Dạy bạn viết các chiến lược -- cấy ghép một chiến lược MyLanguage (Tiến bộ)
Tác giả:FMZ~Lydia, Tạo: 2022-12-26 18:56:00, Cập nhật: 2024-12-15 16:38:42
Dạy bạn viết các chiến lược cấy ghép một chiến lược MyLanguage (Tiến bộ)
Trong bài trướcDạy bạn viết chiến lược -- cấy ghép một chiến lược MyLanguage, một chiến lược MyLanguage đơn giản đã được thử nghiệm để cấy ghép. Nếu đó là một MyLanguage phức tạp hơn, làm thế nào nó có thể được cấy ghép vào một chiến lược ngôn ngữ JavaScript? Có những kỹ năng nào?
Chúng ta hãy xem xét chiến lược được cấy ghép trước:
(*backtest
start: 2019-05-01 00:00:00
end: 2019-11-12 00:00:00
period: 1d
exchanges: [{"eid":"Futures_OKCoin","currency":"BTC_USD"}]
args: [["SlideTick",10,126961],["ContractType","quarter",126961]]
*)
N1:=10;
N2:=21;
AP:=(HIGH+LOW+CLOSE)/3;
ESA:=EMA(AP,N1);
D:=EMA(ABS(AP-ESA),N1);
CI:=(AP-ESA)/(0.015*D);
TCI:=EMA(CI,N2);
WT1:TCI;
WT2:SMA(WT1,4,1);
AA:=CROSS(WT1,WT2);
BB:=CROSSDOWN(WT1,WT2);
REF(AA,1),BPK;
REF(BB,1),SPK;
Các(* backtest... *)ở đầu của chiến lược MyLanguage là mã cấu hình cho cài đặt backtesting. Để tạo điều kiện so sánh, một cấu hình backtesting thống nhất được thiết lập. Chiến lược này cũng là một định dạng ngẫu nhiên, không quá phức tạp (thật phức tạp hơn trong bài viết trước). Đây là một chiến lược đại diện. Để cấy ghép một chiến lược MyLanguage, bạn nên nhìn vào toàn bộ chiến lược trước. Mã của chiến lược ngắn gọn, và bạn có thể có một sự hiểu biết nhất định về chiến lược tổng thể. Đối với chiến lược này, chúng tôi đã thấy rằng một số chức năng chỉ sốEMA, SMAđã được sử dụng:
Hãy xây một bánh xe trước.
-
EMA Các chức năng chỉ số, có sẵn các chức năng thư viện chỉ số sẵn có trực tiếp trong nền tảng FMZ khi viết các chiến lược trong ngôn ngữ JavaScript.
TA.MA. -
SMA Những gì chúng ta cần làm là
SMAchỉ số, mà chúng tôi tìm thấy trong thư viện TA của FMZ không hỗ trợ chức năng chỉ số SMA, và có sự khác biệt giữa chỉ số SMA trong thư viện talib và một trong MyLanguage.
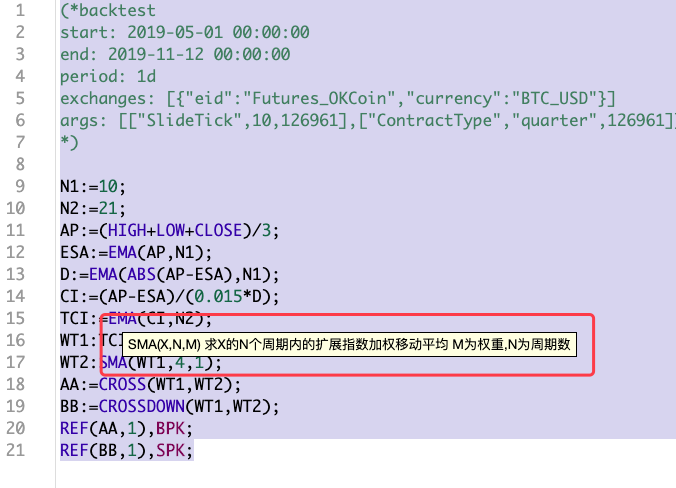
Như chúng ta có thể thấy, phần tham số có một tham số trọng lượng ngoài tham số thời gian.
Chức năng chỉ số SMA trong thư viện talib trong tài liệu API FMZ được mô tả như sau:

Có thể thấy rằngtalib.SMAlà một chỉ số trung bình động đơn giản.
Bằng cách này, chúng ta chỉ có thể thực hiện một SMA của chính mình. Là một nhà phát triển sử dụng ngôn ngữ JavsScript để viết chiến lược, đây cũng là một trong những kỹ năng cần thiết. Sau tất cả, nếu không có bánh xe sẵn sàng, chương trình vẫn cần chạy, chỉ cần xây dựng một.
Nói thật, không có nhiều nghiên cứu về các chỉ số v.v. Nói chung, mọi người tìm kiếm thông tin nếu họ không hiểu nó.

Dường như quá trình thuật toán của lý thuyết này khá đáng tin cậy, và việc thực hiện như sau:
function SMA (arr, n, m) {
var sma = []
var currSMA = null
for (var i = 0; i < arr.length; i++) {
if (arr[i] && !isNaN(arr[i])) {
if (!currSMA) {
currSMA = arr[i]
sma.push(currSMA)
continue
}
// [M*C2+(N-M)*S1]/N
currSMA = (m * arr[i] + (n - m) * currSMA) / n
sma.push(currSMA)
} else {
sma.push(NaN)
}
}
return sma
}
Viết các phần được lấp đầy
Khung chiến lược sử dụng cùng một khuôn khổ như trong bài viếtDạy bạn viết chiến lược -- cấy ghép một chiến lược MyLanguagevà chủ yếu được lấp đầy trong hai phần:
Đầu tiên, xử lý dữ liệu ticker và tính toán chỉ số.
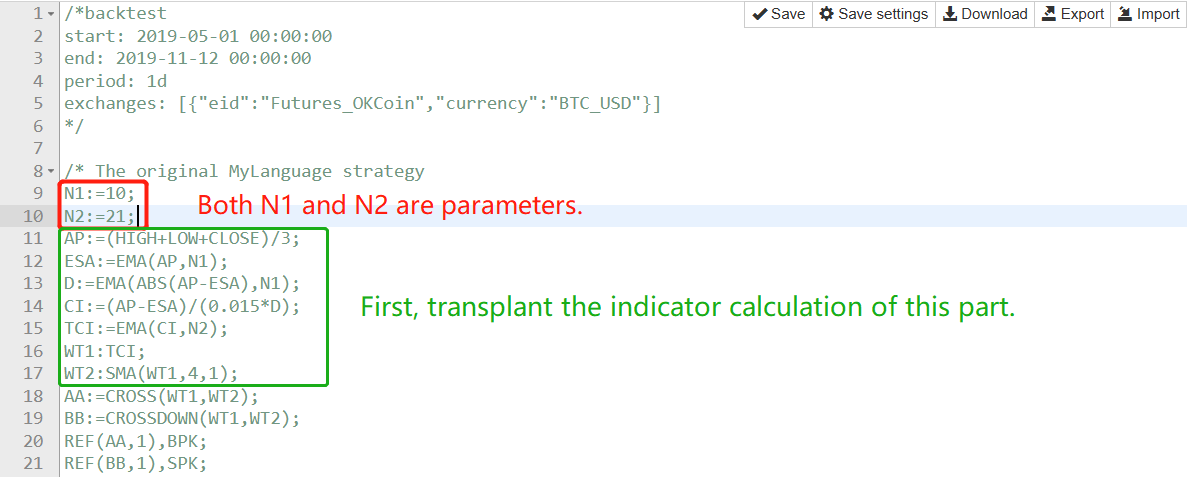
Chúng ta hãy lấy phần này của MyLanguage một câu một lúc, chức năng theo chức năng:
-
AP:=(HIGH+LOW+CLOSE)/3;
Có thể hiểu rằng giá cao nhất, giá thấp nhất và giá đóng của mỗi BAR trong dữ liệu dòng K nên được cộng lại và sau đó chia cho 3 để tính giá trị trung bình, và sau đó lưu dưới dạng một mảng, tương ứng với mỗi BAR một lần một. Nó có thể được xử lý như sau:
function CalcAP (r) { // AP:=(HIGH+LOW+CLOSE)/3;
var arrAP = [] // Declare an empty array
for (var i = 0; i < r.length; i++) { // r is the incoming K-line data, which is an array, use for to traverse this array.
v = (r[i].High + r[i].Low + r[i].Close) / 3 // Calculate the average value.
arrAP.push(v) // Add to the end of the arrAP array, the end is the first when arrAP is empty.
}
return arrAP // Returns this average array, i.e., the AP calculated in the MyLanguage
}
Chức năng này có thể được gọi trong hàm OnTick vòng lặp chính, ví dụ:
// Calculation of indicators
// AP
var ap = CalcAP(records)
-
- Sau khi tính toán AP được hoàn thành, tiếp tục tính toán
ESA:=EMA(AP,N1);:
- Sau khi tính toán AP được hoàn thành, tiếp tục tính toán
Ở đây, chúng ta sẽ sử dụng dữ liệu của AP tính toán trong bước trước để tính toán ESA. Thực tế, ESA là
function CalcESA (ap, n1) { // ESA:=EMA(AP,N1);
if (ap.length <= n1) { // If the AP length is less than the indicator parameter, valid data cannot be calculated. At this time, let the function return false.
return false
}
return TA.EMA(ap, n1)
}
-
D:=EMA(ABS(AP-ESA),N1);
Sử dụng tính toánAP, ESAđể tính toán dữ liệuD- Không.
Các bình luận mã ở đây có thể được đọc để có một số lời khuyên về cách tính toán các chỉ số.
function CalcD (ap, esa, n1) { // D:=EMA(ABS(AP-ESA),N1);
var arrABS_APminusESA = []
if (ap.length != esa.length) {
throw "ap.length != esa.length"
}
for (var i = 0; i < ap.length; i++) {
// When calculating the value of the indicator, it is necessary to determine the validity of the data, because the first few EMA calculations may be the beginning of the array of data is NaN, or null.
// So it must be judged that the data involved in the calculation are all valid values to proceed, and if there are any invalid values, they are filled with NaN to arrABS_APminusESA.
// The data thus calculated, each position corresponds to the previous data one by one, without misalignment.
if (ap[i] && esa[i] && !isNaN(ap[i]) && !isNaN(esa[i])) {
v = Math.abs(ap[i] - esa[i]) // According to ABS(AP-ESA), the specific value is calculated and put into the arrABS_APminusESA array.
arrABS_APminusESA.push(v)
} else {
arrABS_APminusESA.push(NaN)
}
}
if (arrABS_APminusESA.length <= n1) {
return false
}
return TA.EMA(arrABS_APminusESA, n1) // Calculate the EMA indicator of the array arrABS_APminusESA and get the data D (array structure).
}
-
CI:=(AP-ESA)/(0.015*D);Phương pháp tính toán tương tự như bước 1, và mã được phát hành trực tiếp.
function CalcCI (ap, esa, d) { // CI:=(AP-ESA)/(0.015*D);
var arrCI = []
if (ap.length != esa.length || ap.length != d.length) {
throw "ap.length != esa.length || ap.length != d.length"
}
for (var i = 0; i < ap.length; i++) {
if (ap[i] && esa[i] && d[i] && !isNaN(ap[i]) && !isNaN(esa[i]) && !isNaN(d[i])) {
v = (ap[i] - esa[i]) / (0.015 * d[i])
arrCI.push(v)
} else {
arrCI.push(NaN)
}
}
if (arrCI.length == 0) {
return false
}
return arrCI
}
- TCI:=EMACI,N2); Chỉ cần tính chỉ số EMA cho mảng CI.
function CalcTCI (ci, n2) { // TCI:=EMA(CI,N2);
if (ci.length <= n2) {
return false
}
return TA.EMA(ci, n2)
}
- WT2:SMA(WT1,4,1);
Trong bước cuối cùng này, chức năng SMA của bánh xe chúng tôi đã xây dựng trước đây được sử dụng.
function CalcWT2 (wt1) { // WT2:SMA(WT1,4,1);
if (wt1.length <= 4) {
return false
}
return SMA(wt1, 4, 1) // The SMA indicator for wt1 is calculated by using our own implementation of the SMA function.
}
Việc chuyển đổi tín hiệu giao dịch rất đơn giản.
AA:=CROSS(WT1,WT2);
BB:=CROSSDOWN(WT1,WT2);
REF(AA,1),BPK;
REF(BB,1),SPK;
Sau khi đọc các mã này của MyLanguage, chúng ta có thể thấy rằng Golden Cross và Bearish Crossover của WT1 và WT2 được sử dụng làm điều kiện mở. Sử dụng backtest chiến lược MyLanguage trực tiếp, chúng tôi quan sát thấy rằng:
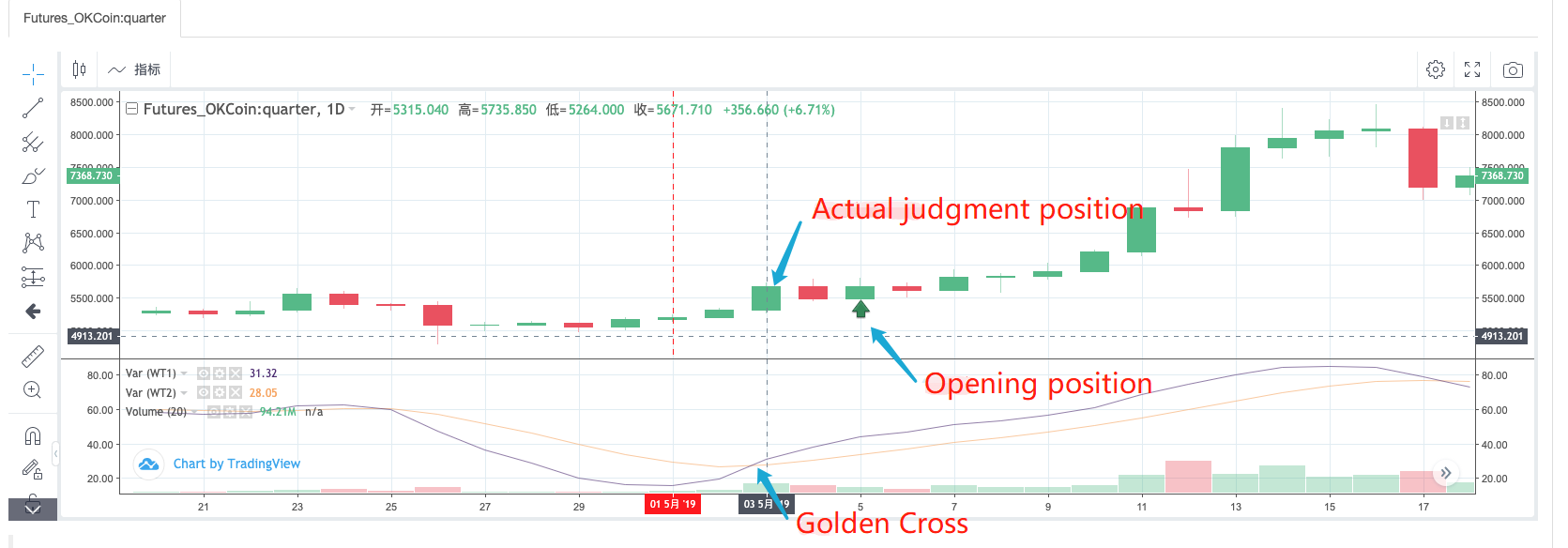
Có thể thấy từ việc quan sát hoạt động thực tế của chiến lược MyLanguage rằng khi một tín hiệu được phát hiện ở vị trí mở, nó thực sự là để phát hiện xem vị trí của BAR tại điểm mở đếm 2 BAR về phía trước có phải là Golden Cross không.
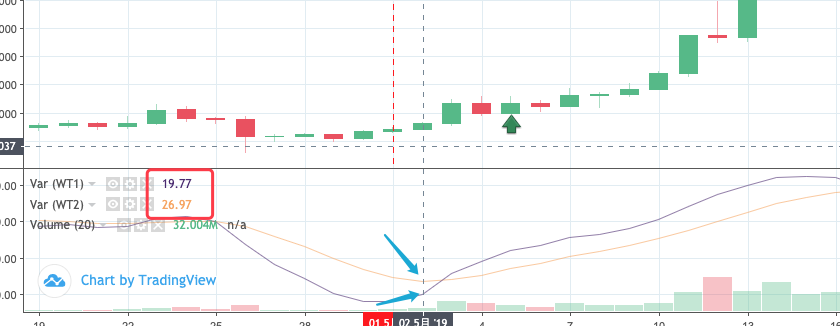
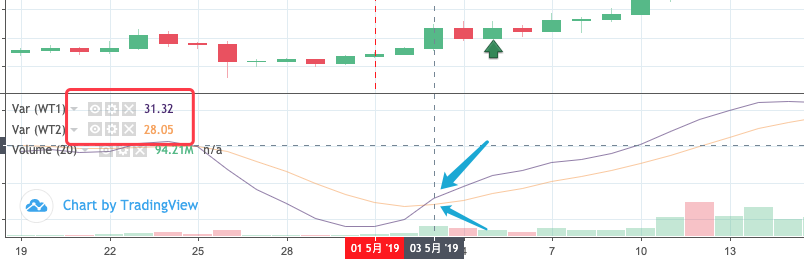
Mã điền của phần phát hiện tín hiệu có thể được viết như sau:
if ((_State == IDLE || _State == SHORT) && wt1[wt1.length - 4] < wt2[wt2.length - 4] && wt1[wt1.length - 3] > wt2[wt2.length - 3]) {
if (_State == IDLE) {
_State = OPENLONG
Log("OPENLONG") // test
}
if (_State == SHORT) {
_State = COVERSHORT
Log("COVERSHORT") // test
}
isOK = false
}
if ((_State == IDLE || _State == LONG) && wt1[wt1.length - 4] > wt2[wt2.length - 4] && wt1[wt1.length - 3] < wt2[wt2.length - 3]) {
if (_State == IDLE) {
_State = OPENSHORT
Log("OPENSHORT") // test
}
if (_State == LONG) {
_State = COVERLONG
Log("COVERLONG") // test
}
isOK = false
}
Ở đây bạn có thể suy nghĩ về lý do tại sao các hướng dẫn SPK và BPK của MyLanguage có thể được thực hiện với mã trên.
Kiểm tra hậu quả
Cấu hình backtest:
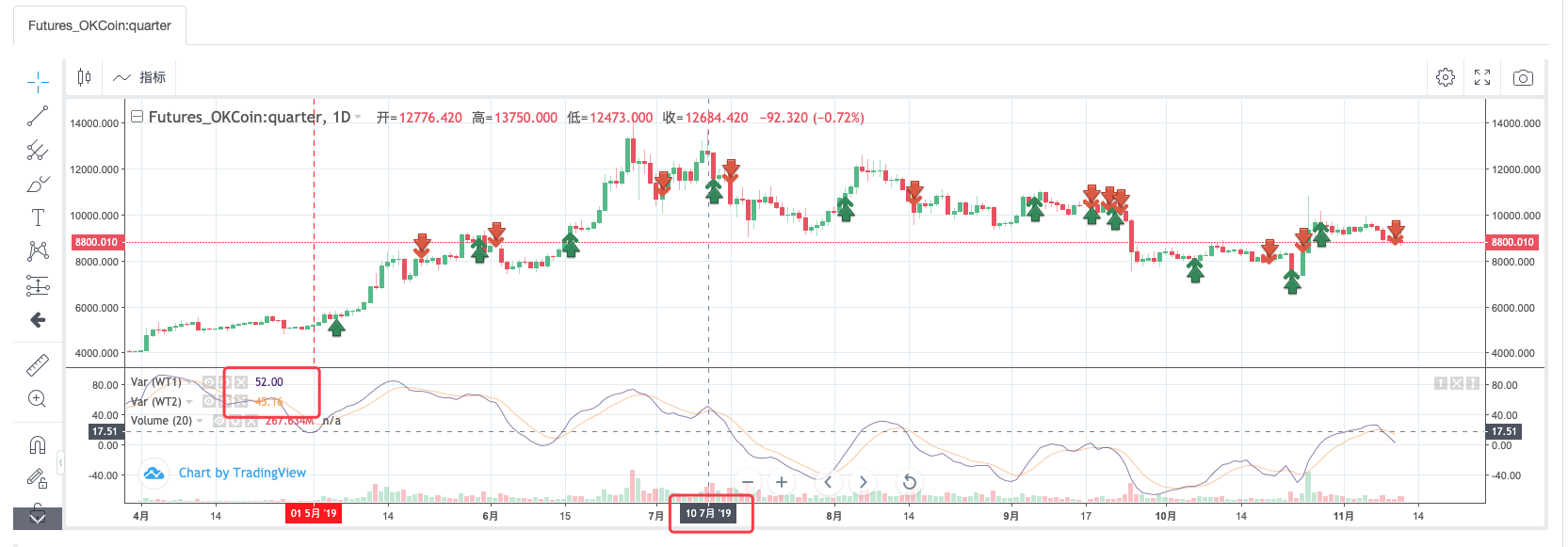
Backtest trong MyLanguage:
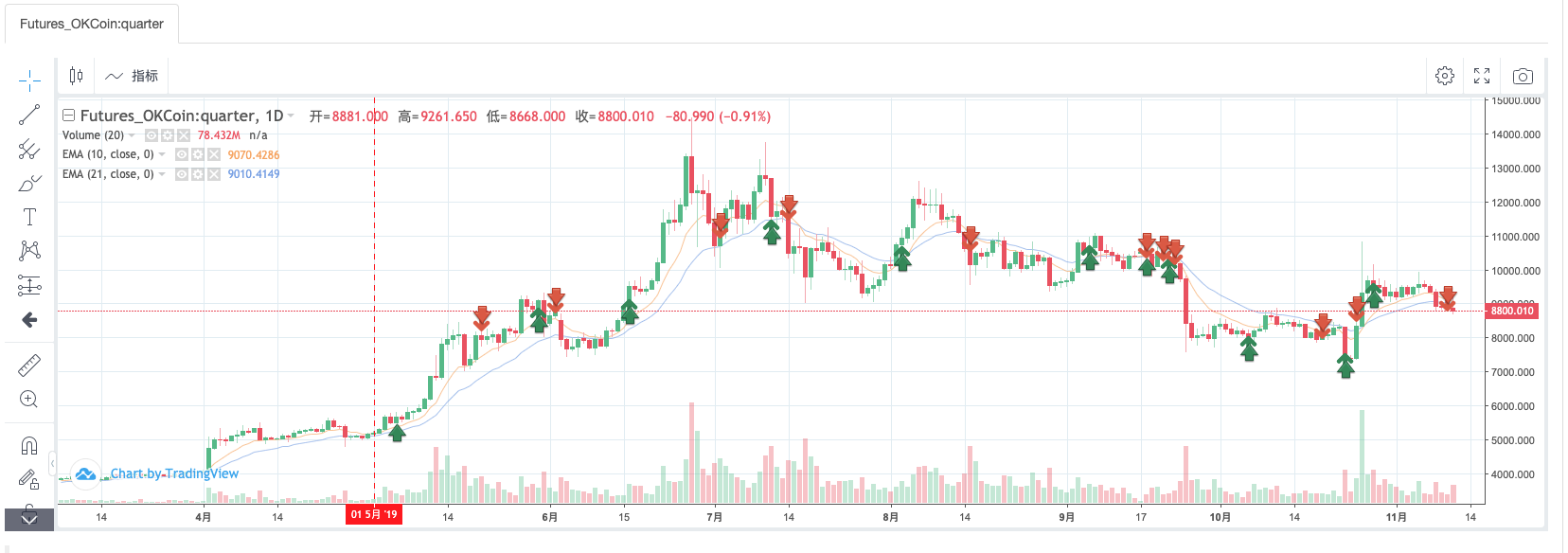
Backtest trong phiên bản JavaScript:
Mã ở đầu hàm OnTick được sử dụng để làm cho backtesting nhanh hơn. Nó được sử dụng để chạy chiến lược dựa trên mô hình Bar. Nếu bạn quan tâm, bạn có thể phân tích nó chi tiết.
function OnTick(){
// The ticker processing part of the driving strategy.
var records = _C(exchange.GetRecords)
if (records[records.length - 1].Time == preTime) {
if (isOK) {
Sleep(500)
return
}
} else {
preTime = records[records.length - 1].Time
}
...
..
.
Mã chiến lược giảng dạy đầy đủ:https://www.fmz.com/strategy/174457
Cảm ơn đã đọc.
- Đạt được các chiến lược vốn chủ sở hữu cân bằng với sự điều chỉnh có trật tự
- Phân tích dữ liệu chuỗi thời gian và kiểm tra lại dữ liệu tick
- Phân tích định lượng thị trường tiền kỹ thuật số
- Giao dịch cặp dựa trên công nghệ dữ liệu
- Ứng dụng công nghệ học máy trong giao dịch
- Sử dụng môi trường nghiên cứu để phân tích các chi tiết của việc bảo hiểm hình tam giác và tác động của phí xử lý đối với chênh lệch giá có thể bảo hiểm
- Cải cách API tương lai Deribit để thích nghi với giao dịch tùy chọn định lượng
- Các công cụ tốt hơn làm cho công việc tốt hơn - học cách sử dụng môi trường nghiên cứu để phân tích các nguyên tắc giao dịch
- Các chiến lược phòng ngừa rủi ro giữa các loại tiền tệ trong giao dịch định lượng các tài sản blockchain
- Mua hướng dẫn chiến lược tiền kỹ thuật số của FMex trên FMZ Quant
- Dạy bạn viết chiến lược -- cấy ghép một chiến lược MyLanguage
- Dạy bạn thêm hỗ trợ đa biểu đồ cho chiến lược
- Dạy bạn viết một hàm tổng hợp K-line trong phiên bản Python
- Phân tích chiến lược kênh Donchian trong môi trường nghiên cứu
- Khi FMZ gặp ChatGPT, ghi nhớ một lần thử sử dụng AI để hỗ trợ học hỏi giao dịch định lượng
- Công cụ giao dịch định lượng sẵn dùng cho các tùy chọn tiền kỹ thuật số
- Chiến lược lưới đơn giản trong phiên bản Python
- Chiến lược dòng lệnh chờ tuyến tính được phát triển dựa trên chức năng phát lại dữ liệu
- Chiến lược để mua người chiến thắng của phiên bản Python
- FMZ Journey -- với Chiến lược chuyển đổi