Strategi perdagangan frekuensi tinggi buku pesanan berdasarkan pembelajaran mesin
 1
7786
1
7786
Strategi perdagangan frekuensi tinggi buku pesanan berdasarkan pembelajaran mesin
- ### I. Teori
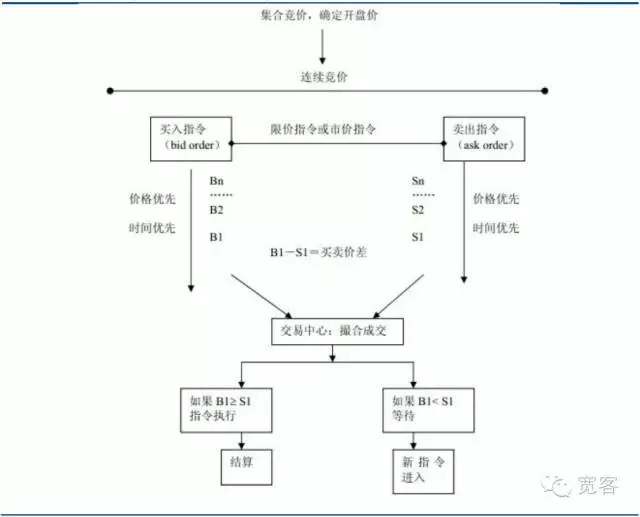
Sistem perdagangan di pasar saham dapat dibagi menjadi dua jenis, yaitu pasar saham yang didorong oleh penawaran dan pasar saham yang didorong oleh pesanan. Yang pertama adalah pasar saham yang bergantung pada penyediaan likuiditas oleh pemasar. Yang kedua adalah pasar saham yang menyediakan likuiditas melalui surat harga yang terbatas.
 Gambar 1 Peta pasar yang didorong pesanan
Gambar 1 Peta pasar yang didorong pesanan
-
(I) Keterangan Buku Pemesanan
Studi buku pesanan adalah bagian dari studi struktur mikro pasar. Teori struktur mikro pasar mengambil teori harga dan teori vendor dari ekonomi mikro sebagai sumber pemikirannya, dan dalam analisis proses dan penyebab pembentukan harga perdagangan aset keuangan dan masalah utamanya, ia menggunakan berbagai teori dan metode seperti keseimbangan umum, keseimbangan lokal, keuntungan marginal, biaya marginal, kontinuitas pasar, teori persediaan, teori permainan, dan ekonomi informasi.
Dari kemajuan penelitian di luar negeri, O’Hara mewakili bidang struktur mikro pasar, dan sebagian besar teori didasarkan pada pasar yang berorientasi pasar (yaitu pasar yang didorong oleh penawaran), seperti model inventaris dan model informasi. Tahun ini, pasar yang didorong oleh pesanan telah secara bertahap menduduki posisi teratas di pasar transaksi aktual, tetapi penelitian yang didorong oleh pesanan secara khusus masih relatif kecil.
Pasar sekuritas domestik dan pasar berjangka adalah pasar yang didorong oleh pesanan. Gambar di bawah ini adalah cuplikan dari buku pesanan Level_1 untuk kontrak berjangka indeks saham IF1312. Tidak banyak informasi yang diperoleh secara langsung dari atas, informasi dasar hanya mencakup harga beli, harga jual, jumlah beli dan jumlah jual.
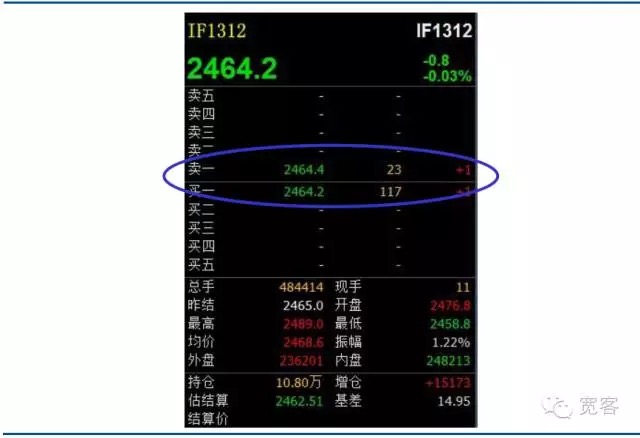 Bagan 2 Indeks Saham Futures Main Force Level-1 Buku Pesenan
Bagan 2 Indeks Saham Futures Main Force Level-1 Buku Pesenan -
(ii) Kemajuan dalam studi transaksi frekuensi tinggi dalam buku pesanan
Ada dua metode yang digunakan untuk memodelkan buku pesanan secara dinamis, yaitu metode ekonomi kuantitatif klasik dan metode pembelajaran mesin. Metode ekonomi kuantitatif adalah metode penelitian utama klasik, seperti pemecahan MRR untuk analisis perbedaan harga, pemecahan Huang dan Stoll, model ACD untuk durasi pesanan, dan model Logistic untuk memprediksi harga.
Pembelajaran mesin juga sangat aktif dalam penelitian akademis di bidang keuangan, seperti pada tahun 2012 dalam Forecasting trends of high_frequency KOSPI200 index data using learning classifiers. Ini adalah ide penelitian yang umum, menggunakan indikator analisis teknis yang umum (MA, EMA, RSI, dll), untuk memprediksi pasar.
-
Aplikasi Pembelajaran Mesin dalam Perdagangan Frekuensi Tinggi Buku Pesenan
- #### (a) Peta arsitektur sistem
Diagram di bawah ini adalah arsitektur sistem dari strategi perdagangan pembelajaran mesin yang khas, termasuk beberapa modul utama dari data buku pesanan, penemuan fitur, konstruksi dan verifikasi model, dan peluang perdagangan. Perlu dicatat bahwa proses perdagangan dipicu oleh peristiwa pasar, dan kedatangan tick adalah salah satu dari mereka.
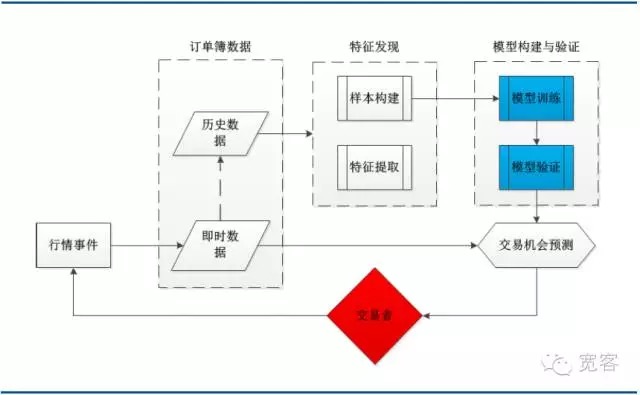 Gambar 3 Arsitektur sistem pemodelan buku pesanan berbasis pembelajaran mesin
Gambar 3 Arsitektur sistem pemodelan buku pesanan berbasis pembelajaran mesin- #### (II) mendukung vektor mesin
Pada tahun 1970-an, Vapnik dan lain-lain mulai membangun sebuah sistem teori yang lebih baik untuk teori pembelajaran statistik (SLT), yang digunakan untuk meneliti hukum statistik dan sifat metode pembelajaran dalam situasi sampel terbatas, membangun kerangka teoritis yang baik untuk masalah pembelajaran mesin dengan sampel terbatas, yang lebih baik dalam memecahkan masalah praktis seperti sampel kecil, non-linear, dimensi tinggi, dan titik terendah lokal. Pada tahun 1995, Vapnik dan lain-lain secara eksplisit mengusulkan sebuah metode pembelajaran universal baru untuk mendukung vektor mesin (SVM, Support Vector Machine), teori ini mendapat perhatian luas dan diterapkan ke berbagai bidang, dan pada awalnya menunjukkan kinerja yang jauh lebih baik daripada metode mereka sendiri.
SVM adalah pengembangan dari superplanet klasifikasi optimal dalam kasus yang dapat dibagi secara linier. Untuk masalah klasifikasi dua kelas, tentukan set sampel pelatihan sebagai ((xi,yi), i = 1,2…l, l adalah bilangan sampel pelatihan, xi adalah sampel pelatihan, yi milik {-1 + 1} adalah tanda kelas dari sampel x yang di input ((output yang diharapkan).
Klasifikasi optimal tidak hanya dapat memisahkan semua sampel dengan benar (dengan skor kesalahan pelatihan 0), tetapi juga dapat membuat margin antara dua kategori menjadi maksimum (dengan margin yang didefinisikan sebagai jumlah jarak terkecil dari kumpulan data pelatihan ke klasifikasi optimal. Klasifikasi optimal berarti bahwa rata-rata kesalahan klasifikasi terhadap data pengujian adalah minimum.
Jika ada sebuah superplanet dalam ruang vektor d:
F(x)=w*x+b=0
Jika bisa memisahkan kedua jenis data tersebut, maka hyperplane tersebut disebut sebagai interface.*x adalah luas interior dua vektor w dan x dalam ruang vektor dimensi d.
Jika interface:
w*x+b=0
Interface yang dapat membuat jarak antara dua jenis sampel terdekat dalam interface tersebut adalah maksimum (Margin), yang disebut sebagai interface optimal.
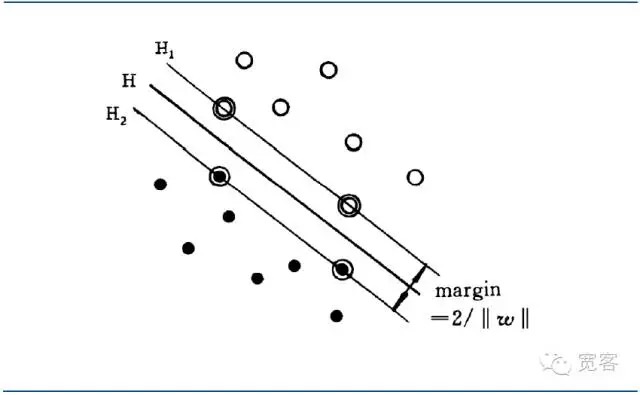 Gambar 4 Grafik antarmuka optimal SVM
Gambar 4 Grafik antarmuka optimal SVMPersamaan antara dua jenis sampel dapat dibuat dengan menggunakan persamaan optimum differential equation.
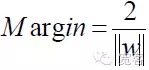
Jadi untuk setiap sampel, ada
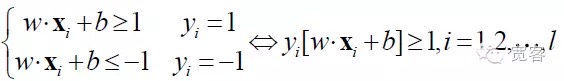
Untuk mendapatkan antarmuka yang optimal, selain memenuhi rumus di atas, Anda juga harus meminimalkan.
Oleh karena itu, model matematis dari masalah SVM adalah:
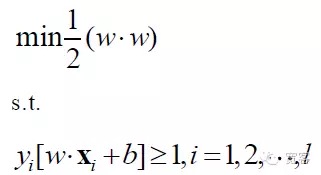
SVM akhirnya menjadi masalah perencanaan yang paling optimal, dengan fokus penelitian akademis yang berfokus pada pemecahan cepat, penyebaran ke kelas multinasional, aplikasi masalah praktis, dan sebagainya.
SVM pada awalnya ditujukan untuk masalah klasifikasi dua, dan berdasarkan persyaratan aplikasi aktual, diperluas ke masalah multi-kelas. Algoritma multi-kelas yang sudah ada meliputi satu-beberapa, satu-satu, pengkodean koreksi kesalahan, DAG-SVM dan klasifikasi SVM multi-i-class, dll.
- #### (III) Pengambilan Indeks Buku Pesan
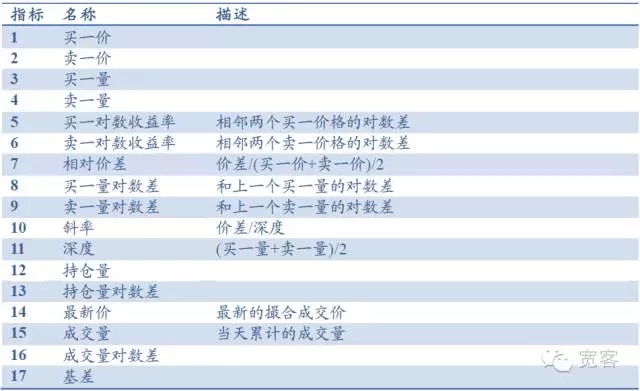
Sebagai contoh, buku pesanan terutama terdiri dari indikator dasar seperti harga beli satu, harga jual satu, jumlah beli satu, jumlah jual satu, dan dapat berasal dari indikator seperti kedalaman, kemiringan, perbedaan harga relatif, indikator lain termasuk jumlah kepemilikan, volume transaksi, perbedaan dasar, dan lain-lain, total 17 indikator, seperti yang ditunjukkan dalam tabel di bawah ini. Juga dapat diperkenalkan indikator analisis teknis yang umum seperti RSI, KDJMA, EMA, dll.
Tabel 1 Database Indikator Berdasarkan Buku Pesan Level
- #### (iv) Karakteristik dinamis buku pesanan dan peluang perdagangan
Dari sudut pandang mikro pasar, ada dua cara untuk mengukur pergerakan harga dalam waktu singkat, salah satunya adalah pergerakan harga median, dan yang lainnya adalah pergerakan harga diferensial silang. Dalam artikel ini, kami memilih pergerakan harga median yang lebih sederhana dan intuitif. Definisi harga median:
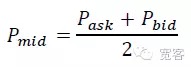
Berdasarkan buku pesanan dalam Δt ukuran perubahan nilai rata-rata ΔP dibagi menjadi tiga kategori.
Grafik di bawah ini adalah distribusi dinamika harga median kontrak IF1311 pada 29 Oktober, dengan 32.400 tick per hari.
Dalam kasus Δt = 1 tick, perubahan nilai rata-rata adalah 0.2 sekitar 6000 kali, perubahan nilai mutlak 0.4 sekitar 1500 kali, perubahan nilai mutlak 0.6 sekitar 150 kali, perubahan nilai mutlak 0.8 lebih besar dari 50 kali, perubahan nilai mutlak lebih besar dari atau sama dengan 1 sekitar 10 kali.
Dalam kasus Δt = 2tick, perubahan nilai rata-rata adalah 0.2 kali, perubahan nilai mutlak 0.4 kali, perubahan nilai mutlak 0.6 kali, perubahan nilai mutlak 0.8 kali, perubahan nilai mutlak 0.8 kali, dan perubahan nilai mutlak lebih besar dari 1 kali.
Kami menganggap bahwa perubahan nilai mutlak lebih besar dari atau sama dengan 0,4 adalah peluang perdagangan potensial. Dalam kasus Δt = 1 tick, ada sekitar 1700 peluang per hari; Dalam kasus Δt = 2 tick, ada sekitar 4000 peluang per hari.
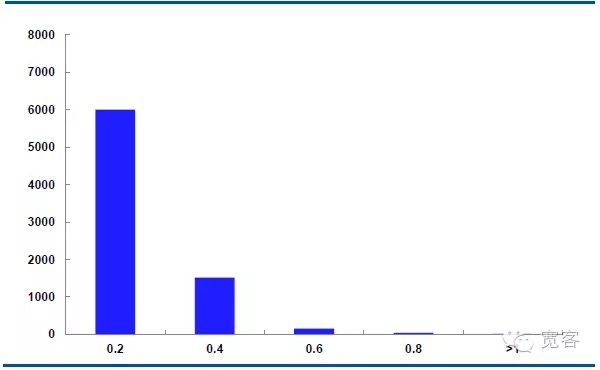
Gambar 5 IF1311 Distribusi perubahan harga median pada 29 Oktober (Δt=1 tick)
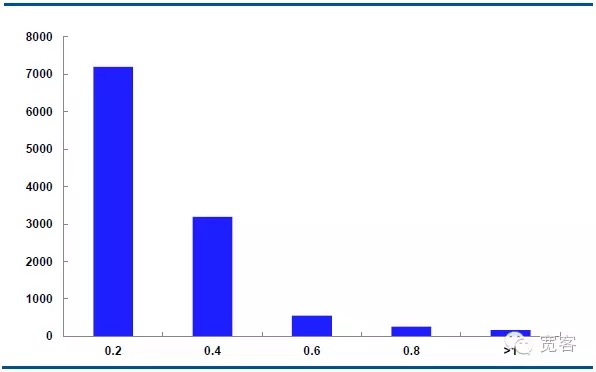
Gambar 6 IF1311 Distribusi perubahan harga median pada 29 Oktober (Δt=2tick)
-
Ketiga, bukti-bukti strategi
Karena model SVM memiliki kompleksitas pelatihan yang lebih tinggi dalam kasus sampel besar dan waktu pelatihan yang lebih lama, kami memilih rentang waktu yang relatif pendek dari data situasi sejarah, dengan contoh data situasi Level_1 dari kontrak IF1311 pada bulan Oktober, untuk memvalidasi validitas model.
-
(I) pengujian efek model
Siklus data: data kontrak IF1311 pada bulan Oktober;
Pengertian Δt: semakin kecil Δt, semakin tinggi kebutuhan akan detail transaksi, ketika Δt = 1 tick, sangat sulit untuk mendapatkan keuntungan dalam transaksi nyata, untuk membandingkan efek model, nilai 1 tick, 2 tick, dan 3 tick;
Indikator penilaian model: akurasi sampel, akurasi tes, waktu prediksi.
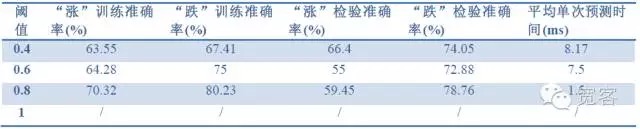 Tabel 2 Prediksi 1 tick dengan data 1 tick
Tabel 2 Prediksi 1 tick dengan data 1 tick Tabel 3 Prediksi efek tick 2 dari data tick 1
Tabel 3 Prediksi efek tick 2 dari data tick 1 Tabel 4 Prediksi Efek 2tick dari 2tick data
Tabel 4 Prediksi Efek 2tick dari 2tick dataDari tiga tabel di atas, kita dapat menyimpulkan bahwa: Akurasi tertinggi mencapai sekitar 70%, dan akurasi mencapai 60% dapat diterjemahkan ke dalam strategi perdagangan.
-
(ii) Strategi Simulasi Hasil
Sebagai contoh pada tanggal 31 Oktober, kita melakukan simulasi perdagangan, komisi perdagangan indeks futures lembaga umumnya adalah komisi perdagangan indeks futures lembaga umumnya adalah 0.26⁄10000, kita asumsikan jumlah transaksi tidak dibatasi, asumsikan setiap perdagangan satu sisi harga sliding 0,2 poin, setiap pesanan turun 1 tangan.
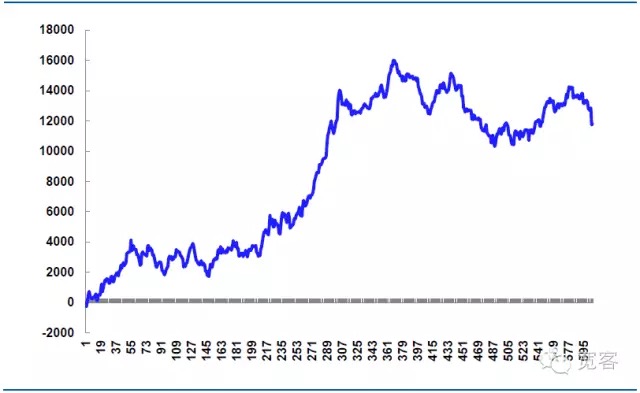
Tabel 5 Simulasi Strategi pada tanggal 31 Oktober

Hari ini ada 605 kali trading, 339 kali profit, 56% win, net profit 11814.99 yuan.
Theoretical slippage adalah 14.520 yuan, ini adalah bagian dari kunci dari strategi perang nyata, jika detail pesanan dikendalikan lebih halus, maka dapat mengurangi slippage, meningkatkan laba bersih, jika detail pesanan dikendalikan tidak tepat, atau pasar berfluktuasi abnormal, slippage akan lebih besar, dan laba bersih akan berkurang, sehingga keberhasilan perdagangan frekuensi tinggi sering tergantung pada pelaksanaan detail.
Gambar 7 Hasil simulasi pada 31 Oktober
Artikel ini ditulis oleh penulis asli dari WGN, terjemahan dari sumber yang diminta.