Conozca las ventajas y desventajas de los tres principales algoritmos de aprendizaje automático.
El autor:Los inventores cuantifican - sueños pequeños, Creado: 2017-10-30 12:01:59, Actualizado: 2017-11-08 13:55:03Conozca las ventajas y desventajas de los tres principales algoritmos de aprendizaje automático.
En el aprendizaje automático, el objetivo es la predicción o el clustering. Este artículo se centra en la predicción. La predicción es el proceso de estimar el valor de las variables de salida a partir de un conjunto de variables de entrada. Por ejemplo, obteniendo un conjunto de características de una casa, podemos predecir su precio de venta. Con esto en mente, vamos a ver los algoritmos más destacados y usados en el aprendizaje automático. Los dividimos en 3 categorías: modelos lineales, modelos basados en árboles y redes neuronales, y nos centramos en los 6 más usados:
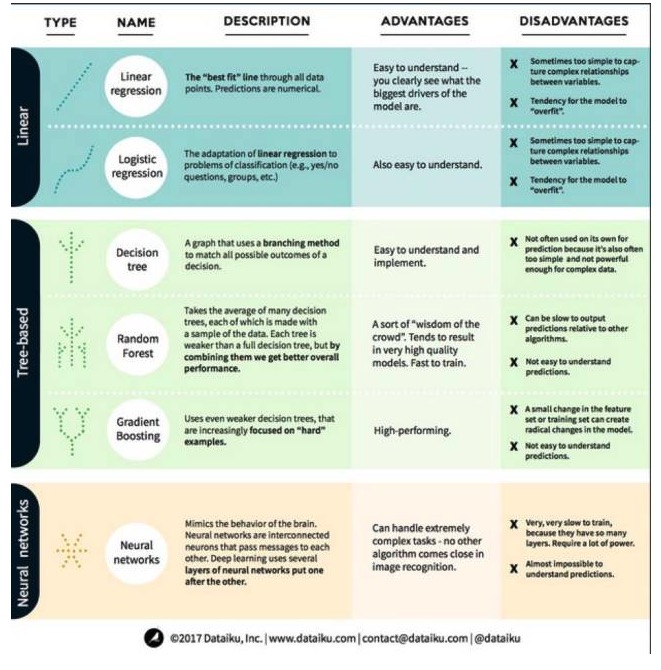
Un algoritmo de modelo lineal: un modelo lineal utiliza fórmulas simples para encontrar las líneas que mejor se ajustan a las pilas a través de un conjunto de puntos de datos. Este método se remonta a hace más de 200 años y tiene una amplia aplicación en estadística y aprendizaje automático. Debido a su simplicidad, es útil para la estadística.
- ### # 1. Regresión lineal
La regresión lineal, o más exactamente, la regresión binaria mínima de la fórmula, es la forma más estándar de un modelo lineal. Para los problemas de regresión, la regresión lineal es el modelo lineal más sencillo. Su desventaja es que el modelo es fácil de sobreajustar, es decir, que el modelo se adapta completamente a los datos entrenados, a costa de su capacidad de propagación a nuevos datos. Por lo tanto, la regresión lineal en el aprendizaje automático (y la regresión lógica de la que hablaremos más adelante) suele ser una regresión lineal, lo que significa que el modelo tiene ciertas penas para evitar la sobreajustación.
Otra desventaja de los modelos lineales es que, debido a que son muy simples, no son fáciles de predecir un comportamiento más complejo cuando las variables de entrada no son independientes.
- ### # 2. Regresión lógica
La regresión lógica es la adaptación de la regresión lineal a los problemas de clasificación. La desventaja de la regresión lógica es la misma que la regresión lineal. Las funciones lógicas son muy buenas para los problemas de clasificación, ya que introducen efectos de umbral.
Dos, el algoritmo del modelo de árbol
- ########### ### ### ### ### ### ### ### ### ### ### ### ### ### ### ## #### #### ## #### #### #### #### ## #### ### ## #### ### #### ##### ## ##### #### ## ### ## ### ## ### #### ## #### ### #### ##### ### #### ### ##### ### ###### ###########################################################################
El árbol de decisión es una ilustración de cada posible resultado de una decisión que se muestra usando el método de ramificación. Por ejemplo, si decides pedir una ensalada, tu primera decisión puede ser la variedad de colza cruda, luego de colza, y luego de la variedad de ensalada. Podemos representar todos los posibles resultados en un árbol de decisión.
Para entrenar un árbol de decisión, necesitamos usar un conjunto de datos de entrenamiento y averiguar qué propiedad es la más útil para el objetivo. Por ejemplo, en el caso de detección de fraude, podemos encontrar que la propiedad que más influye en la predicción del riesgo de fraude es el país. Después de ramificar con la primera propiedad, obtenemos dos subconjuntos, que son los más predictibles si solo sabemos la primera propiedad. Luego, encontramos la segunda propiedad que es mejor para ramificar con estas dos subconjuntas, la dividimos de nuevo, y así sucesivamente, hasta que hay suficientes propiedades para satisfacer las necesidades del objetivo.
- ### ## 2 ## # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
Los bosques aleatorios son la media de muchos árboles de decisión, en los que cada árbol de decisión se entrena con una muestra aleatoria de datos. Cada árbol en un bosque aleatorio es más débil que un árbol de decisión completo, pero si los ponemos todos juntos, podemos obtener un mejor rendimiento general debido a las ventajas de la diversidad.
El bosque aleatorio es un algoritmo muy popular en el aprendizaje automático de hoy. El bosque aleatorio es fácil de entrenar y funciona bastante bien. Su desventaja es que, en comparación con otros algoritmos, el bosque aleatorio puede ser lento en la producción de predicciones, por lo que es posible que no se elija el bosque aleatorio cuando se necesita un pronóstico rápido.
- ### # 3, elevación de la pendiente
La mayor diferencia entre la elevación de gradiente y la elevación aleatoria es que en la elevación de gradiente, los árboles son entrenados uno a uno. Cada árbol posterior es entrenado principalmente por el árbol anterior para identificar datos erróneos. Esto hace que la elevación de gradiente se centre más en situaciones más fáciles de predecir y más en situaciones menos difíciles.
El entrenamiento para elevar la gradiente también es rápido y funciona muy bien. Sin embargo, los pequeños cambios en el conjunto de datos de entrenamiento pueden hacer cambios fundamentales en el modelo y, por lo tanto, los resultados que produce pueden no ser los más viables.
Tres, algoritmos de redes neuronales: una red neuronal es un fenómeno biológico que consiste en neuronas conectadas en el cerebro que intercambian información entre sí. La idea ahora se aplica al campo del aprendizaje automático, llamado ANN. El aprendizaje profundo es una red neuronal de múltiples capas superpuestas.
Transcrito desde la plataforma de Big Data
- ¿Los inventores cuantifican las transacciones de huobi y OKEX, así como las transacciones de USDT?
- Una función de pago pública integrada en la biblioteca de transacciones de monedas digitales
- ¿Cómo calcular el máximo potencial de inversión de una estrategia mediante el recuento de ganancias, fluctuaciones, etc. de una estrategia cuantificada?
- El Demonio de Shannon.
- Lo que es complicado no es la tecnología, sino el espíritu humano.
- ¿Cuál es la recomendación de los usuarios para la ubicación del servidor?
- Bitfinex está funcionando mal, ayuda para analizar, gracias!
- ¿En qué punto de tiempo se basan los datos obtenidos al llamar a la API para la revisión?
- El código de la moneda es el siguiente:
- ¿Por qué en bitfinex sólo hay cuatro pares de transacciones: BCH_USD, BTC_USD, ETH_USD y LTC_USD?
- ¡Bombardeo de 5.000 por centavo: hacer más BTC, hacer contratos de OKEX1229 en blanco, un mes, 5000 por centavo!
- Mecanismos de observación final
- Bug presentado: fallo de guardar botones de interacción sin valores de parámetros predeterminados al crear la política
- ¿Puede el sistema de retrospección seleccionar otras monedas?
- Por favor traduce la página del plan de compra
- Bitfinex tiene tres mercados, ¿cómo puedo hacer que el robot elija?
- Opciones ganadoras bajo una perspectiva dinámica
- Bitfinex no está de acuerdo con las monedas reales y reales
- ¿Cómo se ve la eficacia de la desviación y la horquilla de oro?
- Bithumb obtuvo información de cuenta errónea