Mô hình yếu tố tiền tệ kỹ thuật số
Tác giả:FMZ~Lydia, Tạo: 2022-10-24 17:37:50, Cập nhật: 2023-09-15 20:59:38
Khung mô hình yếu tố
Các báo cáo nghiên cứu về mô hình đa yếu tố của thị trường chứng khoán là lớn, với các lý thuyết và thực tiễn phong phú. Không có vấn đề số lượng tiền tệ, tổng giá trị thị trường, khối lượng giao dịch, thị trường phái sinh, v.v. trong thị trường tiền kỹ thuật số, chỉ cần thực hiện nghiên cứu nhân tố là đủ. Bài báo này chủ yếu dành cho những người mới bắt đầu các chiến lược định lượng, và sẽ không liên quan đến các nguyên tắc toán học phức tạp và phân tích thống kê. Nó sẽ sử dụng thị trường tương lai vĩnh cửu Binance làm nguồn dữ liệu để xây dựng một khuôn khổ đơn giản cho nghiên cứu nhân tố, thuận tiện để đánh giá các chỉ số nhân tố.
Các yếu tố có thể được coi là một chỉ số và một biểu thức có thể được viết. Các yếu tố thay đổi liên tục, phản ánh thông tin thu nhập trong tương lai. Nói chung, các yếu tố đại diện cho một logic đầu tư.
Ví dụ, giả định đằng sau yếu tố giá đóng cửa là giá cổ phiếu có thể dự đoán lợi nhuận trong tương lai, và giá cổ phiếu càng cao, lợi nhuận trong tương lai sẽ càng cao (hoặc có thể thấp hơn). Trên thực tế, xây dựng danh mục đầu tư dựa trên yếu tố này là một mô hình / chiến lược đầu tư để mua cổ phiếu có giá cao trong một vòng thường xuyên. Nói chung, các yếu tố có thể liên tục tạo ra lợi nhuận dư thừa cũng được gọi là Alpha. Ví dụ, yếu tố giá trị thị trường và yếu tố động lực đã được các học giả và cộng đồng đầu tư xác minh là những yếu tố hiệu quả.
Cả thị trường chứng khoán và thị trường tiền kỹ thuật số đều là các hệ thống phức tạp. Không có yếu tố nào có thể dự đoán hoàn toàn lợi nhuận trong tương lai, nhưng chúng vẫn có một mức độ dự đoán nhất định. Alpha hiệu quả (cách đầu tư) sẽ dần dần trở nên vô hiệu với nhiều đầu tư hơn. Tuy nhiên, quá trình này sẽ tạo ra các mô hình khác trên thị trường, do đó sinh ra một alpha mới. Nhân tố giá trị thị trường đã từng là một chiến lược rất hiệu quả trong thị trường cổ phiếu A. Chỉ cần mua 10 cổ phiếu có giá trị thị trường thấp nhất, và điều chỉnh chúng một lần mỗi ngày. Kể từ năm 2007, 10 năm trở lại sẽ mang lại hơn 400 lần lợi nhuận, vượt xa thị trường tổng thể. Tuy nhiên, thị trường chứng khoán ngựa trắng năm 2017 phản ánh sự thất bại của nhân tố giá trị thị trường nhỏ, và nhân tố giá trị đã trở nên phổ biến thay vào đó. Do đó, chúng ta cần liên tục kiểm tra và cố gắng sử dụng alpha.
Các yếu tố tìm kiếm là cơ sở để thiết lập các chiến lược. Một chiến lược tốt hơn có thể được xây dựng bằng cách kết hợp nhiều yếu tố hiệu quả không liên quan.
import requests
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests, zipfile, io
%matplotlib inline
Nguồn dữ liệu
Cho đến nay, dữ liệu đường K hàng giờ của tương lai vĩnh cửu Binance USDT từ đầu năm 2022 cho đến nay đã vượt quá 150 loại tiền tệ. Như chúng tôi đã đề cập trước đây, mô hình yếu tố là một mô hình lựa chọn tiền tệ, hướng đến tất cả các loại tiền tệ chứ không phải một loại tiền tệ nhất định. Dữ liệu đường K bao gồm mở giá cao và đóng giá thấp, khối lượng giao dịch, số lượng giao dịch, khối lượng mua người mua và các dữ liệu khác. Dữ liệu này chắc chắn không phải là nguồn của tất cả các yếu tố, chẳng hạn như chỉ số chứng khoán Mỹ, kỳ vọng tăng lãi suất, lợi nhuận, dữ liệu trên chuỗi, phổ biến trên phương tiện truyền thông xã hội và vân vân.
## Current trading pair
Info = requests.get('https://fapi.binance.com/fapi/v1/exchangeInfo')
symbols = [s['symbol'] for s in Info.json()['symbols']]
symbols = list(filter(lambda x: x[-4:] == 'USDT', [s.split('_')[0] for s in symbols]))
print(symbols)
Ra ngoài:
['BTCUSDT', 'ETHUSDT', 'BCHUSDT', 'XRPUSDT', 'EOSUSDT', 'LTCUSDT', 'TRXUSDT', 'ETCUSDT', 'LINKUSDT',
'XLMUSDT', 'ADAUSDT', 'XMRUSDT', 'DASHUSDT', 'ZECUSDT', 'XTZUSDT', 'BNBUSDT', 'ATOMUSDT', 'ONTUSDT',
'IOTAUSDT', 'BATUSDT', 'VETUSDT', 'NEOUSDT', 'QTUMUSDT', 'IOSTUSDT', 'THETAUSDT', 'ALGOUSDT', 'ZILUSDT',
'KNCUSDT', 'ZRXUSDT', 'COMPUSDT', 'OMGUSDT', 'DOGEUSDT', 'SXPUSDT', 'KAVAUSDT', 'BANDUSDT', 'RLCUSDT',
'WAVESUSDT', 'MKRUSDT', 'SNXUSDT', 'DOTUSDT', 'DEFIUSDT', 'YFIUSDT', 'BALUSDT', 'CRVUSDT', 'TRBUSDT',
'RUNEUSDT', 'SUSHIUSDT', 'SRMUSDT', 'EGLDUSDT', 'SOLUSDT', 'ICXUSDT', 'STORJUSDT', 'BLZUSDT', 'UNIUSDT',
'AVAXUSDT', 'FTMUSDT', 'HNTUSDT', 'ENJUSDT', 'FLMUSDT', 'TOMOUSDT', 'RENUSDT', 'KSMUSDT', 'NEARUSDT',
'AAVEUSDT', 'FILUSDT', 'RSRUSDT', 'LRCUSDT', 'MATICUSDT', 'OCEANUSDT', 'CVCUSDT', 'BELUSDT', 'CTKUSDT',
'AXSUSDT', 'ALPHAUSDT', 'ZENUSDT', 'SKLUSDT', 'GRTUSDT', '1INCHUSDT', 'CHZUSDT', 'SANDUSDT', 'ANKRUSDT',
'BTSUSDT', 'LITUSDT', 'UNFIUSDT', 'REEFUSDT', 'RVNUSDT', 'SFPUSDT', 'XEMUSDT', 'BTCSTUSDT', 'COTIUSDT',
'CHRUSDT', 'MANAUSDT', 'ALICEUSDT', 'HBARUSDT', 'ONEUSDT', 'LINAUSDT', 'STMXUSDT', 'DENTUSDT', 'CELRUSDT',
'HOTUSDT', 'MTLUSDT', 'OGNUSDT', 'NKNUSDT', 'SCUSDT', 'DGBUSDT', '1000SHIBUSDT', 'ICPUSDT', 'BAKEUSDT',
'GTCUSDT', 'BTCDOMUSDT', 'TLMUSDT', 'IOTXUSDT', 'AUDIOUSDT', 'RAYUSDT', 'C98USDT', 'MASKUSDT', 'ATAUSDT',
'DYDXUSDT', '1000XECUSDT', 'GALAUSDT', 'CELOUSDT', 'ARUSDT', 'KLAYUSDT', 'ARPAUSDT', 'CTSIUSDT', 'LPTUSDT',
'ENSUSDT', 'PEOPLEUSDT', 'ANTUSDT', 'ROSEUSDT', 'DUSKUSDT', 'FLOWUSDT', 'IMXUSDT', 'API3USDT', 'GMTUSDT',
'APEUSDT', 'BNXUSDT', 'WOOUSDT', 'FTTUSDT', 'JASMYUSDT', 'DARUSDT', 'GALUSDT', 'OPUSDT', 'BTCUSDT',
'ETHUSDT', 'INJUSDT', 'STGUSDT', 'FOOTBALLUSDT', 'SPELLUSDT', '1000LUNCUSDT', 'LUNA2USDT', 'LDOUSDT',
'CVXUSDT']
print(len(symbols))
Ra ngoài:
153
#Function to obtain any period of K-line
def GetKlines(symbol='BTCUSDT',start='2020-8-10',end='2021-8-10',period='1h',base='fapi',v = 'v1'):
Klines = []
start_time = int(time.mktime(datetime.strptime(start, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000
end_time = min(int(time.mktime(datetime.strptime(end, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000,time.time()*1000)
intervel_map = {'m':60*1000,'h':60*60*1000,'d':24*60*60*1000}
while start_time < end_time:
mid_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
url = 'https://'+base+'.binance.com/'+base+'/'+v+'/klines?symbol=%s&interval=%s&startTime=%s&endTime=%s&limit=1000'%(symbol,period,start_time,mid_time)
res = requests.get(url)
res_list = res.json()
if type(res_list) == list and len(res_list) > 0:
start_time = res_list[-1][0]+int(period[:-1])*intervel_map[period[-1]]
Klines += res_list
if type(res_list) == list and len(res_list) == 0:
start_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
if mid_time >= end_time:
break
df = pd.DataFrame(Klines,columns=['time','open','high','low','close','amount','end_time','volume','count','buy_amount','buy_volume','null']).astype('float')
df.index = pd.to_datetime(df.time,unit='ms')
return df
start_date = '2022-1-1'
end_date = '2022-09-14'
period = '1h'
df_dict = {}
for symbol in symbols:
df_s = GetKlines(symbol=symbol,start=start_date,end=end_date,period=period,base='fapi',v='v1')
if not df_s.empty:
df_dict[symbol] = df_s
symbols = list(df_dict.keys())
print(df_s.columns)
Ra ngoài:
Index(['time', 'open', 'high', 'low', 'close', 'amount', 'end_time', 'volume',
'count', 'buy_amount', 'buy_volume', 'null'],
dtype='object')
Dữ liệu mà chúng tôi quan tâm: giá đóng cửa, giá mở cửa, khối lượng giao dịch, số lượng giao dịch và tỷ lệ mua người mua được chiết xuất từ dữ liệu đường K trước. Dựa trên dữ liệu này, các yếu tố cần thiết được xử lý.
df_close = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_open = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_volume = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_buy_ratio = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_count = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
for symbol in df_dict.keys():
df_s = df_dict[symbol]
df_close[symbol] = df_s.close
df_open[symbol] = df_s.open
df_volume[symbol] = df_s.volume
df_count[symbol] = df_s['count']
df_buy_ratio[symbol] = df_s.buy_amount/df_s.amount
df_close = df_close.dropna(how='all')
df_open = df_open.dropna(how='all')
df_volume = df_volume.dropna(how='all')
df_count = df_count.dropna(how='all')
df_buy_ratio = df_buy_ratio.dropna(how='all')
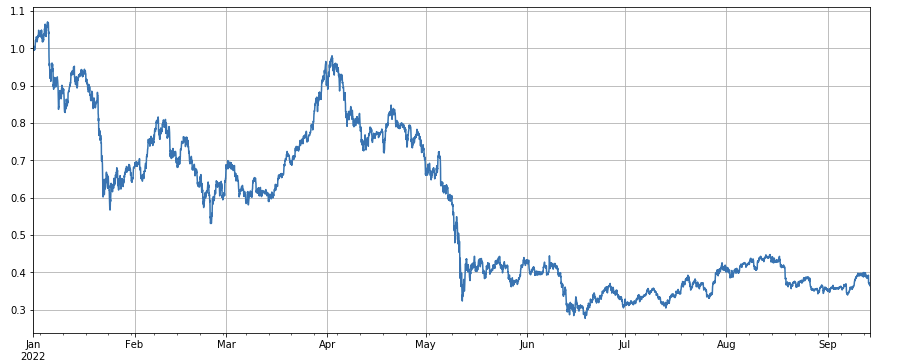
Các hoạt động tổng thể của chỉ số thị trường là ảm đạm, giảm 60% từ đầu năm đến những ngày gần đây.
df_norm = df_close/df_close.fillna(method='bfill').iloc[0] #normalization
df_norm.mean(axis=1).plot(figsize=(15,6),grid=True);
#Final index profit chart
Phán quyết giá trị yếu tố
-
Phương pháp hồi quy Lợi nhuận của giai đoạn sau là biến phụ thuộc, và yếu tố được kiểm tra là biến độc lập. hệ số thu được bằng hồi quy cũng là lợi nhuận của yếu tố. Sau khi phương trình hồi quy được xây dựng, tính hợp lệ và biến động của các yếu tố thường được xem xét dựa trên giá trị trung bình tuyệt đối của giá trị t của hệ số, tỷ lệ của chuỗi giá trị tuyệt đối của giá trị t của hệ số lớn hơn 2, lợi nhuận nhân tố hàng năm, biến động lợi nhuận nhân tố hàng năm và tỷ lệ Sharpe của lợi nhuận nhân tố. Nhiều yếu tố có thể được hồi quy cùng một lúc. Xin tham khảo tài liệu barra để biết chi tiết.
-
IC, IR và các chỉ số khác IC được gọi là hệ số tương quan giữa yếu tố và tỷ lệ lợi nhuận của giai đoạn tiếp theo. Bây giờ, RANK_ IC cũng được sử dụng chung, đó là hệ số tương quan giữa xếp hạng yếu tố và tỷ lệ lợi nhuận cổ phiếu tiếp theo. IR thường là giá trị trung bình của chuỗi IC / độ lệch chuẩn của chuỗi IC.
-
Phương pháp hồi quy phân tầng Trong bài viết này, chúng ta sẽ sử dụng phương pháp này, đó là sắp xếp các loại tiền tệ theo các yếu tố được kiểm tra, chia chúng thành các nhóm N để kiểm tra lại nhóm và sử dụng một khoảng thời gian cố định để điều chỉnh vị trí. Nếu tình hình lý tưởng, tỷ lệ lợi nhuận của các loại tiền tệ nhóm N sẽ hiển thị sự đơn điệu tốt, tăng hoặc giảm đơn điệu, và khoảng cách thu nhập của mỗi nhóm là lớn. Những yếu tố này được phản ánh trong sự phân biệt tốt. Nếu nhóm đầu tiên có lợi nhuận cao nhất và nhóm cuối cùng có lợi nhuận thấp nhất, sau đó đi dài trong nhóm đầu tiên và đi ngắn trong nhóm cuối cùng để có được lợi nhuận cuối cùng, đó là chỉ số tham chiếu của tỷ lệ Sharp.
Hoạt động backtest thực tế
Các đồng tiền được chọn được chia thành 3 nhóm dựa trên thứ hạng các yếu tố từ nhỏ nhất đến lớn nhất. Mỗi nhóm tiền tệ chiếm khoảng 1/3 tổng số. Nếu một yếu tố hiệu quả, số điểm trong mỗi nhóm càng nhỏ, tỷ lệ lợi nhuận sẽ càng cao, nhưng điều này cũng có nghĩa là mỗi loại tiền tệ có tương đối nhiều quỹ được phân bổ. Nếu các vị trí dài và ngắn là đòn bẩy kép tương ứng, và nhóm đầu tiên và nhóm cuối cùng là 10 loại tiền tệ tương ứng, thì một loại tiền tệ chiếm 10% tổng số. Nếu một loại tiền tệ được bán ngắn được tăng gấp đôi, thì 20% được rút; Nếu số lượng nhóm là 50, thì 4% sẽ được rút. Các loại tiền tệ đa dạng có thể làm giảm nguy cơ thiên nga đen. Đi dài nhóm đầu tiên (tỷ số giá trị tối thiểu), đi nhóm thứ ba.
Nói chung, khả năng dự đoán yếu tố có thể được đánh giá theo tỷ lệ trả về và tỷ lệ Sharpe của backtest cuối cùng. Ngoài ra, nó cũng cần phải đề cập đến việc biểu thức yếu tố có đơn giản, nhạy cảm với kích thước của nhóm, nhạy cảm với khoảng điều chỉnh vị trí và nhạy cảm với thời gian ban đầu của backtest.
Đối với tần suất điều chỉnh vị trí, thị trường chứng khoán thường có khoảng thời gian 5 ngày, 10 ngày và một tháng. Tuy nhiên, đối với thị trường tiền kỹ thuật số, khoảng thời gian như vậy chắc chắn là quá dài, và thị trường trong bot thực được theo dõi theo thời gian thực. Không cần phải gắn bó với một khoảng thời gian cụ thể để điều chỉnh lại vị trí. Do đó, trong bot thực, chúng tôi điều chỉnh vị trí theo thời gian thực hoặc trong một khoảng thời gian ngắn.
Theo phương pháp truyền thống, vị trí có thể được đóng nếu nó không nằm trong nhóm khi sắp xếp lần sau. Tuy nhiên, trong trường hợp điều chỉnh vị trí thời gian thực, một số loại tiền có thể chỉ ở biên giới, có thể dẫn đến việc đóng vị trí đi lại. Do đó, chiến lược này áp dụng phương pháp chờ thay đổi nhóm, và sau đó đóng vị trí khi vị trí theo hướng ngược lại cần phải được mở. Ví dụ, nhóm đầu tiên đi dài. Khi các loại tiền trong trạng thái vị trí dài được chia thành nhóm thứ ba, sau đó đóng vị trí và đi ngắn. Nếu vị trí được đóng trong một khoảng thời gian cố định, chẳng hạn như mỗi ngày hoặc mỗi 8 giờ, bạn cũng có thể đóng vị trí mà không cần phải ở trong nhóm. Hãy thử càng nhiều càng tốt.
#Backtest engine
class Exchange:
def __init__(self, trade_symbols, fee=0.0004, initial_balance=10000):
self.initial_balance = initial_balance #Initial assets
self.fee = fee
self.trade_symbols = trade_symbols
self.account = {'USDT':{'realised_profit':0, 'unrealised_profit':0, 'total':initial_balance, 'fee':0, 'leverage':0, 'hold':0}}
for symbol in trade_symbols:
self.account[symbol] = {'amount':0, 'hold_price':0, 'value':0, 'price':0, 'realised_profit':0,'unrealised_profit':0,'fee':0}
def Trade(self, symbol, direction, price, amount):
cover_amount = 0 if direction*self.account[symbol]['amount'] >=0 else min(abs(self.account[symbol]['amount']), amount)
open_amount = amount - cover_amount
self.account['USDT']['realised_profit'] -= price*amount*self.fee #Net of fees
self.account['USDT']['fee'] += price*amount*self.fee
self.account[symbol]['fee'] += price*amount*self.fee
if cover_amount > 0: #Close position first
self.account['USDT']['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount #Profits
self.account[symbol]['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount
self.account[symbol]['amount'] -= -direction*cover_amount
self.account[symbol]['hold_price'] = 0 if self.account[symbol]['amount'] == 0 else self.account[symbol]['hold_price']
if open_amount > 0:
total_cost = self.account[symbol]['hold_price']*direction*self.account[symbol]['amount'] + price*open_amount
total_amount = direction*self.account[symbol]['amount']+open_amount
self.account[symbol]['hold_price'] = total_cost/total_amount
self.account[symbol]['amount'] += direction*open_amount
def Buy(self, symbol, price, amount):
self.Trade(symbol, 1, price, amount)
def Sell(self, symbol, price, amount):
self.Trade(symbol, -1, price, amount)
def Update(self, close_price): #Update assets
self.account['USDT']['unrealised_profit'] = 0
self.account['USDT']['hold'] = 0
for symbol in self.trade_symbols:
if not np.isnan(close_price[symbol]):
self.account[symbol]['unrealised_profit'] = (close_price[symbol] - self.account[symbol]['hold_price'])*self.account[symbol]['amount']
self.account[symbol]['price'] = close_price[symbol]
self.account[symbol]['value'] = abs(self.account[symbol]['amount'])*close_price[symbol]
self.account['USDT']['hold'] += self.account[symbol]['value']
self.account['USDT']['unrealised_profit'] += self.account[symbol]['unrealised_profit']
self.account['USDT']['total'] = round(self.account['USDT']['realised_profit'] + self.initial_balance + self.account['USDT']['unrealised_profit'],6)
self.account['USDT']['leverage'] = round(self.account['USDT']['hold']/self.account['USDT']['total'],3)
#Function of test factor
def Test(factor, symbols, period=1, N=40, value=300):
e = Exchange(symbols, fee=0.0002, initial_balance=10000)
res_list = []
index_list = []
factor = factor.dropna(how='all')
for idx, row in factor.iterrows():
if idx.hour % period == 0:
buy_symbols = row.sort_values().dropna()[0:N].index
sell_symbols = row.sort_values().dropna()[-N:].index
prices = df_close.loc[idx,]
index_list.append(idx)
for symbol in symbols:
if symbol in buy_symbols and e.account[symbol]['amount'] <= 0:
e.Buy(symbol,prices[symbol],value/prices[symbol]-e.account[symbol]['amount'])
if symbol in sell_symbols and e.account[symbol]['amount'] >= 0:
e.Sell(symbol,prices[symbol], value/prices[symbol]+e.account[symbol]['amount'])
e.Update(prices)
res_list.append([e.account['USDT']['total'],e.account['USDT']['hold']])
return pd.DataFrame(data=res_list, columns=['total','hold'],index = index_list)
Xét nghiệm nhân đơn giản
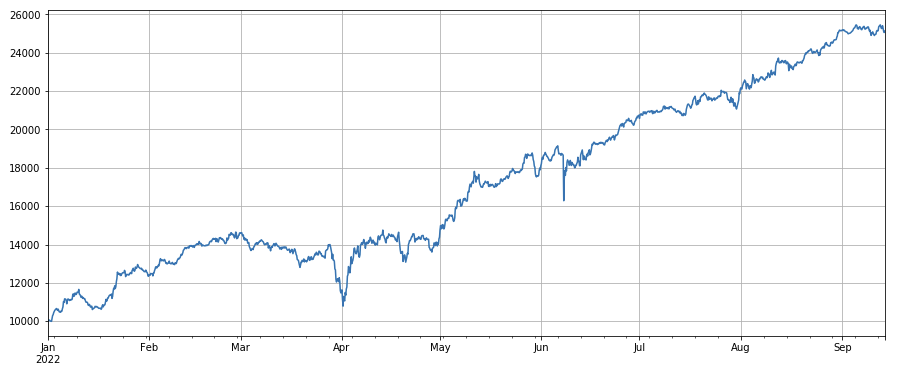
Nhân tố khối lượng giao dịch: Các loại tiền tệ dài đơn giản với khối lượng giao dịch thấp và các loại tiền tệ ngắn với khối lượng giao dịch cao, hoạt động rất tốt, cho thấy các loại tiền tệ phổ biến có xu hướng giảm.
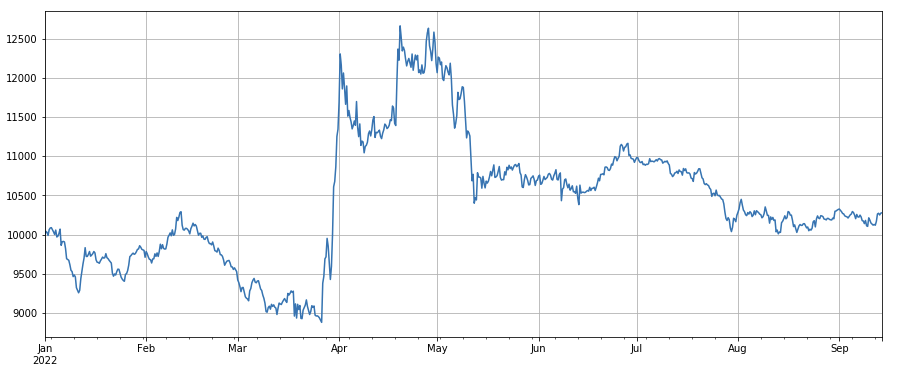
Yếu tố giá giao dịch: ảnh hưởng của các loại tiền tệ dài với giá thấp và các loại tiền tệ ngắn với giá cao đều bình thường.
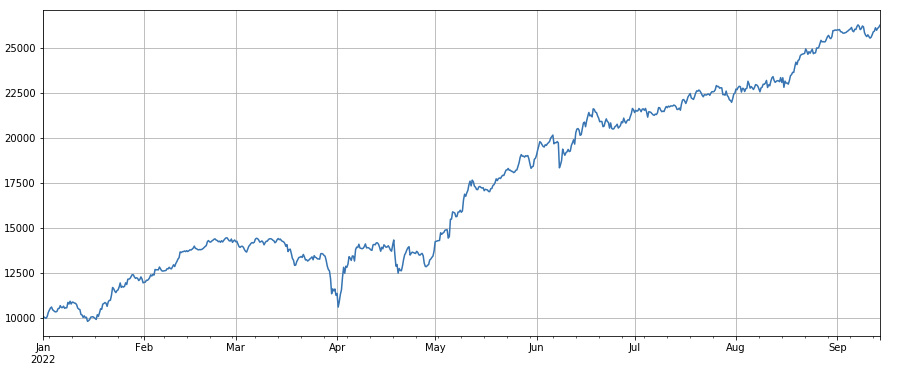
Nhân tố số giao dịch: Hiệu suất rất giống với khối lượng giao dịch. Rõ ràng là mối tương quan giữa nhân tố khối lượng giao dịch và nhân tố số giao dịch rất cao. Trên thực tế, mối tương quan trung bình giữa chúng trong các loại tiền tệ khác nhau đã đạt 0,97, cho thấy hai yếu tố rất giống nhau. Nhân tố này cần phải được tính đến khi tổng hợp nhiều yếu tố.
3h động lực nhân: (df_close - df_close. shift (3)) /df_ close. shift(3). Đó là, sự gia tăng 3 giờ của nhân tố. Các kết quả backtest cho thấy rằng sự gia tăng 3 giờ có đặc điểm hồi quy rõ ràng, tức là, sự gia tăng dễ dàng giảm sau đó. Hiệu suất tổng thể là OK, nhưng cũng có một khoảng thời gian kéo dài rút và dao động.
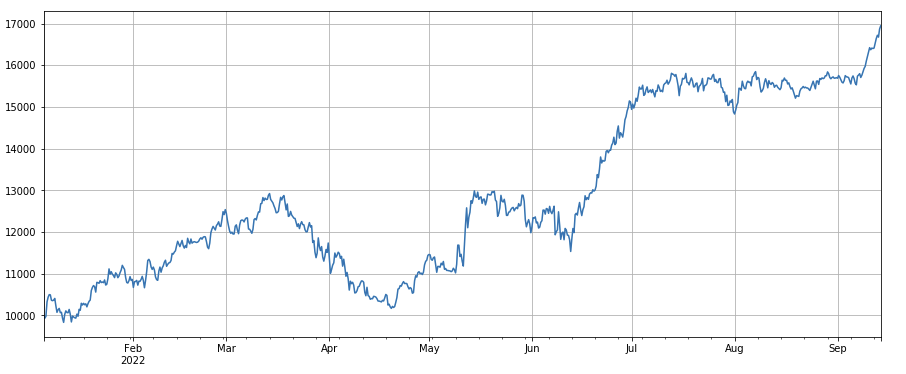
Nhân tố động lượng 24h: kết quả của thời gian điều chỉnh vị trí 24h là tốt, lợi nhuận tương tự như động lượng 3h và rút lại nhỏ hơn.
Nhân tố thay đổi khối lượng giao dịch: df_ volume.rolling ((24).mean() /df_ volume. rolling (96). mean(), tức là tỷ lệ khối lượng giao dịch trong ngày cuối cùng với khối lượng giao dịch trong ba ngày qua. Vị trí được điều chỉnh mỗi 8h. Kết quả của backtesting là tốt, và thu hồi cũng tương đối thấp, cho thấy những người có khối lượng giao dịch hoạt động có xu hướng giảm hơn.
Nhân tố thay đổi số giao dịch: df_ count.rolling ((24).mean() /df_ count.rolling ((96). trung bình (), tức là tỷ lệ số giao dịch trong ngày cuối cùng với số giao dịch trong ba ngày qua. Vị trí được điều chỉnh mỗi 8h. Kết quả của backtesting là tốt, và rút tiền cũng tương đối thấp, cho thấy những người có khối lượng giao dịch hoạt động có xu hướng giảm hơn.
Nhân tố thay đổi giá trị giao dịch đơn: - ((df_volume.rolling(24).mean()/df_count.rolling(24.mean())/(df_volume.rolling(24.mean()/df_count.rolling(96.mean()) , tức là tỷ lệ giá trị giao dịch của ngày cuối cùng với giá trị giao dịch của ba ngày qua, và vị trí sẽ được điều chỉnh mỗi 8h.
Tỷ lệ thay đổi của người mua theo tỷ lệ giao dịch: df_buy_ratio.rolling ((24).mean() /df_buy_ratio.rolling ((96).mean(), tức là tỷ lệ của người mua theo khối lượng đối với tổng khối lượng giao dịch trong ngày cuối cùng đối với giá trị giao dịch trong ba ngày qua, và vị trí sẽ được điều chỉnh mỗi 8 giờ.
Nhân tố biến động: (df_close/df_open).rolling ((24).std ((), đi dài tiền tệ với biến động thấp, nó có một hiệu ứng nhất định.
Nhân tố tương quan giữa khối lượng giao dịch và giá đóng cửa: df_close.rolling ((96).corr ((df_volume), giá đóng cửa trong bốn ngày qua có nhân tố tương quan với khối lượng giao dịch, hoạt động tổng thể tốt.
Các yếu tố được liệt kê ở đây dựa trên khối lượng giá. Trên thực tế, sự kết hợp của công thức yếu tố có thể rất phức tạp mà không có logic rõ ràng. Bạn có thể tham khảo phương pháp xây dựng yếu tố nổi tiếng ALPHA101:https://github.com/STHSF/alpha101.
#transaction volume
factor_volume = df_volume
factor_volume_res = Test(factor_volume, symbols, period=4)
factor_volume_res.total.plot(figsize=(15,6),grid=True);
#transaction price
factor_close = df_close
factor_close_res = Test(factor_close, symbols, period=8)
factor_close_res.total.plot(figsize=(15,6),grid=True);
#transaction count
factor_count = df_count
factor_count_res = Test(factor_count, symbols, period=8)
factor_count_res.total.plot(figsize=(15,6),grid=True);
print(df_count.corrwith(df_volume).mean())
0.9671246744996017
#3h momentum factor
factor_1 = (df_close - df_close.shift(3))/df_close.shift(3)
factor_1_res = Test(factor_1,symbols,period=1)
factor_1_res.total.plot(figsize=(15,6),grid=True);
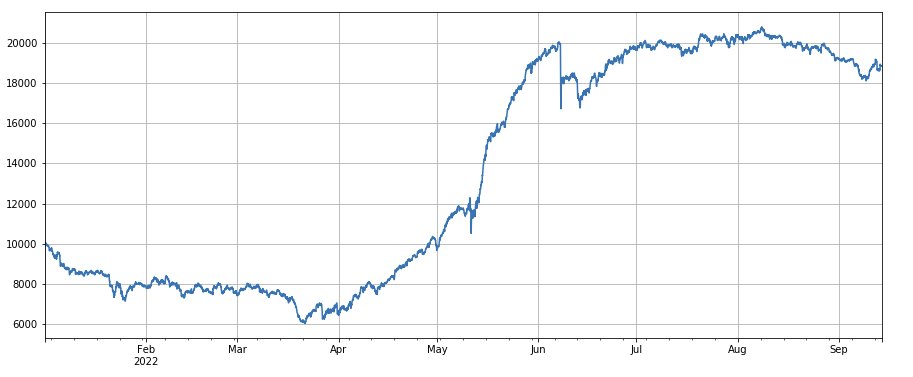
#24h momentum factor
factor_2 = (df_close - df_close.shift(24))/df_close.shift(24)
factor_2_res = Test(factor_2,symbols,period=24)
tamenxuanfactor_2_res.total.plot(figsize=(15,6),grid=True);
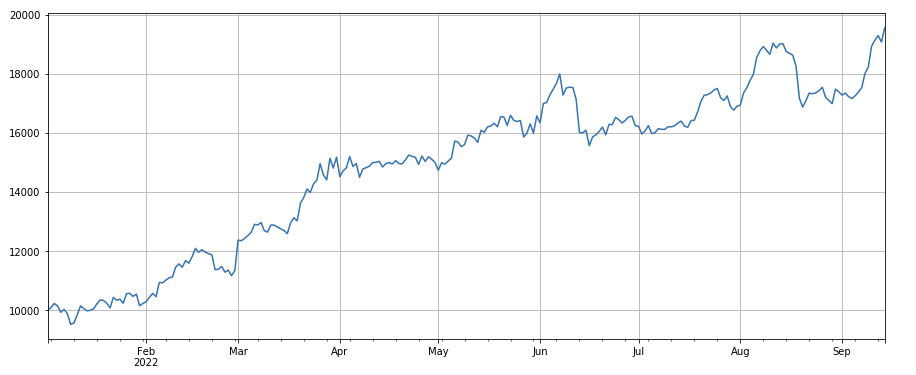
#factor of transaction volume
factor_3 = df_volume.rolling(24).mean()/df_volume.rolling(96).mean()
factor_3_res = Test(factor_3, symbols, period=8)
factor_3_res.total.plot(figsize=(15,6),grid=True);
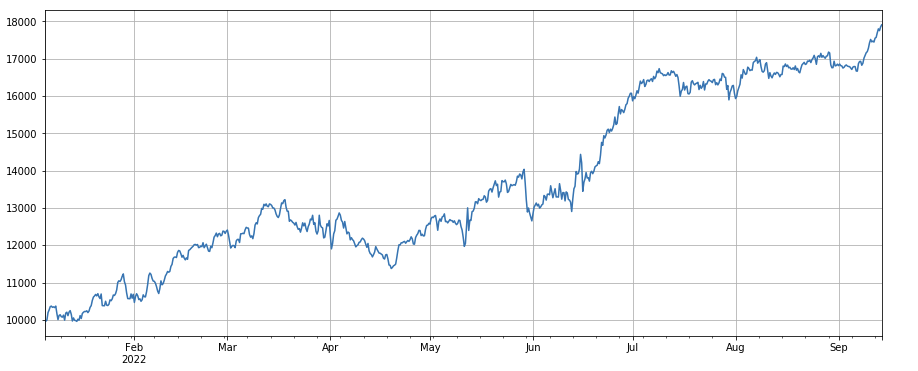
#factor of transaction number
factor_4 = df_count.rolling(24).mean()/df_count.rolling(96).mean()
factor_4_res = Test(factor_4, symbols, period=8)
factor_4_res.total.plot(figsize=(15,6),grid=True);
#factor correlation
print(factor_4.corrwith(factor_3).mean())
0.9707239580854841
#single transaction value factor
factor_5 = -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean())
factor_5_res = Test(factor_5, symbols, period=8)
factor_5_res.total.plot(figsize=(15,6),grid=True);
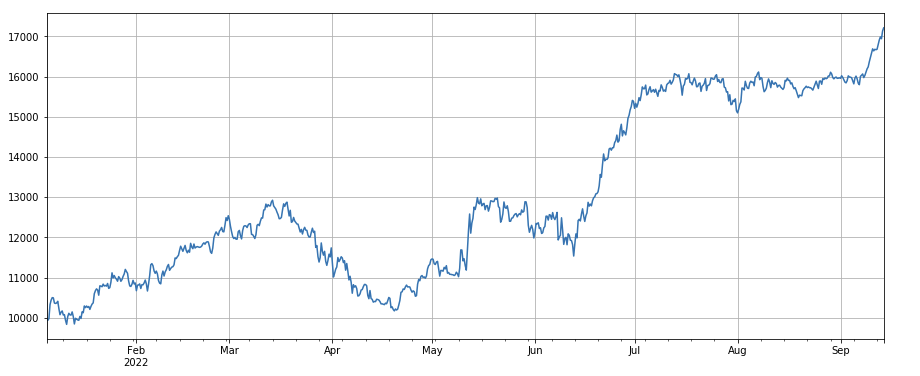
print(factor_4.corrwith(factor_5).mean())
0.861206620552479
#proportion factor of taker by transaction
factor_6 = df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean()
factor_6_res = Test(factor_6, symbols, period=4)
factor_6_res.total.plot(figsize=(15,6),grid=True);
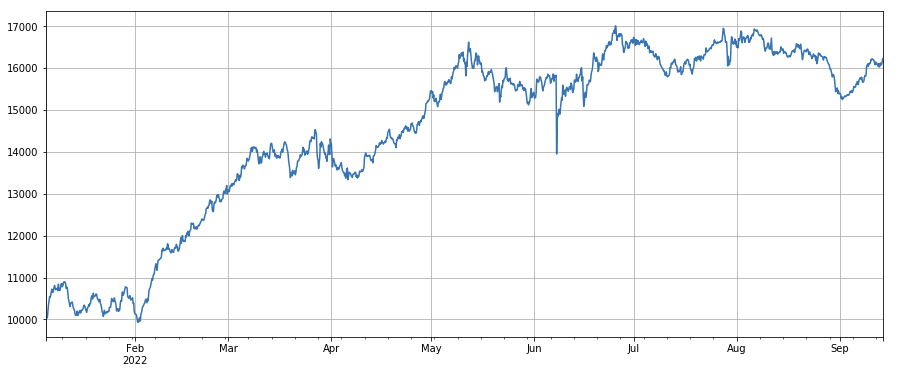
print(factor_3.corrwith(factor_6).mean())
0.1534572192503726
#volatility factor
factor_7 = (df_close/df_open).rolling(24).std()
factor_7_res = Test(factor_7, symbols, period=2)
factor_7_res.total.plot(figsize=(15,6),grid=True);
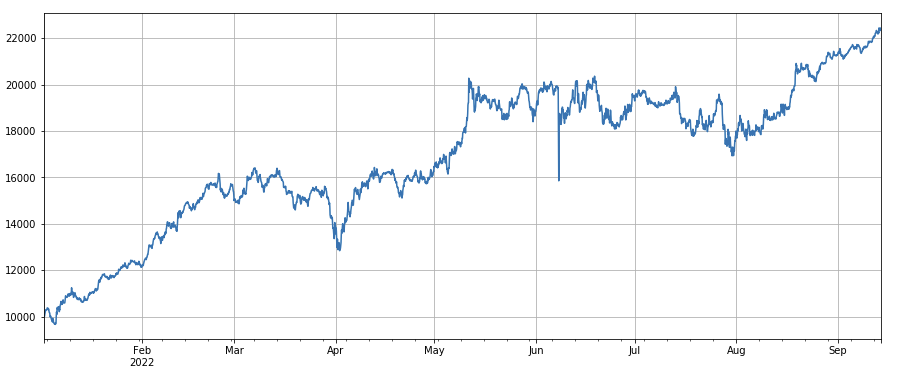
#correlation factor between transaction volume and closing price
factor_8 = df_close.rolling(96).corr(df_volume)
factor_8_res = Test(factor_8, symbols, period=4)
factor_8_res.total.plot(figsize=(15,6),grid=True);
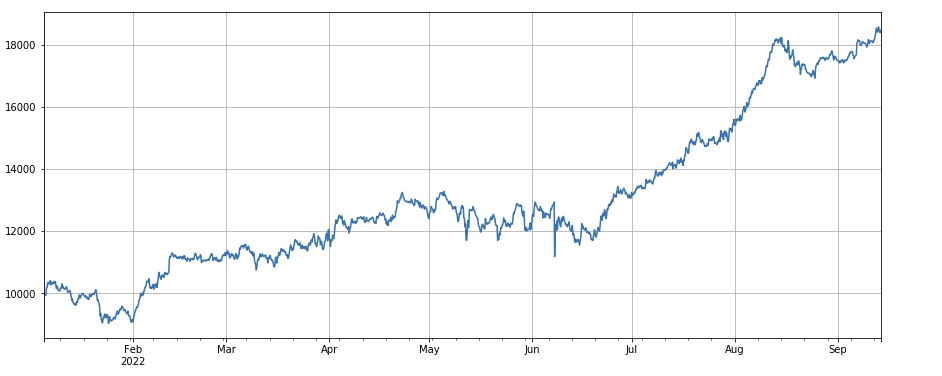
Tổng hợp đa yếu tố
Nó chắc chắn là phần quan trọng nhất của quá trình xây dựng chiến lược để khám phá các yếu tố hiệu quả mới liên tục, nhưng không có một phương pháp tổng hợp yếu tố tốt, một yếu tố alpha duy nhất xuất sắc không thể đóng vai trò tối đa của nó.
Phương pháp cân bằng: tất cả các yếu tố được tổng hợp được cộng với trọng lượng bằng nhau để có được các yếu tố mới sau khi tổng hợp.
Phương pháp cân nhắc tỷ lệ lợi nhuận yếu tố lịch sử: tất cả các yếu tố được kết hợp được thêm theo trung bình toán học của tỷ lệ lợi nhuận yếu tố lịch sử trong giai đoạn gần đây nhất như trọng lượng để có được một yếu tố mới sau khi tổng hợp.
Phương pháp cân nhắc IC_IR tối đa hóa: giá trị IC trung bình của yếu tố tổng hợp trong một khoảng thời gian trong lịch sử được sử dụng như là ước tính giá trị IC của yếu tố tổng hợp trong giai đoạn tiếp theo, và ma trận covariance của giá trị IC lịch sử được sử dụng như là ước tính sự biến động của yếu tố tổng hợp trong giai đoạn tiếp theo. Theo IC_ IR bằng giá trị dự kiến của IC chia cho độ lệch chuẩn của IC để có được giải pháp trọng lượng tối ưu của yếu tố tổng hợp tối đa IC_ IR.
Phân tích thành phần chính (PCA): PCA là một phương pháp phổ biến để giảm kích thước dữ liệu và mối tương quan giữa các yếu tố có thể cao.
Bài viết này sẽ tham chiếu việc gán giá trị nhân theo cách thủ công.ae933a8c-5a94-4d92-8f33-d92b70c36119.pdf
Khi kiểm tra các yếu tố đơn, sắp xếp được cố định, nhưng tổng hợp đa yếu tố cần kết hợp các dữ liệu hoàn toàn khác nhau, vì vậy tất cả các yếu tố cần được tiêu chuẩn hóa, và giá trị cực và giá trị bị thiếu cần phải được loại bỏ nói chung.
#standardize functions, remove missing values and extreme values, and standardize
def norm_factor(factor):
factor = factor.dropna(how='all')
factor_clip = factor.apply(lambda x:x.clip(x.quantile(0.2), x.quantile(0.8)),axis=1)
factor_norm = factor_clip.add(-factor_clip.mean(axis=1),axis ='index').div(factor_clip.std(axis=1),axis ='index')
return factor_norm
df_volume_norm = norm_factor(df_volume)
factor_1_norm = norm_factor(factor_1)
factor_6_norm = norm_factor(factor_6)
factor_7_norm = norm_factor(factor_7)
factor_8_norm = norm_factor(factor_8)
factor_total = 0.6*df_volume_norm + 0.4*factor_1_norm + 0.2*factor_6_norm + 0.3*factor_7_norm + 0.4*factor_8_norm
factor_total_res = Test(factor_total, symbols, period=8)
factor_total_res.total.plot(figsize=(15,6),grid=True);
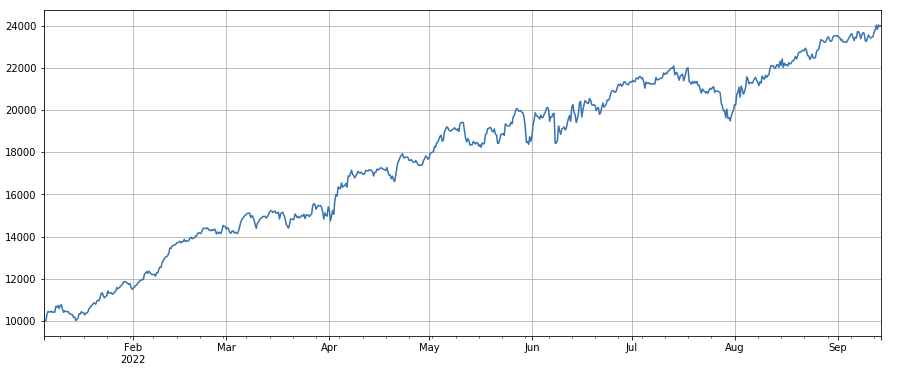
Tóm lại
Bài viết này giới thiệu phương pháp thử nghiệm của yếu tố đơn và kiểm tra các yếu tố đơn phổ biến, và ban đầu giới thiệu phương pháp tổng hợp đa yếu tố. Tuy nhiên, có nhiều nội dung nghiên cứu của đa yếu tố. Mỗi điểm được đề cập trong bài báo có thể được phát triển thêm. Đây là một cách khả thi để biến nghiên cứu về các chiến lược khác nhau thành việc khám phá yếu tố alpha. Việc sử dụng phương pháp yếu tố có thể tăng tốc độ xác minh các ý tưởng giao dịch và có nhiều tài liệu tham khảo.
Robot thực sự từ:https://www.fmz.com/robot/486605
- DEX giao dịch định lượng thực hành ((1) -- dYdX v4 hướng dẫn sử dụng
- Giới thiệu về bộ phận Lead-Lag trong tiền kỹ thuật số (3)
- Giới thiệu về Trọng tài Lead-Lag trong Cryptocurrency (2)
- Giới thiệu về bộ phận Lead-Lag trong tiền kỹ thuật số (2)
- Thảo luận về tiếp nhận tín hiệu bên ngoài của nền tảng FMZ: Một giải pháp hoàn chỉnh để tiếp nhận tín hiệu với dịch vụ Http tích hợp trong chiến lược
- Phân tích nhận tín hiệu bên ngoài nền tảng FMZ: Chiến lược xây dựng dịch vụ HTTP để nhận tín hiệu
- Giới thiệu về Trọng tài Lead-Lag trong Cryptocurrency (1)
- Giới thiệu về bộ phận Lead-Lag trong tiền kỹ thuật số (1)
- Cuộc thảo luận về tiếp nhận tín hiệu bên ngoài của nền tảng FMZ: API mở rộng VS Chiến lược Dịch vụ HTTP tích hợp
- Phân tích nhận tín hiệu bên ngoài nền tảng FMZ: API mở rộng vs chiến lược dịch vụ HTTP tích hợp
- Cuộc thảo luận về phương pháp thử nghiệm chiến lược dựa trên Random Ticker Generator
- Khám phá thiết kế chiến lược tần số cao từ sự thay đổi ma thuật của LeeksReaper
- Phân tích chiến lược của LeeksReaper (2)
- "Chiến lược EMA hai lần ma thuật" từ các cựu chiến binh YouTube
- Thực hiện ngôn ngữ JavaScript của các chỉ số Fisher và vẽ trên FMZ
- Ví dụ về thiết kế chiến lược dYdX
- Thiết kế hệ thống quản lý đồng bộ hóa đơn hàng dựa trên FMZ Quant (1)
- Phân tích chiến lược của LeeksReaper (1)
- Định nghĩa của các khoản đầu tư khác
- Tình trạng gần đây và hoạt động khuyến nghị của chiến lược tỷ lệ tài trợ
- Xem xét thị trường tiền kỹ thuật số năm 2021 và chiến lược đơn giản nhất 10 lần bỏ lỡ
- Từ YouTube: "Chiến lược đường thẳng EMA đôi kỳ diệu"
- Viết một công cụ giao dịch bán tự động bằng ngôn ngữ Pine
- Mô hình nhân tố tiền kỹ thuật số
- Hãy là người cứu rỗi của chính mình trong giao dịch.
- Chiến lược phòng ngừa rủi ro của hợp đồng tương lai và điểm tiền điện tử thủ công
- Thiết kế chiến lược phòng ngừa rủi ro giao ngay tiền điện tử ((1)
- Một chiến lược cân bằng vĩnh cửu phù hợp với thị trường gấu đáy
- Giao dịch số lượng tiền điện tử cho người mới bắt đầu - đưa bạn đến gần số lượng tiền điện tử (8)
- Giao dịch số lượng tiền điện tử cho người mới bắt đầu - đưa bạn đến gần số lượng tiền điện tử (7)
- Giao dịch số lượng tiền điện tử cho người mới bắt đầu - đưa bạn đến gần số lượng tiền điện tử (6)