ドイツ銀行の報告書の研究ノートでは、定量戦略におけるよくある間違いをいくつか挙げている。
 0
2275
0
2275
ドイツ銀行の報告書の研究ノートでは、定量戦略におけるよくある間違いをいくつか挙げている。
- ### “生存者バイアス”
生存者偏差は投資家が直面する最も一般的な問題の一つであり,多くの人々が生存者偏差の存在を知っていますが,その効果を重んじることはほとんどありません.我々は,現在存在している企業のみを使用する傾向があり,これは,破綻や再編によって市販から撤退した企業の影響を排除することを意味します.
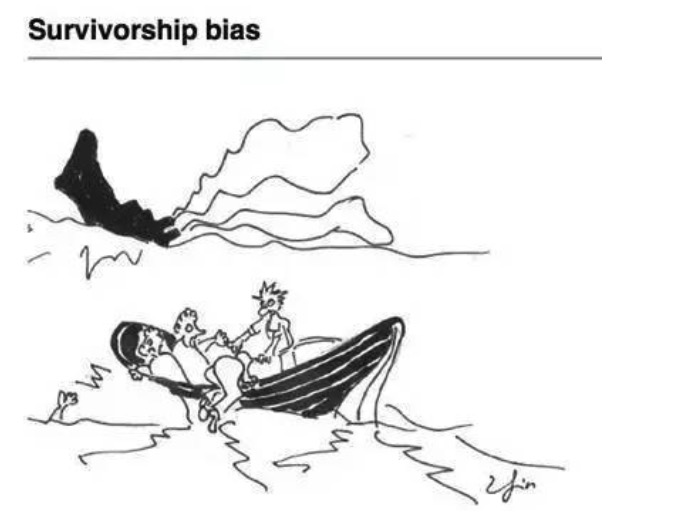
破産,退市,不良な業績を上げている株は,定期的に削除されます. これらの削除された株は,あなたの戦略の株式プールに含まれていません. つまり,過去の反省は,現在構成する株のみを使用しています. 将来の業績や株価の不良なパフォーマンスのために構成株から削除された株の影響を除きます. 下の図は,MSCI欧州指数成分などの重量のある株のポートフォリオとしての過去のパフォーマンスを示しています. 青い線は正しいポートフォリオであり,赤い線は生存者差が偏っているポートフォリオです.
 グラフ1
グラフ1
生存者偏差は投資家が直面する最も一般的な問題の一つであり,多くの人々が生存者偏差の存在を知っていますが,その効果を重んじることはほとんどありません.我々は,現在存在している企業のみを使用する傾向があり,これは,破綻や再編によって市販から撤退した企業の影響を排除することを意味します.
破産,退市,不良な業績を上げている株は,定期的に削除されます. これらの削除された株は,あなたの戦略の株式プールに含まれていません. つまり,過去の反省は,現在構成する株のみを使用しています. 将来の業績や株価の不良なパフォーマンスのために構成株から削除された株の影響を除きます. 下の図は,MSCI欧州指数成分などの重量のある株のポートフォリオとしての過去のパフォーマンスを示しています. 青い線は正しいポートフォリオであり,赤い線は生存者差が偏っているポートフォリオです.
 2 図
2 図
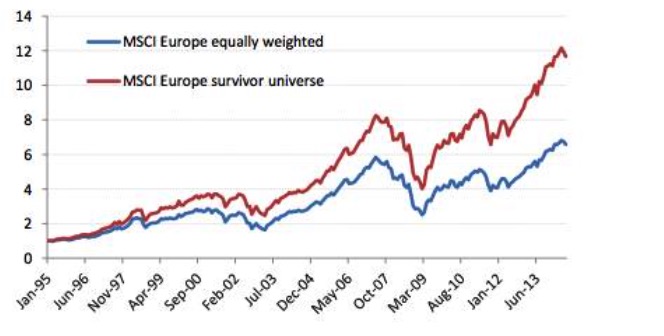
つまり 過去30年にわたって最も良い業績をあげた企業を 振り返ってみると 信用リスクが高い企業もあれば 誰が生き残るかはわかっているので 信用リスクが高いか 困った時に買って 利益は高いのです 破産や退市や不良業績を挙げると 逆に 信用リスクの高い企業への投資は 長期的には 信用リスクの高い企業よりも 利益が低いという結論にたどり着きます
生き残った人の偏差を考慮すると 逆の結果が得られる要素が たくさんあります
 3 図
3 図
- ### 2 前向きな偏見
 グラフ4
グラフ4
7つの罪の一つである生存者偏差は,私たちが過去の時点に立っている時に,どの企業が生き残り,今日もインデックス成分株であるかを予測することができないことであり,生存者偏差は,単なる先見偏差の一種である.先見偏差は,当時利用できなかった,または公開されていないデータを用いて,再評価を意味する.これは,再評価における最も一般的な誤りである.
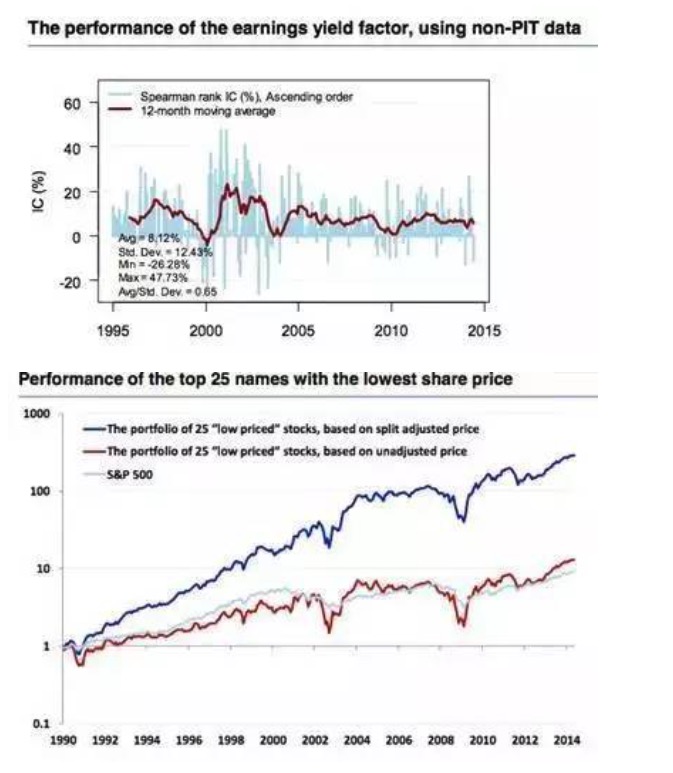
前視偏差の明らかな例は,財務データに表れている.財務データの修正は,検出し難い間違いを引き起こす可能性が高い.一般的には,各社の財務データが公表される時期は異なるが,往々にして遅れがある.反省では,各社のデータ公開の時期に基づいて会社の財務状況を評価する傾向がある.
しかし,その時点でポイントデータ (Point-in-time data,略してPIT data) が入手できない場合,財務報告の遅れの仮定はしばしば誤りである.下図は,PITデータと非PITデータによる差異を証明している.また,歴史的なマクロデータをダウンロードすると,修正された最終値が得られるが,多くの先進国のGDPデータが出版された後に二度調整され,大企業の財務報告の修正も頻繁に修正される.我々が再計測する時点で,最終値はまだ知られず,初期値の分析のみを使用することができる.微小な修正が結論に影響を与える可能性があるが,実際は,多くのマクロデータが初期値による再帰の結果が目立たないことを示す.財務データの調整は,株式選出結果に直接影響を与える.
 グラフ5
グラフ5
- ### 3つ目は 物語を語ること
 グラフ6
グラフ6
データの無いところから物語を語り始めることを好む人もいれば, 量化をする人はデータと結果を持って物語を語りたがる. この2つの状況には多くの類似点があります. 物語を語る上達者,あるいはデータ結果を解釈する上達者というのは, データを入手する前に, 既定の脚本が心の中に存在し, データの裏付けを見つけるだけでよいのです.
1997年から2000年,そして2000年から2002年のアメリカ・テクノロジー・コンポーネント・株式とラッセル3000指数を振り返ると,私たちはまったく逆の結論を見出す.1997年から2000年のアメリカ・テクノロジー・コンポーネント・株式からみると,利率は良い要因であり,裏付けも十分信頼できます.しかし,2002年の間を長引くと,利率指数がもはや良い要因ではないことがわかります.
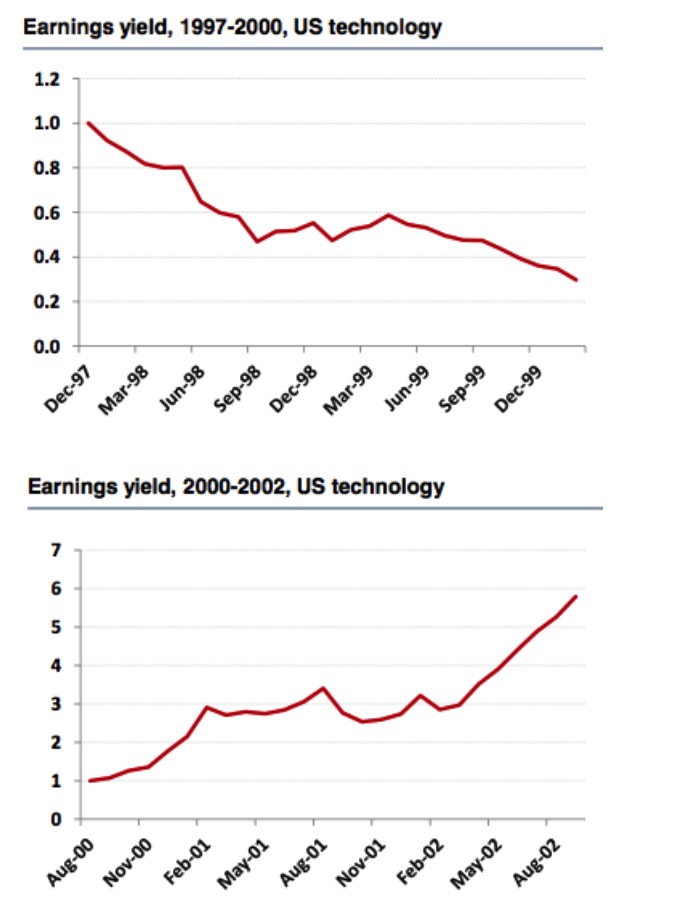 グラフ7
グラフ7
しかし,ラッセル3000指数の市場の動きから,私たちはその逆の結論を得ました. 利回り指数は有効な要因であり, 株式池の選択と再測定の時間は,有効性の判断に非常に大きな影響を与えていることがわかります.
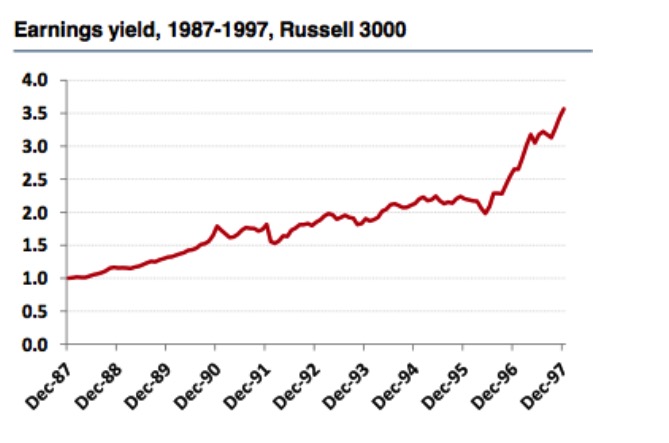 グラフ8
グラフ8
市場では毎日新しい好因のを発見し,永続的な動機を探しています. 公開できる戦略は,反省し,良いパフォーマンスをしています. 物語の語り手は,歴史の説明が非常に魅力的ですが,将来の予測はほとんど役に立たないです. 金融経済における関連性や因果性は,よく理解するのが難しいので,私たちが常識に反したり,元の判断と一致する結果を出したとき,物語の語り手になることはお勧めしません.
- ### 4 データマイニングとデータスヌーピング
 グラフ9
グラフ9
データマイニングは,大量のデータとコンピュータの計算力によって支えられ,人々がしばしば知覚し難い好因数値を得る事を期待する,現在注目されている分野であると言えます.しかし,元の金融データはまだ膨大な量に達していません.取引データは,低騒音値のデータ前提を満たしていません.
時にデータ採掘はほとんど無効である.例えば,我々は,スタンプ500指数に対して2つの異なる因数加重アルゴリズムをモデル化し,2009年~2014年のデータを選択した.結果として,2009年~2014年のデータを用いて,最も優れたパフォーマンスを発揮した6つの因子を選抜し,等重量アルゴリズムを使用した結果が非常に完璧であり,歴史データを使用したサンプル外回測の結果は直線である.
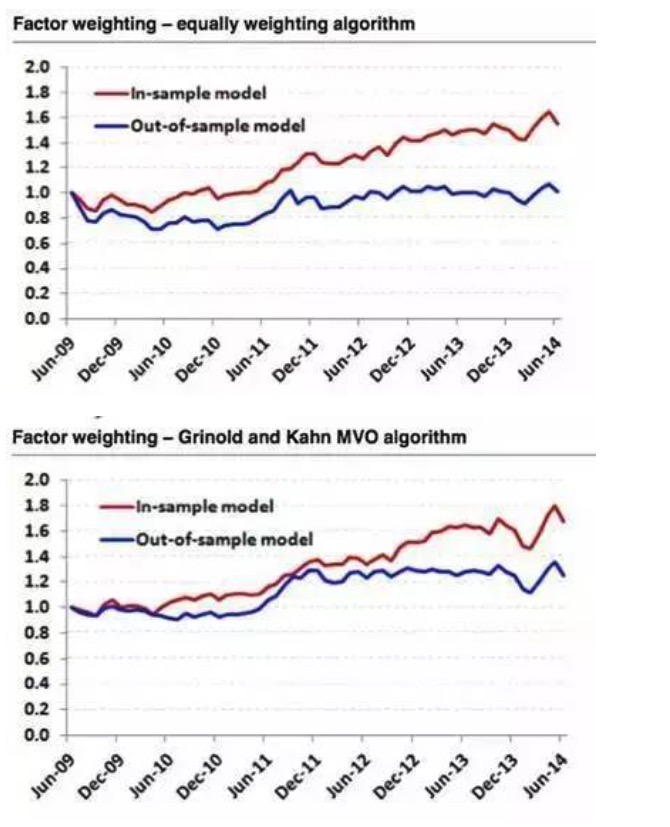 グラフ10
グラフ10
したがって,戦略を策定したり,良い因子を探したりする際には,我々は明確な論理と動機を持つべきであり,定量分析は論理のショートカットではなく,自分の論理や動機を検証するためのツールである. 一般的に,戦略を策定したり,因子を探したりする動機は,金融学の基礎理論知識,市場の有効性,行動金融学などの分野から多く出ます. もちろん,我々は,データマイニングの応用価値を定量領域で否定していません.
- ### 5 信号衰退,ターンオーバー,トランザクションコスト
 グラフ11
グラフ11
信号衰退は,ある要因が生み出された後,今後どのくらいの期間で株価が戻るかを予測する能力を指す. 一般的に,高い換算率と信号衰退は関係している.異なる株価選択因子は,異なる情報衰退特性を有する.信号衰退が速くなるほど,利益を得るためにより高い換算率が必要になる.しかし,より高い換算率は,往々にして取引コストもより高いことを意味する.ポートフォリオの構築に換算率の束縛を追加することは,比較的簡単な方法ですが,最も理想的な方法ではありません.
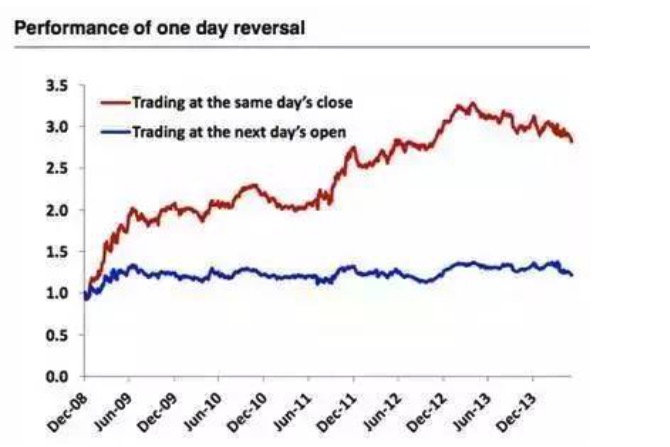
では,最適の調整頻度をどのように決定するか? 注目すべきは,交替レートの制約を厳格にするということは,調整頻度を低下させるという意味ではないということです. 例えば,私たちはよく似たようなことを聞きます. 例えば,私たちは長期の価値投資家であり,私たちは株を3~5年間保有することを期待しています. したがって,私たちは年に一度調整することが可能です. しかし,情報は急速に流れており,私たちはモデルと予想を適時に調整する必要があります.
 グラフ12
グラフ12
毎日閉店時にその日の最悪な100株を買い,過去の保有を売却し,日々の取引を継続し,収益率が非常に高い.ここでの誤りは,先見偏差でもある.閉店台を没収するまでは,その日の最悪な100株がどの株だったかわからない,つまり,プログラム取引を使う,この戦略も不可能である.我々は,その日の開場価格で,昨日の最悪な100株しか買えない.対照的に,開場価格で買いの戦略はほぼ直線である.
- ### 6 異常値 (Outliers) について
 グラフ13
グラフ13
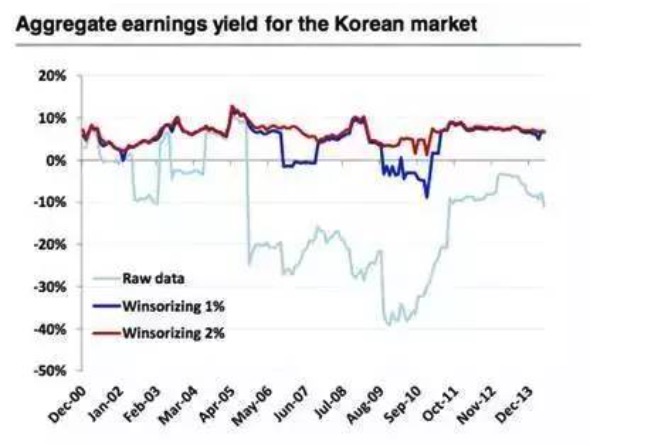
伝統的な異常値制御技術は主にwinsorizationとtruncationの2種類を含む.データの標準化は,異常値制御の1つの方法として近似的に見ることができる.標準化技術は,モデルのパフォーマンスに顕著な影響を与える可能性がある.例えば,下図のスタンプBMI韓国指数成分株の利率,平均値,1%や2%の極値を除去などの方法の結果は大きく異なっています.マクロデータではしばしばこのような問題が発生し,極値の少数は,事前処理を行わないと,結果に深刻な影響を与えるでしょう.
 グラフ14
グラフ14
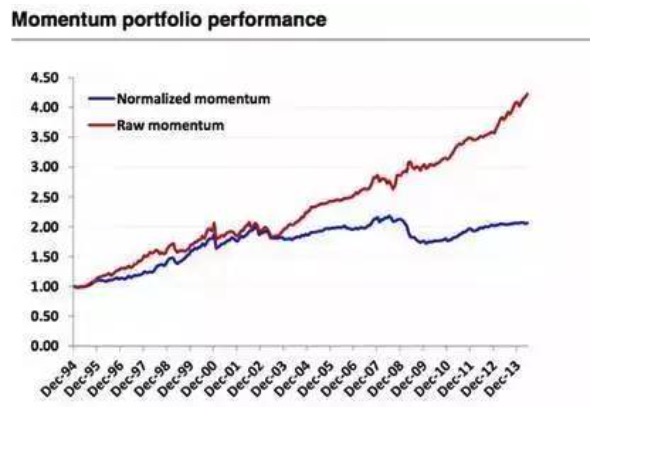
異常値には有用な情報が含まれている可能性があるが,ほとんどの場合,それらは有用な情報を含まない.当然,価格動態因子については例外である.青い線は異常値を除いた組み合わせのパフォーマンスであり,赤い線は原始データである.原始データの動態戦略は,異常値を除いた戦略のパフォーマンスよりもはるかに優れていることがわかります.つまり,異常値には多くの情報が含まれています.
 15 図
15 図
- ### 7 非対称性 (The asymmetric payoff pattern and shorting) [対称性のない報酬パターンとショートリング]
 グラフ16
グラフ16
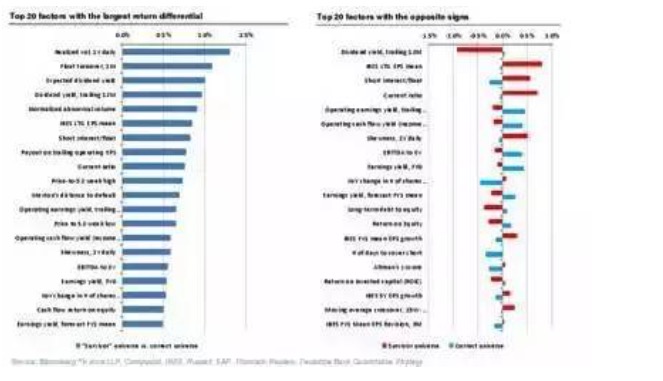
一般的に,多因子戦略を行う際によく使われる策略は多空策である,すなわち,多良い株を同時に多空差とする株である.残念ながら,すべての因子は等しくありません.多空の利益特性が存在し,多空のコストと実在可能性が加え,多空のコストと実在可能性が存在し,量化投資にも大きな困難をもたらします.以下の図は,多空の利益特性を示し,差異の大きさに並べています.多空の需要と高取引コストのために,上位の因子ほど,過剰なアルファを得ることが難しくなります.同時に,価値因子は多端から利益を得る傾向があり,価格動因子と質量因子により多空の利益特性を得ることがより多く見られます.修正因子分析者は,多空の利益特性をより多く持つ傾向があります.
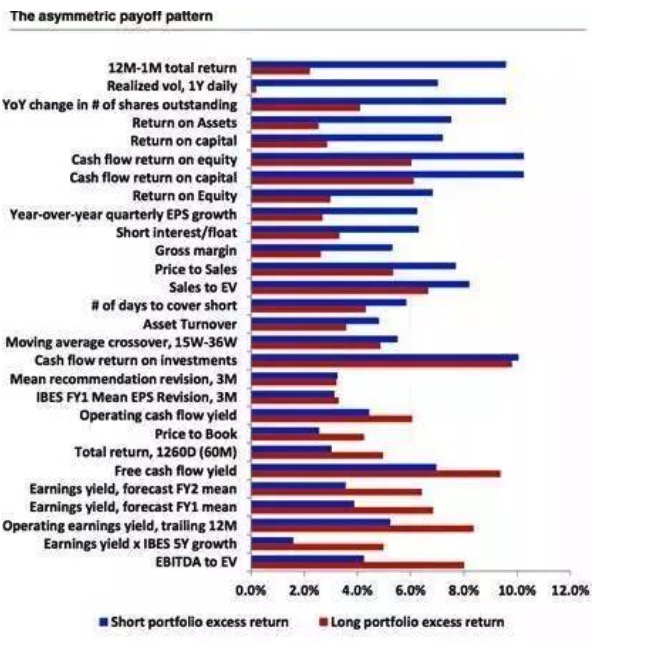 グラフ17
グラフ17
ウォール街の散歩