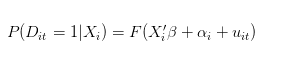Cuando predecimos probabilidades, ¿qué estamos prediciendo?
 3
3568
3
3568
Cuando predecimos probabilidades, ¿qué estamos prediciendo?
Hace mucho tiempo fui a una entrevista, y el tema me lo recuerda de nuevo.
Entrevistador: ¿Usted sabe de la regresión logística? Yo: Claro que lo sé, es muy común. Interrogador: Entonces, ¿cómo crees que la probabilidad de una predicción de regresión logística se explica como la probabilidad de éxito de un individuo? Yo: Por supuesto que no. Si sólo se observa una vez, la probabilidad de un individuo no se puede estimar. Se debe interpretar como que, dado N individuos con la misma característica, la tasa de éxito es igual a la probabilidad estimada.
Bueno, el entrevistador no estaba disponible, y por supuesto, al final de la entrevista, me limpiaron (tal vez debido a mi educación en economía, no en estadística o informática).
Si lo que digo es un poco contradictorio y difícil de entender, cuando estimamos el regreso logístico, lo que obtenemos es:
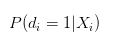
¿No debería ser interpretado como la probabilidad de éxito de un individuo?
- #### Creo que esa afirmación es problemática.
Cuando hablamos de la probabilidad de éxito de una persona en particular, debería ser la cantidad de veces que la misma persona ha tenido éxito en 100 repeticiones bajo las mismas condiciones. Si t es el número de veces que una persona ha intentado, entonces nuestro modelo ideal (el proceso de generación de datos) debería ser el siguiente:
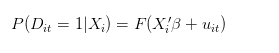
Sin embargo, alternativamente, el proceso de generación de datos reales podría ser el siguiente: