Perdagangan pasangan berdasarkan teknologi berbasis data
Penulis:FMZ~Lydia, Dibuat: 2023-01-05 09:10:25, Diperbarui: 2024-12-19 00:27:10
Perdagangan pasangan berdasarkan teknologi berbasis data
Perdagangan pasangan adalah contoh yang baik dari merumuskan strategi perdagangan berdasarkan analisis matematis.
Prinsip-prinsip dasar
Misalkan Anda memiliki sepasang target investasi X dan Y yang memiliki beberapa koneksi potensial. Misalnya, dua perusahaan memproduksi produk yang sama, seperti Pepsi Cola dan Coca Cola. Anda ingin rasio harga atau basis spread (juga dikenal sebagai perbedaan harga) dari keduanya tetap tidak berubah dari waktu ke waktu. Namun, karena perubahan sementara dalam penawaran dan permintaan, seperti pesanan beli / jual yang besar dari target investasi, dan reaksi terhadap berita penting dari salah satu perusahaan, perbedaan harga antara kedua pasangan mungkin berbeda dari waktu ke waktu. Dalam hal ini, satu objek investasi bergerak naik sementara yang lain bergerak turun relatif satu sama lain. Jika Anda ingin ketidaksepakatan ini kembali normal dari waktu ke waktu, Anda dapat menemukan peluang perdagangan (atau peluang arbitrase). Peluang arbitrase seperti itu dapat ditemukan di mana-mana di pasar mata uang digital atau pasar komoditas berjangka, seperti hubungan antara BTC dan pasar komoditas domestik; hubungan antara aset aman antara hidangan kedelai, hidangan kedelai dan minyak kedelai.
Ketika ada perbedaan harga sementara, Anda akan menjual objek investasi dengan kinerja yang sangat baik (objek investasi yang meningkat) dan membeli objek investasi dengan kinerja yang buruk (objek investasi yang menurun). Anda yakin bahwa margin bunga antara kedua objek investasi akhirnya akan turun melalui penurunan objek investasi dengan kinerja yang sangat baik atau kenaikan objek investasi dengan kinerja yang buruk, atau keduanya. Transaksi Anda akan menghasilkan uang dalam semua situasi serupa ini. Jika objek investasi bergerak naik atau turun bersama-sama tanpa mengubah perbedaan harga di antara mereka, Anda tidak akan menghasilkan atau kehilangan uang.
Oleh karena itu, perdagangan pasangan adalah strategi perdagangan netral pasar, memungkinkan pedagang untuk mendapatkan keuntungan dari hampir semua kondisi pasar: tren naik, tren turun atau konsolidasi horizontal.
Jelaskan konsep: dua tujuan investasi hipotetis
- Membangun lingkungan penelitian kami di platform FMZ Quant
Pertama-tama, untuk bekerja dengan lancar, kita perlu membangun lingkungan penelitian kita. Dalam artikel ini, kita menggunakan platform FMZ Quant (FMZ.COM) untuk membangun lingkungan penelitian kita, terutama untuk menggunakan antarmuka API yang nyaman dan cepat dan sistem Docker yang dikemas dengan baik dari platform ini nanti.
Dalam nama resmi platform FMZ Quant, sistem Docker ini disebut sistem Docker.
Silakan lihat artikel saya sebelumnya tentang cara mengimplementasikan docker dan robot:https://www.fmz.com/bbs-topic/9864.
Pembaca yang ingin membeli server komputasi awan mereka sendiri untuk menyebarkan dockers dapat merujuk pada artikel ini:https://www.fmz.com/digest-topic/5711.
Setelah menyebarkan server komputasi awan dan sistem docker dengan sukses, selanjutnya kita akan menginstal artefak terbesar saat ini Python: Anaconda
Untuk mewujudkan semua lingkungan program yang relevan (perpustakaan ketergantungan, manajemen versi, dll.) yang diperlukan dalam artikel ini, cara termudah adalah menggunakan Anaconda.
Untuk metode instalasi Anaconda, silakan lihat panduan resmi Anaconda:https://www.anaconda.com/distribution/.
Artikel ini juga akan menggunakan numpy dan panda, dua perpustakaan populer dan penting dalam komputasi ilmiah Python.
Karya dasar di atas juga dapat merujuk pada artikel saya sebelumnya, yang memperkenalkan cara mengatur lingkungan Anaconda dan pustaka numpy dan panda.https://www.fmz.com/bbs-topic/9863.
Selanjutnya, mari kita gunakan kode untuk mengimplementasikan
import numpy as np
import pandas as pd
import statsmodels
from statsmodels.tsa.stattools import coint
# just set the seed for the random number generator
np.random.seed(107)
import matplotlib.pyplot as plt
Ya, kita juga akan menggunakan matplotlib, sebuah perpustakaan grafik yang sangat terkenal di Python.
Mari kita membuat target investasi hipotetis X, dan simulasi dan plot pengembalian harian melalui distribusi normal. kemudian kita melakukan jumlah kumulatif untuk mendapatkan nilai harian X.
# Generate daily returns
Xreturns = np.random.normal(0, 1, 100)
# sum them and shift all the prices up
X = pd.Series(np.cumsum(
Xreturns), name='X')
+ 50
X.plot(figsize=(15,7))
plt.show()
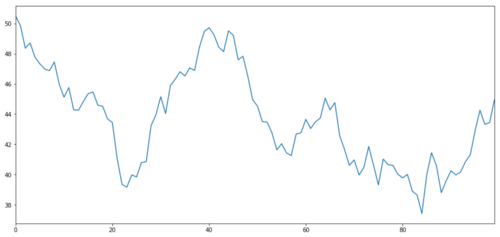
X dari objek investasi disimulasikan untuk memetakan pengembalian harian melalui distribusi normal
Sekarang kita menghasilkan Y, yang sangat terintegrasi dengan X, jadi harga Y harus sangat mirip dengan perubahan X. Kita memodelkannya dengan mengambil X, memindahkannya ke atas dan menambahkan beberapa kebisingan acak yang diekstrak dari distribusi normal.
noise = np.random.normal(0, 1, 100)
Y = X + 5 + noise
Y.name = 'Y'
pd.concat([X, Y], axis=1).plot(figsize=(15,7))
plt.show()
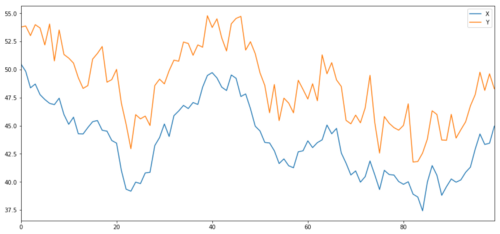
X dan Y dari objek investasi kointegrasi
Kointegrasi
Kointegrasi sangat mirip dengan korelasi, yang berarti bahwa rasio antara dua seri data akan berubah dekat dengan nilai rata-rata.
Y = X + e
Di mana
Untuk pasangan yang berdagang antara dua deret waktu, nilai yang diharapkan dari rasio dari waktu ke waktu harus konvergen ke nilai rata-rata, yaitu, mereka harus kointegrasi. deret waktu yang kita bangun di atas adalah kointegrasi. kita akan memetakan rasio antara mereka sekarang sehingga kita dapat melihat seperti apa.
(Y/X).plot(figsize=(15,7))
plt.axhline((Y/X).mean(), color='red', linestyle='--')
plt.xlabel('Time')
plt.legend(['Price Ratio', 'Mean'])
plt.show()
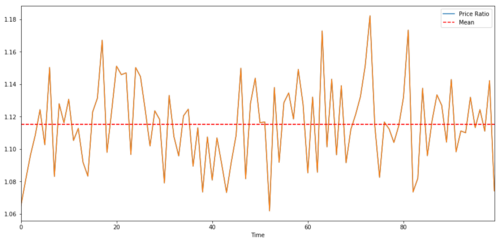
Rasio dan nilai rata-rata antara dua harga target investasi yang terintegrasi bersama
Tes kointegrasi
Metode pengujian yang nyaman adalah menggunakan statsmodels.tsa.stattools. Kita akan melihat nilai p yang sangat rendah, karena kita membuat dua rangkaian data secara artifisial yang terintegrasi sesering mungkin.
# compute the p-value of the cointegration test
# will inform us as to whether the ratio between the 2 timeseries is stationary
# around its mean
score, pvalue, _ = coint(X,Y)
print pvalue
Hasilnya adalah: 1.81864477307e-17
Catatan: korelasi dan kointegrasi
korelasi dan kointegrasi, meskipun mirip dalam teori, tidak sama. mari kita lihat contoh seri data yang relevan tetapi tidak kointegrasi dan sebaliknya. pertama, mari kita periksa korelasi dari seri yang baru kita hasilkan.
X.corr(Y)
Hasilnya adalah: 0,951
Seperti yang kita harapkan, ini sangat tinggi. tapi bagaimana dengan dua rangkaian yang terkait tetapi tidak terintegrasi bersama? contoh sederhana adalah rangkaian dua data menyimpang.
ret1 = np.random.normal(1, 1, 100)
ret2 = np.random.normal(2, 1, 100)
s1 = pd.Series( np.cumsum(ret1), name='X')
s2 = pd.Series( np.cumsum(ret2), name='Y')
pd.concat([s1, s2], axis=1 ).plot(figsize=(15,7))
plt.show()
print 'Correlation: ' + str(X_diverging.corr(Y_diverging))
score, pvalue, _ = coint(X_diverging,Y_diverging)
print 'Cointegration test p-value: ' + str(pvalue)
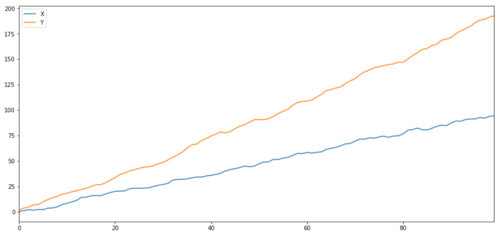
Dua seri terkait (tidak terintegrasi bersama)
Koefisien korelasi: 0,998 Nilai P dari tes kointegrasi: 0,258
Contoh sederhana dari kointegrasi tanpa korelasi adalah urutan distribusi normal dan gelombang persegi.
Y2 = pd.Series(np.random.normal(0, 1, 800), name='Y2') + 20
Y3 = Y2.copy()
Y3[0:100] = 30
Y3[100:200] = 10
Y3[200:300] = 30
Y3[300:400] = 10
Y3[400:500] = 30
Y3[500:600] = 10
Y3[600:700] = 30
Y3[700:800] = 10
Y2.plot(figsize=(15,7))
Y3.plot()
plt.ylim([0, 40])
plt.show()
# correlation is nearly zero
print 'Correlation: ' + str(Y2.corr(Y3))
score, pvalue, _ = coint(Y2,Y3)
print 'Cointegration test p-value: ' + str(pvalue)
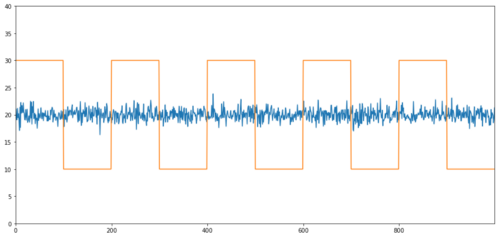
Korélasi: 0,007546 Nilai P dari tes kointegrasi: 0,0
Korelasi sangat rendah, tapi nilai p menunjukkan kointegrasi sempurna!
Bagaimana cara melakukan perdagangan pasangan?
Karena dua deret waktu yang terintegrasi bersama (seperti X dan Y di atas) saling berhadapan dan menyimpang satu sama lain, terkadang spread basisnya tinggi atau rendah.
Kembali ke yang di atas, X dan Y di Y =
Rasio Going Long: Ini adalah ketika rasio
sangat kecil dan kita mengharapkannya meningkat. Rasio Going Short: Ini adalah ketika rasio
sangat besar dan kita mengharapkannya berkurang.
Harap dicatat bahwa kita selalu memiliki
Jika X dan Y dari objek perdagangan bergerak relatif satu sama lain, kita akan menghasilkan uang atau kehilangan uang.
Gunakan data untuk menemukan objek perdagangan dengan perilaku yang sama
Cara terbaik untuk melakukan ini adalah dengan memulai dari subjek perdagangan yang Anda curiga mungkin kointegrasi dan melakukan tes statistik.bias perbandingan ganda.
Bias perbandingan gandajika kita menjalankan 100 tes pada data acak, kita harus melihat 5 nilai p di bawah 0,05. Jika kita ingin membandingkan n target perdagangan untuk kointegrasi, kita akan melakukan n (n-1) / 2 perbandingan, dan kita akan melihat banyak nilai p yang salah, yang akan meningkat dengan peningkatan sampel tes kita. Untuk menghindari situasi ini, pilih beberapa pasangan perdagangan dan kita memiliki alasan untuk menentukan bahwa mereka mungkin kointegrasi, dan kemudian uji mereka secara terpisah. Ini akan sangat mengurangibias perbandingan ganda.
Oleh karena itu, mari kita coba mencari beberapa target perdagangan yang menunjukkan kointegrasi. Mari kita ambil keranjang saham teknologi besar AS dalam Indeks S&P 500 sebagai contoh. Target perdagangan ini beroperasi di segmen pasar yang sama dan memiliki harga kointegrasi. Kita memindai daftar objek perdagangan dan menguji kointegrasi antara semua pasangan.
Matriks skor tes kointegrasi yang dikembalikan, matriks nilai p dan semua pasangan dengan nilai p kurang dari 0,05.Metode ini rentan terhadap bias perbandingan ganda, jadi sebenarnya, mereka perlu melakukan verifikasi kedua.Dalam artikel ini, untuk memudahkan penjelasan kita, kita memilih untuk mengabaikan poin ini dalam contohnya.
def find_cointegrated_pairs(data):
n = data.shape[1]
score_matrix = np.zeros((n, n))
pvalue_matrix = np.ones((n, n))
keys = data.keys()
pairs = []
for i in range(n):
for j in range(i+1, n):
S1 = data[keys[i]]
S2 = data[keys[j]]
result = coint(S1, S2)
score = result[0]
pvalue = result[1]
score_matrix[i, j] = score
pvalue_matrix[i, j] = pvalue
if pvalue < 0.02:
pairs.append((keys[i], keys[j]))
return score_matrix, pvalue_matrix, pairs
Catatan: Kami telah menyertakan penanda acuan pasar (SPX) dalam data - pasar telah mendorong aliran banyak objek perdagangan. Biasanya Anda mungkin menemukan dua objek perdagangan yang tampaknya kointegrasi; Tapi sebenarnya, mereka tidak kointegrasi satu sama lain, tetapi dengan pasar. Ini disebut variabel membingungkan. Penting untuk memeriksa partisipasi pasar dalam hubungan apa pun yang Anda temukan.
from backtester.dataSource.yahoo_data_source import YahooStockDataSource
from datetime import datetime
startDateStr = '2007/12/01'
endDateStr = '2017/12/01'
cachedFolderName = 'yahooData/'
dataSetId = 'testPairsTrading'
instrumentIds = ['SPY','AAPL','ADBE','SYMC','EBAY','MSFT','QCOM',
'HPQ','JNPR','AMD','IBM']
ds = YahooStockDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds,
startDateStr=startDateStr,
endDateStr=endDateStr,
event='history')
data = ds.getBookDataByFeature()['Adj Close']
data.head(3)

Sekarang mari kita coba menggunakan metode kami untuk menemukan pasangan perdagangan yang terintegrasi.
# Heatmap to show the p-values of the cointegration test
# between each pair of stocks
scores, pvalues, pairs = find_cointegrated_pairs(data)
import seaborn
m = [0,0.2,0.4,0.6,0.8,1]
seaborn.heatmap(pvalues, xticklabels=instrumentIds,
yticklabels=instrumentIds, cmap=’RdYlGn_r’,
mask = (pvalues >= 0.98))
plt.show()
print pairs
[('ADBE', 'MSFT')]
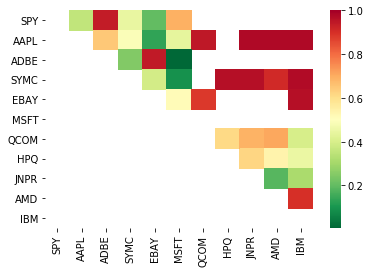
Tampaknya
S1 = data['ADBE']
S2 = data['MSFT']
score, pvalue, _ = coint(S1, S2)
print(pvalue)
ratios = S1 / S2
ratios.plot()
plt.axhline(ratios.mean())
plt.legend([' Ratio'])
plt.show()
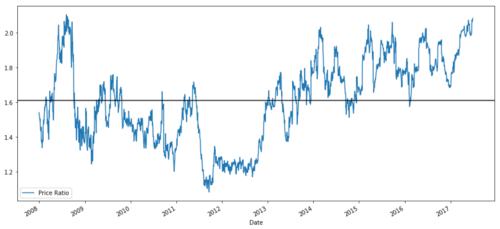
Grafik rasio harga antara MSFT dan ADBE dari tahun 2008 hingga 2017
Rasio ini terlihat seperti rata-rata yang stabil. rasio absolut tidak berguna secara statistik. lebih membantu untuk menstandarisasi sinyal kita dengan memperlakukan mereka sebagai Z Score.
Z Score (Value) = (Value
Peringatan
Pada kenyataannya, kita biasanya mencoba untuk memperluas data dengan asumsi bahwa data terdistribusi secara normal. Namun, banyak data keuangan tidak terdistribusi secara normal, jadi kita harus sangat berhati-hati untuk tidak hanya mengasumsikan normalitas atau distribusi tertentu ketika menghasilkan statistik. Distribusi rasio yang sebenarnya dapat memiliki efek ekor lemak, dan data yang cenderung ekstrim akan membingungkan model kita dan menyebabkan kerugian besar.
def zscore(series):
return (series - series.mean()) / np.std(series)
zscore(ratios).plot()
plt.axhline(zscore(ratios).mean())
plt.axhline(1.0, color=’red’)
plt.axhline(-1.0, color=’green’)
plt.show()
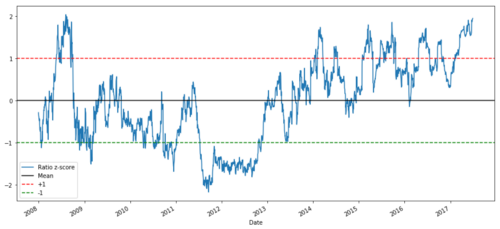
Z rasio harga antara MSFT dan ADBE dari tahun 2008 hingga 2017
Sekarang lebih mudah untuk mengamati pergerakan rasio di dekat nilai rata-rata, tetapi kadang-kadang mudah untuk memiliki perbedaan besar dari nilai rata-rata.
Sekarang setelah kita membahas pengetahuan dasar strategi perdagangan pasangan, dan menentukan subjek integrasi bersama berdasarkan harga historis, mari kita coba mengembangkan sinyal perdagangan.
Mengumpulkan data yang dapat diandalkan dan membersihkan data;
Membuat fungsi dari data untuk mengidentifikasi sinyal perdagangan/logika;
Fungsi dapat bergerak rata-rata atau data harga, korelasi atau rasio sinyal yang lebih kompleks - menggabungkan ini untuk menciptakan fungsi baru;
Gunakan fungsi ini untuk menghasilkan sinyal perdagangan, yaitu, sinyal yang membeli, menjual atau posisi pendek untuk menonton.
Untungnya, kami memiliki platform FMZ Quant (fmz.com), yang telah menyelesaikan empat aspek di atas untuk kami, yang merupakan berkat besar bagi pengembang strategi.
Dalam platform FMZ Quant, ada antarmuka yang dikemas untuk berbagai pertukaran arus utama. Apa yang perlu kita lakukan adalah memanggil antarmuka API ini.
Untuk melengkapi logika dan menjelaskan prinsip dalam artikel ini, kami akan menyajikan logika yang mendasari ini secara rinci.
Mari kita mulai:
Langkah 1: Tentukan pertanyaan Anda
Di sini, kita mencoba untuk membuat sinyal untuk memberitahu kita apakah rasio akan membeli atau menjual pada saat berikutnya, yaitu, variabel prediksi kita Y:
Y = Rasio adalah beli (1) atau jual (-1)
Y ((t) = Sign ((Ratio ((t+1)
Harap dicatat bahwa kita tidak perlu memprediksi harga target transaksi yang sebenarnya, atau bahkan nilai sebenarnya dari rasio (meskipun kita bisa), tetapi hanya arah rasio di langkah berikutnya.
Langkah 2: Kumpulkan data yang dapat diandalkan dan akurat
FMZ Quant adalah teman Anda! Anda hanya perlu menentukan objek transaksi yang akan diperdagangkan dan sumber data yang akan digunakan, dan itu akan mengekstrak data yang diperlukan dan membersihkannya untuk pembagian dividen dan objek transaksi. Jadi data di sini sangat bersih.
Pada hari perdagangan 10 tahun terakhir (sekitar 2500 titik data), kami memperoleh data berikut dengan menggunakan Yahoo Finance: harga pembukaan, harga penutupan, harga tertinggi, harga terendah dan volume perdagangan.
Langkah 3: Pembagian data
Jangan lupa langkah yang sangat penting ini dalam pengujian akurasi model.
Pelatihan 7 tahun ~ 70%
Tes ~ 3 tahun 30%
ratios = data['ADBE'] / data['MSFT']
print(len(ratios))
train = ratios[:1762]
test = ratios[1762:]
Idealnya, kita juga harus membuat set validasi, tapi kita tidak akan melakukannya sekarang.
Tahap 4: Teknik Fitur
Fungsi yang terkait dapat menjadi apa? kita ingin memprediksi arah perubahan rasio. kita telah melihat bahwa dua target perdagangan kita kointegrasi, sehingga rasio ini cenderung bergeser dan kembali ke nilai rata-rata. tampaknya karakteristik kita harus beberapa ukuran rasio rata-rata, dan perbedaan antara nilai saat ini dan nilai rata-rata dapat menghasilkan sinyal perdagangan kita.
Kami menggunakan fungsi berikut:
rasio rata-rata bergerak 60 hari: pengukuran rata-rata bergerak;
Rasio rata-rata bergerak 5 hari: pengukuran nilai rata-rata saat ini;
deviasi standar 60 hari;
Z Score: (5d MA - 60d MA) / 60d SD.
ratios_mavg5 = train.rolling(window=5,
center=False).mean()
ratios_mavg60 = train.rolling(window=60,
center=False).mean()
std_60 = train.rolling(window=60,
center=False).std()
zscore_60_5 = (ratios_mavg5 - ratios_mavg60)/std_60
plt.figure(figsize=(15,7))
plt.plot(train.index, train.values)
plt.plot(ratios_mavg5.index, ratios_mavg5.values)
plt.plot(ratios_mavg60.index, ratios_mavg60.values)
plt.legend(['Ratio','5d Ratio MA', '60d Ratio MA'])
plt.ylabel('Ratio')
plt.show()
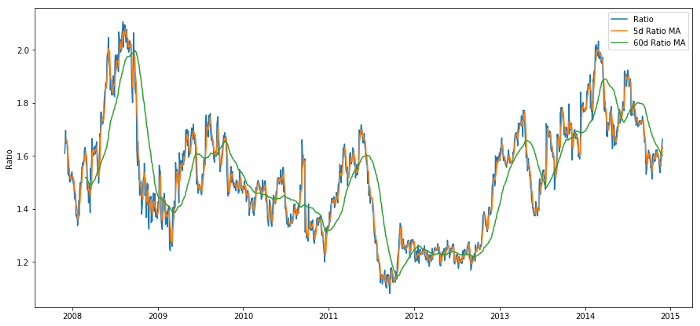
Rasio harga antara 60d dan 5d MA
plt.figure(figsize=(15,7))
zscore_60_5.plot()
plt.axhline(0, color='black')
plt.axhline(1.0, color='red', linestyle='--')
plt.axhline(-1.0, color='green', linestyle='--')
plt.legend(['Rolling Ratio z-Score', 'Mean', '+1', '-1'])
plt.show()
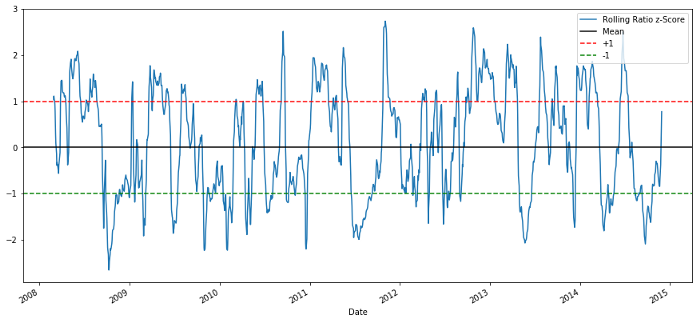
60-5 Z Nilai rasio harga
Z Score dari nilai rata-rata bergulir tidak membawa keluar properti regresi nilai rata-rata dari rasio!
Langkah 5: Pemilihan Model
Mari kita mulai dengan model yang sangat sederhana. Melihat grafik skor z, kita dapat melihat bahwa jika skor z terlalu tinggi atau terlalu rendah, itu akan kembali. Mari kita gunakan +1/- 1 sebagai ambang batas untuk mendefinisikan terlalu tinggi dan terlalu rendah, dan kemudian kita dapat menggunakan model berikut untuk menghasilkan sinyal perdagangan:
Ketika z di bawah -1.0, rasio adalah untuk membeli (1), karena kita mengharapkan z untuk kembali ke 0, sehingga rasio meningkat;
Ketika z di atas 1,0, rasio adalah jual (- 1), karena kita mengharapkan z untuk kembali ke 0, sehingga rasio menurun.
Tahap 6: Pelatihan, verifikasi dan optimalisasi
Akhirnya, mari kita lihat dampak nyata dari model kita pada data yang sebenarnya.
# Plot the ratios and buy and sell signals from z score
plt.figure(figsize=(15,7))
train[60:].plot()
buy = train.copy()
sell = train.copy()
buy[zscore_60_5>-1] = 0
sell[zscore_60_5<1] = 0
buy[60:].plot(color=’g’, linestyle=’None’, marker=’^’)
sell[60:].plot(color=’r’, linestyle=’None’, marker=’^’)
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,ratios.min(),ratios.max()))
plt.legend([‘Ratio’, ‘Buy Signal’, ‘Sell Signal’])
plt.show()
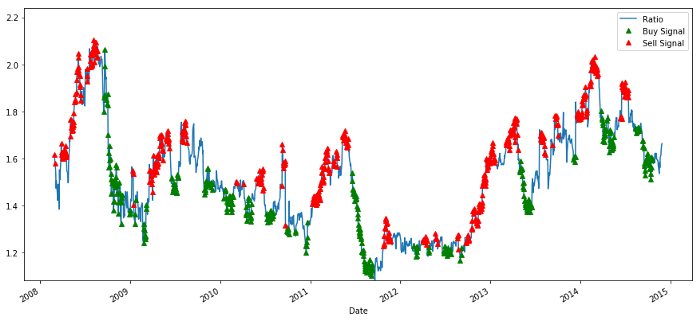
Sinyal rasio harga beli dan jual
Sinyal tampaknya masuk akal. Kita tampaknya menjual ketika itu tinggi atau meningkat (titik merah) dan membelinya kembali ketika itu rendah (titik hijau) dan menurun. Apa artinya ini untuk subjek sebenarnya dari transaksi kita? Mari kita lihat:
# Plot the prices and buy and sell signals from z score
plt.figure(figsize=(18,9))
S1 = data['ADBE'].iloc[:1762]
S2 = data['MSFT'].iloc[:1762]
S1[60:].plot(color='b')
S2[60:].plot(color='c')
buyR = 0*S1.copy()
sellR = 0*S1.copy()
# When buying the ratio, buy S1 and sell S2
buyR[buy!=0] = S1[buy!=0]
sellR[buy!=0] = S2[buy!=0]
# When selling the ratio, sell S1 and buy S2
buyR[sell!=0] = S2[sell!=0]
sellR[sell!=0] = S1[sell!=0]
buyR[60:].plot(color='g', linestyle='None', marker='^')
sellR[60:].plot(color='r', linestyle='None', marker='^')
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,min(S1.min(),S2.min()),max(S1.max(),S2.max())))
plt.legend(['ADBE','MSFT', 'Buy Signal', 'Sell Signal'])
plt.show()
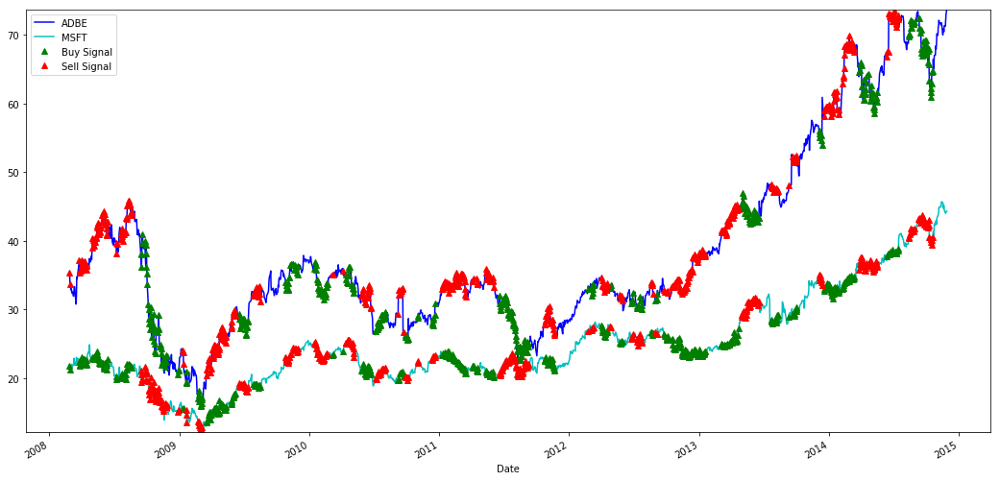
Sinyal untuk membeli dan menjual saham MSFT dan ADBE
Harap perhatikan bagaimana kita kadang-kadang menghasilkan keuntungan dengan
Kita puas dengan sinyal dari data pelatihan. Mari kita lihat apa jenis keuntungan sinyal ini dapat menghasilkan. Ketika rasio rendah, kita dapat membuat back tester sederhana, membeli rasio (beli 1 saham ADBE dan jual rasio x saham MSFT), dan menjual rasio (jual 1 saham ADBE dan membeli rasio x saham MSFT) ketika tinggi, dan menghitung transaksi PnL dari rasio ini.
# Trade using a simple strategy
def trade(S1, S2, window1, window2):
# If window length is 0, algorithm doesn't make sense, so exit
if (window1 == 0) or (window2 == 0):
return 0
# Compute rolling mean and rolling standard deviation
ratios = S1/S2
ma1 = ratios.rolling(window=window1,
center=False).mean()
ma2 = ratios.rolling(window=window2,
center=False).mean()
std = ratios.rolling(window=window2,
center=False).std()
zscore = (ma1 - ma2)/std
# Simulate trading
# Start with no money and no positions
money = 0
countS1 = 0
countS2 = 0
for i in range(len(ratios)):
# Sell short if the z-score is > 1
if zscore[i] > 1:
money += S1[i] - S2[i] * ratios[i]
countS1 -= 1
countS2 += ratios[i]
print('Selling Ratio %s %s %s %s'%(money, ratios[i], countS1,countS2))
# Buy long if the z-score is < 1
elif zscore[i] < -1:
money -= S1[i] - S2[i] * ratios[i]
countS1 += 1
countS2 -= ratios[i]
print('Buying Ratio %s %s %s %s'%(money,ratios[i], countS1,countS2))
# Clear positions if the z-score between -.5 and .5
elif abs(zscore[i]) < 0.75:
money += S1[i] * countS1 + S2[i] * countS2
countS1 = 0
countS2 = 0
print('Exit pos %s %s %s %s'%(money,ratios[i], countS1,countS2))
return money
trade(data['ADBE'].iloc[:1763], data['MSFT'].iloc[:1763], 60, 5)
Hasilnya adalah: 1783.375
Jadi strategi ini tampaknya menguntungkan! Sekarang, kita dapat lebih mengoptimalkan dengan mengubah jendela waktu rata-rata bergerak, dengan mengubah ambang jual beli dan posisi tutup, dan memeriksa peningkatan kinerja data validasi.
Kita juga bisa mencoba model yang lebih kompleks, seperti Regresi Logistik dan SVM, untuk memprediksi 1/-1.
Sekarang, mari kita maju model ini, yang membawa kita ke:
Langkah 7: Uji balik data uji
Di sini lagi, platform FMZ Quant mengadopsi mesin backtesting QPS / TPS berkinerja tinggi untuk mereproduksi lingkungan historis dengan benar, menghilangkan perangkap backtesting kuantitatif umum, dan menemukan kekurangan strategi tepat waktu, sehingga lebih membantu investasi bot nyata.
Untuk menjelaskan prinsipnya, artikel ini masih memilih untuk menunjukkan logika yang mendasari. Dalam penerapan praktis, kami merekomendasikan pembaca untuk menggunakan platform FMZ Quant. Selain menghemat waktu, penting untuk meningkatkan tingkat toleransi kesalahan.
Backtesting sederhana. kita dapat menggunakan fungsi di atas untuk melihat PnL dari data tes.
trade(data['ADBE'].iloc[1762:], data['MSFT'].iloc[1762:], 60, 5)
Hasilnya adalah: 5262.868
Model ini bekerja dengan baik! Ini menjadi model perdagangan pasangan sederhana pertama kami.
Hindari overfitting
Sebelum mengakhiri diskusi, saya ingin membahas overfitting secara khusus. Overfitting adalah perangkap paling berbahaya dalam strategi trading. Algoritma overfitting mungkin berkinerja sangat baik dalam backtest tetapi gagal pada data yang tidak terlihat baru - yang berarti bahwa ia tidak benar-benar mengungkapkan tren data dan tidak memiliki kemampuan prediksi yang nyata. Mari kita berikan contoh sederhana.
Dalam model kami, kami menggunakan parameter rolling untuk memperkirakan dan mengoptimalkan panjang jendela waktu. Kami dapat memutuskan untuk hanya mengulangi semua kemungkinan, jendela waktu yang wajar, dan memilih panjang waktu sesuai dengan kinerja terbaik dari model kami. Mari kita tulis loop sederhana untuk mencetak panjang jendela waktu sesuai dengan pnl dari data pelatihan dan menemukan loop terbaik.
# Find the window length 0-254
# that gives the highest returns using this strategy
length_scores = [trade(data['ADBE'].iloc[:1762],
data['MSFT'].iloc[:1762], l, 5)
for l in range(255)]
best_length = np.argmax(length_scores)
print ('Best window length:', best_length)
('Best window length:', 40)
Sekarang kita memeriksa kinerja model pada data tes, dan kita menemukan bahwa panjang jendela waktu ini jauh dari optimal! Ini karena pilihan asli kita jelas over-fit data sampel.
# Find the returns for test data
# using what we think is the best window length
length_scores2 = [trade(data['ADBE'].iloc[1762:],
data['MSFT'].iloc[1762:],l,5)
for l in range(255)]
print (best_length, 'day window:', length_scores2[best_length])
# Find the best window length based on this dataset,
# and the returns using this window length
best_length2 = np.argmax(length_scores2)
print (best_length2, 'day window:', length_scores2[best_length2])
(40, 'day window:', 1252233.1395)
(15, 'day window:', 1449116.4522)
Jelas bahwa data sampel yang cocok untuk kita tidak selalu akan menghasilkan hasil yang baik di masa depan.
plt.figure(figsize=(15,7))
plt.plot(length_scores)
plt.plot(length_scores2)
plt.xlabel('Window length')
plt.ylabel('Score')
plt.legend(['Training', 'Test'])
plt.show()
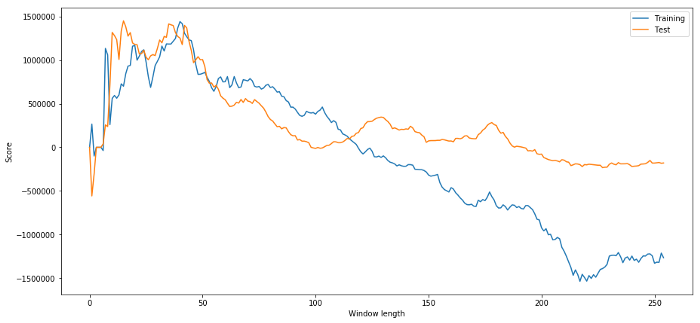
Kita dapat melihat bahwa apa pun antara 20 dan 50 adalah pilihan yang baik untuk jendela waktu.
Untuk menghindari overfit, kita dapat menggunakan penalaran ekonomi atau sifat algoritma untuk memilih panjang jendela waktu.
Langkah selanjutnya.
Dalam artikel ini, kami mengusulkan beberapa metode pengenalan sederhana untuk menunjukkan proses pengembangan strategi perdagangan. Dalam prakteknya, statistik yang lebih kompleks harus digunakan.
Eksponen Hurst;
Waktu paruh regresi rata-rata menyimpulkan dari proses Ornstein-Uhlenbeck;
Filter Kalman.
- Praktik Kuantitatif Bursa DEX (2) -- Panduan Pengguna Hyperliquid
- DEX Exchange Quantitative Practice ((2) -- Hyperliquid Panduan Penggunaan
- Praktik Kuantitatif Bursa DEX (1) -- DYdX v4 Panduan Pengguna
- Pengantar ke Lead-Lag Arbitrage dalam Cryptocurrency (3)
- Praktik Kuantitatif DEX Exchange ((1)-- dYdX v4 Panduan Penggunaan
- Penjelasan tentang suite Lead-Lag dalam mata uang digital (3)
- Pengantar ke Lead-Lag Arbitrage dalam Cryptocurrency (2)
- Penjelasan tentang suite Lead-Lag dalam mata uang digital (2)
- Pembahasan Penerimaan Sinyal Eksternal Platform FMZ: Solusi Lengkap untuk Penerimaan Sinyal dengan Layanan Http Terbina dalam Strategi
- FMZ platform eksplorasi penerimaan sinyal eksternal: strategi built-in https layanan solusi lengkap untuk penerimaan sinyal
- Pengantar ke Lead-Lag Arbitrage dalam Cryptocurrency (1)
- Jaringan saraf dan Seri Perdagangan Kuantitatif Mata Uang Digital (2) - Pelatihan dan Pelatihan Intensif Strategi Perdagangan Bitcoin
- Jaringan Neural dan Seri Perdagangan Kuantitatif Mata Uang Digital (1) - LSTM Memprediksi Harga Bitcoin
- Aplikasi strategi kombinasi SMA dan indeks kekuatan relatif RSI
- Pengembangan strategi CTA dan perpustakaan kelas standar dari platform FMZ Quant
- Strategi perdagangan kuantitatif dengan analisis momentum harga di Python
- Mengimplementasikan Strategi Perdagangan Kuantitatif Mata Uang Digital Dual Thrust di Python
- Cara terbaik untuk menginstal dan meningkatkan untuk Linux docker
- Mencapai strategi ekuitas yang seimbang dengan keselarasan yang teratur
- Analisis Data Seri Waktu dan Tes Balik Data Tick
- Analisis Kuantitatif Pasar Mata Uang Digital
- Aplikasi Teknologi Pembelajaran Mesin dalam Perdagangan
- Menggunakan lingkungan penelitian untuk menganalisis rincian lindung nilai segitiga dan dampak biaya penanganan pada perbedaan harga lindung nilai
- Reformasi Deribit API berjangka untuk beradaptasi dengan perdagangan kuantitatif opsi
- Alat yang lebih baik membuat pekerjaan yang baik - belajar menggunakan lingkungan penelitian untuk menganalisis prinsip perdagangan
- Strategi lindung nilai lintas mata uang dalam perdagangan kuantitatif aset blockchain
- Dapatkan panduan strategi mata uang digital FMex di FMZ Quant
- Mengajarkan Anda untuk menulis strategi -- transplantasi strategi MyLanguage (Advanced)
- Mengajarkan Anda untuk menulis strategi -- menanam strategi MyLanguage
- Mengajarkan Anda untuk menambahkan dukungan multi-chart untuk strategi
- Mengajarkan Anda untuk menulis fungsi sintesis K-line dalam versi Python