デジタル通貨因数モデル
作者: リン・ハーンFMZ~リディア, 作成日:2022-10-24 17:37:50, 更新日:2023-09-15 20:59:38
要素モデル枠組み
株式市場のマルチファクタモデルに関する研究報告は,豊富な理論と実践を備えた大量である.デジタル通貨市場の通貨数,総市場価値,取引量,派生品市場などに関係なく,ファクタリサーチを行うだけで十分である.この論文は主に定量戦略の初心者向けで,複雑な数学的原理や統計分析を伴うものではない.ファクタリサーチのための簡単な枠組みを構築するために,データソースとしてバイナンスパーペチュアル・フューチャーマーケットを使用し,ファクタリサーチに便利である.
要素は指標として考えられ,表現も書ける.要因は,将来の収入情報を反映して絶えず変化する.一般的に,要因は投資論理を表す.
例えば,閉じる価格ファクタルの前提は,株価が将来の収益を予測でき,株価が高くなるほど,将来の収益が高くなる (または低いかもしれない).実際には,この要因に基づいてポートフォリオを構築することは,定期的なラウンドで高価格の株を購入するための投資モデル/戦略である.一般的に,過剰利益を生むことが可能な要因もアルファと呼ばれます.例えば,市場価値ファクタとモメントファクタは,学界と投資コミュニティによって一度有効な要因として検証されています.
株式市場とデジタル通貨市場の両方が複雑なシステムである.将来の利益を完全に予測できる要因はないが,それでも一定の予測可能性がある.効果的なアルファ (投資モード) は,より多くの資本投入により徐々に無効になる.しかし,このプロセスは市場で他のモデルを生み出し,新しいアルファを生む.市場価値因子は,A株市場で非常に効果的な戦略であった.最低市場価値を持つ10株を購入して,1日1回調整するだけです. 2007年以来,10年遅れのテストは,全体の市場をはるかに上回る利益の400倍以上をもたらします.しかし,2017年のホワイトホース株式市場は,小市場価値因子の失敗を反映し,価値因子は人気になりました.したがって,私たちは常にバランスを確認し,アルファを使用しようとする必要があります.
求められる要因は戦略の確立の基礎である.複数の関係のない効果的な要因を組み合わせることでより良い戦略を構築することができる.
import requests
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests, zipfile, io
%matplotlib inline
データ源
現在まで,2022年初頭から現在までのバイナンスUSDT永久期貨の時間K線データは150通貨を超えています.前述したように,因子モデルは通貨選択モデルで,特定の通貨ではなくすべての通貨に指向しています.K線データには,高値開閉低値,取引量,取引数,テイカー購入量などのデータが含まれています.これらのデータは,米国株式指数,利率上昇予想,収益性,チェーン上のデータ,ソーシャルメディアの人気などすべての要因の源ではありません.異常なデータソースも効果的なアルファを見つけることができますが,基本的な価格の量は十分です.
## Current trading pair
Info = requests.get('https://fapi.binance.com/fapi/v1/exchangeInfo')
symbols = [s['symbol'] for s in Info.json()['symbols']]
symbols = list(filter(lambda x: x[-4:] == 'USDT', [s.split('_')[0] for s in symbols]))
print(symbols)
終了しました.
['BTCUSDT', 'ETHUSDT', 'BCHUSDT', 'XRPUSDT', 'EOSUSDT', 'LTCUSDT', 'TRXUSDT', 'ETCUSDT', 'LINKUSDT',
'XLMUSDT', 'ADAUSDT', 'XMRUSDT', 'DASHUSDT', 'ZECUSDT', 'XTZUSDT', 'BNBUSDT', 'ATOMUSDT', 'ONTUSDT',
'IOTAUSDT', 'BATUSDT', 'VETUSDT', 'NEOUSDT', 'QTUMUSDT', 'IOSTUSDT', 'THETAUSDT', 'ALGOUSDT', 'ZILUSDT',
'KNCUSDT', 'ZRXUSDT', 'COMPUSDT', 'OMGUSDT', 'DOGEUSDT', 'SXPUSDT', 'KAVAUSDT', 'BANDUSDT', 'RLCUSDT',
'WAVESUSDT', 'MKRUSDT', 'SNXUSDT', 'DOTUSDT', 'DEFIUSDT', 'YFIUSDT', 'BALUSDT', 'CRVUSDT', 'TRBUSDT',
'RUNEUSDT', 'SUSHIUSDT', 'SRMUSDT', 'EGLDUSDT', 'SOLUSDT', 'ICXUSDT', 'STORJUSDT', 'BLZUSDT', 'UNIUSDT',
'AVAXUSDT', 'FTMUSDT', 'HNTUSDT', 'ENJUSDT', 'FLMUSDT', 'TOMOUSDT', 'RENUSDT', 'KSMUSDT', 'NEARUSDT',
'AAVEUSDT', 'FILUSDT', 'RSRUSDT', 'LRCUSDT', 'MATICUSDT', 'OCEANUSDT', 'CVCUSDT', 'BELUSDT', 'CTKUSDT',
'AXSUSDT', 'ALPHAUSDT', 'ZENUSDT', 'SKLUSDT', 'GRTUSDT', '1INCHUSDT', 'CHZUSDT', 'SANDUSDT', 'ANKRUSDT',
'BTSUSDT', 'LITUSDT', 'UNFIUSDT', 'REEFUSDT', 'RVNUSDT', 'SFPUSDT', 'XEMUSDT', 'BTCSTUSDT', 'COTIUSDT',
'CHRUSDT', 'MANAUSDT', 'ALICEUSDT', 'HBARUSDT', 'ONEUSDT', 'LINAUSDT', 'STMXUSDT', 'DENTUSDT', 'CELRUSDT',
'HOTUSDT', 'MTLUSDT', 'OGNUSDT', 'NKNUSDT', 'SCUSDT', 'DGBUSDT', '1000SHIBUSDT', 'ICPUSDT', 'BAKEUSDT',
'GTCUSDT', 'BTCDOMUSDT', 'TLMUSDT', 'IOTXUSDT', 'AUDIOUSDT', 'RAYUSDT', 'C98USDT', 'MASKUSDT', 'ATAUSDT',
'DYDXUSDT', '1000XECUSDT', 'GALAUSDT', 'CELOUSDT', 'ARUSDT', 'KLAYUSDT', 'ARPAUSDT', 'CTSIUSDT', 'LPTUSDT',
'ENSUSDT', 'PEOPLEUSDT', 'ANTUSDT', 'ROSEUSDT', 'DUSKUSDT', 'FLOWUSDT', 'IMXUSDT', 'API3USDT', 'GMTUSDT',
'APEUSDT', 'BNXUSDT', 'WOOUSDT', 'FTTUSDT', 'JASMYUSDT', 'DARUSDT', 'GALUSDT', 'OPUSDT', 'BTCUSDT',
'ETHUSDT', 'INJUSDT', 'STGUSDT', 'FOOTBALLUSDT', 'SPELLUSDT', '1000LUNCUSDT', 'LUNA2USDT', 'LDOUSDT',
'CVXUSDT']
print(len(symbols))
終了しました.
153
#Function to obtain any period of K-line
def GetKlines(symbol='BTCUSDT',start='2020-8-10',end='2021-8-10',period='1h',base='fapi',v = 'v1'):
Klines = []
start_time = int(time.mktime(datetime.strptime(start, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000
end_time = min(int(time.mktime(datetime.strptime(end, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000,time.time()*1000)
intervel_map = {'m':60*1000,'h':60*60*1000,'d':24*60*60*1000}
while start_time < end_time:
mid_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
url = 'https://'+base+'.binance.com/'+base+'/'+v+'/klines?symbol=%s&interval=%s&startTime=%s&endTime=%s&limit=1000'%(symbol,period,start_time,mid_time)
res = requests.get(url)
res_list = res.json()
if type(res_list) == list and len(res_list) > 0:
start_time = res_list[-1][0]+int(period[:-1])*intervel_map[period[-1]]
Klines += res_list
if type(res_list) == list and len(res_list) == 0:
start_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
if mid_time >= end_time:
break
df = pd.DataFrame(Klines,columns=['time','open','high','low','close','amount','end_time','volume','count','buy_amount','buy_volume','null']).astype('float')
df.index = pd.to_datetime(df.time,unit='ms')
return df
start_date = '2022-1-1'
end_date = '2022-09-14'
period = '1h'
df_dict = {}
for symbol in symbols:
df_s = GetKlines(symbol=symbol,start=start_date,end=end_date,period=period,base='fapi',v='v1')
if not df_s.empty:
df_dict[symbol] = df_s
symbols = list(df_dict.keys())
print(df_s.columns)
終了しました.
Index(['time', 'open', 'high', 'low', 'close', 'amount', 'end_time', 'volume',
'count', 'buy_amount', 'buy_volume', 'null'],
dtype='object')
関心のあるデータ:閉店価格,開店価格,取引量,取引数,テイカー購入比率は,まずK線データから抽出されます.これらのデータに基づいて,必要な要素が処理されます.
df_close = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_open = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_volume = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_buy_ratio = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_count = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
for symbol in df_dict.keys():
df_s = df_dict[symbol]
df_close[symbol] = df_s.close
df_open[symbol] = df_s.open
df_volume[symbol] = df_s.volume
df_count[symbol] = df_s['count']
df_buy_ratio[symbol] = df_s.buy_amount/df_s.amount
df_close = df_close.dropna(how='all')
df_open = df_open.dropna(how='all')
df_volume = df_volume.dropna(how='all')
df_count = df_count.dropna(how='all')
df_buy_ratio = df_buy_ratio.dropna(how='all')
市場指数の全体的な業績は悲観的なもので,年末から最近まで60%低下しています.
df_norm = df_close/df_close.fillna(method='bfill').iloc[0] #normalization
df_norm.mean(axis=1).plot(figsize=(15,6),grid=True);
#Final index profit chart
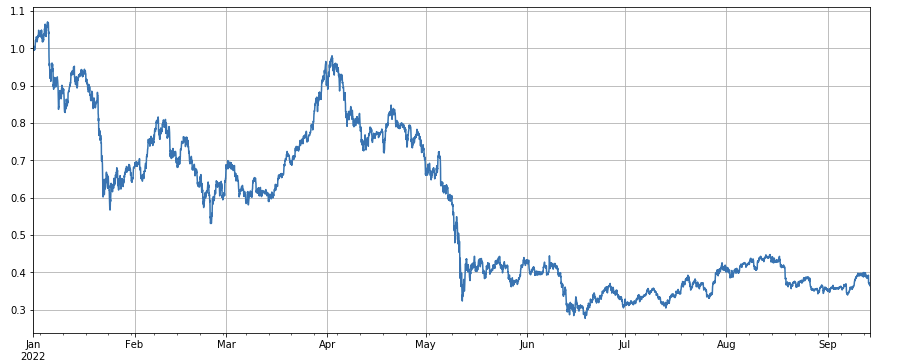
要素の有効性判断
-
リグレーション方法 次の期間の出力は依存変数であり,テストされる因子は独立変数である.回帰によって得られた係数は,その因子の出力でもある.回帰方程式が構築された後,因子の有効性と変動性は,通常,係数t値の絶対平均値,係数t値の絶対値配列の比率が2を超える割合,年間因子収益率,年間因子利益の変動率,および要素利益のシャープ比率を参照して見られる.複数の因子を一度に回帰することができる.詳細については,barra文書を参照してください.
-
IC,IRその他の指標 ICと呼ばれるものは,因子と次の期間のリターン率との間の相関係数である.現在,RANK_ ICも一般的に使用されており,因子ランキングと次のストックリターン率との間の相関係数である. IRは一般的にIC配列の平均値/IC配列の標準偏差である.
-
階層化回帰方法 本文では,この方法を用いて,検証対象となる要因に応じて通貨を整理し,グループバックテストのためにNグループに分割し,ポジション調整のために固定期間を使用します.状況が理想的であれば,グループN通貨の収益率は,単調的に増加または減少し,各グループの収入格差が大きく,良い単調性を示します.そのような要因は良い差別に反映されます.最初のグループが最も高い利益を持ち,最後のグループが最も低い利益を持っている場合,最初のグループでロングに行き,シャープ比率の基準指標である最終的な収益を得るために最後のグループでショートします.
実際のバックテスト操作
選択されるコインは,要素の順序を最小から最大まで3つのグループに分けられる.各通貨グループは合計の約1/3を占める.要素が有効であれば,各グループ内のポイント数が小さいほど,収益率は高くなるが,それはまた,各通貨が比較的多くの資金を割り当てていることを意味します.長期と短期ポジションがそれぞれダブルレバレッジであり,最初のグループと最後のグループがそれぞれ10つの通貨である場合,,1つの通貨は合計の10%を占める.短縮された通貨が倍増した場合,20%が引き出されます.グループ数が50の場合,4%が引き出されます.多元化通貨はブラックスワンのリスクを減らすことができます.最初のグループ (最小値要素) を長引けば,3番目のグループに行く.要因が大きいほど,収益数が高くなるほど,あなたは単に長期または短期ポジションを逆転して,負または逆の負の収益に変えることができます.
一般的に,因子予測能力は,最終バックテストの返答率とシャープ比率に基づいて概ね評価することができる.さらに,因子式が単純で,グループサイズに敏感で,位置調整間隔に敏感で,バックテストの初期時間にも敏感であるかどうかを参照する必要がある.
ポジション調整の頻度に関して,株式市場は通常,5日,10日,1ヶ月の期間があります.しかし,デジタル通貨市場では,そのような期間は疑いなく長すぎており,実際のボットでの市場はリアルタイムで監視されています.再びポジションを調整するために特定の期間に固執する必要はありません.したがって,実際のボットでは,私たちはリアルタイムまたは短い時間でポジションを調整します.
ポジションを閉じる方法については,従来の方法によると,ポジションが次回ソートするときにグループに入っていない場合,ポジションは閉じることができます.しかし,リアルタイムポジション調整の場合,一部の通貨は境界線にちょうど位置している可能性があります.これは前後回転のポジション閉じる可能性があります.したがって,この戦略は,グループ変更を待つ方法を採用し,反対方向にポジションを開く必要があるときにポジションを閉じる方法です.例えば,最初のグループはロングになります.ロングポジションの状態にある通貨が3番目のグループに分かれると,ポジションを閉じてショートします.ポジションが毎日または8時間ごとに固定された期間中に閉ざされた場合,グループに入らずにポジションを閉じることもできます.できるだけ試してみてください.
#Backtest engine
class Exchange:
def __init__(self, trade_symbols, fee=0.0004, initial_balance=10000):
self.initial_balance = initial_balance #Initial assets
self.fee = fee
self.trade_symbols = trade_symbols
self.account = {'USDT':{'realised_profit':0, 'unrealised_profit':0, 'total':initial_balance, 'fee':0, 'leverage':0, 'hold':0}}
for symbol in trade_symbols:
self.account[symbol] = {'amount':0, 'hold_price':0, 'value':0, 'price':0, 'realised_profit':0,'unrealised_profit':0,'fee':0}
def Trade(self, symbol, direction, price, amount):
cover_amount = 0 if direction*self.account[symbol]['amount'] >=0 else min(abs(self.account[symbol]['amount']), amount)
open_amount = amount - cover_amount
self.account['USDT']['realised_profit'] -= price*amount*self.fee #Net of fees
self.account['USDT']['fee'] += price*amount*self.fee
self.account[symbol]['fee'] += price*amount*self.fee
if cover_amount > 0: #Close position first
self.account['USDT']['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount #Profits
self.account[symbol]['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount
self.account[symbol]['amount'] -= -direction*cover_amount
self.account[symbol]['hold_price'] = 0 if self.account[symbol]['amount'] == 0 else self.account[symbol]['hold_price']
if open_amount > 0:
total_cost = self.account[symbol]['hold_price']*direction*self.account[symbol]['amount'] + price*open_amount
total_amount = direction*self.account[symbol]['amount']+open_amount
self.account[symbol]['hold_price'] = total_cost/total_amount
self.account[symbol]['amount'] += direction*open_amount
def Buy(self, symbol, price, amount):
self.Trade(symbol, 1, price, amount)
def Sell(self, symbol, price, amount):
self.Trade(symbol, -1, price, amount)
def Update(self, close_price): #Update assets
self.account['USDT']['unrealised_profit'] = 0
self.account['USDT']['hold'] = 0
for symbol in self.trade_symbols:
if not np.isnan(close_price[symbol]):
self.account[symbol]['unrealised_profit'] = (close_price[symbol] - self.account[symbol]['hold_price'])*self.account[symbol]['amount']
self.account[symbol]['price'] = close_price[symbol]
self.account[symbol]['value'] = abs(self.account[symbol]['amount'])*close_price[symbol]
self.account['USDT']['hold'] += self.account[symbol]['value']
self.account['USDT']['unrealised_profit'] += self.account[symbol]['unrealised_profit']
self.account['USDT']['total'] = round(self.account['USDT']['realised_profit'] + self.initial_balance + self.account['USDT']['unrealised_profit'],6)
self.account['USDT']['leverage'] = round(self.account['USDT']['hold']/self.account['USDT']['total'],3)
#Function of test factor
def Test(factor, symbols, period=1, N=40, value=300):
e = Exchange(symbols, fee=0.0002, initial_balance=10000)
res_list = []
index_list = []
factor = factor.dropna(how='all')
for idx, row in factor.iterrows():
if idx.hour % period == 0:
buy_symbols = row.sort_values().dropna()[0:N].index
sell_symbols = row.sort_values().dropna()[-N:].index
prices = df_close.loc[idx,]
index_list.append(idx)
for symbol in symbols:
if symbol in buy_symbols and e.account[symbol]['amount'] <= 0:
e.Buy(symbol,prices[symbol],value/prices[symbol]-e.account[symbol]['amount'])
if symbol in sell_symbols and e.account[symbol]['amount'] >= 0:
e.Sell(symbol,prices[symbol], value/prices[symbol]+e.account[symbol]['amount'])
e.Update(prices)
res_list.append([e.account['USDT']['total'],e.account['USDT']['hold']])
return pd.DataFrame(data=res_list, columns=['total','hold'],index = index_list)
単純な因子テスト
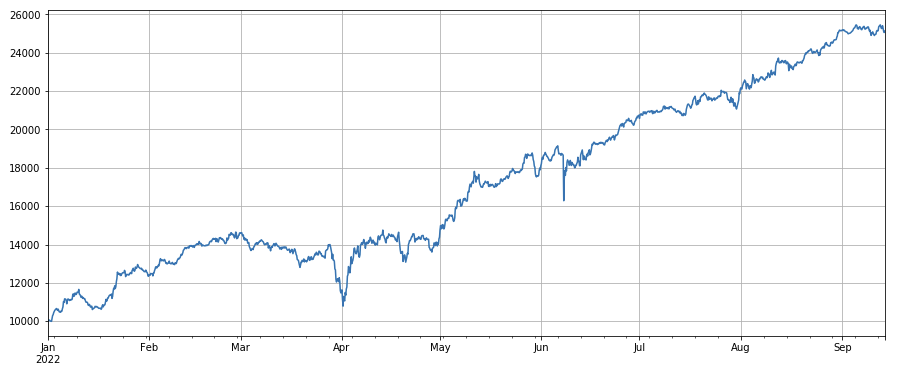
取引量因子: 取引量が少ない単純な長通貨と,取引量が高い短い通貨が非常に良好なパフォーマンスを示し,人気通貨が減少傾向にあることを示しています.
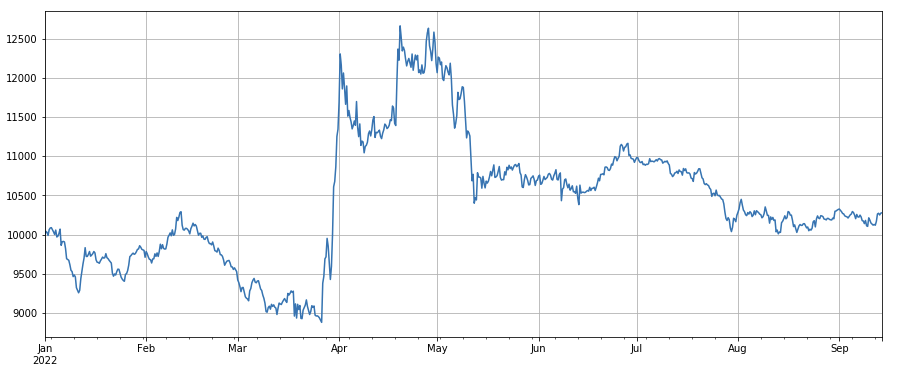
低価格の長通貨と高価格の短通貨の両方の効果は普通です.
トランザクション数因子:パフォーマンスがトランザクション数量と非常に似ている.トランザクション数因子とトランザクション数因子の相関性が非常に高いことは明らかである.実際には,異なる通貨でそれらの間の平均相関率は0.97に達し,この2つの因子が非常に似ていることを示している.複数の因子を合成する際にこの因子を考慮する必要があります.
3hモメントファクター: (df_close - df_close. shift (3)) /df_ close. shift(3).つまり,ファクターの3時間の上昇.バックテスト結果は,3時間の上昇が明らかな回帰特性を有することを示しています.つまり,上昇は後で落ちやすいです.全体的なパフォーマンスはOKですが,長期間の撤退と振動もあります.
24h モメントファクター: 24h ポジション調整期間の結果は良好で,出力は 3h モメントと類似し,引き上げは小さい.
取引量の変化因数:df_ volume.rolling(24).mean() /df_ volume.rolling (96). mean(),つまり,最後の日の取引量と過去3日の取引量の比率である.ポジションは8時間ごとに調整される.バックテストの結果は良好であり,引き出しは比較的低く,活発な取引量を持つ企業が減少する傾向が高いことを示している.
トランザクション番号の変化因数: df_ count.rolling ((24).mean() /df_ count.rolling ((96). mean (),つまり,最後の日のトランザクション番号と最後の3日のトランザクション番号の比率.ポジションは8hごとに調整されます.バックテストの結果は良好であり,引き出も比較的低いため,アクティブトランザクションボリュームを持つ企業は減少傾向が高いことを示しています.
単一の取引価値の変化因数: - ((df_volume.rolling(24).mean() /df_count.rolling(24.mean()) /(df_volume.rolling(24.mean() /df_count.rolling(96.mean()) 取引額は,過去3日間の取引額の比率であり,ポジションは8時間ごとに調整されます.この要因は,取引量の因数とも密接に関連しています.
取引比率によるテイカーの変化因子: df_buy_ratio.rolling ((24).mean() /df_buy_ratio.rolling ((96).mean(),つまり,テイカーの取引量による過去3日間の取引総量に対する取引総量に対する比率であり,ポジションは8時間ごとに調整されます.この因子はかなりうまく動作し,取引量因子との相関はほとんどありません.
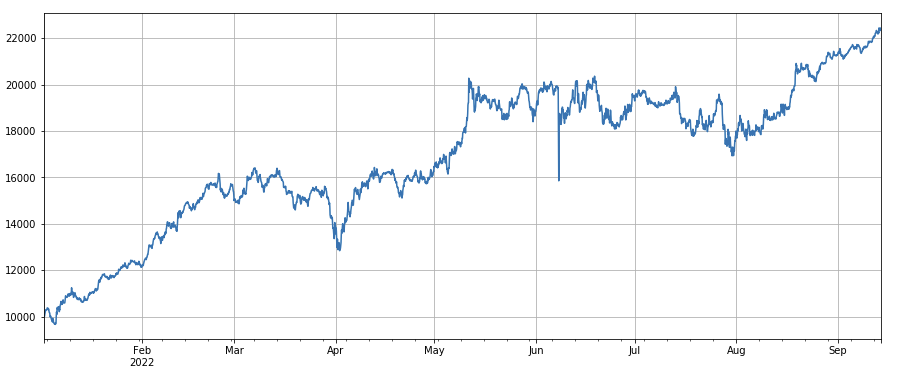
波動性因子: (df_close/df_open).rolling ((24).std ((),低波動性を持つ通貨をロングする,それは一定の効果を持っています.
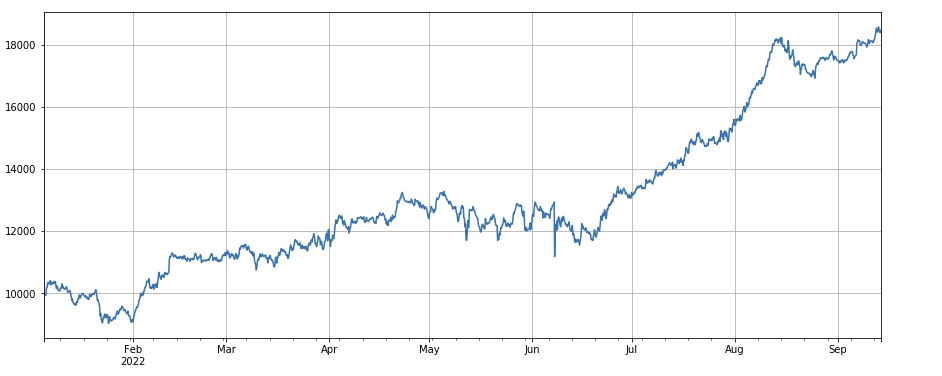
df_close.rolling ((96).corr ((df_volume),過去4日間の閉店価格は,取引量の相関因数を持ち,全体的に良好な業績を示しています.
ここでリストされている要素は価格量に基づいています. 実際,因子式の組み合わせは,明らかな論理なしに非常に複雑です.有名なALPHA101因子構築方法を参照してください:https://github.com/STHSF/alpha101.
#transaction volume
factor_volume = df_volume
factor_volume_res = Test(factor_volume, symbols, period=4)
factor_volume_res.total.plot(figsize=(15,6),grid=True);
#transaction price
factor_close = df_close
factor_close_res = Test(factor_close, symbols, period=8)
factor_close_res.total.plot(figsize=(15,6),grid=True);
#transaction count
factor_count = df_count
factor_count_res = Test(factor_count, symbols, period=8)
factor_count_res.total.plot(figsize=(15,6),grid=True);
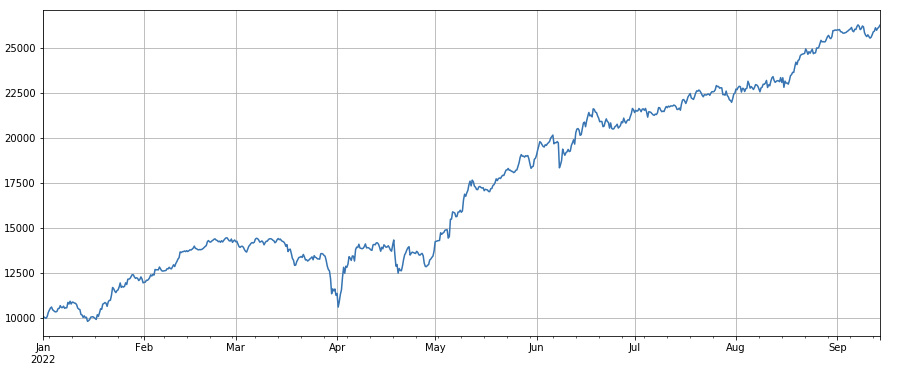
print(df_count.corrwith(df_volume).mean())
0.9671246744996017
#3h momentum factor
factor_1 = (df_close - df_close.shift(3))/df_close.shift(3)
factor_1_res = Test(factor_1,symbols,period=1)
factor_1_res.total.plot(figsize=(15,6),grid=True);
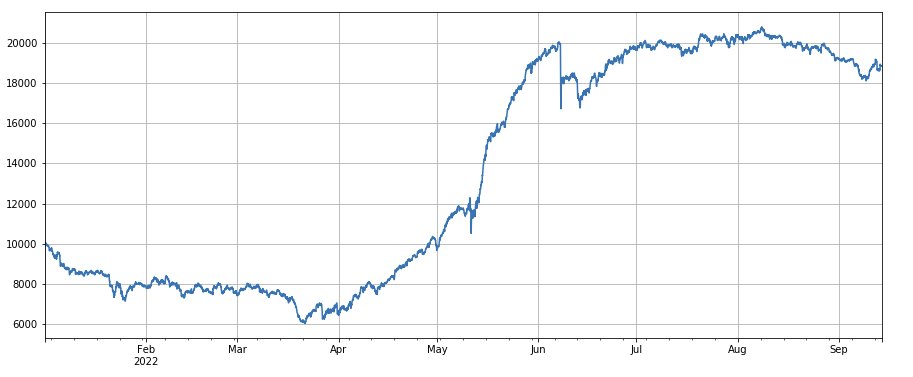
#24h momentum factor
factor_2 = (df_close - df_close.shift(24))/df_close.shift(24)
factor_2_res = Test(factor_2,symbols,period=24)
tamenxuanfactor_2_res.total.plot(figsize=(15,6),grid=True);
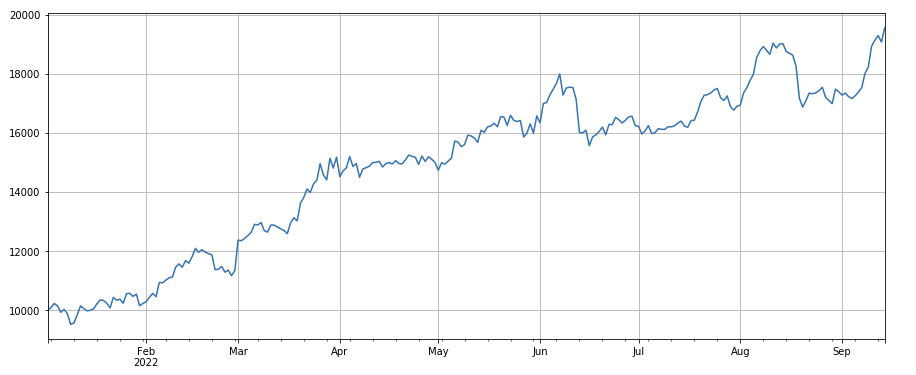
#factor of transaction volume
factor_3 = df_volume.rolling(24).mean()/df_volume.rolling(96).mean()
factor_3_res = Test(factor_3, symbols, period=8)
factor_3_res.total.plot(figsize=(15,6),grid=True);
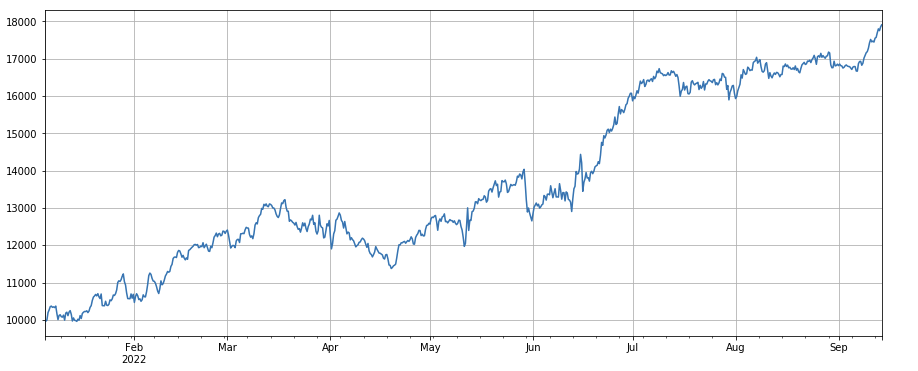
#factor of transaction number
factor_4 = df_count.rolling(24).mean()/df_count.rolling(96).mean()
factor_4_res = Test(factor_4, symbols, period=8)
factor_4_res.total.plot(figsize=(15,6),grid=True);
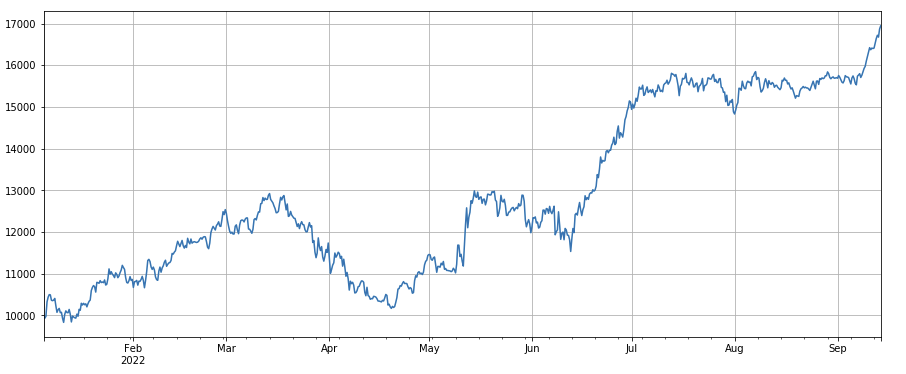
#factor correlation
print(factor_4.corrwith(factor_3).mean())
0.9707239580854841
#single transaction value factor
factor_5 = -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean())
factor_5_res = Test(factor_5, symbols, period=8)
factor_5_res.total.plot(figsize=(15,6),grid=True);
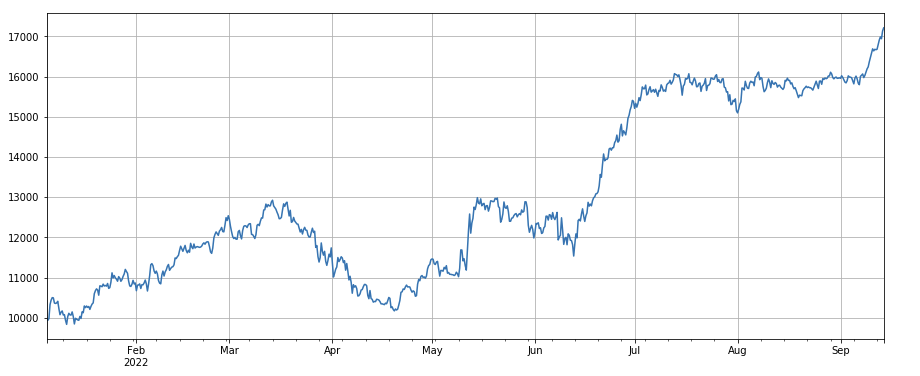
print(factor_4.corrwith(factor_5).mean())
0.861206620552479
#proportion factor of taker by transaction
factor_6 = df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean()
factor_6_res = Test(factor_6, symbols, period=4)
factor_6_res.total.plot(figsize=(15,6),grid=True);
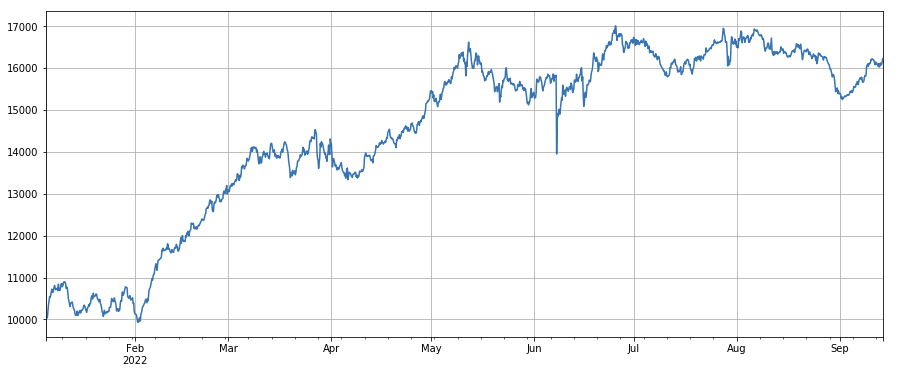
print(factor_3.corrwith(factor_6).mean())
0.1534572192503726
#volatility factor
factor_7 = (df_close/df_open).rolling(24).std()
factor_7_res = Test(factor_7, symbols, period=2)
factor_7_res.total.plot(figsize=(15,6),grid=True);
#correlation factor between transaction volume and closing price
factor_8 = df_close.rolling(96).corr(df_volume)
factor_8_res = Test(factor_8, symbols, period=4)
factor_8_res.total.plot(figsize=(15,6),grid=True);
多因子合成
戦略構築プロセスの最も重要な部分は,常に新しい有効な要因を発見することです.しかし,良い因子合成方法がなければ,優れた単一のアルファ因子は最大限の役割を果たすことはできません.一般的な多因子合成方法には以下が含まれます.
同重量方法:合成するすべての要素は,合成後に新しい要素を得るために等重で加算される.
歴史的因子回帰率の重み付け方法:組み合わせられるすべての因子は,合成後に新しい因子を得るための重みとして,最新の期間の歴史的因子回帰率の算術平均に応じて加算される.この方法でうまく機能する因子はより高い重みを持つ.
IC_IRを最大化する重量化方法: 複合因子の平均IC値は,次の期間の複合因子のIC値の推定として使用され,歴史的なIC値の共変数行列は,次の期間の複合因子の揮発性の推定として使用される.IC_IRによると,ICの予想値をICの標準偏差で割って最大複合因子のIC_IRの最適な重量ソリューションを得る.
主成分解析 (PCA):PCAはデータ次元縮小の一般的な方法であり,因子間の相関性は高い可能性があります.次元縮小後の主成分は合成因子として使用されます.
この論文では,因子有効性割り当てを手動で参照します.上記方法を参照できます.ae933a8c-5a94-4d92-8f33-d92b70c36119.pdf
単因子テストでは,ソートメントは固定されますが,マルチ因子合成はまったく異なるデータを組み合わせなければならないので,すべての因子が標準化され,極端値と欠けている値は一般的に削除する必要があります.ここで,合成のためにdf_ volume\factor_ 1\factor_ 7\factor_ 6\factor_ 8を使用します.
#standardize functions, remove missing values and extreme values, and standardize
def norm_factor(factor):
factor = factor.dropna(how='all')
factor_clip = factor.apply(lambda x:x.clip(x.quantile(0.2), x.quantile(0.8)),axis=1)
factor_norm = factor_clip.add(-factor_clip.mean(axis=1),axis ='index').div(factor_clip.std(axis=1),axis ='index')
return factor_norm
df_volume_norm = norm_factor(df_volume)
factor_1_norm = norm_factor(factor_1)
factor_6_norm = norm_factor(factor_6)
factor_7_norm = norm_factor(factor_7)
factor_8_norm = norm_factor(factor_8)
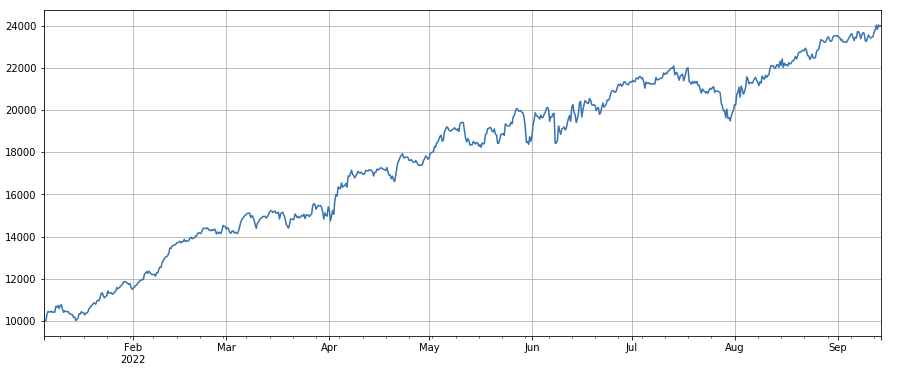
factor_total = 0.6*df_volume_norm + 0.4*factor_1_norm + 0.2*factor_6_norm + 0.3*factor_7_norm + 0.4*factor_8_norm
factor_total_res = Test(factor_total, symbols, period=8)
factor_total_res.total.plot(figsize=(15,6),grid=True);
概要
この論文は単因子試験方法を導入し,一般的な単因子試験方法を導入し,当初はマルチ因子合成方法を導入する.しかし,マルチ因子の研究コンテンツは多くあります.論文で言及されたすべてのポイントはさらに開発することができます.これはさまざまな戦略に関する研究をアルファ因子の探索に変える実行可能な方法です.因子方法論の使用は,取引アイデアの検証を大幅に加速させることができ,参考資料もたくさんあります.
- DEX取引所の量化実践 ((1)-- dYdX v4 ユーザーガイド
- デジタル通貨におけるリード-ラグ套路の紹介 (3)
- 暗号通貨におけるリード・ラグ・アービトラージへの導入 (2)
- デジタル通貨におけるリード-ラグ套路の紹介 (2)
- FMZプラットフォームの外部信号受信に関する議論: 戦略におけるHttpサービス内蔵の信号受信のための完全なソリューション
- FMZプラットフォームの外部信号受信に関する探求:戦略内蔵Httpサービス信号受信の完全な方案
- 暗号通貨におけるリード・ラグ・アービトラージへの導入 (1)
- デジタル通貨におけるリード-ラグ套路の紹介 (1)
- FMZプラットフォームの外部信号受信に関する議論:拡張API VS戦略内蔵HTTPサービス
- FMZプラットフォームの外部信号受信に関する探究:拡張API vs 戦略内蔵HTTPサービス
- ランダム・ティッカー・ジェネレーターに基づく戦略テスト方法に関する議論
- LeeksReaperのマジック・チェンジから 高周波戦略デザインを探索する
- リークスリーパー戦略分析 (2)
- YouTubeベテランの"マジック・ダブル・EMA戦略"
- フィッシャー指標のJavaScript言語の実装とFMZの描画
- dYdX 戦略設計の例
- FMZ Quant をベースにした注文同期管理システムの設計 (1)
- リークスリーパー戦略分析 (1)
- デリビット オプション デルタ ダイナミック・ヘッジ戦略
- 資金調達の戦略の最近の状況と推奨された運用
- 2021年のデジタル通貨市場の見直しと最もシンプルな10倍戦略の見逃し
- YouTubeの巨人『魔法のような双 EMA 均線戦略』
- パイン言語で半自動取引ツールを書く
- デジタル通貨の因数モデル
- 取引の中で自分の救世主になれ
- 暗号通貨の手動期貨とスポットのヘジング戦略
- 仮想通貨のスポットヘッジ戦略の設計 (1)
- 熊市場が底を下げるのに適した永続的なバランス戦略
- 初心者向け暗号通貨量的な取引 - 暗号通貨量的な取引に近づく (8)
- 初心者向け暗号通貨量的な取引 - 暗号通貨量的な取引に近づく (7)
- 初心者向け暗号通貨量的な取引 - 暗号通貨量的な取引に近づく (6)