मस्तिष्क में सहायक वेक्टर मशीनें
 0
2022
0
2022
मस्तिष्क में सहायक वेक्टर मशीनें
समर्थित वेक्टर मशीन (एसवीएम) एक महत्वपूर्ण मशीन सीखने वर्गीकरण है, जो कम आयाम की विशेषताओं को उच्च आयाम में प्रोजेक्ट करने के लिए एक चतुर गैर-रैखिक परिवर्तन का उपयोग करता है, जो अधिक जटिल वर्गीकरण कार्यों को निष्पादित करता है। एसवीएम एक गणितीय चाल का उपयोग करता है, जो वास्तव में मस्तिष्क कोडिंग की कार्यप्रणाली के अनुरूप होता है। हम 2013 के एक प्रकृति लेख से पढ़ सकते हैं और मशीन सीखने और मस्तिष्क के कामकाज के सिद्धांतों के बीच गहरे संबंधों को समझ सकते हैं। लेख का नामः जटिल संज्ञानात्मक कार्यों में मिश्रित चयनात्मकता का महत्व (ओमरी बराक एएल द्वारा)
- #### SVM
यह आश्चर्यजनक संबंध कहाँ से आ सकता है? सबसे पहले हम बात करते हैं तंत्रिका-कोडिंग की प्रकृति के बारे में: जानवर एक निश्चित संकेत प्राप्त करते हैं और उसके अनुसार एक निश्चित कार्य करते हैं, एक बाहरी संकेत को तंत्रिका विद्युत संकेत में परिवर्तित करना है, दूसरा तंत्रिका विद्युत संकेत को निर्णय संकेत में परिवर्तित करना है, पहले की प्रक्रिया को एन्कोडिंग कहा जाता है, और बाद की प्रक्रिया को डिकोडिंग कहा जाता है। और तंत्रिका-कोडिंग का वास्तविक उद्देश्य इसे डिकोड करना है और फिर निर्णय लेना है। इसलिए, मशीन लर्निंग के साथ नेत्र कोड को देखने का सबसे आसान तरीका एक वर्गीकरण है, या यहां तक कि एक लॉजिस्टिक मॉडल के लिए एक रैखिक वर्गीकरण है, जो इनपुट संकेतों को कुछ विशेषताओं के आधार पर वर्गीकृत करता है। जैसे कि एक बाघ को भागते हुए देखना, एक मुर्गी को खाने को देखना, बेशक, कभी-कभी यह अच्छा होता है, उदाहरण के लिए, जब एक तंत्रिका सिग्नल को गति में परिवर्तित किया जाता है, तो यह एक बड़ी मात्रा में तंत्रिका गतिशीलता के लिए एक तंत्र के रूप में रूपांतरण की आवश्यकता होती है, जैसे कि
तो हम देखेंगे कि न्यूरॉन कोडिंग कैसे होती है, सबसे पहले न्यूरॉन को मूल रूप से एक आरसी सर्किट के रूप में देखा जा सकता है जो प्रतिरोध और क्षमता को बाहरी वोल्टेज के आधार पर समायोजित करता है, जब बाहरी सिग्नल पर्याप्त बड़ा होता है, तो यह बंद हो जाता है, अन्यथा यह बंद हो जाता है, एक संकेत को दर्शाता है जो एक निश्चित समय में उत्सर्जित होता है। और हम कोडिंग के बारे में बात करते हैं, अक्सर समय के लिए एक विखंडन प्रसंस्करण करते हैं, यह मानते हुए कि एक छोटी समय की खिड़की में, यह उत्सर्जन दर अपरिवर्तित है, इस प्रकार एक तंत्रिका नेटवर्क इस समय की खिड़की में कोशिकाओं की उत्सर्जन दर को एक साथ देख सकता है एक एन आयामी दिशा, एन न्यूरॉन की संख्या है, यह एन आयामी मात्रा, हम इसे जोड़ते हैं और इसे एक एन्कोडिंग मात्रा कहते हैं, जो जानवरों को एक छवि देख सकती है, या ध्वनि सुन सकती है, जो संबंधित परतों के तंत्रिका नेटवर्क को उत्पन्न करेगी - यानी बाहरी सिग्नल की उपस्थिति। हम इस नेटवर्क पर गहराई से ध्यान नहीं देते हैं।
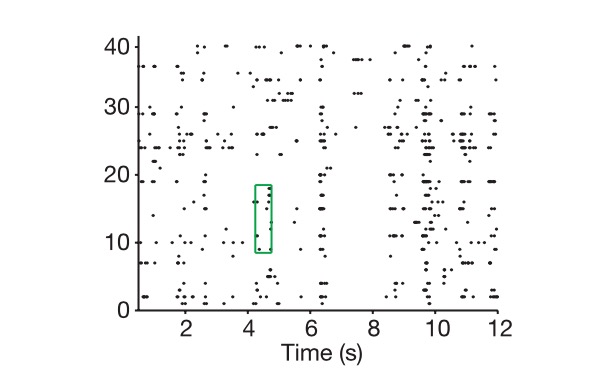
चित्रः ऊर्ध्वाधर अक्ष कोशिकाओं के लिए है, और क्षैतिज अक्ष समय के लिए है, और चित्र दिखाता है कि हम कैसे न्यूरो-कोडिंग निकालने
बेशक, N-dimensional vector और neural encoding के वास्तविक आयाम अलग हैं, लेकिन neural encoding के वास्तविक आयाम को कैसे परिभाषित किया जाए? सबसे पहले, हम इस N-dimensional vector द्वारा चिह्नित N-dimensional space में जाते हैं, और फिर हम सभी संभव कार्य संयोजन देते हैं, जैसे कि आपको एक हजार चित्र दिखाते हैं, मान लें कि ये चित्र पूरी दुनिया का प्रतिनिधित्व करते हैं, और हर बार जब हम एक neural encoding प्राप्त करते हैं, तो हम इसे इस अंतरिक्ष में एक बिंदु के रूप में चिह्नित करते हैं, और अंत में हम वेक्टर बीजगणित की सोच का उपयोग करते हैं और इस हजार बिंदुओं के रूप में बनाए गए उप-स्थान के आयामों को देखते हैं, जिसे एक neural representation के वास्तविक आयाम के रूप में पहचाना जाता है। मैं मानता हूं कि सभी बिंदु वास्तव में इस N-dimensional space में एक पंक्ति पर हैं, तो यह representation एक आयामी है, और यदि सभी बिंदु एक उच्च-आयामी दो-आयामी समतल पर हैं, तो यह 2 आयामी है। वैज्ञानिकों ने पाया है कि neural encoding आमतौर पर बहुत अधिक आया
कोडिंग के वास्तविक आयाम के अलावा, हमारे पास एक और अवधारणा है कि बाहरी सिग्नल का वास्तविक आयाम है, यहां सिग्नल एक तंत्रिका नेटवर्क द्वारा व्यक्त किए गए बाहरी सिग्नल को संदर्भित करता है, और निश्चित रूप से आपको बाहरी सिग्नल के सभी विवरणों को दोहराना होगा यह एक असीमित समस्या है, लेकिन हमारे वर्गीकरण और निर्णय का आधार हमेशा महत्वपूर्ण विशेषताएं हैं, एक आयाम घटाने की प्रक्रिया है, यह पीसीए का विचार भी है। यहाँ हम वास्तविक कार्य में महत्वपूर्ण चर को कार्य के वास्तविक आयाम के रूप में देख सकते हैं, जैसे कि आप एक हाथ की गति को नियंत्रित करना चाहते हैं, आपको आमतौर पर केवल जोड़ों के घूर्णन कोण को नियंत्रित करने की आवश्यकता होती है, और यदि आप इसे एक ठोस गतिशीलता समस्या के रूप में लेते हैं, तो आयाम शायद 10 से अधिक नहीं होंगे, हम इसे के कहते हैं। यहां तक कि अगर यह एक व्यक्ति के चेहरे को पहचानने की समस्या है, तो आयाम की समस्या अभी भी बहुत कम है।
तो वैज्ञानिकों के सामने एक मुख्य सवाल है कि क्यों हम इस समस्या को वास्तविक समस्या से कहीं अधिक कोडिंग आयामों और न्यूरॉन्स की संख्या के साथ हल करते हैं? क्या यह एक बर्बादी नहीं है?
और कम्प्यूटेशनल न्यूरोसाइंस और मशीन लर्निंग के साथ मिलकर हमें बताता है कि न्यूरोइंटरप्रेजेंटेशन की उच्च आयामी विशेषताएं वास्तव में इसकी मजबूत सीखने की क्षमताओं का आधार हैं ☺ कोड आयाम जितना अधिक होता है, सीखने की क्षमता उतनी ही अधिक होती है ☺ ध्यान दें कि हम यहां गहराई नेटवर्क के बारे में भी बात नहीं कर रहे हैं ☺ ऐसा क्यों है ☺ हम यहां न्यूरोइंटरप्रेजेंटेशन के तंत्र के बारे में बात कर रहे हैं जो एसवीएम के समान सिद्धांतों का उपयोग करता है ☺ जब हम एक कम आयामी सिग्नल को उच्च आयाम में प्रोजेक्ट करते हैं, तो हम जितना अधिक वर्गीकरण कर सकते हैं ☺ यहां तक कि एक रैखिक वर्गीकरणकर्ता के रूप में, आप अनगिनत प्रश्नों को हल कर सकते हैं ☺ यह कैसे किया जाता है ☺ और यह कैसे एसवीएम के समर्थन के साथ संगत है ☺
ध्यान दें कि यहां चर्चा की गई तंत्रिका कोड मुख्य रूप से उच्च तंत्रिका केंद्रों के तंत्रिका कोड को संदर्भित करता है, जैसे कि लेख में चर्चा की गई प्रीफ्रंटल कॉर्टेक्स (पीएफसी), क्योंकि निम्न तंत्रिका केंद्रों के कोड नियम वर्गीकरण और निर्णय लेने में बहुत अधिक शामिल नहीं हैं।
पीएफसी के रूप में उच्च मस्तिष्क क्षेत्र
पहले, हम मान लेते हैं कि जब हमारे एन्कोडिंग आयाम वास्तविक कार्यों में महत्वपूर्ण चर के आयामों के बराबर होते हैं, तो हम एक रैखिक वर्गीकरणकर्ता का उपयोग करके गैर-रैखिक वर्गीकरण समस्याओं को हल करने में असमर्थ होंगे (मान लें कि आप एक शहद से शहद को अलग करना चाहते हैं, और आप एक रैखिक सीमा के साथ शहद को शहद से शहद को अलग नहीं कर सकते हैं), और यह भी एक विशिष्ट समस्या है जिसे हम डीप लर्निंग और एसवीएम के बिना हल करने के लिए संघर्ष करते हैं मशीन सीखने में। इस तरह की समस्याओं के लिए एसवीएम के मूल व्याख्या को पुनः प्रतिनिधित्व के रूप में जाना जाता है, यानी हमारे मूल कोऑर्डिनेट सिस्टम को एक नए उच्च आयामी कोऑर्डिनेट सिस्टम में बदलना, यह दर्शाता है कि हम अभी भी ओवरलैप वर्गीकरण के लिए रैखिक वर्गीकरण विधि का उपयोग कर सकते हैं, यहां तक कि अगर आप इसे नीचे दिए गए ग्राफ में देखते हैं, तो यह अभी भी मूर्खतापूर्ण है, और यहां तक कि अगर आप इसे समझते हैं कि शहद और शहद के बीच का अंतरः
SVM ((वेक्टर समर्थित):
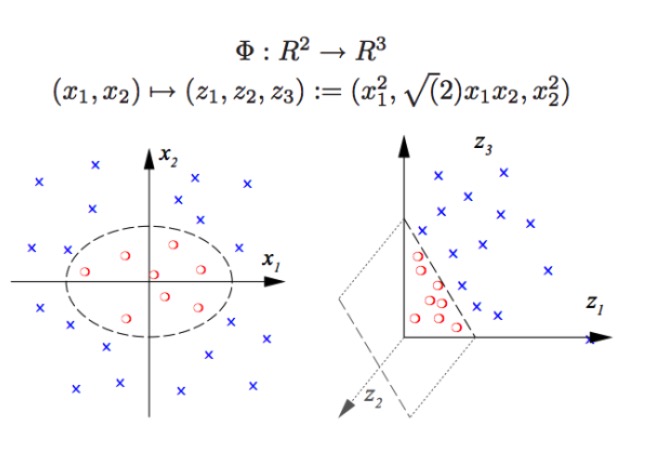
एसवीएम गैर-रैखिक वर्गीकरण कर सकते हैं, उदाहरण के लिए, चित्र में लाल और नीले बिंदुओं को अलग, एक रैखिक सीमा के साथ हम लाल और नीले बिंदुओं को अलग नहीं कर सकते हैं, इसलिए एसवीएम का उपयोग करने का तरीका आयामों को बढ़ाना है। जबकि केवल चर की संख्या में वृद्धि करना असंभव है, उदाहरण के लिए, सिस्टम को मैप करना (एक्स 1, एक्स 2) ।*x2, x2^2) और हम वास्तव में निम्न आयामों से उच्च आयामों तक की यात्रा कर रहे हैं, और आप नीले रंग के बिंदुओं को हवा में फेंक देते हैं, और फिर आप हवा में एक विमान बनाते हैं और आप नीले रंग के बिंदुओं को लाल रंग के बिंदुओं से अलग करते हैं, जैसा कि दाईं ओर दिखाया गया है।
वास्तव में, वास्तविक तंत्रिका नेटवर्क ऐसा ही करते हैं। इस तरह के एक रैखिक वर्गीकरणकर्ता (डीकोडर) द्वारा किए जा सकने वाले वर्गीकरण की विविधता में काफी वृद्धि हुई है, जिसका अर्थ है कि हमें पहले की तुलना में बहुत अधिक पैटर्न पहचानने की क्षमता मिली है। यहाँ, उच्च आयाम उच्च ऊर्जा है, उच्च आयाम हड़ताल सत्य है।
तो, कैसे एक उच्च आयाम के लिए न्यूरॉन कोड? प्रकाश न्यूरॉन्स की एक अधिक संख्या का कोई उपयोग नहीं है. क्योंकि हम जानते हैं कि हम एक रैखिक बीजगणित के माध्यम से जानते हैं कि अगर हम एक बड़ी संख्या में N न्यूरॉन्स है, और प्रत्येक न्यूरॉन के निर्वहन दर केवल K महत्वपूर्ण विशेषता के साथ रैखिक रूप से संबंधित है, तो हम अंत में आयाम को दर्शाता है कि केवल समस्या के आयाम के बराबर है, अपने N न्यूरॉन्स के लिए कोई मतलब नहीं है (अधिकता न्यूरॉन्स पहले के लिए K न्यूरॉन्स के एक रैखिक संयोजन है). यदि आप इस बिंदु को तोड़ने के लिए, आप के साथ K विशेषता के गैर-रैखिक रूप से संबंधित न्यूरॉन्स की जरूरत है, यहाँ हम कहा जाता है गैर-रैखिक मिश्रित प्रकार के न्यूरॉन्स, और इस प्रकार के न्यूरॉन्स की उपस्थिति बहुत जटिल है, और सिद्धांत रूप में एसवीएम में गैर-रैखिक तत्वों के साथ अपने नाभिक फ़ंक्शन के समान है.
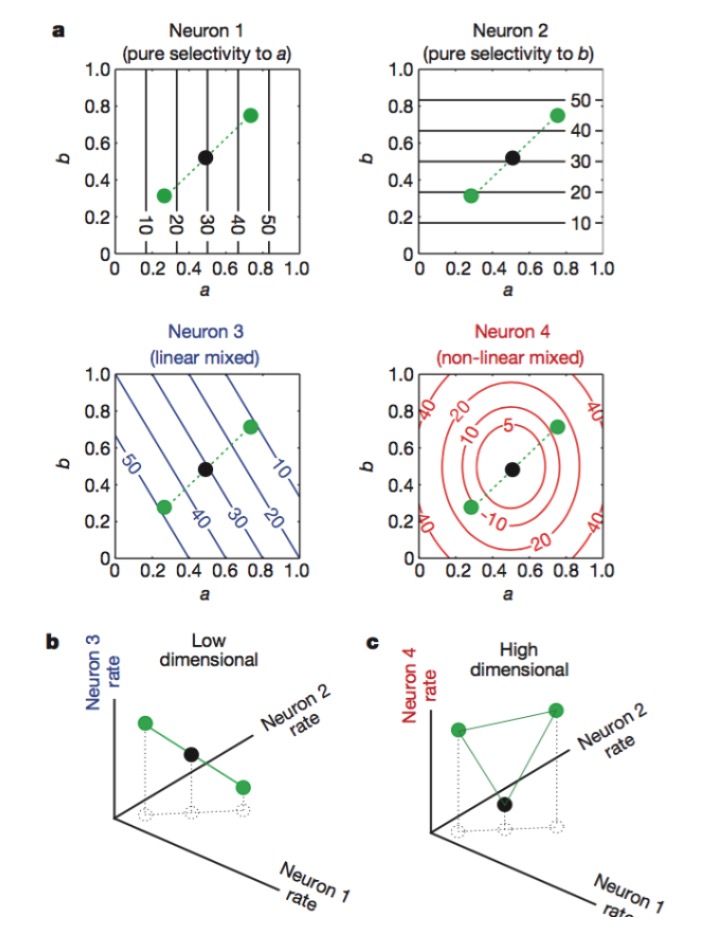
चित्रः न्यूरॉन्स 1 और 2 क्रमशः केवल विशेषता a और b के लिए संवेदनशील हैं, 3 विशेषता a और b के रैखिक मिश्रण के लिए संवेदनशील हैं, और 4 विशेषता के गैर-रैखिक मिश्रण के लिए संवेदनशील हैं। अंततः केवल न्यूरॉन्स 1, 2, 4 के संयोजन से न्यूरॉन-कोडिंग आयाम में वृद्धि होती है (नीचे चित्र) ।
इस प्रकार के कोडिंग को आधिकारिक तौर पर मिश्रित कोडिंग कहा जाता है, जिसे हम समझ नहीं पाते हैं जब लोगों को इस प्रकार के कोडिंग के सिद्धांत का पता नहीं चलता है, क्योंकि यह एक तंत्रिका नेटवर्क है जो एक निश्चित प्रकार के संकेत के लिए बहुत खराब प्रतिक्रिया देता है। आस-पास के तंत्रिका तंत्र में, न्यूरॉन्स एक सेंसर की तरह काम करते हैं, जो संकेतों की विभिन्न विशेषताओं को निकालते हैं और पहचानते हैं। प्रत्येक न्यूरॉन का कार्य काफी विशिष्ट है, जैसे कि रेटिना के रॉड्स और शंकु प्रकाश प्राप्त करने के लिए जिम्मेदार हैं, और फिर गैंगेलियन सेल कोडिंग जारी रखते हैं, प्रत्येक न्यूरॉन एक विशेष रूप से प्रशिक्षित चौकीदार की तरह है। जबकि मस्तिष्क के उच्च क्षेत्रों में, यह स्पष्ट भेद करना मुश्किल है, हम पाते हैं कि एक ही न्यूरॉन विभिन्न विशेषताओं के लिए संवेदनशील हो सकता है, और यह भी कि यह संवेदनशीलता रैखिक नहीं है। यह विभिन्न प्रकार के कार्यों के लिए एक साथ काम करने के बारे में सोचने के बारे में है, और यह विशेषताओं को खोजने के लिए बहुत मुश्किल है, क्योंकि यह विशेषताओं को अलग करने के लिए एक विशेष तरीका है जो संकेतों
प्रकृति के हर विवरण में अंतर्निहित है, बहुत सारे रिडंडेंसी और मिश्रित कोड जो कि अव्यवसायिक दिखता है, जो कि एक अराजक सिग्नल की तरह दिखता है, जो अंततः बेहतर कंप्यूटिंग क्षमता प्राप्त करता है। इस सिद्धांत के बाद, हम आसानी से कुछ कार्यों को संभाल सकते हैं जैसेः
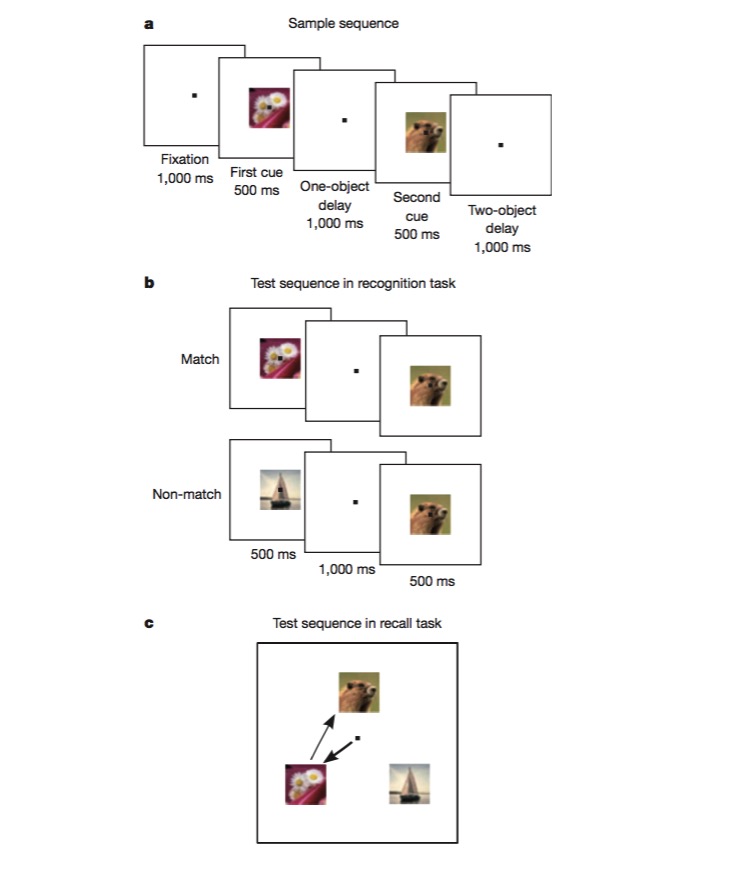
इस कार्य में, पहले चूहे को प्रशिक्षित किया जाता है कि क्या एक छवि पहले की तरह है या नहीं, और फिर दो अलग-अलग छवियों के क्रम का न्याय करने के लिए प्रशिक्षित किया जाता है। इस तरह के कार्य को पूरा करने के लिए चूहे को कार्य के विभिन्न पक्षों को कोड करने में सक्षम होना चाहिए, जैसे कि कार्य प्रकार, छवि प्रकार, आदि, और यह एक उत्कृष्ट परीक्षण है कि क्या मिश्रित गैर-रैखिक कोडिंग तंत्र मौजूद है। प्रयोगों में पुष्टि की गई है कि बड़ी संख्या में न्यूरॉन्स वास्तव में मिश्रित विशेषताओं के लिए संवेदनशील हैं, और गैर-रैखिक हैं।
इस लेख के माध्यम से, हम जानते हैं कि कुछ गैर-रैखिक इकाइयों को शामिल करने से पैटर्न पहचान की क्षमता में काफी सुधार हो सकता है, और एसवीएम ने इसे लागू किया है, गैर-रैखिक वर्गीकरण की समस्या को दूर करने के लिए। और न्यूरोसाइंस और मशीन लर्निंग को एक सिक्के के दो पहलुओं के रूप में गणना करना।
हम मस्तिष्क के क्षेत्रों के कार्यों का अध्ययन करते हैं, पहले मशीन सीखने के तरीकों से डेटा को संसाधित करते हैं, जैसे कि पीसीए द्वारा समस्या के महत्वपूर्ण आयामों को खोजने के लिए, फिर मशीन सीखने के पैटर्न की पहचान करने वाले दिमाग को समझते हैं कि न्यूरोकोडिंग और डिकोडिंग कैसे करें, और अंत में, अगर हमें कुछ नई प्रेरणा मिलती है, तो हम मशीन सीखने के तरीकों को सुधार सकते हैं। मस्तिष्क या मशीन सीखने के एल्गोरिदम के लिए, अंततः सबसे महत्वपूर्ण बात यह है कि जानकारी को सबसे उपयुक्त रूप से प्रदर्शित करने का सबसे उपयुक्त तरीका प्राप्त करें, और अच्छी तरह से प्रदर्शित करने के लिए, सब कुछ आसान है। यह मशीन सीखने की एक चरणबद्ध प्रक्रिया है जो रैखिक तर्क से वापस आया है, जो मशीन के लिए समर्थन करता है, और गहरी सीखने के लिए, शायद यह भी है कि हम मस्तिष्क को विकसित करने के लिए विकसित कर सकते हैं, दुनिया को नियंत्रित करने की एक बढ़ती क्षमता के साथ। या शायद विकास का उद्देश्य स्पष्ट रूप से स्पष्ट होना चाहिए कि कौन सा बाघ है और कौन सा भेड़िया है, और कौन सो सकता है, लेकिन इस प्रक्रिया में, दुनिया को समझने के लिए एक गहरी समझ विकसित होती है, साथ ही साथ प्यार
Image caption चीन के नौसैनिकों के लिए यह एक चुनौती है