Buat robot perdagangan Bitcoin yang tidak akan kehilangan uang
Penulis:FMZ~Lydia, Dibuat: 2023-02-01 11:52:21, Diperbarui: 2024-12-24 20:25:11
Buat robot perdagangan Bitcoin yang tidak akan kehilangan uang
Mari kita gunakan pembelajaran penguatan dalam AI untuk membangun robot perdagangan mata uang digital.
Dalam artikel ini, kita akan membuat dan menerapkan angka frame pembelajaran yang ditingkatkan untuk belajar bagaimana membuat robot perdagangan Bitcoin. Dalam tutorial ini, kita akan menggunakan gym OpenAI dan robot PPO dari perpustakaan stable-baselines, yang merupakan cabang dari perpustakaan baseline OpenAI.
Terima kasih banyak untuk perangkat lunak open source yang disediakan oleh OpenAI dan DeepMind untuk para peneliti pembelajaran mendalam dalam beberapa tahun terakhir. Jika Anda belum melihat pencapaian luar biasa mereka dengan AlphaGo, OpenAI Five, AlphaStar dan teknologi lainnya, Anda mungkin telah hidup dalam isolasi tahun lalu, tetapi Anda harus memeriksanya.
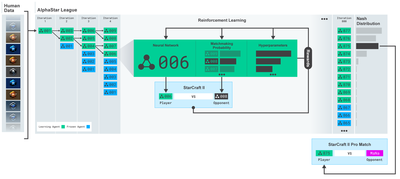
Pelatihan AlphaStar:https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
Meskipun kita tidak akan membuat sesuatu yang mengesankan, masih tidak mudah untuk perdagangan robot Bitcoin dalam transaksi sehari-hari.
Tidak ada nilai dalam apa pun yang terlalu sederhana.
Oleh karena itu, kita tidak hanya harus belajar untuk berdagang sendiri, tetapi juga membiarkan robot berdagang untuk kita.
Rencana

Buat lingkungan gym untuk robot kita untuk melakukan pembelajaran mesin
Membuat lingkungan visual yang sederhana dan elegan
Latih robot kita untuk mempelajari strategi perdagangan yang menguntungkan
Jika Anda tidak terbiasa dengan cara membuat lingkungan gym dari awal, atau bagaimana hanya membuat visualisasi lingkungan ini. Sebelum melanjutkan, jangan ragu untuk google artikel semacam ini.
Memulai
Dalam tutorial ini, kita akan menggunakan dataset Kaggle yang dihasilkan oleh Zielak. Jika Anda ingin mengunduh kode sumber, itu akan disediakan di repositori Github saya, bersama dengan file data.csv. Oke, mari kita mulai.
Pertama, mari kita impor semua perpustakaan yang diperlukan.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
Selanjutnya, mari kita membuat kelas kita untuk lingkungan. Kita perlu lulus dalam nomor bingkai data Panda dan opsional initial_balance dan lookback_window_size, yang akan menunjukkan jumlah langkah waktu lalu diamati oleh robot di setiap langkah. Kita default komisi setiap transaksi untuk 0.075%, yaitu, nilai tukar saat ini Bitmex, dan default parameter serial untuk palsu, yang berarti bahwa nomor bingkai data kita akan dilalui oleh fragmen acak secara default.
Kita juga memanggil dropna() dan reset_index() pada data, pertama menghapus baris dengan nilai NaN, dan kemudian mengatur ulang indeks nomor frame, karena kita telah menghapus data.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
Action_space kami diwakili sebagai kelompok 3 opsi (beli, jual atau tahan) di sini dan kelompok lain dari 10 jumlah (1⁄10, 2⁄10, 3⁄10Saat kita memilih untuk membeli, kita akan membeli jumlah * self.balance kata BTC. Untuk menjual, kita akan menjual jumlah * self.btc_held worth of BTC. Tentu saja, memegang akan mengabaikan jumlah dan tidak melakukan apa-apa.
Observation_space didefinisikan sebagai titik terapung terus menerus yang ditetapkan antara 0 dan 1, dan bentuknya adalah (10, lookback_window_size+1). + 1 digunakan untuk menghitung langkah waktu saat ini. Untuk setiap langkah waktu di jendela, kita akan mengamati nilai OHCLV. Nilai bersih kita sama dengan jumlah BTC yang kita beli atau jual, dan jumlah total dolar yang kita habiskan atau terima pada BTC ini.
Selanjutnya, kita perlu menulis metode reset untuk menginisialisasi lingkungan.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
Di sini kita menggunakan self._reset_session dan self._next_observation, yang belum kita definisikan. Mari kita definisikan mereka terlebih dahulu.
Sesi perdagangan
Bagian penting dari lingkungan kita adalah konsep sesi trading. Jika kita mengerahkan robot ini di luar pasar, kita mungkin tidak pernah menjalankannya selama lebih dari beberapa bulan pada suatu waktu. Untuk alasan ini, kita akan membatasi jumlah frame berturut-turut di self.df, yang merupakan jumlah frame yang dapat dilihat robot kita pada satu waktu.
Dalam metode _reset_session kami, kami mengatur ulang current_step ke 0 pertama. Selanjutnya, kami akan mengatur steps_left ke angka acak antara 1 hingga MAX_TRADING_SESSIONS, yang akan kami tentukan di bagian atas program.
MAX_TRADING_SESSION = 100000 # ~2 months
Selanjutnya, jika kita ingin melintasi jumlah frame secara berturut-turut, kita harus mengaturnya untuk melintasi seluruh jumlah frame, jika tidak kita mengatur frame_start ke titik acak di self.df dan membuat bingkai data baru bernama active_df, yang hanya sepotong dari self.df dan itu mendapatkan dari frame_start ke frame_start + steps_left.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
Efek samping penting dari melintasi jumlah frame data dalam irisan acak adalah bahwa robot kita akan memiliki data yang lebih unik untuk digunakan dalam pelatihan jangka panjang. Misalnya, jika kita hanya melintasi jumlah frame data secara serial (yaitu, dari 0 sampai len(df)), kita hanya akan memiliki banyak titik data unik seperti jumlah frame data. Ruang observasi kita hanya dapat menggunakan jumlah diskrit keadaan pada setiap langkah waktu.
Namun, dengan melintasi potongan-potongan data secara acak, kita dapat membuat hasil perdagangan yang lebih berarti untuk setiap langkah waktu dalam set data awal, yaitu kombinasi perilaku perdagangan dan perilaku harga yang dilihat sebelumnya untuk membuat set data yang lebih unik.
Ketika langkah waktu setelah mengatur ulang lingkungan serial adalah 10, robot kami akan selalu berjalan dalam set data pada saat yang sama, dan ada tiga pilihan setelah setiap langkah waktu: beli, jual atau tahan. Untuk masing-masing dari tiga opsi, Anda membutuhkan opsi lain: 10%, 20%,... atau 100% dari jumlah implementasi tertentu. Ini berarti bahwa robot kami dapat menemukan salah satu dari 10 negara dari 103, total 1030 kasus.
Sekarang kembali ke lingkungan slicing acak kita. Ketika langkah waktu adalah 10, robot kita dapat berada dalam setiap langkah waktu len(df) dalam jumlah bingkai data. Dengan asumsi bahwa pilihan yang sama dibuat setelah setiap langkah waktu, itu berarti bahwa robot dapat mengalami keadaan unik dari setiap len(df) ke pangkat ke-30 dalam 10 langkah waktu yang sama.
Meskipun hal ini dapat membawa kebisingan yang cukup untuk set data besar, saya percaya bahwa robot harus diizinkan untuk belajar lebih banyak dari data terbatas kami. Kami masih akan melewati data tes kami secara serial untuk mendapatkan data terbaru dan tampaknya
Dilihat melalui mata robot
Melalui pengamatan lingkungan visual yang efektif, seringkali membantu untuk memahami jenis fungsi yang akan digunakan robot kita.
Pengamatan lingkungan visualisasi OpenCV
Setiap baris dalam gambar mewakili baris di observation_space. Empat baris pertama garis merah dengan frekuensi yang sama mewakili data OHCL, dan titik oranye dan kuning langsung di bawahnya mewakili volume perdagangan. Bar biru berfluktuasi di bawah ini mewakili nilai bersih robot, sementara bar yang lebih ringan di bawah ini mewakili transaksi robot.
Jika Anda mengamati dengan cermat, Anda bahkan dapat membuat peta lilin sendiri. Di bawah bilah volume perdagangan adalah antarmuka kode Morse, yang menampilkan riwayat perdagangan. Sepertinya robot kita harus dapat belajar cukup dari data di observation_space kita, jadi mari kita lanjutkan. Di sini kita akan mendefinisikan metode _next_observation, kita skala data yang diamati dari 0 hingga 1.
- Penting untuk memperluas hanya data yang diamati oleh robot sejauh ini untuk mencegah penyimpangan utama.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
Lakukan tindakan
Kami telah menetapkan ruang pengamatan kami, dan sekarang saatnya untuk menulis fungsi tangga kami, dan kemudian mengambil tindakan terjadwal robot. Setiap kali self.steps_left == 0 untuk sesi perdagangan kami saat ini, kami akan menjual BTC kami dan memanggil _reset_session(). Jika tidak, kami akan mengatur hadiah ke nilai bersih saat ini. Jika kami kehabisan dana, kami akan mengatur selesai ke True.
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
Mengambil tindakan perdagangan adalah sesederhana mendapatkan current_price, menentukan tindakan yang akan dieksekusi dan jumlah untuk membeli atau menjual.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
Akhirnya, dengan metode yang sama, kita akan menghubungkan transaksi ke self.trades dan memperbarui nilai bersih dan riwayat akun kita.
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
Robot kita dapat memulai lingkungan baru sekarang, menyelesaikan lingkungan secara bertahap, dan mengambil tindakan yang mempengaruhi lingkungan.
Perhatikan perdagangan robot kita
Metode rendering kita bisa sesederhana memanggil print (self.net_word), tapi tidak cukup menarik. Sebaliknya, kita akan menggambar grafik lilin sederhana, yang berisi grafik terpisah dari kolom volume perdagangan dan kekayaan bersih kita.
Kami akan mendapatkan kode di StockTrackingGraph.py dari artikel terakhir saya dan mendesainnya kembali untuk beradaptasi dengan lingkungan Bitcoin. Anda bisa mendapatkan kode dari Github saya.
Perubahan pertama yang perlu kita lakukan adalah memperbarui self.df [
from datetime import datetime
Pertama, impor perpustakaan waktu tanggal, dan kemudian kita akan menggunakan metode utcfromtimestamp untuk mendapatkan string UTC dari setiap timestamp dan strftime sehingga diformat sebagai string: format Y-m-d H: M.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
Akhirnya, kita akan mengubah self. df[
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
Kita bisa melihat robot kami berdagang Bitcoin sekarang.
Bayangkan robot kami berdagang dengan Matplotlib
Label hantu hijau mewakili pembelian BTC, dan label hantu merah mewakili penjualan. Label putih di pojok kanan atas adalah nilai bersih saat ini dari robot, dan label di pojok kanan bawah adalah harga Bitcoin saat ini. Ini sederhana dan elegan. Sekarang, saatnya untuk melatih robot kita dan melihat berapa banyak uang yang bisa kita hasilkan!
Waktu pelatihan
Salah satu kritik yang saya terima dalam artikel sebelumnya adalah kurangnya validasi silang dan kegagalan untuk membagi data menjadi training set dan test set. Tujuan dari ini adalah untuk menguji keakuratan model akhir pada data baru yang belum pernah terlihat sebelumnya. Meskipun ini bukan fokus dari artikel itu, itu benar-benar sangat penting. Karena kita menggunakan data deret waktu, kita tidak memiliki banyak pilihan dalam validasi silang.
Sebagai contoh, bentuk umum dari cross-validation disebut k-fold validation. Dalam validasi ini, Anda membagi data menjadi k kelompok yang sama, satu per satu, secara individual, sebagai kelompok uji dan menggunakan sisa data sebagai kelompok pelatihan. Namun, data deret waktu sangat tergantung pada waktu, yang berarti bahwa data berikutnya sangat tergantung pada data sebelumnya. Jadi k-fold tidak akan bekerja, karena robot kita akan belajar dari data masa depan sebelum perdagangan, yang merupakan keuntungan yang tidak adil.
Ketika diterapkan pada data deret waktu, kekurangan yang sama berlaku untuk sebagian besar strategi penyangkalan silang lainnya. Oleh karena itu, kita hanya perlu menggunakan sebagian dari nomor bingkai data lengkap sebagai set pelatihan dari nomor bingkai ke beberapa indeks sewenang-wenang, dan menggunakan sisa data sebagai set tes.
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
Selanjutnya, karena lingkungan kita hanya diatur untuk menangani satu jumlah frame data, kita akan membuat dua lingkungan, satu untuk data pelatihan dan satu untuk data tes.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
Sekarang, melatih model kita sesederhana membuat robot menggunakan lingkungan kita dan memanggil model.learn.
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
Di sini, kita menggunakan pelat tensor, sehingga kita dapat memvisualisasikan grafik aliran tensor dengan mudah dan melihat beberapa indikator kuantitatif tentang robot kita.
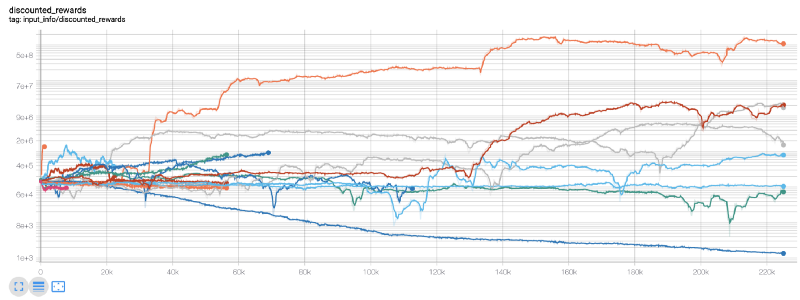
Wow, sepertinya robot kami sangat menguntungkan! Robot terbaik kami bahkan bisa mencapai keseimbangan 1000x dalam 200.000 langkah, dan sisanya akan meningkat setidaknya 30 kali rata-rata!
Pada saat ini, aku menyadari bahwa ada kesalahan di lingkungan... setelah memperbaiki bug, ini adalah grafik hadiah baru:
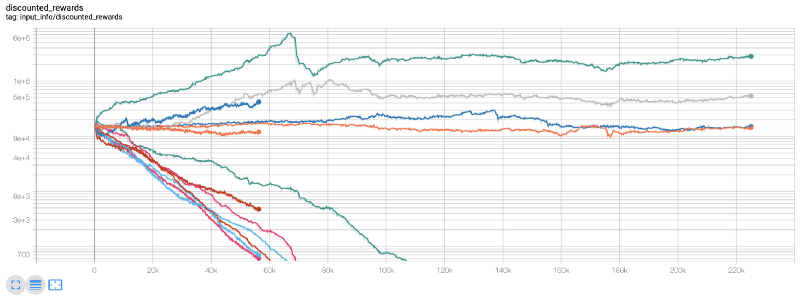
Seperti yang Anda lihat, beberapa robot kami berjalan dengan baik, sementara yang lain bangkrut. Namun, robot dengan kinerja yang baik dapat mencapai 10 kali atau bahkan 60 kali saldo awal paling banyak. Saya harus mengakui bahwa semua mesin yang menguntungkan dilatih dan diuji tanpa komisi, jadi tidak realistis bagi robot kami untuk menghasilkan uang sungguhan. Tapi setidaknya kami menemukan jalan!
Mari kita uji robot kita di lingkungan pengujian (menggunakan data baru yang belum pernah mereka lihat sebelumnya) untuk melihat bagaimana perilaku mereka.
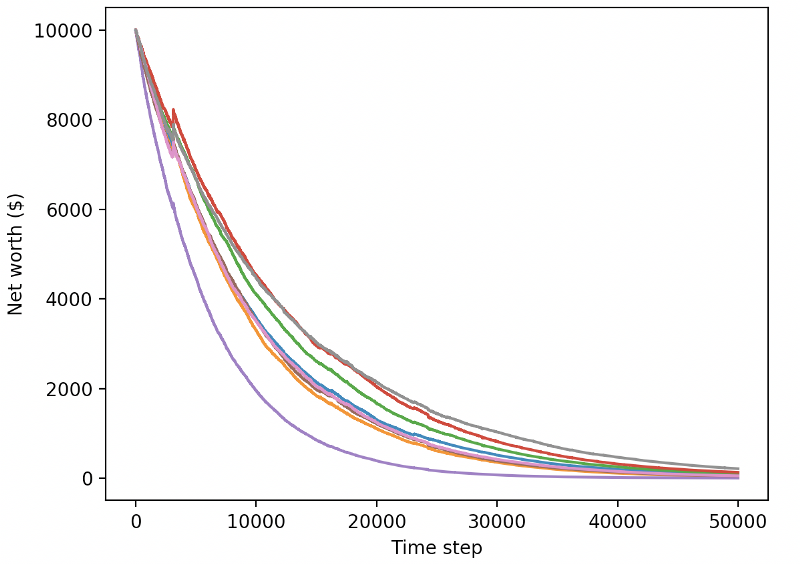
Robot kami yang terlatih akan bangkrut saat memperdagangkan data uji baru.
Jelas, kita masih memiliki banyak pekerjaan yang harus dilakukan. Dengan hanya beralih model untuk menggunakan A2C dengan garis dasar yang stabil alih-alih robot PPO2 saat ini, kita dapat meningkatkan kinerja kita pada set data ini sangat besar. Akhirnya, menurut saran Sean O
reward = self.net_worth - prev_net_worth
Dua perubahan ini saja dapat meningkatkan kinerja dari kumpulan data uji secara signifikan, dan seperti yang Anda lihat di bawah ini, kami akhirnya bisa mendapatkan keuntungan dari data baru yang tidak tersedia dalam kumpulan pelatihan.
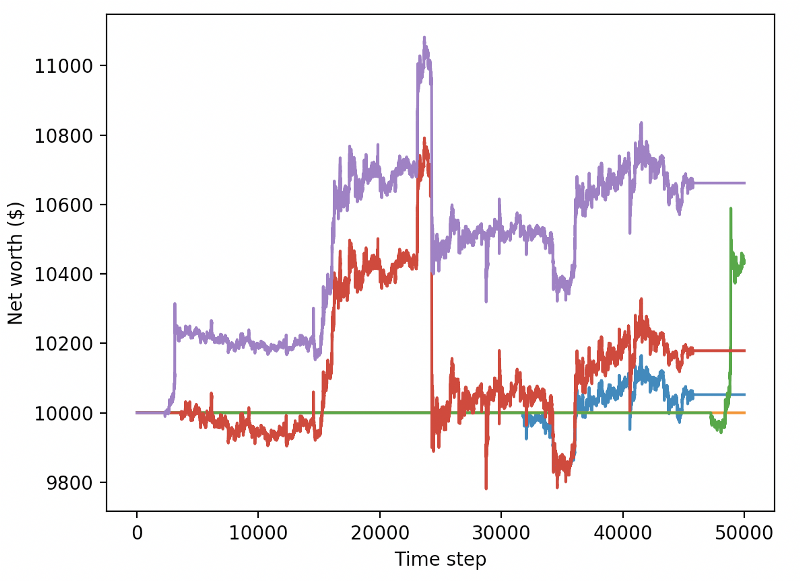
Tapi kita bisa melakukan yang lebih baik. Untuk meningkatkan hasil ini, kita perlu mengoptimalkan parameter super kita dan melatih robot kita untuk waktu yang lebih lama.
Sejauh ini, artikel ini agak panjang, dan kami masih memiliki banyak detail untuk dipertimbangkan, jadi kami berencana untuk beristirahat di sini.
Kesimpulan
Dalam artikel ini, kita mulai menggunakan pembelajaran penguatan untuk membuat robot perdagangan Bitcoin yang menguntungkan dari nol.
Buatlah lingkungan perdagangan Bitcoin dari nol menggunakan gym OpenAI.
Gunakan Matplotlib untuk membangun visualisasi lingkungan.
Gunakan cross-validasi sederhana untuk melatih dan menguji robot kita.
Sesuaikan robot kita sedikit untuk mencapai keuntungan.
Meskipun robot trading kami tidak menguntungkan seperti yang kami harapkan, kami sudah bergerak ke arah yang benar. Lain kali, kami akan memastikan bahwa robot kami dapat secara konsisten mengalahkan pasar. Kami akan melihat bagaimana robot trading kami memproses data real-time. Silakan ikuti artikel saya berikutnya dan Viva Bitcoin!
- Praktik Kuantitatif Bursa DEX (2) -- Panduan Pengguna Hyperliquid
- DEX Exchange Quantitative Practice ((2) -- Hyperliquid Panduan Penggunaan
- Praktik Kuantitatif Bursa DEX (1) -- DYdX v4 Panduan Pengguna
- Pengantar ke Lead-Lag Arbitrage dalam Cryptocurrency (3)
- Praktik Kuantitatif DEX Exchange ((1)-- dYdX v4 Panduan Penggunaan
- Penjelasan tentang suite Lead-Lag dalam mata uang digital (3)
- Pengantar ke Lead-Lag Arbitrage dalam Cryptocurrency (2)
- Penjelasan tentang suite Lead-Lag dalam mata uang digital (2)
- Pembahasan Penerimaan Sinyal Eksternal Platform FMZ: Solusi Lengkap untuk Penerimaan Sinyal dengan Layanan Http Terbina dalam Strategi
- FMZ platform eksplorasi penerimaan sinyal eksternal: strategi built-in https layanan solusi lengkap untuk penerimaan sinyal
- Pengantar ke Lead-Lag Arbitrage dalam Cryptocurrency (1)
- Membuat program kebijakan benar-benar berjalan secara paralel, menambahkan dukungan multi-threaded pada dasar sistem untuk kebijakan JavaScript
- Jika kau tidak tahu bagaimana menulis strategi dalam bahasa Pine yang mudah dipelajari dan mudah digunakan...
- Penghasilan yang diharapkan dari perdagangan frekuensi tinggi
- Bisakah kita melakukan perdagangan kuantitatif tanpa kode?
- "Mendapatkan kesepakatan terbaik" analisis kerentanan di bursa
- 5.6 Membangun pemikiran probabilitas untuk meningkatkan pola perdagangan Anda
- Uniswap V3 diakses di FMZ dengan 200 baris kode
- Ketika FMZ menemukan ChatGPT, upaya untuk menggunakan AI untuk membantu dalam belajar perdagangan kuantitatif
- 9 aturan trading membantu trader menghasilkan $46,000 dari $1,000 dalam waktu kurang dari setahun
- Dari Perdagangan Kuantitatif ke Manajemen Aset - Pengembangan Strategi CTA untuk Pengembalian Absolute
- Rahasia Hidup: 19 Profesional Berbagi Saran tentang Perdagangan Mata Uang Digital
- Menggunakan JavaScript untuk menerapkan eksekusi bersamaan strategi kuantitatif - merangkum fungsi Go
- Aplikasi "Shannon's Demon" dalam Mata Uang Digital
- Uniswap V3 di FMZ dengan kode 200 baris
- Prinsip dan penyusunan model stop loss
- Tycoon mengungkapkan algoritma perdagangan: FMZ Quant platform market maker strategi
- Tiga model potensial dalam perdagangan kuantitatif
- Sistem Perdagangan Intraday Pivot Point
- 6 Strategi dan Praktek Sederhana untuk Pemula dalam Perdagangan Kuantitatif Mata Uang Digital
- Kerangka strategi rentang rata-rata yang benar