मशीन लर्निंग की तीन प्रमुख श्रेणियों और छह प्रमुख एल्गोरिदम के फायदे और नुकसान की पूरी व्याख्या
 0
3329
0
3329
मशीन लर्निंग की तीन प्रमुख श्रेणियों और छह प्रमुख एल्गोरिदम के फायदे और नुकसान की पूरी व्याख्या
मशीन सीखने में, लक्ष्य या तो पूर्वानुमान (prediction) या क्लस्टरिंग (clustering) है। इस लेख में मुख्य रूप से भविष्यवाणी पर ध्यान केंद्रित किया गया है। पूर्वानुमान एक इनपुट चर के एक सेट से आउटपुट चर के मूल्य का अनुमान लगाने की प्रक्रिया है। उदाहरण के लिए, एक घर के बारे में विशेषताओं का एक सेट प्राप्त करके, हम इसकी बिक्री मूल्य की भविष्यवाणी कर सकते हैं। भविष्यवाणी प्रश्नों को दो श्रेणियों में विभाजित किया जा सकता हैः अब हम मशीन सीखने में सबसे अधिक उपयोग किए जाने वाले एल्गोरिदम पर एक नज़र डालते हैं। हम इन एल्गोरिदम को तीन श्रेणियों में विभाजित करते हैंः रैखिक मॉडल, पेड़-आधारित मॉडल और तंत्रिका नेटवर्क।
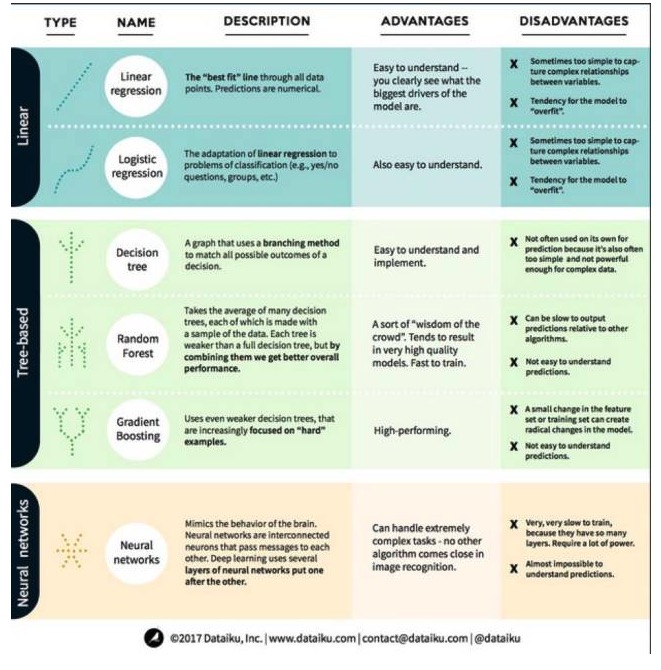
एक, रैखिक मॉडल एल्गोरिदम: रैखिक मॉडल एक सरल सूत्र का उपयोग करता है जो डेटा बिंदुओं के एक सेट के माध्यम से सबसे अच्छी तरह से मेल खाने वाली पंक्तियों को ढूंढता है। यह विधि 200 से अधिक वर्षों से चली आ रही है और यह सांख्यिकी और मशीन सीखने के क्षेत्र में व्यापक रूप से उपयोग की जाती है। इसकी सादगी के कारण, यह सांख्यिकी के लिए उपयोगी है। आप जो चर की भविष्यवाणी करना चाहते हैं (कारण चर) को आपके द्वारा ज्ञात चर (कारण चर) के समीकरण के रूप में दर्शाया गया है, इसलिए भविष्यवाणी केवल एक समस्या है जो इनपुट से आया है, और फिर समीकरण के उत्तर की गणना करें।
- #### 1. रैखिक प्रतिगमन
रैखिक प्रतिगमन, या अधिक सटीक रूप से कहा जाता है कि सबसे कम दो गुना प्रतिगमन, रैखिक मॉडल का सबसे मानक रूप है। प्रतिगमन की समस्या के लिए, रैखिक प्रतिगमन सबसे सरल रैखिक मॉडल है। इसका नुकसान यह है कि मॉडल ओवरफैट करने के लिए आसान है, अर्थात, मॉडल को नए डेटा के लिए प्रचार करने की क्षमता के बलिदान पर पूरी तरह से प्रशिक्षित डेटा के लिए अनुकूलित किया जाता है। इसलिए, मशीन सीखने में रैखिक प्रतिगमन (और हम इसके बाद के बारे में बात करेंगे) आमतौर पर सामान्यीकृत है, जिसका अर्थ है कि मॉडल को ओवरफैट करने से रोकने के लिए कुछ दंड हैं।
रैखिक मॉडल की एक और कमी यह है कि वे बहुत सरल हैं, इसलिए जब इनपुट चर स्वतंत्र नहीं होते हैं तो वे अधिक जटिल व्यवहार की आसानी से भविष्यवाणी नहीं कर सकते हैं।
- #### 2. तार्किक वापसी
लॉजिकल रिग्रेशन एक वर्गीकरण समस्या के लिए रैखिक रिग्रेशन का एक अनुकूलन है। लॉजिकल रिग्रेशन के नुकसान रैखिक रिग्रेशन के समान हैं। लॉजिकल फंक्शन वर्गीकरण समस्या के लिए बहुत अच्छा है क्योंकि यह थ्रेड मूल्य प्रभाव पेश करता है।
2. ट्री मॉडल एल्गोरिदम
- #### 1. निर्णय वृक्ष
एक निर्णय वृक्ष एक शाखा पद्धति का उपयोग करके निर्णय के प्रत्येक संभावित परिणाम को प्रदर्शित करने के लिए एक आरेख है। उदाहरण के लिए, आप एक सलाद ऑर्डर करने का निर्णय लेते हैं, और आपका पहला निर्णय शायद सब्जी की किस्म है, फिर व्यंजनों की किस्म, और फिर सलाद की किस्म। हम सभी संभावित परिणामों को एक निर्णय वृक्ष में प्रदर्शित कर सकते हैं।
निर्णय पेड़ों को प्रशिक्षित करने के लिए, हमें प्रशिक्षण डेटासेट का उपयोग करने और उस विशेषता को खोजने की आवश्यकता है जो लक्ष्य के लिए सबसे अधिक उपयोगी है। उदाहरण के लिए, धोखाधड़ी का पता लगाने के उपयोग के मामले में, हमें यह पता चल सकता है कि धोखाधड़ी के जोखिम की भविष्यवाणी करने के लिए सबसे अधिक प्रभावशाली विशेषता देश है। पहले विशेषता के साथ विभाजन करने के बाद, हमें दो उप-सेट मिलते हैं, जो कि सबसे अधिक सटीक भविष्यवाणी करने में सक्षम होते हैं यदि हम केवल पहले विशेषता को जानते थे। इसके बाद, हम फिर से विभाजित करते हैं और फिर से, जब तक पर्याप्त गुणों का उपयोग करके लक्ष्य की जरूरतों को पूरा नहीं किया जाता है, तब तक हम दो सबसे अच्छे गुणों को ढूंढते हैं।
- #### 2. आकस्मिक वन
एक यादृच्छिक वन कई निर्णय पेड़ों का औसत है, जिनमें से प्रत्येक निर्णय पेड़ को यादृच्छिक डेटा नमूने के साथ प्रशिक्षित किया जाता है। यादृच्छिक वन में प्रत्येक पेड़ एक पूर्ण निर्णय पेड़ की तुलना में कमजोर है, लेकिन सभी पेड़ों को एक साथ रखा जाता है, हम विविधता के फायदे के कारण बेहतर समग्र प्रदर्शन प्राप्त कर सकते हैं।
यादृच्छिक वन आज मशीन सीखने में एक बहुत लोकप्रिय एल्गोरिथ्म है। यादृच्छिक वन को प्रशिक्षित करना आसान है, और यह काफी अच्छा प्रदर्शन करता है। इसका नुकसान यह है कि अन्य एल्गोरिदम की तुलना में, यादृच्छिक वन के आउटपुट की भविष्यवाणी धीमी हो सकती है, इसलिए जब तेजी से भविष्यवाणी की आवश्यकता होती है, तो यादृच्छिक वन का चयन नहीं किया जा सकता है।
- #### 3. ऊंचाई बढ़ना
ग्रेडिएंट बूस्टिंग (GradientBoosting), यादृच्छिक जंगल की तरह, भी निर्णय पेड़ों से बना है। ग्रेडिएंट बूस्टिंग और यादृच्छिक जंगल के बीच सबसे बड़ा अंतर यह है कि ग्रेडिएंट बूस्टिंग में, पेड़ों को एक के बाद एक प्रशिक्षित किया जाता है। प्रत्येक पीछे के पेड़ को मुख्य रूप से गलत डेटा की पहचान करने वाले पहले के पेड़ों द्वारा प्रशिक्षित किया जाता है। इससे ग्रेडिएंट बूस्टिंग को भविष्यवाणी करने में आसान परिस्थितियों पर कम ध्यान देना पड़ता है और कठिन परिस्थितियों पर अधिक ध्यान देना पड़ता है।
ग्रेडियंट प्रशिक्षण भी बहुत तेज़ है और बहुत अच्छा प्रदर्शन करता है। हालांकि, प्रशिक्षण डेटासेट में छोटे बदलाव मॉडल को मौलिक रूप से बदल सकते हैं, इसलिए यह सबसे व्यवहार्य परिणाम नहीं दे सकता है।
3. तंत्रिका नेटवर्क एल्गोरिदम: तंत्रिका नेटवर्क एक जैविक घटना है जो मस्तिष्क में एक दूसरे के साथ सूचनाओं का आदान-प्रदान करने वाले एक दूसरे से जुड़े न्यूरॉन्स से बना है। इस विचार को अब मशीन सीखने के क्षेत्र में लागू किया गया है, जिसे एएनएन (आर्टिफिशियल न्यूरल नेटवर्क) कहा जाता है। गहरी शिक्षा एक बहु-स्तरीय तंत्रिका नेटवर्क है। एएनएन मानव मस्तिष्क की तरह संज्ञानात्मक क्षमताओं को सीखने के माध्यम से प्राप्त करने की एक श्रृंखला है। मॉडल बहुत जटिल कार्यों को संभालने के लिए बहुत अच्छा प्रदर्शन करते हैं, जैसे छवि पहचान। लेकिन, मानव मस्तिष्क की तरह, मॉडल को प्रशिक्षित करना बहुत समय लेने वाला है और बहुत अधिक ऊर्जा की आवश्यकता होती है।
बड़े डेटा क्षेत्र से पुनः प्राप्त