Strategie-Testmethoden basierend auf Random-Market-Generatoren untersucht
Schriftsteller:Die Erfinder quantifizieren - Kleine Träume, Erstellt: 2024-11-29 16:35:44, Aktualisiert: 2024-12-02 09:12:43[TOC]

Vorwort
Das Retestsystem der erfundenen quantitativen Handelsplattform ist ein immer wieder aktualisierendes Retestsystem, das von der ursprünglichen grundlegenden Retestfunktion nach und nach die Funktionalität und Leistungsoptimierung erhöht.
Bedürfnisse
In der Quantitative-Trading-Branche ist die Entwicklung von Strategien und die Optimierung der Validierung von echten Marktdaten untrennbar. In der Praxis kann es jedoch aufgrund der Komplexität und Vielfalt der Marktumgebung zu Mangel an Rücksichten auf historische Daten kommen, wie zum Beispiel die fehlende Abdeckung extremer Märkte oder spezieller Szenarien. Daher ist das Entwerfen eines effizienten Random-Trade-Generators ein wirksames Werkzeug für Entwickler von Quantitativen Strategien.
Wenn wir eine Strategie auf einer Börse oder einer Währung zurückführen wollen, können wir sie mit der offiziellen Datenquelle der FMZ-Plattform überprüfen. Manchmal möchten wir auch sehen, wie die Strategie in einem völlig fremden Markt funktioniert.
Die Nutzung von Daten aus dem Random Market bedeutet:
-
- Die Strategie für die Bewertung der Robustheit Random Market Generatoren können verschiedene mögliche Marktszenarien erstellen, einschließlich extremer, niedrigerer, tendenzieller und pulsierender Märkte. In diesen simulierten Umgebungen können Strategien getestet werden, um zu beurteilen, ob sie sich unter verschiedenen Marktbedingungen stabil verhalten.
Ist die Strategie an Trends und Schwankungen angepasst? Die Strategie ist es, in extremen Märkten erhebliche Verluste zu erzielen.
-
- Potenzielle Schwachstellen der Strategie erkennen Potenzielle Schwächen der Strategie können durch die Simulation einiger außergewöhnlicher Marktverhältnisse (z. B. ein hypothetisches Schwarzes Schwan-Ereignis) erkannt und verbessert werden.
Ist die Strategie zu sehr auf eine bestimmte Marktstruktur angewiesen? Gibt es ein Risiko, dass die Parameter übermäßig abgestimmt sind?
-
- Optimierung der Strategieparameter Randomisierte Daten bieten eine vielfältigere Testumgebung für die Optimierung von Strategieparametern, ohne sich ausschließlich auf historische Daten zu verlassen. Dies ermöglicht eine umfassendere Erfassung der Strategieparameter und vermeidet die Beschränkung auf bestimmte Marktmuster in historischen Daten.
-
- Unzureichende historische Daten In einigen Märkten (z. B. in Schwellenmärkten oder kleinen Währungstransaktionsmärkten) können historische Daten möglicherweise nicht ausreichen, um alle möglichen Marktbedingungen abzudecken. Ein Zufallsmarktgenerator kann eine große Menge an ergänzenden Daten bereitstellen, um eine umfassendere Prüfung zu ermöglichen.
-
- Schnelle Iterationsentwicklung Schnelle Tests mit randomisierten Daten können die Iterationsgeschwindigkeit bei der Strategieentwicklung beschleunigen, ohne auf die realen Markttrends oder die zeitaufwändige Reinigung und Ordnung der Daten angewiesen zu sein.
Aber es braucht auch eine rationale Bewertungsstrategie, und bei den zufällig generierten Marktdaten sollten Sie beachten:
- 1. Obwohl Random-Scenario-Generatoren nützlich sind, hängt ihre Bedeutung von der Qualität der erzeugten Daten und dem Design der Ziel-Szenen ab:
- 2. Die Erzeugungslogik muss dem realen Markt nahe kommen: Wenn die zufällig generierten Märkte vollständig von der Realität entfernt sind, können die Testresultate keinen Referenzwert haben. Zum Beispiel kann ein Generator mit tatsächlichen Marktstatistiken (z. B. Schwankungsfrequenzverteilung, Trendquote) kombiniert werden.
- 3. Nicht vollständig ersetzbar für echte Daten-Tests: Zufallsdaten können nur die Entwicklung und Optimierung von Strategien ergänzen, und die endgültige Strategie muss immer noch in realen Marktdaten überprüft werden.
Wie können wir also einfach, schnell und einfach die Daten herstellen, um sie für das Retesting-System nutzbar zu machen?
Entwurfsideen
Dieses Buch ist entworfen, um zu vergleichsweise einfache, zufällige generative Berechnungen zu geben, aber es gibt eine Vielzahl von Techniken, die angewendet werden können, da die Diskussion begrenzt ist.
In Kombination mit der benutzerdefinierten Datenquellenfunktion des Plattform-Requestsystems haben wir ein Programm in der Sprache Python geschrieben.
- 1. Zufällig erzeugen Sie eine Reihe von K-Linien-Daten, die in CSV-Dateien geschrieben werden, so dass die erzeugten Daten gespeichert werden.
- 2. Dann erstellen Sie einen Dienst, der die Datenquellen für das Retest-System unterstützt.
- 3. Die erzeugten K-Daten werden in einem Diagramm dargestellt.
Für einige Generationsstandards für K-Line-Daten, File Storage usw. können folgende Parametersteuerungen definiert werden:
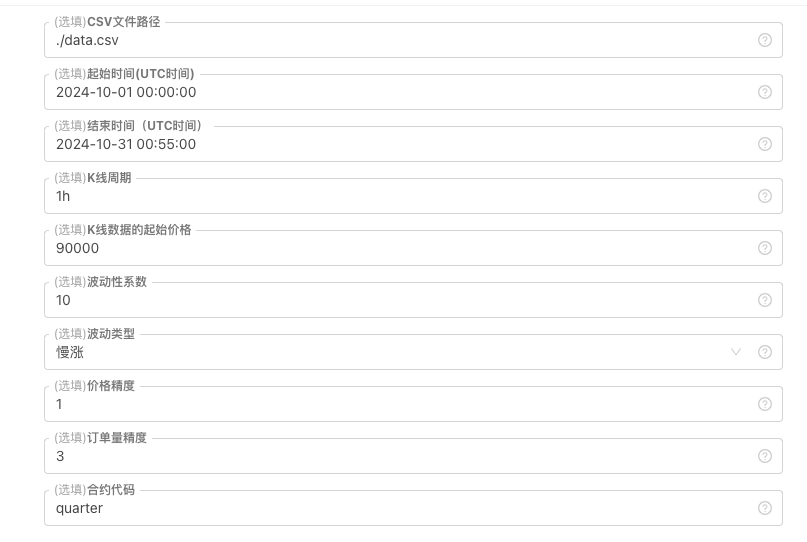
-
Modell, in dem Daten zufällig generiert werden Für die Analogie von K-Linien-Daten ist es nur eine einfache Konstruktion mit einer einfachen Verwendung von Zufallszahlen, die sich von positiven zu negativen Wahrscheinlichkeiten unterscheiden. Wenn nicht viele Daten erzeugt werden, kann dies möglicherweise nicht das gewünschte Verhaltensmuster widerspiegeln. Wenn es eine bessere Methode gibt, kann dieser Teil des Codes ersetzt werden. Aufgrund dieses einfachen Designs können die Randomizationsgenerierungsbereiche und einige Koeffizienten im Code angepasst werden, um die erzeugten Datenwirkungen zu beeinflussen.
-
Überprüfung der Daten Für die erzeugten K-Line-Daten ist auch eine Rationalitätsprüfung erforderlich, um zu überprüfen, ob die Preise für Hoch- und Tiefführungen gegen die Definition verstoßen, um die Kontinuität der K-Line-Daten zu überprüfen und so weiter.
Randomization-Generator für das Retestsystem
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("CSV文件格式有误,列数不同,请检查!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("CSV文件格式有误,请检查!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("数据data.detail:", data["detail"], "响应回测系统请求。")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("不支持的K线周期,请使用 'm', 'h', 或 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("异常数据:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("当前路径:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("文件写入成功,以下是文件内容的一部分:")
Log("".join(lines[:5]))
else:
Log("文件写入失败,文件为空!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("开启自定义数据源服务线程,数据由CSV文件提供。", ", 地址/端口:0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("生成器参数:", "起始时间:", startTime, "结束时间:", endTime, "K线周期:", KLinePeriod, "初始价格:", firstPrice, "波动类型:", arrTrendType[trendType], "波动性系数:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
Praktiken im Retestsystem
1. Erstellen Sie ein Beispiel für die oben genannten Strategien, konfigurieren Sie die Parameter und laufen Sie. 2. Die Festplatte (siehe Politikbeispiel) muss auf dem Host ausgeführt werden, der auf dem Server bereitgestellt wird, da eine öffentliche IP benötigt wird, die vom Retesting-System zugegriffen werden kann, um die Daten zu erhalten. 3. Klicken Sie auf den Interaktionsknopf, und die Strategie erzeugt automatisch Daten zu den zufälligen Märkten.

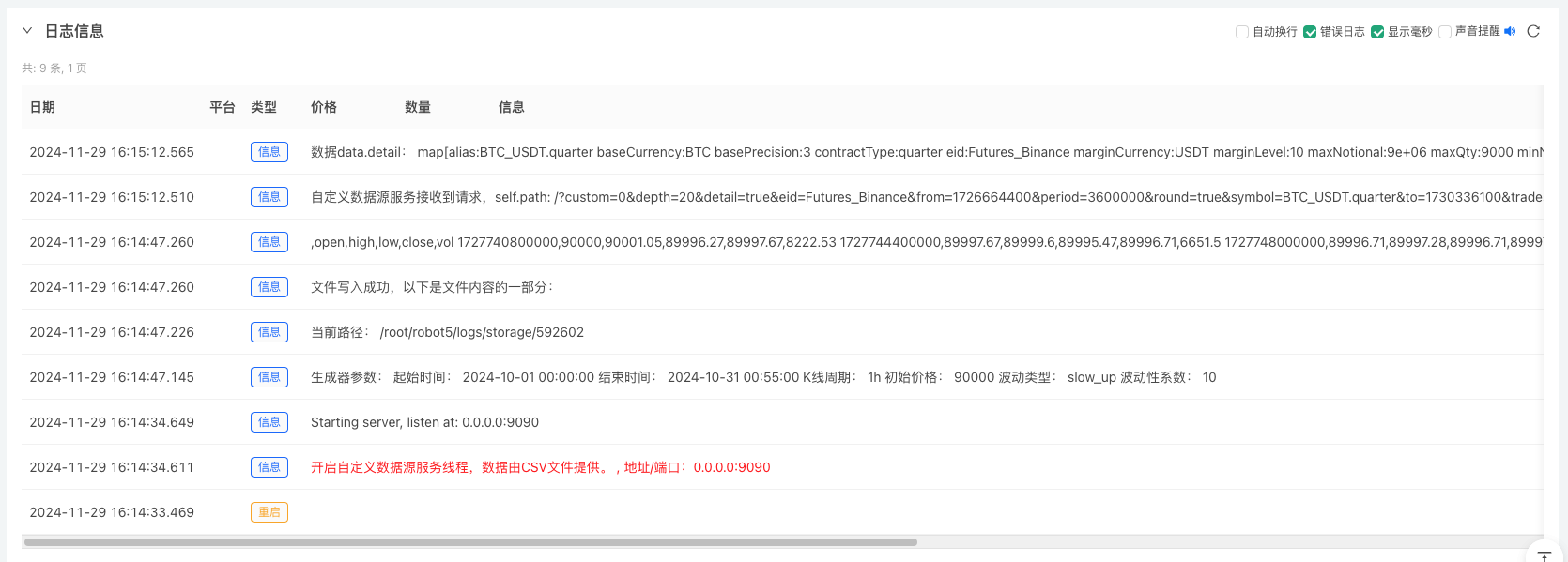
4、生成好的数据会显示在图表上,方便观察,同时数据会记录在本地的data.csv文件
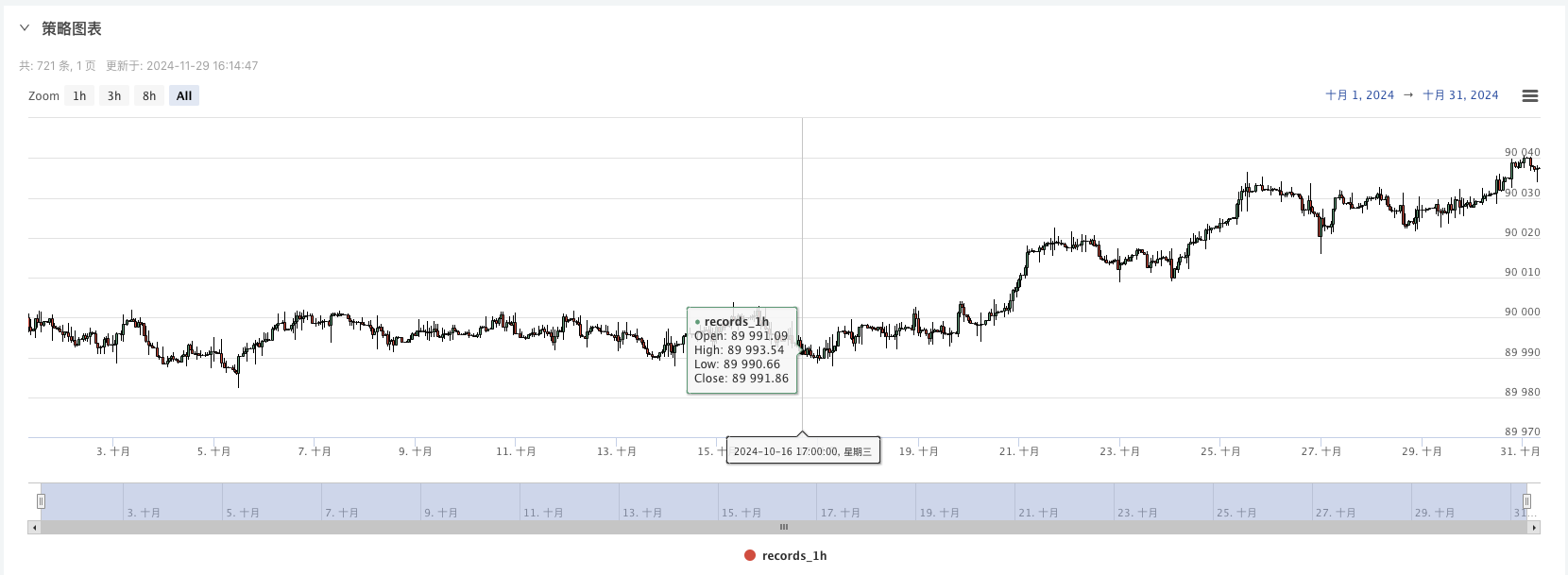
5. Jetzt können wir diese Daten verwenden, die zufällig generiert wurden, um zufällig eine Strategie zu verwenden.
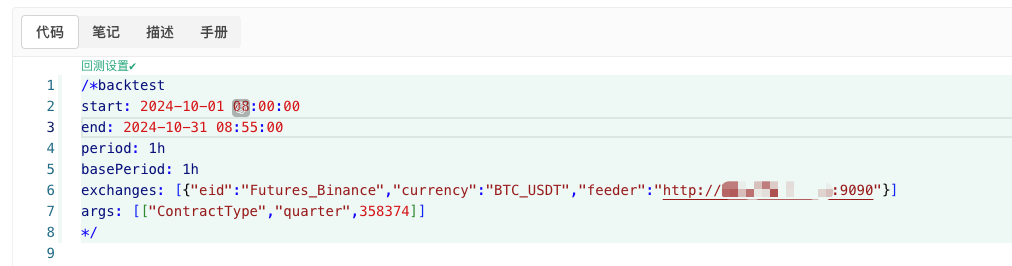
/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
Die Anpassung der Konfiguration basiert auf den oben genannten Informationen.http://xxx.xxx.xxx.xxx:9090Das ist die Server-IP-Adresse und der Port, an dem die Strategie-Realdiskette zufällig generiert wird.
Dies ist die benutzerdefinierte Datenquelle, die Sie im Abschnitt über benutzerdefinierte Datenquellen in der Plattform-API-Dokumentation finden können.
6. Das Retro-System kann Datenquellen auswählen, um zufällige Daten zu testen.
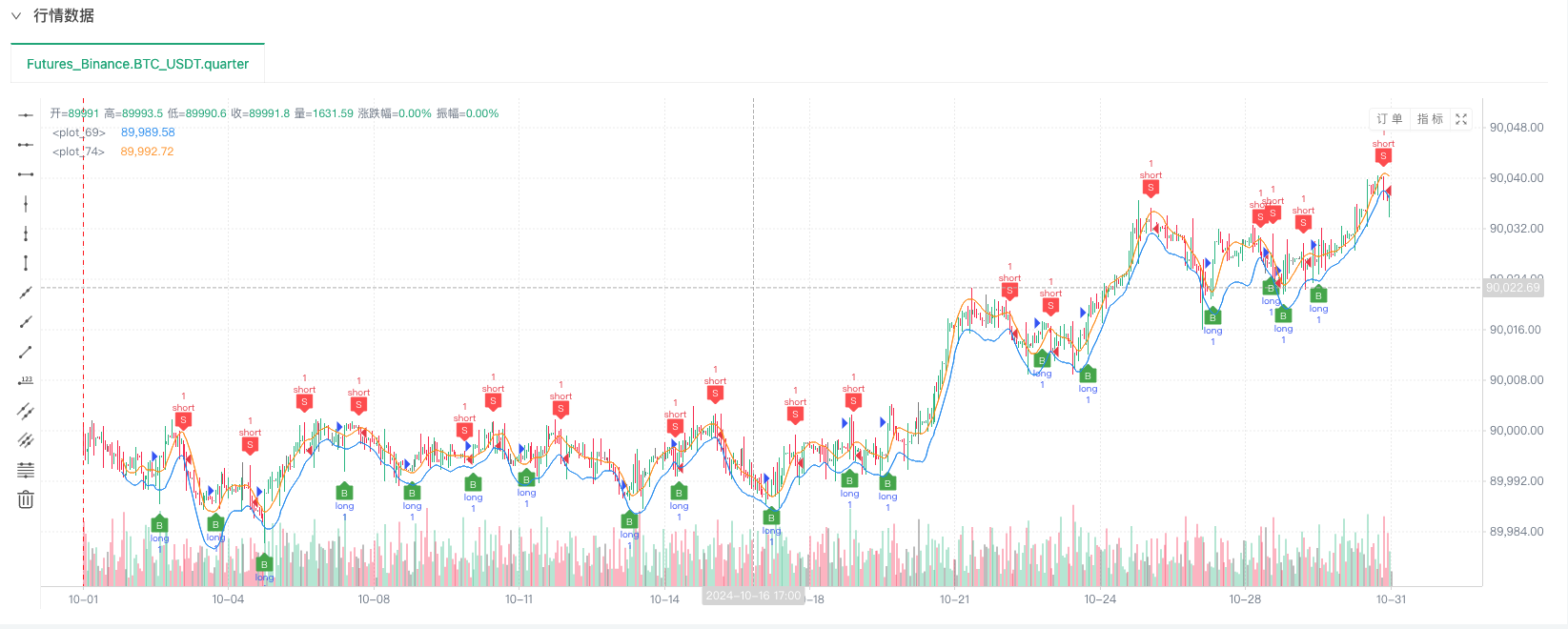
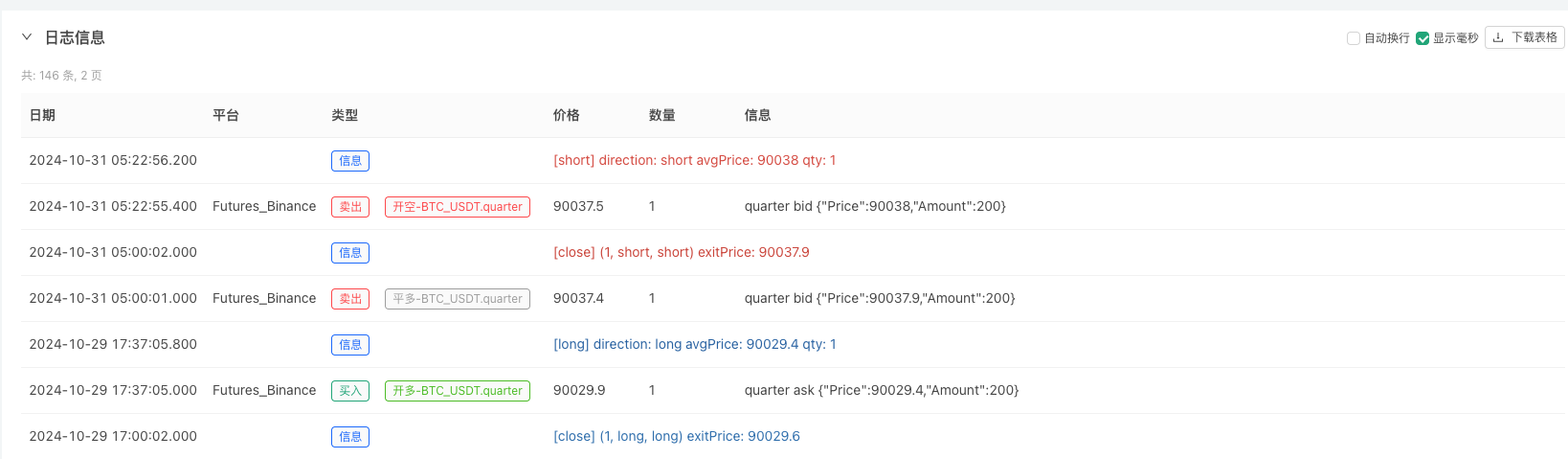
Das Retest-System wurde mit unseren simulierten Daten getestet. Die Daten des Marktdiagramms zum Zeitpunkt der Retestung wurden mit den Daten des realen Marktdiagramms verglichen.
7. Oh ja, ich habe fast vergessen zu sagen! Der Grund für die Erstellung einer Festplatte durch einen Python-Programm, der einen Zufalls-Sache-Generator hat, ist die einfache Darstellung, Bedienung und Anzeige der erzeugten K-Leiste-Daten.
Die Strategie ist hier:Randomization-Generator für das Retestsystem
Danke für die Unterstützung und das Lesen.
- Einführung der Lead-Lag-Suite in der Kryptowährung (3)
- Einführung in Lead-Lag-Arbitrage in Kryptowährungen (2)
- Einführung der Lead-Lag-Suite in der digitalen Währung (2)
- Diskussion über den externen Signalempfang der FMZ-Plattform: Eine Komplettlösung für den Empfang von Signalen mit integriertem Http-Service in der Strategie
- FMZ-Plattform: Erforschung von Signalempfangsstrategien für externe Netzwerke
- Einführung in Lead-Lag-Arbitrage in Kryptowährungen (1)
- Einführung der Lead-Lag-Suite in der Kryptowährung (1)
- Diskussion über den externen Signalempfang der FMZ-Plattform: Erweiterte API VS Strategie eingebauter HTTP-Service
- FMZ-Plattform-External Signal Reception: Erweiterung der API vs. Strategien für den eingebauten HTTP-Dienst
- Diskussion über die Strategie-Testmethode auf Basis eines Zufalls-Ticker-Generators
- Neue Funktion von FMZ Quant: _Serve-Funktion zum einfachen Erstellen von HTTP-Diensten
- Erfinder quantifizieren neue Funktionen: Erstellen von HTTP-Diensten mit _Serve
- FMZ Quant Trading Platform benutzerdefinierte Protokollzugriffsanleitung
- Strategie für den Erwerb und die Überwachung der FMZ-Finanzierungsquote
- FMZ-Finanzierungsraten Akquisition und Überwachung Strategien
- Eine Strategievorlage ermöglicht Ihnen, WebSocket Market nahtlos zu nutzen
- Eine Strategievorlage, mit der Sie die WebSocket-Branche nahtlos nutzen können
- Inventor Quantitative Trading Plattform General Protocol Zugriffsanleitung
- Wie man nach dem FMZ-Upgrade schnell eine universelle Multi-Währungs-Handelsstrategie aufbaut
- Wie man nach dem FMZ-Upgrade schnell eine allgemeine Multi-Währungs-Handelsstrategie aufbaut