मशीन लर्निंग पर आधारित ऑर्डर बुक उच्च आवृत्ति ट्रेडिंग रणनीति
 1
7789
1
7789
मशीन लर्निंग पर आधारित ऑर्डर बुक उच्च आवृत्ति ट्रेडिंग रणनीति
- ### 1. विचारधारा
शेयर बाजारों के लेन-देन तंत्र को बोली-चालित बाजारों और आदेश-चालित बाजारों में विभाजित किया जा सकता है, पहले बाजार के रूप में तरलता प्रदान करने पर भरोसा करते हैं, बाद में लिमिट मूल्य के माध्यम से तरलता प्रदान करते हैं, व्यापार निवेशकों द्वारा खरीद और बिक्री के लिए कमीशन बोली के माध्यम से होता है। चीन का शेयर बाजार आदेश-चालित बाजारों में से एक है, जिसमें स्टॉक बाजार और वायदा बाजार शामिल हैं।
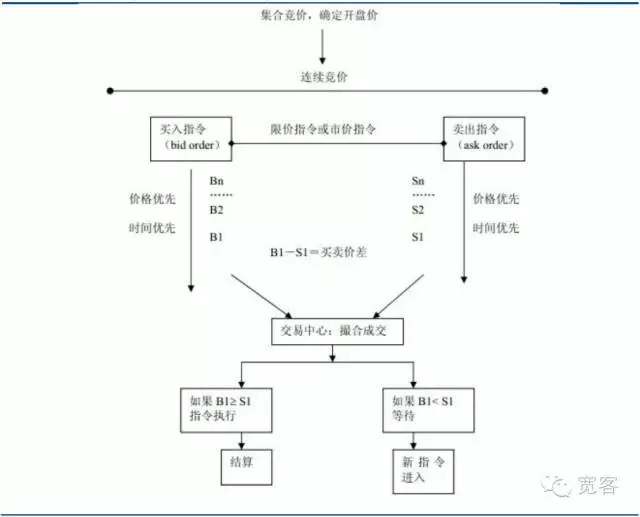 आरेख 1 ऑर्डर-ड्राइव मार्केट ग्राफ
आरेख 1 ऑर्डर-ड्राइव मार्केट ग्राफ
-
(i) लिमिट ऑर्डर बुक प्रोफाइल
ऑर्डर बुक का अध्ययन बाजार के सूक्ष्म संरचना के अध्ययन के दायरे में है, बाजार सूक्ष्म संरचना सिद्धांत सूक्ष्म अर्थशास्त्र में मूल्य सिद्धांत और निर्माता सिद्धांत को अपनी विचारधारा के स्रोत के रूप में रखता है, जबकि इसके केंद्रीय मुद्दों पर वित्तीय परिसंपत्ति लेनदेन और उनके मूल्य निर्माण प्रक्रिया और कारणों के विश्लेषण में, सामान्य संतुलन, स्थानीय संतुलन, सीमांत लाभ, सीमांत लागत, बाजार की निरंतरता, स्टॉक सिद्धांत, गेम थ्योरी, सूचना अर्थशास्त्र आदि जैसे कई सिद्धांतों और विधियों का उपयोग किया जाता है।
विदेशों में अनुसंधान प्रगति के अनुसार, बाजार सूक्ष्म संरचना के क्षेत्र में ओ’हारा का प्रतिनिधित्व किया जाता है, अधिकांश सिद्धांत बाजार-व्यवसायी बाजारों (यानी बोली-चालित बाजार) पर आधारित होते हैं, जैसे कि स्टॉक मॉडल और सूचना मॉडल आदि। इस वर्ष, वास्तविक लेनदेन बाजार में, आदेश-संचालित ऊपर की ओर बढ़ गया है, लेकिन आदेश-संचालित बाजारों पर विशेष रूप से अध्ययन कम है।
घरेलू प्रतिभूति बाजार और वायदा बाजार दोनों आदेश संचालित बाजार के हैं, नीचे दी गई जानकारी स्टॉक इंडेक्स वायदा अनुबंध आईएफ 1312 के लेवल_1 ट्रेडिंग ऑर्डर बुक का स्क्रीनशॉट है। ऊपर से सीधे प्राप्त जानकारी बहुत अधिक नहीं है, बुनियादी जानकारी में एक मूल्य खरीदना, एक मूल्य बेचना, एक मात्रा खरीदना और एक मात्रा बेचना शामिल है। विदेशों में कुछ अकादमिक लेखों में, और ऑर्डर बुक के अनुरूप एक सूचना पुस्तिका भी है, जिसमें सबसे विस्तृत ऑर्डर संचलन डेटा शामिल है, प्रत्येक में ऑर्डर के नीचे की मात्रा, परिष्करण मूल्य, ऑर्डर प्रकार आदि शामिल हैं। चूंकि घरेलू बाजार सूचना पुस्तिका की जानकारी सार्वजनिक नहीं करते हैं, इसलिए हम केवल ऑर्डर बुक पर भरोसा कर सकते हैं।
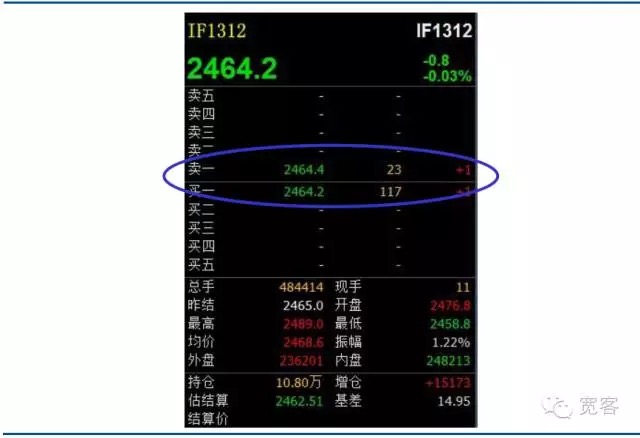 चित्र 2 स्टॉक इंडेक्स फ्यूचर्स लेवल -1 ऑर्डर बुक
चित्र 2 स्टॉक इंडेक्स फ्यूचर्स लेवल -1 ऑर्डर बुक -
(ii) आदेश पुस्तिका उच्च आवृत्ति लेनदेन अध्ययन में प्रगति
ऑर्डर बुक के गतिशील मॉडलिंग के लिए, दो मुख्य तरीके हैं, एक क्लासिक माप अर्थशास्त्र का तरीका है, दूसरा मशीन लर्निंग का तरीका है। माप अर्थशास्त्र का तरीका एक क्लासिक मुख्यधारा का अनुसंधान तरीका है, जैसे कि एमआरआर को तोड़ने का अध्ययन मूल्य अंतर विश्लेषण, हुआंग और स्टोल को तोड़ने आदि, ऑर्डर की निरंतरता के एसीडी मॉडल का अध्ययन, कीमतों की भविष्यवाणी के लिए लॉजिस्टिक मॉडल का अध्ययन करना।
वित्तीय क्षेत्र में मशीन सीखने के अकादमिक अनुसंधान भी बहुत सक्रिय है, जैसे कि 2012 में फोरकास्टिंग ट्रेंड्स ऑफ हाई_फ्रीक्वेंसी KOSPI200 इंडेक्स डेटा यूजिंग लर्निंग क्लासिफायर्स एक सामान्य शोध विचार है, जो तकनीकी विश्लेषण के सामान्य संकेतकों (MA, EMA, RSI, आदि) का उपयोग करके बाजार की भविष्यवाणी करने के लिए मशीन सीखने के वर्गीकरण विधि को पेश करता है। लेकिन यह विधि ऑर्डर बुक की गतिशील जानकारी के लिए अपर्याप्त है, यानी, ऑर्डर बुक की गतिशील जानकारी का उपयोग करके उच्च ब्रोकरिंग ट्रेडों का अध्ययन करना देश और विदेश में कम है, जो गहन अध्ययन के लायक है।
-
2. ऑर्डर बुक में उच्च आवृत्ति ट्रेडिंग में मशीन लर्निंग का अनुप्रयोग
- #### (i) सिस्टम आर्किटेक्चर
नीचे दिए गए चित्र में एक विशिष्ट मशीन लर्निंग ट्रेडिंग रणनीति के लिए एक सिस्टम आर्किटेक्चर है, जिसमें ऑर्डर बुक डेटा, फीचर डिस्कवरी, मॉडल बिल्डिंग और सत्यापन और ट्रेडिंग अवसरों के लिए कई मुख्य मॉड्यूल शामिल हैं। यह ध्यान देने योग्य है कि ट्रेडिंग प्रक्रिया एक घटना घटना से ट्रिगर की जाती है, जिसमें एक घटना है।
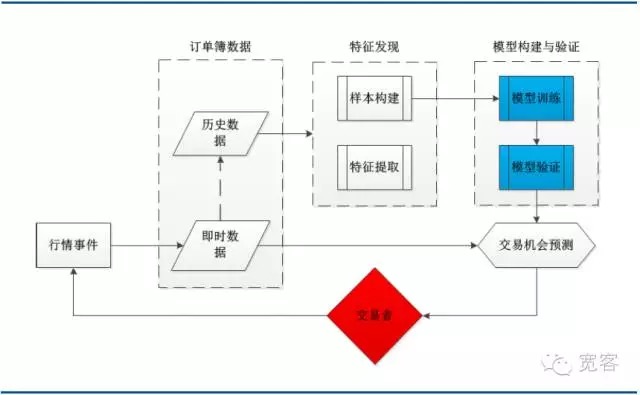 चित्र 3 मशीन लर्निंग-आधारित ऑर्डर बुक मॉडलिंग के लिए सिस्टम आर्किटेक्चर आरेख
चित्र 3 मशीन लर्निंग-आधारित ऑर्डर बुक मॉडलिंग के लिए सिस्टम आर्किटेक्चर आरेख- #### (ii) समर्थित वेक्टर प्रोफाइल
1970 के दशक में, वपनिक और अन्य ने एक बेहतर सैद्धांतिक प्रणाली का निर्माण करना शुरू किया, जिसका उपयोग सीमित नमूना स्थितियों में सांख्यिकीय नियम और सीखने की विधि की प्रकृति का अध्ययन करने के लिए किया जाता है, जो सीमित नमूना मशीन सीखने की समस्याओं के लिए एक अच्छा सैद्धांतिक ढांचा तैयार करता है, जो छोटे नमूने, गैर-रैखिक, उच्च आयाम और स्थानीय चरम बिंदुओं जैसे व्यावहारिक समस्याओं को बेहतर ढंग से हल करता है। 1995 में, वपनिक और अन्य ने एक नए सामान्य सीखने के तरीके का स्पष्ट रूप से प्रस्ताव दिया, जो वेक्टर मशीन एसवीएम का समर्थन करता है। इस सिद्धांत को व्यापक रूप से ध्यान दिया गया और विभिन्न क्षेत्रों में लागू किया गया, जिसने शुरू में अपने स्वयं के तरीकों की तुलना में कई बेहतर प्रदर्शन दिखाए।
एसवीएम एक रैखिक रूप से विभाजित स्थिति में इष्टतम वर्गीकरण सुपरप्लेन से विकसित है। दो प्रकार के वर्गीकरण प्रश्नों के लिए, प्रशिक्षण नमूने सेट को सेट करेंः ((xi, yi), i = 1,2…l, l प्रशिक्षण नमूने के लिए संख्या है, एक्सआई प्रशिक्षण नमूने के लिए है, yi के लिए है {-1 + 1} इनपुट नमूने के लिए क्लास मार्कर है x ((प्रत्याशित आउटपुट)) । एसवीएम एल्गोरिदम का प्रारंभिक बिंदु इष्टतम वर्गीकरण सुपरप्लेन की खोज करना है।
इष्टतम वर्गीकरण सुपरप्लेन न केवल सभी नमूनों को सही ढंग से अलग करने में सक्षम है (प्रशिक्षण त्रुटि स्कोर 0 है), बल्कि दो श्रेणियों के बीच की सीमा (मार्जिन) को अधिकतम करने में सक्षम है, सीमा को प्रशिक्षण डेटासेट से उस वर्गीकरण सुपरप्लेन की न्यूनतम दूरी के योग के रूप में परिभाषित किया गया है। इष्टतम वर्गीकरण सुपरप्लेन का अर्थ है कि परीक्षण डेटा के लिए औसत वर्गीकरण त्रुटि न्यूनतम है।
यदि d-आयामी वेक्टर स्पेस में एक सुपरप्लेन है:
F(x)=w*x+b=0
इन दो प्रकार के डेटा को अलग करने में सक्षम एक सुपरप्लेन को एक अंतरफलक कहा जाता है।*x, d-आयामी वेक्टर स्पेस में दो वेक्टर w और x का समांतर है.
यदि अंतरफलक:
w*x+b=0
इस अंतरफलक को सबसे अच्छा अंतरफलक कहा जाता है, क्योंकि यह निकटतम दो प्रकार के नमूनों के बीच सबसे अधिक दूरी (मार्जिन) बनाता है।
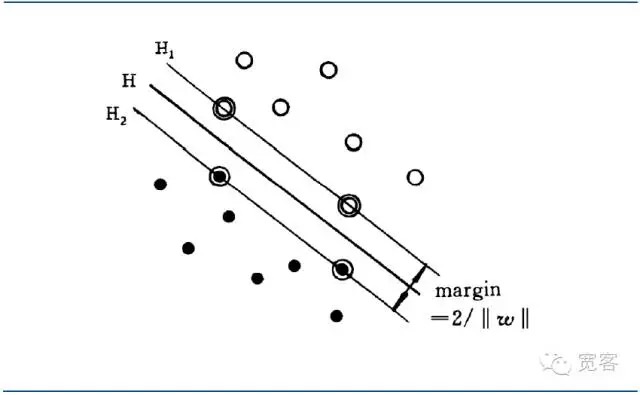 चित्र 4 एसवीएम द्विवर्गीकरण के लिए इष्टतम अंतरफलक आरेख
चित्र 4 एसवीएम द्विवर्गीकरण के लिए इष्टतम अंतरफलक आरेखइष्टतम अंतरफलक समीकरणों के लिए एकीकरण, दो प्रकार के नमूनों के बीच की दूरी को
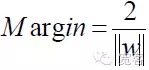
तो किसी भी नमूने के लिए,
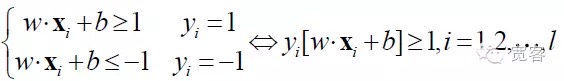
यदि आप किसी भी प्रकार के फ़ंक्शन को फ़ंक्शन के लिए अनुकूलित करना चाहते हैं, तो आपको उपरोक्त सूत्रों को पूरा करने के अलावा फ़ंक्शन को न्यूनतम करना होगा।
एसवीएम प्रश्न का गणितीय मॉडल इस प्रकार है:
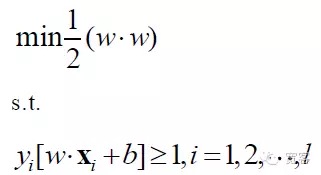
एसवीएम अंततः एक इष्टतम नियोजन समस्या बन गया है, और अकादमिक अनुसंधान के लिए मुख्य रूप से तेजी से हल करने, बहु-वर्ग, व्यावहारिक समस्याओं के अनुप्रयोगों आदि को बढ़ावा देने पर ध्यान केंद्रित किया गया है।
एसवीएम मूल रूप से द्वि-वर्गीकरण समस्याओं के लिए प्रस्तावित है, वर्तमान व्यावहारिक अनुप्रयोग आवश्यकताओं के अनुसार, इसे बहु-वर्गीकरण समस्याओं के लिए विस्तारित किया गया है। मौजूदा बहु-वर्गीकरण एल्गोरिदम में एक-जोड़ी, एक-जोड़ी, त्रुटि-सही कोडिंग, DAG-SVM और Mult i-class SVM वर्गीकरणकर्ता आदि शामिल हैं।
- #### (iii) ऑर्डर बुक सूचकांक निकालना
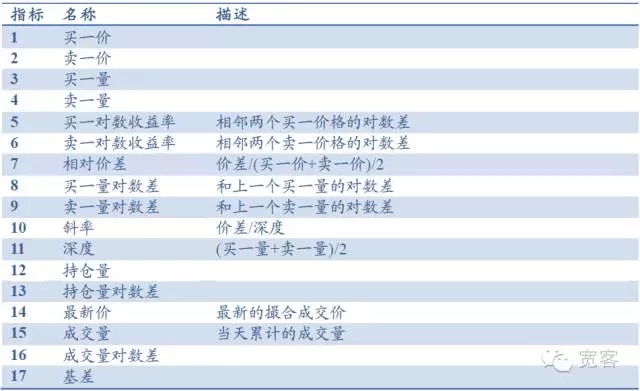
उदाहरण के लिए, स्टॉक इंडेक्स फ्यूचर्स लेवल -1 के मामले में, ऑर्डर बुक में मुख्य रूप से खरीद, बिक्री, खरीद और बिक्री की मात्रा जैसे बुनियादी संकेतक शामिल हैं, और गहराई, स्लैप, सापेक्ष मूल्य अंतर जैसे संकेतक उत्पन्न कर सकते हैं। अन्य संकेतक में होल्डिंग, लेनदेन की मात्रा, आधार अंतर आदि शामिल हैं, कुल 17 संकेतक, जैसा कि नीचे दी गई तालिका में दिखाया गया है। सामान्य तकनीकी विश्लेषण संकेतक जैसे आरएसआई, केडीजेएमए, ईएमए आदि को भी शामिल किया जा सकता है।
तालिका 1 स्तर के आदेश पुस्तिका के आधार पर सूचकांक
- #### (ग) आदेश पुस्तिका की गतिशीलता और व्यापारिक अवसरों का चित्रण
बाजार के सूक्ष्म दृष्टिकोण से, अल्पकालिक मूल्य गतिशीलता को मापने के दो तरीके हैं, एक मध्यवर्ती मूल्य गतिशीलता है, और दूसरा मूल्य अंतर क्रॉसिंग है। इस आलेख में एक अधिक सरल और सहज ज्ञान युक्त मध्यवर्ती मूल्य गतिशीलता का चयन किया गया है। मध्यवर्ती मूल्य की परिभाषाः
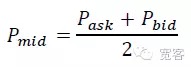
ऑर्डर बुक के भीतर मध्यस्थ मूल्य में परिवर्तन के आकार के आधार पर Δt को तीन श्रेणियों में विभाजित किया गया है।
29 अक्टूबर को मुख्य शक्ति अनुबंध IF1311 की मध्यवर्ती मूल्य गतिशीलता का वितरण, प्रति दिन 32,400 टिक के साथ।
Δt=1tick के मामले में, मध्यवर्ती मूल्य परिवर्तन का निरपेक्ष मान 0.2 लगभग 6000 बार, परिवर्तन का निरपेक्ष मान 0.4 लगभग 1500 बार, परिवर्तन का निरपेक्ष मान 0.6 लगभग 150 बार, परिवर्तन का निरपेक्ष मान 0.8 50 से अधिक बार और परिवर्तन का निरपेक्ष मान 1 से अधिक लगभग 10 बार होता है।
Δt=2tick के मामले में, मध्यवर्ती मूल्य परिवर्तन का निरपेक्ष मान 0.2 लगभग 7000 बार, परिवर्तन का निरपेक्ष मान 0.4 लगभग 3000 बार, परिवर्तन का निरपेक्ष मान 0.6 लगभग 550 बार, परिवर्तन का निरपेक्ष मान 0.8 लगभग 205 बार, परिवर्तन का निरपेक्ष मान 1 से अधिक या बराबर लगभग 10 बार होता है।
हम मानते हैं कि जब परिवर्तन का निरपेक्ष मान 0.4 से अधिक होता है, तो संभावित व्यापारिक अवसर होते हैं। Δt = 1tick के मामले में, प्रति दिन लगभग 1700 अवसर होते हैं; Δt = 2tick के मामले में, प्रति दिन लगभग 4000 अवसर होते हैं।
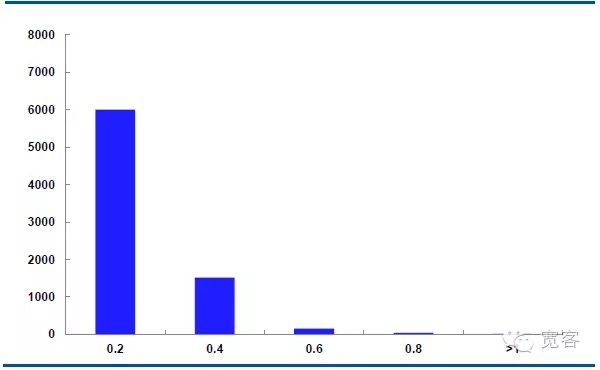
चित्र 5 IF1311 29 अक्टूबर को मध्यवर्ती मूल्य में परिवर्तन का वितरण (Δt=1 tick)
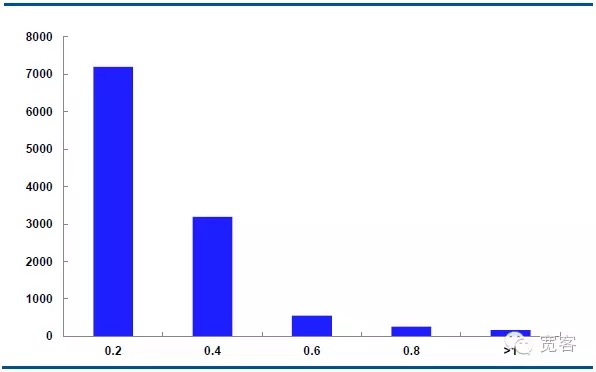
चित्र 6 IF1311 29 अक्टूबर को मध्यवर्ती मूल्य में परिवर्तन का वितरण (Δt=2tick)
-
तीन, रणनीति और प्रमाण
चूंकि एसवीएम मॉडल में बड़े नमूने की स्थिति में प्रशिक्षण की जटिलता अधिक होती है और प्रशिक्षण का समय अधिक होता है, इसलिए हमने ऐतिहासिक परिदृश्य डेटा का चयन किया है जो अपेक्षाकृत कम समय के लिए है, उदाहरण के लिए, अक्टूबर में IF1311 अनुबंध के स्तर_1 परिदृश्य डेटा के साथ मॉडल की प्रभावशीलता को सत्यापित करने के लिए।
-
(i) मॉडल प्रभाव परीक्षण
डेटा चक्रः अक्टूबर में IF1311 अनुबंधों के लिए बाजार डेटा;
Δt मूल्य निर्धारण: Δt जितना छोटा होता है, उतनी ही अधिक लेनदेन की आवश्यकता होती है, जब Δt = 1 टिक होता है, तो वास्तविक लेनदेन में लाभ प्राप्त करना मुश्किल होता है। मॉडल की प्रभावशीलता की तुलना करने के लिए, यहाँ क्रमशः 1 टिक, 2 टिक, 3 टिक का मूल्यांकन किया गया है;
मॉडल मूल्यांकन संकेतकः नमूना सटीकता, परीक्षण सटीकता, पूर्वानुमान समय
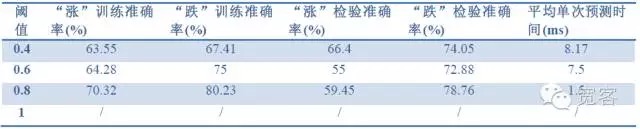 तालिका 2 1 tick डेटा के साथ 1 tick के प्रभाव की भविष्यवाणी
तालिका 2 1 tick डेटा के साथ 1 tick के प्रभाव की भविष्यवाणी तालिका 3 1 tick डेटा पर tick2 के प्रभाव की भविष्यवाणी
तालिका 3 1 tick डेटा पर tick2 के प्रभाव की भविष्यवाणी तालिका 4 2tick डेटा के साथ 2tick के प्रभाव की भविष्यवाणी
तालिका 4 2tick डेटा के साथ 2tick के प्रभाव की भविष्यवाणीउपरोक्त तीन तालिकाओं के आंकड़ों से हम कुछ निष्कर्ष निकाल सकते हैं: उच्चतम सटीकता लगभग 70% तक पहुंचती है, और सटीकता 60% तक पहुंचती है, जिसे ट्रेडिंग रणनीति में परिवर्तित किया जा सकता है।
-
(ii) रणनीतिक अनुकरण
उदाहरण के लिए, 31 अक्टूबर को, हम अनुकरणीय व्यापार करते हैं, संस्थानों के स्टॉक इंडेक्स फ्यूचर ट्रेडिंग प्रसंस्करण शुल्क आम तौर पर है संस्थानों के स्टॉक इंडेक्स फ्यूचर ट्रेडिंग प्रसंस्करण शुल्क आम तौर पर 0.26⁄10000 है, हम मानते हैं कि व्यापार की संख्या को कोई सीमा नहीं है, मान लें कि प्रत्येक व्यापार एकतरफा स्लाइड मूल्य 0.2 है, और प्रत्येक आदेश 1 हाथ है।
तालिका 5 31 अक्टूबर को अनुकरण रणनीति पर ट्रेडों की स्थिति

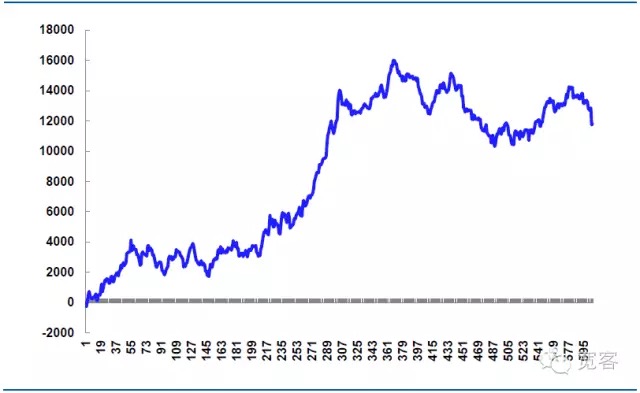
दिन भर में 605 ट्रेडों में से 339 ट्रेडों में जीत दर्ज की गई, 56% जीत दर्ज की गई और कुल 11814.99 युआन का शुद्ध लाभ हुआ।
सैद्धांतिक गिरावट की कीमत 14520 युआन है, जो रणनीतिक युद्ध की कुंजी है, यदि आदेश विवरण को अधिक बारीकी से नियंत्रित किया जाता है, तो गिरावट को कम किया जा सकता है, और शुद्ध लाभ बढ़ाया जा सकता है, यदि आदेश विवरण को अनुचित रूप से नियंत्रित किया जाता है, या बाजार में उतार-चढ़ाव असामान्य है, तो गिरावट अधिक होगी, और शुद्ध लाभ कम हो जाएगा, इसलिए उच्च आवृत्ति व्यापार की सफलता अक्सर विवरण के निष्पादन पर निर्भर करती है।
चित्र 7 31 अक्टूबर को अनुकरण रणनीति का लाभ
मूल निबंध लेखक का है। कृपया स्रोत बताएं।