র্যান্ডম মার্কেট জেনারেটরের উপর ভিত্তি করে কৌশলগত পরীক্ষার পদ্ধতিগুলি অনুসন্ধান করুন
লেখক:উদ্ভাবকগণ - ক্যোটিফিকেশন - ছোট্ট স্বপ্ন, তৈরিঃ ২০২৪-১১-২৯ ১৬ঃ৩৫ঃ৪৪, আপডেটঃ ২০২৪-১২-০২ ০৯ঃ১২ঃ৪৩[TOC]

উপস্থাপনা
উদ্ভাবকগণের কোয়ালিফাইড ট্রেডিং প্ল্যাটফর্মের রিটার্নিং সিস্টেম হল একটি রিটার্নিং সিস্টেম যা ক্রমাগত আপগ্রেড করা হয়, যা প্রাথমিক মৌলিক রিটার্নিং কার্যকারিতা থেকে ক্রমাগত বৈশিষ্ট্য বৃদ্ধি করে, কার্যকারিতা উন্নত করে। প্ল্যাটফর্মের বিকাশের সাথে সাথে রিটার্নিং সিস্টেমগুলি ক্রমাগত আপগ্রেড করা হয়। আজ আমরা রিটার্নিং সিস্টেমের উপর ভিত্তি করে একটি বিষয় নিয়ে আলোচনা করবঃ "এলোমেলো বাজারে ভিত্তি করে কৌশলগত পরীক্ষা"।
চাহিদা
কোয়ালিফাইড ট্রেডিং ক্ষেত্রে, কৌশল বিকাশ এবং অপ্টিমাইজেশান বাস্তব বাজারের ডেটা থেকে পৃথক নয়। তবে, বাস্তব প্রয়োগে, বাজারের পরিবেশে জটিলতা এবং পরিবর্তনশীলতার কারণে, historicalতিহাসিক তথ্যের উপর নির্ভর করে পুনর্বিবেচনার অভাব থাকতে পারে, যেমন চরম বাজার বা বিশেষ দৃশ্যের কভারেজের অভাব। অতএব, একটি দক্ষ র্যান্ডম ট্রেড জেনারেটর ডিজাইন করা কোয়ালিফাইড কৌশল বিকাশকারীদের জন্য একটি কার্যকর সরঞ্জাম হয়ে ওঠে।
যখন আমরা একটি এক্সচেঞ্জ বা মুদ্রার উপর একটি কৌশল পুনরুদ্ধার করতে চাই, আমরা FMZ প্ল্যাটফর্মের অফিসিয়াল ডেটা উত্স ব্যবহার করে এটি পুনরায় পরীক্ষা করতে পারি। কখনও কখনও আমরা দেখতে চাই যে কৌশলটি সম্পূর্ণ অজানা বাজারে কীভাবে কাজ করে, তখন আমরা কৌশল পরীক্ষার জন্য কিছু ডেটা তৈরি করতে পারি।
এলোমেলো বাজারের ডেটা ব্যবহারের অর্থঃ
-
- কৌশলগত রূঢ়তার মূল্যায়ন র্যান্ডম মার্কেট জেনারেটর বিভিন্ন সম্ভাব্য মার্কেট দৃশ্যের সৃষ্টি করতে পারে, যার মধ্যে রয়েছে চরম ওলটপালট, নিম্ন ওলটপালট, প্রবণতা বাজার এবং অস্থির বাজার ইত্যাদি। এই অ্যালগরিদমিক পরিবেশে কৌশলগুলি পরীক্ষা করা বিভিন্ন মার্কেট অবস্থার অধীনে তাদের স্থিতিশীলতার মূল্যায়ন করতে সাহায্য করে। উদাহরণস্বরূপঃ
এই কৌশলটি কি প্রবণতা এবং কম্পনের সাথে সামঞ্জস্যপূর্ণ? এই কৌশলটি কি চরম বাজারে বড় ধরনের ক্ষতির কারণ হতে পারে?
-
- কৌশলগত সম্ভাব্য দুর্বলতা চিহ্নিত করুন কিছু অস্বাভাবিক বাজার পরিস্থিতি (যেমন একটি অনুমিত ব্ল্যাক সোয়ান ইভেন্ট) সিমুলেট করে কৌশলটির সম্ভাব্য দুর্বলতা সনাক্ত করা যায় এবং উন্নত করা যায়; উদাহরণস্বরূপঃ
আপনি কি মনে করেন যে আপনার কৌশলটি কোনও বাজার কাঠামোর উপর অত্যধিক নির্ভরশীল? আপনি কি মনে করেন যে, এই প্যারামিটারগুলি খুব বেশি ফিট হওয়ার ঝুঁকি আছে?
-
- অপ্টিমাইজ করা কৌশলগত পরামিতি এলোমেলোভাবে উত্পন্ন তথ্য কৌশলগত প্যারামিটার সংশোধন করার জন্য আরও বৈচিত্র্যময় পরীক্ষার পরিবেশ সরবরাহ করে, যা পুরোপুরি historicalতিহাসিক তথ্যের উপর নির্ভর করে না। এটি কৌশলগত প্যারামিটারগুলির আরও বিস্তৃত পরিসীমা খুঁজে পেতে পারে, যা historicalতিহাসিক ডেটাতে নির্দিষ্ট বাজারের প্যাটার্নগুলিতে সীমাবদ্ধ নয়।
-
- ঐতিহাসিক তথ্যের অভাব পূরণ কিছু বাজারে (যেমন, উদীয়মান বা ছোট মুদ্রা বিনিময় বাজার) ঐতিহাসিক তথ্য সব সম্ভাব্য বাজারের অবস্থা আবরণ করার জন্য যথেষ্ট নাও হতে পারে। এলোমেলো বাজারের জেনারেটর একটি বৃহত পরিপূরক তথ্য প্রদান করতে পারে যা আরও ব্যাপক পরীক্ষার জন্য সাহায্য করে।
-
- দ্রুত পুনরাবৃত্তি উন্নয়ন র্যান্ডম ডেটা ব্যবহার করে দ্রুত পরীক্ষার মাধ্যমে, রিয়েল-টাইম মার্কেট বাজার বা সময়সাপেক্ষ ডেটা পরিষ্কার এবং সাজানোর উপর নির্ভর না করে কৌশল বিকাশের আইডেরির গতি বাড়ানো যায়।
তবে একটি যুক্তিসঙ্গত মূল্যায়ন কৌশলও প্রয়োজন, এবং এলোমেলোভাবে উত্পন্ন বাজারের ডেটা সম্পর্কে সতর্কতা অবলম্বন করুনঃ
- ১। যদিও এলোমেলো বাজারের জেনারেটরগুলি কার্যকর, তবে এর অর্থ নির্ভর করে ডেটা উত্পাদনের গুণমান এবং লক্ষ্য দৃশ্যের নকশার উপরঃ
- ২. জেনেরেশন লজিকটি বাস্তব বাজারের কাছাকাছি হওয়া দরকারঃ যদি এলোমেলোভাবে উত্পন্ন বাজারগুলি বাস্তবতা থেকে সম্পূর্ণরূপে বিচ্ছিন্ন হয় তবে পরীক্ষার ফলাফলগুলির কোনও রেফারেন্সের মূল্য থাকতে পারে না। উদাহরণস্বরূপ, একটি জেনারেটরকে বাস্তব বাজারের পরিসংখ্যানগত বৈশিষ্ট্যগুলি (যেমন উদ্বায়ী হার বিতরণ, প্রবণতা অনুপাত) দিয়ে ডিজাইন করা যেতে পারে।
- ৩. বাস্তব ডেটা পরীক্ষার সম্পূর্ণ প্রতিস্থাপন নেইঃ র্যান্ডম ডেটা কেবল কৌশলগুলির বিকাশ এবং অপ্টিমাইজেশানকে পরিপূরক করতে পারে এবং চূড়ান্ত কৌশলগুলি এখনও বাস্তব বাজারের ডেটাতে তাদের কার্যকারিতা যাচাই করতে হবে।
আমরা কীভাবে সহজ, দ্রুত এবং সহজেই তথ্য তৈরি করতে পারি যা রিসেটিং সিস্টেম ব্যবহার করতে পারে?
ডিজাইন
এই নিবন্ধটি র্যান্ডম মার্কেট জেনারেটরের তুলনামূলকভাবে সহজ গণনা দেওয়ার জন্য ডিজাইন করা হয়েছে, বাস্তবে বিভিন্ন ধরণের অ্যালগরিদম, ডেটা মডেল ইত্যাদি প্রযুক্তি প্রয়োগ করা যেতে পারে, কারণ আলোচনাটি সীমিত।
প্ল্যাটফর্ম রিভিউ সিস্টেমের কাস্টম ডেটা উত্সের বৈশিষ্ট্যগুলির সাথে, আমরা পাইথন ভাষা ব্যবহার করে একটি প্রোগ্রাম লিখেছি।
- ১। একটি K-line ডাটা সেটকে একটি CSV ফাইলের স্থায়ী রেকর্ডে র্যান্ডমভাবে তৈরি করুন, যাতে তৈরি করা ডেটা রেকর্ড করা যায়।
- ২। তারপর একটি পরিষেবা তৈরি করুন যা রিসেটিং সিস্টেমে ডেটা উত্স সমর্থন করে।
- ৩, উত্পন্ন কে-লাইন ডেটা চার্টে প্রদর্শিত হয়।
কে-লাইন ডেটার জন্য কিছু জেনারেটর মানদণ্ড, ফাইল স্টোরেজ ইত্যাদির জন্য, নিম্নলিখিত পরামিতি নিয়ন্ত্রণগুলি সংজ্ঞায়িত করা যেতে পারেঃ
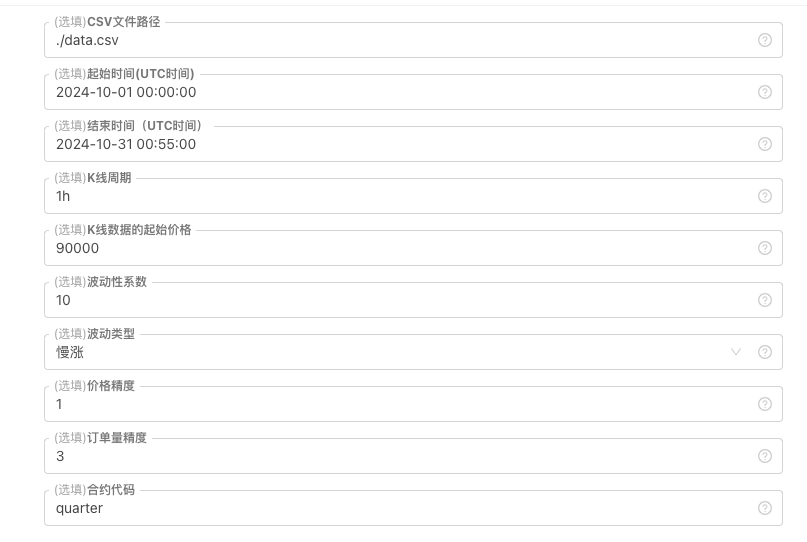
-
ডাটা র্যান্ডম জেনারেট করা হয় কে-লাইন ডেটার অ্যালগরিদমের জন্য, কেবলমাত্র একটি সহজ নকশার জন্য একটি সহজ ব্যবহার করা হয়েছে, যা ধনাত্মক নেতিবাচক সম্ভাব্যতার জন্য একটি র্যান্ডম সংখ্যা, যখন উত্পন্ন ডেটা খুব কম হয় তখন এটি প্রয়োজনীয় ট্রেডিং প্যাটার্নগুলি প্রতিফলিত করতে পারে না। যদি আরও ভাল উপায় থাকে তবে এই অংশটি প্রতিস্থাপন করা যেতে পারে। এই সহজ নকশার উপর ভিত্তি করে, কোডের র্যান্ডম সংখ্যা উত্পাদন পরিসীমা এবং কিছু গুণক সামঞ্জস্য করে উত্পন্ন ডেটা প্রভাবকে প্রভাবিত করতে পারে।
-
তথ্য পরীক্ষা উত্পাদিত কে-লাইন ডেটার জন্য যুক্তিসঙ্গততা পরীক্ষা করা প্রয়োজন, উচ্চ-নিম্ন চার্জ নির্ধারণের বিপরীত কিনা তা পরীক্ষা করা, কে-লাইন ডেটার ধারাবাহিকতা পরীক্ষা করা ইত্যাদি।
রিসেট সিস্টেম র্যান্ডম ট্রেন্ড জেনারেটর
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据data.detail:", data["detail"], "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("不支持的K线周期,请使用 'm', 'h', 或 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("异常数据:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("当前路径:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("文件写入成功,以下是文件内容的一部分:")
Log("".join(lines[:5]))
else:
Log("文件写入失败,文件为空!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("开启自定义数据源服务线程,数据由CSV文件提供。", ", 地址/端口:0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("生成器参数:", "起始时间:", startTime, "结束时间:", endTime, "K线周期:", KLinePeriod, "初始价格:", firstPrice, "波动类型:", arrTrendType[trendType], "波动性系数:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
পুনরায় পরীক্ষা সিস্টেমের অনুশীলন
১, উপরের নীতির উদাহরণ তৈরি করুন, প্যারামিটারগুলি কনফিগার করুন এবং চালান। ২, রিয়েল ডিস্ক (পলিসি ইনস্ট্যান্স) সার্ভারে স্থাপিত হোস্টের উপর চালানো প্রয়োজন, কারণ ডেটা পাওয়ার জন্য একটি পাবলিক নেটওয়ার্ক আইপি প্রয়োজন, যা পুনর্বিবেচনার সিস্টেমগুলি অ্যাক্সেস করতে পারে। ৩. ইন্টারঅ্যাকশন বোতামে ক্লিক করলে, কৌশলটি স্বয়ংক্রিয়ভাবে এলোমেলো মার্কেটিং ডেটা তৈরি করতে শুরু করে।

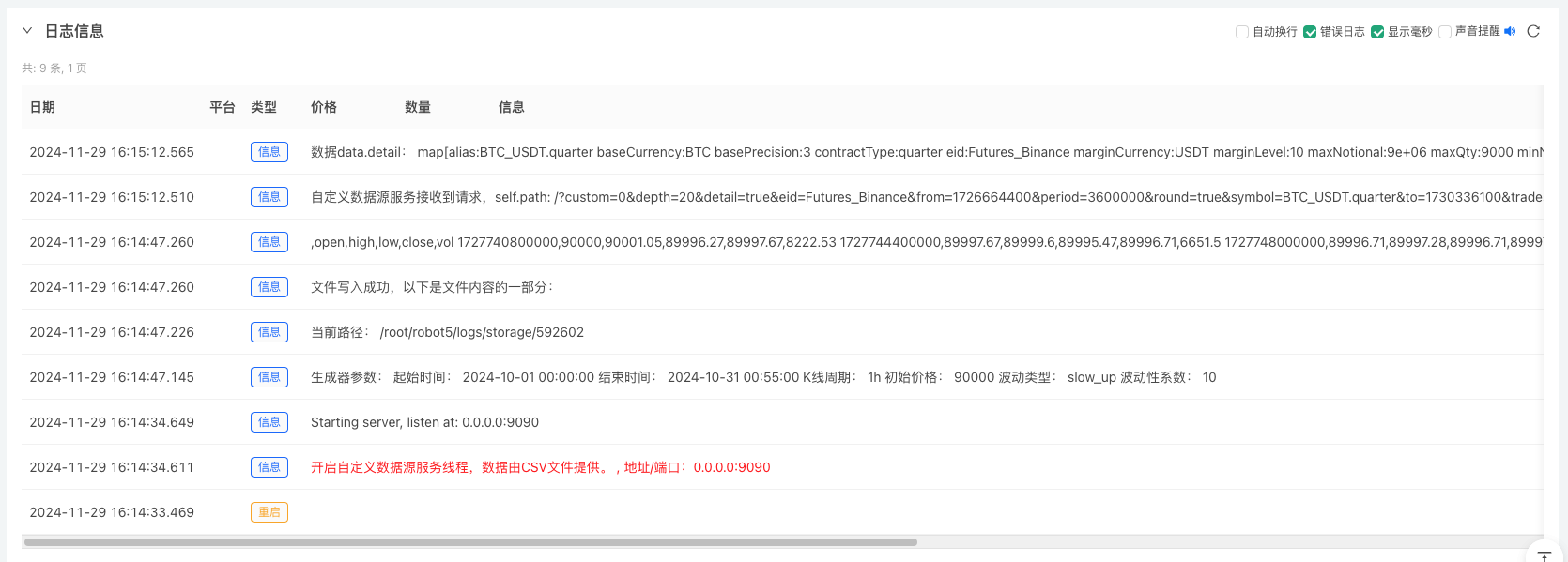
4、生成好的数据会显示在图表上,方便观察,同时数据会记录在本地的data.csv文件
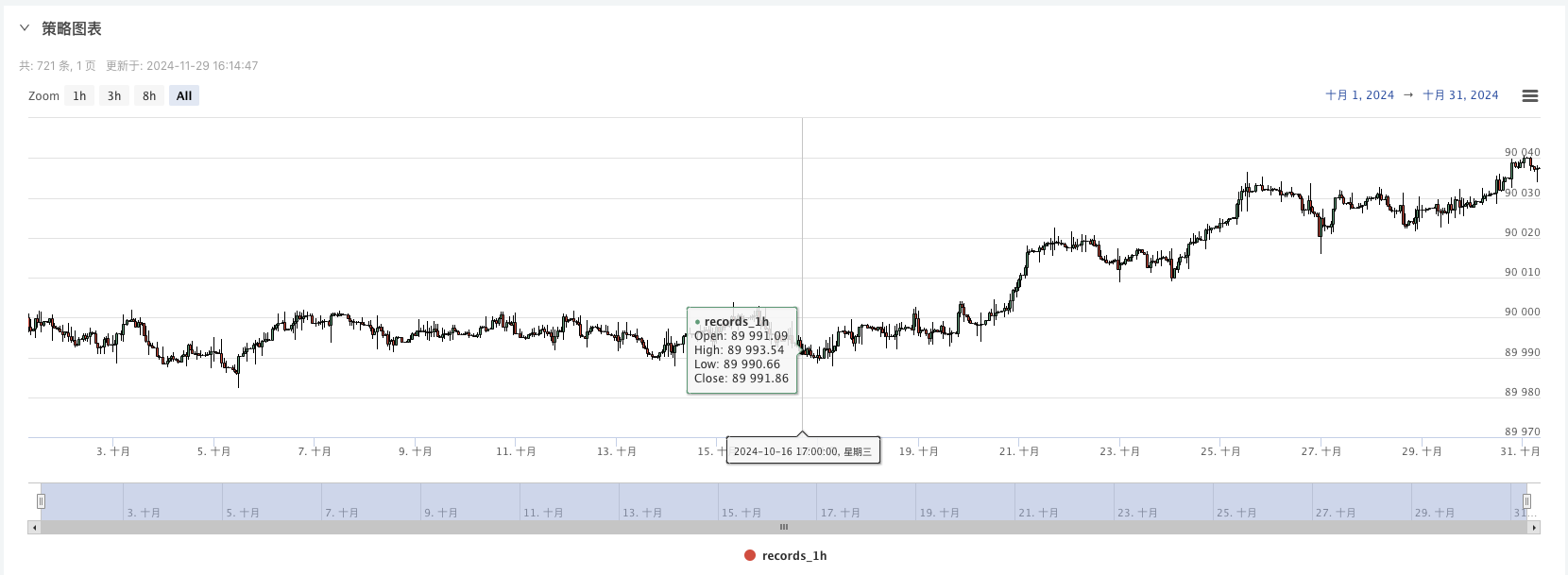
এখন আমরা এই র্যান্ডমাইজড ডেটা ব্যবহার করতে পারি, এবং একটি কৌশল ব্যবহার করে এটিকে আবার পরীক্ষা করতে পারি।
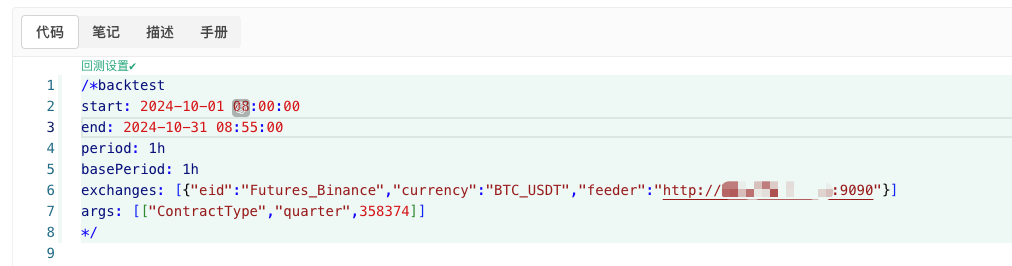
/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
উপরের তথ্যের ভিত্তিতে কনফিগারেশন, বিশেষত সামঞ্জস্য।http://xxx.xxx.xxx.xxx:9090এটি হল সার্ভারের আইপি ঠিকানা এবং খোলা পোর্ট যা এলোমেলোভাবে পলিসি তৈরি করে।
এটি একটি কাস্টমাইজড ডেটা উত্স, যা প্ল্যাটফর্মের API ডকুমেন্টেশনে কাস্টমাইজড ডেটা উত্স বিভাগে অনুসন্ধান করা যেতে পারে।
৬। রিট্র্যাকশন সিস্টেমটি ভাল ডেটা উত্স সেট আপ করে র্যান্ডম মার্কেটিং ডেটা পরীক্ষা করতে পারে।
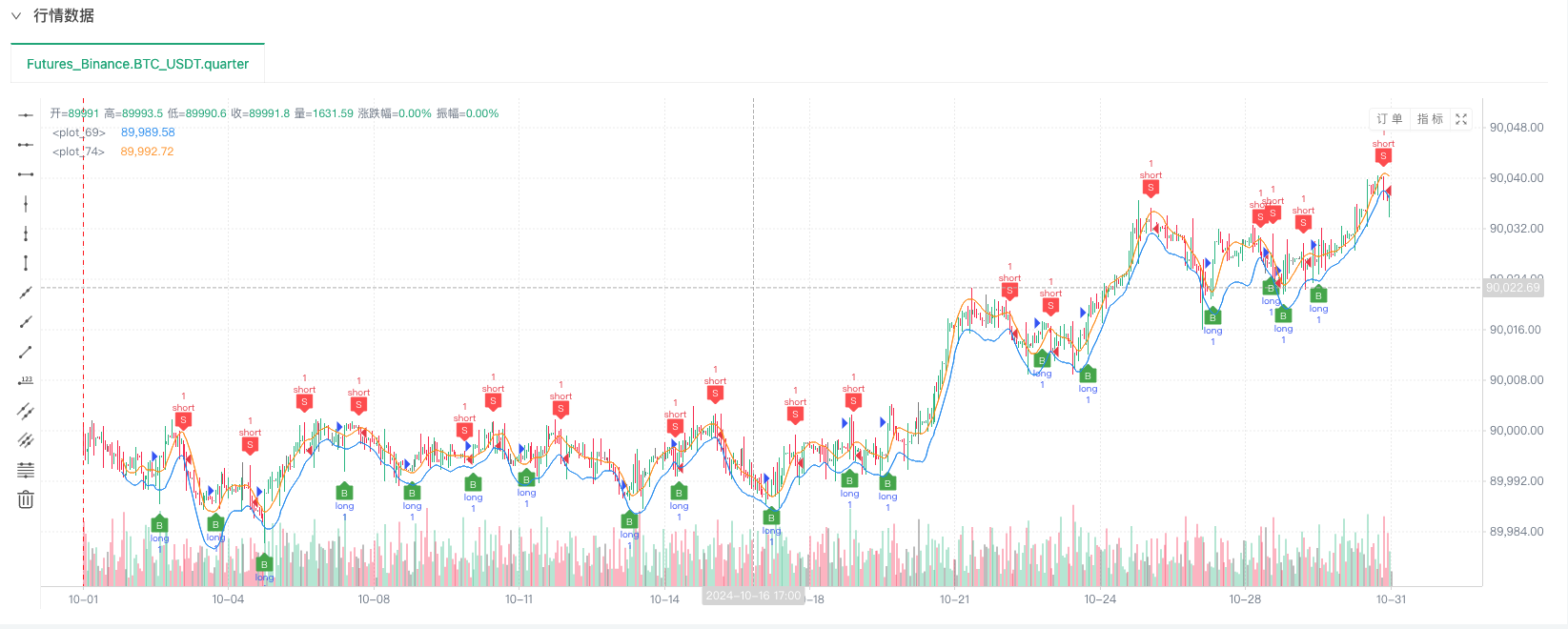
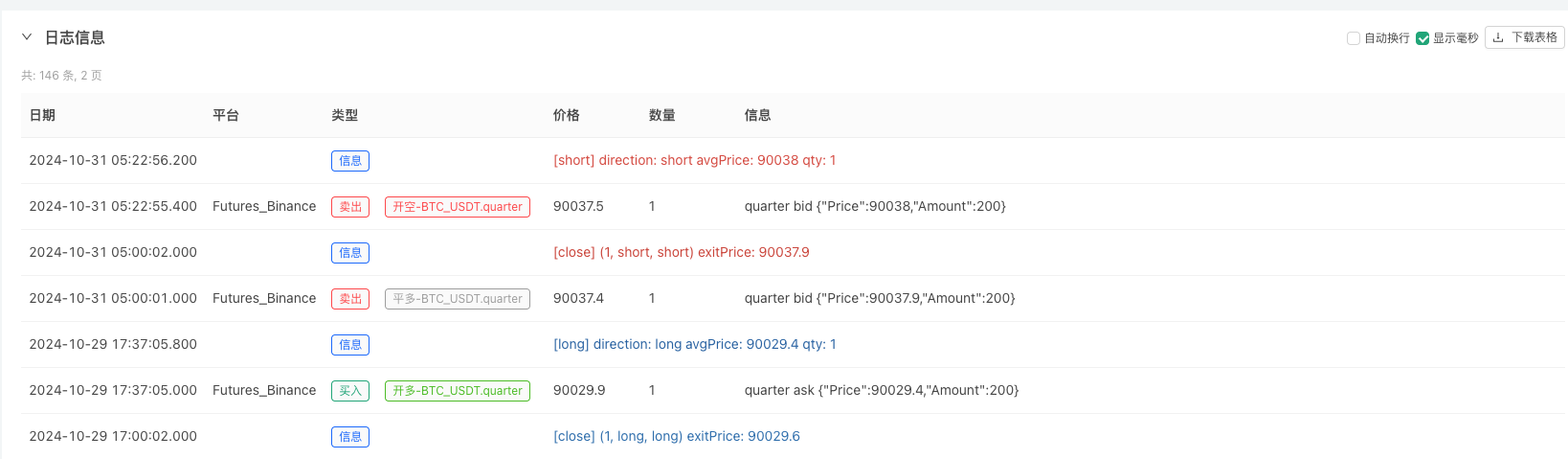
এই সময়ে, রিটার্নিং সিস্টেমটি আমাদের ময়লা তৈরির ময়লা তৈরির অ্যালগরিদম ডেটা দিয়ে পরীক্ষা করা হয়। রিটার্নিংয়ের সময় বাজারের চার্টের ডেটাগুলির সাথে র্যান্ডম বাজারের উত্পাদিত বাস্তব চার্টের ডেটাগুলির তুলনা করে, সময়ঃ 16 অক্টোবর, 2024, 17:00 পূর্ণাঙ্গ, ডেটা একই।
৭, ওহ হ্যাঁ, প্রায় ভুলেই গেছি! এই র্যান্ডম ব্যাচ জেনারেটরের জন্য পাইথন প্রোগ্রামটি একটি রিয়েল ডিস্ক তৈরি করার জন্য তৈরি করা হয়েছিল যাতে এটি সহজেই প্রদর্শন, পরিচালনা, উত্পন্ন কে-লাইন ডেটা প্রদর্শন করতে পারে। বাস্তব প্রয়োগে এটি সম্পূর্ণরূপে একটি স্বতন্ত্র পাইথন স্ক্রিপ্ট লিখতে পারে, যাতে রিয়েল ডিস্ক চালানোর প্রয়োজন হয় না।
এই কৌশলটির উত্স কোডঃরিসেট সিস্টেম র্যান্ডম ট্রেন্ড জেনারেটর
ধন্যবাদ সমর্থন ও পড়ার জন্য।
- ডিজিটাল মুদ্রায় লিড-ল্যাগ স্যুটের ভূমিকা (3)
- ক্রিপ্টোকারেন্সিতে লিড-লেগ আর্বিট্রেজের ভূমিকা (2)
- ডিজিটাল মুদ্রায় লিড-ল্যাগ স্যুটের ভূমিকা (২)
- এফএমজেড প্ল্যাটফর্মের বাহ্যিক সংকেত গ্রহণ নিয়ে আলোচনাঃ কৌশলগতভাবে অন্তর্নির্মিত এইচটিটিপি পরিষেবা সহ সংকেত গ্রহণের জন্য একটি সম্পূর্ণ সমাধান
- এফএমজেড প্ল্যাটফর্মের বহিরাগত সংকেত গ্রহণের অন্বেষণঃ কৌশলগুলি অন্তর্নির্মিত এইচটিটিপি পরিষেবাগুলির সংকেত গ্রহণের সম্পূর্ণ সমাধান
- ক্রিপ্টোকারেন্সিতে লিড-লেগ আর্বিট্রেজের ভূমিকা (1)
- ডিজিটাল মুদ্রায় লিড-ল্যাগ স্যুটের ভূমিকা
- এফএমজেড প্ল্যাটফর্মের বাহ্যিক সংকেত গ্রহণের বিষয়ে আলোচনাঃ বর্ধিত এপিআই বনাম কৌশল অন্তর্নির্মিত এইচটিটিপি পরিষেবা
- এফএমজেড প্ল্যাটফর্মের বহিরাগত সংকেত গ্রহণের অন্বেষণঃ এক্সটেনশান এপিআই বনাম কৌশল অন্তর্নির্মিত এইচটিটিপি পরিষেবা
- র্যান্ডম টিকার জেনারেটরের উপর ভিত্তি করে কৌশল পরীক্ষার পদ্ধতি নিয়ে আলোচনা
- এফএমজেড কোয়ান্টের নতুন বৈশিষ্ট্যঃ সহজেই এইচটিটিপি সার্ভিস তৈরি করতে _সার্ভ ফাংশন ব্যবহার করুন
- উদ্ভাবক নতুন বৈশিষ্ট্য পরিমাণঃ _Serve ফাংশন ব্যবহার করে সহজেই HTTP পরিষেবা তৈরি করুন
- FMZ কোয়ান্ট ট্রেডিং প্ল্যাটফর্ম কাস্টম প্রোটোকল অ্যাক্সেস গাইড
- এফএমজেড তহবিলের হার অর্জন এবং পর্যবেক্ষণ কৌশল
- এফএমজেড তহবিলের হার প্রাপ্তি এবং পর্যবেক্ষণ কৌশল কৌশল
- একটি কৌশল টেমপ্লেট আপনাকে ওয়েবসকেট মার্কেটকে নির্বিঘ্নে ব্যবহার করতে দেয়
- একটি নীতিমালা টেমপ্লেট যা আপনাকে ওয়েবসকেট ক্ষেত্রের সাথে নির্বিঘ্নে ব্যবহার করতে দেয়
- ইনভেন্টর কোয়ালিফাইড ট্রেডিং প্ল্যাটফর্মের সাধারণ প্রোটোকল অ্যাক্সেস গাইড
- এফএমজেড আপগ্রেডের পরে কীভাবে দ্রুত একটি ইউনিভার্সাল মাল্টি-কারেন্সি ট্রেডিং কৌশল তৈরি করবেন
- এফএমজেড আপগ্রেডের পরে কীভাবে দ্রুত একটি সাধারণ বহু-মুদ্রা ট্রেডিং কৌশল তৈরি করা যায়