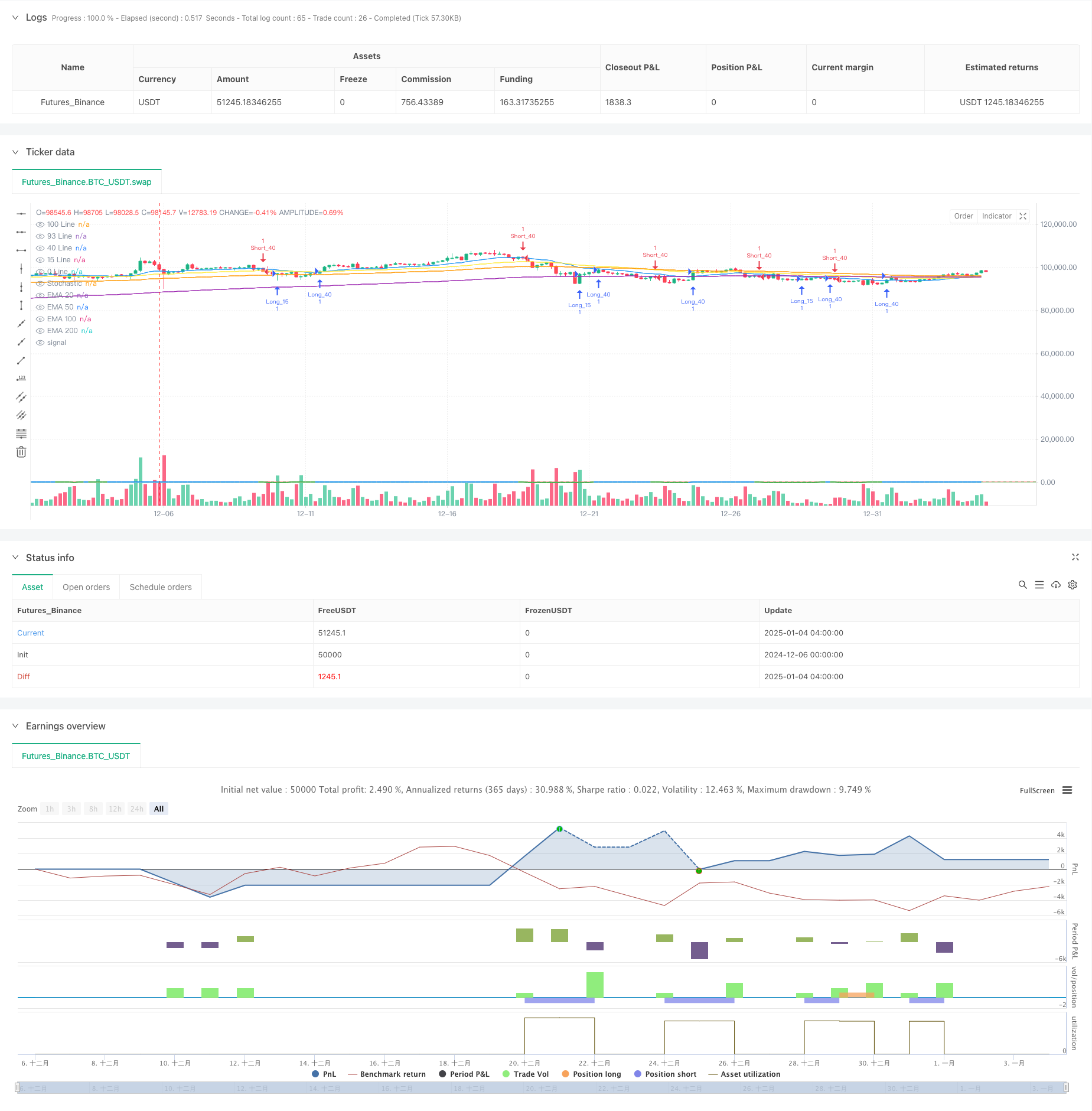
개요
이 전략은 확률적 오실레이터를 기반으로 한 지능형 거래 시스템입니다. 이 솔루션은 역동적인 추세 인식, 다중 신호 확인, 지능적인 위험 관리 기능을 결합하여 매수 과다 및 매도 과다 시장 상황을 자동으로 식별하고 거래를 실행할 수 있습니다. 이 전략은 색상 구분 시스템을 통해 시장 현황을 시각적으로 표시하고, 추세 확인을 위해 다기간 이동 평균선(EMA)을 통합하며, 유연한 손절매 및 이익실현 설정을 제공합니다.
전략 원칙
전략의 핵심은 확률적 오실레이터와 다중 이동 평균 시스템의 조정에 기초합니다. K 값이 사전 설정된 매수 과다 또는 매도 과다 수준(93⁄15)이나 중간 수준(40)을 돌파할 때 거래 신호가 생성됩니다. 이 시스템은 색상 변화를 통해 시장 상황을 시각적으로 표시합니다(빨간색은 하락 가능성, 녹색은 상승 가능성, 파란색은 중립을 나타냄). 또한 추세 확인을 위해 20, 50, 100 및 200기간 지수 이동 평균(EMA)이 통합되어 있습니다. 이 전략에는 1:1, 1:4, 1:8과 같은 다양한 위험-수익 비율 설정을 지원하는 지능형 위험 관리 시스템도 포함되어 있습니다.
전략적 이점
- 신호 시스템은 명확하고 직관적이며 색상 코딩을 통해 시장 상태를 빠르게 식별할 수 있습니다.
- 거짓 신호 위험을 줄이기 위한 다중 신호 확인 메커니즘
- 유연한 위험 관리 시스템, 맞춤형 위험-수익률 지원
- 다중 기간 이동 평균과 결합하여 추세 확인 제공
- 수동 작업의 위험을 줄이기 위한 자동 손절매 및 이익 실현 설정
- 코드 구조가 명확하고 유지 관리 및 최적화가 쉽습니다.
전략적 위험
- 변동성이 큰 시장에서는 빈번한 거래 신호가 생성될 수 있습니다.
- 고정 매수 과다 및 매도 과다 임계값은 모든 시장 환경에 적합하지 않을 수 있습니다.
- 변동성이 큰 시장에서는 이동평균 시스템이 뒤처질 수 있습니다.
- 위험을 통제하기 위해서는 합리적인 손절매 수준을 설정하는 것이 필요합니다. 해결책에는 신호 필터링 메커니즘 추가, 임계값의 동적 조정, 이동 평균 매개변수 최적화, 손절매 전략의 엄격한 구현이 포함됩니다.
전략 최적화 방향
- 시장 변동에 따라 매수 과다 및 매도 과다 수준을 동적으로 조정하기 위한 적응형 임계값 시스템 도입
- 신호 확인을 위해 볼륨 표시기를 추가합니다.
- 거짓 신호를 줄이기 위한 지능형 신호 필터링 메커니즘 개발
- 추세 판단의 정확도를 높이기 위해 이동 평균 매개변수를 최적화합니다.
- 매개변수 선택을 최적화하기 위한 머신 러닝 알고리즘 소개
- 추가된 추적 제어 메커니즘
요약하다
이 전략은 확률적 오실레이터, 이동 평균 시스템, 지능적 위험 관리를 결합하여 포괄적인 거래 시스템을 구축합니다. 전략 설계는 실용성과 실행 가능성에 초점을 맞추고 있으며, 다양한 위험 선호도를 지닌 거래자에게 적합합니다. 지속적인 최적화와 개선을 통해 이 전략은 다양한 시장 환경에서도 안정적인 성과를 유지할 것으로 기대됩니다.
전략 소스 코드
/*backtest
start: 2024-12-06 00:00:00
end: 2025-01-04 08:00:00
period: 4h
basePeriod: 4h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT"}]
*/
// This Pine Script™ code is subject to the terms of the Mozilla Public License 2.0 at https://mozilla.org/MPL/2.0/
// © petrusvorenusperegrinus
//██████╗ ███████╗████████╗██████╗ ██╗ ██╗███████╗
//██╔══██╗██╔════╝╚══██╔══╝██╔══██╗██║ ██║██╔════╝
//██████╔╝█████╗ ██║ ██████╔╝██║ ██║███████╗
//██╔═══╝ ██╔══╝ ██║ ██╔══██╗██║ ██║╚════██║
//██║ ███████╗ ██║ ██║ ██║╚██████╔╝███████║
//╚═╝ ╚══════╝ ╚═╝ ╚═╝ ╚═╝ ╚═════╝ ╚══════╝
//██╗ ██╗ ██████╗ ██████╗ ███████╗███╗ ██╗██╗ ██╗███████╗
//██║ ██║██╔═══██╗██╔══██╗██╔════╝████╗ ██║██║ ██║██╔════╝
//██║ ██║██║ ██║██████╔╝█████╗ ██╔██╗ ██║██║ ██║███████╗
//╚██╗ ██╔╝██║ ██║██╔══██╗██╔══╝ ██║╚██╗██║██║ ██║╚════██║
// ╚████╔╝ ╚██████╔╝██║ ██║███████╗██║ ╚████║╚██████╔╝███████║
// ╚═══╝ ╚═════╝ ╚═╝ ╚═╝╚══════╝╚═╝ ╚═══╝ ╚═════╝ ╚══════╝
//██████╗ ███████╗██████╗ ███████╗ ██████╗ ██████╗ ██╗███╗ ██╗██╗ ██╗███████╗
//██╔══██╗██╔════╝██╔══██╗██╔════╝██╔════╝ ██╔══██╗██║████╗ ██║██║ ██║██╔════╝
//██████╔╝█████╗ ██████╔╝█████╗ ██║ ███╗██████╔╝██║██╔██╗ ██║██║ ██║███████╗
//██╔═══╝ ██╔══╝ ██╔══██╗██╔══╝ ██║ ██║██╔══██╗██║██║╚██╗██║██║ ██║╚════██║
//██║ ███████╗██║ ██║███████╗╚██████╔╝██║ ██║██║██║ ╚████║╚██████╔╝███████║
//╚═╝ ╚══════╝╚═╝ ╚═╝╚══════╝ ╚═════╝ ╚═╝ ╚═╝╚═╝╚═╝ ╚═══╝ ╚═════╝ ╚══════╝
//@version=6
strategy("CM Stochastic POP Method 3", shorttitle="CM_Stochastic POP_M3", overlay=true)
// Stochastic Settings
length = input.int(14, "Stochastic Length", minval=1)
smoothK = input.int(5, "Smooth K", minval=1)
// Risk:Reward Settings
use_rr = input.bool(true, "Use Risk:Reward Ratio")
use_sl = input.bool(true, "Use Stop Loss") // New input for Stop Loss toggle
rr_options = input.string("1:1", "Risk:Reward Ratio", options=["1:1", "1:4", "1:8"])
stop_percent = input.float(1.0, "Stop Loss (%)", minval=0.1, step=0.1)
// Convert selected R:R ratio to number
get_rr_multiplier(rr) =>
switch rr
"1:1" => 1.0
"1:4" => 4.0
"1:8" => 8.0
=> 1.0 // default case
rr_ratio = get_rr_multiplier(rr_options)
// Fixed Level Settings
upperLine = 93.0 // Fixed sell level
midLine = 40.0 // Buy/Sell level
lowerLine = 15.0 // Fixed buy level
// EMA Settings
ema20 = ta.ema(close, 20)
ema50 = ta.ema(close, 50)
ema100 = ta.ema(close, 100)
ema200 = ta.ema(close, 200)
// Calculate Stochastic with smoothing
k = ta.sma(ta.stoch(close, high, low, length), smoothK)
// Dynamic color based on K value
kColor = k >= upperLine ? color.red : // Above 93 -> Red
k <= lowerLine ? color.green : // Below 15 -> Green
k <= midLine ? color.green : // Below 40 -> Green
color.blue // Between 40-93 -> Blue
// Buy Signals:
longCondition1 = ta.crossover(k, lowerLine) // Cross above 15
longCondition2 = ta.crossover(k, midLine) // Cross above 40
// Sell Signals:
shortCondition1 = ta.crossunder(k, upperLine) // Cross below 93
shortCondition2 = ta.crossunder(k, midLine) // Cross below 40
calc_tp_sl(entry_price, is_long) =>
sl_distance = entry_price * (stop_percent / 100)
sl = is_long ? entry_price - sl_distance : entry_price + sl_distance
tp_distance = sl_distance * rr_ratio
tp = is_long ? entry_price + tp_distance : entry_price - tp_distance
[sl, tp]
// Long entries
if (longCondition1)
if (use_rr)
[sl, tp] = calc_tp_sl(close, true)
strategy.entry("Long_15", strategy.long)
if (use_sl)
strategy.exit("Exit_15", "Long_15", stop=sl, limit=tp)
else
strategy.exit("Exit_15", "Long_15", limit=tp)
else
strategy.entry("Long_15", strategy.long)
if (longCondition2)
if (use_rr)
[sl, tp] = calc_tp_sl(close, true)
strategy.entry("Long_40", strategy.long)
if (use_sl)
strategy.exit("Exit_40", "Long_40", stop=sl, limit=tp)
else
strategy.exit("Exit_40", "Long_40", limit=tp)
else
strategy.entry("Long_40", strategy.long)
// Short entries
if (shortCondition1)
if (use_rr)
[sl, tp] = calc_tp_sl(close, false)
strategy.entry("Short_93", strategy.short)
if (use_sl)
strategy.exit("Exit_93", "Short_93", stop=sl, limit=tp)
else
strategy.exit("Exit_93", "Short_93", limit=tp)
else
strategy.entry("Short_93", strategy.short)
if (shortCondition2)
if (use_rr)
[sl, tp] = calc_tp_sl(close, false)
strategy.entry("Short_40", strategy.short)
if (use_sl)
strategy.exit("Exit_40", "Short_40", stop=sl, limit=tp)
else
strategy.exit("Exit_40", "Short_40", limit=tp)
else
strategy.entry("Short_40", strategy.short)
// Plot EMAs
plot(ema20, title="EMA 20", color=color.blue, linewidth=1, force_overlay = true)
plot(ema50, title="EMA 50", color=color.yellow, linewidth=1, force_overlay = true)
plot(ema100, title="EMA 100", color=color.orange, linewidth=1, force_overlay = true)
plot(ema200, title="EMA 200", color=color.purple, linewidth=1, force_overlay = true)
// Plot Stochastic line
plot(k, title="Stochastic", color=kColor, linewidth=2)
// Plot reference lines
hline(100, title="100 Line", color=color.white, linestyle=hline.style_solid)
hline(upperLine, title="93 Line", color=color.red, linestyle=hline.style_solid)
hline(midLine, title="40 Line", color=color.green, linestyle=hline.style_dashed)
hline(lowerLine, title="15 Line", color=color.green, linestyle=hline.style_solid)
hline(0, title="0 Line", color=color.white, linestyle=hline.style_solid)