ট্রেডিংয়ে মেশিন লার্নিং প্রযুক্তির প্রয়োগ
লেখক:এফএমজেড-লিডিয়া, সৃষ্টিঃ ২০২২-১২-৩০ 10:53:07, আপডেটঃ ২০২৩-০৯-২০ 09:30:09
ট্রেডিংয়ে মেশিন লার্নিং প্রযুক্তির প্রয়োগ
এফএমজেড কান্ট প্ল্যাটফর্মে ডেটা গবেষণার সময় লেনদেনের সমস্যার ক্ষেত্রে মেশিন লার্নিং প্রযুক্তি প্রয়োগ করার চেষ্টা করার পর কিছু সাধারণ সতর্কতা এবং ফাঁদ সম্পর্কে আমার পর্যবেক্ষণ থেকে এই নিবন্ধের অনুপ্রেরণা এসেছে।
যদি আপনি আমার আগের নিবন্ধগুলি না পড়ে থাকেন, তাহলে আমরা আপনাকে এই নিবন্ধের আগে FMZ Quant প্ল্যাটফর্মে প্রতিষ্ঠিত স্বয়ংক্রিয় ডেটা গবেষণা পরিবেশ গাইড এবং ট্রেডিং কৌশল তৈরির পদ্ধতিগত পদ্ধতিটি পড়ার পরামর্শ দিই।
এই দুটি নিবন্ধের ঠিকানা এখানেঃhttps://www.fmz.com/digest-topic/9862এবংhttps://www.fmz.com/digest-topic/9863.
গবেষণার পরিবেশ গঠনের বিষয়ে
এই টিউটোরিয়ালটি সমস্ত দক্ষতার স্তরের উত্সাহী, প্রকৌশলী এবং ডেটা সায়েন্টিস্টদের জন্য। আপনি শিল্পের নেতা বা প্রোগ্রামিং শিক্ষানবিস কিনা, আপনার একমাত্র দক্ষতা যা দরকার তা হ'ল পাইথন প্রোগ্রামিং ভাষার প্রাথমিক বোঝা এবং কমান্ড লাইন অপারেশনগুলির পর্যাপ্ত জ্ঞান (একটি ডেটা সায়েন্স প্রকল্প সেট আপ করতে সক্ষম হওয়া যথেষ্ট) ।
- FMZ কোয়ান্ট ডকার ইনস্টল করুন এবং Anaconda সেটআপ করুন
এফএমজেড কোয়ান্ট প্ল্যাটফর্মFMZ.COMএটি কেবলমাত্র প্রধান মূলধারার এক্সচেঞ্জগুলির জন্য উচ্চমানের ডেটা উত্স সরবরাহ করে না, তবে ডেটা বিশ্লেষণ সম্পন্ন করার পরে স্বয়ংক্রিয় লেনদেন সম্পাদন করতে আমাদের সহায়তা করার জন্য সমৃদ্ধ এপিআই ইন্টারফেসের একটি সেট সরবরাহ করে। এই ইন্টারফেসের সেটে ব্যবহারিক সরঞ্জামগুলি অন্তর্ভুক্ত রয়েছে, যেমন অ্যাকাউন্টের তথ্য অনুসন্ধান করা, উচ্চ, খোলা, নিম্ন, প্রাপ্তির মূল্য, ট্রেডিং ভলিউম এবং বিভিন্ন প্রধান মূলধারার এক্সচেঞ্জগুলির বিভিন্ন সাধারণভাবে ব্যবহৃত প্রযুক্তিগত বিশ্লেষণ সূচক অনুসন্ধান করা। বিশেষত, এটি প্রকৃত ট্রেডিং প্রক্রিয়ার প্রধান প্রধান মূলধারার এক্সচেঞ্জগুলিকে সংযুক্ত করে পাবলিক এপিআই ইন্টারফেসের জন্য শক্তিশালী প্রযুক্তিগত সহায়তা সরবরাহ করে।
উপরে উল্লিখিত সমস্ত বৈশিষ্ট্য একটি Docker-like সিস্টেমে ক্যাপসুল করা হয়। আমাদের যা করতে হবে তা হল আমাদের নিজস্ব ক্লাউড কম্পিউটিং পরিষেবা ক্রয় বা ভাড়া নেওয়া এবং Docker সিস্টেম স্থাপন করা।
FMZ Quant প্ল্যাটফর্মের আনুষ্ঠানিক নামে ডকার সিস্টেমকে ডকার সিস্টেম বলা হয়।
দয়া করে আমার আগের নিবন্ধটি দেখুন কিভাবে একটি ডকার এবং রোবট স্থাপন করবেনঃhttps://www.fmz.com/bbs-topic/9864.
যারা নিজের ক্লাউড কম্পিউটিং সার্ভার ক্রয় করতে চান তারা এই নিবন্ধটি দেখতে পারেনঃhttps://www.fmz.com/digest-topic/5711.
ক্লাউড কম্পিউটিং সার্ভার এবং ডকার সিস্টেম সফলভাবে স্থাপন করার পর, পরবর্তী আমরা পাইথন বর্তমান বৃহত্তম শিল্পকর্ম ইনস্টল করা হবেঃ Anaconda
এই নিবন্ধে প্রয়োজনীয় সমস্ত প্রাসঙ্গিক প্রোগ্রাম পরিবেশ (নির্ভরতা লাইব্রেরি, সংস্করণ পরিচালনা ইত্যাদি) বাস্তবায়ন করার জন্য, সবচেয়ে সহজ উপায় হ'ল অ্যানাকোন্ডা ব্যবহার করা। এটি একটি প্যাকেজড পাইথন ডেটা সায়েন্স বাস্তুতন্ত্র এবং নির্ভরতা লাইব্রেরি ম্যানেজার।
যেহেতু আমরা ক্লাউড সার্ভিসে অ্যানাকোন্ডা ইনস্টল করছি, তাই আমরা ক্লাউড সার্ভারে লিনাক্স সিস্টেম এবং অ্যানাকোন্ডার কমান্ড লাইন সংস্করণ ইনস্টল করার পরামর্শ দিচ্ছি।
Anaconda এর ইনস্টলেশন পদ্ধতির জন্য, অনুগ্রহ করে Anaconda এর অফিসিয়াল গাইড দেখুনঃhttps://www.anaconda.com/distribution/.
আপনি যদি একজন অভিজ্ঞ পাইথন প্রোগ্রামার হন এবং আপনি যদি মনে করেন যে আপনার অ্যানাকোন্ডা ব্যবহার করার দরকার নেই, তবে এটি কোনও সমস্যা নয়। আমি ধরে নেব যে প্রয়োজনীয় নির্ভরশীল পরিবেশ ইনস্টল করার সময় আপনার সাহায্যের প্রয়োজন নেই। আপনি সরাসরি এই বিভাগটি এড়িয়ে যেতে পারেন।
একটি ট্রেডিং কৌশল তৈরি করুন
একটি ট্রেডিং কৌশল চূড়ান্ত আউটপুট নিম্নলিখিত প্রশ্নের উত্তর দিতে হবেঃ
-
দিকনির্দেশনাঃ সম্পদটি সস্তা, ব্যয়বহুল বা ন্যায্য মূল্য কিনা তা নির্ধারণ করুন।
-
ওপেনিং পজিশনের শর্তাবলীঃ যদি সম্পদটি সস্তা বা ব্যয়বহুল হয়, তাহলে আপনাকে লম্বা বা শর্ট পজিশনে যেতে হবে।
-
লেনদেন বন্ধ করাঃ যদি সম্পদের মূল্য যুক্তিসঙ্গত হয় এবং আমাদের কাছে সম্পদে একটি অবস্থান থাকে (পূর্ববর্তী ক্রয় বা বিক্রয়), তাহলে আপনার অবস্থান বন্ধ করা উচিত?
-
মূল্য পরিসীমাঃ যে মূল্য (বা পরিসীমা) এ পজিশন খোলা হয়েছিল।
-
Quantity: ট্রেড করা অর্থের পরিমাণ (যেমন, ডিজিটাল মুদ্রার পরিমাণ বা কমোডিটি ফিউচার লটের সংখ্যা) ।
মেশিন লার্নিং এই প্রশ্নগুলোর প্রত্যেকটির উত্তর দিতে ব্যবহার করা যেতে পারে, কিন্তু এই নিবন্ধের বাকি অংশে, আমরা প্রথম প্রশ্নের উপর ফোকাস করব, যা বাণিজ্যের দিক।
কৌশলগত পন্থা
কৌশল গঠনের জন্য দুটি ধরণের পদ্ধতি রয়েছেঃ একটি মডেল ভিত্তিক; অন্যটি ডেটা মাইনিংয়ের উপর ভিত্তি করে। এই দুটি পদ্ধতি মূলত একে অপরের বিপরীত।
মডেল ভিত্তিক কৌশল নির্মাণে, আমরা বাজারের অকার্যকারিতা মডেল থেকে শুরু করি, গাণিতিক অভিব্যক্তি (যেমন মূল্য এবং মুনাফা) তৈরি করি এবং দীর্ঘ সময়ের মধ্যে তাদের কার্যকারিতা পরীক্ষা করি। এই মডেলটি সাধারণত একটি বাস্তব জটিল মডেলের একটি সরলীকৃত সংস্করণ এবং এর দীর্ঘমেয়াদী তাত্পর্য এবং স্থায়িত্ব যাচাই করা দরকার। সাধারণ প্রবণতা অনুসরণ করে, অর্থ বিপরীত এবং সালিশ কৌশল এই বিভাগে পড়ে।
অন্যদিকে, আমরা প্রথমে দামের নিদর্শনগুলি সন্ধান করি এবং ডেটা মাইনিং পদ্ধতিতে অ্যালগরিদম ব্যবহার করার চেষ্টা করি। এই নিদর্শনগুলির কারণগুলি গুরুত্বপূর্ণ নয়, কারণ কেবলমাত্র সনাক্ত করা নিদর্শনগুলি ভবিষ্যতে পুনরাবৃত্তি করতে থাকবে। এটি একটি অন্ধ বিশ্লেষণ পদ্ধতি, এবং আমাদের এলোমেলো নিদর্শনগুলি থেকে বাস্তব নিদর্শনগুলি সনাক্ত করতে কঠোরভাবে পরীক্ষা করতে হবে।
স্পষ্টতই, মেশিন লার্নিং ডেটা মাইনিং পদ্ধতিতে প্রয়োগ করা খুব সহজ। আসুন দেখি কিভাবে ডেটা মাইনিংয়ের মাধ্যমে লেনদেনের সংকেত তৈরি করতে মেশিন লার্নিং ব্যবহার করা যায়।
কোড উদাহরণটি এফএমজেড কোয়ান্ট প্ল্যাটফর্ম এবং একটি স্বয়ংক্রিয় লেনদেন এপিআই ইন্টারফেসের উপর ভিত্তি করে একটি ব্যাকটেস্টিং সরঞ্জাম ব্যবহার করে। উপরের বিভাগে ডকার স্থাপন এবং অ্যানাকোন্ডা ইনস্টল করার পরে, আপনাকে কেবল আমাদের প্রয়োজনীয় ডেটা সায়েন্স বিশ্লেষণ লাইব্রেরি এবং বিখ্যাত মেশিন লার্নিং মডেল স্কিকিট-লার্ণ ইনস্টল করতে হবে। আমরা এই বিভাগটি আবার যাব না।
pip install -U scikit-learn
ট্রেডিং কৌশল সংকেত তৈরি করতে মেশিন লার্নিং ব্যবহার করুন
- ডেটা মাইনিং আমরা শুরু করার আগে, একটি স্ট্যান্ডার্ড মেশিন লার্নিং সমস্যা সিস্টেম নিম্নলিখিত চিত্র দেখানো হয়ঃ
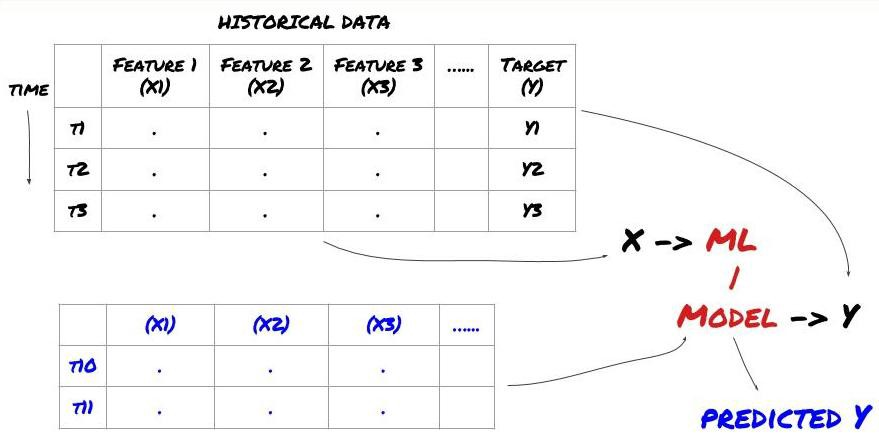
মেশিন লার্নিং সমস্যা সিস্টেম
আমরা যে বৈশিষ্ট্যটি তৈরি করতে যাচ্ছি তার কিছু ভবিষ্যদ্বাণী করার ক্ষমতা থাকতে হবে (এক্স) । আমরা লক্ষ্য পরিবর্তনশীল (ওয়াই) ভবিষ্যদ্বাণী করতে চাই এবং ML মডেলকে প্রশিক্ষণের জন্য ঐতিহাসিক তথ্য ব্যবহার করতে চাই যা প্রকৃত মানের যতটা সম্ভব কাছাকাছি ভবিষ্যদ্বাণী করতে পারে। অবশেষে, আমরা এই মডেলটি ব্যবহার করি নতুন ডেটাতে ভবিষ্যদ্বাণী করার জন্য যেখানে Y অজানা। এটি আমাদের প্রথম ধাপে নিয়ে যায়ঃ
১ম ধাপঃ আপনার প্রশ্নটি লিখুন
- আপনি কি ভবিষ্যদ্বাণী করতে চান? একটি ভাল ভবিষ্যদ্বাণী কি? আপনি ভবিষ্যদ্বাণী ফলাফল মূল্যায়ন কিভাবে?
অর্থাৎ, উপরে আমাদের ফ্রেমওয়ার্কে, Y কি?
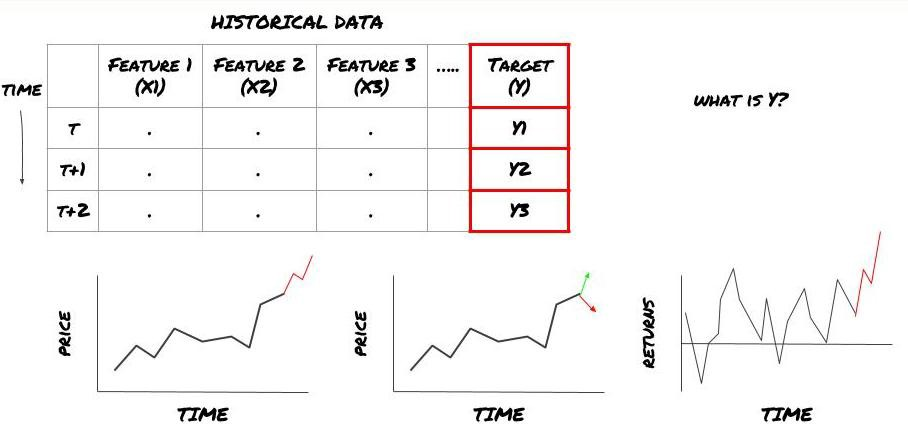
তুমি কি ভবিষ্যদ্বাণী করতে চাও?
আপনি কি ভবিষ্যতের দাম, ভবিষ্যতের রিটার্ন/পিএনএল, কিনুন/বিক্রয় সংকেত, পোর্টফোলিও বরাদ্দ অপ্টিমাইজ করতে চান এবং কার্যকরভাবে লেনদেন চালানোর চেষ্টা করতে চান?
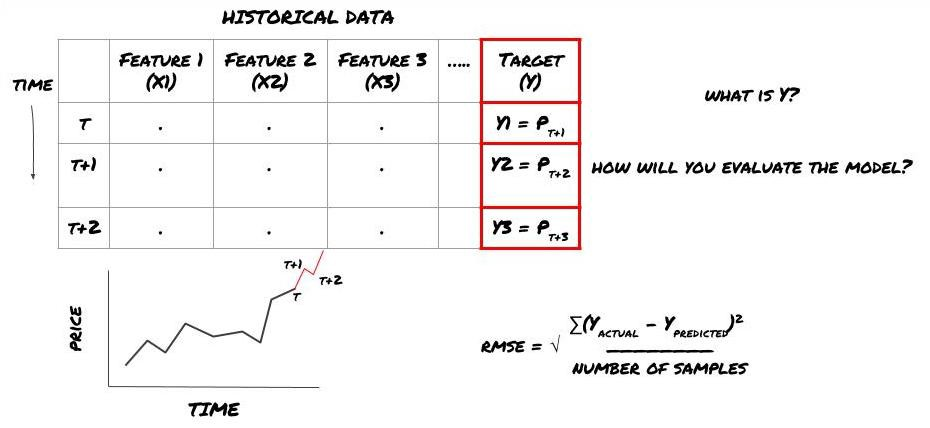
ধরুন আমরা পরবর্তী টাইমস্ট্যাম্পের দামের পূর্বাভাস দেওয়ার চেষ্টা করছি। এই ক্ষেত্রে, Y (t) = মূল্য (t+1) । এখন আমরা আমাদের কাঠামো সম্পূর্ণ করতে ঐতিহাসিক তথ্য ব্যবহার করতে পারি।
মনে রাখবেন যে Y (t) শুধুমাত্র ব্যাকটেস্টে জানা যায়, কিন্তু যখন আমরা আমাদের মডেল ব্যবহার করি, তখন আমরা সময় t এর মূল্য (t + 1) জানি না। আমরা Y (প্রত্যাশিত, t) ভবিষ্যদ্বাণী করতে আমাদের মডেলটি ব্যবহার করি এবং কেবলমাত্র সময় t + 1 এ প্রকৃত মানের সাথে এটি তুলনা করি। এর অর্থ হল যে আপনি Y কে ভবিষ্যদ্বাণী মডেলের একটি বৈশিষ্ট্য হিসাবে ব্যবহার করতে পারবেন না।
একবার আমরা লক্ষ্য Y জানি, আমরা কীভাবে আমাদের পূর্বাভাসগুলি মূল্যায়ন করব তাও সিদ্ধান্ত নিতে পারি। আমরা যে ডেটা চেষ্টা করব তার বিভিন্ন মডেলের মধ্যে পার্থক্য করা গুরুত্বপূর্ণ। আমরা যে সমস্যাটি সমাধান করছি তার ভিত্তিতে আমাদের মডেলের দক্ষতা পরিমাপ করার জন্য একটি সূচক নির্বাচন করুন। উদাহরণস্বরূপ, যদি আমরা দামগুলি পূর্বাভাস দিই তবে আমরা সূচক হিসাবে মূল গড় বর্গক্ষেত্রের ত্রুটি ব্যবহার করতে পারি। কিছু সাধারণভাবে ব্যবহৃত সূচক (ইএমএ, এমএসিডি, বৈচিত্র্য স্কোর ইত্যাদি) এফএমজেড কোয়ান্ট টুলবক্সে প্রাক-কোড করা হয়েছে। আপনি এপিআই ইন্টারফেসের মাধ্যমে এই সূচকগুলিকে বিশ্বব্যাপী কল করতে পারেন।
ভবিষ্যতের দামের পূর্বাভাসের জন্য এমএল ফ্রেমওয়ার্ক
প্রদর্শনের উদ্দেশ্যে, আমরা একটি অনুমানযোগ্য বিনিয়োগ বস্তুর প্রত্যাশিত ভবিষ্যতের রেফারেন্স (বেস) মান পূর্বাভাস দেওয়ার জন্য একটি পূর্বাভাস মডেল তৈরি করব, যেখানেঃ
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
যেহেতু এটি একটি রিগ্রেশন সমস্যা, তাই আমরা RMSE (মূল গড় বর্গক্ষেত্র ত্রুটি) উপর মডেলটি মূল্যায়ন করব। আমরা মূল্যায়ন মানদণ্ড হিসাবে মোট Pnl ব্যবহার করব।
দ্রষ্টব্যঃ RMSE সম্পর্কে প্রাসঙ্গিক গাণিতিক জ্ঞান পাওয়ার জন্য দয়া করে Baidu এনসাইক্লোপিডিয়া দেখুন।
- আমাদের লক্ষ্য: একটি মডেল তৈরি করা যাতে পূর্বাভাসের মান Y এর যতটা সম্ভব কাছাকাছি হয়।
পদক্ষেপ ২ঃ নির্ভরযোগ্য তথ্য সংগ্রহ করুন
এমন তথ্য সংগ্রহ করুন এবং পরিষ্কার করুন যা আপনার সমস্যা সমাধান করতে সাহায্য করতে পারে।
কোন ডেটা আপনাকে বিবেচনা করতে হবে যা লক্ষ্য পরিবর্তনশীল Y পূর্বাভাস দিতে পারে? যদি আমরা মূল্য পূর্বাভাস দিই, আপনি বিনিয়োগের বস্তুর দামের ডেটা, বিনিয়োগের বস্তুর ট্রেডিং পরিমাণের ডেটা, সংশ্লিষ্ট বিনিয়োগের বস্তুর অনুরূপ ডেটা, বিনিয়োগের বস্তুর সূচক স্তর এবং অন্যান্য সামগ্রিক বাজার সূচক এবং অন্যান্য সংশ্লিষ্ট সম্পদের দাম ব্যবহার করতে পারেন।
আপনার এই ডেটার জন্য ডেটা অ্যাক্সেসের অনুমতি সেট করতে হবে এবং আপনার ডেটা সঠিক কিনা তা নিশ্চিত করতে হবে এবং হারিয়ে যাওয়া ডেটা সমাধান করতে হবে (একটি খুব সাধারণ সমস্যা) । একই সাথে, আপনার ডেটা নিরপেক্ষ এবং সমস্ত বাজারের অবস্থার সম্পূর্ণ প্রতিনিধিত্বমূলক কিনা তা নিশ্চিত করুন (উদাহরণস্বরূপ, মুনাফা এবং ক্ষতির একই সংখ্যক দৃশ্যকল্প) মডেলের পক্ষপাত এড়াতে। আপনাকে ডিভিডেন্ড, বিভক্ত বিনিয়োগের লক্ষ্য, অবিরত ইত্যাদি পেতে ডেটা পরিষ্কার করতে হবে।
আপনি যদি এফএমজেড কোয়ান্ট প্ল্যাটফর্ম (এফএমজেড. কম) ব্যবহার করেন তবে আমরা গুগল, ইয়াহু, এনএসই এবং কোয়ান্ডল থেকে বিনামূল্যে বিশ্বব্যাপী ডেটা অ্যাক্সেস করতে পারি; সিটিপি এবং ইসুনির মতো দেশীয় পণ্যের ফিউচারগুলির গভীরতার ডেটা; বিন্যান্স, ওকেএক্স, হুবি এবং বিটমেক্সের মতো মূলধারার ডিজিটাল মুদ্রা বিনিময় থেকে ডেটা। এফএমজেড কোয়ান্ট প্ল্যাটফর্ম এই ডেটাগুলি যেমন বিনিয়োগের লক্ষ্যগুলির বিভক্তি এবং গভীর বাজারের ডেটা প্রাক পরিষ্কার এবং ফিল্টার করে এবং কৌশল বিকাশকারীদের কাছে একটি ফর্ম্যাটে উপস্থাপন করে যা পরিমাণগত অনুশীলনকারীদের পক্ষে সহজেই বোঝা যায়।
এই নিবন্ধের প্রদর্শনকে সহজ করার জন্য, আমরা ভার্চুয়াল বিনিয়োগের লক্ষ্যমাত্রার
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
উপরের কোড দিয়ে, Auquan
ধাপ ৩ঃ তথ্য বিভক্ত করুন
- প্রশিক্ষণ সেট তৈরি করুন, ক্রস যাচাইকরণ করুন এবং ডেটা থেকে এই ডেটা সেটগুলি পরীক্ষা করুন।
এটা খুবই গুরুত্বপূর্ণ পদক্ষেপ!আমরা চালিয়ে যাওয়ার আগে, আমাদের আপনার মডেলকে প্রশিক্ষণের জন্য ডেটা সেটগুলিতে বিভক্ত করা উচিত; মডেলের কর্মক্ষমতা মূল্যায়নের জন্য পরীক্ষার ডেটা সেটগুলি। এটি 60-70% প্রশিক্ষণ সেট এবং 30-40% পরীক্ষার সেটগুলিতে বিভক্ত করার পরামর্শ দেওয়া হয়।
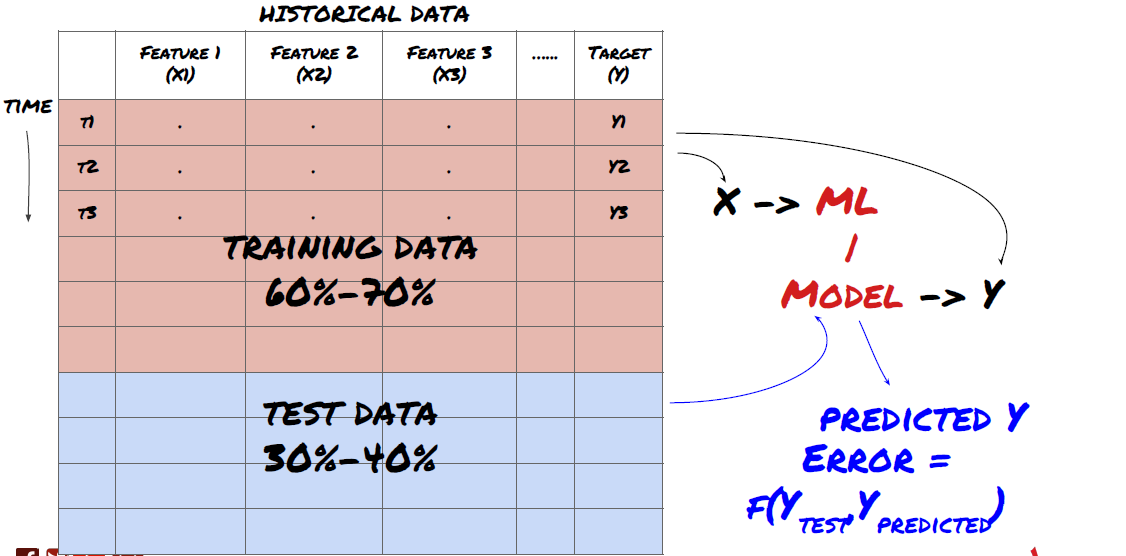
প্রশিক্ষণ সেট এবং পরীক্ষার সেটগুলিতে ডেটা বিভক্ত করুন
যেহেতু প্রশিক্ষণ ডেটা মডেলের পরামিতিগুলি মূল্যায়ন করতে ব্যবহৃত হয়, আপনার মডেলটি এই প্রশিক্ষণ ডেটাগুলিতে অতিরিক্ত ফিট হতে পারে এবং প্রশিক্ষণ ডেটা মডেলের কর্মক্ষমতাকে বিভ্রান্ত করতে পারে। যদি আপনি কোনও পৃথক পরীক্ষার ডেটা সংরক্ষণ না করেন এবং প্রশিক্ষণের জন্য সমস্ত ডেটা ব্যবহার করেন না তবে আপনি জানতে পারবেন না যে আপনার মডেলটি নতুন অদৃশ্য ডেটাতে কতটা ভাল বা খারাপ সম্পাদন করে। এটি রিয়েল-টাইম ডেটাতে প্রশিক্ষিত এমএল মডেলের ব্যর্থতার অন্যতম প্রধান কারণঃ লোকেরা সমস্ত উপলব্ধ ডেটা প্রশিক্ষণ দেয় এবং প্রশিক্ষণ ডেটা সূচকগুলি দ্বারা উত্তেজিত হয়, তবে মডেলটি প্রশিক্ষিত রিয়েল-টাইম ডেটাতে কোনও অর্থপূর্ণ ভবিষ্যদ্বাণী করতে পারে না।
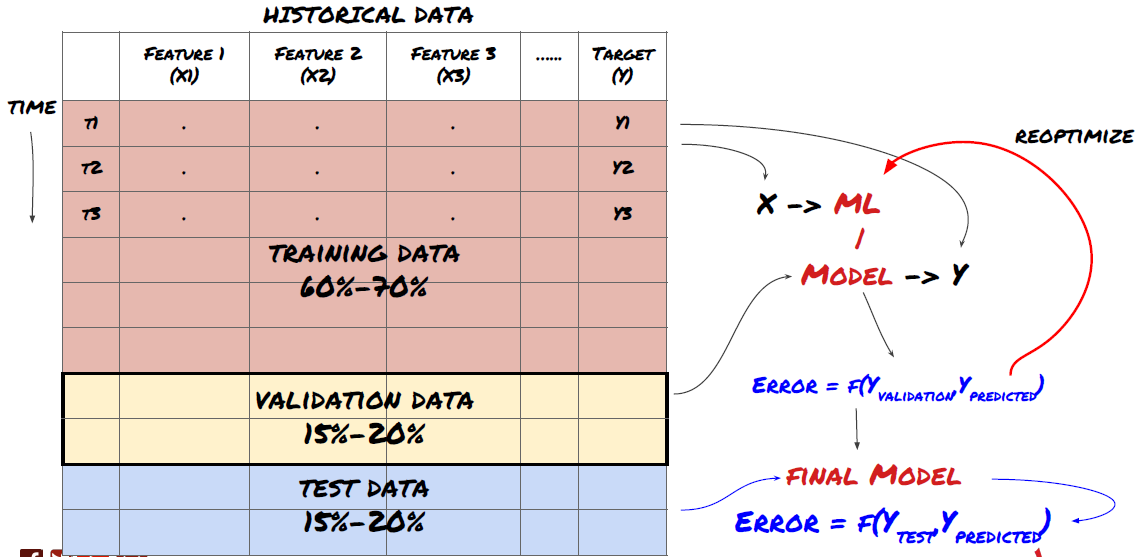
তথ্যকে প্রশিক্ষণ সেট, যাচাইকরণ সেট এবং পরীক্ষার সেটে বিভক্ত করুন
এই পদ্ধতির সাথে সমস্যা আছে। যদি আমরা প্রশিক্ষণ ডেটা বারবার প্রশিক্ষণ করি, পরীক্ষার ডেটাগুলির কর্মক্ষমতা মূল্যায়ন করি এবং আমাদের মডেলটি অপ্টিমাইজ করি যতক্ষণ না আমরা কর্মক্ষমতা নিয়ে সন্তুষ্ট হই, আমরা পরীক্ষার ডেটা প্রশিক্ষণ ডেটার অংশ হিসাবে অব্যক্তভাবে গ্রহণ করি। শেষ পর্যন্ত, আমাদের মডেলটি প্রশিক্ষণ এবং পরীক্ষার ডেটার এই সেটে ভাল পারফর্ম করতে পারে, তবে এটি গ্যারান্টি দিতে পারে না যে এটি নতুন ডেটা ভালভাবে ভবিষ্যদ্বাণী করতে পারে।
এই সমস্যা সমাধানের জন্য, আমরা একটি পৃথক বৈধতা ডেটাসেট তৈরি করতে পারি। এখন, আপনি ডেটা প্রশিক্ষণ দিতে পারেন, বৈধতা ডেটা কর্মক্ষমতা মূল্যায়ন, অপ্টিমাইজ যতক্ষণ না আপনি কর্মক্ষমতা সন্তুষ্ট হন, এবং অবশেষে পরীক্ষা ডেটা পরীক্ষা। এই ভাবে, পরীক্ষা ডেটা দূষিত হবে না, এবং আমরা আমাদের মডেল উন্নত করার জন্য পরীক্ষা ডেটা কোন তথ্য ব্যবহার করবে না।
মনে রাখবেন, একবার আপনি আপনার পরীক্ষার ডেটার পারফরম্যান্স পরীক্ষা করলে, ফিরে যান না এবং আপনার মডেলটি আরও অনুকূল করার চেষ্টা করুন। যদি আপনি দেখতে পান যে আপনার মডেলটি ভাল ফলাফল দেয় না, তবে মডেলটি পুরোপুরি বাতিল করুন এবং আবার শুরু করুন। এটি পরামর্শ দেওয়া হয় যে 60% প্রশিক্ষণ ডেটা, 20% বৈধতা ডেটা এবং 20% পরীক্ষার ডেটা বিভক্ত করা যেতে পারে।
আমাদের প্রশ্নের জন্য, আমাদের তিনটি ডেটা সেট আছে। আমরা একটি প্রশিক্ষণ সেট হিসাবে ব্যবহার করব, দ্বিতীয়টি যাচাইকরণ সেট হিসাবে, এবং তৃতীয়টি আমাদের পরীক্ষার সেট হিসাবে।
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
এর প্রত্যেকটির জন্য, আমরা লক্ষ্য ভেরিয়েবল Y যোগ করি, যা পরবর্তী পাঁচটি বেস মানের গড় হিসাবে সংজ্ঞায়িত করা হয়।
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
ধাপ ৪ঃ ফিচার ইঞ্জিনিয়ারিং
ডেটা আচরণ বিশ্লেষণ করুন এবং ভবিষ্যদ্বাণীমূলক বৈশিষ্ট্য তৈরি করুন
এখন প্রকৃত প্রকল্প নির্মাণ শুরু হয়েছে। বৈশিষ্ট্য নির্বাচন এর সোনার নিয়ম হল যে পূর্বাভাস ক্ষমতা প্রধানত বৈশিষ্ট্য থেকে আসে, মডেল থেকে নয়। আপনি দেখতে পাবেন যে বৈশিষ্ট্য নির্বাচন মডেল নির্বাচন তুলনায় কর্মক্ষমতা উপর অনেক বড় প্রভাব আছে। বৈশিষ্ট্য নির্বাচন জন্য কিছু বিবেচনারঃ
-
লক্ষ্য ভেরিয়েবলের সাথে সম্পর্কের অন্বেষণ না করে এলোমেলোভাবে বৈশিষ্ট্যগুলির একটি বড় সেট নির্বাচন করবেন না।
-
লক্ষ্য ভেরিয়েবলের সাথে সামান্য বা কোনও সম্পর্কই অতিরিক্ত ফিটিংয়ের কারণ হতে পারে।
-
আপনার নির্বাচিত বৈশিষ্ট্যগুলি একে অপরের সাথে অত্যন্ত সম্পর্কিত হতে পারে, এই ক্ষেত্রে একটি ছোট সংখ্যক বৈশিষ্ট্যও লক্ষ্যকে ব্যাখ্যা করতে পারে।
-
আমি সাধারণত কিছু স্বজ্ঞাত বৈশিষ্ট্য তৈরি করি, লক্ষ্য ভেরিয়েবল এবং এই বৈশিষ্ট্যগুলির মধ্যে সম্পর্ক পরীক্ষা করি, এবং কোনটি ব্যবহার করতে হবে তা সিদ্ধান্ত নেওয়ার জন্য তাদের মধ্যে সম্পর্ক।
-
আপনি সর্বোচ্চ তথ্য সহগ (এমআইসি) অনুযায়ী প্রার্থী বৈশিষ্ট্যগুলি বাছাই করার জন্য প্রধান উপাদান বিশ্লেষণ (পিসিএ) এবং অন্যান্য পদ্ধতিগুলি সম্পাদন করার চেষ্টা করতে পারেন।
বৈশিষ্ট্য রূপান্তর/স্বাভাবিককরণঃ
এমএল মডেলগুলি সাধারণীকরণের ক্ষেত্রে ভাল সম্পাদন করে। তবে, সময় সিরিজের ডেটা নিয়ে কাজ করার সময় সাধারণীকরণ কঠিন, কারণ ভবিষ্যতের ডেটা ব্যাপ্তি অজানা। আপনার ডেটা স্বাভাবিকীকরণের ব্যাপ্তির বাইরে থাকতে পারে, যা মডেল ত্রুটির দিকে পরিচালিত করে। তবে আপনি এখনও কিছু স্তরের স্থিতিশীলতা জোর করার চেষ্টা করতে পারেনঃ
-
স্কেলিংঃ স্ট্যান্ডার্ড ডিভিয়েশন বা কার্টিল পরিসরের মাধ্যমে বৈশিষ্ট্যগুলি ভাগ করা।
-
সেন্টারিংঃ বর্তমান মান থেকে ঐতিহাসিক গড় মান বিয়োগ করুন।
-
নরমালাইজেশনঃ উপরে উল্লিখিত (এক্স - গড়) /stdev এর দুটি প্রত্যাবর্তনশীল সময়কাল।
-
নিয়মিত নরমালাইজেশনঃ -১ থেকে +১ এর পরিসরে ডেটা স্ট্যান্ডার্ডাইজ করুন এবং ব্যাকট্র্যাকিং সময়ের মধ্যে কেন্দ্রটি পুনরায় নির্ধারণ করুন (x-min) / ((max min) ।
মনে রাখবেন যেহেতু আমরা ঐতিহাসিক ধ্রুবক গড় মান, স্ট্যান্ডার্ড ডিভিয়েশন, সর্বোচ্চ বা ন্যূনতম মান ব্যাকট্র্যাকিং সময়ের পরে ব্যবহার করি, বৈশিষ্ট্যটির স্বাভাবিকীকরণ মান বিভিন্ন সময়ে বিভিন্ন প্রকৃত মান উপস্থাপন করবে। উদাহরণস্বরূপ, যদি বৈশিষ্ট্যটির বর্তমান মান 5 হয় এবং পরপর 30 টি সময়ের জন্য গড় মান 4.5 হয় তবে এটি কেন্দ্রীকরণের পরে 0.5 তে রূপান্তরিত হবে। এর পরে, যদি পরপর 30 টি সময়ের গড় মান 3 হয় তবে 3.5 মান 0.5 হয়ে যায়। এটি ভুল মডেলের কারণ হতে পারে। অতএব, স্বাভাবিকীকরণ জটিল, এবং আপনাকে মডেলের কর্মক্ষমতা উন্নত করে (যদি সত্যিই থাকে) তা খুঁজে বের করতে হবে।
আমাদের সমস্যার প্রথম পুনরাবৃত্তির জন্য, আমরা মিশ্র পরামিতি ব্যবহার করে একটি বড় সংখ্যা বৈশিষ্ট্য তৈরি করেছি। পরে আমরা দেখতে চেষ্টা করব যে আমরা বৈশিষ্ট্যগুলির সংখ্যা হ্রাস করতে পারি কিনা।
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
ধাপ ৫ঃ মডেল নির্বাচন
নির্বাচিত প্রশ্ন অনুযায়ী উপযুক্ত পরিসংখ্যানগত/এমএল মডেল নির্বাচন করুন।
মডেলের পছন্দটি কীভাবে সমস্যাটি গঠিত হয় তার উপর নির্ভর করে। আপনি কি তত্ত্বাবধানে সমাধান করছেন (বৈশিষ্ট্য ম্যাট্রিক্সের প্রতিটি পয়েন্ট এক্সকে লক্ষ্য ভেরিয়েবল Y এর সাথে ম্যাপ করা হয়) বা তত্ত্বাবধানে শেখার (একটি প্রদত্ত ম্যাপিং ছাড়াই, মডেলটি একটি অজানা প্যাটার্ন শিখতে চেষ্টা করে)? আপনি কি রিগ্রেশন (ভবিষ্যতে সময়ে প্রকৃত দামের পূর্বাভাস) বা শ্রেণিবদ্ধকরণ (ভবিষ্যতে সময়ে কেবল মূল্যের দিকনির্দেশের পূর্বাভাস (বৃদ্ধি / হ্রাস)) নিয়ে কাজ করছেন?

তত্ত্বাবধানে বা তত্ত্বাবধানে শেখার

পুনরাবৃত্তি বা শ্রেণীবিভাগ
কিছু সাধারণ তত্ত্বাবধানে শেখার অ্যালগরিদম আপনাকে শুরু করতে সাহায্য করতে পারেঃ
-
লিনিয়ার রিগ্রেশন (প্যারামিটার, রিগ্রেশন)
-
লজিস্টিক রিগ্রেশন (প্যারামিটার, শ্রেণীবিভাগ)
-
K-Nearest Neighbor (KNN) অ্যালগরিদম (কেস-ভিত্তিক, রিগ্রেশন)
-
এসভিএম, এসভিআর (প্যারামিটার, শ্রেণীবিভাগ এবং রিগ্রেশন)
-
সিদ্ধান্ত গাছ
-
সিদ্ধান্ত বন
আমি একটি সহজ মডেল দিয়ে শুরু করার পরামর্শ দিচ্ছি, যেমন রৈখিক বা লজিস্টিক রিগ্রেশন, এবং প্রয়োজন অনুসারে সেখান থেকে আরও জটিল মডেল তৈরি করুন। এটিও সুপারিশ করা হয় যে আপনি মডেলের পিছনে গণিতটি অন্ধভাবে ব্ল্যাক বক্স হিসাবে ব্যবহার করার পরিবর্তে পড়ুন।
ধাপ ৬ঃ প্রশিক্ষণ, যাচাইকরণ এবং অপ্টিমাইজেশন (ধাপ ৪-৬ পুনরাবৃত্তি করুন)
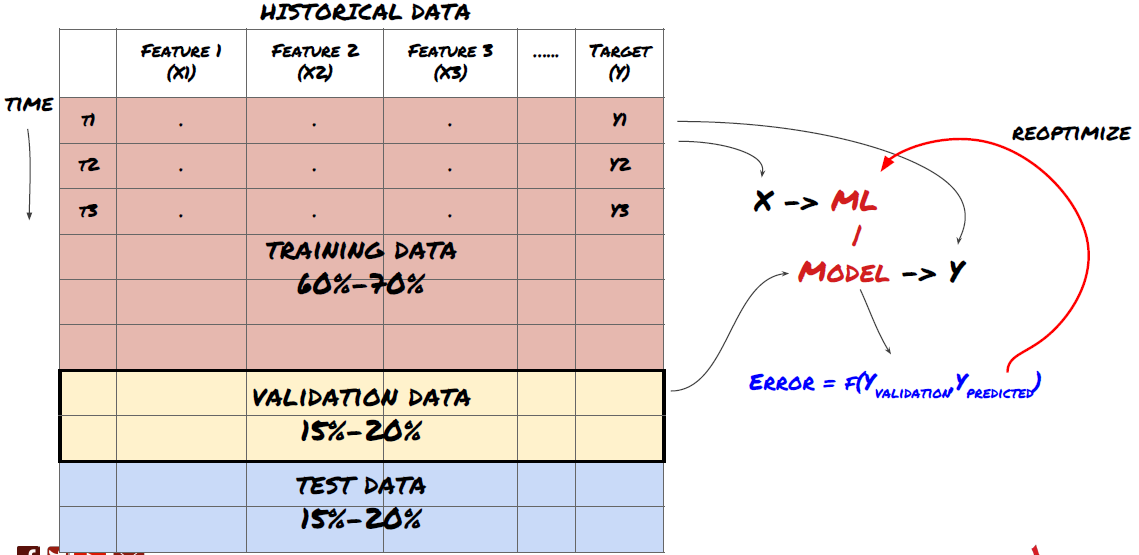
আপনার মডেলকে প্রশিক্ষণ এবং অপ্টিমাইজ করার জন্য প্রশিক্ষণ এবং যাচাইকরণ ডেটা সেট ব্যবহার করুন
এখন আপনি অবশেষে মডেলটি তৈরি করতে প্রস্তুত। এই পর্যায়ে, আপনি আসলে মডেল এবং মডেল প্যারামিটারগুলি পুনরাবৃত্তি করেন। প্রশিক্ষণ ডেটাতে আপনার মডেলকে প্রশিক্ষণ দিন, যাচাইকরণ ডেটাতে এর পারফরম্যান্স পরিমাপ করুন এবং তারপরে ফিরে যান, অপ্টিমাইজ করুন, পুনরায় প্রশিক্ষণ দিন এবং এটি মূল্যায়ন করুন। যদি আপনি মডেলের পারফরম্যান্সের সাথে সন্তুষ্ট না হন তবে দয়া করে অন্য মডেলটি চেষ্টা করুন। আপনি অবশেষে একটি মডেল না পাওয়া পর্যন্ত আপনি এই পর্যায়ে অনেকবার চক্র করেন।
যখন আপনার পছন্দের মডেল থাকবে, তখনই পরবর্তী ধাপে যেতে পারবেন।
আমাদের প্রদর্শন সমস্যার জন্য, আসুন একটি সহজ লিনিয়ার রিগ্রেশন দিয়ে শুরু করিঃ
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
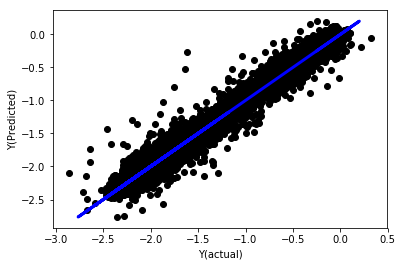
নরমালাইজেশন ছাড়াই লিনিয়ার রিগ্রেশন
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
মডেল সহগগুলি দেখুন। আমরা আসলে তাদের তুলনা করতে পারি না বা বলতে পারি না যে কোনটি গুরুত্বপূর্ণ, কারণ তারা সবাই বিভিন্ন স্কেলে রয়েছে। আসুন তাদের একই অনুপাতের সাথে সামঞ্জস্যপূর্ণ করার জন্য নরমালাইজেশন চেষ্টা করি এবং কিছু মসৃণতা প্রয়োগ করি।
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
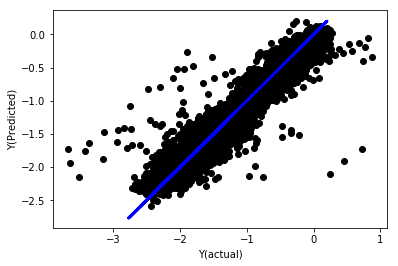
নরমালাইজেশনের সাথে লিনিয়ার রিগ্রেশন
Mean squared error: 0.05
Variance score: 0.90
এই মডেলটি আগের মডেলকে উন্নত করে না, কিন্তু এটি খারাপ নয়। এখন আমরা কোনটি আসলে গুরুত্বপূর্ণ তা দেখতে সহগগুলি তুলনা করতে পারি।
আসুন কোঅফিসিয়েন্টগুলো দেখে নিই:
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
এর ফলাফল হল:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
আমরা স্পষ্টভাবে দেখতে পাচ্ছি যে কিছু বৈশিষ্ট্য অন্যদের তুলনায় উচ্চতর সহগ রয়েছে এবং তাদের ভবিষ্যদ্বাণী করার ক্ষমতা আরও শক্তিশালী হতে পারে।
আসুন বিভিন্ন বৈশিষ্ট্যের মধ্যে সম্পর্ক দেখি।
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
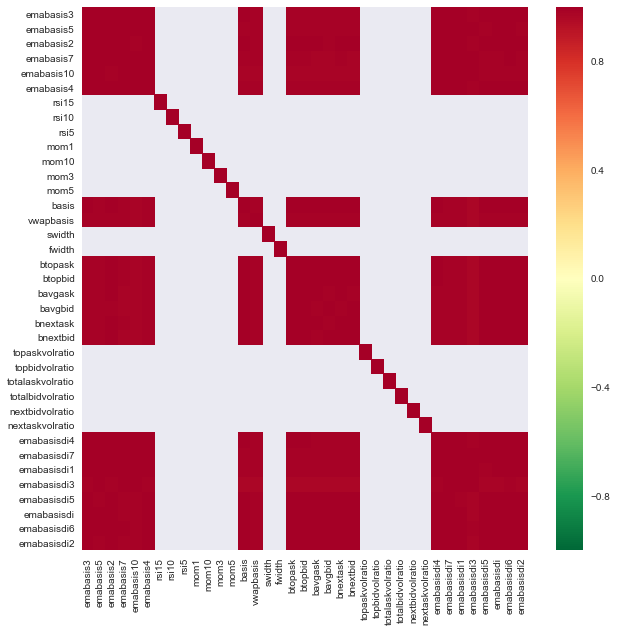
বৈশিষ্ট্যগুলির মধ্যে সম্পর্ক
গাঢ় লাল এলাকাগুলি অত্যন্ত সম্পর্কিত ভেরিয়েবলগুলি উপস্থাপন করে। আসুন আবার কিছু বৈশিষ্ট্য তৈরি / সংশোধন করি এবং আমাদের মডেলটি উন্নত করার চেষ্টা করি।
উদাহরণস্বরূপ, আমি সহজেই emabasisdi7 এর মত বৈশিষ্ট্যগুলিকে বাদ দিতে পারি, যা অন্য বৈশিষ্ট্যগুলির কেবল রৈখিক সংমিশ্রণ।
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
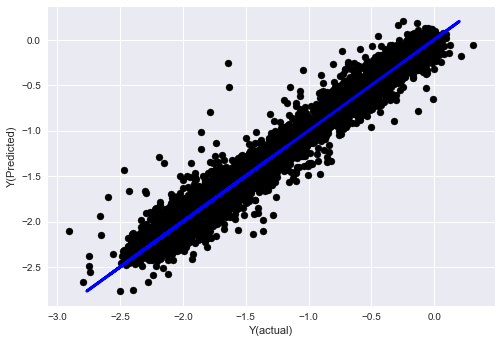
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
দেখুন, আমাদের মডেলের পারফরম্যান্স পরিবর্তন হয়নি। আমাদের লক্ষ্য ভেরিয়েবল ব্যাখ্যা করার জন্য আমাদের কেবল কয়েকটি বৈশিষ্ট্য দরকার। আমি আপনাকে উপরের বৈশিষ্ট্যগুলির আরও চেষ্টা করার পরামর্শ দিচ্ছি, নতুন সমন্বয় ইত্যাদি চেষ্টা করুন, আমাদের মডেলটি কী উন্নত করতে পারে তা দেখতে।
আমরা আরও জটিল মডেল চেষ্টা করতে পারি মডেলের পরিবর্তন কর্মক্ষমতা উন্নত করতে পারে কিনা তা দেখতে।
- কে-নিকটতম প্রতিবেশী (কেএনএন) অ্যালগরিদম
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
- এসভিআর
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- সিদ্ধান্ত গাছ
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
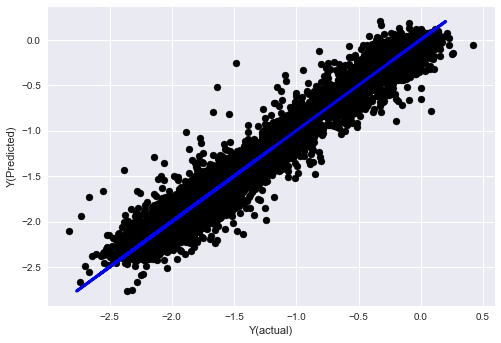
ধাপ ৭ঃ পরীক্ষার তথ্য ব্যাক-টেস্ট করুন
প্রকৃত নমুনা তথ্যের কার্যকারিতা পরীক্ষা করুন
পরীক্ষার ডেটা সেটগুলিতে ব্যাকটেস্টিং পারফরম্যান্স (অস্পৃশ্য)
এটি একটি সমালোচনামূলক মুহূর্ত। আমরা পরীক্ষার তথ্যের শেষ ধাপ থেকে আমাদের চূড়ান্ত অপ্টিমাইজেশান মডেল চালাই, আমরা শুরুতে এটি একপাশে রেখেছি এবং আমরা এখনও পর্যন্ত তথ্য স্পর্শ করি নি।
এটি আপনাকে রিয়েল-টাইম ট্রেডিং শুরু করার সময় আপনার মডেলটি কীভাবে নতুন এবং অদৃশ্য ডেটাতে কার্যকর হবে তার একটি বাস্তবসম্মত প্রত্যাশা দেয়। অতএব, আপনার কাছে একটি পরিষ্কার ডেটা সেট রয়েছে তা নিশ্চিত করা প্রয়োজন যা মডেলটি প্রশিক্ষণ বা যাচাই করতে ব্যবহৃত হয় না।
আপনি যদি পরীক্ষার ডেটার ব্যাকটেস্ট ফলাফল পছন্দ না করেন তবে দয়া করে মডেলটি বাতিল করুন এবং আবার শুরু করুন। কখনই ফিরে যান না বা আপনার মডেলটি পুনরায় অনুকূলিত করুন না, যা ওভার ফিটিংয়ের দিকে পরিচালিত করবে! (এছাড়াও একটি নতুন পরীক্ষার ডেটা সেট তৈরি করার পরামর্শ দেওয়া হয়, কারণ এই ডেটা সেটটি এখন দূষিত; যখন মডেলটি বাতিল করা হয়, তখন আমরা ইতিমধ্যে ডেটা সেটের সামগ্রীটি অবিকল্পিতভাবে জানি) ।
এখানে আমরা এখনও Auquan
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
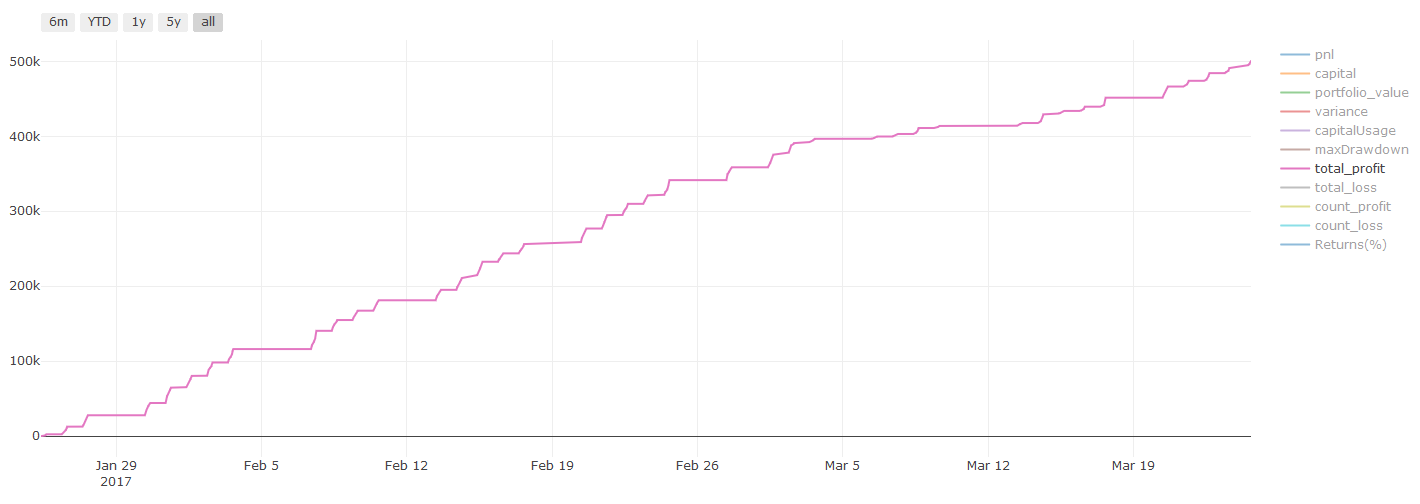
ব্যাকটেস্টিং ফলাফল, Pnl মার্কিন ডলারে গণনা করা হয় (Pnl লেনদেনের খরচ এবং অন্যান্য ফি অন্তর্ভুক্ত নয়)
ধাপ ৮ঃ মডেল উন্নত করার জন্য অন্যান্য পদ্ধতি
রোলিং যাচাইকরণ, সেট লার্নিং, ব্যাগিং এবং বুমিং
আরও তথ্য সংগ্রহ, আরও ভাল বৈশিষ্ট্য তৈরি বা আরও মডেল চেষ্টা করার পাশাপাশি, আরও কয়েকটি বিষয় রয়েছে যা আপনি উন্নত করার চেষ্টা করতে পারেন।
১. রোলিং যাচাইকরণ
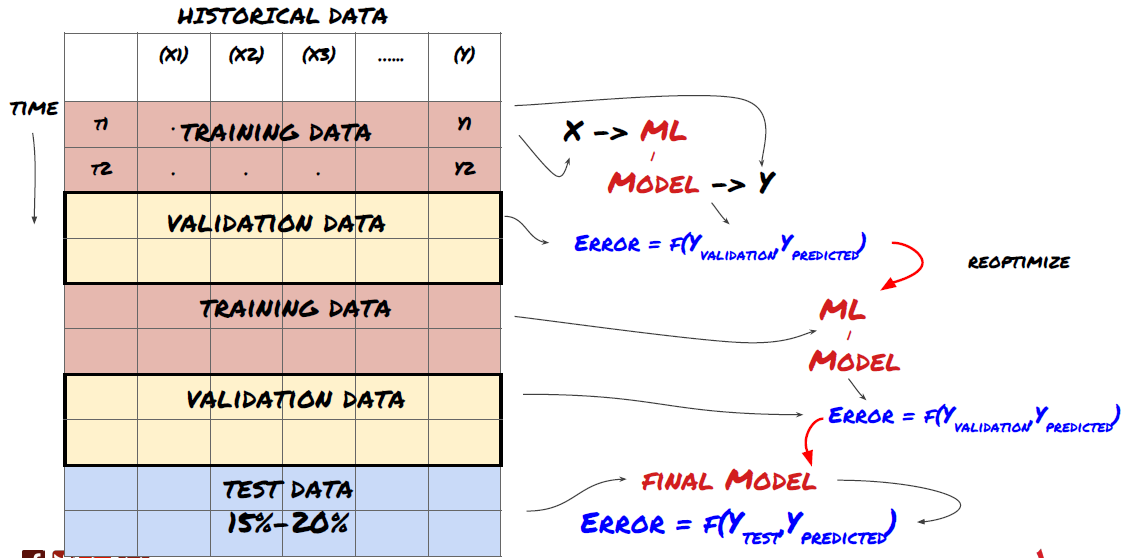
রোলিং যাচাইকরণ
বাজারের অবস্থা খুব কমই একই থাকে। ধরুন আপনার কাছে এক বছরের ডেটা আছে, এবং আপনি জানুয়ারী থেকে আগস্ট পর্যন্ত ডেটা প্রশিক্ষণের জন্য ব্যবহার করেন, এবং সেপ্টেম্বর থেকে ডিসেম্বর পর্যন্ত ডেটা ব্যবহার করে আপনার মডেলটি পরীক্ষা করুন। আপনি শেষ পর্যন্ত বাজারের নির্দিষ্ট অবস্থার জন্য প্রশিক্ষণ নিতে পারেন। সম্ভবত বছরের প্রথমার্ধে বাজারের কোনও ওঠানামা ছিল না, এবং কিছু চরম সংবাদ সেপ্টেম্বরে বাজারে তীব্র উত্থানের দিকে পরিচালিত করেছিল। আপনার মডেলটি এই মডেলটি শিখতে সক্ষম হবে না, এবং এটি আপনাকে আবর্জনা পূর্বাভাসের ফলাফল আনবে।
জানুয়ারি থেকে ফেব্রুয়ারি পর্যন্ত প্রশিক্ষণ, মার্চ মাসে যাচাইকরণ, এপ্রিল থেকে মে পর্যন্ত পুনঃ প্রশিক্ষণ, জুন মাসে যাচাইকরণ ইত্যাদির মতো অগ্রগামী রোলিং যাচাইকরণের চেষ্টা করা ভাল।
২. সেট লার্নিং
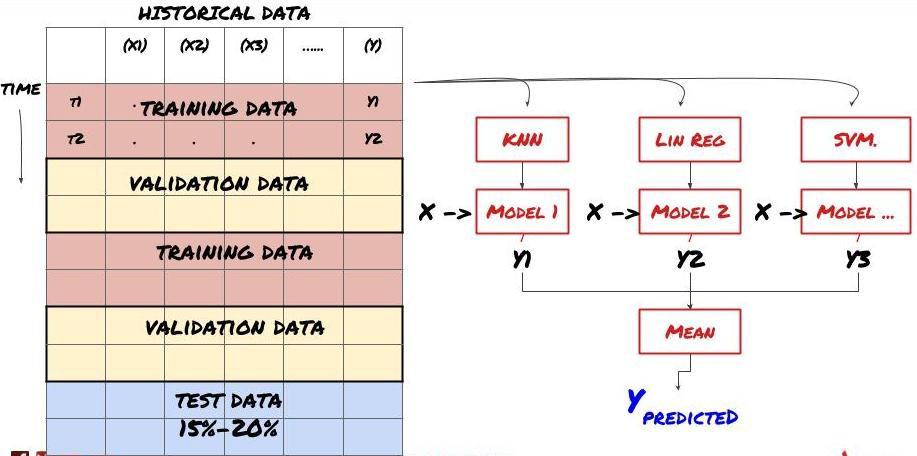
সেট লার্নিং
কিছু মডেল নির্দিষ্ট পরিস্থিতির পূর্বাভাসে খুব কার্যকর হতে পারে, যখন মডেলগুলি অন্যান্য পরিস্থিতি বা নির্দিষ্ট পরিস্থিতিতে পূর্বাভাসে অত্যন্ত ওভারফিট হতে পারে। ত্রুটি এবং ওভারফিট হ্রাস করার একটি উপায় হ'ল বিভিন্ন মডেলের একটি সেট ব্যবহার করা। আপনার পূর্বাভাসটি অনেক মডেল দ্বারা তৈরি পূর্বাভাসের গড় হবে এবং বিভিন্ন মডেলের ত্রুটিগুলি অফসেট বা হ্রাস করা যেতে পারে। কিছু সাধারণ সেট পদ্ধতি হ'ল ব্যাগিং এবং বুস্টিং।
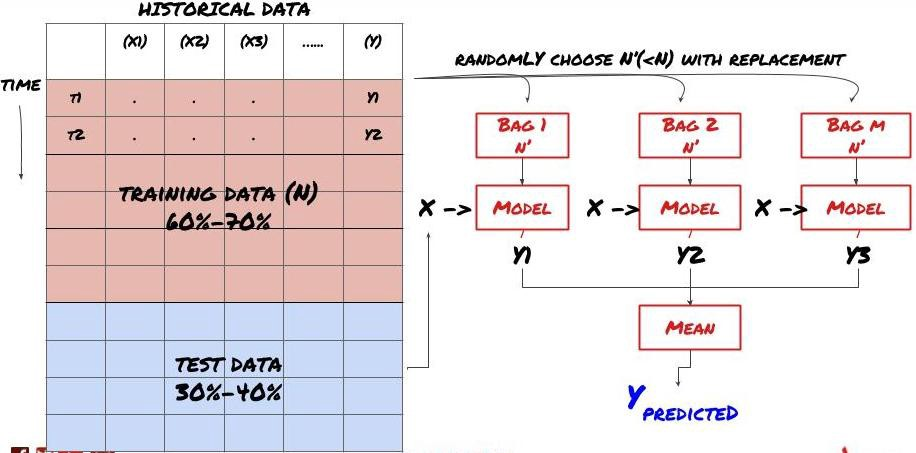
প্যাকিং
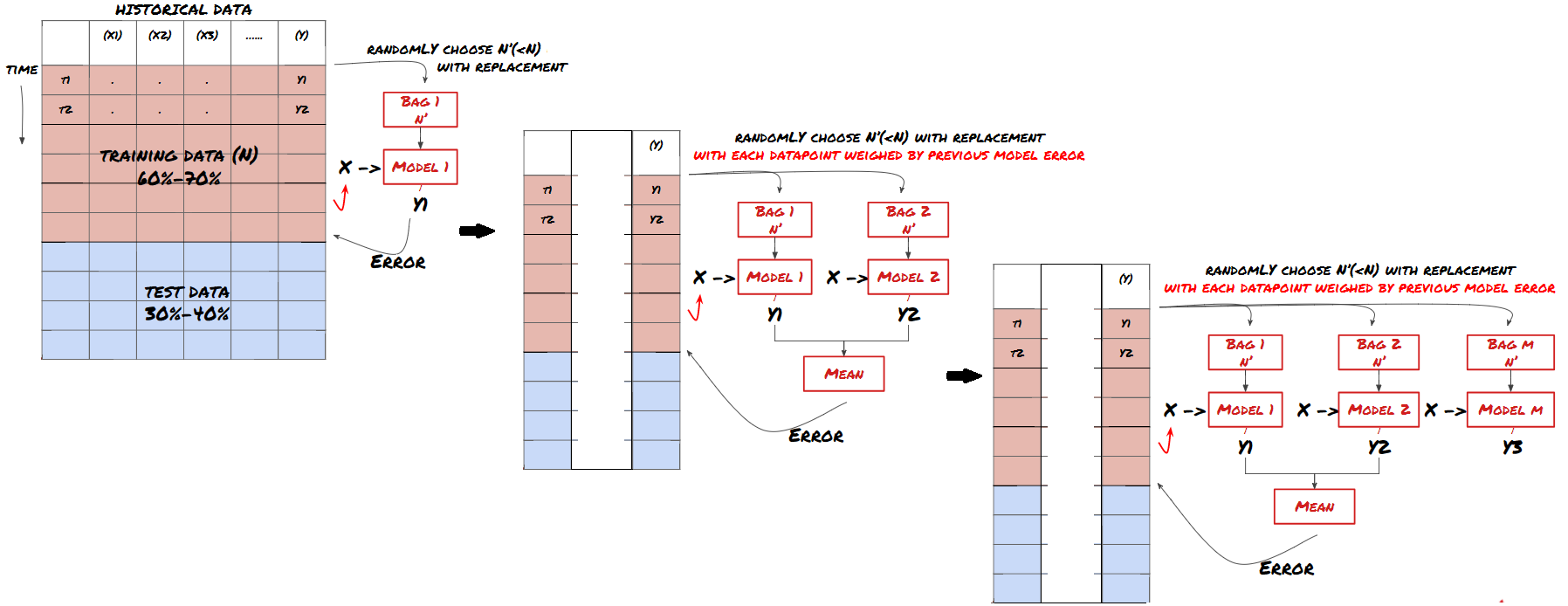
উত্সাহ
সংক্ষিপ্ততার স্বার্থে, আমি এই পদ্ধতিগুলি এড়িয়ে যাব, তবে আপনি অনলাইনে আরও তথ্য পেতে পারেন।
আসুন আমাদের সমস্যার জন্য একটি সেট পদ্ধতি চেষ্টা করিঃ
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
এখন পর্যন্ত আমরা অনেক জ্ঞান এবং তথ্য সংগ্রহ করেছি। আসুন দ্রুত পর্যালোচনা করিঃ
-
আপনার সমস্যা সমাধান করুন;
-
নির্ভরযোগ্য তথ্য সংগ্রহ এবং তথ্য পরিষ্কার করা;
-
প্রশিক্ষণ, যাচাইকরণ এবং পরীক্ষার সেটগুলিতে ডেটা বিভক্ত করুন;
-
বৈশিষ্ট্য তৈরি করুন এবং তাদের আচরণ বিশ্লেষণ করুন;
-
আচরণ অনুযায়ী উপযুক্ত প্রশিক্ষণ মডেল নির্বাচন করুন;
-
আপনার মডেলকে প্রশিক্ষণের জন্য এবং ভবিষ্যদ্বাণী করার জন্য প্রশিক্ষণ তথ্য ব্যবহার করুন;
-
ভেরিফিকেশন সেটের পারফরম্যান্স পরীক্ষা করুন এবং পুনরায় অপ্টিমাইজ করুন;
-
পরীক্ষার সেটের চূড়ান্ত পারফরম্যান্স যাচাই করুন।
এটা কি আপনার মাথায় আসেনি? কিন্তু এটা এখনো শেষ হয়নি। আপনার কাছে শুধুমাত্র একটি নির্ভরযোগ্য পূর্বাভাস মডেল আছে। আমাদের কৌশলতে আমরা আসলে কি চেয়েছিলাম তা মনে আছে? সুতরাং আপনার প্রয়োজন নেইঃ
-
ট্রেডিংয়ের দিকনির্দেশনা নির্ধারণের জন্য ভবিষ্যদ্বাণীমূলক মডেলের উপর ভিত্তি করে সংকেত তৈরি করা।
-
খোলা ও বন্ধ পজিশন চিহ্নিত করার জন্য নির্দিষ্ট কৌশল তৈরি করা;
-
পজিশন এবং মূল্য চিহ্নিত করার জন্য সিস্টেমটি চালান।
উপরে উল্লিখিতটি FMZ Quant প্ল্যাটফর্ম ব্যবহার করবে (FMZ.COM) এফএমজেড কোয়ান্ট প্ল্যাটফর্মে, অত্যন্ত ক্যাপসুলযুক্ত এবং নিখুঁত এপিআই ইন্টারফেস রয়েছে, পাশাপাশি অর্ডার এবং ট্রেডিং ফাংশনগুলি যা বিশ্বব্যাপী কল করা যেতে পারে। আপনাকে একের পর এক বিভিন্ন এক্সচেঞ্জের এপিআই ইন্টারফেসগুলি সংযুক্ত এবং যুক্ত করার দরকার নেই। এফএমজেড কোয়ান্ট প্ল্যাটফর্মের কৌশল স্কোয়ারে, এই নিবন্ধে মেশিন লার্নিং পদ্ধতির সাথে মেলে এমন অনেক পরিপক্ক এবং নিখুঁত বিকল্প কৌশল রয়েছে, এটি আপনার নির্দিষ্ট কৌশলটিকে আরও শক্তিশালী করবে। কৌশল স্কোয়ারটি অবস্থিতঃhttps://www.fmz.com/square.
** লেনদেনের খরচ সম্পর্কে গুরুত্বপূর্ণ দ্রষ্টব্যঃ ** আপনার মডেল আপনাকে বলবে যখন নির্বাচিত সম্পদটি দীর্ঘ বা শর্ট যাচ্ছে। যাইহোক, এটি ফি / লেনদেনের খরচ / উপলব্ধ ট্রেডিং পরিমাণ / স্টপ লস ইত্যাদি বিবেচনা করে না। লেনদেনের খরচ সাধারণত লাভজনক লেনদেনকে ক্ষতিতে পরিণত করে। উদাহরণস্বরূপ, $ 0.05 এর প্রত্যাশিত মূল্য বৃদ্ধি সহ একটি সম্পদ একটি ক্রয়, তবে যদি আপনাকে এই লেনদেনের জন্য $ 0.10 দিতে হয় তবে আপনাকে অবশেষে $ 0.05 এর নেট ক্ষতি পাবেন। আপনি ব্রোকারের কমিশন, বিনিময় ফি এবং পয়েন্ট পার্থক্য বিবেচনা করার পরে, আমাদের বড় মুনাফা চার্টটি উপরের মতো দেখায়ঃ
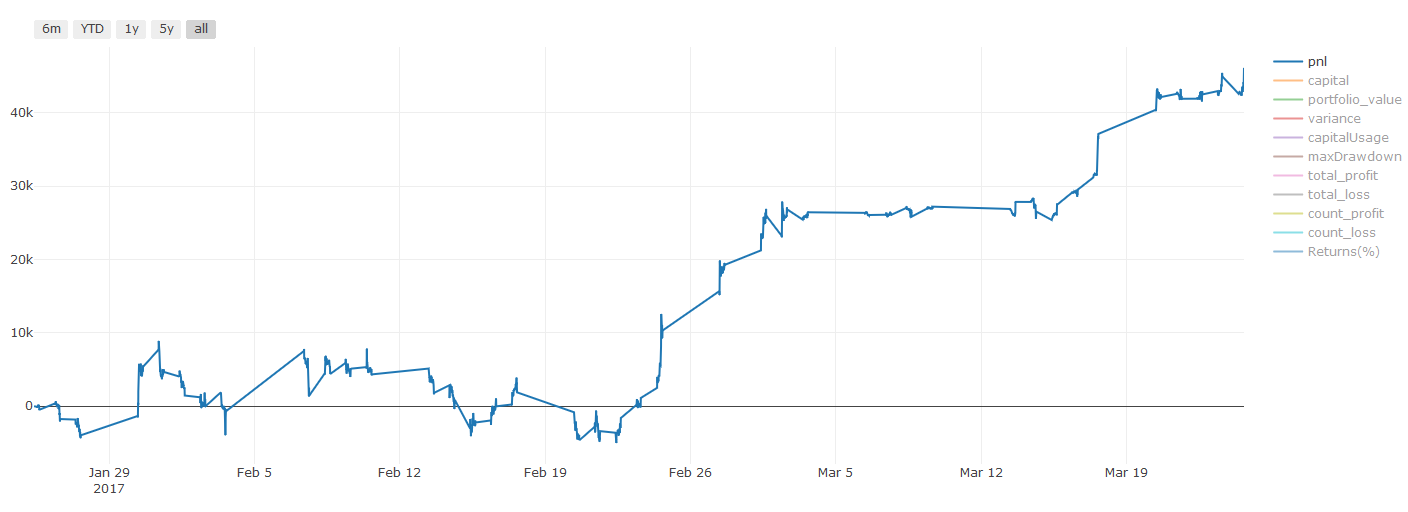
ট্রেডিং ফি এবং পয়েন্ট পার্থক্যের পরে ব্যাকটেস্টের ফলাফল Pnl হল USD।
লেনদেনের ফি এবং দামের পার্থক্য আমাদের PNL এর 90% এরও বেশি! আমরা পরবর্তী নিবন্ধে এগুলি বিস্তারিতভাবে আলোচনা করব।
অবশেষে, আসুন আমরা কিছু সাধারণ ফাঁদগুলি দেখে নিই।
কি করতে হবে এবং কি না করতে হবে
-
আপনার সমস্ত শক্তি দিয়ে অতিরিক্ত ফিটিং এড়ান!
-
প্রতিটি ডেটা পয়েন্টের পরে পুনরায় প্রশিক্ষণ দেবেন নাঃ এটি মেশিন লার্নিং বিকাশে লোকেরা একটি সাধারণ ভুল করে। যদি আপনার মডেলটি প্রতিটি ডেটা পয়েন্টের পরে পুনরায় প্রশিক্ষণের প্রয়োজন হয় তবে এটি খুব ভাল মডেল নাও হতে পারে। অর্থাৎ এটি নিয়মিত পুনরায় প্রশিক্ষণের প্রয়োজন এবং কেবলমাত্র যুক্তিসঙ্গত ফ্রিকোয়েন্সিতে প্রশিক্ষণের প্রয়োজন (উদাহরণস্বরূপ, যদি দিনের মধ্যে পূর্বাভাস দেওয়া হয় তবে এটি প্রতি সপ্তাহের শেষে পুনরায় প্রশিক্ষণের প্রয়োজন) ।
-
পক্ষপাত এড়িয়ে চলুন, বিশেষত ভবিষ্যতের দিকে তাকানো পক্ষপাতঃ এটি মডেলটি কাজ না করার আরেকটি কারণ, এবং আপনি ভবিষ্যতের কোনও তথ্য ব্যবহার করবেন না তা নিশ্চিত করুন। বেশিরভাগ ক্ষেত্রে, এর অর্থ হ'ল লক্ষ্য পরিবর্তনশীল Y মডেলের বৈশিষ্ট্য হিসাবে ব্যবহৃত হয় না। আপনি ব্যাকটেস্টিংয়ের সময় এটি ব্যবহার করতে পারেন, তবে আপনি যখন মডেলটি বাস্তবে চালাবেন তখন এটি উপলব্ধ হবে না, যা আপনার মডেলটিকে অযোগ্য করে তুলবে।
-
ডেটা মাইনিং পক্ষপাত থেকে সাবধান থাকুনঃ আমরা আমাদের ডেটাতে এটি উপযুক্ত কিনা তা নির্ধারণের জন্য মডেলিংয়ের একটি সিরিজ পরিচালনা করার চেষ্টা করছি, যদি কোনও বিশেষ কারণ না থাকে তবে দয়া করে নিশ্চিত করুন যে আপনি র্যান্ডম মোডটি প্রকৃত মোড থেকে পৃথক করার জন্য কঠোর পরীক্ষা চালান যা ঘটতে পারে। উদাহরণস্বরূপ, রৈখিক রিগ্রেশন উত্তোলন প্রবণতা প্যাটার্নটি ভালভাবে ব্যাখ্যা করে, তবে এটি বৃহত্তর র্যান্ডম ভ্রমনের একটি ভগ্নাংশ হয়ে উঠতে পারে!
অতিরিক্ত ফিটিং এড়ানো
এটা খুবই গুরুত্বপূর্ণ এবং আমি মনে করি এটা পুনরায় উল্লেখ করা দরকার।
-
ট্রেডিং কৌশলগুলির মধ্যে অতিরিক্ত ফিটিং সবচেয়ে বিপজ্জনক ফাঁদ।
-
একটি জটিল অ্যালগরিদম ব্যাকটেস্টে খুব ভাল পারফর্ম করতে পারে, তবে এটি নতুন অদৃশ্য ডেটাতে দুর্ভাগ্যজনকভাবে ব্যর্থ হয়। এই অ্যালগরিদমটি আসলে ডেটাগুলির কোনও প্রবণতা প্রকাশ করে না, বা এটির বাস্তব ভবিষ্যদ্বাণী করার ক্ষমতা নেই। এটি যে ডেটা দেখে তার জন্য এটি খুব উপযুক্ত;
-
আপনার সিস্টেমকে যতটা সম্ভব সহজ রাখুন। যদি আপনি দেখতে পান যে ডেটা ব্যাখ্যা করার জন্য আপনার অনেক জটিল ফাংশন প্রয়োজন, আপনি অতিরিক্ত ফিট হতে পারেন;
-
আপনার উপলব্ধ ডেটাকে প্রশিক্ষণ এবং পরীক্ষার ডেটাতে বিভক্ত করুন এবং রিয়েল-টাইম লেনদেনের জন্য মডেলটি ব্যবহার করার আগে সর্বদা বাস্তব নমুনা ডেটার কার্যকারিতা যাচাই করুন।
- ক্রিপ্টোকারেন্সিতে লিড-লেগ আর্বিট্রেজের ভূমিকা (2)
- ডিজিটাল মুদ্রায় লিড-ল্যাগ স্যুটের ভূমিকা (২)
- এফএমজেড প্ল্যাটফর্মের বাহ্যিক সংকেত গ্রহণ নিয়ে আলোচনাঃ কৌশলগতভাবে অন্তর্নির্মিত এইচটিটিপি পরিষেবা সহ সংকেত গ্রহণের জন্য একটি সম্পূর্ণ সমাধান
- এফএমজেড প্ল্যাটফর্মের বহিরাগত সংকেত গ্রহণের অন্বেষণঃ কৌশলগুলি অন্তর্নির্মিত এইচটিটিপি পরিষেবাগুলির সংকেত গ্রহণের সম্পূর্ণ সমাধান
- ক্রিপ্টোকারেন্সিতে লিড-লেগ আর্বিট্রেজের ভূমিকা (1)
- ডিজিটাল মুদ্রায় লিড-ল্যাগ স্যুটের ভূমিকা
- এফএমজেড প্ল্যাটফর্মের বাহ্যিক সংকেত গ্রহণের বিষয়ে আলোচনাঃ বর্ধিত এপিআই বনাম কৌশল অন্তর্নির্মিত এইচটিটিপি পরিষেবা
- এফএমজেড প্ল্যাটফর্মের বহিরাগত সংকেত গ্রহণের অন্বেষণঃ এক্সটেনশান এপিআই বনাম কৌশল অন্তর্নির্মিত এইচটিটিপি পরিষেবা
- র্যান্ডম টিকার জেনারেটরের উপর ভিত্তি করে কৌশল পরীক্ষার পদ্ধতি নিয়ে আলোচনা
- র্যান্ডম মার্কেট জেনারেটরের উপর ভিত্তি করে কৌশলগত পরীক্ষার পদ্ধতিগুলি অনুসন্ধান করুন
- এফএমজেড কোয়ান্টের নতুন বৈশিষ্ট্যঃ সহজেই এইচটিটিপি সার্ভিস তৈরি করতে _সার্ভ ফাংশন ব্যবহার করুন
- নিউরাল নেটওয়ার্ক এবং ডিজিটাল মুদ্রা পরিমাণগত ট্রেডিং সিরিজ (1) - LSTM বিটকয়েনের মূল্য পূর্বাভাস দেয়
- এসএমএ এবং আরএসআই রিলেটিভ স্ট্রেনথ ইন্ডেক্সের সমন্বিত কৌশল প্রয়োগ
- সিটিএ কৌশল এবং এফএমজেড কোয়ান্ট প্ল্যাটফর্মের স্ট্যান্ডার্ড ক্লাস লাইব্রেরির বিকাশ
- পাইথনে মূল্য গতিবিধি বিশ্লেষণ সহ পরিমাণগত ট্রেডিং কৌশল
- পাইথনে একটি ডুয়াল থ্রাস্ট ডিজিটাল মুদ্রা পরিমাণগত ট্রেডিং কৌশল বাস্তবায়ন করুন
- লিনাক্স ডকারের জন্য ইনস্টল এবং আপগ্রেড করার সর্বোত্তম উপায়
- দীর্ঘ শর্ট পজিশনের সুষম সমন্বয় সহ সুষম মূলধন কৌশল অর্জন
- টাইম সিরিজ ডেটা বিশ্লেষণ এবং টিক ডেটা ব্যাকটেস্টিং
- ডিজিটাল মুদ্রা বাজারের পরিমাণগত বিশ্লেষণ
- ডেটা-চালিত প্রযুক্তির উপর ভিত্তি করে জোড়া বাণিজ্য
- ত্রিভুজীয় হেজিংয়ের বিশদ বিশ্লেষণ এবং হেজিংযোগ্য মূল্য পার্থক্যের উপর হ্যান্ডলিং ফিগুলির প্রভাবের জন্য গবেষণা পরিবেশ ব্যবহার করুন
- বিকল্পের পরিমাণগত ব্যবসায়ের সাথে মানিয়ে নিতে ডেরিবিত ফিউচার এপিআই সংস্কার করুন
- ভাল সরঞ্জাম ভাল কাজ করে -- ট্রেডিং নীতি বিশ্লেষণের জন্য গবেষণা পরিবেশ ব্যবহার করতে শিখুন
- ব্লকচেইন সম্পদের পরিমাণগত লেনদেনে ক্রস-ভারেন্সি হেজিং কৌশল
- FMex এর ডিজিটাল মুদ্রা কৌশল গাইড FMZ Quant এ কিনুন
- আপনাকে কৌশল লিখতে শেখাবে -- একটি মাইল্যাঙ্গুয়েজ কৌশল প্রতিস্থাপন (উন্নত)
- আপনাকে কৌশল লিখতে শেখাবে -- মাই ল্যাঙ্গুয়েজের কৌশল প্রতিস্থাপন করবে
- আপনাকে কৌশল মাল্টি চার্ট সমর্থন যোগ করতে শেখান
- পাইথন সংস্করণে একটি কে-লাইন সংশ্লেষণ ফাংশন লিখতে শেখান
- গবেষণা পরিবেশে ডনচিয়ান চ্যানেল কৌশল বিশ্লেষণ