Visite guidée des algorithmes d'apprentissage automatique
 0
3102
0
3102
Visite guidée des algorithmes d’apprentissage automatique
Après avoir compris les problèmes d’apprentissage automatique que nous devons résoudre (http://machinelearningmastery.com/practical-machine-learning-problems/), nous pouvons réfléchir aux données que nous devons collecter et aux algorithmes que nous pouvons utiliser. Il y a beaucoup d’algorithmes dans le domaine de l’apprentissage automatique, et il y a beaucoup d’extensions pour chaque type d’algorithme, il est donc difficile de déterminer le bon pour un problème particulier. Dans cet article, je vais vous donner deux façons de résumer les algorithmes que vous rencontrerez dans la réalité.
- #### Comment apprendre
Les algorithmes sont classés en différentes catégories en fonction de la manière dont ils traitent l’expérience, l’environnement ou tout ce que nous appelons des données d’entrée. Les manuels d’apprentissage de l’apprentissage automatique et de l’intelligence artificielle considèrent généralement d’abord les méthodes d’apprentissage que les algorithmes peuvent adapter.
Il n’y a que quelques principaux styles d’apprentissage ou modèles d’apprentissage discutés ici, et quelques exemples de base. Cette méthode de classification ou d’organisation est bonne car elle vous oblige à réfléchir aux rôles des données d’entrée et au processus de préparation du modèle, puis à choisir l’algorithme qui convient le mieux à votre problème pour obtenir les meilleurs résultats.
L’apprentissage supervisé: les données d’entrée sont appelées données de formation et sont marquées avec un résultat connu. Par exemple, un e-mail est un spam ou un cours d’une action sur une période donnée. Le modèle fait des prédictions, qui sont corrigées si elles sont erronées, et ce processus se poursuit jusqu’à ce qu’il atteigne un certain niveau de validité pour les données de formation. L’apprentissage non supervisé: les données d’entrée ne sont pas marquées et aucun résultat n’est déterminé. Les modèles induisent la structure et la valeur numérique des données. Des exemples de problèmes incluent l’apprentissage des règles d’association et les problèmes de regroupement, et des exemples d’algorithmes incluent les algorithmes Apriori et les algorithmes K-mean. L’apprentissage semi-supervisé: les données d’entrée sont un mélange de données marquées et non marquées, il y a quelques problèmes de prédiction mais le modèle doit aussi apprendre la structure et la composition des données. Les exemples de problèmes incluent les problèmes de classification et de régression, et les exemples d’algorithmes sont essentiellement des extensions d’algorithmes d’apprentissage non supervisé. Apprentissage renforcé: les données d’entrée peuvent stimuler le modèle et le faire réagir. La rétroaction ne provient pas seulement de l’apprentissage supervisé, mais aussi des récompenses ou des punitions dans l’environnement. Des exemples de problèmes sont le contrôle par des robots, des exemples d’algorithmes incluent le Q-learning et l’apprentissage des différences temporelles.
Lors de l’intégration de la simulation de données dans les décisions commerciales, la plupart utilisent des méthodes d’apprentissage supervisé et non supervisé. Un sujet en vogue est l’apprentissage semi-supervisé, comme le problème de classification d’images, dans lequel il y a une grande base de données de problèmes, mais seulement une petite partie des images est marquée.
- #### Similitude des algorithmes
Les algorithmes sont essentiellement classés en fonction de leur fonction ou de leur forme. Par exemple, les algorithmes basés sur des arbres, les algorithmes de réseaux neuronaux. C’est une méthode de classification très utile, mais pas parfaite.
Dans cette section, j’ai énuméré les algorithmes de classification que je considère comme les plus intuitifs. Je n’ai pas une liste exhaustive d’algorithmes ou de méthodes de classification, mais je pense qu’il est utile de donner aux lecteurs une idée générale. Si vous avez des informations que je n’ai pas énumérées, n’hésitez pas à les partager.
- #### Regression
La régression se préoccupe de la relation entre les variables. Elle applique des méthodes statistiques. Quelques exemples d’algorithmes incluent:
Ordinary Least Squares Logistic Regression Stepwise Regression Multivariate Adaptive Regression Splines (MARS) Locally Estimated Scatterplot Smoothing (LOESS)
- #### Instance-based Methods
L’apprentissage basé sur les instances simule un problème de décision, l’exemple ou l’exemple utilisé est très important pour le modèle. Cette méthode établit une base de données sur les données existantes, puis ajoute de nouvelles données, puis utilise une méthode de mesure de la similitude pour trouver la meilleure correspondance dans la base de données et faire une prédiction. Pour cette raison, cette méthode est également connue sous le nom de méthode du vainqueur et méthode basée sur la mémoire.
k-Nearest Neighbour (kNN) Learning Vector Quantization (LVQ) Self-Organizing Map (SOM)
- #### Regularization Methods
C’est une extension d’autres méthodes (généralement la méthode de régression) qui favorisent des modèles plus simples et plus performants en induction. Je l’énumère ici car elle est populaire et puissante.
Ridge Regression Least Absolute Shrinkage and Selection Operator (LASSO) Elastic Net
- #### Decision Tree Learning
Les méthodes d’arbre de décision sont des méthodes qui construisent un modèle de décision basé sur les valeurs réelles dans les données. Les arbres de décision sont utilisés pour résoudre des problèmes d’inclusion et de régression.
Classification and Regression Tree (CART) Iterative Dichotomiser 3 (ID3) C4.5 Chi-squared Automatic Interaction Detection (CHAID) Decision Stump Random Forest Multivariate Adaptive Regression Splines (MARS) Gradient Boosting Machines (GBM)
- #### Bayesian
La méthode bayésienne est l’application du théorème de Bayes à la résolution de problèmes de classification et de régression.
Naive Bayes Averaged One-Dependence Estimators (AODE) Bayesian Belief Network (BBN)
- #### Kernel Methods
La plus connue des méthodes Kernel est la méthode Support Vector Machines. Cette méthode permet de cartographier les données d’entrée dans une dimension plus élevée, ce qui facilite la modélisation de certains problèmes de classification et de régression.
Support Vector Machines (SVM) Radial Basis Function (RBF) Linear Discriminate Analysis (LDA)
- #### Clustering Methods
Clustering (en anglais: clustering) est un terme qui décrit le problème et la méthode. Les méthodes de clustering sont généralement classées par la façon dont elles sont modélisées. Toutes les méthodes de clustering sont organisées avec une structure de données unifiée, de sorte qu’il y a le plus de points communs dans chaque groupe.
K-Means Expectation Maximisation (EM)
- #### Association Rule Learning
L’apprentissage des règles d’association est une méthode utilisée pour extraire des règles entre les données, grâce auxquelles des liens peuvent être trouvés entre de grandes quantités de données spatiales multidimensionnelles, et ces liens importants peuvent être utilisés par l’organisation.
Apriori algorithm Eclat algorithm
- #### Artificial Neural Networks
Les réseaux de neurones artificiels sont inspirés de la structure et de la fonction des réseaux de neurones biologiques. Ils appartiennent à la catégorie des réseaux de correspondance de modèles et sont souvent utilisés pour des problèmes de régression et de classification, mais ils sont constitués de centaines d’algorithmes et de variantes.
Perceptron Back-Propagation Hopfield Network Self-Organizing Map (SOM) Learning Vector Quantization (LVQ)
- #### Deep Learning
L’approche de l’apprentissage en profondeur est une mise à jour moderne des réseaux de neurones artificiels. Comparée aux réseaux de neurones traditionnels, elle possède un plus grand nombre de structures de réseaux plus complexes, et beaucoup de méthodes sont concernées par l’apprentissage semi-supervisé, un type d’apprentissage dans lequel il y a beaucoup de données, mais peu de données marquées.
Restricted Boltzmann Machine (RBM) Deep Belief Networks (DBN) Convolutional Network Stacked Auto-encoders
- #### Dimensionality Reduction
Dimensionality Reduction, comme la méthode de regroupement, cherche et utilise une structure unifiée dans les données, mais elle utilise moins d’informations pour résumer et décrire les données.
Principal Component Analysis (PCA) Partial Least Squares Regression (PLS) Sammon Mapping Multidimensional Scaling (MDS) Projection Pursuit
- #### Ensemble Methods
Les méthodes d’ensemble sont composées de nombreux petits modèles qui sont entraînés indépendamment, tirent des conclusions indépendantes et finissent par constituer une prédiction globale. Beaucoup de recherches se concentrent sur les modèles utilisés et sur la façon dont ces modèles sont assemblés.
Boosting Bootstrapped Aggregation (Bagging) AdaBoost Stacked Generalization (blending) Gradient Boosting Machines (GBM) Random Forest
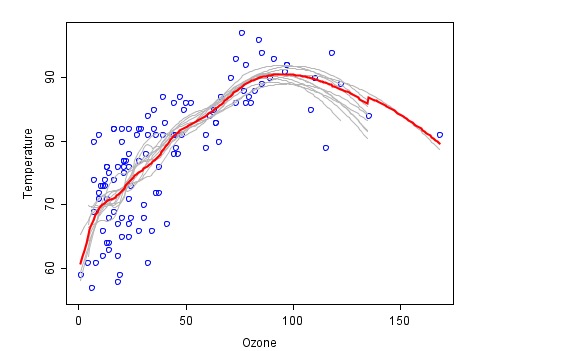
Ceci est un exemple d’appariement avec une méthode de synthèse (en anglais) où chaque code de feu est représenté en gris et la prévision finale de la synthèse finale en rouge.
- #### Autres ressources
Cette visite d’algorithmes d’apprentissage automatique est destinée à vous donner une vue d’ensemble de ce que sont les algorithmes et de certains outils qui les associent.
Voici d’autres ressources, ne les prenez pas trop au sérieux, plus vous en saurez sur les algorithmes, plus vous en aurez de bénéfices, mais il peut être utile d’avoir une connaissance approfondie de certains algorithmes.
- Liste des algorithmes d’apprentissage automatique: c’est une ressource sur le wiki, bien que complète, je pense que la classification n’est pas très bonne.
- Machine Learning Algorithms Category: C’est aussi une ressource sur le wiki, un peu mieux que celle ci-dessus, classée par ordre alphabétique.
- CRAN Task View: Machine Learning & Statistical Learning: Extension du langage R pour les algorithmes d’apprentissage automatique, pour mieux comprendre ce que les autres utilisent.
- Top 10 Algorithms in Data Mining: Cet article publié, et maintenant un livre, contient les algorithmes de data mining les plus populaires. Une autre liste d’algorithmes de base, dont il y en a peu, vous aidera à approfondir votre connaissance.
Le projet a été lancé par le développeur de Python, Dafei.