Perdagangan berpasangan berasaskan teknologi data
Penulis:FMZ~Lydia, Dicipta: 2023-01-05 09:10:25, Dikemas kini: 2024-12-19 00:27:10
Perdagangan berpasangan berasaskan teknologi data
Perdagangan pasangan adalah contoh yang baik untuk merumuskan strategi perdagangan berdasarkan analisis matematik.
Prinsip asas
Misalkan anda mempunyai sepasang sasaran pelaburan X dan Y yang mempunyai beberapa hubungan berpotensi. Sebagai contoh, dua syarikat menghasilkan produk yang sama, seperti Pepsi Cola dan Coca Cola. Anda ingin nisbah harga atau penyebaran asas (juga dikenali sebagai perbezaan harga) kedua-duanya tetap tidak berubah dari masa ke masa. Walau bagaimanapun, kerana perubahan sementara dalam bekalan dan permintaan, seperti pesanan beli / jual besar sasaran pelaburan, dan tindak balas terhadap berita penting dari salah satu syarikat, perbezaan harga antara kedua-dua pasangan mungkin berbeza dari masa ke masa. Dalam kes ini, satu objek pelaburan bergerak ke atas sementara yang lain bergerak ke bawah berbanding satu sama lain. Jika anda ingin perselisihan ini kembali normal dari masa ke masa, anda boleh mencari peluang perdagangan (atau peluang arbitrase). Peluang arbitrase seperti itu boleh didapati di mana-mana di pasaran mata wang digital atau pasaran komoditi niaga hadapan domestik, seperti hubungan antara BTC dan mata wang asing; antara hidangan soya aman; jenis aset niaga hadapan soya dan minyak soya di mana-mana.
Apabila terdapat perbezaan harga sementara, anda akan menjual objek pelaburan dengan prestasi yang sangat baik (objek pelaburan yang meningkat) dan membeli objek pelaburan dengan prestasi yang kurang baik (objek pelaburan yang jatuh). Anda yakin bahawa margin faedah antara kedua-dua objek pelaburan akhirnya akan jatuh melalui kejatuhan objek pelaburan dengan prestasi yang sangat baik atau kenaikan objek pelaburan dengan prestasi yang buruk, atau keduanya. Transaksi anda akan menghasilkan wang dalam semua situasi yang sama ini. Jika objek pelaburan bergerak naik atau turun bersama-sama tanpa mengubah perbezaan harga di antara mereka, anda tidak akan membuat atau kehilangan wang.
Oleh itu, perdagangan pasangan adalah strategi perdagangan neutral pasaran, yang membolehkan peniaga mendapat keuntungan daripada hampir semua keadaan pasaran: trend menaik, trend menurun atau penyatuan mendatar.
Terangkan konsep: dua sasaran pelaburan hipotetik
- Membina persekitaran penyelidikan kami di atas platform FMZ Quant
Pertama sekali, untuk bekerja dengan lancar, kita perlu membina persekitaran penyelidikan kita. Dalam artikel ini, kita menggunakan platform FMZ Quant (FMZ.COM) untuk membina persekitaran penyelidikan kita, terutamanya untuk menggunakan antara muka API yang mudah dan pantas dan sistem Docker yang dikemas dengan baik platform ini kemudian.
Dalam nama rasmi platform FMZ Quant, sistem Docker ini dipanggil sistem Docker.
Sila rujuk artikel saya sebelum ini mengenai cara menggunakan docker dan robot:https://www.fmz.com/bbs-topic/9864.
Pembaca yang ingin membeli pelayan pengkomputeran awan mereka sendiri untuk menggunakan pelabuhan boleh merujuk artikel ini:https://www.fmz.com/digest-topic/5711.
Selepas menyebarkan pelayan pengkomputeran awan dan sistem docker dengan berjaya, seterusnya kita akan memasang artifak terbesar sekarang Python: Anaconda
Untuk merealisasikan semua persekitaran program yang relevan (bibliotek ketergantungan, pengurusan versi, dan lain-lain) yang diperlukan dalam artikel ini, cara yang paling mudah adalah menggunakan Anaconda.
Untuk kaedah pemasangan Anaconda, sila rujuk panduan rasmi Anaconda:https://www.anaconda.com/distribution/.
Artikel ini juga akan menggunakan numpy dan panda, dua perpustakaan popular dan penting dalam pengkomputeran saintifik Python.
Kerja asas di atas juga boleh merujuk kepada artikel saya sebelumnya, yang memperkenalkan cara menyediakan persekitaran Anaconda dan perpustakaan numpy dan panda.https://www.fmz.com/bbs-topic/9863.
Seterusnya, mari kita gunakan kod untuk melaksanakan
import numpy as np
import pandas as pd
import statsmodels
from statsmodels.tsa.stattools import coint
# just set the seed for the random number generator
np.random.seed(107)
import matplotlib.pyplot as plt
Ya, kita juga akan menggunakan matplotlib, perpustakaan carta yang sangat terkenal dalam Python.
Mari kita menghasilkan sasaran pelaburan hipotetik X, dan mensimulasikan dan merangka pulangan harian melalui pengedaran normal.
# Generate daily returns
Xreturns = np.random.normal(0, 1, 100)
# sum them and shift all the prices up
X = pd.Series(np.cumsum(
Xreturns), name='X')
+ 50
X.plot(figsize=(15,7))
plt.show()
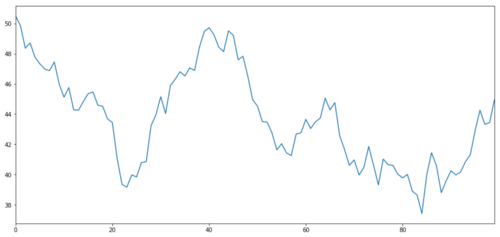
X objek pelaburan disimulasikan untuk merangka pulangan harian melalui pengedaran normal
Sekarang kita menjana Y, yang sangat bersepadu dengan X, jadi harga Y harus sangat serupa dengan perubahan X. Kita model ini dengan mengambil X, memindahkannya ke atas dan menambah beberapa bunyi rawak yang diekstrak dari pengedaran normal.
noise = np.random.normal(0, 1, 100)
Y = X + 5 + noise
Y.name = 'Y'
pd.concat([X, Y], axis=1).plot(figsize=(15,7))
plt.show()
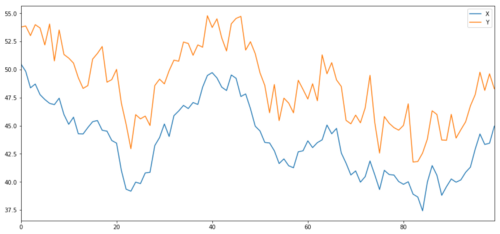
X dan Y objek pelaburan kointegrasi
Penggabungan
Kointegrasi sangat serupa dengan korelasi, yang bermaksud bahawa nisbah antara dua siri data akan berubah berhampiran nilai purata.
Y = X + e
Di mana
Untuk pasangan yang berdagang antara dua siri masa, nilai yang dijangkakan nisbah dari masa ke masa mesti konvergen ke nilai purata, iaitu, mereka harus disatukan. siri masa yang kita bina di atas disatukan. kita akan merangka nisbah antara mereka sekarang supaya kita dapat melihat seperti apa.
(Y/X).plot(figsize=(15,7))
plt.axhline((Y/X).mean(), color='red', linestyle='--')
plt.xlabel('Time')
plt.legend(['Price Ratio', 'Mean'])
plt.show()
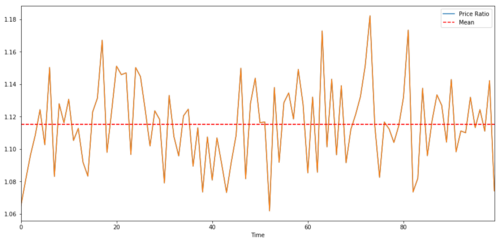
Nisbah dan nilai purata antara dua harga sasaran pelaburan bersepadu
Ujian kointegrasi
Satu kaedah ujian yang mudah adalah menggunakan statsmodels.tsa.stattools. Kita akan melihat nilai p yang sangat rendah, kerana kita mencipta dua siri data secara buatan yang disatukan sebanyak mungkin.
# compute the p-value of the cointegration test
# will inform us as to whether the ratio between the 2 timeseries is stationary
# around its mean
score, pvalue, _ = coint(X,Y)
print pvalue
Hasilnya ialah: 1.81864477307e-17
Nota: korelasi dan kointegrasi
Korrelasi dan kointegrasi, walaupun sama dalam teori, tidak sama. mari kita lihat contoh-contoh siri data yang relevan tetapi tidak kointegrasi dan sebaliknya. mula-mula, mari kita periksa korelasi siri yang baru kita hasilkan.
X.corr(Y)
Hasilnya ialah: 0.951
Seperti yang kita jangkakan, ini sangat tinggi. tetapi bagaimana dengan dua siri yang berkaitan tetapi tidak bersama-integrasi? contoh mudah adalah satu siri dua data menyimpang.
ret1 = np.random.normal(1, 1, 100)
ret2 = np.random.normal(2, 1, 100)
s1 = pd.Series( np.cumsum(ret1), name='X')
s2 = pd.Series( np.cumsum(ret2), name='Y')
pd.concat([s1, s2], axis=1 ).plot(figsize=(15,7))
plt.show()
print 'Correlation: ' + str(X_diverging.corr(Y_diverging))
score, pvalue, _ = coint(X_diverging,Y_diverging)
print 'Cointegration test p-value: ' + str(pvalue)
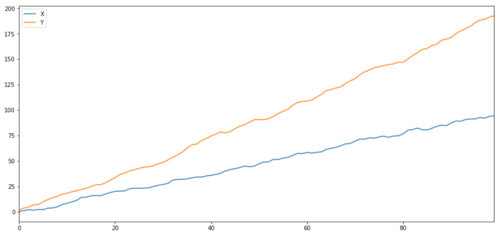
Dua siri yang berkaitan (tidak bersepadu)
Pekali korelasi: 0.998 Nilai P ujian kointegrasi: 0.258
Contoh mudah kointegrasi tanpa korelasi adalah urutan pengedaran normal dan gelombang persegi.
Y2 = pd.Series(np.random.normal(0, 1, 800), name='Y2') + 20
Y3 = Y2.copy()
Y3[0:100] = 30
Y3[100:200] = 10
Y3[200:300] = 30
Y3[300:400] = 10
Y3[400:500] = 30
Y3[500:600] = 10
Y3[600:700] = 30
Y3[700:800] = 10
Y2.plot(figsize=(15,7))
Y3.plot()
plt.ylim([0, 40])
plt.show()
# correlation is nearly zero
print 'Correlation: ' + str(Y2.corr(Y3))
score, pvalue, _ = coint(Y2,Y3)
print 'Cointegration test p-value: ' + str(pvalue)
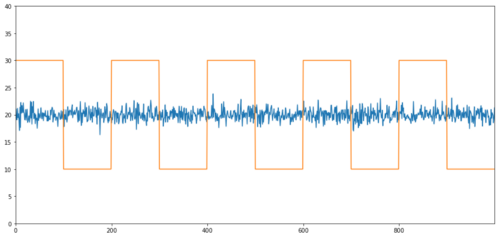
Korrelasi: 0.007546 Nilai P ujian kointegrasi: 0.0
Hubungan adalah sangat rendah, tetapi nilai p menunjukkan integrasi sempurna!
Bagaimana untuk menjalankan perdagangan pasangan?
Oleh kerana dua siri masa yang terintegrasi bersama (seperti X dan Y di atas) saling berhadapan dan menyimpang satu sama lain, kadang-kadang spread asas tinggi atau rendah.
Kembali ke atas, X dan Y dalam Y =
Perbandingan panjang: Ini adalah apabila nisbah
sangat kecil dan kita menjangkakan ia meningkat. Perbandingan pergi pendek: Ini adalah apabila nisbah
sangat besar dan kita mengharapkannya berkurangan.
Sila ambil perhatian bahawa kita sentiasa mempunyai
Jika X dan Y objek dagangan bergerak relatif antara satu sama lain, kita akan membuat wang atau kehilangan wang.
Gunakan data untuk mencari objek perdagangan dengan tingkah laku yang sama
Cara terbaik untuk melakukan ini adalah dengan bermula dari subjek dagangan yang anda mengesyaki mungkin kointegrasi dan melakukan ujian statistik.bias perbandingan berganda.
Bias perbandingan bergandamerujuk kepada peningkatan peluang penjanaan nilai p penting yang salah semasa menjalankan banyak ujian, kerana kita perlu menjalankan sebilangan besar ujian. Jika kita menjalankan 100 ujian pada data rawak, kita harus melihat nilai p 5 di bawah 0.05. Jika anda ingin membandingkan n sasaran perdagangan untuk kointegrasi, anda akan melakukan n (n-1) / 2 perbandingan, dan anda akan melihat banyak nilai p yang salah, yang akan meningkat dengan peningkatan sampel ujian anda. Untuk mengelakkan situasi ini, pilih beberapa pasangan perdagangan dan anda mempunyai alasan untuk menentukan bahawa mereka mungkin kointegrasi, dan kemudian uji mereka secara berasingan. Ini akan mengurangkan banyakbias perbandingan berganda.
Oleh itu, mari kita cuba mencari beberapa sasaran dagangan yang menunjukkan kointegrasi. Mari kita ambil bakul saham teknologi AS yang besar dalam Indeks S&P 500 sebagai contoh. Sasaran dagangan ini beroperasi di segmen pasaran yang serupa dan mempunyai harga kointegrasi. Kami mengimbas senarai objek dagangan dan menguji kointegrasi antara semua pasangan.
Matriks skor ujian kointegrasi yang dikembalikan, matriks nilai p dan semua pasangan dengan nilai p kurang daripada 0,05.Kaedah ini terdedah kepada bias perbandingan berganda, jadi sebenarnya, mereka perlu menjalankan pengesahan kedua.Dalam artikel ini, untuk kemudahan penjelasan kami, kami memilih untuk mengabaikan titik ini dalam contoh.
def find_cointegrated_pairs(data):
n = data.shape[1]
score_matrix = np.zeros((n, n))
pvalue_matrix = np.ones((n, n))
keys = data.keys()
pairs = []
for i in range(n):
for j in range(i+1, n):
S1 = data[keys[i]]
S2 = data[keys[j]]
result = coint(S1, S2)
score = result[0]
pvalue = result[1]
score_matrix[i, j] = score
pvalue_matrix[i, j] = pvalue
if pvalue < 0.02:
pairs.append((keys[i], keys[j]))
return score_matrix, pvalue_matrix, pairs
Nota: Kami telah memasukkan penanda aras pasaran (SPX) dalam data - pasaran telah memacu aliran banyak objek perdagangan. Biasanya anda mungkin menemui dua objek perdagangan yang nampaknya disatukan; Tetapi sebenarnya, mereka tidak disatukan antara satu sama lain, tetapi dengan pasaran. Ini dipanggil pembolehubah mengelirukan. Adalah penting untuk memeriksa penyertaan pasaran dalam sebarang hubungan yang anda dapati.
from backtester.dataSource.yahoo_data_source import YahooStockDataSource
from datetime import datetime
startDateStr = '2007/12/01'
endDateStr = '2017/12/01'
cachedFolderName = 'yahooData/'
dataSetId = 'testPairsTrading'
instrumentIds = ['SPY','AAPL','ADBE','SYMC','EBAY','MSFT','QCOM',
'HPQ','JNPR','AMD','IBM']
ds = YahooStockDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds,
startDateStr=startDateStr,
endDateStr=endDateStr,
event='history')
data = ds.getBookDataByFeature()['Adj Close']
data.head(3)

Sekarang mari kita cuba menggunakan kaedah kita untuk mencari pasangan perdagangan yang terintegrasi.
# Heatmap to show the p-values of the cointegration test
# between each pair of stocks
scores, pvalues, pairs = find_cointegrated_pairs(data)
import seaborn
m = [0,0.2,0.4,0.6,0.8,1]
seaborn.heatmap(pvalues, xticklabels=instrumentIds,
yticklabels=instrumentIds, cmap=’RdYlGn_r’,
mask = (pvalues >= 0.98))
plt.show()
print pairs
[('ADBE', 'MSFT')]
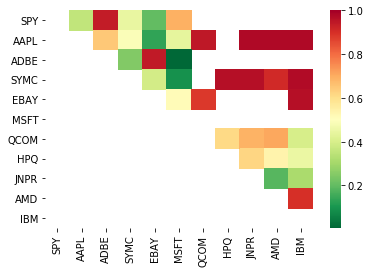
Ia kelihatan seperti
S1 = data['ADBE']
S2 = data['MSFT']
score, pvalue, _ = coint(S1, S2)
print(pvalue)
ratios = S1 / S2
ratios.plot()
plt.axhline(ratios.mean())
plt.legend([' Ratio'])
plt.show()
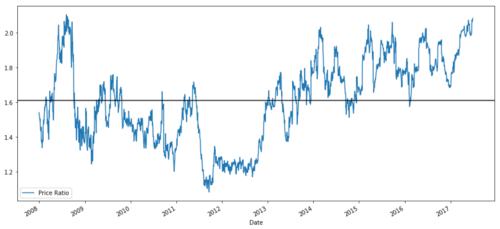
Grafik nisbah harga antara MSFT dan ADBE dari 2008 hingga 2017
Rasio ini kelihatan seperti purata yang stabil. nisbah mutlak tidak berguna secara statistik. Ia lebih membantu untuk standardkan isyarat kita dengan merawatnya sebagai Z Score. Z Score ditakrifkan sebagai:
Z Score (Value) = (Value
Amaran
Sebenarnya, kita biasanya cuba untuk mengembangkan data dengan premis bahawa data itu diedarkan secara normal. Walau bagaimanapun, banyak data kewangan tidak didistribusikan secara normal, jadi kita mesti sangat berhati-hati untuk tidak hanya mengandaikan normaliti atau sebarang pengedaran tertentu ketika menghasilkan statistik. Pengedaran benar nisbah mungkin mempunyai kesan ekor lemak, dan data yang cenderung melampau akan mengelirukan model kita dan membawa kepada kerugian besar.
def zscore(series):
return (series - series.mean()) / np.std(series)
zscore(ratios).plot()
plt.axhline(zscore(ratios).mean())
plt.axhline(1.0, color=’red’)
plt.axhline(-1.0, color=’green’)
plt.show()
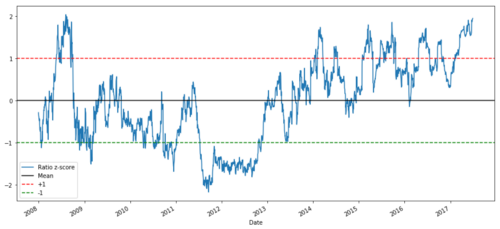
Z nisbah harga antara MSFT dan ADBE dari 2008 hingga 2017
Sekarang lebih mudah untuk memerhatikan pergerakan nisbah berhampiran nilai purata, tetapi kadang-kadang mudah untuk mempunyai perbezaan yang besar dari nilai purata.
Sekarang kita telah membincangkan pengetahuan asas strategi perdagangan pasangan, dan menentukan subjek integrasi bersama berdasarkan harga sejarah, mari kita cuba membangunkan isyarat perdagangan.
Mengumpul data yang boleh dipercayai dan membersihkan data;
Membuat fungsi dari data untuk mengenal pasti isyarat perdagangan/logik;
Fungsi boleh menjadi purata bergerak atau data harga, korelasi atau nisbah isyarat yang lebih kompleks - menggabungkan ini untuk mewujudkan fungsi baru;
Gunakan fungsi ini untuk menjana isyarat perdagangan, iaitu isyarat yang membeli, menjual atau kedudukan pendek untuk menonton.
Nasib baik, kami mempunyai platform FMZ Quant (fmz.com), yang telah melengkapkan empat aspek di atas untuk kami, yang merupakan berkat yang besar untuk pemaju strategi.
Dalam platform FMZ Quant, terdapat antara muka yang dikapsulkan untuk pelbagai pertukaran arus perdana. Apa yang perlu kita lakukan adalah memanggil antara muka API ini. Selebihnya logik pelaksanaan asas telah selesai oleh pasukan profesional.
Untuk melengkapkan logik dan menerangkan prinsip dalam artikel ini, kami akan membentangkan logik asas ini secara terperinci.
Mari kita mulakan:
Langkah 1: Sediakan soalan anda
Di sini, kita cuba untuk membuat isyarat untuk memberitahu kita sama ada nisbah akan membeli atau menjual pada masa akan datang, iaitu, ramalan kita pembolehubah Y:
Y = Nisbah adalah beli (1) atau menjual (-1)
Y(t)= Sign(Ratio(t+1)
Sila ambil perhatian bahawa kita tidak perlu meramalkan harga sasaran transaksi sebenar, atau bahkan nilai sebenar nisbah (walaupun kita boleh), tetapi hanya arah nisbah dalam langkah seterusnya.
Langkah 2: Kumpulkan data yang boleh dipercayai dan tepat
FMZ Quant adalah kawan anda! anda hanya perlu menentukan objek transaksi yang akan didagangkan dan sumber data yang akan digunakan, dan ia akan mengekstrak data yang diperlukan dan membersihkannya untuk pembahagian dividen dan objek transaksi. jadi data di sini sangat bersih.
Pada hari dagangan 10 tahun yang lalu (kira-kira 2500 titik data), kami memperoleh data berikut dengan menggunakan Yahoo Finance: harga pembukaan, harga penutupan, harga tertinggi, harga terendah dan jumlah dagangan.
Langkah 3: Pembagian data
Jangan lupa langkah ini sangat penting dalam menguji ketepatan model.
Latihan 7 tahun ~ 70%
Ujian ~ 3 tahun 30%
ratios = data['ADBE'] / data['MSFT']
print(len(ratios))
train = ratios[:1762]
test = ratios[1762:]
Sebaiknya, kita juga harus membuat set pengesahan, tetapi kita tidak akan melakukannya buat masa ini.
Langkah 4: Kejuruteraan Ciri
Apakah fungsi yang berkaitan? Kami ingin meramalkan arah perubahan nisbah. Kami telah melihat bahawa kedua-dua sasaran dagangan kami disatukan, jadi nisbah ini cenderung bergeser dan kembali ke nilai purata. Nampaknya ciri-ciri kami harus menjadi beberapa ukuran nisbah purata, dan perbezaan antara nilai semasa dan nilai purata boleh menghasilkan isyarat dagangan kami.
Kami menggunakan fungsi berikut:
Rasio purata bergerak 60 hari: pengukuran purata bergolak;
Rasio purata bergerak 5 hari: pengukuran nilai purata semasa;
60 hari penyimpangan standard;
Z Score: (5d MA - 60d MA) / 60d SD.
ratios_mavg5 = train.rolling(window=5,
center=False).mean()
ratios_mavg60 = train.rolling(window=60,
center=False).mean()
std_60 = train.rolling(window=60,
center=False).std()
zscore_60_5 = (ratios_mavg5 - ratios_mavg60)/std_60
plt.figure(figsize=(15,7))
plt.plot(train.index, train.values)
plt.plot(ratios_mavg5.index, ratios_mavg5.values)
plt.plot(ratios_mavg60.index, ratios_mavg60.values)
plt.legend(['Ratio','5d Ratio MA', '60d Ratio MA'])
plt.ylabel('Ratio')
plt.show()
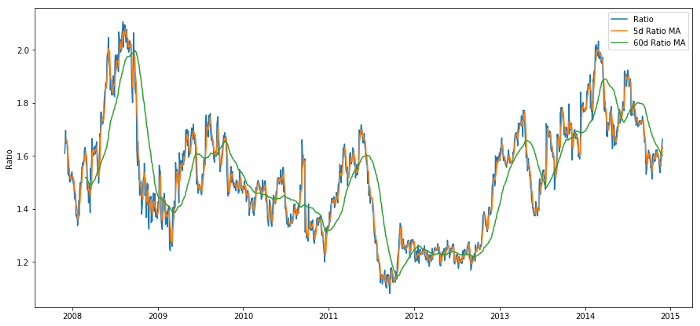
Nisbah harga antara 60d dan 5d MA
plt.figure(figsize=(15,7))
zscore_60_5.plot()
plt.axhline(0, color='black')
plt.axhline(1.0, color='red', linestyle='--')
plt.axhline(-1.0, color='green', linestyle='--')
plt.legend(['Rolling Ratio z-Score', 'Mean', '+1', '-1'])
plt.show()
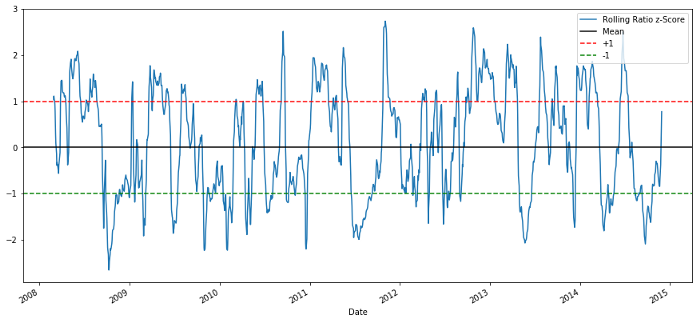
60-5 Z Nilai nisbah harga
Z-Score nilai purata bergolak tidak membawa semula sifat regresi nilai purata nisbah!
Langkah 5: Pilihan Model
Mari kita mulakan dengan model yang sangat mudah. Melihat carta skor z, kita dapat melihat bahawa jika skor z terlalu tinggi atau terlalu rendah, ia akan kembali. Mari kita gunakan +1/- 1 sebagai ambang untuk menentukan terlalu tinggi dan terlalu rendah, dan kemudian kita boleh menggunakan model berikut untuk menjana isyarat perdagangan:
Apabila z di bawah -1.0, nisbah adalah untuk membeli (1), kerana kita mengharapkan z untuk kembali ke 0, jadi nisbah meningkat;
Apabila z melebihi 1.0, nisbah adalah jual (- 1), kerana kita mengharapkan z untuk kembali ke 0, jadi nisbah menurun.
Langkah 6: Latihan, pengesahan dan pengoptimuman
Akhirnya, mari kita lihat kesan sebenar model kami pada data sebenar. mari kita lihat prestasi isyarat ini pada nisbah sebenar:
# Plot the ratios and buy and sell signals from z score
plt.figure(figsize=(15,7))
train[60:].plot()
buy = train.copy()
sell = train.copy()
buy[zscore_60_5>-1] = 0
sell[zscore_60_5<1] = 0
buy[60:].plot(color=’g’, linestyle=’None’, marker=’^’)
sell[60:].plot(color=’r’, linestyle=’None’, marker=’^’)
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,ratios.min(),ratios.max()))
plt.legend([‘Ratio’, ‘Buy Signal’, ‘Sell Signal’])
plt.show()
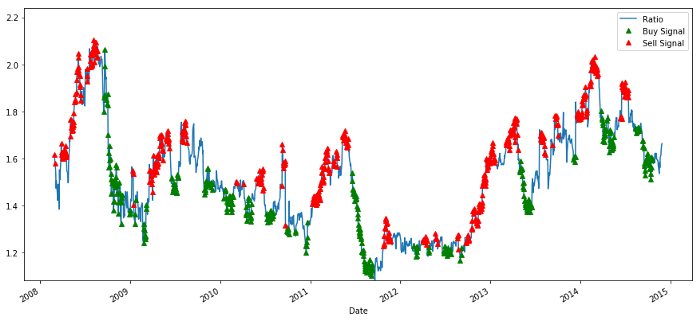
Isyarat nisbah harga beli dan jual
Isyarat itu kelihatan munasabah. Kita nampaknya menjual apabila ia tinggi atau meningkat (titik merah) dan membelinya semula apabila ia rendah (titik hijau) dan menurun. Apa yang ini bermakna untuk subjek sebenar transaksi kita? Mari kita lihat:
# Plot the prices and buy and sell signals from z score
plt.figure(figsize=(18,9))
S1 = data['ADBE'].iloc[:1762]
S2 = data['MSFT'].iloc[:1762]
S1[60:].plot(color='b')
S2[60:].plot(color='c')
buyR = 0*S1.copy()
sellR = 0*S1.copy()
# When buying the ratio, buy S1 and sell S2
buyR[buy!=0] = S1[buy!=0]
sellR[buy!=0] = S2[buy!=0]
# When selling the ratio, sell S1 and buy S2
buyR[sell!=0] = S2[sell!=0]
sellR[sell!=0] = S1[sell!=0]
buyR[60:].plot(color='g', linestyle='None', marker='^')
sellR[60:].plot(color='r', linestyle='None', marker='^')
x1,x2,y1,y2 = plt.axis()
plt.axis((x1,x2,min(S1.min(),S2.min()),max(S1.max(),S2.max())))
plt.legend(['ADBE','MSFT', 'Buy Signal', 'Sell Signal'])
plt.show()
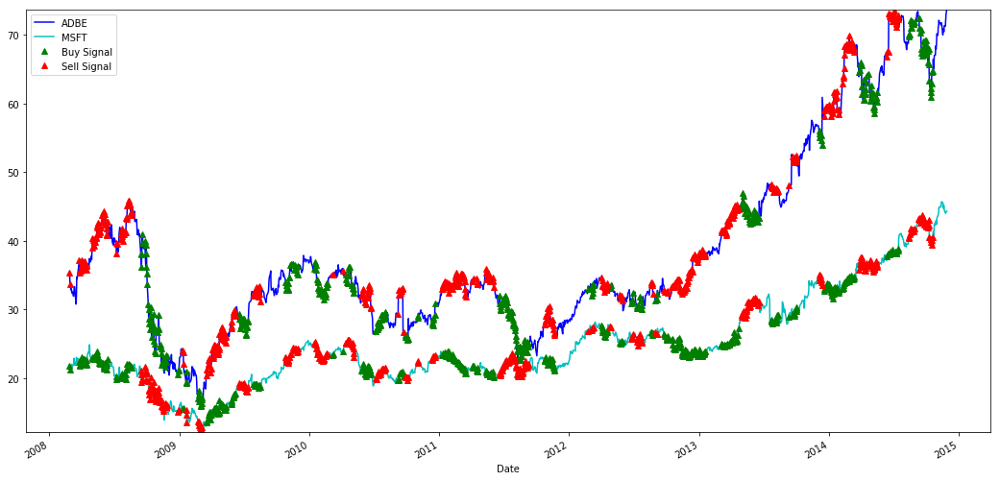
Isyarat untuk membeli dan menjual saham MSFT dan ADBE
Sila perhatikan bagaimana kita kadang-kadang membuat keuntungan dengan
Kami berpuas hati dengan isyarat data latihan. Mari kita lihat apa jenis keuntungan isyarat ini boleh menjana. Apabila nisbah rendah, kita boleh membuat penguji belakang yang mudah, membeli nisbah (beli 1 saham ADBE dan jual nisbah x saham MSFT), dan menjual nisbah (jual 1 saham ADBE dan beli x saham MSFT nisbah) apabila ia tinggi, dan mengira transaksi PnL nisbah ini.
# Trade using a simple strategy
def trade(S1, S2, window1, window2):
# If window length is 0, algorithm doesn't make sense, so exit
if (window1 == 0) or (window2 == 0):
return 0
# Compute rolling mean and rolling standard deviation
ratios = S1/S2
ma1 = ratios.rolling(window=window1,
center=False).mean()
ma2 = ratios.rolling(window=window2,
center=False).mean()
std = ratios.rolling(window=window2,
center=False).std()
zscore = (ma1 - ma2)/std
# Simulate trading
# Start with no money and no positions
money = 0
countS1 = 0
countS2 = 0
for i in range(len(ratios)):
# Sell short if the z-score is > 1
if zscore[i] > 1:
money += S1[i] - S2[i] * ratios[i]
countS1 -= 1
countS2 += ratios[i]
print('Selling Ratio %s %s %s %s'%(money, ratios[i], countS1,countS2))
# Buy long if the z-score is < 1
elif zscore[i] < -1:
money -= S1[i] - S2[i] * ratios[i]
countS1 += 1
countS2 -= ratios[i]
print('Buying Ratio %s %s %s %s'%(money,ratios[i], countS1,countS2))
# Clear positions if the z-score between -.5 and .5
elif abs(zscore[i]) < 0.75:
money += S1[i] * countS1 + S2[i] * countS2
countS1 = 0
countS2 = 0
print('Exit pos %s %s %s %s'%(money,ratios[i], countS1,countS2))
return money
trade(data['ADBE'].iloc[:1763], data['MSFT'].iloc[:1763], 60, 5)
Hasilnya ialah: 1783.375
Jadi strategi ini nampaknya menguntungkan! Sekarang, kita boleh mengoptimumkan lagi dengan mengubah tingkap masa purata bergerak, dengan mengubah ambang pembelian / penjualan dan kedudukan tutup, dan memeriksa peningkatan prestasi data pengesahan.
Kita juga boleh mencuba model yang lebih kompleks, seperti Regresi Logistik dan SVM, untuk meramalkan 1/-1.
Sekarang, mari kita majukan model ini, yang membawa kita kepada:
Langkah 7: Uji semula data ujian
Di sini lagi, platform FMZ Quant menggunakan enjin backtesting QPS / TPS berprestasi tinggi untuk menghasilkan semula persekitaran sejarah dengan benar, menghapuskan perangkap backtesting kuantitatif biasa, dan menemui kekurangan strategi tepat pada masanya, untuk lebih membantu pelaburan bot sebenar.
Untuk menerangkan prinsipnya, artikel ini masih memilih untuk menunjukkan logik yang mendasari. Dalam aplikasi praktikal, kami mengesyorkan pembaca menggunakan platform FMZ Quant. Selain menjimatkan masa, penting untuk meningkatkan kadar toleransi ralat.
Ujian balik adalah mudah. Kita boleh menggunakan fungsi di atas untuk melihat PnL data ujian.
trade(data['ADBE'].iloc[1762:], data['MSFT'].iloc[1762:], 60, 5)
Hasilnya ialah: 5262.868
Ia menjadi model perdagangan pasangan mudah pertama kami.
Elakkan pemasangan berlebihan
Sebelum menamatkan perbincangan ini, saya ingin membincangkan terlalu banyak secara khusus. Overfitting adalah perangkap yang paling berbahaya dalam strategi perdagangan. Algoritma overfitting mungkin berfungsi dengan sangat baik dalam backtest tetapi gagal pada data yang tidak kelihatan baru - yang bermaksud bahawa ia tidak benar-benar mendedahkan sebarang trend data dan tidak mempunyai keupayaan ramalan yang sebenar. Mari kita berikan contoh yang mudah.
Dalam model kami, kami menggunakan parameter bergulir untuk menganggarkan dan mengoptimumkan panjang tetingkap masa. Kami boleh memutuskan untuk hanya mengulangi semua kemungkinan, jangka masa tetingkap yang munasabah, dan memilih jangka masa mengikut prestasi terbaik model kami. Mari
# Find the window length 0-254
# that gives the highest returns using this strategy
length_scores = [trade(data['ADBE'].iloc[:1762],
data['MSFT'].iloc[:1762], l, 5)
for l in range(255)]
best_length = np.argmax(length_scores)
print ('Best window length:', best_length)
('Best window length:', 40)
Sekarang kita memeriksa prestasi model pada data ujian, dan kita mendapati bahawa panjang tetingkap masa ini adalah jauh dari optimum! Ini kerana pilihan asal kita jelas over-fit data sampel.
# Find the returns for test data
# using what we think is the best window length
length_scores2 = [trade(data['ADBE'].iloc[1762:],
data['MSFT'].iloc[1762:],l,5)
for l in range(255)]
print (best_length, 'day window:', length_scores2[best_length])
# Find the best window length based on this dataset,
# and the returns using this window length
best_length2 = np.argmax(length_scores2)
print (best_length2, 'day window:', length_scores2[best_length2])
(40, 'day window:', 1252233.1395)
(15, 'day window:', 1449116.4522)
Adalah jelas bahawa data sampel yang sesuai untuk kita tidak akan selalu menghasilkan hasil yang baik pada masa akan datang.
plt.figure(figsize=(15,7))
plt.plot(length_scores)
plt.plot(length_scores2)
plt.xlabel('Window length')
plt.ylabel('Score')
plt.legend(['Training', 'Test'])
plt.show()
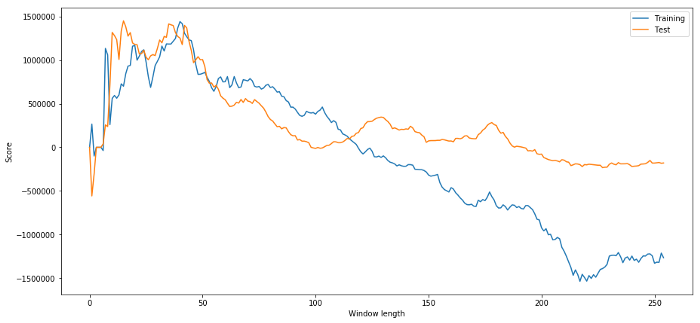
Kita boleh lihat bahawa apa-apa di antara 20 dan 50 adalah pilihan yang baik untuk tingkap masa.
Untuk mengelakkan overfit, kita boleh menggunakan penalaran ekonomi atau sifat algoritma untuk memilih panjang tetingkap masa.
Langkah seterusnya
Dalam artikel ini, kami mencadangkan beberapa kaedah pengenalan mudah untuk menunjukkan proses membangunkan strategi perdagangan. Dalam amalan, statistik yang lebih kompleks harus digunakan.
Eksponen Hurst;
Separuh hayat regresi purata yang disimpulkan daripada proses Ornstein-Uhlenbeck;
Penapis Kalman.
- Amalan Kuantitatif Bursa DEX (2) -- Panduan Pengguna Hyperliquid
- DEX Exchange Quantitative Practice ((2) -- Panduan Penggunaan Hyperliquid
- Amalan Kuantitatif Bursa DEX (1) -- Panduan Pengguna dYdX v4
- Pengenalan kepada Arbitraj Lead-Lag dalam Cryptocurrency (3)
- DEX Exchange Quantitative Practice ((1) -- panduan pengguna dYdX v4
- Pengenalan suite Lead-Lag dalam mata wang digital (3)
- Pengenalan kepada Arbitraj Lead-Lag dalam Cryptocurrency (2)
- Pendahuluan mengenai Lead-Lag dalam mata wang digital (2)
- Perbincangan mengenai Penerimaan Isyarat Luaran Platform FMZ: Penyelesaian Lengkap untuk Menerima Isyarat dengan Perkhidmatan Http Terbina dalam Strategi
- Penyelidikan penerimaan isyarat luaran platform FMZ: strategi penyelesaian lengkap untuk penerimaan isyarat perkhidmatan HTTP terbina dalam
- Pengenalan kepada Arbitraj Lead-Lag dalam Cryptocurrency (1)
- Rangkaian Perdagangan Kuantitatif Rangkaian Rangkaian Neural dan Mata Wang Digital (2) - Pembelajaran dan Latihan Intensif Strategi Perdagangan Bitcoin
- Rangkaian Perdagangan Kuantitatif Rangkaian Rangkaian Rangkaian Neural dan Mata Wang Digital (1) - LSTM Meramalkan Harga Bitcoin
- Penggunaan strategi gabungan indeks kekuatan relatif SMA dan RSI
- Pembangunan strategi CTA dan perpustakaan kelas standard platform FMZ Quant
- Strategi perdagangan kuantitatif dengan analisis momentum harga dalam Python
- Melaksanakan Strategi Dagangan Kuantitatif Mata Wang Digital Dual Thrust di Python
- Cara terbaik untuk memasang dan menaik taraf untuk Linux docker
- Mencapai strategi ekuiti yang seimbang dengan penyelarasan yang teratur
- Analisis Data Siri Masa dan Ujian Balik Data Tick
- Analisis Kuantitatif Pasaran Mata Wang Digital
- Penggunaan Teknologi Pembelajaran Mesin dalam Perdagangan
- Menggunakan persekitaran penyelidikan untuk menganalisis butiran lindung nilai segitiga dan kesan yuran pengendalian pada perbezaan harga lindung nilai
- Reformasi API niaga hadapan Deribit untuk menyesuaikan diri dengan perdagangan kuantitatif opsyen
- Alat yang lebih baik membuat kerja yang baik - belajar menggunakan persekitaran penyelidikan untuk menganalisis prinsip perdagangan
- Strategi lindung nilai silang mata wang dalam perdagangan kuantitatif aset blockchain
- Dapatkan panduan strategi mata wang digital FMex di FMZ Quant
- Mengajar anda untuk menulis strategi - pemindahan strategi MyLanguage (Advanced)
- Mengajar anda untuk menulis strategi - menanam strategi MyLanguage
- Mengajar anda untuk menambah sokongan pelbagai carta kepada strategi
- Mengajar anda untuk menulis fungsi sintesis K-garis dalam versi Python