양성 전략의 샘플 외 데이터 테스트의 필요성
저자:발명가들의 수량화 - 작은 꿈, 2018-01-26 12:11:58, 업데이트: 2019-07-31 18:03:38실제 빅데이터입니다. 양적 전략에 샘플을 제외한 데이터를 테스트해야 합니다.

-
NO:01
인간의 삶, 어린부터 어른까지, 어른부터 노인까지, 사실은 실수하고 수정하고 실수를 반복하는 과정입니다. 거의 아무도 예외가 아닙니다. 어쩌면 많은 실수를 한 적이있을 수도 있습니다. 현재는 매우 낮은 수준으로 보입니다. 또는 부동산, 인터넷, 디지털 통화 등과 같은 많은 기회를 놓쳤을 수도 있습니다.
그 들음의 한 종이 말하길 "나는 원래 그렇게 하지 않아야 했다"... "만약... 내가"...
저는 이 질문을 오랫동안 품고 있었고, 풀 수 없었지만, 나중에 깨달았습니다. 사실, 이것은 두려워할만한 것이 아니었습니다. 왜냐하면 그 당시의 모든 선택, 옳든 틀든, 우리를 미리 정해진 결과로부터 벗어나 अज्ञात으로 이끌고 갔기 때문입니다. 그리고 우리의 반성은 단지 역사적인 데이터에서 벗어난 하나님의 관점을 열어줍니다.
-
NO:02
나는 많은 거래 시스템을 보았는데, 리테이팅 시 성공률이 50% 이상이다. 이러한 높은 승률을 가정하면 또한 1:1 이상의 수익/손실 비율이 있을 수 있다. 그러나, 예외 없이, 이러한 시스템은 실제 판에 적용되면 기본적으로 손실을 입는다. 리테이팅 시, 실수로 오른쪽에서 왼쪽으로 바라보고, 신의 관점을 열었다는 것 중 손실을 초래하는 많은 이유가 있다.

그러나 거래는 복잡하게 얽혀있는 일이고, 후속 시선으로 볼 때 매우 명확하지만, 만약 우리가 하나님의 관점을 가지고 있지 않으면, 처음부터 다시 돌아가지 않으면, 여전히 미지수하다. 이것은 양적 근원 문제에 대한 역사적 데이터의 한계를 부딪히게 된다.
-
NO:03
그러나 제한된 데이터 상태에서 제한된 데이터를 최대한 활용하여 거래 전략을 종합적으로 검증하는 방법은 무엇입니까? 일반적으로 두 가지 방법이 있습니다.
역습 검사의 기본 원리는: 이전보다 더 긴 역사 데이터를 사용하여 모델을 훈련시키고, 그 다음 비교적 짧은 데이터를 사용하여 모델을 검사하고, 데이터의 창을 계속 뒤로 이동하여 훈련과 검사의 단계를 반복합니다.

1, 훈련 데이터: 2000년에서 2001년, 테스트 데이터: 2002년; 2 훈련 데이터: 2001년에서 2002년, 테스트 데이터: 2003년 3, 훈련 데이터 (2002~2003년, 테스트 데이터 (2004년) 4. 훈련 데이터: 2003년에서 2004년, 테스트 데이터: 2005년. 5. 훈련 데이터 (2004~2005년, 테스트 데이터 (2006년)
이 모든 것은 우리가 할 수 있는 일입니다.
마지막으로 (2002년, 2003년, 2004년, 2005년, 2006년...) 테스트 결과를 통계적으로 분석하여 전략의 성능을 종합적으로 평가합니다.
아래 그림에서 볼 수 있듯이, 이 후속 검사의 원리를 직관적으로 설명할 수 있습니다:
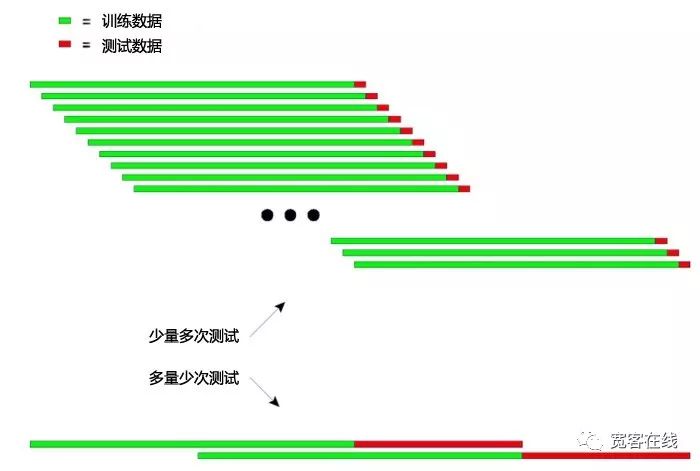
위 그림은 각각 두 가지 방법으로 진행 검사를 보여줍니다.
첫 번째: 검사를 한 번에 테스트 데이터가 짧고 테스트 횟수가 더 많습니다. 두 번째: 테스트 데이터의 길이가 더 길고 테스트 횟수가 더 적다.
실제 응용분야에서는 테스트 데이터의 길이를 변경하여 여러 차례 테스트를 수행하여 모델이 비평형 데이터에 대응하는 안정성을 판단할 수 있다.
-
NO:04
교차 검사의 기본 원칙: 모든 데이터 대상을 N 부분으로 나누고, 각각의 N-1 부분으로 훈련하고, 나머지 부분으로 검사를 한다.
2000년에서 2003년까지의 연간을 4개 부분으로 나눈다. 그 크로스 검사의 작동 과정은 다음과 같다. 1, 훈련 데이터: 2001-2003, 테스트 데이터: 2000; 2, 훈련 데이터: 2000-2002, 테스트 데이터: 2003 3, 훈련 데이터: 2000, 2001, 2003, 테스트 데이터: 2002; 4, 훈련 데이터: 2000, 2002, 2003, 테스트 데이터: 2001;
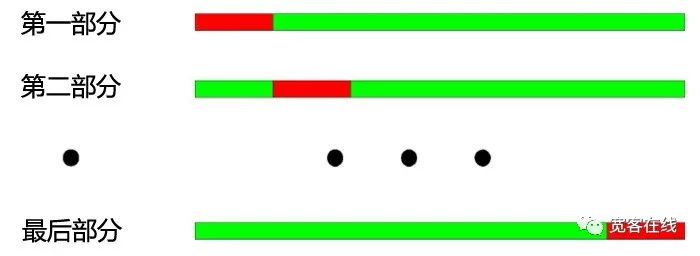
위 그림에서 보듯이, 크로스테이크의 가장 큰 장점은 제한된 데이터를 최대한 활용하는 것입니다. 각 훈련 데이터는 테스트 데이터이기도 합니다. 그러나 크로스테이크를 전략 모델에 적용할 때 명백한 단점이 있습니다.
1, 가격 데이터가 불균형할 때 모델 테스트 결과는 종종 신뢰할 수 없습니다. 예를 들어, 2008년 데이터를 사용하여 훈련하고 2005년 데이터를 사용하여 테스트하십시오. 2008년 시장 환경이 2005년보다 크게 변한 가능성이 있으므로 모델 테스트 결과는 신뢰할 수 없습니다.
2, 첫 번째와 마찬가지로, 크로스 검사에서 최신 데이터로 훈련 모델을 사용해서 오래된 데이터로 테스트 모델을 사용하는 것은 그 자체로 논리적으로 맞지 않습니다.
-
NO:05
또한, 양적 전략 모델에 대한 검사를 할 때, 양도검사나 교차검사 모두 데이터 중복 문제가 발생한다.
거래 전략 모델을 개발할 때, 대부분의 기술 지표는 특정 길이의 역사적 데이터에 기초한다. 예를 들어, 트렌딩 지표를 사용하여 지난 50 일 동안의 역사적 데이터를 계산하고, 다음 거래일에 그 지표가 그 거래일 이전 50 일 동안의 데이터를 계산하는 경우, 두 지표의 계산 데이터의 49 일 동안의 데이터가 동일하므로, 두 인접한 날마다 지표의 변화가 거의 눈에 띄지 않게 된다.
데이터 중복은 다음과 같은 영향을 미칩니다.
1, 모델 예측의 결과의 느린 변화는 지주 변동의 느린 변화를 초래합니다. 이것이 우리가 흔히 말하는 지표의 지체입니다.
2, 모델 결과 검사에 사용되지 않는 일부 통계 값은 반복된 데이터로 인한 순서 관련성 때문에 일부 통계 검사 결과가 신뢰할 수 없게 된다.
-
NO:06
좋은 거래 전략은 미래에 수익성이 있어야 한다. 샘플 외부 테스트는 거래 전략을 객관적으로 검출하는 것 외에도 유저의 시간을 효율적으로 절약할 수 있다.
대부분의 경우, 샘플 전체의 최적의 매개 변수를 직접 사용하면 실제 전투에 들어가는 것이 매우 위험합니다.
파라미터 최적화 시점 이전의 모든 역사적 데이터를 구분하여, 샘플 내 데이터와 샘플 외 데이터로 나누면, 먼저 샘플 내 데이터를 사용하여 파라미터 최적화하고, 다시 샘플 외 데이터를 사용하여 샘플 외 테스트를 수행하면, 이러한 오류를 분류할 수 있으며, 동시에 최적화 된 전략이 미래의 시장에 적용될 수 있는지 검증할 수 있다.
-
NO:07
거래와 마찬가지로, 우리는 결코 시간을 통과하지 못하고, 스스로 한 번의 실수 없이 올바른 결정을 내릴 수 없습니다. 만약 신의 손이나 미래에서 돌아오는 능력이 있다면, 테스트를 거치지 않고, 직접 온라인 상에 실시간 거래를 할 수 있습니다. 그리고 필자는 역사 데이터에서 우리의 전략을 검증해야합니다.
그러나, 거대한 데이터의 역사를 가지고 있더라도, 무한하고 예측할 수 없는 미래에 직면했을 때, 역사는 극도로 부족하다. 따라서 역사에 기반한 상위에서 아래로 밀어내는 거래 시스템은 결국 시간이 지남에 따라 가라앉을 것이다. 왜냐하면 역사는 무한한 미래가 없기 때문이다. 따라서 완전한 긍정적인 기대 거래 시스템은 그 내재의 원칙/논리학에 의해 뒷받침되어야 한다.

-
NO:08
우리는 (창조자 양자화 양자화 거래소) 현 수량화 회로를 변화시키고, 더 순수한 수량화 회로를 만들기 위해 현재의 수량화 회로를 변화시키고자 합니다. 이 세상에는 아무도 지식과 이론을 창조하지 않았습니다. 그들은 단지 우리가 발견할 때까지 기다리고 있었습니다.

나눔은 태도이고 지혜입니다.
롯데백화점 저자: 후키보
- API 문서 예시 테스트 실패
- 대량 다운로드 API 문제
- 자이프 거래소에 웹소켓을 지원하기를 바랍니다.
- 쿠코인 거래소를 지원하는 것을 추가합니다
- 재검토 및 실시간 시에는 항상 Invalid order price / amount를 표시합니다.
- 400: {"코드":-1121,"msg":"무효의 기호. "}
- Gate.IO 파이썬 문제 ((1/3): HttpUtil.py 코드를 해독해 주세요
- Gate.io交易所的问题
- 트렌드 트레이더: 실제 전투에서 트렌드 트레이딩을 통해 수익을 창출하거나 새로운 기회를 사냥합니다.
- 만약 for 문장이 행렬을 가로지르면?
- 为何exchang.GetTrades只能返回最后一笔交易?
- 리린은 미술을 배우고 있습니다.
- 절차적 거래에서 전략이 실패하는지 여부를 정확하게 판단하는 규칙
- 회귀 규모에 기반한 역 거래 전략
- 알리 클라우드 CentOS 7.4에서 여러 프로그램을 실행하는 방법
- 섹스 거래소를 늘리길 바랍니다!
- 새로운 사람이 MA 함수를 묻는 질문
- 삼각형 헤지프 수단을 구입했습니다. 안내 부탁드립니다.
- 토큰 PRO 리버드 계정을 독립적으로 추가할 수 있는 거래소
- OKEx의 역사적인 K 라인 데이터를 가진 사람은 누구입니까? 예를 들어 몇 달 전의 데이터, 단지 최근 며칠의 데이터에 대한 것뿐만 아니라,