क्या डीप लर्निंग का उपयोग लेनदेन को मात्रात्मक बनाने के लिए किया जा सकता है
लेखक:आविष्कारक मात्रा - छोटे सपने, बनाया गयाः 2017-07-11 13:38:28, अद्यतन किया गयाः 2017-07-11 13:39:18क्या डीप लर्निंग का उपयोग लेनदेन को मात्रात्मक बनाने के लिए किया जा सकता है
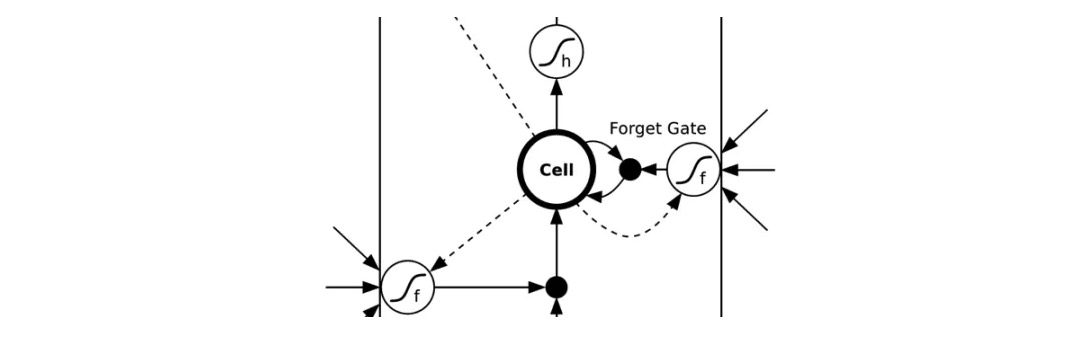
- ### हो सकता है, लेकिन भविष्यवाणियों के साथ नहीं खेलते हैं ((उच्च आवृत्ति व्यापार को छोड़कर))
मैं कई लेखों को देखता हूं, सार्वजनिक पत्रिकाओं या ब्रोकरों ने लेखों के बारे में लिखा है कि डीप लर्निंग को इनपुट के रूप में ऐतिहासिक संकेतकों पर आधारित है, एलएसटीएम जैसे नेटवर्क का उपयोग करके भविष्य के शेयरों, वायदा की आय को भविष्यवाणी करने के लिए, और व्यापार रणनीति के रूप में मेल खाने के लिए। इस तरह से मैंने मूल रूप से कोशिश की है, या तो वर्गीकरण के माध्यम से, या प्रतिगमन के माध्यम से भविष्यवाणी करने के लिए, परिणाम खराब हैं। और आउटपुट बहुत अधिक झुकाव है।
यहां नई तकनीकों का उपयोग करके स्टॉक जैसे परिसंपत्तियों की कीमतों का अनुमान लगाने के बारे में बात नहीं की जा रही है, लेकिन सबसे पहले, यह स्पष्ट करने के लिए कि आप भविष्य की भविष्यवाणी क्यों कर सकते हैं? यह ऐतिहासिक डेटा पर आधारित भविष्य की भविष्यवाणी करने की धारणा मजबूत है, एक मजबूत परिकल्पना के तहत, एक ब्लैक बॉक्स के साथ रन में एक कठिन जीत का परिणाम है। यह विश्वास करना मुश्किल है। यही कारण है कि वित्तीय अनुप्रयोगों में निर्णय पेड़ जैसे एल्गोरिदम थोड़ा अधिक हैं।
तो इस तरह की अच्छी नई तकनीक का उपयोग कैसे किया जाता है? डीप लर्निंग छवि वर्गीकरण के लिए उपयुक्त है, कुंजी यह है कि छवि और नाम के बीच एक स्थिर डेटा आयाम सहसंबंध है, जो अधिक जटिल है, लेकिन संबंध स्थिर है। और वित्तीय अनुक्रम अलग हैं, ऐतिहासिक डेटा भविष्य की भविष्यवाणी करने के लिए तर्क में ही अस्थिर है, जो इस तरह के एक जटिल उपकरण के साथ परिणामों को केवल अधिक भ्रमित करता है। लेकिन वास्तव में, डीप लर्निंग में विशेष रूप से उपयुक्त अनुप्रयोग है, विशेष रूप से मैं क्या कहना सुविधाजनक नहीं हूं, इस तरह के अनुप्रयोग की विशेषता निश्चित रूप से स्थिर सहसंबंध है।
ज़ेनो क्वांटिफ़िकेशन से पुनर्प्रकाशित
- K लाइन कार है, सममित लाइन सड़क है!
- कुछ एक्सचेंजों के लिए दोहराव संतुलन के मुद्दे
- वैज्ञानिक और दार्शनिक दृष्टिकोण से, बिना तर्क के रणनीति पर विश्वास कैसे करें?
- बहुमुखी प्रवृत्ति पीछे हटने की रणनीति
- यह एक बहुत ही महत्वपूर्ण और महत्वपूर्ण मुद्दा है, लेकिन यह एक बहुत ही महत्वपूर्ण मुद्दा है।
- स्थायी रूप से प्रभावी व्यापार मॉडल
- सूचकांकः कृपया ओकेएक्स अनुबंध के बारे में पूछें, क्या कोई सूचकांक है? क्या यह सूचकांक एपीआई के साथ पढ़ा जा सकता है?
- मल्टी-प्लेटफॉर्म हेजिंग स्टेबिलिटी सट्टेबाजी V2.1 (नोट)
- Bitcoin ने ETC को खोला, आविष्कारकों ने क्वांटिफाइड किया, ETC कब समर्थित होगा?
- ब्लॉकचेन तकनीक के चार महत्वपूर्ण तकनीकी बिंदु जो आपको पता होने चाहिए!
- OKEX के फ्यूचर्स की गहराई क्यों केवल 5 हैं?
- पेंडोरा का आकर्षक बॉक्सः कैसे वित्तीय व्यापारी जोखिम मुक्त वसा खाते हैं
- नए लोगों के लिए सवाल. GetRecords द्वारा प्राप्त K-लाइन डेटा और रीट्रेस किए गए चार्ट वास्तविक डेटा के साथ असंगत हैं।
- गर्मियों की गर्मी, टोकन के साथ आविष्कारक को मात्रात्मक रूप से जोड़ें, 5 छूट आपको मात्रा व्यापार शुरू करने के लिए आमंत्रित करते हैं
- पायथन संस्करण TableTemplet
- लेनदेन को चरम पर लाएंः सैद्धांतिक सीमाएं और लेनदेन प्रणाली
- एक्सचेंज लेबल पर नहीं दिखाई जाने वाली मुद्राओं को कैसे अनुकूलित करें जब आप डिजिटल मुद्रा व्यापार रोबोट बनाते हैं
- [Python] इंटरफ़ेस पर प्रदर्शित लॉगस्टेटस फ़ंक्शन
- [Python] इंटरफ़ेस पर प्रदर्शित लॉगस्टेटस फ़ंक्शन
- एक्सचेंज की प्रक्रियाओं का सारांश