प्रोग्रामेटिक व्यापारियों के लिए एक शक्तिशाली उपकरणः औसत और भिन्नता की गणना के लिए क्रमिक अद्यतन एल्गोरिथ्म
लेखक:FMZ~Lydia, बनाया गयाः 2023-11-09 15:00:05, अद्यतनः 2024-11-08 09:15:23
परिचय
प्रोग्रामेटिक ट्रेडिंग में, अक्सर औसत और विचलन की गणना करना आवश्यक होता है, जैसे कि चलती औसत और अस्थिरता संकेतकों की गणना करना। जब हमें उच्च आवृत्ति और दीर्घकालिक गणना की आवश्यकता होती है, तो ऐतिहासिक डेटा को लंबे समय तक बनाए रखना आवश्यक होता है, जो अनावश्यक और संसाधन-खपत दोनों है। यह लेख भारित औसत और विचलन की गणना के लिए एक ऑनलाइन अद्यतन एल्गोरिथ्म पेश करता है, जो वास्तविक समय डेटा स्ट्रीम को संसाधित करने और गतिशील रूप से समायोजित करने के लिए विशेष रूप से महत्वपूर्ण है। व्यापारियों को जल्दी से तैनात करने और वास्तविक ट्रेडिंग में एल्गोरिथ्म को लागू करने में मदद करने के लिए लेख में संबंधित पायथन कोड कार्यान्वयन भी प्रदान किया गया है।
सरल औसत और भिन्नता
यदि हम उपयोग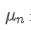 nth डेटा बिंदु के औसत मूल्य का प्रतिनिधित्व करने के लिए, यह मानते हुए कि हम पहले से ही n-1 डेटा बिंदुओं / अपलोड / संपत्ति / 28e28ae0beba5e8a810a6.png का औसत गणना की है, अब हम एक नया डेटा बिंदु / अपलोड / संपत्ति / 28d4723cf4cab1cf78f50.png प्राप्त करते हैं। हम नए औसत संख्या की गणना करना चाहते हैंनिम्नलिखित एक विस्तृत व्युत्पन्न है।
nth डेटा बिंदु के औसत मूल्य का प्रतिनिधित्व करने के लिए, यह मानते हुए कि हम पहले से ही n-1 डेटा बिंदुओं / अपलोड / संपत्ति / 28e28ae0beba5e8a810a6.png का औसत गणना की है, अब हम एक नया डेटा बिंदु / अपलोड / संपत्ति / 28d4723cf4cab1cf78f50.png प्राप्त करते हैं। हम नए औसत संख्या की गणना करना चाहते हैंनिम्नलिखित एक विस्तृत व्युत्पन्न है।
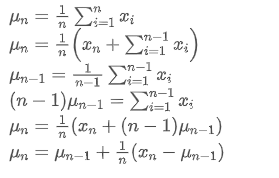
भिन्नता अद्यतन प्रक्रिया को निम्नलिखित चरणों में विभाजित किया जा सकता हैः
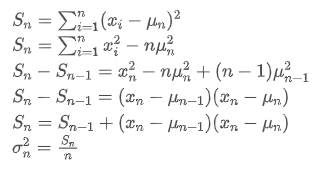
जैसा कि उपरोक्त दो सूत्रों से देखा जा सकता है, यह प्रक्रिया हमें प्रत्येक नए डेटा बिंदु प्राप्त करने पर नए औसत और विचलन को अपडेट करने की अनुमति देती है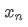 केवल पिछले डेटा के औसत और विचलन को बनाए रखते हुए, ऐतिहासिक डेटा को सहेजने के बिना, गणनाओं को अधिक कुशल बनाते हुए। हालांकि, समस्या यह है कि हम इस तरह से क्या गणना करते हैं सभी नमूनों का औसत और विचलन है, जबकि वास्तविक रणनीतियों में, हमें एक निश्चित निश्चित अवधि पर विचार करने की आवश्यकता है। उपरोक्त औसत अद्यतन का अवलोकन करने से पता चलता है कि नए डेटा और पिछले औसत के बीच विचलन एक अनुपात से गुणा होता है। यदि यह अनुपात तय है, तो यह घातीय रूप से भारित औसत की ओर ले जाएगा, जिस पर हम आगे चर्चा करेंगे।
केवल पिछले डेटा के औसत और विचलन को बनाए रखते हुए, ऐतिहासिक डेटा को सहेजने के बिना, गणनाओं को अधिक कुशल बनाते हुए। हालांकि, समस्या यह है कि हम इस तरह से क्या गणना करते हैं सभी नमूनों का औसत और विचलन है, जबकि वास्तविक रणनीतियों में, हमें एक निश्चित निश्चित अवधि पर विचार करने की आवश्यकता है। उपरोक्त औसत अद्यतन का अवलोकन करने से पता चलता है कि नए डेटा और पिछले औसत के बीच विचलन एक अनुपात से गुणा होता है। यदि यह अनुपात तय है, तो यह घातीय रूप से भारित औसत की ओर ले जाएगा, जिस पर हम आगे चर्चा करेंगे।
एक्सपोनेंशियली भारित औसत
घातीय भारित औसत को निम्नलिखित पुनरावर्ती संबंध द्वारा परिभाषित किया जा सकता है:
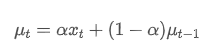
उनमें से,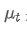 समय बिंदु t पर घातीय भारित औसत है,
समय बिंदु t पर घातीय भारित औसत है,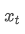 समय बिंदु t पर अवलोकन मूल्य है, α वजन कारक है, और
समय बिंदु t पर अवलोकन मूल्य है, α वजन कारक है, और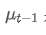 पिछले समय बिंदु का घातीय भारित औसत है।
पिछले समय बिंदु का घातीय भारित औसत है।
घातीय भारित विचलन
भिन्नता के संबंध में, हमें प्रत्येक समय बिंदु पर वर्ग विचलन के घातीय भारित औसत की गणना करने की आवश्यकता है। यह निम्नलिखित पुनरावर्ती संबंध के माध्यम से प्राप्त किया जा सकता हैः
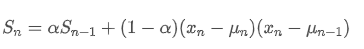
उनमें से,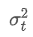 समय बिंदु t पर घातीय भारित विचलन है, और
समय बिंदु t पर घातीय भारित विचलन है, और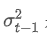 पिछले समय बिंदु का घातीय भारित विचलन है।
पिछले समय बिंदु का घातीय भारित विचलन है।
घातीय भारित औसत और भिन्नता का अवलोकन करें, उनके वृद्धिशील अद्यतन सहज हैं, पिछले मूल्यों का एक हिस्सा बनाए रखते हैं और नए परिवर्तन जोड़ते हैं। विशिष्ट व्युत्पन्न प्रक्रिया का संदर्भ इस पेपर में दिया जा सकता हैःhttps://fanf2.user.srcf.net/hermes/doc/antiforgery/stats.pdf
एसएमए और ईएमए
एसएमए (जिसे अंकगणितीय औसत भी कहा जाता है) और ईएमए दो सामान्य सांख्यिकीय उपाय हैं, जिनमें से प्रत्येक की अलग-अलग विशेषताएं और उपयोग हैं। पहला प्रत्येक अवलोकन को समान वजन देता है, जो डेटा सेट की केंद्रीय स्थिति को दर्शाता है। दूसरा एक पुनरावर्ती गणना विधि है जो अधिक हालिया अवलोकनों को अधिक वजन देता है। प्रत्येक अवलोकन के लिए वर्तमान समय से दूरी बढ़ने के साथ वजन घातीय रूप से कम हो जाते हैं।
- वजन का वितरण: एसएमए प्रत्येक डेटा बिंदु को समान भार देता है, जबकि ईएमए सबसे हाल के डेटा बिंदुओं को अधिक भार देता है।
- नई जानकारी के प्रति संवेदनशीलता: एसएमए नए जोड़े गए आंकड़ों के प्रति पर्याप्त संवेदनशील नहीं है, क्योंकि इसमें सभी डेटा बिंदुओं की पुनः गणना शामिल है। दूसरी ओर, ईएमए नवीनतम आंकड़ों में परिवर्तन को अधिक तेजी से प्रतिबिंबित कर सकता है।
- कम्प्यूटेशनल जटिलता: एसएमए की गणना अपेक्षाकृत सरल है, लेकिन जैसे-जैसे डेटा बिंदुओं की संख्या बढ़ती है, वैसे ही गणना लागत भी बढ़ जाती है। ईएमए की गणना अधिक जटिल है, लेकिन इसकी पुनरावर्ती प्रकृति के कारण, यह निरंतर डेटा स्ट्रीम को अधिक कुशलता से संभाल सकती है।
ईएमए और एसएमए के बीच अनुमानित रूपांतरण विधि
यद्यपि एसएमए और ईएमए वैचारिक रूप से भिन्न हैं, हम एक उपयुक्त α मान चुनकर एक विशिष्ट संख्या में अवलोकन वाले एसएमए के लिए ईएमए को अनुमानित बना सकते हैं। इस अनुमानित संबंध को प्रभावी नमूना आकार द्वारा वर्णित किया जा सकता है, जो ईएमए में वजन कारक α का एक कार्य है।
एसएमए एक निश्चित समय खिड़की के भीतर सभी कीमतों का अंकगणितीय औसत है। एक समय खिड़की एन के लिए, एसएमए का केंद्र बिंदु (यानी वह स्थिति जहां औसत संख्या स्थित है) को माना जा सकता हैः
एसएमए का केंद्र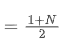
ईएमए एक प्रकार का भारित औसत है जहां सबसे हाल के डेटा बिंदुओं का अधिक वजन होता है। ईएमए का वजन समय के साथ घातीय रूप से घटता है। ईएमए का केंद्र बिंदु निम्नलिखित श्रृंखलाओं को जोड़कर प्राप्त किया जा सकता हैः
ईएमए का केंद्र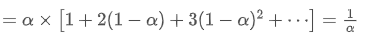
जब हम मान लेते हैं कि एसएमए और ईएमए में एक ही सेंट्रोइड है, तो हम प्राप्त कर सकते हैंः
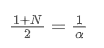
इस समीकरण को हल करने के लिए, हम α और N के बीच संबंध प्राप्त कर सकते हैं।
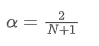
इसका अर्थ है कि N दिनों के दिए गए एसएमए के लिए,
विभिन्न अद्यतन आवृत्तियों के साथ ईएमए का रूपांतरण
मान लीजिये हमारे पास एक ईएमए है जो हर सेकंड में अपडेट होता है, /upload/asset/28da19ef219cae323a32f.png के वजन कारक के साथ। इसका मतलब है कि हर सेकंड में, नया डेटा बिंदु /upload/asset/28da19ef219cae323a32f.png के वजन के साथ ईएमए में जोड़ा जाएगा, जबकि पुराने डेटा बिंदुओं के प्रभाव को /upload/asset/28cfb008ac438a12e1127.png से गुणा किया जाएगा।
यदि हम अद्यतन आवृत्ति को बदलते हैं, जैसे कि हर f सेकंड में एक बार अद्यतन करना, तो हम एक नया वजन कारक / अपलोड / परिसंपत्ति / 28d2d28762e349a03c531.png ढूंढना चाहते हैं, ताकि f सेकंड के भीतर डेटा बिंदुओं का समग्र प्रभाव हर सेकंड में अद्यतन होने पर समान हो।
f सेकंड के भीतर, यदि कोई अद्यतन नहीं किया जाता है, तो पुराने डेटा बिंदुओं का प्रभाव लगातार f बार गिर जाएगा, प्रत्येक बार / अपलोड/संपत्ति/28e50eb9c37d5626d6691.png से गुणा किया जाएगा। इसलिए, f सेकंड के बाद कुल क्षय कारक / अपलोड/संपत्ति/28e296f97d8c8344a2ee6.png है।
प्रत्येक f सेकंड में अद्यतन ईएमए के लिए एक अद्यतन अवधि के भीतर प्रत्येक सेकंड में अद्यतन ईएमए के रूप में एक ही क्षय प्रभाव है बनाने के लिए, हम एक अद्यतन अवधि के भीतर क्षय कारक के बराबर f सेकंड के बाद कुल क्षय कारक सेटः
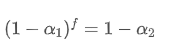
इस समीकरण को हल करते हुए, हम नए वजन कारकों प्राप्त करते हैं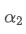
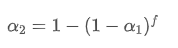
यह सूत्र नए भार कारक /अपलोड/संपत्ति/28d2d28762e349a03c531.png का अनुमानित मूल्य प्रदान करता है, जो अद्यतन आवृत्ति में परिवर्तन होने पर ईएमए चिकनाई प्रभाव को अपरिवर्तित रखता है। उदाहरण के लिएः जब हम औसत मूल्य की गणना करते हैं एक मूल्य के साथ 0.001 और इसे हर 10 सेकंड में अद्यतन, अगर यह हर सेकंड में एक अद्यतन करने के लिए बदला जाता है, समकक्ष मूल्यलगभग 0.01 होगा।
एक मूल्य के साथ 0.001 और इसे हर 10 सेकंड में अद्यतन, अगर यह हर सेकंड में एक अद्यतन करने के लिए बदला जाता है, समकक्ष मूल्यलगभग 0.01 होगा।
पायथन कोड का कार्यान्वयन
class ExponentialWeightedStats:
def __init__(self, alpha):
self.alpha = alpha
self.mu = 0
self.S = 0
self.initialized = False
def update(self, x):
if not self.initialized:
self.mu = x
self.S = 0
self.initialized = True
else:
temp = x - self.mu
new_mu = self.mu + self.alpha * temp
self.S = self.alpha * self.S + (1 - self.alpha) * temp * (x - self.mu)
self.mu = new_mu
@property
def mean(self):
return self.mu
@property
def variance(self):
return self.S
# Usage example
alpha = 0.05 # Weight factor
stats = ExponentialWeightedStats(alpha)
data_stream = [] # Data stream
for data_point in data_stream:
stats.update(data_point)
सारांश
उच्च आवृत्ति प्रोग्रामेटिक ट्रेडिंग में, वास्तविक समय के डेटा की तेजी से प्रसंस्करण महत्वपूर्ण है। कंप्यूटेशनल दक्षता में सुधार और संसाधन खपत को कम करने के लिए, इस लेख में डेटा स्ट्रीम के भारित औसत और विचलन की निरंतर गणना के लिए एक ऑनलाइन अपडेट एल्गोरिथ्म पेश किया गया है। वास्तविक समय के क्रमिक अपडेट का उपयोग विभिन्न सांख्यिकीय डेटा और संकेतक गणनाओं के लिए भी किया जा सकता है, जैसे कि दो परिसंपत्ति की कीमतों के बीच संबंध, रैखिक फिटिंग, आदि, जिसमें बड़ी क्षमता है। क्रमिक अद्यतन डेटा को एक संकेत प्रणाली के रूप में मानता है, जो निश्चित अवधि की गणना की तुलना में सोच में एक विकास है। यदि आपकी रणनीति में अभी भी ऐसे भाग शामिल हैं जो ऐतिहासिक डेटा का उपयोग करके गणना करते हैं, तो इसे इस दृष्टिकोण के अनुसार बदलने पर विचार करेंः केवल सिस्टम स्थिति के अनुमानों को रिकॉर्ड करें और नए डेटा आने पर सिस्टम स्थिति को अपडेट करें; इस चक्र को आगे बढ़ाते हुए दोहराएं।
- मात्रात्मक व्यापार में कुशल समूह नियंत्रण प्रबंधन के लिए एफएमजेड के विस्तारित एपीआई का उपयोग करने के फायदे
- मुद्रा के स्थायी अनुबंधों पर सूचीबद्ध होने के बाद मूल्य प्रदर्शन
- एफएमजेड के विस्तारित एपीआई का उपयोग करके परिमाणित लेनदेन में लाभ के लिए कुशल समूह नियंत्रण प्रबंधन
- मुद्राओं के ऑनलाइन स्थायी अनुबंध के बाद कीमतों का प्रदर्शन
- मुद्राओं और बिटकॉइन के उदय और पतन के बीच संबंध
- मुद्राओं के गिरने और बिटकॉइन के बीच संबंध
- केंद्रीकृत एक्सचेंजों में ऑर्डर बुक के संतुलन पर संक्षिप्त चर्चा
- जोखिम और रिटर्न का मापन - मार्कोविट्ज़ सिद्धांत का परिचय
- केंद्रीय एक्सचेंजों के ऑर्डर बुक संतुलन पर चर्चा
- जोखिम और रिटर्न को मापने के लिए पोमा कोविच का सिद्धांत
- प्रोग्रामेटिक व्यापारियों के लिए लाभः वृद्धिशील अद्यतन एल्गोरिथ्म औसत और अंतर की गणना करता है
- बाजार शोर का निर्माण और अनुप्रयोग
- पीएसवाई कारक उन्नयन और परिवर्तन
- उच्च आवृत्ति व्यापार रणनीति विश्लेषण - पेनी जंप
- वैकल्पिक व्यापारिक विचार--के-लाइन क्षेत्र व्यापारिक रणनीति
- बाजार के शोर का निर्माण और अनुप्रयोग
- PSY (मानसिक रेखा) कारक उन्नयन और परिवर्तन
- उच्च आवृत्ति ट्रेडिंग रणनीति विश्लेषण - पेनी जंप
- स्थिति जोखिम को कैसे मापें - VaR पद्धति का परिचय
- वैकल्पिक व्यापार विचार - के लाइन क्षेत्र व्यापार रणनीति