Übersicht über die Vor- und Nachteile von drei und sechs Algorithmen für maschinelles Lernen
Schriftsteller:Die Erfinder quantifizieren - Kleine Träume, Erstellt: 2017-10-30 12:01:59, Aktualisiert: 2017-11-08 13:55:03Übersicht über die Vor- und Nachteile von drei und sechs Algorithmen für maschinelles Lernen
In Machine Learning ist das Ziel entweder die Vorhersage oder das Clustern. Der Schwerpunkt dieses Artikels liegt auf der Vorhersage. Vorhersage ist der Prozess, den Wert der Ausgabe aus einer Reihe von Input-Variablen zu prognostizieren. Zum Beispiel, wenn wir eine Reihe von Merkmalen für ein Haus erhalten, können wir seinen Verkaufspreis prognostizieren. In diesem Zusammenhang wollen wir uns die wichtigsten und am häufigsten verwendeten Algorithmen in der Maschinellen Lerntechnik anschauen. Wir haben sie in drei Kategorien eingeteilt: lineare Modelle, baumbasierte Modelle und neurale Netzwerke.
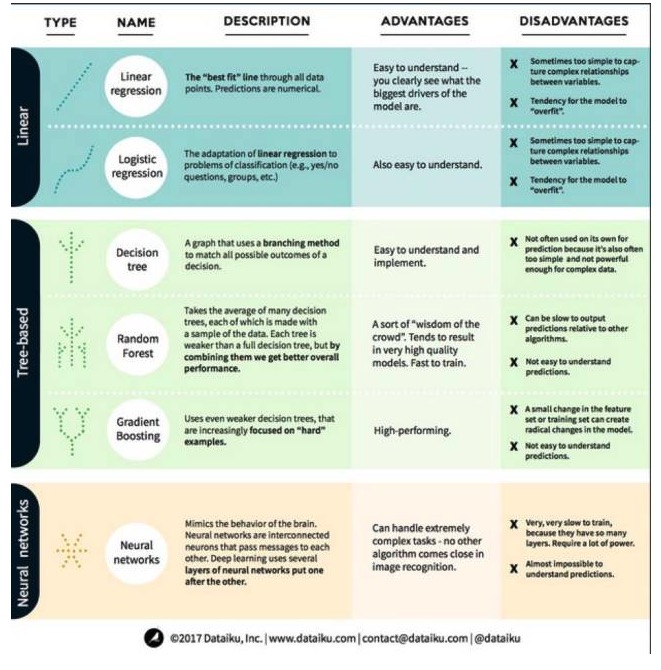
1. Linearmodell-Algorithmen: Linearmodelle verwenden einfache Formeln, um durch eine Reihe von Datenpunkten die Zeilen zu finden, in denen sich die Best-Fit-Zeichen befinden. Diese Methode wurde vor mehr als 200 Jahren in der Statistik und im Maschinenlernen eingesetzt. Sie ist aufgrund ihrer Einfachheit nützlich für die Statistik.
- ### ## 1. Lineare Regression
Die Linearregression, oder genauer gesagt, die minimale zweimalige Regressionsregression, ist die Standardform des Linearmodells. Für Regressionsprobleme ist die Linearregression das einfachste Linearmodell. Der Nachteil ist, dass das Modell leicht zu überanpassen ist, d. h. dass das Modell sich vollständig an die ausgebildeten Daten anpasst, zu Lasten der Fähigkeit, sich auf neue Daten auszurichten.
Ein weiterer Nachteil von Linearmodellen ist, dass sie, da sie sehr einfach sind, nicht leicht komplexere Verhaltensweisen vorhersagen, wenn die Inputvariablen nicht unabhängig sind.
- ### ## 2. Logische Regression
Logische Regression ist die Anpassung der Linearregression an die Klassifizierungsprobleme. Die Nachteile der Logischen Regression sind die gleichen wie bei der Linearregression. Die Logische Funktion ist sehr gut für Klassifizierungsprobleme, da sie den Threshold-Effekt einführt.
2. Algorithmen für Baummodelle
- #### ## 1, der Entscheidungsträufer
Entscheidungsbäume sind Abbildungen von allen möglichen Ergebnissen der Entscheidung, die mit der Branching-Methode dargestellt wird. Zum Beispiel, wenn Sie sich entscheiden, einen Salat zu bestellen, ist Ihre erste Entscheidung wahrscheinlich die Art von rohem Gemüse, dann Gemüse, dann die Art von Salatcreme. Wir können alle möglichen Ergebnisse in einem Entscheidungsbaum darstellen.
Um einen Entscheidungsbaum zu trainieren, müssen wir die Trainingsdatensätze verwenden und herausfinden, welche Eigenschaft für das Ziel am nützlichsten ist. Zum Beispiel in den Anwendungsfällen der Betrugserkennung können wir feststellen, dass die Eigenschaft, die den größten Einfluss auf die Vorhersage von Betrugsrisiken hat, das Land ist. Nach dem Verzweigen der ersten Eigenschaft erhalten wir zwei Subsätze, die am genauesten vorhergesagt werden können, wenn wir nur die erste Eigenschaft kennen.
- #### ## 2 ## ## ## ## ##
Zufallswälder sind die Durchschnittswerte vieler Entscheidungsträume, bei denen jeder Entscheidungsträum mit einer zufälligen Datenprobe trainiert wird. Jeder Baum im Zufallswald ist schwächer als ein vollständiger Entscheidungsträum, aber wenn wir alle Bäume zusammenstellen, können wir aufgrund der Vorteile der Vielfalt eine bessere Gesamtleistung erzielen.
Random Forests sind heute sehr beliebte Algorithmen im Maschinellen Lernen. Random Forests sind leicht zu trainieren und leisten eine ziemlich gute Leistung. Der Nachteil ist, dass Random Forests im Vergleich zu anderen Algorithmen die Prognosen langsam ausführen können, so dass man sich bei Bedarf für schnelle Prognosen wahrscheinlich nicht für Random Forests entscheidet.
- ### ## 3, Steigerung
Gradient Boosting besteht wie der Zufallswald aus schwachen Entscheidungsträumen. Der größte Unterschied zwischen Gradient Boosting und Zufallswald ist, dass bei Gradient Boosting die Bäume eins nach dem anderen trainiert werden. Jeder nachfolgende Baum wird hauptsächlich von dem Baum vor ihm trainiert, der falsche Daten erkennt.
Das Training mit der Steigerung ist auch schnell und sehr gut. Kleine Änderungen an den Trainingsdatensätzen können jedoch zu grundlegenden Veränderungen des Modells führen, so dass die Ergebnisse, die es erzeugt, möglicherweise nicht die besten sind.
3. Neuralnetz-Algorithmen: Neuronale Netzwerke sind biologische Phänomene, in denen Neuronen miteinander verbunden sind und Informationen ausgetauscht werden. Diese Idee wird jetzt auf den Bereich des Maschinellen Lernens angewendet und wird als ANN bezeichnet.
Übertragen von Big Data Plateau
- Die Erfinder quantifizieren die Unterstützung von Huobi und OKEX für Münztransaktionen und USDT-Transaktionen.
- Öffentliche Einzahlungsfunktion, integriert in die digitale Währungskasse
- Wie berechnen Sie die maximale Kapitalkapazität einer Strategie, indem Sie die Rückkopplung von Erträgen, Volatilität und anderen Daten der Strategie quantifizieren?
- Der Dämon von Shannon
- Kompliziert ist nicht die Technik, sondern der menschliche Geist!
- Bitfinex-Interface-Zugriff ist langsam, was empfehlen Sie für die Serverplatzierung?
- Bitfinex läuft falsch, Hilfe bei der Analyse, vielen Dank!
- Bitte fragen Sie, auf welchem Zeitpunkt basieren die Daten, die die API bei der Wiederholung aufruft?
- Ich habe den Code für die Bitcoin-Münze angefordert.
- Warum gibt es bei bitfinex nur vier Handelspaare: BCH_USD, BTC_USD, ETH_USD und LTC_USD?
- Der Sprung von 5000 pro Coin: Mehr BTC, freier OKEX1229-Vertrag, pro Monat 5000 pro Coin!
- Der letzte Beobachter
- Fehlermeldung: Ein Interaktionsknopf ohne Default-Parameterwerte beim Erstellen von Richtlinien scheiterte beim Speichern
- Kann das Retargeting-System nicht andere Währungen auswählen?
- Bitte übersetzen Sie die Seite des Kaufplans.
- Bitfinex hat drei Märkte, wie lassen wir einen Roboter wählen?
- Die Optionen unter der dynamischen Perspektive sind ein Gewinn.
- Bitfinex-Überprüfung und Überprüfung der Währungseinheit sind nicht übereinstimmend
- Wie sieht die Wirksamkeit von Abtrünnigen und Goldforks aus?
- Bithumb erhielt Fehler bei der Bereitstellung von Kontoinformationen