussfolgerung
In diesem Artikel beginnen wir mit dem Verstärkungslernen, um einen profitablen Bitcoin-Handelsroboter von Grund auf neu zu erstellen.
Erstellen Sie eine Bitcoin-Handelsumgebung von Grund auf mit OpenAI's Gym.
Verwenden Sie Matplotlib, um die Visualisierung der Umgebung zu erstellen.
Verwenden Sie eine einfache Quervalidierung, um unseren Roboter zu trainieren und zu testen.
Wir müssen unsere Roboter leicht anpassen, um Gewinne zu erzielen.
Obwohl unser Handelsroboter nicht so profitabel war, wie wir gehofft hatten, bewegen wir uns bereits in die richtige Richtung. Nächstes Mal werden wir sicherstellen, dass unsere Roboter den Markt konsequent schlagen können. Wir werden sehen, wie unsere Handelsroboter Echtzeitdaten verarbeiten. Bitte folgen Sie meinem nächsten Artikel und Viva Bitcoin weiter!
- Quantitative Praxis der DEX-Börsen (2) -- Benutzerhandbuch für Hyperflüssigkeiten
- DEX-Börsen Quantitative Praxis ((2) -- Hyperliquid Benutzerhandbuch
- Quantitative Praxis der DEX-Börsen (1) -- dYdX v4 Benutzerhandbuch
- Einführung in Lead-Lag-Arbitrage in Kryptowährungen (3)
- DEX-Börsen Quantitative Praxis ((1)-- dYdX v4 Benutzerhandbuch
- Einführung der Lead-Lag-Suite in der Kryptowährung (3)
- Einführung in Lead-Lag-Arbitrage in Kryptowährungen (2)
- Einführung der Lead-Lag-Suite in der digitalen Währung (2)
- Diskussion über den externen Signalempfang der FMZ-Plattform: Eine Komplettlösung für den Empfang von Signalen mit integriertem Http-Service in der Strategie
- FMZ-Plattform: Erforschung von Signalempfangsstrategien für externe Netzwerke
- Einführung in Lead-Lag-Arbitrage in Kryptowährungen (1)
- Das Programm kann parallel ausgeführt werden und unterstützt mehrere Themen an der Unterseite von JavaScript-Policies.
- Wenn du nicht weißt, wie man eine Strategie in einer so leicht zu erlernenden und benutzerfreundlichen Pine-Sprache schreibt...
- Erwartete Gewinne aus Hochfrequenz-Handel
- Können wir quantitative Transaktionen ohne Code durchführen?
- "Erhalten Sie das beste Angebot" Analyse der Schwachstelle in der Börse
- 5.6 Entwickeln Sie Wahrscheinlichkeitsdenken, um Ihr Handelsmuster zu verbessern
- Elegant und einfach! Zugriff auf Uniswap V3 auf FMZ mit 200 Zeilen Code
- Wenn FMZ auf ChatGPT stößt, wird versucht, KI zu nutzen, um beim Lernen des quantitativen Handels zu helfen
- 9 Handelsregeln helfen einem Händler, in weniger als einem Jahr 46.000 Dollar von 1.000 Dollar zu verdienen
- Vom quantitativen Handel zum Asset Management - Entwicklung einer CTA-Strategie für eine absolute Rendite
- Das Geheimnis des Überlebens: 19 Fachleute geben Ratschläge zum Handel mit digitalen Währungen
- Verwenden Sie JavaScript, um die gleichzeitige Ausführung der quantitativen Strategie umzusetzen - die Go-Funktion einkapseln
- Die Anwendung von "Shannons Dämon" in digitaler Währung
- Elegant und einfach! Uniswap V3 mit 200 Codezeilen auf FMZ
- Grundsatz und Erstellung des Stop-Loss-Modells
- Tycoon enthüllt Algorithmushandel: FMZ Quant Plattform Marktmacherstrategie
- Drei mögliche Modelle im quantitativen Handel
- Pivot Point Intraday Trading System (Einzelhandelssystem für den Intraday-Handel)
- 6 einfache Strategien und Praktiken für Anfänger im quantitativen Handel mit digitaler Währung
- Strategischer Rahmen für den realen Durchschnittsbereich