5.4 हमें नमुने के बाहर परीक्षण की आवश्यकता क्यों है
लेखक:अच्छाई, बनाया गयाः 2019-05-10 09:13:53, अद्यतन किया गयाःसारांश
पिछले भाग में, हमने आपको दिखाया कि कैसे रणनीति बैकटेस्टिंग प्रदर्शन रिपोर्ट को पढ़ने के लिए कई महत्वपूर्ण प्रदर्शन संकेतकों पर ध्यान केंद्रित करके। वास्तव में, यह एक रणनीति लिखने के लिए मुश्किल नहीं है जो बैकटेस्टिंग प्रदर्शन रिपोर्ट में लाभ कमा रही है। यह आकलन करना मुश्किल है कि क्या यह रणनीति भविष्य में वास्तविक बाजार में प्रभावी रहेगी। इसलिए आज मैं ऑफ-सैंपल परीक्षण और इसके महत्व को समझाऊंगा।
बैकटेस्टिंग वास्तविक बाजार के बराबर नहीं है
कई शुरुआती लोग अपनी ट्रेडिंग रणनीतियों के बारे में आसानी से आश्वस्त होते हैं और एक प्रदर्शन रिपोर्ट या फंड वक्र के साथ अपने विचारों को व्यवहार में लाने के लिए तैयार होते हैं जो अच्छा दिखता है। यह स्वीकार किया जाना चाहिए कि यह बैकटेस्टिंग परिणाम एक निश्चित बाजार की स्थिति के साथ पूरी तरह से फिट बैठता है, लेकिन एक बार ट्रेडिंग रणनीति को दीर्घकालिक लड़ाई में डाल दिया जाता है, तो वे पाएंगे कि रणनीति वास्तव में प्रभावी नहीं है।
मैंने कई ट्रेडिंग रणनीतियों को देखा है, और बैकटेस्टिंग करते समय सफलता दर 50% तक पहुंच सकती है। इस तरह की उच्च जीत दर की धारणा के तहत, अभी भी लाभ और हानि का अनुपात 1: 1 है। हालांकि, एक बार इन रणनीतियों को व्यवहार में लाया जाने के बाद, वे सभी पैसा खो रहे हैं। इसके कई कारण हैं। इन कारणों में से, डेटा नमूना बहुत छोटा है, जो डेटा के विचलन का कारण बनता है।
हालाँकि, ट्रेडिंग इतनी उलझी हुई चीज है, और यह बाद में बहुत स्पष्ट है, लेकिन अगर हम मूल पर लौटते हैं, तो हम अभी भी अभिभूत महसूस करते हैं। इसमें मात्रात्मककरण का मूल कारण शामिल है - ऐतिहासिक डेटा की सीमाएं। इसलिए, यदि हम केवल सीमित ऐतिहासिक डेटा का उपयोग ट्रेडिंग रणनीति का परीक्षण करने के लिए करते हैं, तो
नमूना के बाहर का परीक्षण क्या है?
डेटा सीमित होने पर ट्रेडिंग रणनीति का वैज्ञानिक परीक्षण करने के लिए सीमित डेटा का पूर्ण उपयोग कैसे करें? इसका उत्तर ऑफ-सैंपल टेस्ट विधि है। बैकटेस्टिंग के दौरान, ऐतिहासिक डेटा को समय अनुक्रम के अनुसार दो खंडों में विभाजित किया जाता है। डेटा के पिछले खंड का उपयोग रणनीति अनुकूलन के लिए किया जाता है, जिसे प्रशिक्षण सेट कहा जाता है, और डेटा के अंतिम खंड का उपयोग ऑफ-सैंपल परीक्षण के लिए किया जाता है, जिसे परीक्षण सेट कहा जाता है।
यदि आपकी रणनीति हमेशा वैध है, तो प्रशिक्षण सेट डेटा में सर्वोत्तम मापदंडों के कई सेटों का अनुकूलन करें, और परीक्षण सेट डेटा पर फिर से बैकटेस्ट करने के लिए इन मापदंडों के सेटों को लागू करें। आदर्श रूप से, बैकटेस्ट परिणाम प्रशिक्षण सेटों के साथ लगभग समान होने चाहिए, या अंतर उचित सीमा के भीतर है। फिर यह कहा जा सकता है कि यह रणनीति अपेक्षाकृत प्रभावी है।
लेकिन अगर एक रणनीति प्रशिक्षण सेट में अच्छी तरह से प्रदर्शन करता है, लेकिन परीक्षण सेट खराब प्रदर्शन करता है, या बहुत कुछ बदल जाता है, और जब अन्य मापदंडों का उपयोग किया जाता है, तो रणनीति डेटा माइग्रेशन पूर्वाग्रह हो सकता है।
उदाहरण के लिए, मान लीजिए कि आप कमोडिटी वायदा रीबार का बैकटेस्ट करना चाहते हैं। अब उस रीबार में लगभग 10 वर्षों (2009 ~ 2019) के डेटा हैं, आप 2009 से 2015 तक के डेटा का उपयोग प्रशिक्षण सेट के रूप में, 2015 से 2019 तक के डेटा का उपयोग परीक्षण सेट के रूप में कर सकते हैं। यदि प्रशिक्षण सेट में सबसे अच्छा पैरामीटर सेट है (15, 90), (5, 50), (10, 100)... तो हम इन पैरामीटर सेट को परीक्षण सेट में डालते हैं। इन दो बैकटेस्ट प्रदर्शन रिपोर्टों और फंड वक्रों की तुलना करके यह निर्धारित करें कि क्या उनका अंतर उचित सीमा के भीतर है।
यदि आप नमुना परीक्षण का उपयोग नहीं करते हैं, तो रणनीति का परीक्षण करने के लिए 2009 से 2019 तक के डेटा का सीधे उपयोग करें। ऐतिहासिक डेटा के अति-फिटिंग के कारण परिणाम एक अच्छी बैकटेस्ट प्रदर्शन रिपोर्ट हो सकती है, लेकिन ऐसे बैकटेस्ट परिणामों का वास्तविक बाजार के लिए बहुत कम अर्थ है और इसका कोई मार्गदर्शक प्रभाव नहीं है, खासकर अधिक मापदंडों वाली रणनीतियों के लिए।
उन्नत नमुना परीक्षण
जैसा कि ऊपर उल्लेख किया गया है, ऐतिहासिक डेटा की कमी के आधार पर, नमूने के भीतर और बाहर डेटा बनाने के लिए डेटा को दो भागों में विभाजित करना एक अच्छा विचार है। लेकिन यदि आप पुनरावर्ती परीक्षण और क्रॉस-चेक परीक्षण कर सकते हैं, तो यह और भी बेहतर हो सकता है।
पुनरावर्ती परीक्षण का मूल सिद्धांतः मॉडल को प्रशिक्षित करने के लिए पिछले लंबे ऐतिहासिक डेटा का उपयोग करें, और फिर मॉडल का परीक्षण करने के लिए अपेक्षाकृत छोटे डेटा का उपयोग करें, और फिर डेटा पुनर्प्राप्त करने के लिए समय खिड़की को लगातार स्थानांतरित करें, प्रशिक्षण और परीक्षण के चरणों को दोहराएं।
प्रशिक्षण डेटाः 2000 से 2001, परीक्षण डेटाः 2002;
प्रशिक्षण डेटाः 2001 से 2002, परीक्षण डेटाः 2003;
प्रशिक्षण डेटाः 2002 से 2003, परीक्षण डेटाः 2004;
प्रशिक्षण डेटाः 2003 से 2004, परीक्षण डेटाः 2005;
प्रशिक्षण डेटाः 2004 से 2005, परीक्षण डेटाः 2006;
...और इसी तरह...
अंत में, रणनीति के प्रदर्शन का व्यापक मूल्यांकन करने के लिए परीक्षण परिणामों (2002, 2003, 2004, 2005, 2006...) का सांख्यिकीय विश्लेषण किया गया।
निम्नलिखित आरेख रिकर्सिव परीक्षण के सिद्धांत को सहज रूप से समझा सकता हैः
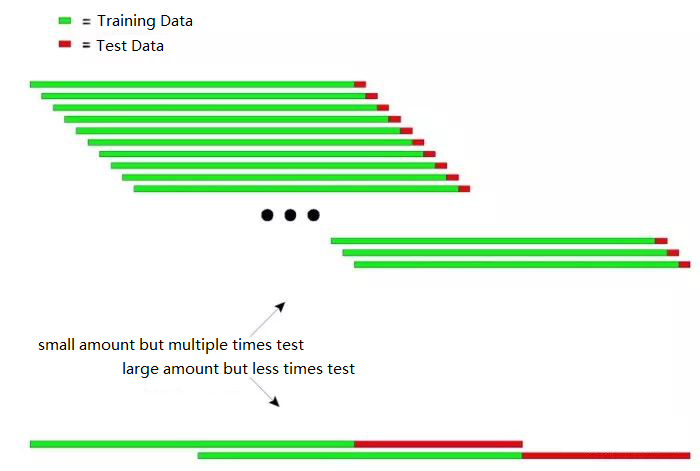
उपरोक्त चित्र में पुनरावर्ती परीक्षण के दो तरीके दिखाए गए हैं।
पहला प्रकार: छोटी मात्रा में लेकिन कई बार परीक्षण
दूसरा प्रकार: बड़ी मात्रा में लेकिन कम बार परीक्षण
व्यावहारिक अनुप्रयोगों में, गैर-स्थिर डेटा के जवाब में मॉडल की स्थिरता निर्धारित करने के लिए परीक्षण डेटा की लंबाई को बदलकर कई परीक्षण किए जा सकते हैं।
क्रॉस-चेकिंग परीक्षण का मूल सिद्धांतः सभी डेटा को N भागों में विभाजित करें, प्रत्येक बार प्रशिक्षण के लिए N-1 भागों का उपयोग करें, और शेष भाग का उपयोग परीक्षण के लिए करें।
वर्ष 2000 से वर्ष 2003 तक, इसे वार्षिक विभाजन के अनुसार चार भागों में विभाजित किया गया है। क्रॉस-चेकिंग परीक्षण का संचालन इस प्रकार हैः
प्रशिक्षण डेटाः 2001-2003, परीक्षण डेटाः 2000;
प्रशिक्षण डेटाः 2000-2002, परीक्षण डेटाः 2003;
प्रशिक्षण डेटाः 2000, 2001, 2003, परीक्षण डेटाः 2002;
प्रशिक्षण डेटाः 2000, 2002, 2003, परीक्षण डेटाः 2001;
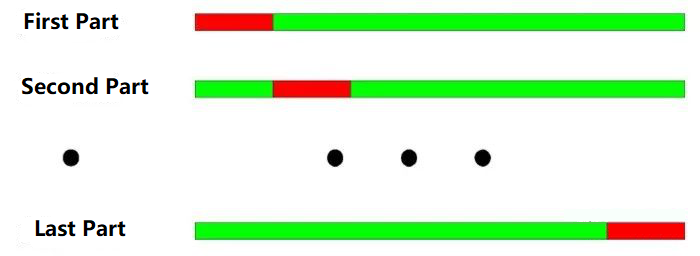
जैसा कि ऊपर दिए गए चित्र में दिखाया गया हैः क्रॉस-चेकिंग टेस्ट का सबसे बड़ा लाभ सीमित डेटा का पूर्ण उपयोग करना है, और प्रत्येक प्रशिक्षण डेटा भी परीक्षण डेटा है। हालांकि, बैकटेस्ट पर क्रॉस-चेकिंग लागू होने पर स्पष्ट कमियां भी हैंः
जब मूल्य डेटा स्थिर नहीं होता है, तो मॉडल के परीक्षण परिणाम अक्सर अविश्वसनीय होते हैं। उदाहरण के लिए, प्रशिक्षण के लिए 2008 के डेटा और परीक्षण के लिए 2005 के डेटा का उपयोग करें। यह बहुत संभावना है कि 2008 में बाजार का माहौल 2005 की तुलना में बहुत बदल गया है, इसलिए मॉडल परीक्षण के परिणाम विश्वसनीय नहीं हैं।
पहले के समान, क्रॉस-चेक परीक्षण में, यदि मॉडल को नवीनतम डेटा के साथ प्रशिक्षित किया जाता है और मॉडल को पुराने डेटा के साथ परीक्षण किया जाता है, तो यह अपने आप में बहुत तार्किक नहीं है।
इसके अतिरिक्त, मात्रात्मक रणनीति मॉडल का परीक्षण करते समय, रिकर्सिव परीक्षण और क्रॉस-चेक परीक्षण दोनों में डेटा ओवरलैप की समस्याएं आई हैं।
एक ट्रेडिंग रणनीति मॉडल विकसित करते समय, अधिकांश तकनीकी संकेतक एक निश्चित अवधि के ऐतिहासिक डेटा पर आधारित होते हैं। उदाहरण के लिए, पिछले 50 दिनों के ऐतिहासिक डेटा की गणना करने के लिए प्रवृत्ति संकेतक का उपयोग करना, लेकिन अगले ट्रेडिंग दिन के लिए, जो फिर से ट्रेडिंग दिन के पहले 50 दिनों के डेटा से गणना की जाती है, दो संकेतकों की गणना के लिए डेटा 49 दिनों के लिए समान है। इसके परिणामस्वरूप प्रत्येक आसन्न दो दिनों के लिए संकेतक में बहुत ही नगण्य परिवर्तन होगा।
डेटा ओवरलैप के निम्नलिखित प्रभाव हो सकते हैंः
मॉडल द्वारा भविष्यवाणी किए गए परिणामों में धीमी गति से परिवर्तन स्थिति में धीमी गति से बदलाव की ओर जाता है, जो कि हम अक्सर कहते हैं कि संकेतकों का हिस्टेरिसिस है।
मॉडल परिणामों के परीक्षण के लिए कुछ सांख्यिकीय मान उपलब्ध नहीं हैं। दोहराए गए डेटा के कारण होने वाले अनुक्रम सहसंबंध के कारण, कुछ सांख्यिकीय परीक्षणों के परिणाम विश्वसनीय नहीं हैं।
एक अच्छी ट्रेडिंग रणनीति भविष्य में लाभदायक होनी चाहिए। नमूना परीक्षण, वस्तुनिष्ठ रूप से ट्रेडिंग रणनीतियों का पता लगाने के अलावा, मात्रात्मक व्यापारियों के लिए समय बचाने में अधिक कुशल है। ज्यादातर मामलों में, सभी नमूनों के इष्टतम मापदंडों का सीधे उपयोग करना बहुत खतरनाक है।
यदि पैरामीटर अनुकूलन के लिए समय बिंदु से पहले सभी ऐतिहासिक डेटा को अलग किया जाता है, और डेटा को नमूना में डेटा और नमूना के बाहर के डेटा में विभाजित किया जाता है, तो नमूना में डेटा का उपयोग करके पैरामीटर को अनुकूलित किया जाता है, और फिर नमूना के बाहर के नमूने का उपयोग नमूना परीक्षण के लिए किया जाता है। त्रुटि का पता लगाया जाएगा, और साथ ही यह परीक्षण किया जा सकता है कि क्या अनुकूलित रणनीति भविष्य के बाजार के लिए उपयुक्त है।
संक्षेप में
व्यापार की तरह ही, हम कभी भी समय में वापस नहीं जा सकते और अपने लिए सही निर्णय नहीं ले सकते। यदि आपके पास समय यात्रा करने की क्षमता है, तो आपको व्यापार करने की आवश्यकता नहीं होगी। आखिरकार, हम सभी नश्वर हैं, हमें अपनी रणनीति को ऐतिहासिक डेटा में सत्यापित करना चाहिए।
हालांकि, विशाल इतिहास डेटा के साथ भी, अंतहीन और अप्रत्याशित भविष्य के सामने, इतिहास बेहद दुर्लभ है। इसलिए, इतिहास पर आधारित व्यापार प्रणाली अंततः समय के साथ डूब जाएगी। क्योंकि इतिहास भविष्य को समाप्त नहीं कर सकता है। इसलिए, एक पूर्ण सकारात्मक अपेक्षा व्यापार प्रणाली को इसके अंतर्निहित सिद्धांतों और तर्क द्वारा समर्थित किया जाना चाहिए।
स्कूल के बाद व्यायाम
वास्तविक जीवन में कौन सी घटनाएं हैं जो उत्तरजीवी पूर्वाग्रह हैं?
नमूना में और बाहर बैकटेस्ट की तुलना करने के लिए FMZ क्वांट प्लेटफॉर्म का उपयोग करें।
- मैट एक्सचेंज कब जोड़ें?
- जब आप अपने फोन पर टर्मिनल एमुलेटर के माध्यम से लिनक्स होस्टिंग इंस्टॉल करते हैं, तो खराब सिस्टम कॉल का कारण क्या हो सकता है?
- क्या GetDepth द्वारा लौटाई गई गहराई को समायोजित किया जा सकता है?
- कैसे एक रोबोट को स्थानीय, विन या मैक पर तैनात करने के लिए
- टोकन फ्यूचर्स एक्सचेंज को जोड़ने में गलती हुई।
- क्या व्यवस्थापक Deribit के लिए WSS कनेक्शन कोड प्रदान कर सकते हैं?
- BitMax का उपयोग करके संकलित करें
- कृपया विज़ुअलाइज़ेशन प्रोग्राम को सबसे अधिक कीमत कैसे रिकॉर्ड करें
- क्या एक ही समय में कई डिजिटल मुद्रा जोड़े के लिए बोली लगाने का कोई तरीका है? ब्याज दरों को कई मुद्रा जोड़े के लिए तेजी से स्कैन करने की आवश्यकता है।
- 5.5 ट्रेडिंग रणनीति अनुकूलन
- 5.3 रणनीति बैकटेस्ट परफॉर्मेंस रिपोर्ट कैसे पढ़ें
- अक्सर पूछे जाने वाले प्रश्न
- एक प्रश्न है कि डिजिटल मुद्रा पुनरीक्षण में, यदि अनुकरणीय टिक का अंतर्निहित चक्र 1 मिनट है, तो प्रति मिनट कितने टिक डेटा का अनुकरण किया जा सकता है?
- एफएमजेड क्वांटिफाइड प्लेटफॉर्म बिटकॉइन और डिजिटल मुद्राओं की क्वांटिफाइड रणनीतियों के बारे में कुछ सीखना
- 5.2 मात्रात्मक ट्रेडिंग बैकटेस्टिंग कैसे करें
- कृपया बताएं कि डिजिटल मुद्रा रणनीति समीक्षा में, क्या आप वर्तमान बार के समापन या अगले बार के समापन के साथ शूट करते हैं?
- पूछें कि डिजिटल मुद्रा रणनीति समीक्षा में, खुले समतल ट्रेडों का आकार बड़ा नहीं है, क्यों अक्सर लेनदेन नहीं हो सकता है, पदों को फ्रीज किया जाता है
- 5.1 बैकटेस्टिंग का अर्थ और जाल
- 4.6 सी++ भाषा में रणनीतियों को कैसे लागू करें
- ईमा के बारे में एक और सवाल