র্যান্ডম টিকার জেনারেটরের উপর ভিত্তি করে কৌশল পরীক্ষার পদ্ধতি নিয়ে আলোচনা
লেখক:এফএমজেড-লিডিয়া, তৈরিঃ ২০২৪-১২-০২ ১১ঃ২৬ঃ১৩, আপডেটঃ ২০২৪-১২-০২ ২১ঃ৩৯ঃ৩৯
প্রিফেস
এফএমজেড কোয়ান্ট ট্রেডিং প্ল্যাটফর্মের ব্যাকটেস্টিং সিস্টেম একটি ব্যাকটেস্টিং সিস্টেম যা ক্রমাগত পুনরাবৃত্তি, আপডেট এবং আপগ্রেড করা হয়। এটি প্রাথমিক বেসিক ব্যাকটেস্টিং ফাংশন থেকে ধীরে ধীরে ফাংশন যুক্ত করে এবং পারফরম্যান্স অপ্টিমাইজ করে। প্ল্যাটফর্মের বিকাশের সাথে সাথে ব্যাকটেস্টিং সিস্টেমটি অপ্টিমাইজ করা এবং আপগ্রেড করা অব্যাহত থাকবে। আজ আমরা ব্যাকটেস্টিং সিস্টেমের উপর ভিত্তি করে একটি বিষয় নিয়ে আলোচনা করবঃ
চাহিদা
পরিমাণগত ট্রেডিংয়ের ক্ষেত্রে, কৌশলগুলির বিকাশ এবং অপ্টিমাইজেশানকে বাস্তব বাজারের ডেটা যাচাইকরণ থেকে পৃথক করা যায় না। তবে, প্রকৃত অ্যাপ্লিকেশনগুলিতে, জটিল এবং পরিবর্তিত বাজারের পরিবেশের কারণে, ব্যাকটেস্টিংয়ের জন্য historicalতিহাসিক ডেটাতে নির্ভর করা অপর্যাপ্ত হতে পারে, যেমন চরম বাজারের পরিস্থিতি বা বিশেষ দৃশ্যের কভারেজের অভাব। অতএব, একটি দক্ষ এলোমেলো বাজার জেনারেটর ডিজাইন করা পরিমাণগত কৌশল বিকাশকারীদের জন্য একটি কার্যকর সরঞ্জাম হয়ে উঠেছে।
যখন আমাদের কৌশলটিকে একটি নির্দিষ্ট এক্সচেঞ্জ বা মুদ্রার উপর historicalতিহাসিক ডেটা ট্র্যাক করতে দেওয়া দরকার, তখন আমরা ব্যাকটেস্টিংয়ের জন্য এফএমজেড প্ল্যাটফর্মের অফিসিয়াল ডেটা উত্স ব্যবহার করতে পারি। কখনও কখনও আমরা দেখতে চাই যে কৌশলটি সম্পূর্ণ অজানা বাজারে কীভাবে সম্পাদন করে, যাতে আমরা কৌশলটি পরীক্ষা করার জন্য কিছু ডেটা তৈরি করতে পারি।
এলোমেলো টিকার ডেটা ব্যবহারের গুরুত্ব হলঃ
-
- কৌশলগুলির দৃঢ়তা মূল্যায়ন করুন এলোমেলো টিকার জেনারেটর বিভিন্ন সম্ভাব্য বাজার দৃশ্যকল্প তৈরি করতে পারে, যার মধ্যে রয়েছে চরম অস্থিরতা, কম অস্থিরতা, ট্রেন্ডিং বাজার এবং অস্থির বাজার। এই সিমুলেটেড পরিবেশে পরীক্ষার কৌশলগুলি তাদের কর্মক্ষমতা বিভিন্ন বাজারের অবস্থার অধীনে স্থিতিশীল কিনা তা মূল্যায়ন করতে সহায়তা করতে পারে। উদাহরণস্বরূপঃ
কৌশলটি প্রবণতা এবং অস্থিরতার পরিবর্তনের সাথে মানিয়ে নিতে পারে? চরম বাজারের পরিস্থিতিতে কৌশলটি কি বড় ক্ষতির সম্মুখীন হবে?
-
- কৌশলটির সম্ভাব্য দুর্বলতাগুলি চিহ্নিত করুন কিছু অস্বাভাবিক বাজার পরিস্থিতির অনুকরণ করে (যেমন কল্পিত কালো সোয়ান ইভেন্টগুলি), কৌশলটির সম্ভাব্য দুর্বলতাগুলি আবিষ্কৃত এবং উন্নত করা যেতে পারে। উদাহরণস্বরূপঃ
কৌশলটি কি একটি নির্দিষ্ট বাজারের কাঠামোর উপর অত্যধিক নির্ভর করে? প্যারামিটারগুলি অতিরিক্ত ফিট হওয়ার ঝুঁকি আছে কি?
-
- কৌশলগত পরামিতিগুলি অপ্টিমাইজ করা এলোমেলোভাবে উত্পন্ন ডেটা কৌশল পরামিতি অপ্টিমাইজেশনের জন্য সম্পূর্ণরূপে ঐতিহাসিক তথ্যের উপর নির্ভর না করে একটি আরও বৈচিত্র্যময় পরীক্ষার পরিবেশ সরবরাহ করে। এটি আপনাকে কৌশলটির পরামিতি পরিসীমা আরও ব্যাপকভাবে খুঁজে পেতে এবং ঐতিহাসিক ডেটাতে নির্দিষ্ট বাজারের নিদর্শনগুলিতে সীমাবদ্ধ হওয়া এড়াতে সহায়তা করে।
-
- ঐতিহাসিক তথ্যের ফাঁক পূরণ করা কিছু বাজারে (যেমন উদীয়মান বাজার বা ছোট মুদ্রা ট্রেডিং বাজার), ঐতিহাসিক তথ্য সমস্ত সম্ভাব্য বাজার পরিস্থিতি আবরণ করার জন্য যথেষ্ট নাও হতে পারে। এলোমেলো টিকার জেনারেটর আরো ব্যাপক পরীক্ষা পরিচালনা করতে সাহায্য করার জন্য একটি বড় পরিমাণে সম্পূরক তথ্য প্রদান করতে পারে।
-
- দ্রুত পুনরাবৃত্তি উন্নয়ন দ্রুত পরীক্ষার জন্য এলোমেলো ডেটা ব্যবহার করে রিয়েল-টাইম মার্কেট টিকার শর্ত বা সময়সাপেক্ষ ডেটা পরিষ্কার এবং সংগঠনের উপর নির্ভর না করে কৌশল বিকাশের পুনরাবৃত্তিকে ত্বরান্বিত করতে পারে।
যাইহোক, কৌশলটি যুক্তিসঙ্গতভাবে মূল্যায়ন করাও প্রয়োজনীয়। এলোমেলোভাবে উত্পন্ন টিকার ডেটার জন্য, দয়া করে নোট করুনঃ
-
- যদিও এলোমেলো বাজার জেনারেটরগুলি দরকারী, তবে তাদের গুরুত্ব উত্পন্ন ডেটার গুণমান এবং লক্ষ্য দৃশ্যকল্পের নকশার উপর নির্ভর করেঃ
-
- উত্পাদন যুক্তি বাস্তব বাজারের কাছাকাছি হতে হবেঃ যদি এলোমেলোভাবে উত্পাদিত বাজার বাস্তবতার সাথে সম্পূর্ণরূপে সংযুক্ত না হয় তবে পরীক্ষার ফলাফলগুলির রেফারেন্স মানের অভাব হতে পারে। উদাহরণস্বরূপ, জেনারেটরটি প্রকৃত বাজারের পরিসংখ্যানগত বৈশিষ্ট্যগুলির উপর ভিত্তি করে ডিজাইন করা যেতে পারে (যেমন অস্থিরতা বিতরণ, প্রবণতা অনুপাত) ।
-
- এটি বাস্তব ডেটা পরীক্ষার সম্পূর্ণরূপে প্রতিস্থাপন করতে পারে নাঃ এলোমেলো ডেটা কেবল কৌশলগুলির বিকাশ এবং অপ্টিমাইজেশানকে পরিপূরক করতে পারে। চূড়ান্ত কৌশলটি এখনও বাস্তব বাজারের ডেটাতে এর কার্যকারিতা যাচাই করতে হবে।
এত কিছু বলার পর, কিভাবে আমরা কিছু তথ্য তৈরি করতে পারি? কিভাবে আমরা ব্যাকটেস্টিং সিস্টেমের জন্য তথ্য তৈরি করতে পারি যাতে এটি সহজেই, দ্রুত এবং সহজে ব্যবহার করা যায়?
ডিজাইন আইডিয়া
এই নিবন্ধটি আলোচনার জন্য একটি সূচনা পয়েন্ট সরবরাহ করার জন্য ডিজাইন করা হয়েছে এবং তুলনামূলকভাবে সহজ র্যান্ডম টিকার জেনারেশন গণনা সরবরাহ করে। আসলে, বিভিন্ন সিমুলেশন অ্যালগরিদম, ডেটা মডেল এবং অন্যান্য প্রযুক্তি প্রয়োগ করা যেতে পারে। আলোচনার সীমিত জায়গার কারণে, আমরা জটিল ডেটা সিমুলেশন পদ্ধতি ব্যবহার করব না।
প্ল্যাটফর্ম ব্যাকটেস্টিং সিস্টেমের কাস্টম ডেটা সোর্স ফাংশনকে একত্রিত করে, আমরা পাইথনে একটি প্রোগ্রাম লিখেছি।
-
- K-লাইন ডেটার একটি সেট এলোমেলোভাবে তৈরি করুন এবং ধ্রুবক রেকর্ডিংয়ের জন্য একটি CSV ফাইলে লিখুন, যাতে উত্পন্ন ডেটা সংরক্ষণ করা যায়।
-
- তারপরে ব্যাকটেস্টিং সিস্টেমের জন্য ডেটা উত্স সমর্থন প্রদানের জন্য একটি পরিষেবা তৈরি করুন।
-
- গ্রাফটিতে তৈরি করা K-লাইন ডেটা প্রদর্শন করুন।
কিছু জেনারেশন স্ট্যান্ডার্ড এবং কে-লাইন ডেটার ফাইল স্টোরেজের জন্য নিম্নলিখিত পরামিতি নিয়ন্ত্রণগুলি সংজ্ঞায়িত করা যেতে পারেঃ
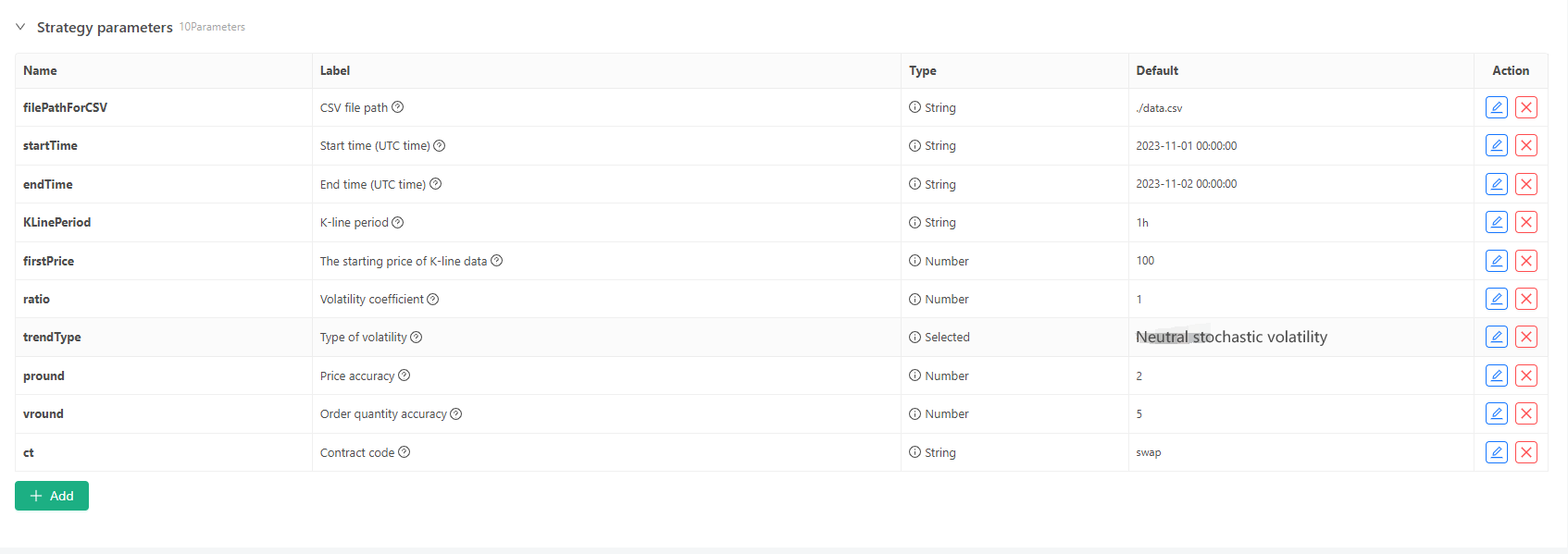
-
র্যান্ডম ডেটা জেনারেশন মোড কে-লাইন ডেটার ওঠানামা টাইপের সিমুলেশনের জন্য, ধনাত্মক এবং নেতিবাচক র্যান্ডম সংখ্যাগুলির সম্ভাব্যতা ব্যবহার করে একটি সহজ নকশা তৈরি করা হয়। যখন উত্পন্ন ডেটা খুব বেশি হয় না, এটি প্রয়োজনীয় বাজারের প্যাটার্নটি প্রতিফলিত করতে পারে না। যদি আরও ভাল পদ্ধতি থাকে তবে কোডের এই অংশটি প্রতিস্থাপন করা যেতে পারে। এই সহজ নকশার উপর ভিত্তি করে, র্যান্ডম নম্বর জেনারেশন পরিসীমা এবং কোডের কিছু সহগগুলি সামঞ্জস্য করা উত্পন্ন ডেটা প্রভাবকে প্রভাবিত করতে পারে।
-
তথ্য যাচাইকরণ উত্পন্ন কে-লাইন ডেটাগুলিকে যুক্তিসঙ্গততার জন্য পরীক্ষা করা দরকার, উচ্চ উদ্বোধনী এবং নিম্ন বন্ধের দাম সংজ্ঞা লঙ্ঘন করে কিনা তা পরীক্ষা করতে এবং কে-লাইন ডেটার ধারাবাহিকতা পরীক্ষা করতে হবে।
ব্যাকটেস্টিং সিস্টেম র্যান্ডম টিকার জেনারেটর
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("the custom data source service receives the request, self.path:", self.path, "query parameter:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is incorrect, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data.detail: ", data["detail"], "Respond to backtesting system requests.")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("Unsupported K-line period, please use 'm', 'h', or 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("Abnormal data:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("Current path:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("The file was written successfully. The following is part of the file content:")
Log("".join(lines[:5]))
else:
Log("Failed to write the file, the file is empty!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("Start the custom data source service thread, and the data is provided by the CSV file.", ", Address/Port: 0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("Failed to start custom data source service!")
Log("error message:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("Generator parameters:", "Start time:", startTime, "End time:", endTime, "K-line period:", KLinePeriod, "Initial price:", firstPrice, "Type of volatility:", arrTrendType[trendType], "Volatility coefficient:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
ব্যাকটেস্টিং সিস্টেমে অনুশীলন
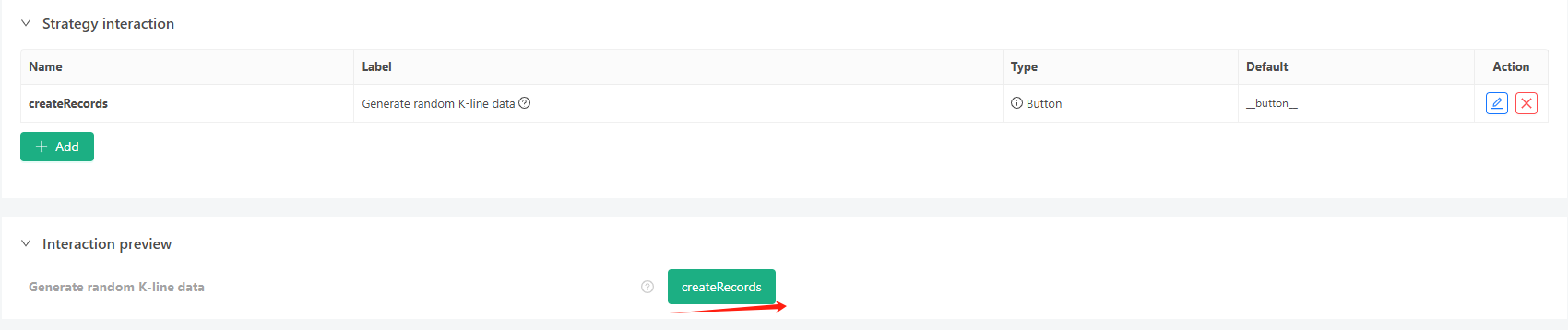
- উপরের স্ট্র্যাটেজি ইনস্ট্যান্স তৈরি করুন, প্যারামিটার কনফিগার করুন এবং এটি চালান।
- লাইভ ট্রেডিং (কৌশল দৃষ্টান্ত) সার্ভারে মোতায়েন ডকার চালানো প্রয়োজন, এটি একটি পাবলিক নেটওয়ার্ক আইপি প্রয়োজন, যাতে ব্যাকটেস্টিং সিস্টেম এটি অ্যাক্সেস করতে পারে এবং তথ্য পেতে পারে।
- ইন্টারঅ্যাকশন বোতামে ক্লিক করুন, এবং কৌশলটি স্বয়ংক্রিয়ভাবে এলোমেলো টিকার ডেটা তৈরি করতে শুরু করবে।
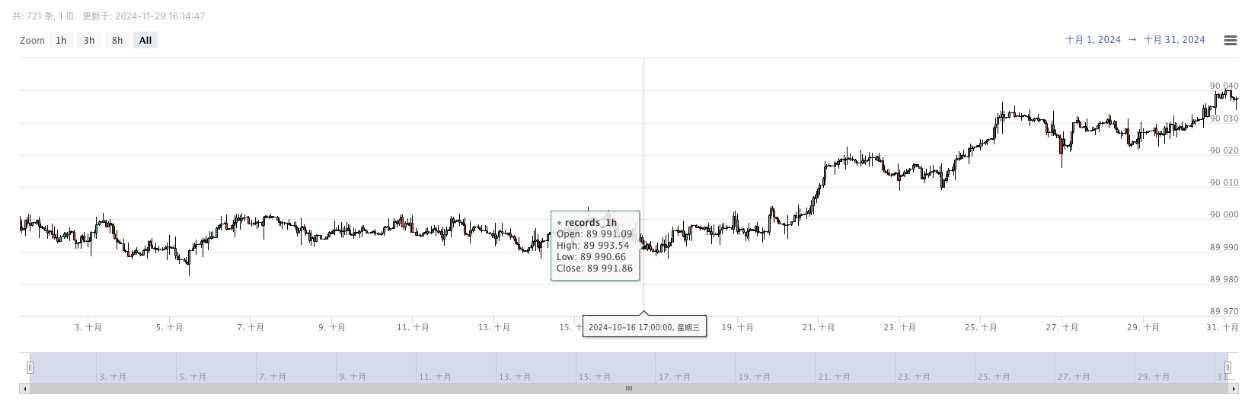
- উত্পন্ন ডেটা সহজ পর্যবেক্ষণের জন্য চার্টে প্রদর্শিত হবে এবং ডেটা স্থানীয় ডেটা.সিএসভি ফাইলে রেকর্ড করা হবে।
- এখন আমরা এই এলোমেলোভাবে উৎপন্ন তথ্য ব্যবহার করতে পারি এবং ব্যাকটেস্টিংয়ের জন্য যে কোন কৌশল ব্যবহার করতে পারিঃ

/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
উপরের তথ্য অনুযায়ী, কনফিগার করুন এবং সামঞ্জস্য করুন।http://xxx.xxx.xxx.xxx:9090হল সার্ভারের আইপি ঠিকানা এবং এলোমেলো টিকার জেনারেশন কৌশলটির খোলা পোর্ট।
এটি কাস্টম ডেটা উত্স, যা প্ল্যাটফর্ম এপিআই নথির কাস্টম ডেটা উত্স বিভাগে পাওয়া যাবে।
- ব্যাকটেস্ট সিস্টেম ডাটা সোর্স সেট আপ করার পর, আমরা এলোমেলো বাজার তথ্য পরীক্ষা করতে পারেনঃ
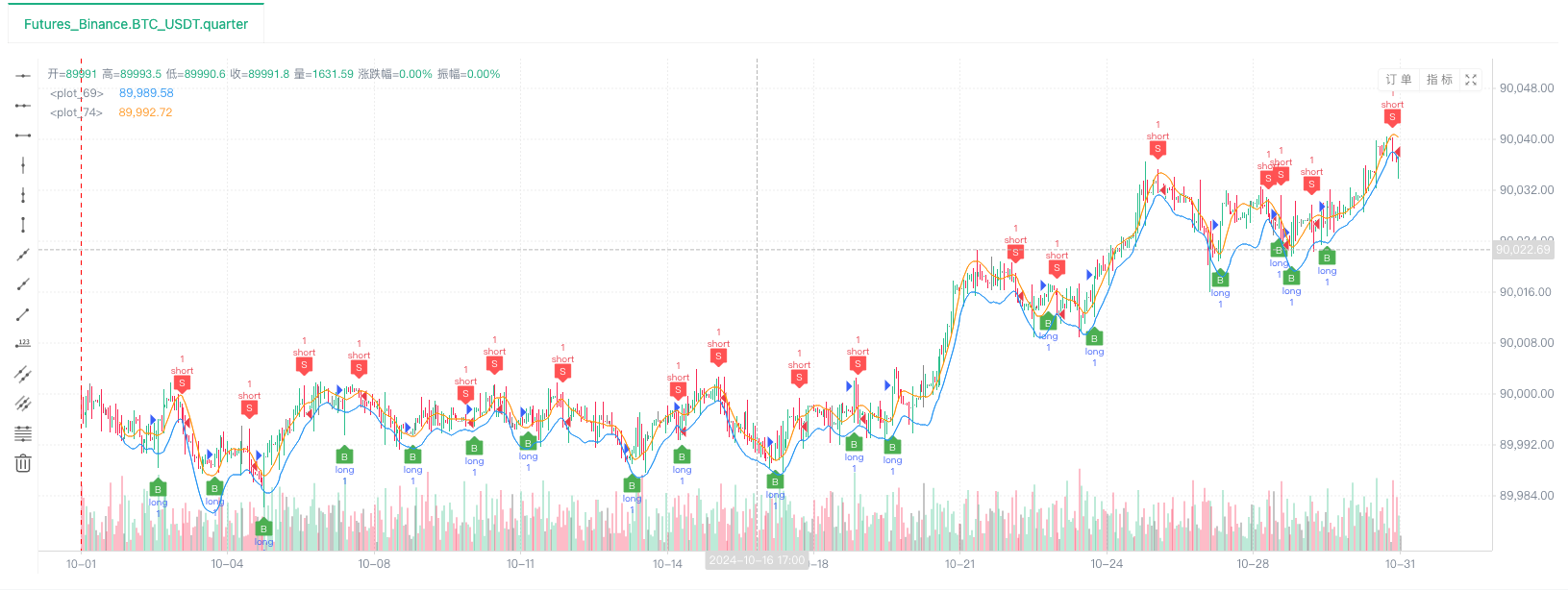
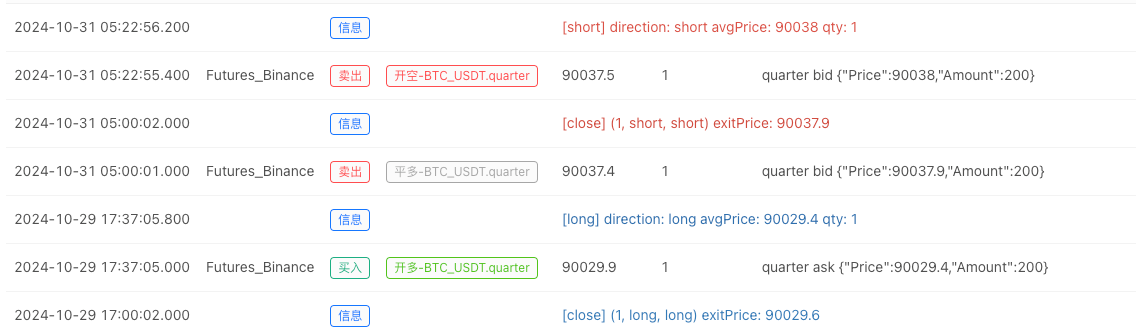
এই সময়ে, ব্যাকটেস্ট সিস্টেমটি আমাদের
- ওহ, হ্যাঁ, আমি প্রায় এটি উল্লেখ করতে ভুলে গেছি! কেন এই পাইথন প্রোগ্রাম র্যান্ডম টিকার জেনারেটর একটি লাইভ ট্রেডিং তৈরি করে তা হল উৎপন্ন কে-লাইন ডেটা প্রদর্শন, অপারেশন এবং প্রদর্শন সহজতর করা। প্রকৃত প্রয়োগে, আপনি একটি স্বাধীন পাইথন স্ক্রিপ্ট লিখতে পারেন, তাই আপনাকে লাইভ ট্রেডিং চালাতে হবে না।
কৌশল উৎস কোডঃব্যাকটেস্টিং সিস্টেম র্যান্ডম টিকার জেনারেটর
আপনার সমর্থন এবং পড়ার জন্য ধন্যবাদ।
- DEX এক্সচেঞ্জের পরিমাণগত অনুশীলন ((1)-- dYdX v4 ব্যবহারের নির্দেশিকা
- ডিজিটাল মুদ্রায় লিড-ল্যাগ স্যুটের ভূমিকা (3)
- ক্রিপ্টোকারেন্সিতে লিড-লেগ আর্বিট্রেজের ভূমিকা (2)
- ডিজিটাল মুদ্রায় লিড-ল্যাগ স্যুটের ভূমিকা (২)
- এফএমজেড প্ল্যাটফর্মের বাহ্যিক সংকেত গ্রহণ নিয়ে আলোচনাঃ কৌশলগতভাবে অন্তর্নির্মিত এইচটিটিপি পরিষেবা সহ সংকেত গ্রহণের জন্য একটি সম্পূর্ণ সমাধান
- এফএমজেড প্ল্যাটফর্মের বহিরাগত সংকেত গ্রহণের অন্বেষণঃ কৌশলগুলি অন্তর্নির্মিত এইচটিটিপি পরিষেবাগুলির সংকেত গ্রহণের সম্পূর্ণ সমাধান
- ক্রিপ্টোকারেন্সিতে লিড-লেগ আর্বিট্রেজের ভূমিকা (1)
- ডিজিটাল মুদ্রায় লিড-ল্যাগ স্যুটের ভূমিকা
- এফএমজেড প্ল্যাটফর্মের বাহ্যিক সংকেত গ্রহণের বিষয়ে আলোচনাঃ বর্ধিত এপিআই বনাম কৌশল অন্তর্নির্মিত এইচটিটিপি পরিষেবা
- এফএমজেড প্ল্যাটফর্মের বহিরাগত সংকেত গ্রহণের অন্বেষণঃ এক্সটেনশান এপিআই বনাম কৌশল অন্তর্নির্মিত এইচটিটিপি পরিষেবা
- র্যান্ডম মার্কেট জেনারেটরের উপর ভিত্তি করে কৌশলগত পরীক্ষার পদ্ধতিগুলি অনুসন্ধান করুন
- এফএমজেড কোয়ান্টের নতুন বৈশিষ্ট্যঃ সহজেই এইচটিটিপি সার্ভিস তৈরি করতে _সার্ভ ফাংশন ব্যবহার করুন
- উদ্ভাবক নতুন বৈশিষ্ট্য পরিমাণঃ _Serve ফাংশন ব্যবহার করে সহজেই HTTP পরিষেবা তৈরি করুন
- FMZ কোয়ান্ট ট্রেডিং প্ল্যাটফর্ম কাস্টম প্রোটোকল অ্যাক্সেস গাইড
- এফএমজেড তহবিলের হার অর্জন এবং পর্যবেক্ষণ কৌশল
- এফএমজেড তহবিলের হার প্রাপ্তি এবং পর্যবেক্ষণ কৌশল কৌশল
- একটি কৌশল টেমপ্লেট আপনাকে ওয়েবসকেট মার্কেটকে নির্বিঘ্নে ব্যবহার করতে দেয়
- একটি নীতিমালা টেমপ্লেট যা আপনাকে ওয়েবসকেট ক্ষেত্রের সাথে নির্বিঘ্নে ব্যবহার করতে দেয়
- ইনভেন্টর কোয়ালিফাইড ট্রেডিং প্ল্যাটফর্মের সাধারণ প্রোটোকল অ্যাক্সেস গাইড
- এফএমজেড আপগ্রেডের পরে কীভাবে দ্রুত একটি ইউনিভার্সাল মাল্টি-কারেন্সি ট্রেডিং কৌশল তৈরি করবেন