LSTM 프레임워크를 사용하여 비트코인 가격을 실시간으로 예측합니다
저자:수직 덩어리 구름, 제작: 2020-05-20 15:45:23, 업데이트: 2020-05-20 15:46:37
참고: 이 사례는 연구용으로만 제공되며 투자 추천은 아닙니다.
비트코인의 가격 데이터는 시간 계열에 기반하고 있기 때문에 비트코인의 가격 예측은 대부분 LSTM 모델을 사용하여 이루어집니다.
장기 단기 기억 (LSTM) 은 특히 시간 순서 데이터 (또는 영화, 문장 등과 같은 시간/공간/구조 순서를 갖는 데이터) 에 적합한 심층 학습 모델로 암호화폐의 가격 방향을 예측하는 이상적인 모델이다.
이 문서는 주로 LSTM을 통해 데이터 조화를 통해 비트코인의 미래 가격을 예측하기 위해 작성되었습니다.
가져오기 위한 라이브러리
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
from matplotlib import pyplot as plt
%matplotlib inline
데이터 분석
데이터 로딩
BTC의 일일 거래 데이터를 읽어보세요
data = pd.read_csv(filepath_or_buffer="btc_data_day")
데이터를 볼 수 있는 현재 총 1380개의 데이터가 있으며, 데이터에는 날짜, 오픈, 하이, 로우, 클로즈, 볼륨 (BTC), 볼륨 (Currency), 가중된 가격 등이 있습니다.
data.info()
다음 10줄의 자료를 참조하세요.
data.head(10)
데이터 시각화
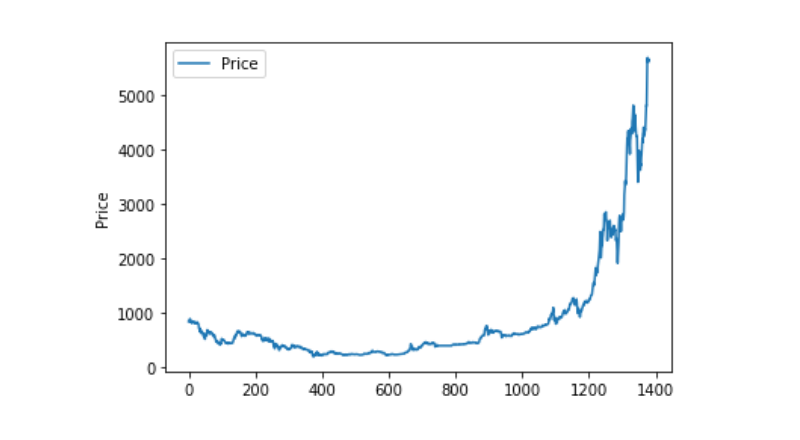
matplotlib를 사용하여 Weighted Price를 그려내서 데이터의 분포와 흐름을 살펴보십시오. 도표에서 우리는 데이터 0의 부분을 발견하고 있으며, 아래 데이터에 이상이 있는지 확인해야 합니다.
plt.plot(data['Weighted Price'], label='Price')
plt.ylabel('Price')
plt.legend()
plt.show()
비정상적인 데이터 처리
먼저 이 데이터에 nan 데이터를 포함하고 있는지 확인해 봅시다.
data.isnull().sum()
Date 0
Open 0
High 0
Low 0
Close 0
Volume (BTC) 0
Volume (Currency) 0
Weighted Price 0
dtype: int64
다시 0의 데이터를 살펴보면, 우리의 데이터에는 0가 포함되어 있고, 우리는 0을 처리해야 합니다.
(data == 0).astype(int).any()
Date False
Open True
High True
Low True
Close True
Volume (BTC) True
Volume (Currency) True
Weighted Price True
dtype: bool
data['Weighted Price'].replace(0, np.nan, inplace=True)
data['Weighted Price'].fillna(method='ffill', inplace=True)
data['Open'].replace(0, np.nan, inplace=True)
data['Open'].fillna(method='ffill', inplace=True)
data['High'].replace(0, np.nan, inplace=True)
data['High'].fillna(method='ffill', inplace=True)
data['Low'].replace(0, np.nan, inplace=True)
data['Low'].fillna(method='ffill', inplace=True)
data['Close'].replace(0, np.nan, inplace=True)
data['Close'].fillna(method='ffill', inplace=True)
data['Volume (BTC)'].replace(0, np.nan, inplace=True)
data['Volume (BTC)'].fillna(method='ffill', inplace=True)
data['Volume (Currency)'].replace(0, np.nan, inplace=True)
data['Volume (Currency)'].fillna(method='ffill', inplace=True)
(data == 0).astype(int).any()
Date False
Open False
High False
Low False
Close False
Volume (BTC) False
Volume (Currency) False
Weighted Price False
dtype: bool
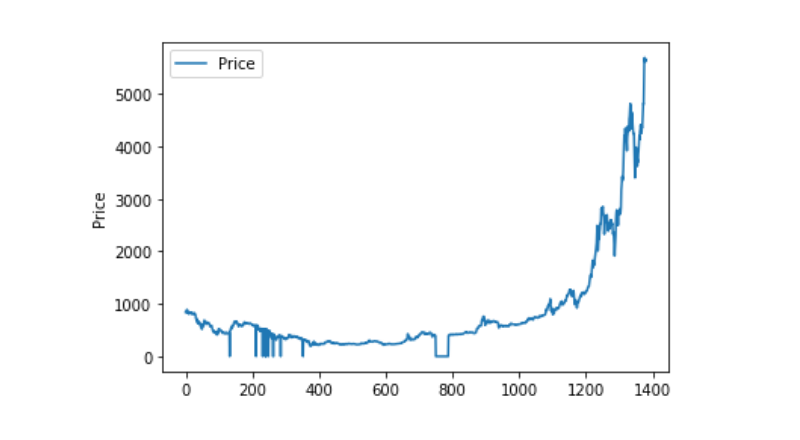
데이터의 분포와 움직임을 살펴보면, 이 곡선은 매우 연속적입니다.
plt.plot(data['Weighted Price'], label='Price')
plt.ylabel('Price')
plt.legend()
plt.show()
훈련 데이터 세트와 테스트 데이터 세트 분할
데이터를 0 - 1으로 통합합니다.
data_set = data.drop('Date', axis=1).values
data_set = data_set.astype('float32')
mms = MinMaxScaler(feature_range=(0, 1))
data_set = mms.fit_transform(data_set)
테스트 데이터 세트와 훈련 데이터 세트를 2:8로 나누십시오.
ratio = 0.8
train_size = int(len(data_set) * ratio)
test_size = len(data_set) - train_size
train, test = data_set[0:train_size,:], data_set[train_size:len(data_set),:]
훈련 데이터베이스와 테스트 데이터베이스를 생성합니다. 우리의 훈련 데이터베이스와 테스트 데이터베이스를 생성하는 창시 기간은 1일입니다.
def create_dataset(data):
window = 1
label_index = 6
x, y = [], []
for i in range(len(data) - window):
x.append(data[i:(i + window), :])
y.append(data[i + window, label_index])
return np.array(x), np.array(y)
train_x, train_y = create_dataset(train)
test_x, test_y = create_dataset(test)
모델 정의와 훈련
이 때 우리는 간단한 모델을 사용했습니다. 이 모델의 구조는 다음과 같습니다. 1. LSTM2. Dense.
여기에 LSTM의 입력 모양에 대한 설명이 필요합니다. Input Shape의 입력 차이는 ((batch_size, time steps, features)) 입니다. 여기서, time steps 값은 데이터를 입력할 때의 시간 창 간격입니다. 여기서 우리는 1일을 시간 창으로 사용하고 있으며, 우리의 데이터는 일 데이터입니다. 따라서 여기 우리의 시간 단계는 1입니다.
긴 단기 기억 (Long short-term memory, LSTM) 은 긴 연속 훈련 과정에서 경사 및 경사 폭발 문제를 해결하기 위해 주로 사용되는 특별한 RNN이다.
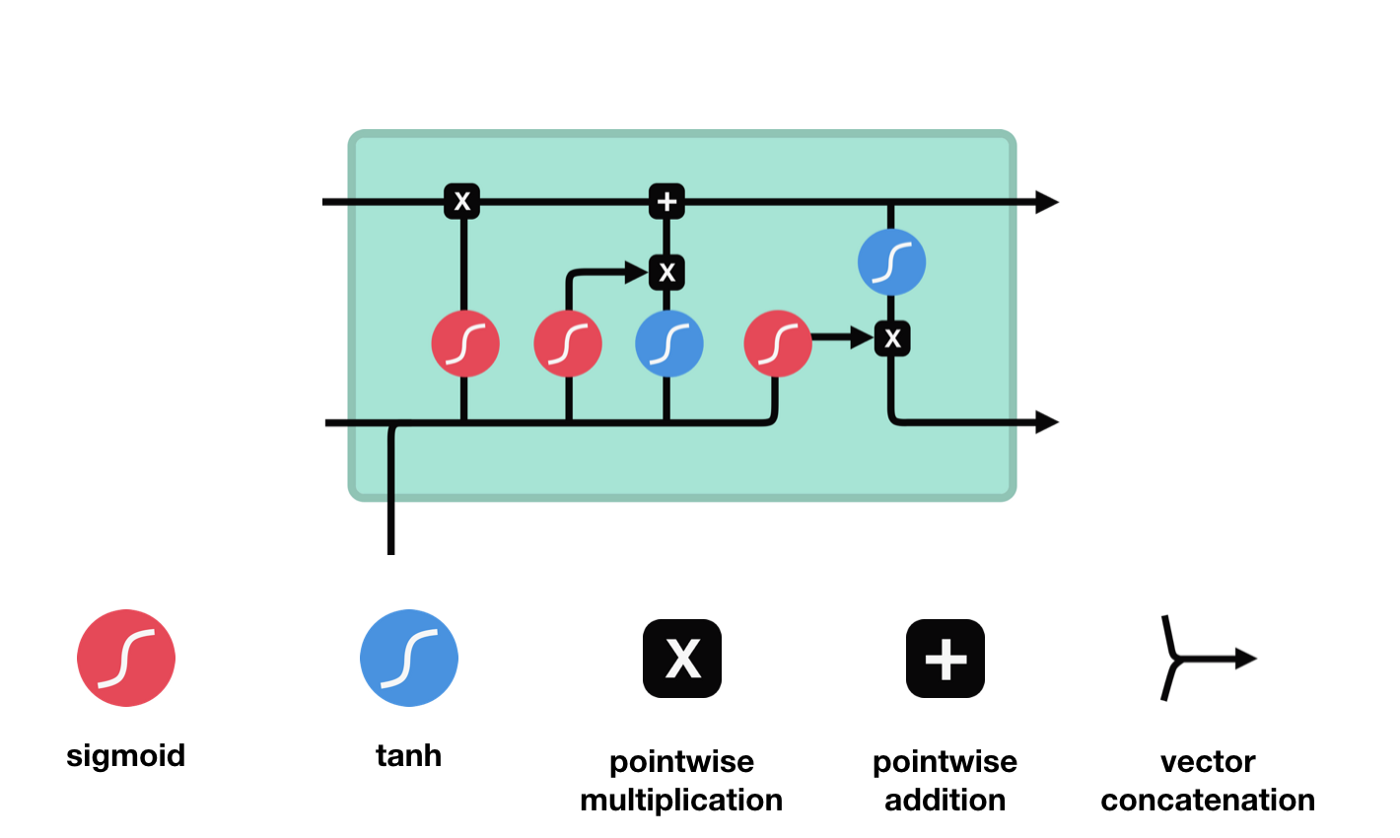
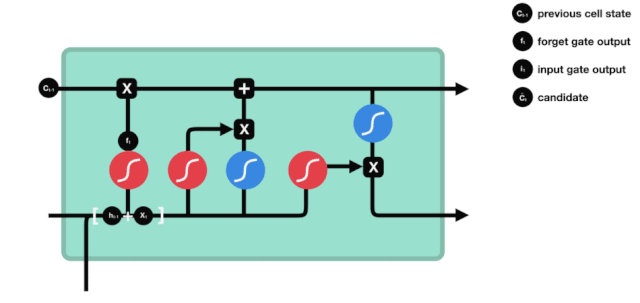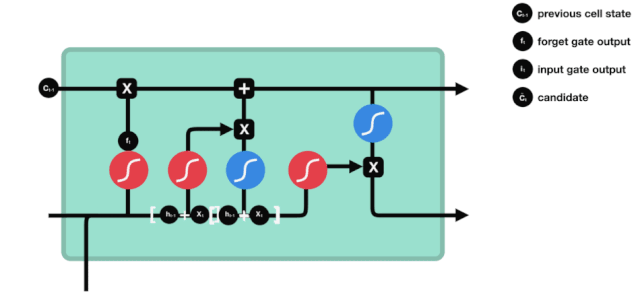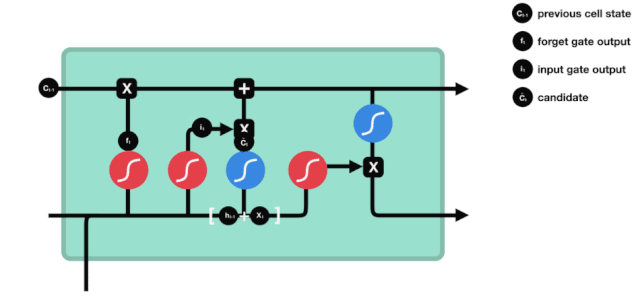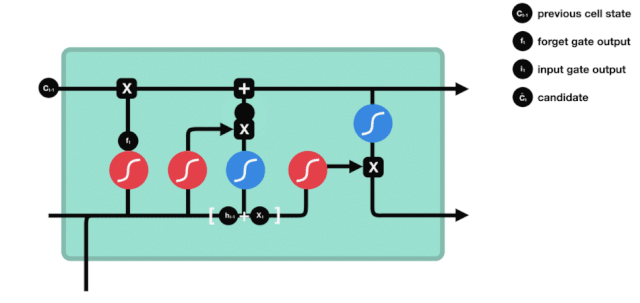
LSTM의 네트워크 구조 도표에서 볼 수 있듯이 LSTM은 실제로 3개의 sigmoid 활성화 함수, 2개의 tanh 활성화 함수, 3개의 곱셈, 1개의 덧셈을 포함하는 작은 모델이다.
세포 상태
세포 상태는 LSTM의 핵심이며, 그는 위의 그림에서 가장 위에 있는 검은 선이고, 이 검은 선 아래에는 우리가 나중에 소개하는 몇 개의 문이 있습니다. 세포 상태는 각 문의 결과에 따라 업데이트됩니다. 아래에서 우리가 소개하는 문들을 통해 세포 상태의 과정을 이해할 수 있습니다.
LSTM 네트워크는 문이라고 불리는 구조를 통해 세포 상태에 대한 정보를 삭제하거나 추가할 수 있다. 문은 어떤 정보가 통과되는지 선택적으로 결정할 수 있다. 문의 구조는 시그모이드 계층과 점 곱하기 동작의 조합이다. 시그모이드 계층의 출력은 0 - 1이고, 0은 통과할 수 없다는 것을 의미하며, 1은 통과할 수 있다는 것을 의미한다.
잊혀진 문
LSTM의 첫 번째 단계는 세포 상태가 어떤 정보를 버려야 하는지 결정하는 것이다. 이 부분의 동작은 잊기 문이라고 불리는 시그모이드 단위로 처리된다.
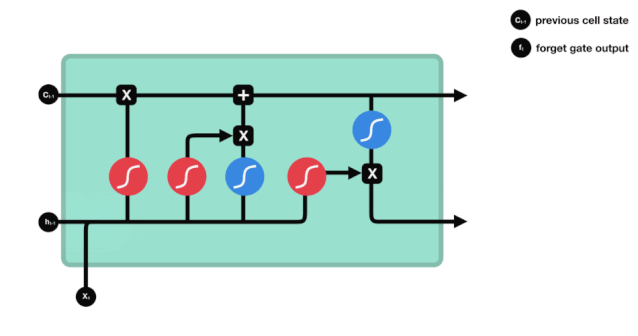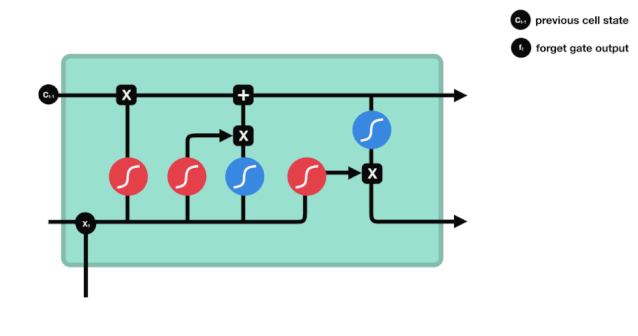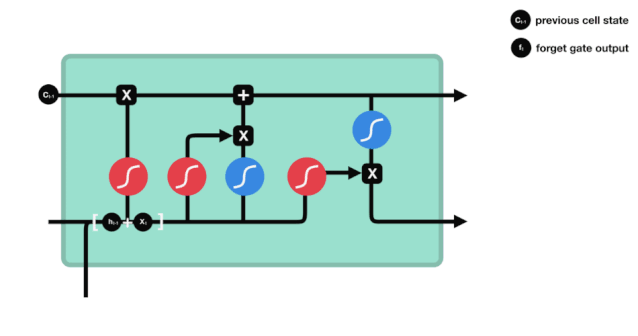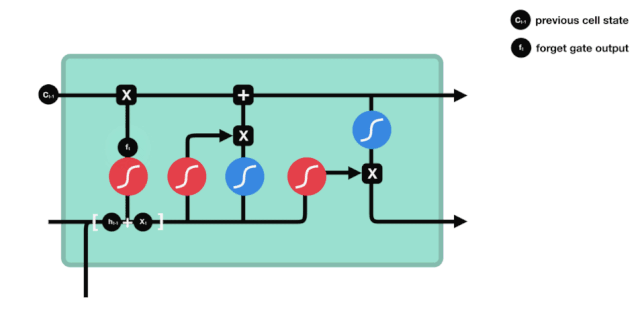
우리가 볼 수 있듯이, 잊기 문은 $h_{l-1}$와 $x_{t}$ 정보를 보고 0 - 1 사이의 벡터를 출력합니다. 이 벡터 안의 0 - 1 값은 세포 상태 $C_{t-1}$에서 어떤 정보가 얼마나 유지되거나 버려지는지 나타냅니다. 0은 유지되지 않음을 나타냅니다. 1은 유지됩니다.
수학 표현식: $f_{t}=\sigma\left ((W_{f} \cdot\left[h_{t-1}, x_{t}\right]+b_{f}\right) $
입구
다음 단계는 세포 상태에 어떤 새로운 정보를 추가할지 결정하는 것입니다. 이 단계는 입력문으로 이루어집니다.
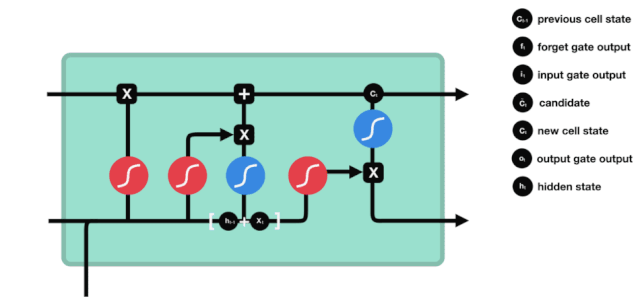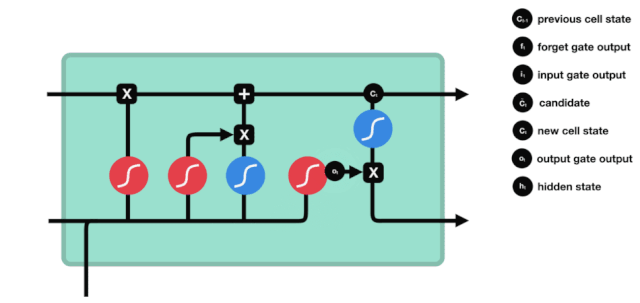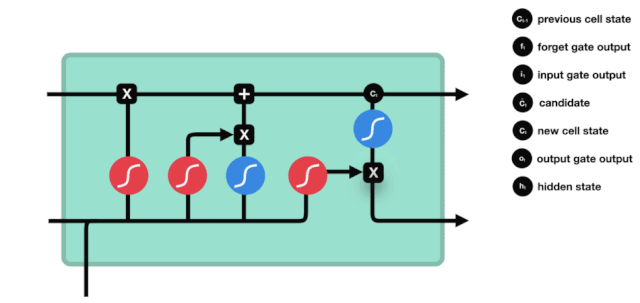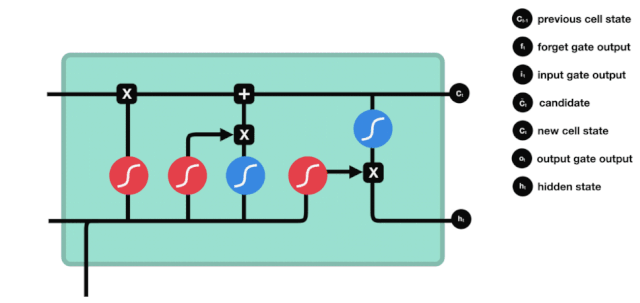
우리는 $h_{l-1}$와 $x_{t}$의 정보가 또 하나의 잊혀진 문 (sigmoid) 과 입력된 문 (tanh) 에 들어간 것을 볼 수 있다. 왜냐하면 잊혀진 문의 출력은 0- 1의 값이기 때문에, 만약 잊혀진 문이 0의 출력이 된다면, 입력된 문의 결과 $C_{i}$는 현재 세포 상태에 추가되지 않을 것이고, 만약 1이라면, 전부 세포 상태에 추가될 것이다. 따라서 여기서 잊혀진 문의 역할은 입력된 문의 결과를 선택적으로 세포 상태에 추가하는 것이다.
수학 공식은 $C_{t}=f_{t} * C_{t-1} + i_{t} * \tilde{C}_{t} $
출구
세포 상태가 업데이트된 후 $h_{l-1}$와 $x_{t}$의 합에 따라 입력된 결과로 출력되는 세포의 어떤 상태 특성을 판단하는 것이 필요합니다. 여기에 입력된 것은 출력 문이라고 불리는 시그모이드 계층을 거쳐 판정을 받는 조건이 필요하고, 세포 상태가 tanh 계층을 거쳐 -1~1 사이의 값을 얻는 벡터를 얻습니다. 이 벡터는 출력 문에서 얻은 판정을 받은 조건과 곱하면 최종 RNA 단위의 출력을 얻습니다.
def create_model():
model = Sequential()
model.add(LSTM(50, input_shape=(train_x.shape[1], train_x.shape[2])))
model.add(Dense(1))
model.compile(loss='mae', optimizer='adam')
model.summary()
return model
model = create_model()

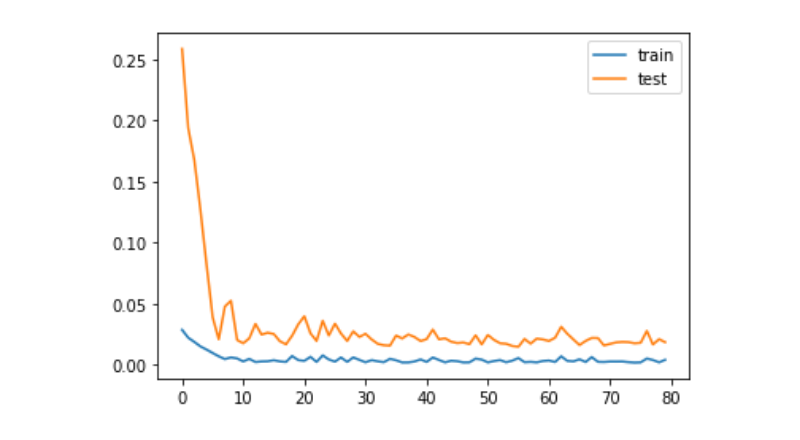
history = model.fit(train_x, train_y, epochs=80, batch_size=64, validation_data=(test_x, test_y), verbose=1, shuffle=False)
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()
train_x, train_y = create_dataset(train)
test_x, test_y = create_dataset(test)
예측
predict = model.predict(test_x)
plt.plot(predict, label='predict')
plt.plot(test_y, label='ground true')
plt.legend()
plt.show()
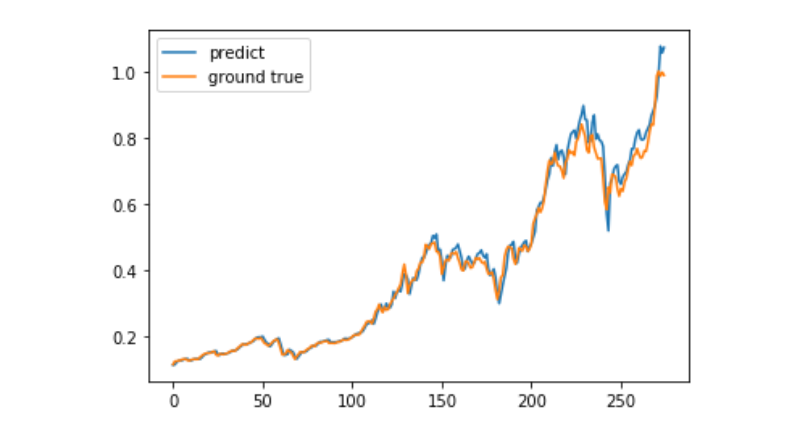
현재 머신러닝을 사용하여 비트코인의 장기 가격 움직임을 예측하는 것은 매우 어렵고, 이 문서는 학습 사례로만 사용될 수 있다. 이 사례는 마트리 퓨즈 클라우드의 데모 이미지와 함께 온라인에 출시될 예정이며, 관심 있는 사용자가 직접 체험할 수 있다.
- My 언어에 대한 도움말
- 자동으로 주문을 올리고 취소할 수 있는 정책을 찾는 것은 간단합니다.
- my 언어는 얼마나 많은 거래가 있는지 판단합니다.
티커의 라스트와 GetRecords의 클로즈 토큰의 계약이 실시간 거래에 일치하는지? - 왜 레코드 길이가 잘못되었을까요?
- err_msg:결정 또는 배달 중입니다. 위치를 얻을 수 없습니다
- 최근에는 왜
老가 다시 문을 열었는지 모르겠어요? - 이 테스트는 더 많이 했거나 아무것도하지 않은 확률이 있습니까?
- BARSBK
- 자바스크립트 버전의 HTTPQuery가 HTTP/2를 지원하지 않는가요? 제3자 js를 직접 도입할 수 있나요?
- 어떻게 점화와 그림으로 거래를 할 수 있을까요?
- 시각화 정책은 여러 거래소를 추가할 수 있습니까? (예정상 3개)
- 코인터넷 상속 계약은 거래 가능한가요?
- 재검토시 데이터 이상
- 어떻게 하면 이윤표가 실제 디스크에 적용될 수 있을까요?
- 이 두 개의 평면선은 서로 겹쳐집니다.
- 왜 리얼 디스크 검색에서 두 바만 반환합니까?
- ZBG 플랫폼 오류 보고
- 독립적인 양적 거래 백그라운드를 만들 때 시작 오류가 발생했습니다
- TA 지표의 숫자는 실제 디스크와 일치하지 않습니다