Análisis cuantitativo del mercado de divisas digitales
El autor:FMZ~Lydia, Creado: 2023-01-06 10:28:01, Actualizado: 2023-09-20 10:27:27
Análisis cuantitativo del mercado de divisas digitales
Un enfoque basado en datos para el análisis especulativo de las monedas digitales
¿Qué pasa con el precio de Bitcoin? ¿Cuáles son las razones para el aumento y disminución del precio de la moneda digital? ¿Están los precios de mercado de diferentes Altcoins inextricablemente relacionados o en gran medida independientes? ¿Cómo podemos predecir lo que sucederá a continuación?
Los artículos sobre monedas digitales, como Bitcoin y Ethereum, están ahora llenos de especulaciones. Cientos de autoproclamados expertos están abogando por la tendencia que esperan. Lo que falta a muchos de estos análisis es una base sólida para datos básicos y modelos estadísticos.
El objetivo de este artículo es proporcionar una breve introducción al análisis de monedas digitales utilizando Python. Usaremos un sencillo script de Python para recuperar, analizar y visualizar los datos de diferentes monedas digitales. En este proceso, encontraremos tendencias interesantes en el comportamiento del mercado de estas fluctuaciones y cómo se desarrollan.
Este no es un artículo que explique la moneda digital, ni tampoco es una opinión sobre qué monedas específicas aumentarán y cuáles disminuirán.
Paso 1: Configurar nuestro entorno de trabajo de datos
Este tutorial está destinado a entusiastas, ingenieros y científicos de datos de todos los niveles de habilidad. Ya sea que usted sea un líder de la industria o un principiante en programación, la única habilidad que necesita es una comprensión básica del lenguaje de programación Python y un conocimiento suficiente de las operaciones de línea de comandos (ser capaz de configurar un proyecto de ciencia de datos es suficiente).
1.1 Instale el muelle de FMZ Quant y configure Anaconda
- Sistema Docker de la plataforma FMZ Quant La plataforma FMZ QuantFMZ.COMEste conjunto de interfaces incluye herramientas prácticas, como consultar la información de la cuenta, consultar el alto, abierto, bajo, precio de recibo, volumen de negociación y varios indicadores de análisis técnico comúnmente utilizados de varios intercambios principales. En particular, proporciona un fuerte soporte técnico para las interfaces API públicas que conectan los principales intercambios principales en el proceso de negociación real.
Todas las características mencionadas anteriormente están encapsuladas en un sistema similar a Docker. Lo que necesitamos hacer es comprar o alquilar nuestros propios servicios de computación en la nube e implementar el sistema Docker.
En el nombre oficial de la plataforma FMZ Quant, este sistema Docker se llama sistema Docker.
Por favor, consulte mi artículo anterior sobre cómo desplegar un docker y robot:https://www.fmz.com/bbs-topic/9864.
Los lectores que quieran comprar su propio servidor de computación en la nube para implementar dockers pueden consultar este artículo:https://www.fmz.com/digest-topic/5711.
Después de desplegar el servidor de computación en la nube y el sistema de docker con éxito, a continuación instalaremos el artefacto más grande de Python: Anaconda
Para realizar todos los entornos de programa relevantes (bibliotecas de dependencias, gestión de versiones, etc.) requeridos en este artículo, la forma más simple es usar Anaconda.
Dado que instalamos Anaconda en el servicio en la nube, recomendamos que el servidor en la nube instale el sistema Linux más la versión de línea de comandos de Anaconda.
Para el método de instalación de Anaconda, consulte la guía oficial de Anaconda:https://www.anaconda.com/distribution/.
Si usted es un programador Python experimentado y si siente que no necesita usar Anaconda, no es un problema en absoluto. Asumiré que no necesita ayuda al instalar el entorno dependiente necesario. Puede omitir esta sección directamente.
1.2 Crear un entorno de proyecto de análisis de datos para Anaconda
Una vez que Anaconda está instalado, necesitamos crear un nuevo entorno para gestionar nuestros paquetes dependientes. En la interfaz de línea de comandos de Linux, ingresamos:
conda create --name cryptocurrency-analysis python=3
para crear un nuevo entorno de Anaconda para nuestro proyecto.
A continuación, entrada:
source activate cryptocurrency-analysis (linux/MacOS operating system)
or
activate cryptocurrency-analysis (windows operating system)
para activar el medio ambiente.
A continuación, entrada:
conda install numpy pandas nb_conda jupyter plotly
para instalar varios paquetes dependientes necesarios para este proyecto.
Nota: ¿Por qué usar el entorno de Anaconda? Si planea ejecutar muchos proyectos de Python en su computadora, es útil separar los paquetes dependientes (bibliotecas de software y paquetes) de diferentes proyectos para evitar conflictos. Ananconda creará un directorio de entorno especial para los paquetes dependientes de cada proyecto, para que todos los paquetes puedan administrarse y distinguirse correctamente.
1.3 Crear un cuaderno Jupyter
Después de instalar el entorno y los paquetes dependientes, ejecutar:
jupyter notebook
para iniciar el núcleo de iPython, luego visitehttp://localhost:8888/con su navegador, crear un nuevo cuaderno de Python, asegurándose de que utiliza el:
Python [conda env:cryptocurrency-analysis]
el corazón

1.4 Envases dependientes de las importaciones
Crear un cuaderno de Jupyter vacío, y lo primero que tenemos que hacer es importar los paquetes dependientes requeridos.
import os
import numpy as np
import pandas as pd
import pickle
from datetime import datetime
También necesitamos importar Plotly y habilitar el modo fuera de línea:
import plotly.offline as py
import plotly.graph_objs as go
import plotly.figure_factory as ff
py.init_notebook_mode(connected=True)
Paso 2: Obtener la información del precio de la moneda digital
La preparación está completa, y ahora podemos comenzar a obtener los datos a analizar. Primero, usaremos la interfaz API de la plataforma FMZ Quant para obtener los datos de precios de Bitcoin.
Para el uso de estas dos funciones, consulte:https://www.fmz.com/api.
2.1 Escribir una función de recopilación de datos Quandl
Para facilitar la adquisición de datos, necesitamos escribir una función para descargar y sincronizar datos de Quandl (quandl.comEsta es una interfaz de datos financieros gratuita, que goza de una alta reputación en el extranjero. La plataforma FMZ Quant también proporciona una interfaz de datos similar, que se utiliza principalmente para transacciones de bots reales.
Durante la transacción real del bot, puede llamar a las funciones GetTicker y GetRecords en Python directamente para obtener datos de precios.https://www.fmz.com/api.
def get_quandl_data(quandl_id):
# Download and cache data columns from Quandl
cache_path = '{}.pkl'.format(quandl_id).replace('/','-')
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(quandl_id))
except (OSError, IOError) as e:
print('Downloading {} from Quandl'.format(quandl_id))
df = quandl.get(quandl_id, returns="pandas")
df.to_pickle(cache_path)
print('Cached {} at {}'.format(quandl_id, cache_path))
return df
Aquí, la biblioteca de pepinos se utiliza para serializar los datos y guardar los datos descargados como un archivo, para que el programa no descargue los mismos datos cada vez que se ejecute. Esta función devolverá datos en formato Pandas Dataframe. Si no está familiarizado con el concepto de marco de datos, puede imaginarlo como un poderoso Excel.
2.2 Acceso a los datos de precios de las monedas digitales de la bolsa Kraken
Tomemos el Kraken Bitcoin Exchange como ejemplo, comenzando por obtener su precio de Bitcoin.
# Get prices on the Kraken Bitcoin exchange
btc_usd_price_kraken = get_quandl_data('BCHARTS/KRAKENUSD')
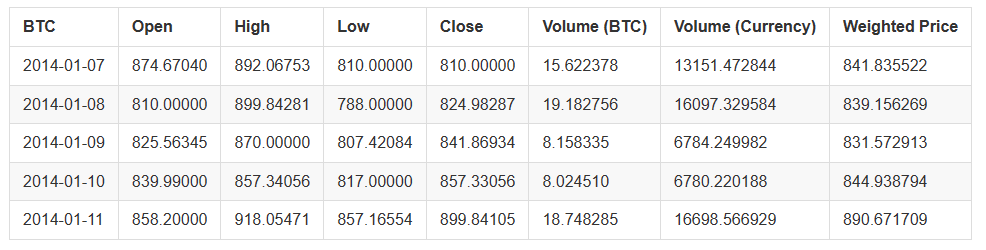
Utilice el método head() para ver las primeras cinco filas del cuadro de datos.
btc_usd_price_kraken.head()
El resultado es:
A continuación, vamos a hacer una tabla simple con el fin de verificar la corrección de los datos por visualización.
# Make a table of BTC prices
btc_trace = go.Scatter(x=btc_usd_price_kraken.index, y=btc_usd_price_kraken['Weighted Price'])
py.iplot([btc_trace])
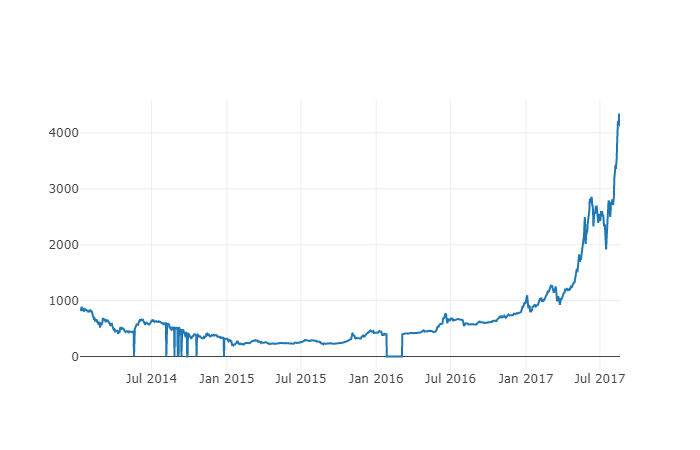
Aquí, usamos Plotly para completar la parte de visualización. En comparación con el uso de algunas bibliotecas de visualización de datos de Python más maduras, como Matplotlib, Plotly es una opción menos común, pero es realmente una buena opción, porque puede llamar a gráficos completamente interactivos D3.js
Consejos: El gráfico generado se puede comparar con el gráfico de precios de Bitcoin de los principales intercambios (como el gráfico de OKX, Binance o Huobi) como una verificación rápida de integridad para confirmar si los datos descargados son generalmente consistentes.
2.3 Obtener datos de precios de los principales intercambios de Bitcoin
Los lectores cuidadosos pueden haber notado que hay datos faltantes en los datos anteriores, especialmente a finales de 2014 y principios de 2016.
La característica del intercambio de moneda digital es que la relación de oferta y demanda determina el precio de la moneda. Por lo tanto, ningún precio de transacción puede convertirse en el
Comencemos descargando los datos de cada intercambio en el marco de datos compuesto por tipos de diccionario.
# Download price data from COINBASE, BITSTAMP and ITBIT
exchanges = ['COINBASE','BITSTAMP','ITBIT']
exchange_data = {}
exchange_data['KRAKEN'] = btc_usd_price_kraken
for exchange in exchanges:
exchange_code = 'BCHARTS/{}USD'.format(exchange)
btc_exchange_df = get_quandl_data(exchange_code)
exchange_data[exchange] = btc_exchange_df
2.4 Integrar todos los datos en un mismo marco de datos
A continuación, vamos a definir una función especial para fusionar las columnas que son comunes a cada marco de datos en un nuevo marco de datos.
def merge_dfs_on_column(dataframes, labels, col):
'''Merge a single column of each dataframe into a new combined dataframe'''
series_dict = {}
for index in range(len(dataframes)):
series_dict[labels[index]] = dataframes[index][col]
return pd.DataFrame(series_dict)
Ahora, todos los marcos de datos se integran en base a la columna
# Integrate all data frames
btc_usd_datasets = merge_dfs_on_column(list(exchange_data.values()), list(exchange_data.keys()), 'Weighted Price')
Finalmente, utilizamos el método
btc_usd_datasets.tail()
Los resultados se muestran de la siguiente manera:
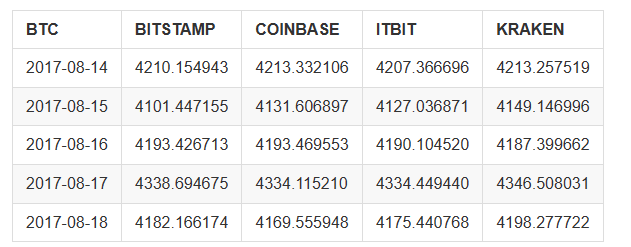
A partir de la tabla anterior, podemos ver que estos datos están en línea con nuestras expectativas, con aproximadamente el mismo rango de datos, pero ligeramente diferentes en función del retraso o las características de cada intercambio.
2.5 Proceso de visualización de los datos de precios
Desde la perspectiva de la lógica de análisis, el siguiente paso es comparar estos datos a través de la visualización. Para hacer esto, primero necesitamos definir una función auxiliar. Al proporcionar un comando de una sola línea para usar datos para hacer un gráfico, la llamamos función df_scatter.
def df_scatter(df, title, seperate_y_axis=False, y_axis_label='', scale='linear', initial_hide=False):
'''Generate a scatter plot of the entire dataframe'''
label_arr = list(df)
series_arr = list(map(lambda col: df[col], label_arr))
layout = go.Layout(
title=title,
legend=dict(orientation="h"),
xaxis=dict(type='date'),
yaxis=dict(
title=y_axis_label,
showticklabels= not seperate_y_axis,
type=scale
)
)
y_axis_config = dict(
overlaying='y',
showticklabels=False,
type=scale )
visibility = 'visible'
if initial_hide:
visibility = 'legendonly'
# Table tracking for each series
trace_arr = []
for index, series in enumerate(series_arr):
trace = go.Scatter(
x=series.index,
y=series,
name=label_arr[index],
visible=visibility
)
# Add a separate axis to the series
if seperate_y_axis:
trace['yaxis'] = 'y{}'.format(index + 1)
layout['yaxis{}'.format(index + 1)] = y_axis_config
trace_arr.append(trace)
fig = go.Figure(data=trace_arr, layout=layout)
py.iplot(fig)
Para su fácil comprensión, este artículo no discutirá demasiado el principio lógico de esta función auxiliar.
Ahora, podemos crear gráficos de datos de precios de Bitcoin fácilmente!
# Plot all BTC transaction prices
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
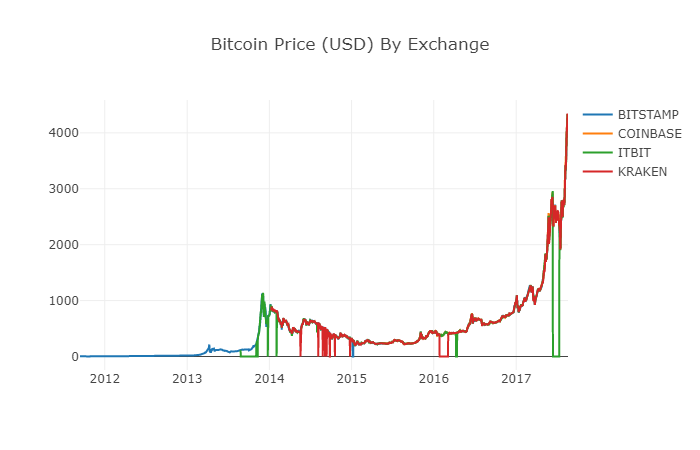
2.6 Datos de precios claros y agregados
Como se puede ver en el gráfico anterior, aunque las cuatro series de datos siguen aproximadamente el mismo camino, todavía hay algunos cambios irregulares.
En el período 2012-2017, sabemos que el precio de Bitcoin nunca ha sido igual a cero, así que primero eliminamos todos los valores cero en el marco de datos.
# Clear the "0" value
btc_usd_datasets.replace(0, np.nan, inplace=True)
Después de reconstruir los marcos de datos, podemos ver un gráfico más claro sin datos faltantes.
# Plot the revised data frame
df_scatter(btc_usd_datasets, 'Bitcoin Price (USD) By Exchange')
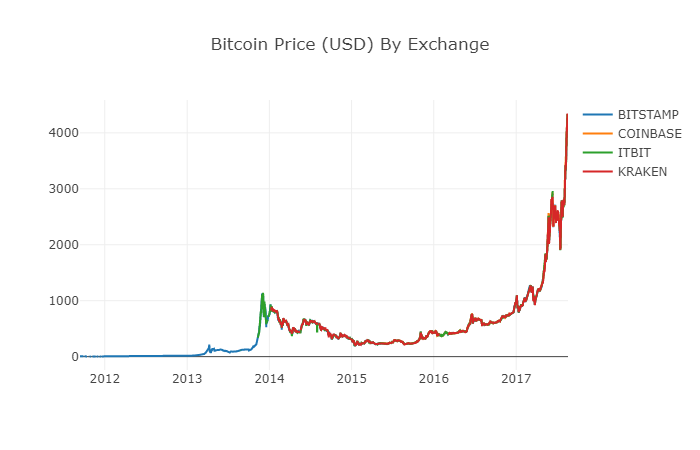
Podemos calcular una nueva columna ahora: el precio promedio diario de Bitcoin de todos los intercambios.
# Calculate the average BTC price as a new column
btc_usd_datasets['avg_btc_price_usd'] = btc_usd_datasets.mean(axis=1)
La nueva columna es el índice de precios de Bitcoin! Vamos a dibujarlo de nuevo para comprobar si los datos se ven mal.
# Plot the average BTC price
btc_trace = go.Scatter(x=btc_usd_datasets.index, y=btc_usd_datasets['avg_btc_price_usd'])
py.iplot([btc_trace])
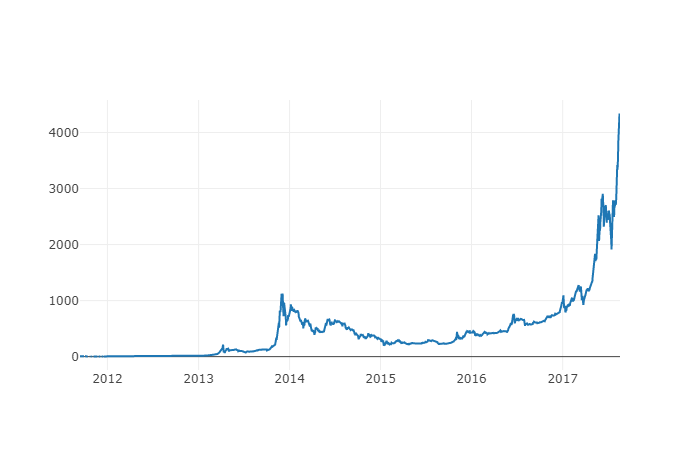
Parece que no hay ningún problema. Más adelante, vamos a seguir utilizando estos datos agregados de la serie de precios para determinar el tipo de cambio entre otras monedas digitales y el USD.
Paso 3: Recoge el precio de las Altcoins
Hasta ahora, tenemos los datos de las series temporales del precio de Bitcoin. A continuación, echemos un vistazo a algunos datos de monedas digitales no Bitcoin, es decir, Altcoins. Por supuesto, el término
3.1 Definir las funciones auxiliares a través de la API del intercambio Poloniex
Primero, utilizamos la API del intercambio Poloniex para obtener la información de datos de las transacciones de moneda digital. Definimos dos funciones auxiliares para obtener los datos relacionados con Altcoins. Estas dos funciones descargan y almacenan en caché los datos JSON a través de API.
Primero, definimos la función get_json_data, que descargará y almacenará en caché los datos JSON de la URL dada.
def get_json_data(json_url, cache_path):
'''Download and cache JSON data, return as a dataframe.'''
try:
f = open(cache_path, 'rb')
df = pickle.load(f)
print('Loaded {} from cache'.format(json_url))
except (OSError, IOError) as e:
print('Downloading {}'.format(json_url))
df = pd.read_json(json_url)
df.to_pickle(cache_path)
print('Cached {} at {}'.format(json_url, cache_path))
return df
A continuación, definimos una nueva función que generará la solicitud HTTP de la API de Poloniex y llamar a la función get_ json_data definida para guardar los resultados de datos de la llamada.
base_polo_url = 'https://poloniex.com/public?command=returnChartData¤cyPair={}&start={}&end={}&period={}'
start_date = datetime.strptime('2015-01-01', '%Y-%m-%d') # Data acquisition since 2015
end_date = datetime.now() # Until today
pediod = 86400 # pull daily data (86,400 seconds per day)
def get_crypto_data(poloniex_pair):
'''Retrieve cryptocurrency data from poloniex'''
json_url = base_polo_url.format(poloniex_pair, start_date.timestamp(), end_date.timestamp(), pediod)
data_df = get_json_data(json_url, poloniex_pair)
data_df = data_df.set_index('date')
return data_df
La función anterior extraerá el código de caracteres correspondiente de la moneda digital (como
3.2 Descargar datos de precios de transacción de Poloniex
Para obtener estas monedas digitales, los individuos generalmente tienen que comprar Bitcoin primero, y luego convertirlos en Altcoins de acuerdo con su relación de precio. Por lo tanto, tenemos que descargar el tipo de cambio de cada moneda digital a Bitcoin, y luego usar los datos de precio de Bitcoin existentes para convertirlo en USD. Descargaremos los datos de tipo de cambio para las 9 principales monedas digitales: Ethereum, Litecoin, Ripple, EthereumClassic, Stellar, Dash, Siacoin, Monero y NEM.
altcoins = ['ETH','LTC','XRP','ETC','STR','DASH','SC','XMR','XEM']
altcoin_data = {}
for altcoin in altcoins:
coinpair = 'BTC_{}'.format(altcoin)
crypto_price_df = get_crypto_data(coinpair)
altcoin_data[altcoin] = crypto_price_df
Ahora, tenemos un diccionario que contiene 9 marcos de datos, cada uno de los cuales contiene datos históricos del precio promedio diario entre Altcoins y Bitcoin.
Podemos determinar si los datos son correctos a través de las últimas filas de la tabla de precios de Ethereum.
altcoin_data['ETH'].tail()
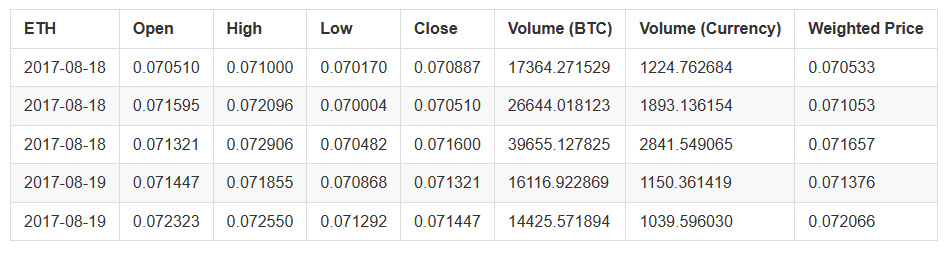
3.3 Unificar la unidad monetaria de todos los datos de precios en USD
Ahora, podemos combinar los datos del tipo de cambio de BTC y Altcoins con nuestro índice de precios de Bitcoin para calcular el precio histórico de cada Altcoin (en USD) directamente.
# Calculate USD Price as a new column in each altcoin data frame
for altcoin in altcoin_data.keys():
altcoin_data[altcoin]['price_usd'] = altcoin_data[altcoin]['weightedAverage'] * btc_usd_datasets['avg_btc_price_usd']
Aquí, añadimos una nueva columna para cada marco de datos de Altcoin para almacenar su correspondiente precio en dólares.
A continuación, podemos reutilizar la función merge_dfs_on_column definida previamente para crear un marco de datos combinado e integrar el precio en USD de cada moneda digital.
# Combine the USD price of each Altcoin into a single data frame
combined_df = merge_dfs_on_column(list(altcoin_data.values()), list(altcoin_data.keys()), 'price_usd')
¡Ya está!
Ahora vamos a añadir el precio de Bitcoin como la última columna al marco de datos fusionado.
# Add BTC price to data frame
combined_df['BTC'] = btc_usd_datasets['avg_btc_price_usd']
Ahora tenemos un marco de datos único, que contiene los precios diarios en dólares de diez monedas digitales que estamos verificando.
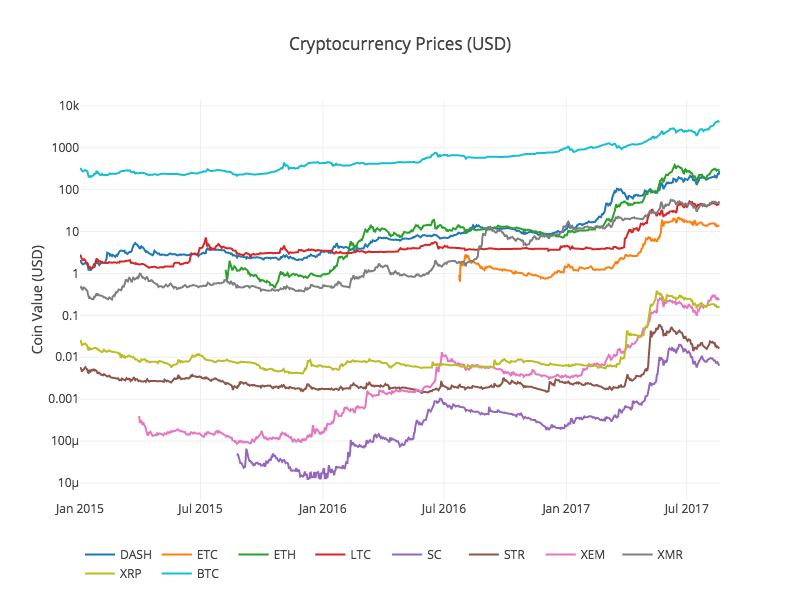
Llamamos a la función anterior df_scatter de nuevo, mostrando los precios correspondientes de todas las Altcoins en forma de gráfico.
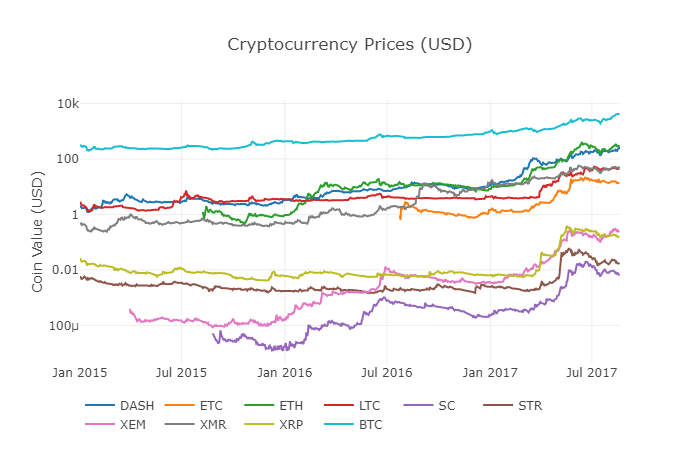
Este gráfico nos muestra una imagen completa del cambio del precio de cambio de cada moneda digital en los últimos años.
Nota: aquí usamos el eje y de la especificación logarítmica para comparar todas las monedas digitales en el mismo gráfico. También puede probar diferentes parámetros (como escala=
3.4 Comienza el análisis de correlación
Los lectores cuidadosos pueden haber notado que los precios de las monedas digitales parecen ser relevantes, aunque sus valores de divisas varían ampliamente y son altamente volátiles.
Por supuesto, las conclusiones basadas en datos son más convincentes que las intuiciones basadas en imágenes.
Podemos usar la función Pandas corr() para verificar la hipótesis de correlación anterior. Este método de prueba calcula el coeficiente de correlación de Pearson de cada columna del marco de datos correspondiente a la otra columna.
Nota de revisión de 2017.8.22: Esta sección fue modificada para utilizar la tasa de rendimiento diaria en lugar del valor absoluto del precio al calcular el coeficiente de correlación.
El cálculo directo basado en una serie temporal no sólida (como los datos de precios en bruto) puede conducir a la desviación del coeficiente de correlación. Para resolver este problema, nuestra solución es utilizar el método pct_change() para convertir el valor absoluto de cada precio en el marco de datos en la tasa de rendimiento diaria correspondiente.
Por ejemplo, calculemos el coeficiente de correlación en 2016.
# Calculating the Pearson correlation coefficient for digital currencies in 2016
combined_df_2016 = combined_df[combined_df.index.year == 2016]
combined_df_2016.pct_change().corr(method='pearson')
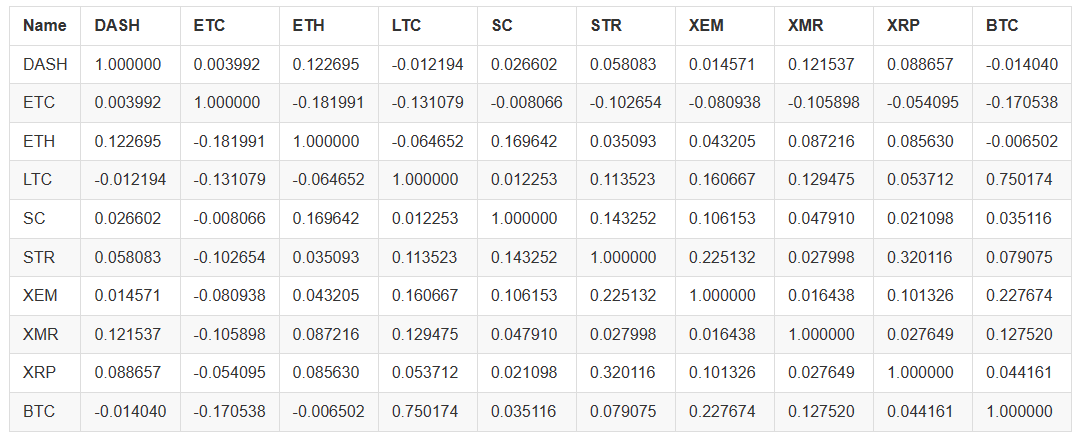
El gráfico anterior muestra el coeficiente de correlación. Cuando el coeficiente está cerca de 1 o -1, significa que esta serie está correlacionada positivamente o negativamente, respectivamente. Cuando el coeficiente de correlación está cerca de 0, significa que los objetos correspondientes no están correlacionados y sus fluctuaciones son independientes entre sí.
Para visualizar mejor los resultados, creamos una nueva función de ayuda visual.
def correlation_heatmap(df, title, absolute_bounds=True):
'''Plot a correlation heatmap for the entire dataframe'''
heatmap = go.Heatmap(
z=df.corr(method='pearson').as_matrix(),
x=df.columns,
y=df.columns,
colorbar=dict(title='Pearson Coefficient'),
)
layout = go.Layout(title=title)
if absolute_bounds:
heatmap['zmax'] = 1.0
heatmap['zmin'] = -1.0
fig = go.Figure(data=[heatmap], layout=layout)
py.iplot(fig)
correlation_heatmap(combined_df_2016.pct_change(), "Cryptocurrency Correlations in 2016")
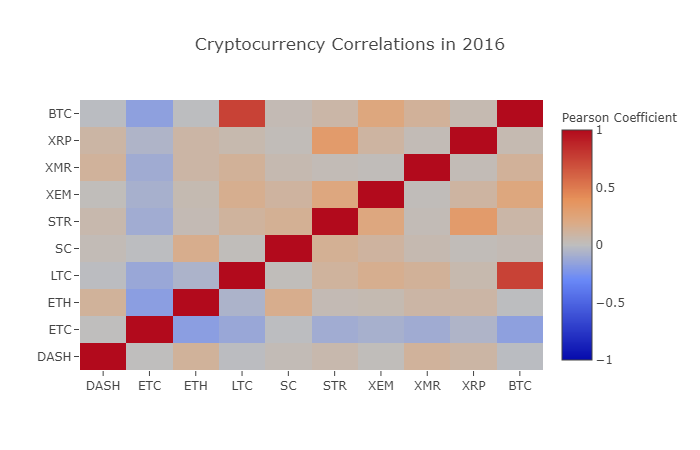
Aquí, el valor rojo oscuro representa una fuerte correlación (cada moneda está obviamente altamente correlacionada consigo misma), y el valor azul oscuro representa una correlación inversa.
Básicamente, muestra la fluctuación de los precios de las diferentes monedas digitales en 2016, con poca correlación estadísticamente significativa.
Ahora, para verificar nuestra hipótesis de que
combined_df_2017 = combined_df[combined_df.index.year == 2017]
combined_df_2017.pct_change().corr(method='pearson')
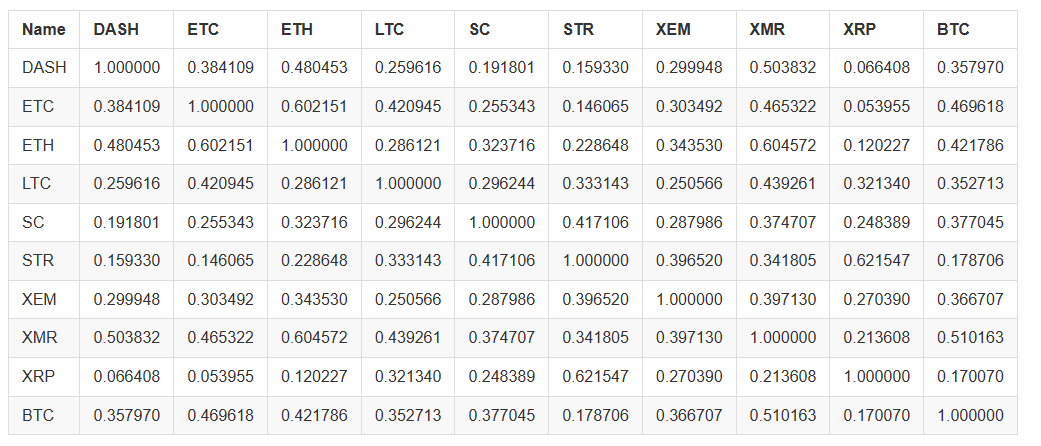
¿Son los datos anteriores más relevantes? ¿Son suficientes para utilizarlos como criterio de evaluación de la inversión?
Sin embargo, vale la pena señalar que casi todas las monedas digitales se han vuelto cada vez más interconectadas.
correlation_heatmap(combined_df_2017.pct_change(), "Cryptocurrency Correlations in 2017")
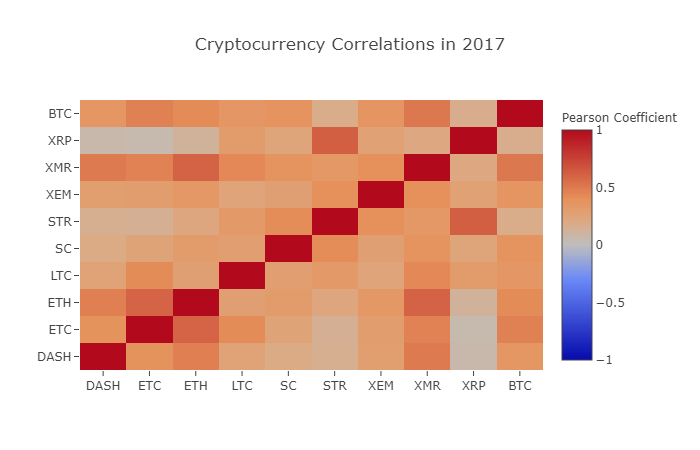
Como podemos ver en el cuadro anterior, las cosas se están volviendo cada vez más interesantes.
¿Por qué sucede esto?
Pero la verdad es que no estoy seguro...
Mi primera reacción es que los fondos de cobertura han comenzado recientemente a operar públicamente en el mercado de divisas digitales. Estos fondos tienen mucho más capital que los comerciantes ordinarios. Cuando un fondo cubre su capital invertido entre múltiples monedas digitales, utiliza estrategias comerciales similares para cada moneda de acuerdo con variables independientes (como el mercado de valores). Desde esta perspectiva, tiene sentido que ocurra esta tendencia de creciente correlación.
Una comprensión más profunda de XRP y STR
Por ejemplo, es obvio del gráfico anterior que XRP (el token de Ripple
Curiosamente, Stellar y Ripple son plataformas de tecnología financiera muy similares, ambas con el objetivo de reducir los tediosos pasos de transferencia transfronteriza entre bancos. Es concebible que algunos grandes jugadores y fondos de cobertura puedan usar estrategias comerciales similares para sus inversiones en Stellar y Ripple, considerando la similitud de los tokens utilizados por los servicios de blockchain. Esta puede ser la razón por la cual XRP es más relevante para STR que otras monedas digitales.
¡Bueno, es tu turno!
Las explicaciones anteriores son en gran parte especulativas, y usted puede hacerlo mejor. Basado en la base que hemos establecido, usted tiene cientos de maneras diferentes de continuar explorando las historias contenidas en los datos.
Los lectores pueden consultar la investigación en las siguientes direcciones:
- Agregue más datos de moneda digital a todo el análisis.
- Ajustar el intervalo de tiempo y la granularidad del análisis de correlación para obtener una visión de tendencia optimizada o de grano grueso.
- En comparación con los datos de precios originales, si desea predecir las fluctuaciones de precios futuras, es posible que necesite más datos de relación cantidad compra / venta.
- Agregue datos de precios a las acciones, materias primas y monedas fiduciarias para determinar cuál de ellas es relevante para las monedas digitales (pero no olvide el viejo dicho
correlación no implica causalidad ). - Utilice el Registro de Eventos, GDELT y Google Trends para cuantificar el número de palabras calientes que rodean una moneda digital específica.
- Utilice los datos para entrenar un modelo de aprendizaje automático predictivo para predecir los precios del mañana.
- Utilice su análisis para crear un robot de negociación automático, que puede aplicarse al sitio web de intercambio de
Poloniex FMZ.COM) se recomienda aquí.o Coinbase a través de la interfaz de programación de aplicaciones correspondiente (API). Tenga cuidado: un robot con un rendimiento deficiente puede destruir fácilmente sus activos al instante.
La mejor parte de Bitcoin y la moneda digital en general es su naturaleza descentralizada, lo que la hace más libre y democrática que cualquier otro activo. Puede compartir su análisis de código abierto, participar en la comunidad o escribir un blog! Espero que haya dominado las habilidades necesarias para el autoanálisis y la capacidad de pensar dialécticamente al leer cualquier artículo especulativo de moneda digital en el futuro, especialmente aquellas predicciones sin soporte de datos. Gracias por leer. Si tiene algún comentario, sugerencia o crítica sobre este tutorial, por favor deje un mensaje enhttps://www.fmz.com/bbs.
- Prácticas de cuantificación de las bolsas DEX ((1) -- dYdX v4 Guía de uso
- Introducción al conjunto de Lead-Lag en las monedas digitales (3)
- Introducción al arbitraje de lead-lag en criptomonedas (2)
- Introducción al conjunto de Lead-Lag en las monedas digitales (2)
- Discusión sobre la recepción de señales externas de la plataforma FMZ: una solución completa para recibir señales con servicio HTTP incorporado en la estrategia
- Exploración de la recepción de señales externas de la plataforma FMZ: estrategias para una solución completa de recepción de señales de servicios HTTP integrados
- Introducción al arbitraje de lead-lag en criptomonedas (1)
- Introducción al conjunto de Lead-Lag en las monedas digitales (1)
- Discusión sobre la recepción de señales externas de la plataforma FMZ: API extendida VS estrategia Servicio HTTP incorporado
- Exploración de la recepción de señales externas de la plataforma FMZ: API de expansión vs estrategia de servicio HTTP incorporado
- Discusión sobre el método de prueba de estrategias basado en el generador de tickers aleatorios
- Compartición tardía: Robot de alta frecuencia Bitcoin con 5% de rendimientos diarios en 2014
- Redes neuronales y moneda digital Serie de comercio cuantitativo (2) - Aprendizaje y capacitación intensivos Estrategia de comercio de Bitcoin
- Las redes neuronales y la serie de comercio cuantitativo de moneda digital (1) - LSTM predice el precio de Bitcoin
- Aplicación de la estrategia combinada del índice de resistencia relativa de la SMA y del RSI
- El desarrollo de la estrategia de CTA y la biblioteca de clases estándar de la plataforma FMZ Quant
- Estrategia de negociación cuantitativa con análisis de impulso de precios en Python
- Implementar una estrategia de negociación cuantitativa de moneda digital de doble impulso en Python
- La mejor manera de instalar y actualizar para Linux docker
- Lograr estrategias equitativas equilibradas de posiciones largas y cortas con una alineación ordenada
- Análisis de datos de series temporales y pruebas de retroceso de datos de tick
- Comercio de pares basado en tecnología basada en datos
- Aplicación de la tecnología de aprendizaje automático en el comercio
- Utilice el entorno de investigación para analizar los detalles de la cobertura triangular y el impacto de las tarifas de gestión en la diferencia de precios cubierta.
- Reforma de la API de futuros de Deribit para adaptarla a la negociación cuantitativa de opciones
- Mejores herramientas hacen un buen trabajo - aprender a utilizar el entorno de investigación para analizar los principios comerciales
- Estrategias de cobertura de divisas cruzadas en la negociación cuantitativa de activos de cadena de bloques
- Adquiere la guía de estrategia de moneda digital de FMex en FMZ Quant
- Enseñarle a escribir estrategias -- trasplantar una estrategia MyLanguage (Advanced)
- Enseñar a escribir estrategias -- trasplantar una estrategia MyLanguage
- Enseñarle a añadir soporte multi-gráfico a la estrategia