ट्रेडिंग में मशीन लर्निंग तकनीक का अनुप्रयोग
 3
3650
3
3650

यह पोस्ट इन्वेंटर क्वांट प्लेटफॉर्म पर डेटा शोध के दौरान ट्रेडिंग समस्याओं पर मशीन लर्निंग तकनीक लागू करने के प्रयास के बाद कुछ सामान्य चेतावनियों और नुकसानों के बारे में मेरे अवलोकन से प्रेरित है।
यदि आपने मेरा पिछला लेख नहीं पढ़ा है, तो हम अनुशंसा करते हैं कि आप इस लेख से पहले इन्वेंटर क्वांटिटेटिव प्लेटफॉर्म पर स्थापित स्वचालित डेटा अनुसंधान वातावरण और ट्रेडिंग रणनीतियों को विकसित करने के लिए व्यवस्थित दृष्टिकोण के बारे में मेरी पिछली मार्गदर्शिका पढ़ें।
पते यहां हैं: https://www.fmz.com/digest-topic/4187 और https://www.fmz.com/digest-topic/4169.
अनुसंधान वातावरण की स्थापना के बारे में
यह ट्यूटोरियल सभी कौशल स्तरों के उत्साही, इंजीनियरों और डेटा वैज्ञानिकों के लिए डिज़ाइन किया गया है। चाहे आप उद्योग विशेषज्ञ हों या प्रोग्रामिंग के नौसिखिए, आपको केवल पायथन प्रोग्रामिंग भाषा की बुनियादी समझ और कमांड लाइन संचालन का पर्याप्त ज्ञान होना चाहिए। (डेटा विज्ञान परियोजना स्थापित करने की क्षमता पर्याप्त है)
- इन्वेंटर क्वांट होस्टर स्थापित करना और एनाकोंडा सेट अप करना
प्रमुख मुख्यधारा एक्सचेंजों से उच्च गुणवत्ता वाले डेटा स्रोत प्रदान करने के अलावा, इन्वेंटर क्वांटिटेटिव प्लेटफॉर्म FMZ.COM हमें डेटा विश्लेषण पूरा करने के बाद स्वचालित लेनदेन करने में मदद करने के लिए API इंटरफेस का एक समृद्ध सेट भी प्रदान करता है। इंटरफेस के इस सेट में व्यावहारिक उपकरण शामिल हैं जैसे खाता जानकारी की क्वेरी करना, उच्च, प्रारंभिक, निम्न, समापन मूल्य, ट्रेडिंग वॉल्यूम, विभिन्न मुख्यधारा के एक्सचेंजों के विभिन्न आमतौर पर इस्तेमाल किए जाने वाले तकनीकी विश्लेषण संकेतक आदि की क्वेरी करना, विशेष रूप से वास्तविक समय में प्रमुख मुख्यधारा के एक्सचेंजों से जुड़ने के लिए। ट्रेडिंग प्रक्रियाएं। सार्वजनिक एपीआई इंटरफ़ेस शक्तिशाली तकनीकी सहायता प्रदान करता है।
ऊपर बताई गई सभी विशेषताएं Docker जैसी ही एक प्रणाली में समाहित हैं। हमें बस इतना करना है कि अपनी खुद की क्लाउड कंप्यूटिंग सेवा खरीदनी है या किराए पर लेनी है और फिर Docker सिस्टम को तैनात करना है।
इन्वेंटर क्वांटिटेटिव प्लेटफॉर्म के आधिकारिक नाम में, इस डॉकर सिस्टम को होस्ट सिस्टम कहा जाता है।
होस्ट और रोबोट को तैनात करने के तरीके के बारे में अधिक जानकारी के लिए, कृपया मेरा पिछला लेख देखें: https://www.fmz.com/bbs-topic/4140
जो पाठक अपना स्वयं का क्लाउड कंप्यूटिंग सर्वर परिनियोजन होस्ट खरीदना चाहते हैं, वे इस लेख का संदर्भ ले सकते हैं: https://www.fmz.com/bbs-topic/2848
क्लाउड कंप्यूटिंग सेवा और होस्ट सिस्टम को सफलतापूर्वक तैनात करने के बाद, हम सबसे शक्तिशाली पायथन टूल स्थापित करेंगे: एनाकोंडा
इस आलेख के लिए आवश्यक सभी प्रासंगिक प्रोग्राम वातावरण (आश्रित लाइब्रेरीज़, संस्करण प्रबंधन, आदि) को प्राप्त करने के लिए, सबसे आसान तरीका एनाकोंडा का उपयोग करना है। यह एक पैकेज्ड पायथन डेटा विज्ञान पारिस्थितिकी तंत्र और निर्भरता प्रबंधक है।
चूंकि हम एनाकोंडा को क्लाउड सेवा पर स्थापित कर रहे हैं, इसलिए हम अनुशंसा करते हैं कि आप लिनक्स सिस्टम के साथ-साथ एनाकोंडा का कमांड लाइन संस्करण भी क्लाउड सर्वर पर स्थापित करें।
एनाकोंडा की स्थापना विधि के लिए, कृपया एनाकोंडा की आधिकारिक मार्गदर्शिका देखें: https://www.anaconda.com/distribution/
यदि आप एक अनुभवी पायथन प्रोग्रामर हैं और एनाकोंडा का उपयोग करने की आवश्यकता महसूस नहीं करते हैं, तो यह बिल्कुल ठीक है। मैं यह मानूंगा कि आपको आवश्यक निर्भरताएं स्थापित करने में सहायता की आवश्यकता नहीं है और आप इस अनुभाग को छोड़ सकते हैं।
एक व्यापारिक रणनीति विकसित करें
किसी ट्रेडिंग रणनीति के अंतिम आउटपुट में निम्नलिखित प्रश्नों के उत्तर होने चाहिए:
निर्देश: निर्धारित करें कि कोई परिसंपत्ति सस्ती है, महंगी है, या उचित मूल्य पर है।
प्रारंभिक शर्तें: यदि परिसंपत्ति की कीमत सस्ती या महंगी है, तो आपको लॉन्ग या शॉर्ट जाना चाहिए।
व्यापार बंद करें: यदि परिसंपत्ति का मूल्य उचित है और हमारे पास उस परिसंपत्ति में कोई स्थिति है (पिछली खरीद या बिक्री), तो क्या आपको स्थिति बंद कर देनी चाहिए?
मूल्य सीमा: वह मूल्य (या सीमा) जिस पर व्यापार खोला जाता है
मात्रा: कारोबार की गई धनराशि की मात्रा (जैसे डिजिटल मुद्रा की मात्रा या कमोडिटी फ्यूचर्स के लॉट की संख्या)
इनमें से प्रत्येक प्रश्न का उत्तर देने के लिए मशीन लर्निंग का उपयोग किया जा सकता है, लेकिन इस लेख के बाकी भाग में हम पहले प्रश्न का उत्तर देने पर ध्यान केंद्रित करेंगे, जो कि व्यापार की दिशा से संबंधित है।
रणनीतिक दृष्टिकोण
रणनीति बनाने के लिए दो प्रकार के दृष्टिकोण हैं, एक मॉडल-आधारित और दूसरा डेटा माइनिंग-आधारित। ये दोनों मूलतः विपरीत दृष्टिकोण हैं।
मॉडल-आधारित रणनीति निर्माण में, हम बाजार की अकुशलताओं के एक मॉडल से शुरुआत करते हैं, गणितीय अभिव्यक्तियों (जैसे, कीमतें, रिटर्न) का निर्माण करते हैं और लंबी समयावधि में उनकी प्रभावशीलता का परीक्षण करते हैं। यह मॉडल आमतौर पर वास्तविक जटिल मॉडल का सरलीकृत संस्करण होता है, तथा दीर्घावधि में इसके महत्व और स्थायित्व को सत्यापित करने की आवश्यकता होती है। सामान्य प्रवृत्ति अनुसरण, माध्य प्रत्यावर्तन और मध्यस्थता रणनीतियाँ इस श्रेणी में आती हैं।
दूसरी ओर, हम पहले मूल्य पैटर्न देखते हैं और डेटा माइनिंग विधियों में एल्गोरिदम का उपयोग करने का प्रयास करते हैं। इन पैटर्नों का कारण क्या है, यह महत्वपूर्ण नहीं है, क्योंकि यह निश्चित है कि ये पैटर्न भविष्य में भी दोहराए जाते रहेंगे। यह एक अंध विश्लेषण पद्धति है और हमें यादृच्छिक पैटर्न से वास्तविक पैटर्न की पहचान करने के लिए कठोर निरीक्षण की आवश्यकता होती है। “परीक्षण और त्रुटि”, “बार चार्ट पैटर्न” और “फीचर मास रिग्रेशन” इस श्रेणी में आते हैं।
स्पष्टतः, मशीन लर्निंग डेटा माइनिंग विधियों के लिए आसानी से उपयुक्त है। आइए देखें कि डेटा माइनिंग के माध्यम से ट्रेडिंग सिग्नल बनाने के लिए मशीन लर्निंग का उपयोग कैसे किया जा सकता है।
कोड उदाहरण इन्वेंटर क्वांटिटेटिव प्लेटफॉर्म पर आधारित बैकटेस्टिंग टूल और स्वचालित ट्रेडिंग एपीआई इंटरफेस का उपयोग करते हैं। होस्टर को तैनात करने और उपरोक्त अनुभाग में एनाकोंडा को स्थापित करने के बाद, आपको केवल डेटा विज्ञान विश्लेषण लाइब्रेरी और प्रसिद्ध मशीन लर्निंग मॉडल स्किकिट-लर्न को स्थापित करने की आवश्यकता है। हम इस भाग के बारे में विस्तार से नहीं बताएंगे।
pip install -U scikit-learn
ट्रेडिंग रणनीति संकेत बनाने के लिए मशीन लर्निंग का उपयोग करना
- डेटा खनन
आरंभ करने से पहले, एक मानक मशीन लर्निंग समस्या इस प्रकार दिखती है:
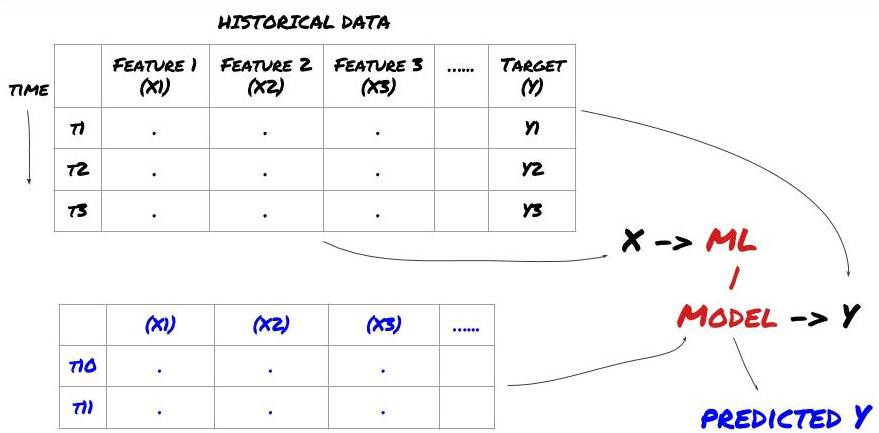
मशीन लर्निंग समस्या ढांचा
हम जो विशेषताएं बनाने जा रहे हैं उनमें कुछ पूर्वानुमान क्षमता (X) अवश्य होनी चाहिए, हम लक्ष्य चर (Y) का पूर्वानुमान लगाना चाहते हैं, तथा ऐतिहासिक डेटा का उपयोग कर एक ML मॉडल को प्रशिक्षित करना चाहते हैं जो Y का पूर्वानुमान यथासंभव वास्तविक मान के करीब लगा सके। अंततः, हम इस मॉडल का उपयोग नये डेटा पर पूर्वानुमान लगाने के लिए करते हैं जहां Y अज्ञात है। इससे हम पहले चरण पर पहुंचते हैं:
चरण 1: अपनी समस्या सेट करें
- आप क्या भविष्यवाणी करना चाहते हैं? अच्छा पूर्वानुमान क्या है? आप पूर्वानुमान परिणामों का मूल्यांकन कैसे करते हैं?
अर्थात्, हमारे उपरोक्त ढांचे में, Y क्या है?
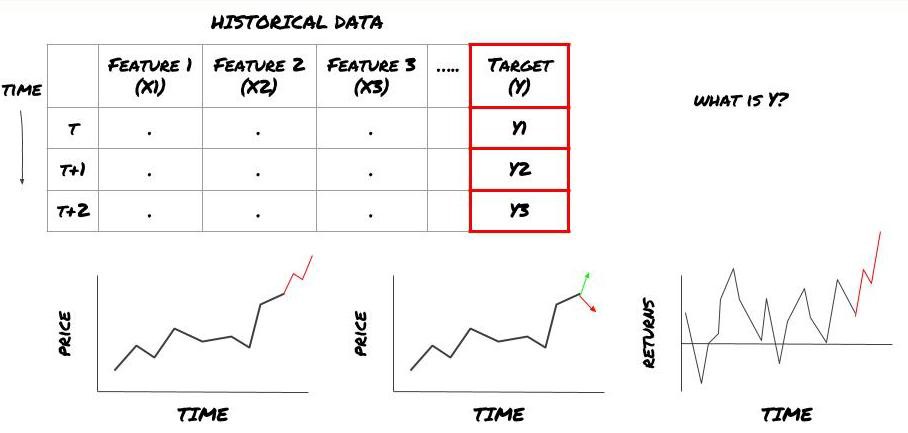
आप क्या भविष्यवाणी करना चाहते हैं?
क्या आप भावी कीमतों, भावी रिटर्न/पीएनएल, खरीद/बिक्री संकेतों का पूर्वानुमान लगाना चाहते हैं, पोर्टफोलियो आवंटन को अनुकूलित करना चाहते हैं और कुशलतापूर्वक ट्रेडों को निष्पादित करने का प्रयास करना चाहते हैं?
मान लीजिए हम अगले टाइमस्टैम्प पर कीमत का अनुमान लगाने की कोशिश कर रहे हैं। इस स्थिति में, Y(t) = मूल्य(t+1). अब हम ऐतिहासिक डेटा के साथ अपना ढांचा पूरा कर सकते हैं
ध्यान दें कि Y(t) केवल बैकटेस्ट में ही ज्ञात है, लेकिन जब हम अपने मॉडल का उपयोग करते हैं तो हमें समय t (t+1) पर कीमत ज्ञात नहीं होगी। हम अपने मॉडल का उपयोग Y(पूर्वानुमानित, t) का पूर्वानुमान लगाने के लिए करते हैं और इसकी तुलना केवल समय t+1 पर वास्तविक मान से करते हैं। इसका मतलब यह है कि आप पूर्वानुमान मॉडल में Y को एक विशेषता के रूप में उपयोग नहीं कर सकते।
एक बार जब हमें अपना लक्ष्य Y पता चल जाता है, तो हम यह भी तय कर सकते हैं कि अपनी भविष्यवाणियों का मूल्यांकन कैसे करें। यह हमारे डेटा पर आजमाए जाने वाले विभिन्न मॉडलों में अंतर करने के लिए महत्वपूर्ण है। हम जिस समस्या का समाधान कर रहे हैं उसके आधार पर, अपने मॉडल की दक्षता मापने के लिए एक मीट्रिक चुनें। उदाहरण के लिए, यदि हम कीमतों का पूर्वानुमान लगा रहे हैं, तो हम मीट्रिक के रूप में मूल माध्य वर्ग त्रुटि का उपयोग कर सकते हैं। कुछ सामान्य रूप से प्रयुक्त संकेतक (मूविंग एवरेज, एमएसीडी और विचरण स्कोर, आदि) को इन्वेंटर क्वांट टूलबॉक्स में पूर्व-कोडित किया गया है, और आप एपीआई इंटरफेस के माध्यम से इन संकेतकों को वैश्विक स्तर पर कॉल कर सकते हैं।
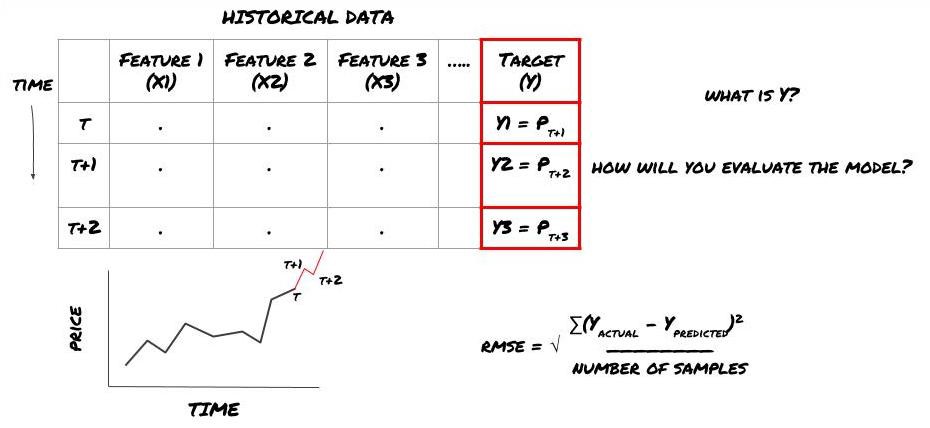
भविष्य की कीमतों की भविष्यवाणी के लिए एमएल ढांचा
प्रदर्शन के लिए, हम एक काल्पनिक निवेश लक्ष्य के भविष्य के अपेक्षित आधार मूल्य की भविष्यवाणी करने के लिए एक पूर्वानुमान मॉडल बनाएंगे, जहां:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
चूंकि यह एक प्रतिगमन समस्या है, इसलिए हम मॉडल का मूल्यांकन RMSE (रूट मीन स्क्वैयर्ड एरर) पर करेंगे। हम मूल्यांकन मानदंड के रूप में कुल पीएनएल का भी उपयोग करेंगे
नोट: RMSE के बारे में प्रासंगिक गणितीय ज्ञान के लिए, कृपया Baidu Encyclopedia की प्रासंगिक सामग्री देखें
- हमारा लक्ष्य: एक ऐसा मॉडल बनाना जो पूर्वानुमानित मानों को यथासंभव Y के करीब लाए।
चरण 2: विश्वसनीय डेटा एकत्र करें
ऐसे डेटा को एकत्रित और साफ़ करें जो आपकी समस्या को हल करने में आपकी मदद कर सकते हैं
लक्ष्य चर Y के लिए पूर्वानुमान शक्ति प्राप्त करने के लिए आपको किस डेटा पर विचार करने की आवश्यकता है? यदि हम कीमतों का पूर्वानुमान लगा रहे हैं, तो आप लक्ष्य मूल्य डेटा, लक्ष्य ट्रेडिंग मात्रा डेटा, संबंधित लक्ष्यों के लिए समान डेटा, समग्र बाजार संकेतक जैसे लक्ष्य सूचकांक स्तर, अन्य संबंधित परिसंपत्तियों की कीमतें आदि का उपयोग कर सकते हैं।
आपको इस डेटा के लिए डेटा एक्सेस अनुमतियाँ सेट करनी होंगी और यह सुनिश्चित करना होगा कि आपका डेटा सटीक है और गुम डेटा (एक बहुत ही सामान्य समस्या) को हल करना होगा। यह भी सुनिश्चित करें कि आपका डेटा निष्पक्ष हो और आपके मॉडल में पूर्वाग्रह से बचने के लिए सभी बाजार स्थितियों (जैसे, जीत/हार परिदृश्यों की समान संख्या) का पर्याप्त रूप से प्रतिनिधित्व करता हो। आपको लाभांश, पोर्टफोलियो विभाजन, निरंतरता आदि के लिए डेटा को भी साफ़ करने की आवश्यकता हो सकती है।
यदि आप इन्वेंटर क्वांटिटेटिव प्लेटफॉर्म (FMZ.COM) का उपयोग कर रहे हैं, तो हम Google, Yahoo, NSE और Quandl से मुफ्त वैश्विक डेटा तक पहुँच सकते हैं; CTP और Yisheng जैसे घरेलू कमोडिटी फ्यूचर्स से गहन डेटा; Binance, OKEX, Huobi और BitMex इन्वेंटर क्वांटिटेटिव प्लेटफॉर्म इस डेटा को पहले से साफ और फ़िल्टर भी करता है, जैसे कि निवेश लक्ष्य विभाजन और गहन बाजार डेटा, और इसे रणनीति डेवलपर्स के सामने ऐसे प्रारूप में प्रस्तुत करता है जिसे मात्रात्मक कार्यकर्ताओं के लिए समझना आसान होता है।
इस लेख की सुविधा के लिए, हम वर्चुअल निवेश लक्ष्य ‘MQK’ के रूप में निम्नलिखित डेटा का उपयोग करते हैं। हम Auquan’s Toolbox नामक एक बहुत ही सुविधाजनक मात्रात्मक उपकरण का भी उपयोग करते हैं। अधिक जानकारी के लिए, कृपया देखें: https://github.com/Auquan / auquan-टूलबॉक्स-पायथन
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
उपरोक्त कोड के साथ, ऑक्वान के टूलबॉक्स ने डेटा को डाउनलोड किया है और डेटा फ्रेम डिक्शनरी में लोड किया है। अब हमें डेटा को अपने पसंदीदा प्रारूप में तैयार करना होगा। फ़ंक्शन ds.getBookDataByFeature() डेटा फ़्रेमों का एक शब्दकोश लौटाता है, प्रत्येक फ़ीचर के लिए एक डेटा फ़्रेम। हम सभी सुविधाओं के साथ स्टॉक के लिए नया डेटाफ्रेम बनाते हैं।
चरण 3: डेटा को विभाजित करें
- डेटा से प्रशिक्षण सेट बनाएं, इन सेटों का क्रॉस-सत्यापन करें और उनका परीक्षण करें
यह एक काफी अहम कदम है! आगे बढ़ने से पहले, हमें आपके मॉडल को प्रशिक्षित करने के लिए डेटा को एक प्रशिक्षण डेटासेट में विभाजित करना चाहिए, और मॉडल के प्रदर्शन का मूल्यांकन करने के लिए एक परीक्षण डेटासेट में विभाजित करना चाहिए। अनुशंसित विभाजन है: 60-70% प्रशिक्षण सेट और 30-40% परीक्षण सेट
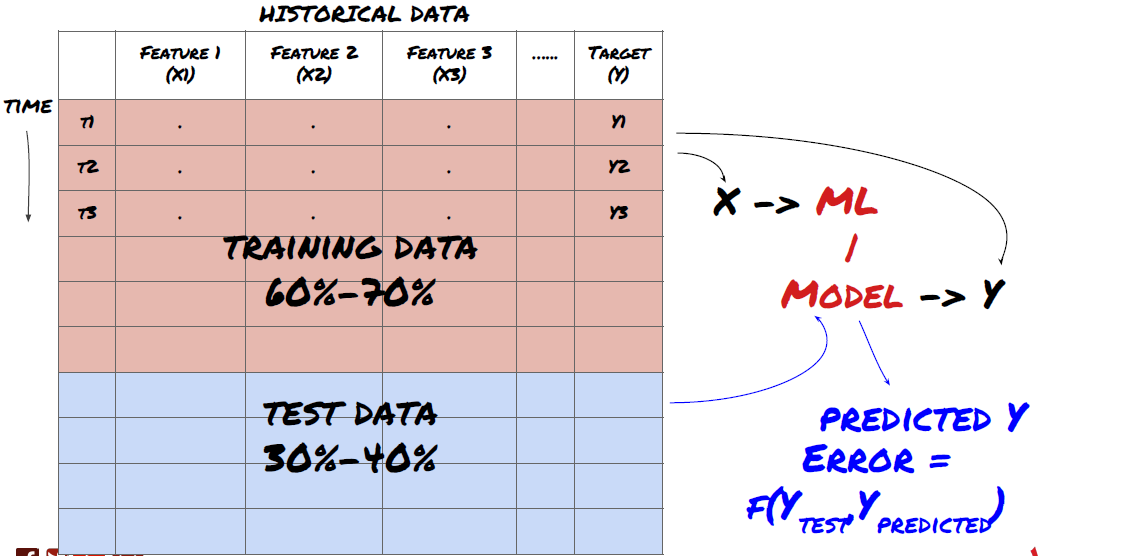
डेटा को प्रशिक्षण और परीक्षण सेट में विभाजित करें
चूंकि प्रशिक्षण डेटा का उपयोग मॉडल मापदंडों का मूल्यांकन करने के लिए किया जाता है, इसलिए आपका मॉडल इस प्रशिक्षण डेटा के लिए ओवरफिट हो सकता है और प्रशिक्षण डेटा मॉडल के प्रदर्शन को गुमराह कर सकता है। यदि आप कोई अलग परीक्षण डेटा नहीं रखते हैं और प्रशिक्षण के लिए सभी डेटा का उपयोग करते हैं, तो आपको यह पता नहीं चलेगा कि आपका मॉडल नए, अदृश्य डेटा पर कितना अच्छा या बुरा प्रदर्शन करेगा। यह मुख्य कारणों में से एक है कि प्रशिक्षित एमएल मॉडल लाइव डेटा पर विफल क्यों होते हैं: लोग सभी उपलब्ध डेटा पर प्रशिक्षण लेते हैं और प्रशिक्षण डेटा मेट्रिक्स से उत्साहित होते हैं, लेकिन मॉडल लाइव डेटा पर कोई सार्थक भविष्यवाणी नहीं कर सकता है जिस पर इसे प्रशिक्षित नहीं किया गया था।
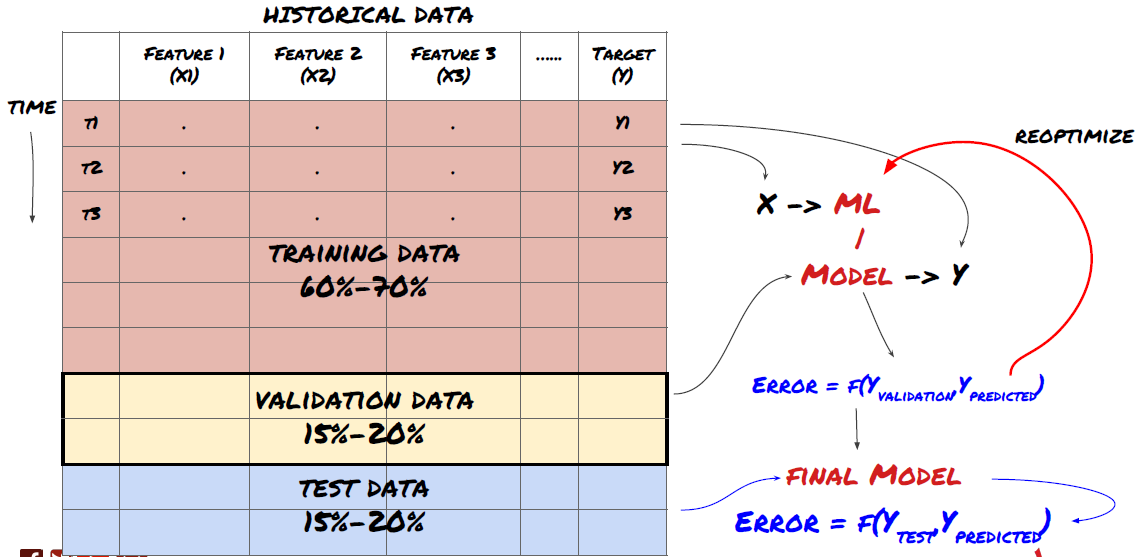
डेटा को प्रशिक्षण, सत्यापन और परीक्षण सेटों में विभाजित करें
इस दृष्टिकोण में समस्याएं हैं। यदि हम प्रशिक्षण डेटा पर बार-बार प्रशिक्षण करते हैं, परीक्षण डेटा पर प्रदर्शन का मूल्यांकन करते हैं और अपने मॉडल को तब तक अनुकूलित करते हैं जब तक कि हम प्रदर्शन से संतुष्ट नहीं हो जाते, तो हम परीक्षण डेटा को प्रशिक्षण डेटा के भाग के रूप में शामिल कर लेते हैं। अंततः, हमारा मॉडल प्रशिक्षण और परीक्षण डेटा के इस सेट पर अच्छा प्रदर्शन कर सकता है, लेकिन इसकी कोई गारंटी नहीं है कि यह नए डेटा का अच्छी तरह से पूर्वानुमान लगा सकेगा।
इस समस्या के समाधान के लिए, हम एक अलग सत्यापन डेटासेट बना सकते हैं। अब आप डेटा पर प्रशिक्षण ले सकते हैं, सत्यापन डेटा पर प्रदर्शन का मूल्यांकन कर सकते हैं, प्रदर्शन से संतुष्ट होने तक अनुकूलन कर सकते हैं, और अंत में परीक्षण डेटा पर परीक्षण कर सकते हैं। इस तरह, परीक्षण डेटा दूषित नहीं होगा और हम अपने मॉडल को बेहतर बनाने के लिए परीक्षण डेटा से किसी भी जानकारी का उपयोग नहीं करेंगे।
याद रखें, एक बार जब आपने परीक्षण डेटा पर प्रदर्शन की जांच कर ली है, तो पीछे जाकर मॉडल को और अधिक अनुकूलित करने का प्रयास न करें। यदि आपको लगे कि आपका मॉडल अच्छे परिणाम नहीं दे रहा है, तो मॉडल को पूरी तरह त्याग दें और दोबारा शुरू करें। सुझाया गया विभाजन 60% प्रशिक्षण डेटा, 20% सत्यापन डेटा और 20% परीक्षण डेटा हो सकता है।
हमारी समस्या के लिए, हमारे पास तीन डेटासेट उपलब्ध हैं और हम एक को प्रशिक्षण सेट के रूप में, दूसरे को सत्यापन सेट के रूप में, तथा तीसरे को परीक्षण सेट के रूप में उपयोग करेंगे।
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
इनमें से प्रत्येक में हम लक्ष्य चर Y जोड़ते हैं, जिसे अगले पाँच आधार मानों के औसत के रूप में परिभाषित किया जाता है
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
चरण 4: फ़ीचर इंजीनियरिंग
डेटा के व्यवहार का विश्लेषण करें और पूर्वानुमान शक्ति के साथ सुविधाएँ बनाएँ
अब परियोजना का वास्तविक निर्माण कार्य शुरू हो गया है। विशेषता चयन का स्वर्णिम नियम यह है कि पूर्वानुमान लगाने की शक्ति मुख्यतः विशेषताओं से आती है, मॉडल से नहीं। आप पाएंगे कि मॉडल के चयन की तुलना में सुविधाओं के चयन का प्रदर्शन पर कहीं अधिक प्रभाव पड़ता है। सुविधा चयन पर कुछ नोट्स:
लक्ष्य चर के साथ उनके संबंध की खोज किए बिना मनमाने ढंग से सुविधाओं के एक बड़े समूह का चयन न करें।
लक्ष्य चर के साथ कम या कोई संबंध न होने से ओवरफिटिंग हो सकती है
आपके द्वारा चुनी गई विशेषताएँ एक दूसरे से अत्यधिक सहसम्बन्धित हो सकती हैं, ऐसी स्थिति में विशेषताओं की एक छोटी संख्या भी लक्ष्य को स्पष्ट कर सकती है।
मैं आमतौर पर कुछ ऐसे फीचर्स बनाता हूं जो सहज ज्ञान युक्त हों और यह देखता हूं कि लक्ष्य चर इन फीचर्स के साथ किस प्रकार सह-संबंधित है, साथ ही यह भी देखता हूं कि वे एक-दूसरे के साथ किस प्रकार सह-संबंधित हैं, ताकि यह तय किया जा सके कि किन फीचर्स का उपयोग करना है।
आप अधिकतम सूचना गुणांक (एमआईसी) के आधार पर उम्मीदवार सुविधाओं को रैंक करने, प्रमुख घटक विश्लेषण (पीसीए) करने और अन्य तरीकों का भी प्रयास कर सकते हैं।
सुविधा रूपांतरण/सामान्यीकरण:
एमएल मॉडल सामान्यीकरण के साथ अच्छा प्रदर्शन करते हैं। हालाँकि, समय श्रृंखला डेटा के साथ काम करते समय सामान्यीकरण मुश्किल होता है क्योंकि डेटा की भविष्य की सीमा अज्ञात होती है। आपका डेटा सामान्यीकृत सीमा से बाहर हो सकता है, जिसके कारण मॉडल गलत हो सकता है। लेकिन आप अभी भी कुछ हद तक स्थिरता लाने का प्रयास कर सकते हैं:
स्केलिंग: मानक विचलन या इंटरक्वार्टराइल रेंज द्वारा विभाजित विशेषताएं
केन्द्रीकरण: वर्तमान मान से ऐतिहासिक औसत घटाएँ
सामान्यीकरण: उपरोक्त (x - माध्य) / stdev के दो लुकबैक अवधि
पारंपरिक सामान्यीकरण: डेटा को -1 से +1 की सीमा तक सामान्यीकृत करें और लुकबैक अवधि (x-min)/(max-min) के भीतर पुनः केन्द्रित करें
ध्यान दें कि चूंकि हम लुक-बैक अवधि में ऐतिहासिक चलित माध्य, मानक विचलन, अधिकतम या न्यूनतम मूल्य का उपयोग करते हैं, इसलिए विशेषता का सामान्यीकृत मूल्य अलग-अलग समय पर अलग-अलग वास्तविक मूल्यों का प्रतिनिधित्व करेगा। उदाहरण के लिए, यदि किसी विशेषता का वर्तमान मान 5 है और चालू 30-अवधि का औसत 4.5 है, तो केंद्रित करने के बाद इसे 0.5 में परिवर्तित कर दिया जाएगा। बाद में, यदि 30-अवधि का चालू औसत 3 हो जाता है, तो 3.5 का मान 0.5 हो जाएगा। यह कारण हो सकता है कि मॉडल गलत है। इसलिए, नियमितीकरण मुश्किल है और आपको यह पता लगाना होगा कि वास्तव में मॉडल के प्रदर्शन में क्या सुधार होता है (यदि कुछ भी हो)।
हमारी समस्या की पहली पुनरावृत्ति के लिए, हमने मिश्रण मापदंडों का उपयोग करके बड़ी संख्या में विशेषताएं बनाईं। बाद में हम यह देखने का प्रयास करेंगे कि क्या हम सुविधाओं की संख्या कम कर सकते हैं
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
चरण 5: मॉडल चयन
चुनी गई समस्या के लिए उपयुक्त सांख्यिकीय/एमएल मॉडल चुनें
मॉडल का चुनाव इस बात पर निर्भर करता है कि समस्या किस प्रकार तैयार की गई है। क्या आप एक पर्यवेक्षित (फीचर मैट्रिक्स में प्रत्येक बिंदु X को लक्ष्य चर Y पर मैप किया गया है) या एक अपर्यवेक्षित सीखने की समस्या (कोई मैपिंग नहीं दी गई है और मॉडल अज्ञात पैटर्न सीखने की कोशिश करता है) हल कर रहे हैं? क्या आप प्रतिगमन (भविष्य में वास्तविक मूल्य की भविष्यवाणी) या वर्गीकरण समस्या (भविष्य में मूल्य की केवल दिशा (वृद्धि/कमी) की भविष्यवाणी) हल कर रहे हैं।

पर्यवेक्षित या अपर्यवेक्षित शिक्षण

प्रतिगमन या वर्गीकरण
कुछ सामान्य पर्यवेक्षित शिक्षण एल्गोरिदम आपको आरंभ करने में मदद कर सकते हैं:
LinearRegression(पैरामीटर, रिग्रेशन)
लॉजिस्टिक रिग्रेशन (पैरामीटर, वर्गीकरण)
K-निकटतम पड़ोसी (KNN) एल्गोरिथ्म (उदाहरण-आधारित, प्रतिगमन)
एसवीएम, एसवीआर (पैरामीटर, वर्गीकरण और प्रतिगमन)
निर्णय वृक्ष
निर्णय वन
मैं एक सरल मॉडल, जैसे कि रैखिक या लॉजिस्टिक रिग्रेशन, से शुरुआत करने और आवश्यकतानुसार अधिक जटिल मॉडल बनाने की सलाह देता हूं। यह भी अनुशंसित है कि आप मॉडल को आँख मूंदकर ब्लैक बॉक्स की तरह उपयोग करने के बजाय इसके पीछे के गणित को पढ़ें।
चरण 6: प्रशिक्षण, सत्यापन और अनुकूलन (चरण 4-6 दोहराएं)
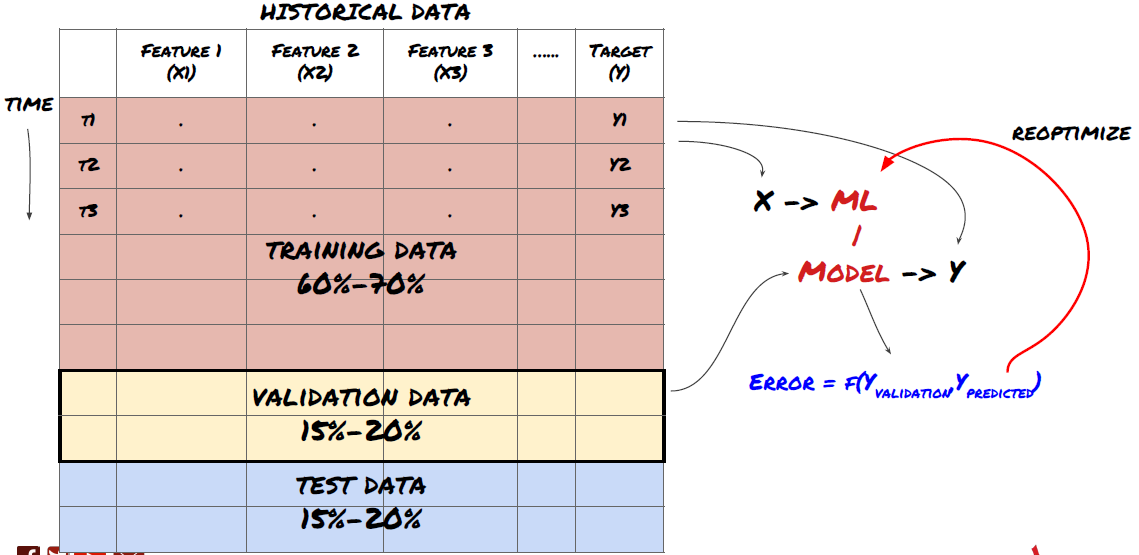
प्रशिक्षण और सत्यापन डेटासेट का उपयोग करके अपने मॉडल को प्रशिक्षित और अनुकूलित करें
अब आप अंततः अपना मॉडल बनाने के लिए तैयार हैं। इस स्तर पर, आप वास्तव में केवल मॉडल और मॉडल मापदंडों पर ही पुनरावृत्ति कर रहे हैं। अपने मॉडल को प्रशिक्षण डेटा पर प्रशिक्षित करें, सत्यापन डेटा पर उसके प्रदर्शन को मापें, फिर वापस जाएं, अनुकूलन करें, पुनः प्रशिक्षित करें और मूल्यांकन करें। यदि आप किसी मॉडल के प्रदर्शन से संतुष्ट नहीं हैं, तो किसी अन्य मॉडल का उपयोग करके देखें। आप इस चरण से कई बार गुजरते हैं जब तक कि आपको अंततः वह मॉडल नहीं मिल जाता जिससे आप संतुष्ट हों।
जब आपको कोई पसंदीदा मॉडल मिल जाए, तो अगले चरण पर आगे बढ़ें।
हमारी प्रदर्शन समस्या के लिए, आइए एक सरल रेखीय प्रतिगमन से शुरू करें
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
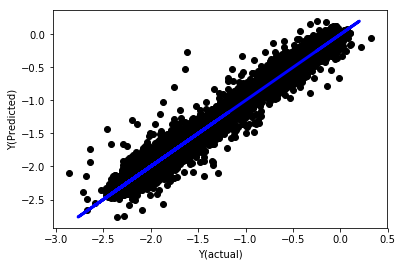
सामान्यीकरण के बिना रैखिक प्रतिगमन
”` (‘Coefficients: \n’, array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -