Trois images pour comprendre l'apprentissage automatique : concepts de base, cinq grandes écoles et neuf algorithmes courants
 0
2390
0
2390
Trois images pour comprendre l’apprentissage automatique : concepts de base, cinq grandes écoles et neuf algorithmes courants
- #### Un aperçu de l’apprentissage automatique

Qu’est-ce que l’apprentissage automatique ?
Les machines apprennent en analysant de grandes quantités de données. Par exemple, elles n’ont pas besoin d’être programmées pour reconnaître des chats ou des visages humains, elles peuvent être entraînées à utiliser des images pour récapituler et reconnaître des cibles spécifiques.
La relation entre l’apprentissage automatique et l’intelligence artificielle
L’apprentissage automatique est une discipline de recherche et d’algorithmes qui consiste à rechercher des modèles dans les données et à les utiliser pour faire des prédictions. L’apprentissage automatique fait partie du domaine de l’intelligence artificielle et est à la croisée des chemins de la découverte de la connaissance et de l’exploration de données.
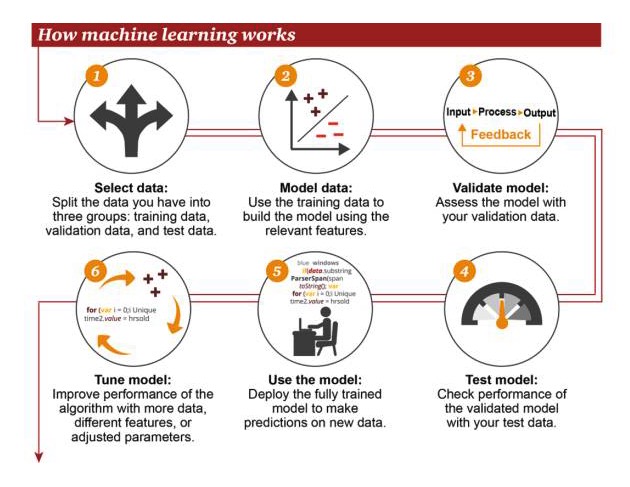
Comment fonctionne l’apprentissage automatique
1 Sélectionnez les données: divisez vos données en trois groupes: données d’entraînement, données de vérification et données de test 2 Données de modèle: utilisation des données de formation pour construire des modèles utilisant des caractéristiques connexes 3 Modèles de validation: utilisez vos données de validation pour accéder à vos modèles 4 Modèles de test: utilisez vos données de test pour vérifier les performances des modèles validés 5 Utiliser des modèles: utiliser des modèles parfaitement formés pour faire des prédictions sur de nouvelles données 6 Modèle d’optimisation: utilisez plus de données, des caractéristiques différentes ou des paramètres modifiés pour améliorer la performance de l’algorithme
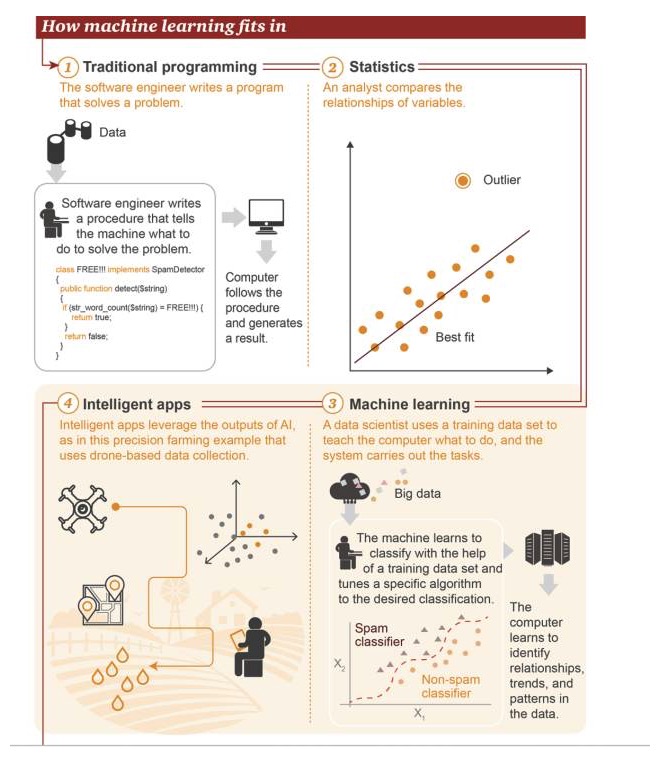
Où est l’apprentissage automatique ?
1 Programme traditionnel: les ingénieurs logiciels écrivent des programmes pour résoudre des problèmes. Il y a d’abord des données→ Pour résoudre un problème, les ingénieurs logiciels écrivent un processus pour dire à la machine ce qu’elle doit faire→ L’ordinateur exécute ce processus, puis produit un résultat 2 Statistique: les analystes comparent les relations entre les variables 3 L’apprentissage automatique: les scientifiques utilisent les ensembles de données de formation pour enseigner à l’ordinateur ce qu’il doit faire, puis le système exécute la tâche. D’abord, il y a le Big Data→ La machine apprend à utiliser les ensembles de formation pour classer, à régler des algorithmes spécifiques pour réaliser la classification cible→ L’ordinateur apprend à reconnaître les relations, les tendances et les modèles dans les données 4 Applications intelligentes: les applications intelligentes utilisent les résultats obtenus par l’intelligence artificielle, comme le montre un exemple d’application de l’agriculture de précision, basée sur les données collectées par les drones

Applications concrètes de l’apprentissage automatique
L’apprentissage automatique a de nombreux scénarios d’utilisation, voici quelques exemples, comment allez-vous l’utiliser ?
Cartographie et modélisation 3D rapide: Pour construire un pont ferroviaire, les scientifiques de données et les experts du domaine de PwC appliquent l’apprentissage automatique aux données collectées par les drones. Cette combinaison permet une surveillance précise et un retour rapide sur la réussite du travail.
Augmentation de l’analyse pour réduire les risques: Pour détecter les transactions internes, PwC combine l’apprentissage automatique et d’autres techniques d’analyse, ce qui permet de développer un profil d’utilisateur plus complet et une meilleure compréhension des comportements suspects complexes.
Objectifs de prédiction des meilleures performances: PwC utilise l’apprentissage automatique et d’autres méthodes d’analyse pour évaluer le potentiel des différents chevaux de course sur le terrain de la Melbourne Cup.
- #### Deux, l’évolution de l’apprentissage automatique

Les différentes “ tribus ” de chercheurs en intelligence artificielle se disputent la suprématie depuis des décennies. Est-ce le moment pour ces tribus de s’unir ? Elles devront peut-être le faire, car la collaboration et la fusion algorithmique sont les seuls moyens de réaliser une véritable intelligence artificielle universelle (AGI).
Les cinq grands groupes
1 Symbolisme: utilisation des symboles, des règles et de la logique pour représenter la connaissance et pour effectuer des raisonnements logiques, les algorithmes préférés sont: les règles et les arbres de décision 2 Bayesian: l’obtention de la probabilité d’un événement pour la déduction de probabilités, l’algorithme préféré est: simple Bayesian ou Markov 3 L’associationnisme: utilise des matrices de probabilité et des neurones pondérés pour identifier et intégrer dynamiquement des modèles, l’algorithme préféré est: les réseaux de neurones 4 L’évolutionnisme: générer des variations, puis en extraire les meilleures pour un objectif spécifique. L’algorithme préféré est: l’algorithme génétique 5 Analogizer: optimiser les fonctions en fonction des contraintes ((aller le plus haut possible, mais en même temps ne pas quitter la route), l’algorithme préféré est:
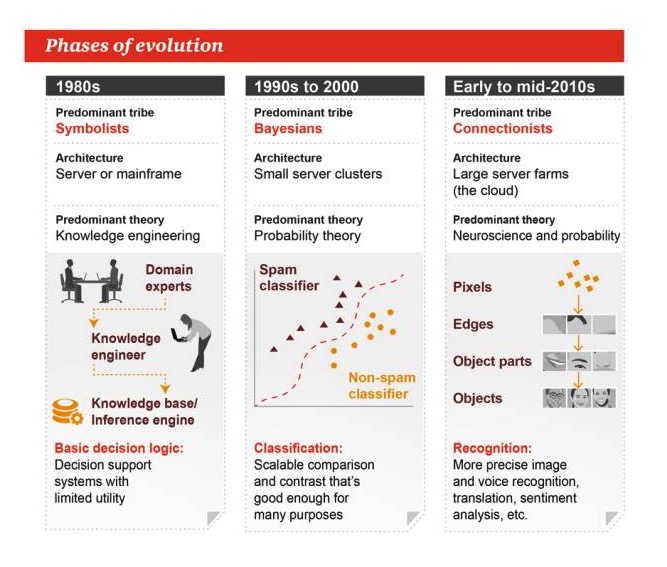
Les étapes de l’évolution
Les années 1980
Genre dominant: le symbolisme Architecture: serveur ou grand écran La théorie dominante: l’ingénierie du savoir Logique de base de la prise de décision: Système d’aide à la décision, utilisation limitée
Les années 1990 à 2000
Genre dominant: Bayes Architecture: un petit groupe de serveurs La théorie dominante est la théorie des probabilités. Classification: comparaison ou comparaison extensible, suffisamment bonne pour de nombreuses tâches
Début et milieu des années 2010
Genre dominant: liéisme L’architecture: une grande ferme de serveurs Les théories dominantes: les neurosciences et les probabilités Reconnaissance: reconnaissance, traduction, analyse des émotions, etc. plus précises des images et des voix
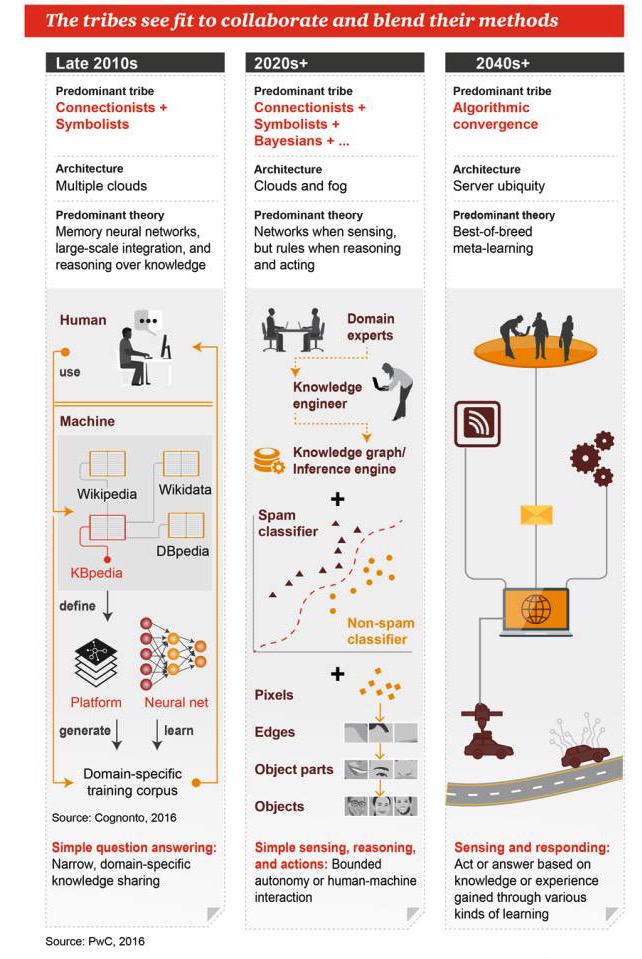
Ces genres ont l’espoir de collaborer et de fusionner leurs méthodes.
Fin des années 2010
Genres dominants: syndicalisme + symbolisme Architecture: beaucoup de nuages Les théories dominantes: les réseaux de mémoire, l’intégration de masse et le raisonnement fondé sur la connaissance Questions et réponses simples: partage de connaissances dans des domaines restreints et spécifiques
Années 2020 et plus
Les deux groupes de pensée ont été influencés par le néo-clérialisme, le symbolisme, le Bayesianisme et le néo-clérialisme. Architecture: le cloud et le cloud computing La théorie dominante: il y a des réseaux pour la perception, des règles pour le raisonnement et le travail Perception, raisonnement et action simples: une automatisation ou une interaction humaine-machine limitée
Les années 2040+
Genres dominants: la fusion des algorithmes Architecture: serveur omniprésent La théorie dominante: le méta-apprentissage de la meilleure combinaison Perception et réponse: action ou réponse basée sur des connaissances ou des expériences acquises par plusieurs modes d’apprentissage
- #### Troisièmement, les algorithmes de l’apprentissage automatique

Quel type d’algorithme d’apprentissage machine devriez-vous utiliser? Cela dépend en grande partie de la nature et de la quantité de données disponibles et de vos objectifs de formation dans chaque cas d’utilisation spécifique. N’utilisez pas les algorithmes les plus complexes, sauf si le résultat vaut la peine de payer des dépenses et des ressources coûteuses.
Arbre de décision: Dans le cadre d’une réponse progressive, une analyse d’arbre de décision typique utilise des variables de stratification ou des nœuds de décision, par exemple, pour classer un utilisateur donné en fiable ou non.
Avantages: Aptitude à évaluer une gamme de caractéristiques, qualités et attributs de personnes, lieux et objets Exemples de scénarios: évaluation de crédit basée sur des règles, prévision des résultats des courses
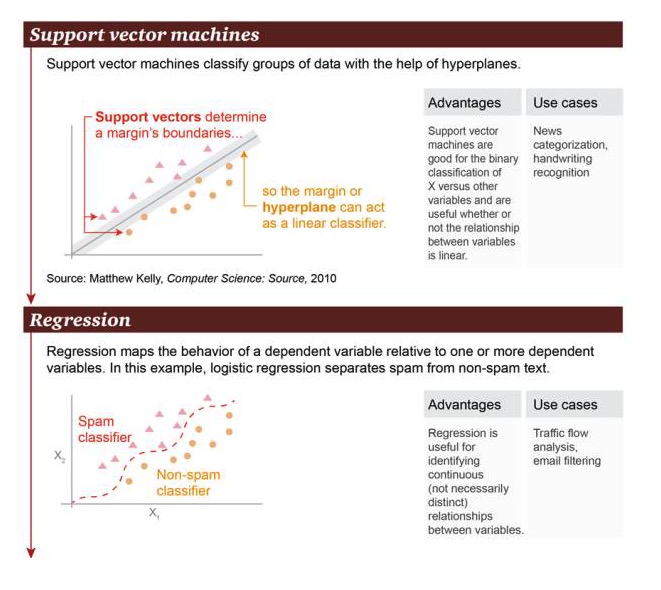
Machine vectorielle de support: basée sur l’hyperplan, la machine vectorielle de support permet de classer les groupes de données.
Avantages: la machine à support de vecteurs est douée pour effectuer des opérations de classification binaire entre la variable X et d’autres variables, que leur relation soit linéaire ou non Les scénarios sont les suivants: classement de l’actualité, reconnaissance de l’écriture.
Regression: la régression permet de tracer une relation d’état entre une variable de causalité et une ou plusieurs variables de causalité. Dans cet exemple, une distinction est faite entre le spam et le non-spam.
Avantages: la régression peut être utilisée pour identifier une relation continue entre les variables, même si cette relation n’est pas très évidente Exemples de scénarios: analyse du trafic routier, filtrage des courriels
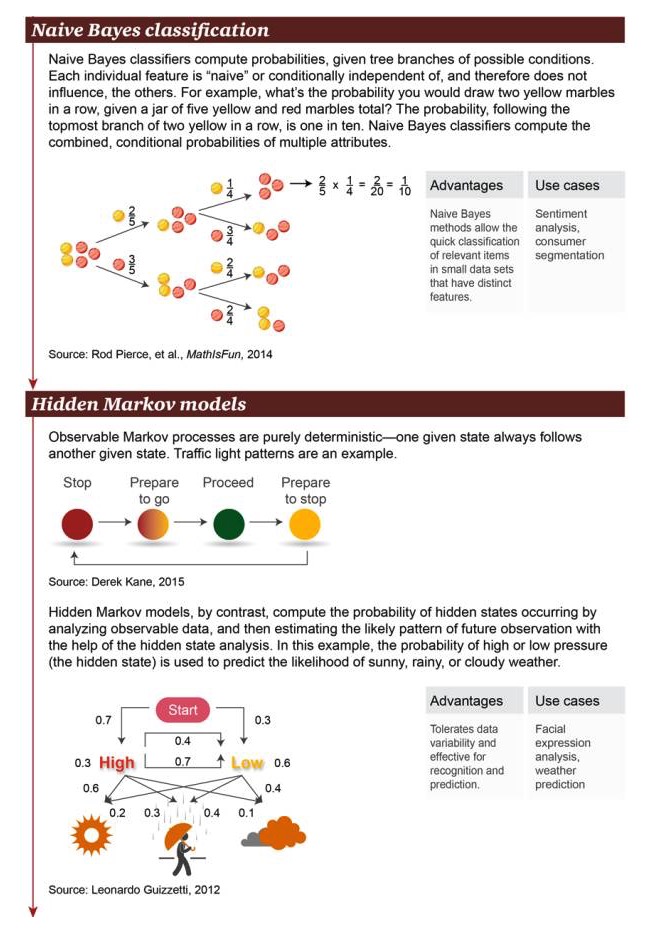
Classification naïve de Bayes: la classification naïve de Bayes est utilisée pour calculer la probabilité de branche d’une condition possible. Chaque caractéristique indépendante est “naïve” ou indépendante des conditions, de sorte qu’elle n’affecte pas d’autres objets. Par exemple, quelle est la probabilité d’obtenir deux petites boules jaunes consécutives dans un panier contenant un total de 5 petites boules jaunes et rouges?
Avantages: Pour les objets apparentés présentant des caractéristiques significatives dans de petits ensembles de données, une méthode Bayesian simple permet une classification rapide Exemples de scénarios: analyse des émotions, catégorisation des consommateurs
Le modèle de Markov caché: un processus de Markov qui montre une certitude absolue qu’un état donné est souvent accompagné d’un autre état. Les feux de signalisation sont un exemple. Au contraire, le modèle de Markov caché calcule l’apparition d’un état caché en analysant les données visibles.
Avantages: la variabilité des données est permise, elle s’applique aux opérations de reconnaissance et de prévision Exemples de scènes: analyse des expressions faciales, prévisions météorologiques
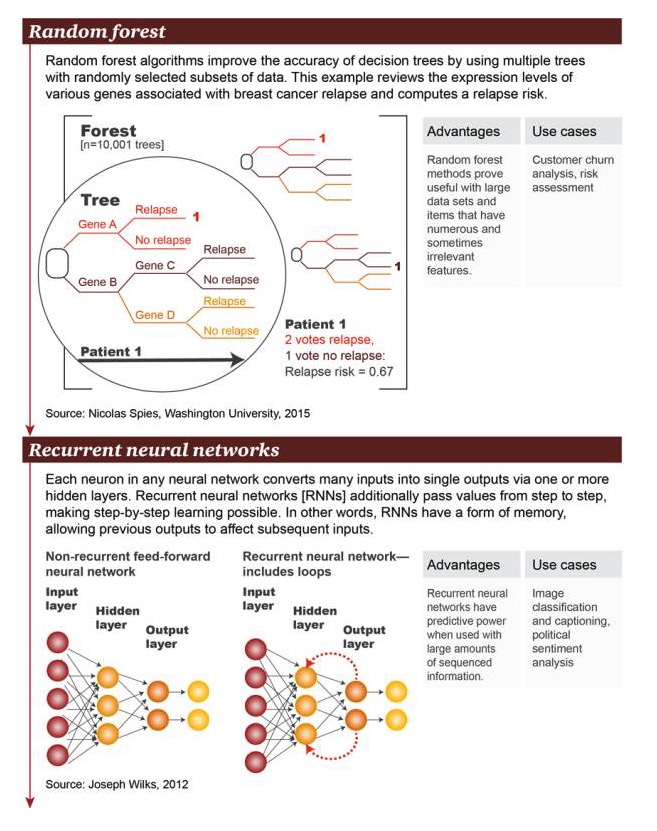
La forêt aléatoire: l’algorithme de la forêt aléatoire améliore la précision de l’arbre de décision en utilisant plusieurs arbres avec des sous-ensembles de données choisis au hasard. L’exemple ci examine un grand nombre de gènes associés à la récidive du cancer du sein au niveau de l’expression génique et calcule le risque de récidive.
Avantages: la méthode de la forêt aléatoire s’est avérée utile pour les grands ensembles de données et la présence d’un grand nombre d’articles (item) avec des caractéristiques parfois non-corrélatives Exemples de scénarios: analyse des pertes d’utilisateurs, évaluation des risques
RNN: Dans un réseau neuronal aléatoire, chaque neurone transforme de nombreuses entrées en sorties individuelles à travers une ou plusieurs couches cachées. Les RNN transmettent des valeurs par couches, permettant ainsi l’apprentissage par couches. En d’autres termes, les RNN possèdent une sorte de mémoire qui permet aux sorties précédentes d’influencer celles qui suivent.
Avantages: les réseaux de neurones circulaires sont prédictifs en présence d’une grande quantité d’informations ordonnées Exemples de scénarios: classement d’images avec ajout de sous-titres, analyse des sentiments politiques

La mémoire longue courte durée (LSTM) et le réseau neuronal à unité récurrente à porte (GRU): les formes antérieures de RNN sont détériorées. Alors que ces premiers réseaux ne permettent que de conserver une petite quantité d’informations antérieures, les réseaux neuronaux récents (LSTM et GRU) ont une mémoire longue et courte durée. En d’autres termes, ces RNN récents ont une meilleure capacité de contrôle de la mémoire, permettant de conserver des valeurs antérieures ou de les réinitialiser lorsque cela est nécessaire pour traiter de nombreuses séries d’étapes, ce qui évite la dégradation finale des valeurs transmises par degré de “dégradation” ou par étape.
Avantages: La mémoire à long terme et les réseaux de neurones à unité circulaire de contrôle de porte présentent les mêmes avantages que les autres réseaux de neurones circulaires, mais sont plus souvent utilisés car ils ont une meilleure capacité de mémoire Exemple de scène: traitement du langage naturel, traduction
Réseau neuronal convolutionnel: La convolution est la fusion de poids provenant de couches ultérieures qui peuvent être utilisées pour marquer les couches de sortie.
Avantages: Les réseaux de neurones enveloppés sont très utiles lorsqu’il y a de très grands ensembles de données, de nombreuses caractéristiques et des tâches de classification complexes Des scénarios comme la reconnaissance d’images, la traduction de texte en voix, la détection de drogues.
- #### Le lien vers le texte original:
http://usblogs.pwc.com/emerging-technology/a-look-at-machine-learning-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-evolution-infographic/
Le projet a été lancé par le gouvernement de la République démocratique du Congo.