Máy vectơ hỗ trợ trong não
 0
2024
0
2024
Máy vectơ hỗ trợ trong não
Máy vectơ hỗ trợ (SVM) là một phân loại học máy quan trọng, nó sử dụng sự biến đổi phi tuyến tính khéo léo để chiếu các đặc điểm dưới chiều lên chiều cao, có thể thực hiện các nhiệm vụ phân loại phức tạp hơn (các cú đánh nâng). SWM dường như sử dụng một trò chơi tinh tế về toán học, nhưng thực tế phù hợp với cơ chế mã hóa não bộ, chúng ta có thể đọc từ một bài báo của Nature năm 2013 để hiểu mối liên hệ sâu sắc giữa học máy và nguyên tắc hoạt động của não bộ (các mối liên hệ bề mặt là nghiên cứu não bộ bằng học máy). Tên bài viết: The importance of mixed selectivity in complex cognitive tasks (by Omri Barak al. )
- #### SVM
Đầu tiên chúng ta hãy nói về bản chất của mã hóa thần kinh: động vật nhận được một tín hiệu nhất định và hành động theo đó, một là chuyển đổi tín hiệu bên ngoài thành tín hiệu điện thần kinh, và một là chuyển đổi tín hiệu điện thần kinh thành tín hiệu quyết định, quá trình trước được gọi là mã hóa, quá trình sau được gọi là giải mã. Và mục đích thực sự của mã hóa thần kinh là giải mã và sau đó đưa ra quyết định. Vì vậy, để giải mã bằng cách nhìn bằng máy học, cách đơn giản nhất là xem phân loại, thậm chí là phân loại tuyến tính của mô hình logistic, để phân loại tín hiệu đầu vào theo một phân loại đặc điểm nhất định.
Vậy chúng ta hãy xem cách mã hóa thần kinh được thực hiện như thế nào. Đầu tiên, một tế bào thần kinh có thể được xem như một mạch RC điều chỉnh điện trở và điện tích theo điện áp ngoài, và khi tín hiệu bên ngoài đủ lớn, nó sẽ dẫn, nếu không, nó sẽ đóng, và biểu thị một tín hiệu bằng tần số phát điện trong một khoảng thời gian nhất định. Và chúng ta nói về mã hóa, thường là làm một xử lý phân tán về thời gian, cho rằng trong một cửa sổ thời gian nhỏ, tần số phát điện này là không thay đổi, do đó một mạng thần kinh có thể làm các tế bào phát điện xếp hàng trong cửa sổ thời gian này với một chiều N, N là số lượng tế bào thần kinh, và chiều N này, chúng ta gọi là mã hóa, biểu thị hình ảnh mà động vật có thể nhìn thấy, hoặc âm thanh nghe thấy, sẽ gây ra một mạng thần kinh tương ứng của lớp vỏ tương ứng - tức là một tín hiệu bên ngoài.
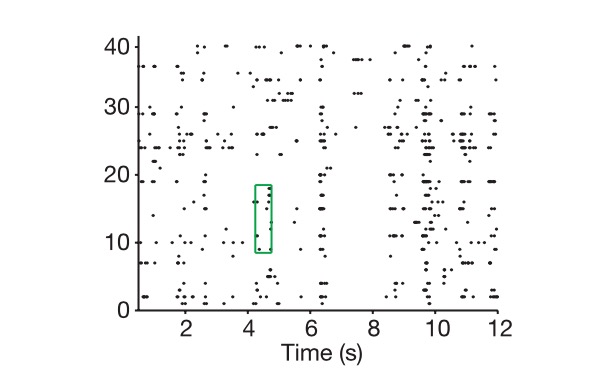
Biểu đồ: Dọc theo chiều dọc là tế bào, chiều ngang là thời gian, và biểu đồ cho thấy cách chúng ta lấy mã hóa thần kinh.
Tất nhiên, n-dimensional vector và n-code có chiều thực khác nhau, làm thế nào để xác định n-dimensional vector của n-code? Đầu tiên, chúng ta đi vào không gian n-dimensional này được đánh dấu bởi n-dimensional vector, sau đó chúng ta đưa ra tất cả các tổ hợp nhiệm vụ có thể, chẳng hạn như cho bạn thấy một ngàn hình ảnh giả sử những hình ảnh đại diện cho toàn bộ thế giới, đánh dấu mỗi n-code chúng ta nhận được là một điểm trong không gian này, và cuối cùng chúng ta sử dụng suy nghĩ của thuật toán vector để xem chiều của một không gian con tạo thành một ngàn điểm, đó là chiều thực của biểu hiện n-dimensional.
Ngoài các chiều thực tế của mã hóa, chúng ta còn có một khái niệm là chiều thực tế của tín hiệu bên ngoài, ở đây tín hiệu là tín hiệu bên ngoài được thể hiện bởi mạng thần kinh, tất nhiên bạn phải lặp lại tất cả các chi tiết của tín hiệu bên ngoài đó là một vấn đề vô hạn, tuy nhiên chúng ta phân loại và quyết định dựa trên luôn luôn là các đặc điểm quan trọng, một quá trình giảm kích thước, đó cũng là ý tưởng của PCA. Ở đây chúng ta có thể xem các biến quan trọng trong nhiệm vụ thực sự là chiều thực tế của nhiệm vụ, ví dụ như bạn muốn kiểm soát chuyển động của một cánh tay, bạn thường chỉ cần kiểm soát góc xoay của khớp, nếu bạn xem nó như một vấn đề động lực học rắn, chiều không cao hơn 10, chúng ta gọi là K.
Vậy các nhà khoa học phải đối mặt với một vấn đề cốt lõi, tại sao phải giải quyết vấn đề này bằng một số lượng nơ-ron và một số lượng mã hóa lớn hơn rất nhiều so với vấn đề thực sự?
Và tính toán thần kinh học và học máy cùng nhau cho chúng ta biết rằng tính chất chiều cao của biểu hiện thần kinh chính là nền tảng cho khả năng học tập cao của nó. Định dạng càng cao, khả năng học tập càng tốt.
Lưu ý rằng mã hóa thần kinh được thảo luận ở đây chủ yếu là mã hóa thần kinh của các trung tâm thần kinh cấp cao, chẳng hạn như vỏ não tiền trán trước (PFC) được thảo luận trong bài viết, vì quy tắc mã hóa của các trung tâm thần kinh cấp thấp không liên quan nhiều đến phân loại và ra quyết định.
Các vùng não cao cấp của PFC
Thứ nhất, chúng ta giả định rằng chúng ta sẽ không thể xử lý các vấn đề phân loại phi tuyến tính bằng cách sử dụng một phân loại tuyến tính khi kích thước mã hóa của chúng ta bằng với kích thước của các biến quan trọng trong nhiệm vụ thực (giả sử bạn muốn tách một quả dưa chuột ra khỏi một quả dưa chuột, bạn không thể lấy nó ra khỏi nó bằng một đường viền tuyến tính), và đó cũng là vấn đề điển hình mà chúng ta khó giải quyết khi học sâu và SVM không tham gia vào học máy. Sử dụng giải pháp cốt lõi của SVM cho các loại vấn đề này được gọi là đại diện lại, tức là thay đổi hệ thống tọa độ gốc của chúng ta sang một bộ tọa độ mới có chiều cao hơn, cho thấy chúng ta vẫn có thể sử dụng phân loại siêu tuyến tính khi không có phương pháp phân loại siêu tuyến tính.
SVM ((hỗ trợ máy vector):
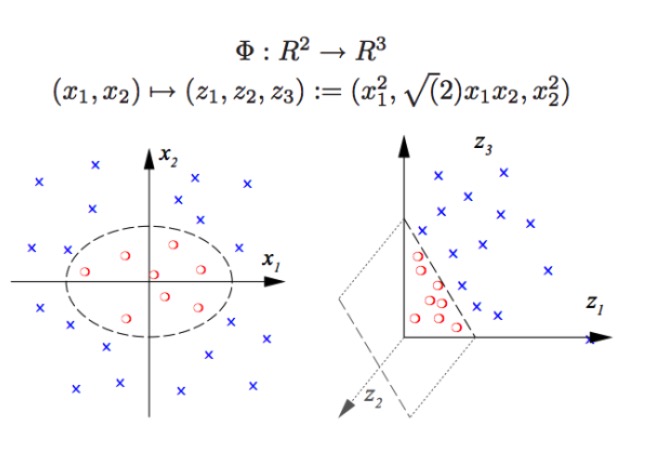
SVM có thể phân loại không tuyến tính, ví dụ như tách các điểm đỏ và điểm xanh trong biểu đồ, không thể tách các điểm đỏ và điểm xanh với ranh giới tuyến tính (hình bên trái), do đó cách SVM sử dụng chính là tăng chiều. Mà chỉ đơn giản là tăng số lượng biến số là không thực tế, ví dụ như bản đồ (x1, x2) vào hệ thống (x1, x2, x1 + x2) thực tế là không gian tuyến tính hai chiều (hình vẽ riêng biệt là điểm đỏ và điểm xanh cũng nằm trên một mặt phẳng), chỉ sử dụng hàm không tuyến tính (x1 ^ 2, x1)*x2, x2^2) chúng ta có một sự chuyển đổi thực sự từ chiều thấp sang chiều cao, và khi bạn ném một chấm xanh vào không gian, và sau đó bạn vẽ một mặt phẳng trên không gian, và bạn tách những chấm xanh ra khỏi những chấm đỏ, như hình bên phải.
Trên thực tế, những gì mà một mạng lưới thần kinh thực sự làm cũng tương tự như vậy. Một phân loại tuyến tính như vậy có thể làm được rất nhiều thứ phân loại, có nghĩa là chúng ta có khả năng nhận dạng mô hình mạnh hơn nhiều so với trước đây. Ở đây, chiều cao là năng lượng cao, tấn công chiều cao là sự thật.
Vậy làm thế nào để có được một chiều cao của mã hóa thần kinh? Số lượng lớn các neuron quang học là vô dụng. Bởi vì chúng ta đã học đại số tuyến tính, chúng ta biết rằng nếu chúng ta có một số lượng lớn các neuron N, và mỗi neuron chỉ có độ phóng điện liên quan đến K đặc điểm quan trọng tuyến tính, sau đó chúng ta cuối cùng biểu thị chiều chỉ là tương đương với các chiều của vấn đề chính nó, bạn N neuron không có tác dụng ((những neuron được thêm là sự kết hợp tuyến tính của các neuron K trước khi).
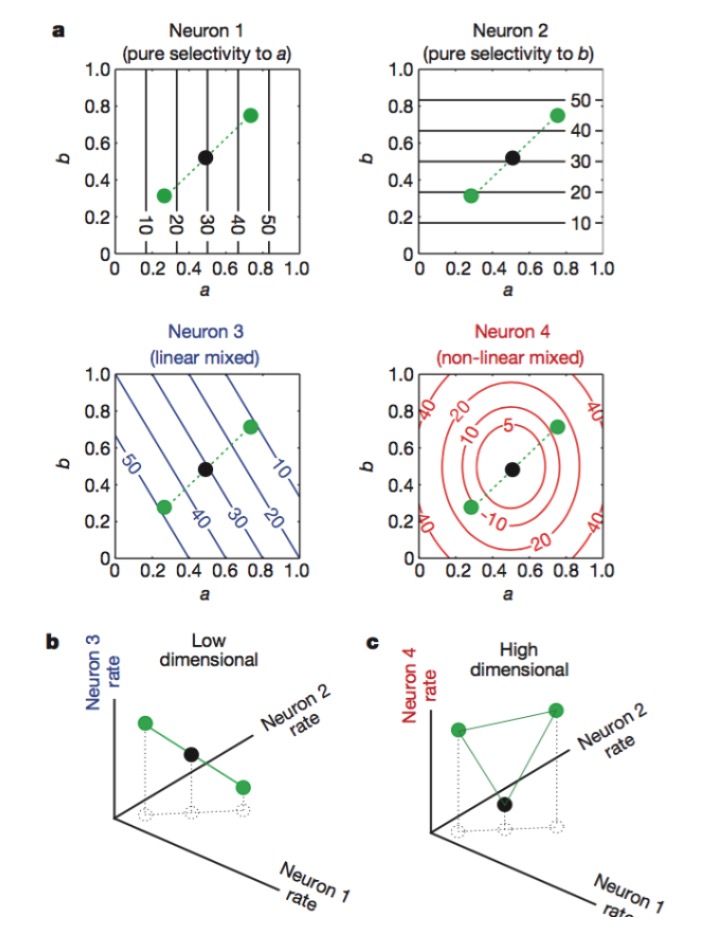
Hình 1: Neurons 1 và 2 chỉ nhạy cảm với đặc điểm a và b, 3 nhạy cảm với hỗn hợp tuyến tính của đặc điểm a và b, và 4 nhạy cảm với hỗn hợp không tuyến tính của đặc điểm. Cuối cùng, chỉ có sự kết hợp của neurons 1, 2, 4 làm cho kích thước mã hóa thần kinh tăng lên (hình dưới).
Các chức năng của mỗi tế bào thần kinh là khá cụ thể, chẳng hạn như các rods và cones của màng lưới thị giác chịu trách nhiệm nhận photon, và sau đó các tế bào Gangelion tiếp tục mã hóa, mỗi tế bào thần kinh giống như một lính canh được đào tạo chuyên nghiệp. Trong các khu vực cao cấp của não, sự phân biệt rõ ràng này là khó nhìn thấy, chúng tôi thấy rằng một tế bào thần kinh có thể nhạy cảm với nhiều đặc điểm, và điều này không phải là nhạy cảm.
Mỗi chi tiết của thiên nhiên đều chứa trong đó một nền tảng, một lượng lớn sự dư thừa và mã hóa hỗn hợp - một cách hành xử có vẻ không chuyên nghiệp, một tín hiệu có vẻ lộn xộn, và cuối cùng có khả năng tính toán tốt hơn. Với nguyên tắc này, chúng ta có thể dễ dàng xử lý một số nhiệm vụ như:
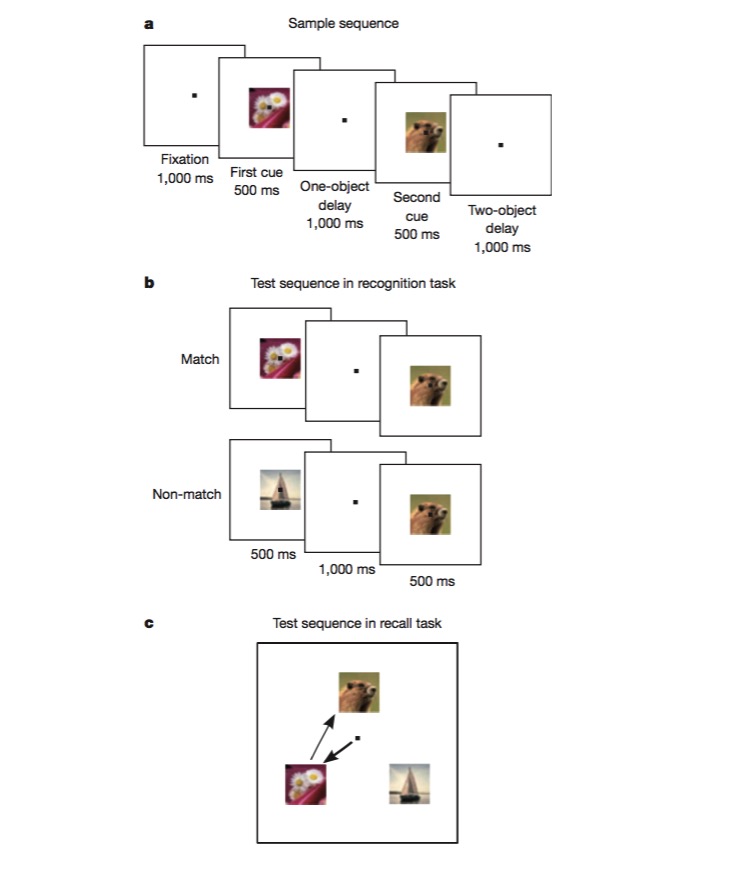
Trong nhiệm vụ này, con khỉ được huấn luyện để phân biệt một hình ảnh với hình ảnh trước đó, sau đó được huấn luyện để đánh giá thứ tự xuất hiện của hai hình ảnh khác nhau. Để hoàn thành nhiệm vụ này, con khỉ có thể mã hóa các khía cạnh khác nhau của nhiệm vụ, chẳng hạn như loại nhiệm vụ, loại hình ảnh, và đây là một thử nghiệm tuyệt vời để kiểm tra xem có cơ chế mã hóa không tuyến tính hỗn hợp hay không.
Sau khi đọc bài viết này, chúng ta đã biết rằng thiết kế mạng thần kinh có thể cải thiện khả năng nhận dạng mô hình nếu đưa vào một số đơn vị phi tuyến tính, và SVM đã áp dụng điều này để giải quyết các vấn đề phân loại phi tuyến tính.
Chúng ta nghiên cứu chức năng của các vùng não, xử lý dữ liệu bằng các phương pháp học máy, ví dụ như tìm ra các chiều quan trọng của vấn đề bằng PCA, sau đó hiểu được mã hóa thần kinh và giải mã bằng cách nhận dạng mô hình học máy, và cuối cùng chúng ta có thể cải thiện phương pháp học máy nếu chúng ta có được một số cảm hứng mới. Đối với não hoặc thuật toán học máy, điều quan trọng nhất cuối cùng là có được cách biểu thị thông tin phù hợp nhất, và có biểu thị tốt, mọi thứ dễ dàng hơn.
Hồ Chí Minh - Công nghệ tàu tuần dương