Diskussion über die Strategie-Testmethode auf Basis eines Zufalls-Ticker-Generators
Schriftsteller:FMZ~Lydia, Erstellt: 2024-12-02 11:26:13, Aktualisiert: 2024-12-02 21:39:39
Vorwort
Das Backtesting-System der FMZ Quant Trading Platform ist ein Backtesting-System, das sich ständig wiederholt, aktualisiert und aktualisiert. Es fügt Funktionen hinzu und optimiert die Leistung nach und nach von der ursprünglichen grundlegenden Backtesting-Funktion. Mit der Entwicklung der Plattform wird das Backtesting-System weiterhin optimiert und aktualisiert. Heute werden wir ein Thema diskutieren, das auf dem Backtesting-System basiert:
Nachfrage
Im Bereich des quantitativen Handels können die Entwicklung und Optimierung von Strategien nicht von der Verifizierung realer Marktdaten getrennt werden. In tatsächlichen Anwendungen kann es jedoch aufgrund des komplexen und sich verändernden Marktumfelds unzureichend sein, sich auf historische Daten für das Backtesting zu verlassen, z. B. fehlende Abdeckung extremer Marktbedingungen oder spezieller Szenarien. Daher ist die Entwicklung eines effizienten Zufallsmarktgenerators zu einem effektiven Werkzeug für quantitative Strategieentwickler geworden.
Wenn wir die Strategie historische Daten auf einer bestimmten Börse oder Währung zurückverfolgen lassen müssen, können wir die offizielle Datenquelle der FMZ-Plattform für Backtesting verwenden.
Die Bedeutung der Verwendung zufälliger Tickerdaten besteht darin:
-
- Bewertung der Robustheit der Strategien Der Zufallsticker-Generator kann eine Vielzahl möglicher Marktszenarien erstellen, einschließlich extremer Volatilität, geringer Volatilität, Trendmärkten und volatilen Märkten.
Kann sich die Strategie an den Trend- und Volatilitätswechsel anpassen? Wird die Strategie unter extremen Marktbedingungen einen großen Verlust verursachen?
-
- Identifizierung potenzieller Schwachstellen der Strategie Durch die Simulation einiger abnormaler Marktsituationen (wie hypothetische Schwarze Schwanenereignisse) können mögliche Schwächen in der Strategie entdeckt und verbessert werden.
Stützt sich die Strategie zu sehr auf eine bestimmte Marktstruktur? Gibt es eine Gefahr einer Überanpassung der Parameter?
-
- Optimierung der Strategieparameter Zufällig generierte Daten bieten eine vielfältigere Testumgebung für die Optimierung von Strategieparametern, ohne sich ausschließlich auf historische Daten verlassen zu müssen.
-
- Die Lücke in historischen Daten füllen In einigen Märkten (z. B. aufstrebenden Märkten oder kleinen Devisenmärkten) reichen historische Daten möglicherweise nicht aus, um alle möglichen Marktbedingungen abzudecken.
-
- Schnelle iterative Entwicklung Die Verwendung zufälliger Daten für schnelle Tests kann die Iteration der Strategieentwicklung beschleunigen, ohne sich auf Echtzeitmarktbedingungen oder zeitaufwendige Reinigung und Organisation von Daten zu verlassen.
Es ist jedoch auch notwendig, die Strategie rational zu bewerten.
-
- Zwar sind zufällige Marktgeneratoren nützlich, aber ihre Bedeutung hängt von der Qualität der erzeugten Daten und der Gestaltung des Ziel-Szenarios ab:
-
- Die Generationslogik muss dem realen Markt nahe sein: Wenn der zufällig generierte Markt völlig außer Kontakt mit der Realität steht, können die Testergebnisse keinen Referenzwert haben.
-
- Es kann nicht vollständig das Testen von realen Daten ersetzen: Zufallsdaten können nur die Entwicklung und Optimierung von Strategien ergänzen.
Wie können wir Daten für das Backtesting-System "fabrizieren", damit es sie bequem, schnell und einfach nutzen kann?
Entwurfsideen
Dieser Artikel soll einen Ausgangspunkt für die Diskussion bieten und eine relativ einfache zufällige Tickererzeugung berechnen. In der Tat gibt es eine Vielzahl von Simulationsalgorithmen, Datenmodellen und anderen Technologien, die angewendet werden können. Aufgrund des begrenzten Raums der Diskussion werden wir keine komplexen Datensimulationsmethoden verwenden.
Wir haben die benutzerdefinierte Datenquelle des Backtesting-Systems der Plattform kombiniert und ein Programm in Python geschrieben.
-
- Generieren Sie eine Reihe von K-Liniendaten zufällig und schreiben Sie sie in eine CSV-Datei für eine dauerhafte Aufzeichnung, so dass die generierten Daten gespeichert werden können.
-
- Dann erstellen Sie einen Dienst zur Unterstützung der Datenquelle für das Backtesting-System.
-
- Anzeigen der erzeugten K-Liniendaten im Diagramm.
Für einige Generationsstandards und Datei-Speicherung von K-Line-Daten können folgende Parametersteuerungen definiert werden:
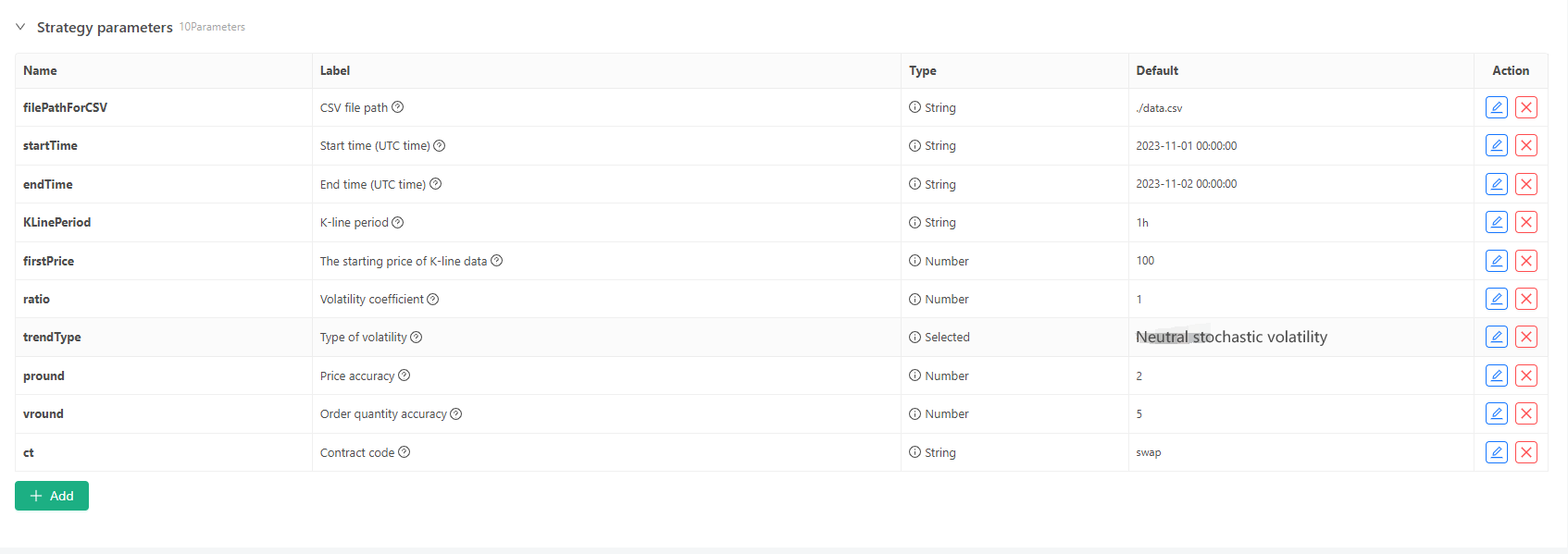
-
Zufällig generierter Datenmodus Für die Simulation der Schwankungsart von K-Liniendaten wird einfach ein einfaches Design mit der Wahrscheinlichkeit von positiven und negativen Zufallszahlen erstellt. Wenn die erzeugten Daten nicht viel sind, spiegeln sie möglicherweise nicht das erforderliche Marktmuster wider. Wenn es eine bessere Methode gibt, kann dieser Teil des Codes ersetzt werden. Auf der Grundlage dieses einfachen Designs kann die Anpassung des Zufallszahlengenerationsbereichs und einiger Koeffizienten im Code den erzeugten Dateneffekt beeinflussen.
-
Überprüfung der Daten Die erzeugten K-Liniendaten müssen auch auf Rationalität geprüft werden, um zu überprüfen, ob die hohen Eröffnungs- und niedrigen Schlusskosten gegen die Definition verstoßen, und um die Kontinuität der K-Liniendaten zu überprüfen.
Backtest-System zufälliger Tickergenerator
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("the custom data source service receives the request, self.path:", self.path, "query parameter:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is incorrect, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data.detail: ", data["detail"], "Respond to backtesting system requests.")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("Unsupported K-line period, please use 'm', 'h', or 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("Abnormal data:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("Current path:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("The file was written successfully. The following is part of the file content:")
Log("".join(lines[:5]))
else:
Log("Failed to write the file, the file is empty!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("Start the custom data source service thread, and the data is provided by the CSV file.", ", Address/Port: 0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("Failed to start custom data source service!")
Log("error message:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("Generator parameters:", "Start time:", startTime, "End time:", endTime, "K-line period:", KLinePeriod, "Initial price:", firstPrice, "Type of volatility:", arrTrendType[trendType], "Volatility coefficient:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
Praxis im Backtesting-System
- Erstellen Sie die obige Strategie-Instanz, konfigurieren Sie die Parameter und führen Sie sie aus.
- Der Live-Handel (Strategie-Instanz) muss auf dem auf dem Server bereitgestellten Docker ausgeführt werden, er benötigt eine öffentliche Netzwerk-IP, damit das Backtesting-System darauf zugreifen und Daten erhalten kann.
- Klicken Sie auf die Interaktionsschaltfläche, und die Strategie wird automatisch mit der Generierung zufälliger Tickerdaten beginnen.
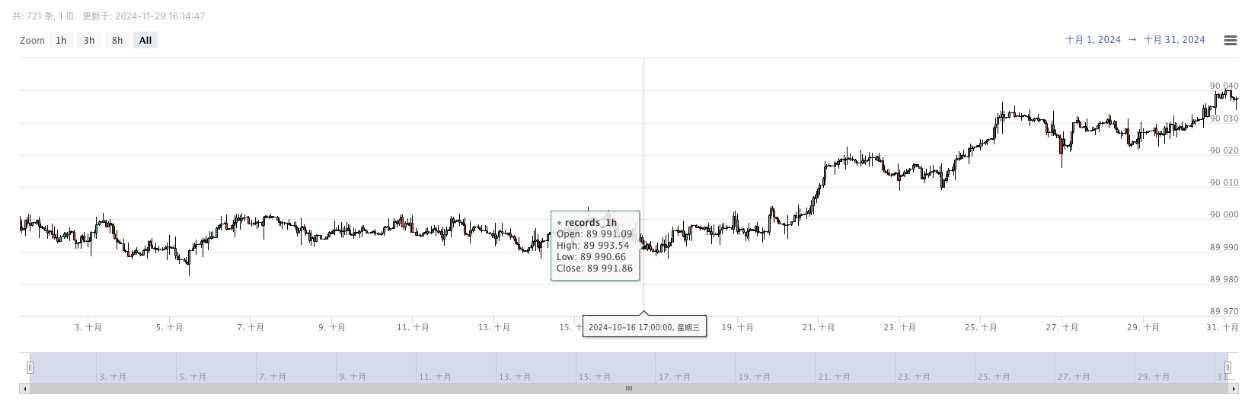
- Die erzeugten Daten werden für eine einfache Beobachtung auf dem Diagramm angezeigt und in der lokalen Datei data.csv erfasst.
- Jetzt können wir diese zufällig generierten Daten verwenden und jede Strategie für Backtesting verwenden:

/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
Nach den oben genannten Angaben konfigurieren und anpassen.http://xxx.xxx.xxx.xxx:9090ist die IP-Adresse des Servers und der offene Port der Strategie zur Erstellung zufälliger Tickers.
Dies ist die benutzerdefinierte Datenquelle, die im Abschnitt benutzerdefinierte Datenquelle des Plattform-API-Dokumentes zu finden ist.
- Nachdem das Backtest-System die Datenquelle eingerichtet hat, können wir die zufälligen Marktdaten testen:
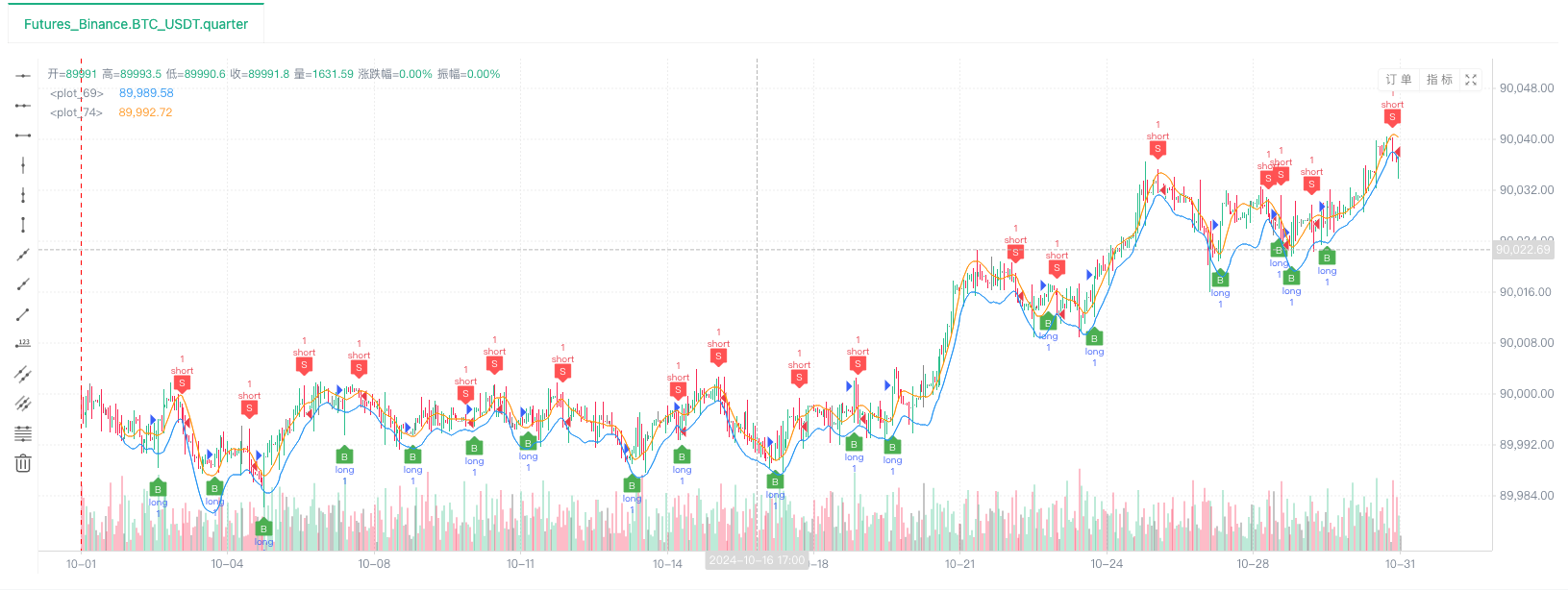
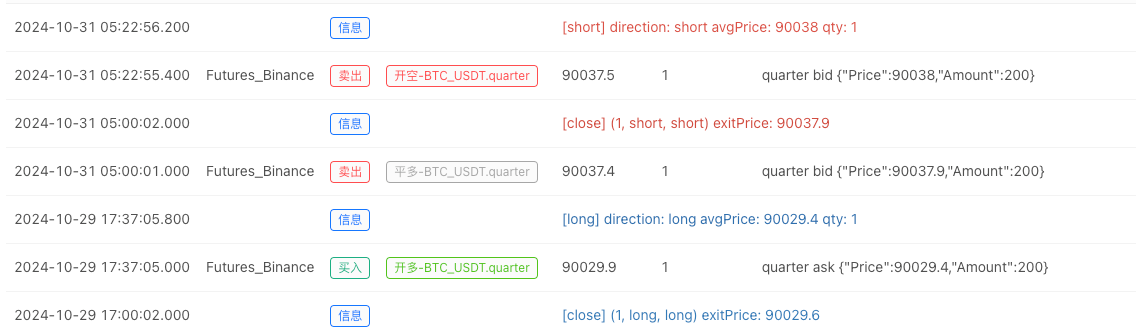
Zu diesem Zeitpunkt wird das Backtest-System mit unseren
- Oh, ja, ich habe fast vergessen, es zu erwähnen! Der Grund, warum dieses Python-Programm des Zufalls-Ticker-Generators einen Live-Handel erstellt, ist die Demonstration, Bedienung und Anzeige der generierten K-Liniendaten zu erleichtern. In der tatsächlichen Anwendung können Sie ein unabhängiges Python-Skript schreiben, so dass Sie nicht den Live-Handel ausführen müssen.
Strategie-Quellcode:Backtest-System zufälliger Tickergenerator
Vielen Dank für Ihre Unterstützung und Lesung.
- DEX-Börsen Quantitative Praxis ((1)-- dYdX v4 Benutzerhandbuch
- Einführung der Lead-Lag-Suite in der Kryptowährung (3)
- Einführung in Lead-Lag-Arbitrage in Kryptowährungen (2)
- Einführung der Lead-Lag-Suite in der digitalen Währung (2)
- Diskussion über den externen Signalempfang der FMZ-Plattform: Eine Komplettlösung für den Empfang von Signalen mit integriertem Http-Service in der Strategie
- FMZ-Plattform: Erforschung von Signalempfangsstrategien für externe Netzwerke
- Einführung in Lead-Lag-Arbitrage in Kryptowährungen (1)
- Einführung der Lead-Lag-Suite in der Kryptowährung (1)
- Diskussion über den externen Signalempfang der FMZ-Plattform: Erweiterte API VS Strategie eingebauter HTTP-Service
- FMZ-Plattform-External Signal Reception: Erweiterung der API vs. Strategien für den eingebauten HTTP-Dienst
- Strategie-Testmethoden basierend auf Random-Market-Generatoren untersucht
- Neue Funktion von FMZ Quant: _Serve-Funktion zum einfachen Erstellen von HTTP-Diensten
- Erfinder quantifizieren neue Funktionen: Erstellen von HTTP-Diensten mit _Serve
- FMZ Quant Trading Platform benutzerdefinierte Protokollzugriffsanleitung
- Strategie für den Erwerb und die Überwachung der FMZ-Finanzierungsquote
- FMZ-Finanzierungsraten Akquisition und Überwachung Strategien
- Eine Strategievorlage ermöglicht Ihnen, WebSocket Market nahtlos zu nutzen
- Eine Strategievorlage, mit der Sie die WebSocket-Branche nahtlos nutzen können
- Inventor Quantitative Trading Plattform General Protocol Zugriffsanleitung
- Wie man nach dem FMZ-Upgrade schnell eine universelle Multi-Währungs-Handelsstrategie aufbaut