Créez un robot de trading Bitcoin qui ne perdra pas d'argent
Auteur:FMZ~Lydia, Créé: 2023-02-01 11:52:21, mis à jour: 2024-12-24 20:25:11
Créez un robot de trading Bitcoin qui ne perdra pas d'argent
Utilisons l'apprentissage par renforcement dans l'IA pour construire un robot de trading de devises numériques.
Dans cet article, nous allons créer et appliquer un numéro de cadre d'apprentissage amélioré pour apprendre à faire un robot de trading Bitcoin.
Merci beaucoup pour le logiciel open source fourni par OpenAI et DeepMind pour les chercheurs en apprentissage profond au cours des dernières années.
La formation AlphaStar:https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
Bien que nous ne créerons rien d'impressionnant, il n'est toujours pas facile de négocier des robots Bitcoin dans les transactions quotidiennes.
Il n'y a pas de valeur dans tout ce qui est trop simple.
Par conséquent, non seulement nous devrions apprendre à négocier nous-mêmes, mais aussi laisser les robots négocier pour nous.
Le plan

Créer un environnement de gym pour notre robot pour effectuer l'apprentissage automatique
Rendre un environnement visuel simple et élégant
Entraînez notre robot à apprendre une stratégie de trading rentable
Si vous n'êtes pas familier avec la façon de créer des environnements de gym à partir de zéro, ou comment simplement rendre la visualisation de ces environnements. Avant de continuer, n'hésitez pas à googler un article de ce genre. Ces deux actions ne seront pas difficiles même pour les programmeurs les plus novices.
Les débuts
Dans ce tutoriel, nous utiliserons le jeu de données Kaggle généré par Zielak. Si vous voulez télécharger le code source, il sera fourni dans mon référentiel Github, avec le fichier de données.csv. Ok, commençons.
Tout d'abord, importons toutes les bibliothèques nécessaires. Assurez-vous d'utiliser pip pour installer les bibliothèques qui vous manquent.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
Ensuite, créons notre classe pour l'environnement. Nous devons passer un numéro de trame de données Panda et un initial_balance optionnel et un lookback_window_size, qui indiqueront le nombre d'étapes de temps passé observées par le robot à chaque étape. Nous par défaut la commission de chaque transaction à 0.075%, c'est-à-dire le taux de change actuel de Bitmex, et par défaut le paramètre de série à faux, ce qui signifie que notre numéro de trame de données sera traversé par des fragments aléatoires par défaut.
Nous appelons également dropna() et reset_index() sur les données, supprimez d'abord la ligne avec la valeur NaN, puis réinitialisez l'index du numéro de trame, parce que nous avons supprimé les données.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
Notre action_space est représenté comme un groupe de 3 options (acheter, vendre ou détenir) ici et un autre groupe de 10 montants (1⁄10, 2⁄10, 3⁄10Lorsque nous choisissons d'acheter, nous allons acheter le montant * self.balance mot de BTC. Pour vendre, nous allons vendre le montant * self.btc_held valeur de BTC. Bien sûr, la tenue ignorera le montant et ne rien faire.
Notre observation_space est défini comme un point flottant continu placé entre 0 et 1, et sa forme est (10, lookback_window_size+1). + 1 est utilisé pour calculer l'étape de temps en cours. Pour chaque étape de temps dans la fenêtre, nous observerons la valeur OHCLV. Notre valeur nette est égale au nombre de BTC que nous achetons ou vendons, et au montant total de dollars que nous dépensons ou recevons sur ces BTC.
Ensuite, nous devons écrire la méthode de réinitialisation pour initialiser l'environnement.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
Ici, nous utilisons self._reset_session et self._next_observation, que nous n'avons pas encore définis.
Séance de négociation
Une partie importante de notre environnement est le concept de sessions de trading. Si nous déployons ce robot en dehors du marché, nous ne pourrons peut-être jamais le faire fonctionner pendant plus de quelques mois à la fois. Pour cette raison, nous limiterons le nombre de trames consécutives dans self.df, qui est le nombre de trames que notre robot peut voir à la fois.
Dans notre méthode de _reset_session, nous réinitialisons d'abord le current_step à 0. Ensuite, nous définirons steps_left sur un nombre aléatoire entre 1 et MAX_TRADING_SESSIONS, que nous définirons en haut du programme.
MAX_TRADING_SESSION = 100000 # ~2 months
Ensuite, si nous voulons traverser le nombre de trames consécutivement, nous devons le définir pour traverser le nombre total de trames, sinon nous définissons frame_start à un point aléatoire dans self.df et créons un nouveau cadre de données nommé active_df, qui est juste une tranche de self.df et il va de frame_start à frame_start + steps_left.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
Un effet secondaire important de traverser le nombre de trames de données dans la tranche aléatoire est que notre robot aura plus de données uniques à utiliser dans l'entraînement à long terme. Par exemple, si nous traversons seulement le nombre de trames de données de manière sérielle (c'est-à-dire de 0 à len(df)), nous n'aurons que autant de points de données uniques que le nombre de trames de données. Notre espace d'observation ne peut utiliser qu'un nombre discret d'états à chaque étape de temps.
Cependant, en traversant les tranches de l'ensemble de données au hasard, nous pouvons créer un ensemble plus significatif de résultats de négociation pour chaque étape de temps dans l'ensemble de données initial, c'est-à-dire la combinaison du comportement de négociation et du comportement des prix vu précédemment pour créer des ensembles de données plus uniques.
Lorsque l'étape de temps après la réinitialisation de l'environnement série est de 10, notre robot fonctionnera toujours dans l'ensemble de données en même temps, et il y a trois options après chaque étape de temps: acheter, vendre ou conserver. Pour chacune des trois options, vous avez besoin d'une autre option: 10%, 20%,... ou 100% du montant de mise en œuvre spécifique. Cela signifie que notre robot peut rencontrer l'un des 10 états de n'importe quel 103, un total de 1030 cas.
Maintenant, revenons à notre environnement de découpe aléatoire. Lorsque l'étape de temps est de 10, notre robot peut être dans n'importe quelle étape de temps len(df) dans le nombre de trames de données. En supposant que le même choix est fait après chaque étape de temps, cela signifie que le robot peut expérimenter l'état unique de n'importe quelle étape de temps len(df) à la 30e puissance dans les mêmes 10 étapes de temps.
Bien que cela puisse apporter un bruit considérable à de grands ensembles de données, je crois que les robots devraient être autorisés à en apprendre davantage à partir de nos données limitées.
Observé à travers les yeux d'un robot
Grâce à une observation visuelle efficace de l'environnement, il est souvent utile de comprendre le type de fonctions que notre robot utilisera.
Observation de l'environnement de visualisation OpenCV
Chaque ligne dans l'image représente une ligne dans notre observation_space. Les quatre premières lignes de lignes rouges avec des fréquences similaires représentent les données OHCL, et les points orange et jaune directement en dessous représentent le volume de trading. La barre bleue fluctuante ci-dessous représente la valeur nette du robot, tandis que la barre plus claire ci-dessous représente la transaction du robot.
Si vous observez attentivement, vous pouvez même faire vous-même une carte de bougies. Sous la barre de volume de trading, il y a une interface de code Morse, affichant l'historique des transactions. Il semble que notre robot devrait être capable d'apprendre suffisamment des données de notre observation_space, alors continuons. Ici, nous définirons la méthode _next_observation, nous échelonnerons les données observées de 0 à 1.
- Il est important d'étendre uniquement les données observées par le robot jusqu'à présent pour éviter les écarts de direction.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
Prenez des mesures
Nous avons établi notre espace d'observation, et maintenant il est temps d'écrire notre fonction d'échelle, puis de prendre l'action programmée du robot. Chaque fois que self.steps_left == 0 pour notre session de trading en cours, nous allons vendre notre BTC et appeler _reset_session(). Sinon, nous allons régler la récompense à la valeur nette actuelle. Si nous manquons de fonds, nous allons régler fait à Vrai.
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
Prendre une action de trading est aussi simple que d'obtenir le prix actuel, de déterminer les actions à exécuter et la quantité à acheter ou à vendre.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
Enfin, selon la même méthode, nous ajouterons la transaction aux transactions personnelles et mettrons à jour notre valeur nette et l'historique de nos comptes.
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
Notre robot peut démarrer un nouvel environnement maintenant, compléter l'environnement progressivement, et prendre des mesures qui affectent l'environnement.
Regardez notre commerce de robots
Notre méthode de rendu peut être aussi simple que d'appeler print (self.net_word), mais ce n'est pas assez intéressant. au lieu de cela, nous allons dessiner un simple graphique de bougie, qui contient un graphique séparé de la colonne de volume de trading et notre valeur nette.
Nous allons obtenir le code dans StockTrackingGraph.py de mon dernier article et le redessiner pour l'adapter à l'environnement Bitcoin. Vous pouvez obtenir le code de mon Github.
La première modification que nous devons faire est de mettre à jour self.df [
from datetime import datetime
Tout d'abord, importez la bibliothèque de l'heure de la date, puis nous utiliserons la méthode utcfromtimestamp pour obtenir la chaîne UTC de chaque horodatage et strftime afin qu'elle soit formatée comme une chaîne: format Y-m-d H:M.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
Enfin, nous allons changer self. df[
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
On peut regarder nos robots échanger des bitcoins maintenant.
Visualisez notre robot négocier avec Matplotlib
L'étiquette fantôme verte représente l'achat de BTC, et l'étiquette fantôme rouge représente la vente. L'étiquette blanche dans le coin supérieur droit est la valeur nette actuelle du robot, et l'étiquette dans le coin inférieur droit est le prix actuel du Bitcoin. C'est simple et élégant. Maintenant, il est temps de former nos robots et de voir combien d'argent nous pouvons gagner!
Temps de formation
L'une des critiques que j'ai reçues dans l'article précédent était le manque de validation croisée et l'incapacité de diviser les données en ensembles de formation et en ensembles de tests. Le but de cela est de tester l'exactitude du modèle final sur de nouvelles données qui n'ont jamais été vues auparavant. Bien que ce ne soit pas le centre de cet article, c'est vraiment très important. Parce que nous utilisons des données de séries chronologiques, nous n'avons pas beaucoup de choix dans la validation croisée.
Par exemple, une forme commune de validation croisée est appelée validation k-fold. Dans cette validation, vous divisez les données en k groupes égaux, un par un, individuellement, en tant que groupe de test et utilisez le reste des données en tant que groupe de formation. Cependant, les données de séries chronologiques sont très dépendantes du temps, ce qui signifie que les données ultérieures sont très dépendantes des données précédentes. Donc, k-fold ne fonctionnera pas, car notre robot apprendra des données futures avant de trader, ce qui est un avantage injuste.
Lorsqu'il est appliqué aux données de séries temporelles, le même défaut s'applique à la plupart des autres stratégies de validation croisée. Par conséquent, nous n'avons besoin que d'utiliser une partie du numéro de trame de données complète comme ensemble d'entraînement du numéro de trame à certains indices arbitraires, et d'utiliser le reste des données comme ensemble de test.
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
Ensuite, puisque notre environnement est configuré pour gérer un seul nombre de trames de données, nous allons créer deux environnements, un pour les données d'entraînement et un pour les données de test.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
Maintenant, former notre modèle est aussi simple que de créer un robot en utilisant notre environnement et appeler model.learn.
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
Ici, nous utilisons des plaques tensorielles, de sorte que nous pouvons visualiser facilement nos diagrammes de flux tensoriels et voir quelques indicateurs quantitatifs sur notre robot.
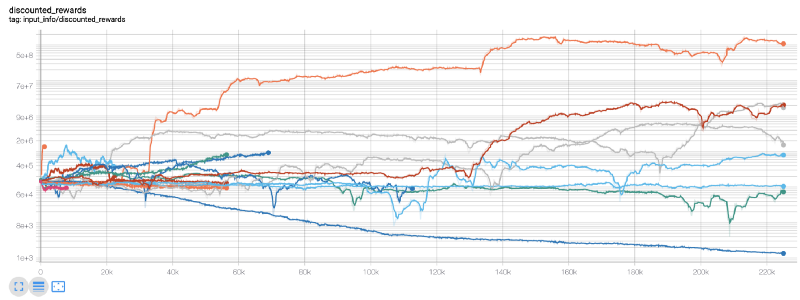
Wow, il semble que notre robot soit très rentable! Notre meilleur robot peut même atteindre 1000 fois l'équilibre en 200 000 pas, et le reste augmentera au moins 30 fois en moyenne!
À ce moment-là, j'ai réalisé qu'il y avait une erreur dans l'environnement... après avoir corrigé le bug, voici le nouveau tableau de récompense:
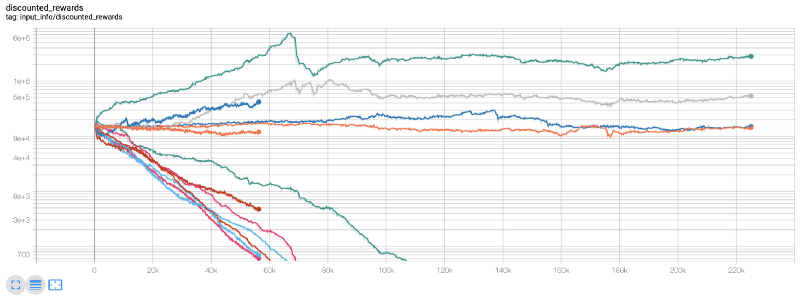
Comme vous pouvez le voir, certains de nos robots se portent bien, tandis que d'autres font faillite. Cependant, les robots avec de bonnes performances peuvent atteindre 10 fois ou même 60 fois le solde initial au maximum. Je dois admettre que toutes les machines rentables sont formées et testées sans commission, il est donc irréaliste pour nos robots de faire de l'argent réel. Mais au moins, nous avons trouvé le moyen!
Testons nos robots dans l'environnement de test (en utilisant de nouvelles données qu'ils n'ont jamais vues auparavant) pour voir comment ils se comporteront.
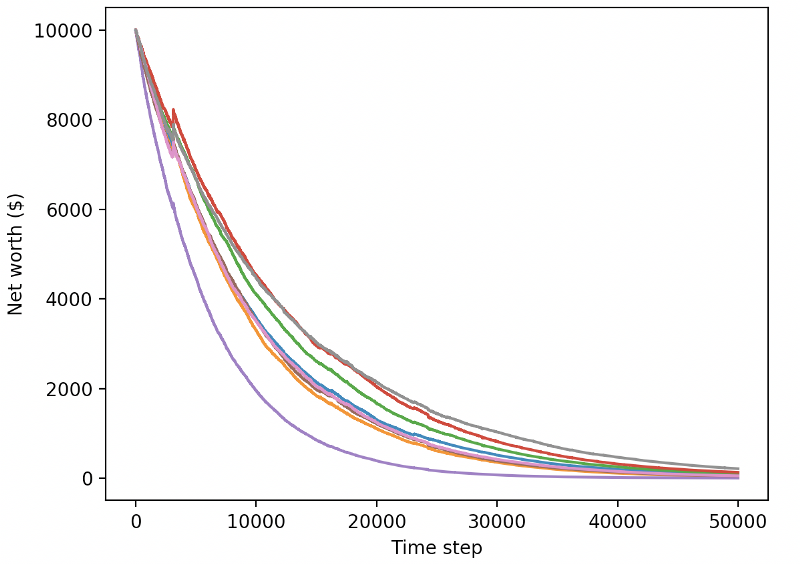
Nos robots bien entraînés vont faire faillite en échangeant de nouvelles données de test.
Il est évident que nous avons encore beaucoup de travail à faire. En basculant simplement les modèles pour utiliser A2C avec une base stable au lieu du robot PPO2 actuel, nous pouvons améliorer considérablement notre performance sur cet ensemble de données. Enfin, selon la suggestion de Sean O
reward = self.net_worth - prev_net_worth
Ces deux changements à eux seuls peuvent améliorer considérablement les performances de l'ensemble de données de test, et comme vous pouvez le voir ci-dessous, nous avons finalement pu profiter de nouvelles données qui n'étaient pas disponibles dans l'ensemble de formation.
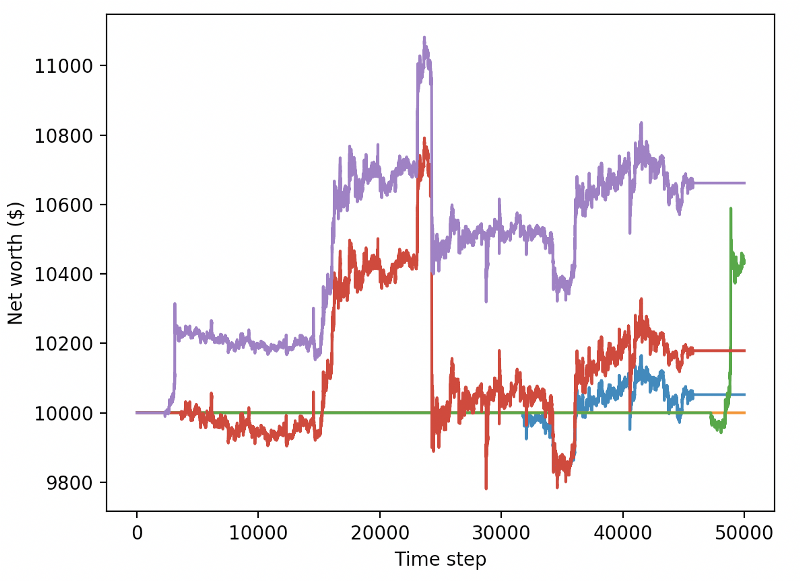
Mais nous pouvons faire mieux. Pour améliorer ces résultats, nous devons optimiser nos super paramètres et former nos robots plus longtemps. Il est temps pour le GPU de commencer à travailler et à tirer sur tous les cylindres!
Jusqu'à présent, cet article a été un peu long, et nous avons encore beaucoup de détails à considérer, donc nous prévoyons de prendre une pause ici.
Conclusion
Dans cet article, nous commençons à utiliser l'apprentissage par renforcement pour créer un robot de trading Bitcoin rentable à partir de zéro.
Créez un environnement de trading Bitcoin à partir de zéro en utilisant le gymnase d'OpenAI.
Utilisez Matplotlib pour construire la visualisation de l'environnement.
Utilisez une simple validation croisée pour entraîner et tester notre robot.
Ajustez légèrement nos robots pour réaliser des profits.
Bien que notre robot de trading n'ait pas été aussi rentable que nous l'avions espéré, nous nous dirigeons déjà dans la bonne direction. La prochaine fois, nous nous assurerons que nos robots peuvent toujours battre le marché. Nous verrons comment nos robots de trading traitent les données en temps réel. Veuillez continuer à suivre mon prochain article et Viva Bitcoin!
- Pratiques quantitatives des échanges DEX (2) -- Guide de l'utilisateur des hyperliquides
- Expérience de la quantification sur les échanges DEX (2) -- Guide d'utilisation de Hyperliquid
- Pratique quantitative des échanges DEX (1) -- Guide de l'utilisateur dYdX v4
- Introduction à l'arbitrage au retard de plomb dans les crypto-monnaies (3)
- Pratiques de quantification de l'échange DEX ((1) -- dYdX v4 Guide d'utilisation
- Introduction à la suite de Lead-Lag dans les monnaies numériques (3)
- Introduction à l'arbitrage au retard de plomb dans les crypto-monnaies (2)
- Introduction à la suite de Lead-Lag dans les monnaies numériques (2)
- Discussion sur la réception de signaux externes de la plateforme FMZ: une solution complète pour la réception de signaux avec un service Http intégré dans la stratégie
- Exploration de la réception de signaux externes sur la plateforme FMZ: stratégie intégrée pour la réception de signaux sur le service HTTP
- Introduction à l'arbitrage au retard de plomb dans les crypto-monnaies (1)
- Pour que les stratégies s'exécutent en parallèle, ajouter une prise en charge multi-threads au niveau inférieur du système pour les stratégies JavaScript.
- Si vous ne savez pas écrire une stratégie dans un langage aussi facile à apprendre et à utiliser...
- Les bénéfices attendus des transactions à haute fréquence
- On peut faire du commerce quantitatif sans code?
- " Obtenez la meilleure offre " analyse de la vulnérabilité dans l'échange
- 5.6 Construisez la pensée de probabilité pour améliorer votre modèle de trading
- Uniswap V3 sur FMZ avec 200 lignes de code
- Lorsque FMZ rencontre ChatGPT, une tentative d'utiliser l'IA pour aider à apprendre le trading quantitatif
- 9 règles de trading permettent à un trader de gagner 46 000 $ sur 1 000 $ en moins d'un an.
- De la négociation quantitative à la gestion d'actifs - Développement de la stratégie CTA pour un rendement absolu
- Le secret de la survie: 19 professionnels partagent leurs conseils sur le commerce de la monnaie numérique
- Utilisez JavaScript pour mettre en œuvre l'exécution simultanée de la stratégie quantitative - encapsuler la fonction Go
- L'application du démon de Shannon dans la monnaie numérique
- Uniswap V3 est accessible sur FMZ avec 200 lignes de code.
- Principe et élaboration du modèle de stop-loss
- Tycoon révèle le trading algorithmique: la plateforme FMZ Quant est une stratégie de fabricant de marché
- Trois modèles potentiels dans le commerce quantitatif
- Système de négociation intraday en points pivots
- 6 stratégies et pratiques simples pour les débutants dans le commerce quantitatif de monnaie numérique
- Cadre stratégique de la fourchette réelle moyenne