Was bedeutet Support Vector Machine (SVM)?
 0
4601
0
4601
Was bedeutet Support Vector Machine (SVM)?
Ich habe kürzlich ein Post auf Reddit gesehen mit dem Titel Please explain Support Vector Machines (SVM) like I am a 5 year old, also habe ich mich gefreut.
- #### Was ist SVM?
Support-Vektor-Maschine (SVM)
Natürlich erstmal auf der Wiki. Support Vector Machines are learning models used for classification: which individuals in a population belong where? So… how do SVM and the mysterious “kernel” work?
Die Geschichte geht so:
Am Valentinstag vor langer Zeit wollte der Große Mann seine Geliebte retten, aber der Teufel spielte ein Spiel mit ihm.
Der Teufel scheint regelmäßig zwei farbige Bälle auf den Tisch zu legen und sagt: “Kannst du sie mit einem Stock trennen?”
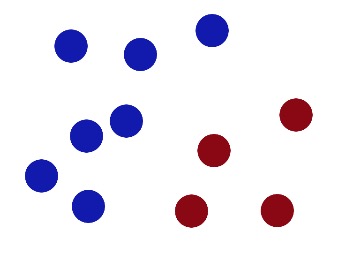
Was hat der Große Mann denn damit zu tun?
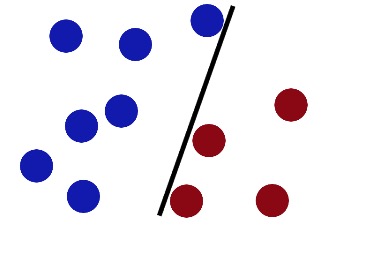
Dann legte der Teufel noch mehr Bälle auf den Tisch, und es schien, als ob einer von ihnen das falsche Lager verlassen hätte.
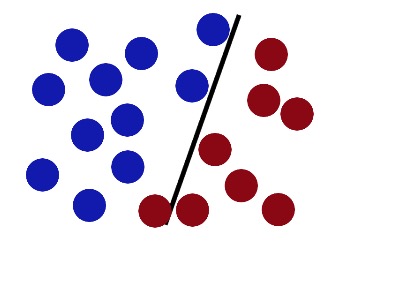
SVM ist der Versuch, die Stäbe in die beste Position zu bringen, um so viel Raum wie möglich auf beiden Seiten zu haben.
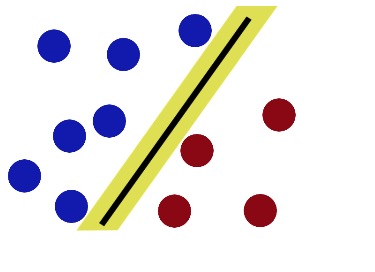
Jetzt ist der Stock eine gute Trennlinie, auch wenn der Teufel mehr Kugeln gesetzt hat.
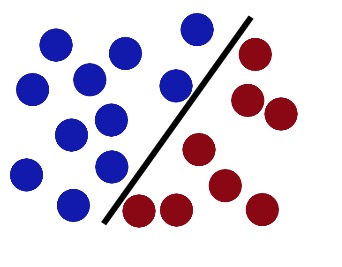
Dann gibt es noch einen weiteren, wichtigeren Trick in der SVM-Toolbox. Der Teufel sieht, dass der Große Mann einen Trick gelernt hat, und gibt ihm eine neue Herausforderung.
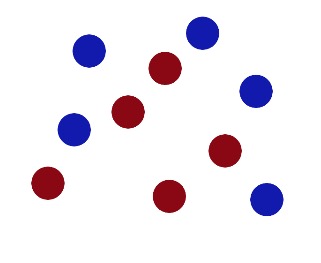
Nun, da er keinen Stock hat, der ihm helfen kann, die beiden Kugeln zu trennen, was soll er jetzt tun? Wie in allen Marvel-Filmen, schlägt er auf den Tisch und die Kugel fliegt in die Luft. Dann greift er mit der Leichtigkeit von Superman ein Blatt Papier und steckt es zwischen die beiden Kugeln.
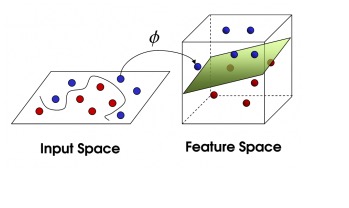
Nun, aus der Perspektive des Teufels sehen die Kugeln aus, als wären sie durch eine Kurve getrennt.
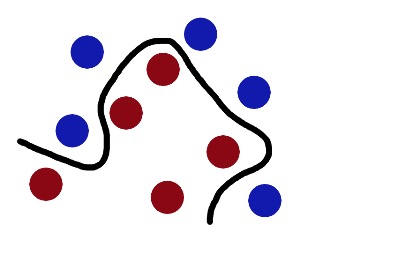
Dann nennen die langweiligen Erwachsenen die Kugeln “Daten”, die Stöcke “Classifier”, den Maximum-Spacer-Trick “Optimierung”, den Schreibtisch “Kernelling” und das Blatt Papier “Hyperplane”.
Weitere Informationen:
Please explain Support Vector Machines (SVM) like I am a 5 year old. : MachineLearning
Support Vector Machines explained well
-
Die Antworten der Benutzer sind zuverlässig.



- #### Die Antwort von Han Oliver
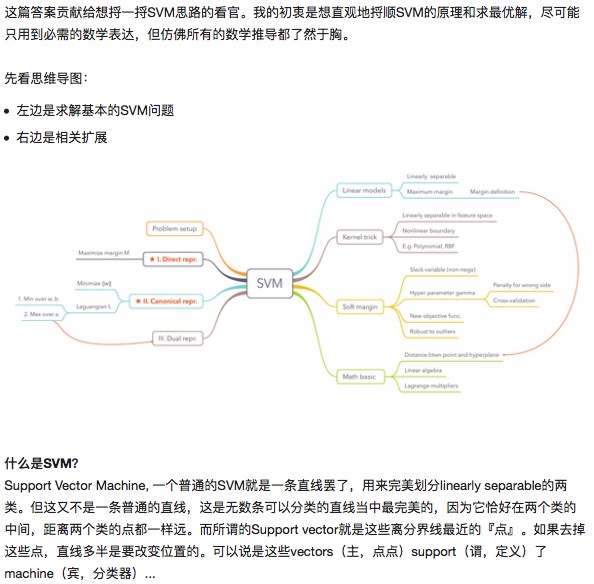
Was ist SVM?
SVM - support vector machine, auch bekannt als Support Vector Machine, ist ein Supervised Learning Algorithmus, der zur Kategorie Classification gehört. In der Anwendung von Data Mining entspricht und unterscheidet es sich von unsupervised Clustering. Es wird in den Bereichen Machine Learning, Computer Vision und Data Mining verwendet. Die Grundsätze der SVM sind in Abbildung 1 dargestellt.
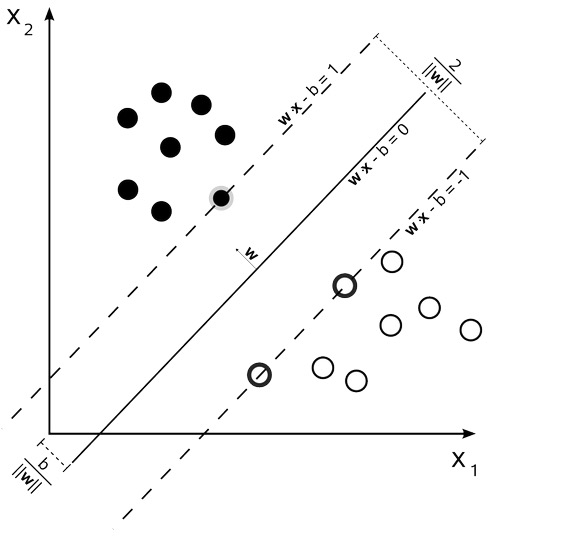
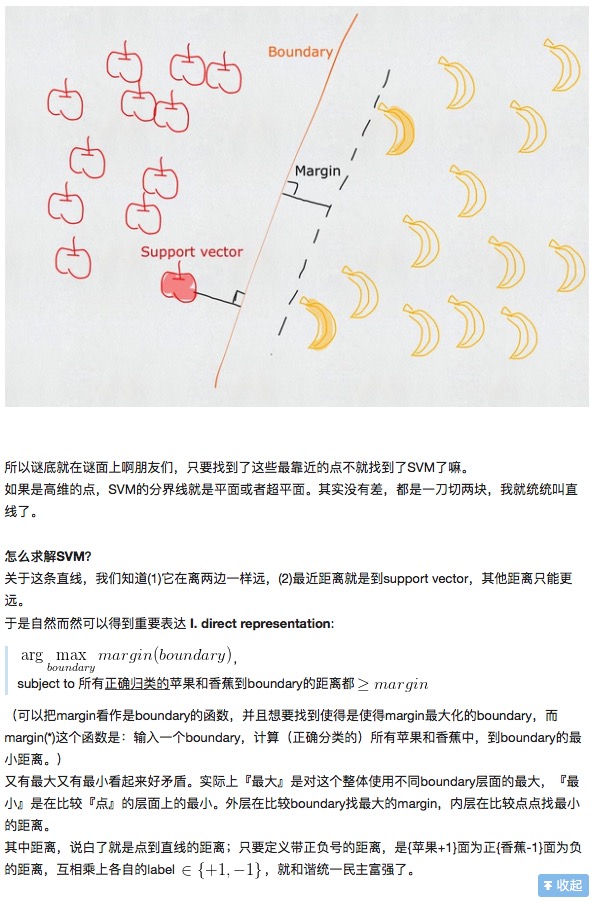
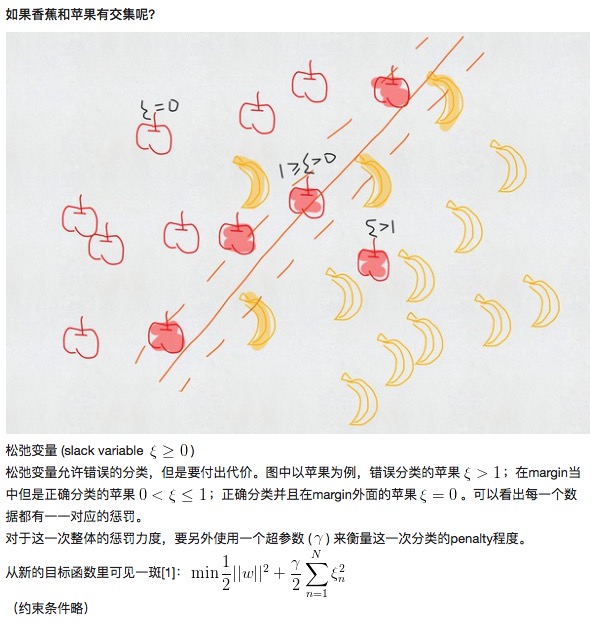
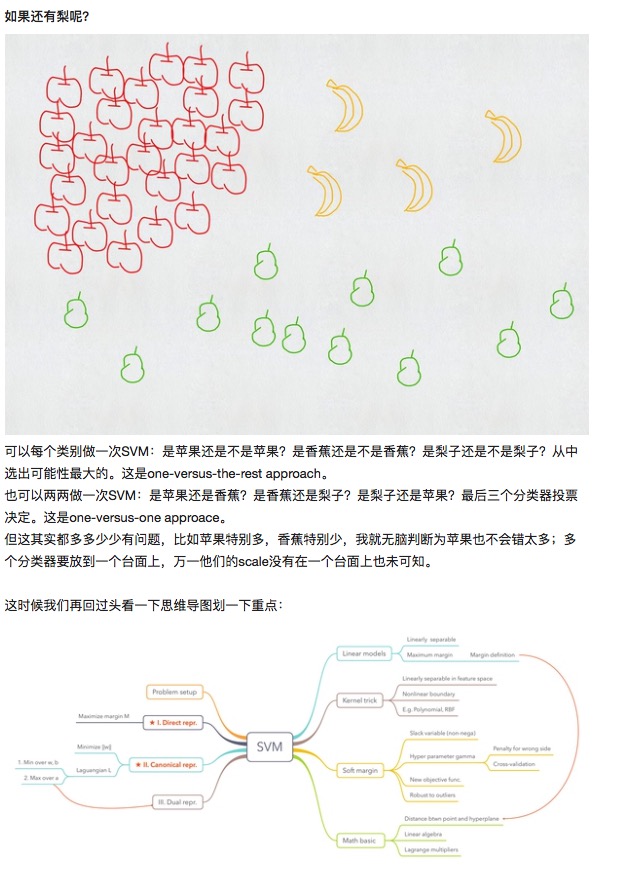
Angenommen, wir wollen durch die Dreieckegradlinie die reinen und die leeren Kreise in zwei Kategorien unterteilen: Es gibt also unzählige Linien, die diese Aufgabe erfüllen können. In der SVM suchen wir nach einer optimalen Trennlinie, die die größte Marge auf beiden Seiten hat. In diesem Fall werden mehrere Datenpunkte, deren Ränder größer sind, als Supportvektoren bezeichnet, was auch der Ursprung des Namens des Klassifikationsalgorithmus ist.
Ausdehnung auf beliebige n-Dimensionen und sogar auf unendliche Dimensionen, wie in Abbildung 2.
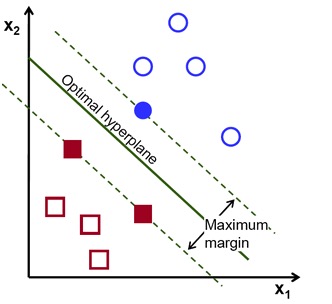
We got a bunch of data points in a n- dimensional to infinite-dimensional space, Then one can always find a optimal hyperplane which is always in the n-1 dimension.
Schließlich: Statistische Ausrichtung: Support Vector Machines (SVM) wiki:Support vector machine Kurse: Seite auf columbia.edu Das ist eine großartige Video-Demonstration. http://youtu.be/3liCbRZPrZA
Übertragung von Unbekannt