The advantages and disadvantages of the three major categories of machine learning algorithms
Author: Inventors quantify - small dreams, Created: 2017-10-30 12:01:59, Updated: 2017-11-08 13:55:03The advantages and disadvantages of the three major categories of machine learning algorithms
In machine learning, the goal is either prediction or clustering. This article focuses on prediction. Prediction is the process of predicting the value of an output variable from a set of input variables. For example, if we get a set of features for a house, we can predict its sale price. Prediction problems can be divided into two categories: With that in mind, let's take a look at the most prominent and commonly used algorithms in machine learning. We've divided them into three categories: linear models, tree-based models, and neural networks, focusing on the six most commonly used algorithms:
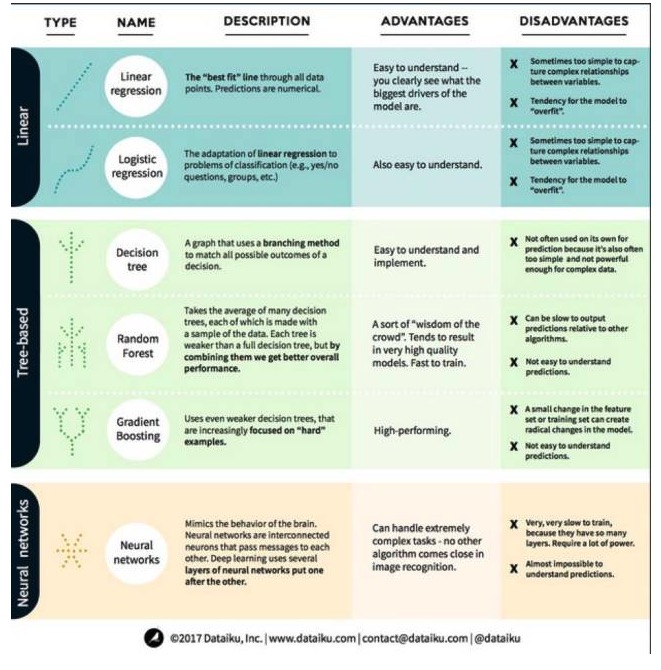
Linear model algorithm: A linear model uses a simple formula to find the line that best fits the curve through a set of data points. This method dates back over 200 years and is widely used in both statistics and machine learning. Because of its simplicity, it is useful for statistics. The variable you want to predict is represented as an equation of the variable you already know, so the prediction is just a matter of entering the variable itself and then calculating the answer to the equation.
- ### ## 1. Linear regression
Linear regression, or more accurately the linear least squares regression, is the most standard form of linear model. For regression problems, linear regression is the simplest linear model. Its disadvantage is that the model is easily over-fitted, that is, the model fully adapts to the data that has been trained at the expense of its ability to propagate to new data.
Another disadvantage of linear models is that since they are very simple, they are not easy to predict more complex behavior when the input variables are not independent.
- ##### 2. Logical regression
Logical regression is the adaptation of linear regression to classification problems. The disadvantages of logical regression are the same as linear regression. Logical functions are very good for classification problems because they introduce threshold effects.
Second, the tree model algorithm
- ###############################################################################################################################################################################################################################################################
A decision tree is an illustration of each possible outcome of a decision using a branching method. For example, you decide to order a salad, and your first decision is probably the type of raw cabbage, then the side dishes, then the type of salad dressing. We can represent all possible outcomes in a decision tree.
In order to train decision trees, we need to use the training data set and find out which attribute is most useful to the target. For example, in the fraud detection use case, we may find that the attribute that has the greatest impact on predicting fraud risk is the country. After branching the first attribute, we get two subsets, which are most accurately predictable if we only know the first attribute.
- ### ## 2 ## Random forest
Random forests are the average of many decision trees, each of which is trained with a random sample of data. Each tree in a random forest is weaker than a complete decision tree, but putting all the trees together gives us better overall performance due to the advantages of diversity.
Random forests are a very popular algorithm in machine learning today. Random forests are easy to train, and perform quite well. Its disadvantage is that, compared to other algorithms, random forests can be slow to output predictions, so it may not be possible to choose random forests when fast predictions are needed.
- ### ## 3, elevation increase
Gradient Boosting, like Random Forests, is made up of weak decision trees. The biggest difference between gradient boosting and random forests is that in gradient boosting, the trees are trained one by one. Each back tree is trained primarily by the tree in front to identify the wrong data. This makes gradient boosting more focused on predictable situations and less difficult ones.
Training for gradient elevation is also fast and performs very well. However, small changes to the training dataset can make fundamental changes to the model, so the results it produces may not be the most viable.
Neural network algorithms: A neural network is a biological phenomenon in which neurons in the brain are interconnected and exchange information with each other. This idea is now applied to the field of machine learning, where it is known as ANN. Deep learning is a layered neural network. ANN is a series of models that acquire cognitive abilities similar to those of the human brain by learning.
Transcribed from Big Data Landscape
- Inventors quantify support for huobi and OKEX coins and USDT transactions?
- Open a withdrawal function that is integrated into the digital currency trading library
- How do you calculate the maximum funding capacity of a strategy by measuring the returns, volatility, etc. of a strategy?
- Shannon’s Demon
- It's not the technology that's complicated, it's the human mind!
- Bitfinex's interface access is slow, what do you guys have recommendations for server placement?
- Bitfinex is running erroneously, help analyze, thank you!
- Please tell me which time point the data retrieved when the API was called is based on?
- The code for the Bitcoin coin.
- Why is there only four pairs of BCH_USD, BTC_USD, ETH_USD, and LTC_USD in bitfinex?
- In the meantime, I'm going to start a new blog, and I'm going to start a new blog, and I'm going to start a new blog.
- Mechanism of final viewing
- Submitted Bug: An interaction button without a default parameter value when creating a policy failed to save
- Can the retargeting system select other currencies?
- Please translate the buy plan page
- Bitfinex has three markets, how do you get the robot to choose?
- Options from a dynamic perspective are a win-win
- Bitfinex counter-measurement and counter-measurement currency units are inconsistent
- How do you view the effectiveness of the backsliding and gold forks?
- Bithumb received account information in error