क्वांटिफाइंग रणनीतियों के लिए आउट-सैंपल डेटा परीक्षण की आवश्यकता
लेखक:आविष्कारक मात्रा - छोटे सपने, बनाया गयाः 2018-01-26 12:11:58, अद्यतन किया गयाः 2019-07-31 18:03:38वास्तविक समय में बड़े डेटा का उपयोग करना।

-
NO:01
मानव जीवन, छोटे से बड़े तक, बड़े से बूढ़े तक, वास्तव में गलती करने, सुधार करने और गलती करने की एक निरंतर प्रक्रिया है, लगभग कोई भी अपवाद नहीं हो सकता है। शायद आपने कई गलतियां की हैं, जो अब बहुत कम दिखाई देती हैं; या शायद कई अवसरों को याद किया है, जैसेः रियल एस्टेट, इंटरनेट, डिजिटल मुद्रा आदि... पहले अलविदा, क्या यह एक फोड़ा है, जब आप फोड़ा आते हैं, तो आप वहां नहीं होते हैं?
यहाँ तक कि एक सुनने वाला कहता है, "मुझे शुरू में नहीं करना चाहिए था"... "अगर... मैं... "
मैंने इस सवाल को लंबे समय तक रखा और इसे हल नहीं किया, लेकिन बाद में यह समझ में आया। वास्तव में, यह कुछ भी डराने वाला नहीं है, क्योंकि उस समय हर विकल्प, चाहे सही हो या गलत, हमें पूर्व निर्धारित परिणामों से दूर ले जाएगा और अज्ञात की ओर ले जाएगा; और हमारी चिंतनशीलता, केवल ऐतिहासिक डेटा से परे, भगवान के दृष्टिकोण को खोलती है।
-
NO:02
मैंने कई ट्रेडिंग सिस्टम देखे हैं, जिनमें रिट्रीट के समय सफलता का प्रतिशत 50% से अधिक हो सकता है। इस उच्च जीत की दर के साथ, जीत और हार का अनुपात 1:1 से अधिक हो सकता है। लेकिन, कोई अपवाद नहीं, एक बार जब ये सिस्टम वास्तविक प्लेट पर लगाए जाते हैं, तो वे मूल रूप से घाटे में होते हैं। घाटे का कारण बनने के कई कारण हैं, जिनमें से एक है, रिट्रीट के समय, अनजाने में, दाएं से बाएं देखने के लिए, भगवान का दृष्टिकोण खोलना।

हालाँकि, लेन-देन एक ऐसी उलझन है, जो बाद में स्पष्ट रूप से दिखाई देती है, लेकिन यदि हम भगवान के दृष्टिकोण के घेरे के बिना वापस जाते हैं, तो हम अभी भी अजनबी हैं। यह मात्रात्मक मूल प्रश्नों और ऐतिहासिक डेटा की सीमाओं के बारे में है। तो, यदि केवल सीमित ऐतिहासिक डेटा के साथ लेन-देन प्रणाली की जांच की जाती है, तो पीछे की ओर देखने के लिए ड्राइविंग की समस्या से बचना मुश्किल है।
-
NO:03
लेकिन सीमित डेटा के साथ, सीमित डेटा का अधिकतम उपयोग कैसे किया जाए ताकि लेन-देन की रणनीति का पूर्ण परीक्षण किया जा सके? आमतौर पर दो तरीके होते हैंः अनुवर्ती परीक्षण और क्रॉस-समीक्षा।
प्रक्षेपण परीक्षण के मूल सिद्धांतः पहले लंबे ऐतिहासिक डेटा के साथ मॉडल को प्रशिक्षित करें, और फिर अपेक्षाकृत कम डेटा के साथ मॉडल का परीक्षण करें, फिर डेटा लेने की खिड़की को लगातार पीछे की ओर ले जाएं, प्रशिक्षण और परीक्षण के चरणों को दोहराएं।

1. प्रशिक्षण डेटाः 2000 से 2001; परीक्षण डेटाः 2002; 2. प्रशिक्षण डेटाः 2001-2002; परीक्षण डेटाः 2003; 3. प्रशिक्षण डेटाः 2002-2003, परीक्षण डेटाः 2004; 4. प्रशिक्षण डेटाः 2003 से 2004 तक, परीक्षण डेटाः 2005; 5. प्रशिक्षण डेटाः 2004-2005; परीक्षण डेटाः 2006;
... और इस तरह...
अंत में, रणनीतियों के प्रदर्शन का समग्र मूल्यांकन करने के लिए (२००२, २००३, २००४, २००५, २००६...) परीक्षण के परिणामों का सांख्यिकीय विश्लेषण किया गया।
नीचे दिए गए चित्र में, प्रक्षेपण परीक्षण के सिद्धांतों को एक सहज व्याख्या दी गई हैः
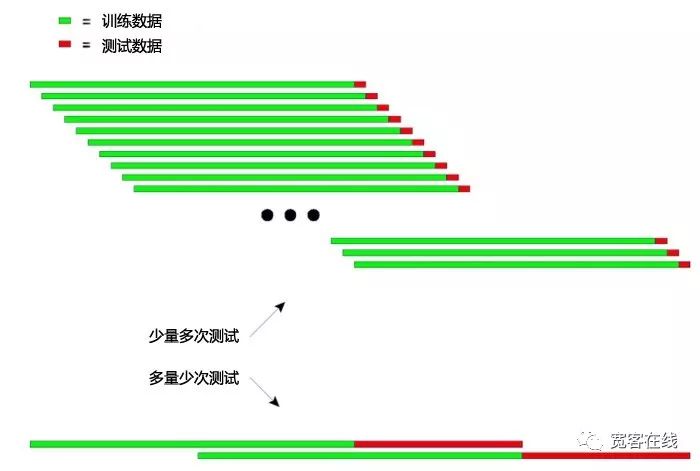
उपरोक्त चित्र में प्रक्षेपण परीक्षण के दो अलग-अलग तरीके दिखाए गए हैं।
पहलाः प्रत्येक परीक्षण में, परीक्षण डेटा अपेक्षाकृत छोटा है और परीक्षणों की संख्या अधिक है। दूसराः प्रत्येक परीक्षण में, परीक्षण डेटा अपेक्षाकृत लंबा होता है और परीक्षण की संख्या कम होती है।
व्यावहारिक अनुप्रयोगों में, परीक्षण डेटा की लंबाई को बदलकर कई बार परीक्षण किया जा सकता है ताकि मॉडल के असमान डेटा के प्रति स्थिरता का निर्धारण किया जा सके।
-
NO:04
क्रॉस-टेस्टिंग का मूल सिद्धांतः सभी डेटा को N भागों में विभाजित करें, उनमें से N-1 भागों के साथ प्रत्येक बार प्रशिक्षण करें और शेष भागों के साथ परीक्षण करें।
वर्ष 2000 से 2003 के बीच के वर्षों को चार भागों में विभाजित किया गया है। क्रॉस-समीक्षा का संचालन इस प्रकार हैः 1. प्रशिक्षण डेटाः 2001-2003, परीक्षण डेटाः 2000; 2. प्रशिक्षण डेटाः 2000-2002, परीक्षण डेटाः 2003; 3. प्रशिक्षण डेटाः 2000, 2001, 2003, परीक्षण डेटाः 2002; 4. प्रशिक्षण डेटाः 2000, 2002, 2003, परीक्षण डेटाः 2001;
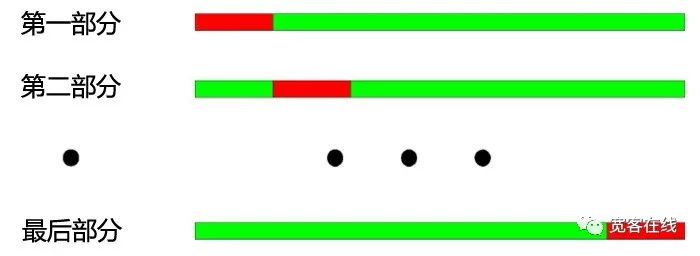
जैसा कि ऊपर दिखाया गया है, क्रॉस-टेस्टिंग का सबसे बड़ा लाभ सीमित डेटा का पूरा उपयोग करना है, प्रत्येक प्रशिक्षण डेटा भी परीक्षण डेटा है। लेकिन क्रॉस-टेस्टिंग को रणनीति मॉडल के परीक्षण के लिए लागू करने के लिए भी स्पष्ट नुकसान हैंः
1. जब मूल्य डेटा असमान होता है, तो मॉडल के परीक्षण के परिणाम अक्सर अविश्वसनीय होते हैं। उदाहरण के लिए, 2008 के डेटा के साथ प्रशिक्षण और 2005 के डेटा के साथ परीक्षण। यह बहुत संभव है कि 2008 के बाजार के माहौल में 2005 की तुलना में बहुत बदलाव हुआ है, इसलिए मॉडल के परीक्षण के परिणाम अविश्वसनीय हैं।
2, पहले के समान, क्रॉस-टेस्टिंग में, पुराने डेटा परीक्षण मॉडल के बजाय नवीनतम डेटा के साथ प्रशिक्षण मॉडल का उपयोग करना अपने आप में बहुत तर्कसंगत नहीं है।
-
NO:05
इसके अलावा, क्वांटिफाइड रणनीति मॉडल के परीक्षण में, दोनों प्रक्षेपण परीक्षण और क्रॉस-टेस्ट में डेटा ओवरलैप की समस्या होती है।
ट्रेडिंग रणनीति मॉडल विकसित करते समय, अधिकांश तकनीकी संकेतक एक निश्चित लंबाई के ऐतिहासिक डेटा पर आधारित होते हैं। उदाहरण के लिए, एक ट्रेंडिंग संकेतक का उपयोग करके पिछले 50 दिनों के ऐतिहासिक डेटा की गणना की जाती है, और अगले ट्रेडिंग दिवस पर, यह संकेतक 50 दिनों से पहले के डेटा की गणना करता है, तो इन दो संकेतकों की गणना 49 दिनों के लिए समान होती है, जिससे प्रत्येक दो आसन्न दिनों में संकेतक का परिवर्तन बहुत अस्पष्ट हो जाता है।
डेटा ओवरलैप करने से निम्नलिखित प्रभाव पड़ सकते हैंः
1. मॉडल के अनुमान के परिणामों में धीमी गति से बदलाव होने से स्टॉक में धीमी गति से बदलाव होता है, जिसे हम अक्सर संकेतकों की पिछड़ेपन कहते हैं।
2. मॉडल परिणामों के परीक्षण के लिए कुछ सांख्यिकीय मान अनुपयोगी हैं, जो दोहराए गए डेटा के परिणामस्वरूप होने वाले क्रम के कारण संबंधित हैं, जिससे कुछ सांख्यिकीय परीक्षण परिणाम अविश्वसनीय हो जाते हैं।
-
NO:06
एक अच्छी ट्रेडिंग रणनीति भविष्य में लाभदायक होनी चाहिए। नमूना परीक्षण, ट्रेडिंग रणनीति का उद्देश्यपूर्ण परीक्षण करने के अलावा, व्यापक ग्राहकों के समय को और अधिक कुशलता से बचा सकता है।
ज्यादातर मामलों में, सभी नमूनों के इष्टतम पैरामीटर का उपयोग करना बहुत खतरनाक होता है।
यदि पैरामीटर अनुकूलन के समय से पहले के सभी ऐतिहासिक डेटा को अलग किया जाता है, तो इन-सैम्पल डेटा और आउट-सैम्पल डेटा में विभाजित किया जाता है, पहले इन-सैम्पल डेटा का उपयोग पैरामीटर अनुकूलन के लिए किया जाता है, और फिर आउट-सैम्पल डेटा का उपयोग करके आउट-सैम्पल परीक्षण के लिए किया जाता है, तो इस त्रुटि को बाहर निकाला जा सकता है, जबकि यह भी जांचना संभव है कि अनुकूलित रणनीति भविष्य के बाजारों के लिए लागू होती है या नहीं।
-
NO:07
व्यापार की तरह, हम कभी भी समय के माध्यम से सही निर्णय लेने के लिए कभी भी सही निर्णय नहीं ले सकते हैं। यदि भगवान का हाथ है या भविष्य से वापस आने की क्षमता है, तो बिना परीक्षण के, सीधे ऑनलाइन वास्तविक ट्रेडिंग करें, और एक बेड़े में भर जाएं। और मुझे, जैसे मनुष्यों को, हमारी रणनीति को ऐतिहासिक डेटा में जांचना होगा।
लेकिन, यहां तक कि जब एक विशाल डेटा इतिहास होता है, तो यह अंतहीन और अप्रत्याशित भविष्य के सामने बहुत कम दिखता है। इसलिए, इतिहास पर आधारित ट्रेडिंग सिस्टम, जो नीचे से ऊपर की ओर धकेल दिया जाता है, अंततः समय के साथ डूब जाता है। क्योंकि इतिहास अंतहीन भविष्य नहीं हो सकता है। इसलिए, एक पूर्ण आशावादी ट्रेडिंग सिस्टम को इसके अंतर्निहित सिद्धांतों / तर्क द्वारा समर्थित किया जाना चाहिए।

-
NO:08
हम (आविष्कारक क्वांटिफाइड क्वांटिफाइड ट्रेडिंग प्लेटफॉर्म) एक शुद्ध क्वांटिफाइड सर्कल बनाने के लिए मौजूदा क्वांटिफाइड सर्कल को बदलना चाहते हैं, जिसमें कोई भी चीज नहीं है, एक्सचेंज बंद है, और धोखेबाज हैं। दुनिया में कभी भी कोई भी ज्ञान और सिद्धांत नहीं बनाया गया है, वे केवल हमारे लिए खोज के लिए इंतजार कर रहे हैं।

साझा करना एक रवैया है, बल्कि एक बुद्धि है!
अतिथि ऑनलाइन लेखक हुकीबो
- एपीआई दस्तावेज़ीकरण उदाहरण परीक्षण विफल
- बड़े पैमाने पर डाउनलोड एपीआई समस्या
- ज़ाइफ़ एक्सचेंज के लिए वेबसॉकेट का समर्थन करना चाहते हैं।
- Kucoin एक्सचेंज के लिए समर्थन जोड़ने की उम्मीद
- पुनः परीक्षण और वास्तविक समय में हमेशा Invalid order price / amount दिखाता है
- GetOrders: 400: {"कोड":-1121,"msg":"अमान्य प्रतीक. "}
- गेट.आईओ पायथन समस्या ((1/3): HttpUtil.py कोड को समझें
- Gate.io交易所的问题
- ट्रेंड ट्रेडरः वास्तविक युद्ध में ट्रेंड ट्रेडिंग लाभ कार्ड या नए अवसरों का शिकार करने के लिए बाहर निकलें
- और अगर हम for के साथ एक सरणी को पार करते हैं?
- 为何exchang.GetTrades只能返回最后一笔交易?
- रीन ने सौंदर्य सीखने के लिए अपडेट पोस्ट किया
- प्रक्रियात्मक लेनदेन में रणनीतियों के विफल होने का सही निर्धारण करने के नियम
- रिवर्स ट्रेडिंग रणनीतियाँ रिटर्न की मात्रा के आधार पर
- अली क्लाउड CentOS 7.4 पर एक से अधिक प्रोग्राम कैसे शुरू करें?
- हम सेक्स एक्सचेंजों को बढ़ाने की उम्मीद करते हैं!
- नए लोग MA फ़ंक्शन के बारे में पूछते हैं
- त्रिभुज हेजिंग सूट (स्वयं ले जाने वाला हार्ड ट्रिमर) खरीदें, मार्गदर्शन के लिए पूछें
- क्या स्वतंत्र रूप से एक टोकन प्रो लीवरेज खाता जोड़ने के लिए एक्सचेंजों
- ओकेएक्स के इतिहास के बारे में कौन सा डेटा है? उदाहरण के लिए, कुछ महीने पहले के डेटा, न कि केवल हाल के दिनों के डेटा, धन्यवाद