Crie um robô de negociação de Bitcoin que não perca dinheiro
Autora:FMZ~Lydia, Criado: 2023-02-01 11:52:21, Atualizado: 2024-12-24 20:25:11
Crie um robô de negociação de Bitcoin que não perca dinheiro
Vamos usar a aprendizagem de reforço na IA para construir um robô de negociação de moeda digital.
Neste artigo, criaremos e aplicaremos um número de quadro de aprendizagem aprimorado para aprender como fazer um robô de negociação Bitcoin.
Muito obrigado pelo software de código aberto fornecido pela OpenAI e DeepMind para os pesquisadores de aprendizado profundo nos últimos anos. Se você não viu suas incríveis realizações com AlphaGo, OpenAI Five, AlphaStar e outras tecnologias, você pode ter vivido isolado no ano passado, mas você deve conferir.
Treinamento AlphaStar:https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
Embora não vamos criar nada impressionante, ainda não é fácil negociar robôs Bitcoin em transações diárias.
Não há valor em nada que seja muito simples.
Portanto, não só devemos aprender a negociar nós mesmos, mas também deixar os robôs negociarem por nós.
Plano

Criar um ambiente de ginástica para o nosso robô realizar aprendizagem de máquina
Reproduzir um ambiente visual simples e elegante
Treinar o nosso robô para aprender uma estratégia comercial rentável
Se você não está familiarizado com como criar ambientes de ginástica a partir do zero, ou como simplesmente renderizar a visualização desses ambientes.
Começando
Neste tutorial, vamos usar o conjunto de dados Kaggle gerado por Zielak. Se você quiser baixar o código fonte, ele será fornecido no meu repositório do Github, juntamente com o arquivo de dados.csv. Ok, vamos começar.
Primeiro, vamos importar todas as bibliotecas necessárias.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
Em seguida, vamos criar nossa classe para o ambiente. Precisamos passar um número de quadro de dados Pandas e um inicial_balance opcional e um lookback_window_size, que indicará o número de passos de tempo passado observados pelo robô em cada etapa. Nós predefinimos a comissão de cada transação para 0,075%, ou seja, a taxa de câmbio atual do Bitmex, e predefinimos o parâmetro serial para falso, o que significa que nosso número de quadro de dados será atravessado por fragmentos aleatórios por padrão.
Também chamamos dropna() e reset_index() nos dados, primeiro excluir a linha com valor NaN, e, em seguida, redefinir o índice de número de quadro, porque nós excluímos os dados.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
Nosso action_space é representado como um grupo de 3 opções (comprar, vender ou manter) aqui e outro grupo de 10 valores (1⁄10, 2⁄10, 3⁄10Quando escolhemos comprar, vamos comprar quantidade * self.balance palavra de BTC. Para vender, vamos vender quantidade * self.btc_held valor de BTC. Claro, a detenção vai ignorar a quantidade e não fazer nada.
Nosso observation_space é definido como um ponto flutuante contínuo definido entre 0 e 1, e sua forma é (10, lookback_window_size+1). + 1 é usado para calcular o passo de tempo atual. Para cada passo de tempo na janela, observaremos o valor OHCLV. Nosso patrimônio líquido é igual ao número de BTCs que compramos ou vendemos e a quantidade total de dólares que gastamos ou recebemos nesses BTCs.
Em seguida, precisamos escrever o método de reinicialização para inicializar o ambiente.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
Aqui usamos self._reset_session e self._next_observation, que ainda não definimos.
Sessão de negociação
Uma parte importante do nosso ambiente é o conceito de sessões de negociação. Se implementarmos este robô fora do mercado, podemos nunca executá-lo por mais de alguns meses de cada vez. Por esta razão, vamos limitar o número de quadros consecutivos em self.df, que é o número de quadros que nosso robô pode ver de uma vez.
Em nosso método _reset_session, nós redefinimos o current_step para 0 primeiro. Em seguida, vamos definir steps_left para um número aleatório entre 1 e MAX_TRADING_SESSIONS, que vamos definir no topo do programa.
MAX_TRADING_SESSION = 100000 # ~2 months
Em seguida, se quisermos percorrer o número de quadros consecutivamente, devemos configurá-lo para percorrer todo o número de quadros, caso contrário, definimos frame_start em um ponto aleatório em self.df e criamos um novo quadro de dados chamado active_df, que é apenas uma fatia de self.df e está indo de frame_start para frame_start + steps_left.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
Um efeito colateral importante de atravessar o número de quadros de dados na fatia aleatória é que nosso robô terá mais dados únicos para uso em treinamento de longo prazo. Por exemplo, se atravessarmos apenas o número de quadros de dados de forma serial (isto é, de 0 a len(df)), teremos apenas tantos pontos de dados únicos quanto o número de quadros de dados. Nosso espaço de observação só pode usar um número discreto de estados em cada etapa de tempo.
No entanto, atravessando as fatias do conjunto de dados aleatoriamente, podemos criar um conjunto mais significativo de resultados de negociação para cada etapa do conjunto de dados inicial, ou seja, a combinação de comportamento de negociação e comportamento de preço visto anteriormente para criar conjuntos de dados mais únicos.
Quando o passo de tempo após a reinicialização do ambiente serial é 10, nosso robô sempre executará o conjunto de dados ao mesmo tempo, e há três opções após cada passo de tempo: comprar, vender ou manter. Para cada uma das três opções, você precisa de outra opção: 10%, 20%,... ou 100% do valor específico da implementação. Isso significa que nosso robô pode encontrar um dos 10 estados de qualquer 103, um total de 1030 casos.
Agora voltando ao nosso ambiente de corte aleatório. Quando o passo de tempo é 10, nosso robô pode estar em qualquer passo de tempo len(df) dentro do número de quadros de dados. Supondo que a mesma escolha é feita após cada passo de tempo, isso significa que o robô pode experimentar o estado único de qualquer len(df) à 30a potência nos mesmos 10 passos de tempo.
Embora isso possa trazer um ruído considerável para grandes conjuntos de dados, acredito que os robôs devem ser autorizados a aprender mais a partir de nossos dados limitados.
Observado através dos olhos de um robô
Através de uma observação visual eficaz do ambiente, muitas vezes é útil entender o tipo de funções que nosso robô usará.
Observação do ambiente de visualização OpenCV
Cada linha na imagem representa uma linha em nosso observation_space. As primeiras quatro linhas de linhas vermelhas com frequências semelhantes representam dados OHCL, e os pontos laranja e amarelo diretamente abaixo representam o volume de negociação. A barra azul flutuante abaixo representa o valor líquido do robô, enquanto a barra mais clara abaixo representa a transação do robô.
Se você observar cuidadosamente, você pode até fazer um mapa de velas você mesmo. Abaixo da barra de volume de negociação há uma interface de código Morse, exibindo o histórico de negociação. Parece que nosso robô deve ser capaz de aprender o suficiente a partir dos dados em nosso observation_space, então vamos continuar. Aqui vamos definir o método _next_observation, escalamos os dados observados de 0 a 1.
- É importante estender apenas os dados observados pelo robô até agora para evitar desvios principais.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
Tomar medidas
Nós estabelecemos nosso espaço de observação, e agora é hora de escrever nossa função de escada, e então tomar a ação programada do robô. Sempre que self.steps_left == 0 para nossa sessão de negociação atual, venderemos nosso BTC e chamaremos _reset_session(). Caso contrário, definiremos a recompensa para o valor líquido atual. Se ficarmos sem fundos, definiremos feito para True.
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
Tomar uma ação de negociação é tão simples quanto obter o preço atual, determinar as ações a serem executadas e a quantidade a comprar ou vender.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
Por último, no mesmo método, anexaremos a transacção ao self.trades e atualizaremos o nosso valor líquido e o histórico da conta.
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
O nosso robô pode começar um novo ambiente agora, completar o ambiente gradualmente e tomar medidas que afetem o ambiente.
Vê o nosso comércio de robôs.
Nosso método de renderização pode ser tão simples quanto chamar a impressão (self.net_word), mas não é interessante o suficiente. em vez disso, vamos desenhar um gráfico de vela simples, que contém um gráfico separado da coluna de volume de negociação e nosso patrimônio líquido.
Vamos obter o código em StockTrackingGraph.py do meu último artigo e redesenhá-lo para adaptá-lo ao ambiente Bitcoin.
A primeira mudança que precisamos fazer é atualizar self.df [
from datetime import datetime
Primeiro, importar a biblioteca de datas e horas, e então vamos usar o método utcfromtimestamp para obter a string UTC de cada timestamp e strftime para que seja formatada como uma string: formato Y-m-d H:M.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
Finalmente, vamos mudar self. df[
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
Podemos ver os nossos robôs negociar Bitcoin agora.
Visualize o nosso robô negociando com o Matplotlib
O rótulo fantasma verde representa a compra de BTC, e o rótulo fantasma vermelho representa a venda. O rótulo branco no canto superior direito é o valor líquido atual do robô, e o rótulo no canto inferior direito é o preço atual do Bitcoin. É simples e elegante. Agora, é hora de treinar nossos robôs e ver quanto dinheiro podemos ganhar!
Tempo de formação
Uma das críticas que recebi no artigo anterior foi a falta de validação cruzada e o fracasso em dividir os dados em conjuntos de treinamento e conjuntos de teste. O propósito disso é testar a precisão do modelo final em novos dados que nunca foram vistos antes. Embora este não seja o foco desse artigo, é realmente muito importante.
Por exemplo, uma forma comum de validação cruzada é chamada de validação k-fold. Nesta validação, você divide os dados em k grupos iguais, um por um, individualmente, como o grupo de teste e usa o restante dos dados como o grupo de treinamento. No entanto, os dados de séries temporais são altamente dependentes do tempo, o que significa que os dados subsequentes são altamente dependentes dos dados anteriores.
Quando aplicado aos dados de séries temporais, a mesma falha se aplica à maioria das outras estratégias de validação cruzada. Portanto, precisamos apenas usar uma parte do número de quadro de dados completo como o conjunto de treinamento do número de quadro para alguns índices arbitrários, e usar o resto dos dados como o conjunto de teste.
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
Em seguida, uma vez que o nosso ambiente é configurado apenas para lidar com um único número de quadros de dados, vamos criar dois ambientes, um para os dados de treinamento e um para os dados de teste.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
Treinar o nosso modelo é tão simples como criar um robô usando o nosso ambiente e chamar o modelo.learn.
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
Aqui, usamos placas tensoras, para que possamos visualizar nossos gráficos de fluxo tensorial facilmente e ver alguns indicadores quantitativos sobre nosso robô.
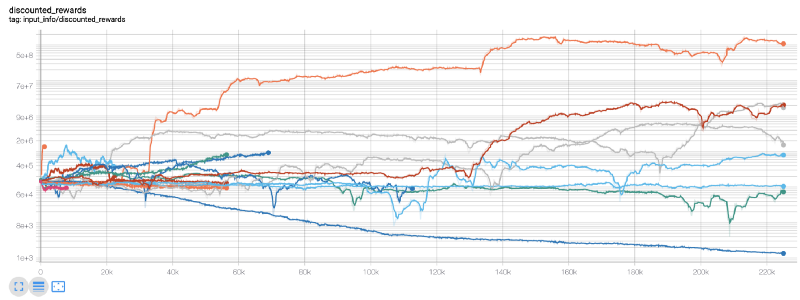
Parece que o nosso robô é muito rentável! O nosso melhor robô pode até atingir o equilíbrio 1000x em 200.000 passos, e o resto aumentará pelo menos 30 vezes em média!
Neste momento, percebi que houve um erro no ambiente... depois de corrigir o bug, este é o novo gráfico de recompensa:
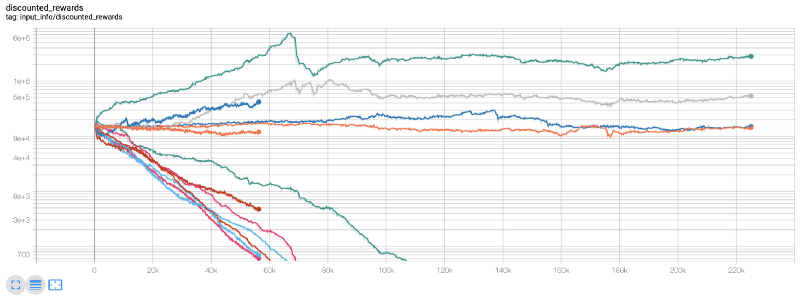
Como você pode ver, alguns de nossos robôs estão indo bem, enquanto outros estão falidos. No entanto, robôs com bom desempenho podem chegar a 10 vezes ou até 60 vezes o saldo inicial no máximo. Devo admitir que todas as máquinas lucrativas são treinadas e testadas sem comissão, por isso é irrealista que nossos robôs ganhem dinheiro real. Mas pelo menos encontramos o caminho!
Vamos testar os nossos robôs no ambiente de teste (usando novos dados que nunca viram antes) para ver como se comportarão.
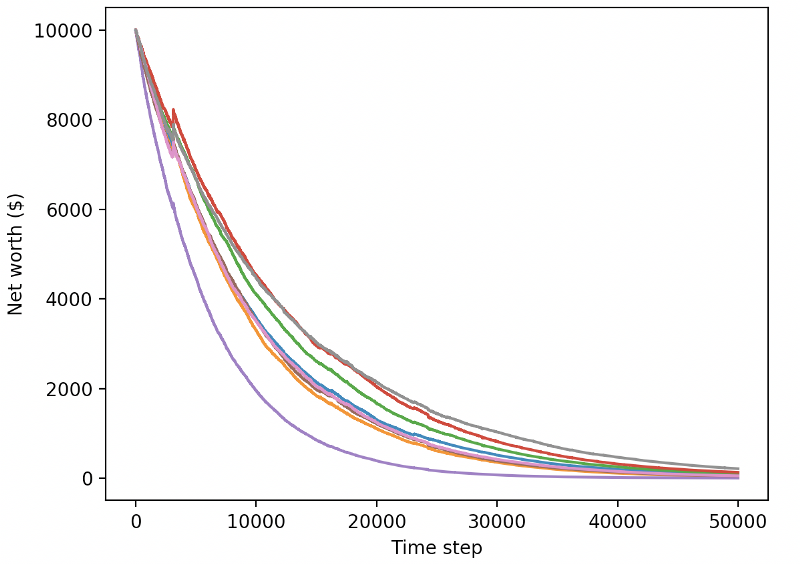
Os nossos robôs bem treinados irão à falência quando trocarem novos dados de teste.
Obviamente, ainda temos muito trabalho a fazer. Simplesmente mudando os modelos para usar A2C com base estável em vez do robô PPO2 atual, podemos melhorar muito nosso desempenho neste conjunto de dados. Finalmente, de acordo com a sugestão de Sean O
reward = self.net_worth - prev_net_worth
Estas duas mudanças sozinhas podem melhorar o desempenho do conjunto de dados de teste muito, e como podem ver abaixo, finalmente fomos capazes de lucrar com novos dados que não estavam disponíveis no conjunto de treinamento.
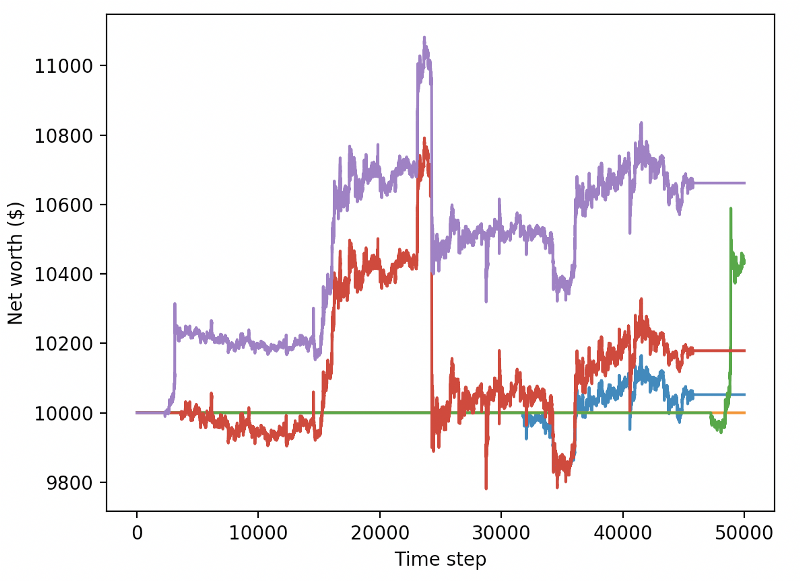
Mas podemos fazer melhor. Para melhorar estes resultados, precisamos de otimizar os nossos super parâmetros e treinar os nossos robôs por mais tempo. É hora da GPU começar a trabalhar e disparar em todos os cilindros!
Até agora, este artigo foi um pouco longo, e ainda temos muitos detalhes para considerar, então planejamos descansar aqui. No próximo artigo, usaremos a otimização Bayesiana para particionar os melhores hiperparâmetros para o nosso espaço de problema e nos prepararemos para treinamento / teste em GPU usando CUDA.
Conclusão
Neste artigo, começamos a usar o aprendizado de reforço para criar um robô de negociação Bitcoin rentável a partir do zero.
Crie um ambiente de negociação de Bitcoin a partir do zero usando o ginásio do OpenAI.
Use Matplotlib para construir a visualização do ambiente.
Usamos a validação cruzada para treinar e testar o nosso robô.
Ajustar os nossos robôs ligeiramente para obter lucros.
Embora nosso robô de negociação não tenha sido tão lucrativo quanto esperávamos, já estamos nos movendo na direção certa. Na próxima vez, garantiremos que nossos robôs possam bater consistentemente o mercado. Veremos como nossos robôs de negociação processam dados em tempo real. Por favor, continue a seguir meu próximo artigo e Viva Bitcoin!
- Prática quantitativa das bolsas DEX (2) -- Guia do utilizador do hiperlíquido
- Práticas de quantificação da DEX Exchange ((2) -- Guia de uso do Hyperliquid
- Prática quantitativa das bolsas DEX (1) -- dYdX v4 Guia do utilizador
- Introdução à arbitragem de lead-lag em criptomoedas (3)
- Práticas de quantificação da DEX exchange ((1) -- dYdX v4 Guia de uso
- Introdução ao conjunto de Lead-Lag na moeda digital (3)
- Introdução à arbitragem de lead-lag em criptomoedas (2)
- Introdução ao suporte de Lead-Lag na moeda digital (2)
- Discussão sobre a recepção de sinais externos da plataforma FMZ: uma solução completa para receber sinais com serviço HTTP em estratégia
- Discussão da recepção de sinais externos da plataforma FMZ: estratégias para o sistema completo de recepção de sinais do serviço HTTP embutido
- Introdução à arbitragem de lead-lag em criptomoedas (1)
- Fazer com que as políticas sejam executadas em simultâneo, aumentando o suporte a múltiplos fios no fundo do sistema para as políticas do JavaScript
- Se não sabes escrever uma estratégia numa linguagem tão fácil de aprender e de usar...
- Os benefícios esperados do comércio de alta frequência
- Podemos fazer negociação quantitativa sem código?
- "Obtenha o melhor negócio" análise da vulnerabilidade na troca
- 5.6 Construir o pensamento de probabilidade para melhorar o seu padrão de negociação
- Acesso Uniswap V3 no FMZ com 200 linhas de código
- Quando FMZ encontra ChatGPT, uma tentativa de usar IA para ajudar na aprendizagem de negociação quantitativa
- 9 regras de negociação ajudam um comerciante a ganhar $ 46.000 de $ 1.000 em menos de um ano
- De negociação quantitativa para gestão de ativos - Desenvolvimento de estratégias CTA para o retorno absoluto
- O segredo para a sobrevivência: 19 profissionais compartilham seus conselhos sobre o comércio de moeda digital
- Use JavaScript para implementar a execução simultânea da estratégia quantitativa - encapsular a função Go
- A aplicação do "demônio de Shannon" na moeda digital
- Elegante e simples! Acesso ao Uniswap V3 com 200 linhas de código no FMZ
- Princípio e elaboração do modelo de stop-loss
- Tycoon revela algoritmo de negociação: FMZ Quant plataforma estratégia de mercado
- Três modelos potenciais de negociação quantitativa
- Sistema de negociação intradiário de ponto pivô
- 6 estratégias e práticas simples para iniciantes em negociação quantitativa de moeda digital
- Quadro estratégico do intervalo verdadeiro médio