Discusión sobre el método de prueba de estrategias basado en el generador de tickers aleatorios
El autor:FMZ~Lydia, Creado: 2024-12-02 11:26:13, Actualizado: 2024-12-02 21:39:39
Prefacio
El sistema de backtesting de la Plataforma de Comercio Cuántico FMZ es un sistema de backtesting que se está iterando, actualizando y actualizando constantemente. Agrega funciones y optimiza el rendimiento gradualmente desde la función de backtesting básica inicial. Con el desarrollo de la plataforma, el sistema de backtesting continuará siendo optimizado y actualizado.
Demandas
En el campo del comercio cuantitativo, el desarrollo y la optimización de estrategias no pueden separarse de la verificación de datos reales del mercado. Sin embargo, en aplicaciones reales, debido al entorno de mercado complejo y cambiante, confiar en datos históricos para backtesting puede ser insuficiente, como la falta de cobertura de condiciones extremas de mercado o escenarios especiales. Por lo tanto, el diseño de un generador de mercado aleatorio eficiente se ha convertido en una herramienta efectiva para los desarrolladores de estrategias cuantitativas.
Cuando necesitamos dejar que la estrategia rastree datos históricos en un determinado intercambio o moneda, podemos usar la fuente de datos oficial de la plataforma FMZ para backtesting.
La importancia de utilizar datos aleatorios de ticker es:
-
- Evaluar la solidez de las estrategias El generador de ticker aleatorio puede crear una variedad de escenarios de mercado posibles, incluyendo volatilidad extrema, baja volatilidad, mercados de tendencia y mercados volátiles.
¿Puede la estrategia adaptarse a la tendencia y al cambio de volatilidad? ¿La estrategia incurrirá en una gran pérdida en condiciones extremas de mercado?
-
- Identificar las posibles debilidades de la estrategia Al simular algunas situaciones de mercado anormales (como eventos hipotéticos de cisne negro), se pueden descubrir y mejorar posibles debilidades en la estrategia.
¿Se basa demasiado la estrategia en una determinada estructura de mercado? ¿Existe el riesgo de sobreajuste de los parámetros?
-
- Optimización de los parámetros de la estrategia Los datos generados aleatoriamente proporcionan un entorno de prueba más diverso para la optimización de parámetros de estrategia, sin tener que confiar completamente en datos históricos.
-
- Relleno del vacío en los datos históricos En algunos mercados (como los mercados emergentes o los pequeños mercados de comercio de divisas), los datos históricos pueden no ser suficientes para cubrir todas las condiciones posibles del mercado.
-
- Desarrollo iterativo rápido El uso de datos aleatorios para pruebas rápidas puede acelerar la iteración del desarrollo de estrategias sin depender de las condiciones del mercado en tiempo real o la limpieza y organización de datos que consumen mucho tiempo.
Sin embargo, también es necesario evaluar la estrategia de manera racional.
-
- Aunque los generadores aleatorios de mercado son útiles, su importancia depende de la calidad de los datos generados y del diseño del escenario objetivo:
-
- La lógica de generación debe estar cerca del mercado real: si el mercado generado al azar está completamente fuera de contacto con la realidad, los resultados de las pruebas pueden carecer de valor de referencia.
-
- No puede sustituir completamente las pruebas de datos reales: los datos aleatorios sólo pueden complementar el desarrollo y la optimización de las estrategias.
Dicho esto, ¿cómo podemos "fabricar" algunos datos? ¿Cómo podemos "fabricar" datos para que el sistema de backtesting pueda usarlos de manera cómoda, rápida y fácil?
Ideas de diseño
Este artículo está diseñado para proporcionar un punto de partida para la discusión y proporciona un cálculo de generación de ticker aleatorio relativamente simple. De hecho, hay una variedad de algoritmos de simulación, modelos de datos y otras tecnologías que se pueden aplicar. Debido al espacio limitado de la discusión, no utilizaremos métodos de simulación de datos complejos.
Combinando la función de fuente de datos personalizada del sistema de backtesting de la plataforma, escribimos un programa en Python.
-
- Generar un conjunto de datos de línea K al azar y escribirlos en un archivo CSV para la grabación persistente, de modo que los datos generados se pueden guardar.
-
- Luego crear un servicio para proporcionar soporte de fuente de datos para el sistema de backtesting.
-
- Mostrar los datos generados de la línea K en el gráfico.
Para algunos estándares de generación y almacenamiento de archivos de datos de línea K, se pueden definir los siguientes controles de parámetros:
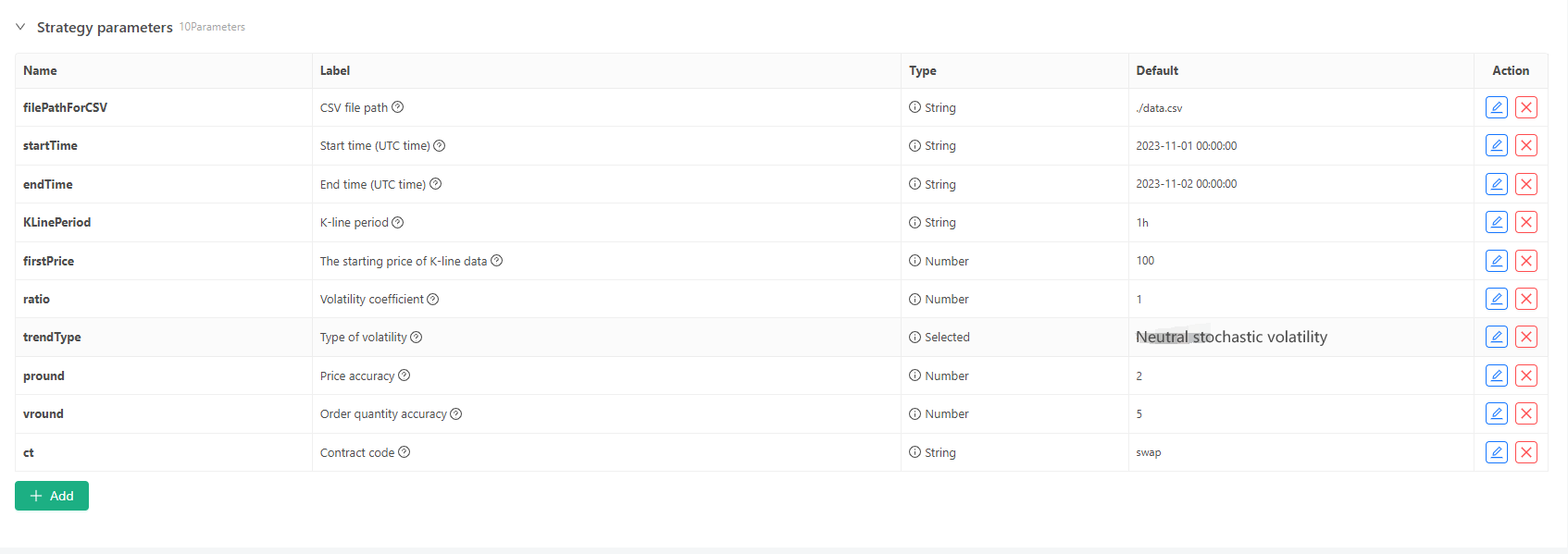
-
Modo de generación aleatoria de datos Para la simulación del tipo de fluctuación de los datos de la línea K, un diseño simple se hace simplemente utilizando la probabilidad de números aleatorios positivos y negativos. Basándose en este diseño simple, ajustar el rango de generación de números aleatorios y algunos coeficientes en el código puede afectar el efecto de los datos generados.
-
Verificación de los datos Los datos generados de la línea K también deben comprobarse en cuanto a su racionalidad, para comprobar si los altos precios de apertura y los bajos de cierre violan la definición y para comprobar la continuidad de los datos de la línea K.
Sistema de pruebas de retroceso Generador de ticker aleatorio
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("the custom data source service receives the request, self.path:", self.path, "query parameter:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is incorrect, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data.detail: ", data["detail"], "Respond to backtesting system requests.")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("Unsupported K-line period, please use 'm', 'h', or 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("Abnormal data:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("Current path:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("The file was written successfully. The following is part of the file content:")
Log("".join(lines[:5]))
else:
Log("Failed to write the file, the file is empty!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("Start the custom data source service thread, and the data is provided by the CSV file.", ", Address/Port: 0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("Failed to start custom data source service!")
Log("error message:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("Generator parameters:", "Start time:", startTime, "End time:", endTime, "K-line period:", KLinePeriod, "Initial price:", firstPrice, "Type of volatility:", arrTrendType[trendType], "Volatility coefficient:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
Práctica en el sistema de pruebas de retroceso
- Crear la instancia de la estrategia anterior, configurar los parámetros y ejecutarlo.
- El comercio en vivo (instancia de estrategia) debe ejecutarse en el docker desplegado en el servidor, necesita una IP de red pública, para que el sistema de backtesting pueda acceder a él y obtener datos.
- Haga clic en el botón de interacción, y la estrategia comenzará a generar datos de ticker aleatorios automáticamente.
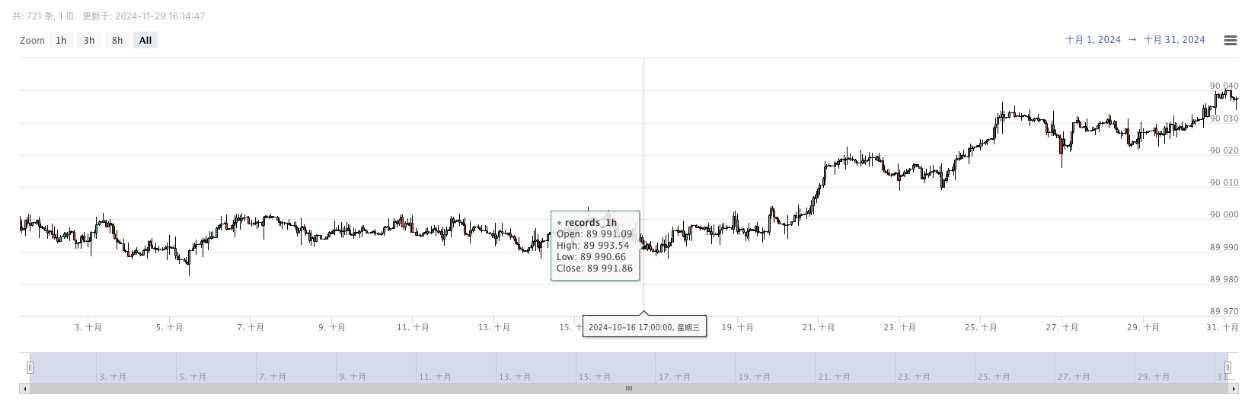
- Los datos generados se mostrarán en el gráfico para una fácil observación, y los datos se registrarán en el archivo local data.csv.
- Ahora podemos usar estos datos generados al azar y utilizar cualquier estrategia para backtesting:

/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
Según la información anterior, configurar y ajustar.http://xxx.xxx.xxx.xxx:9090es la dirección IP del servidor y el puerto abierto de la estrategia de generación aleatoria de tickers.
Este es el origen de datos personalizado, que se puede encontrar en la sección de Fuente de datos personalizados del documento de la API de la plataforma.
- Después de que el sistema de backtest establece la fuente de datos, podemos probar los datos de mercado aleatorios:
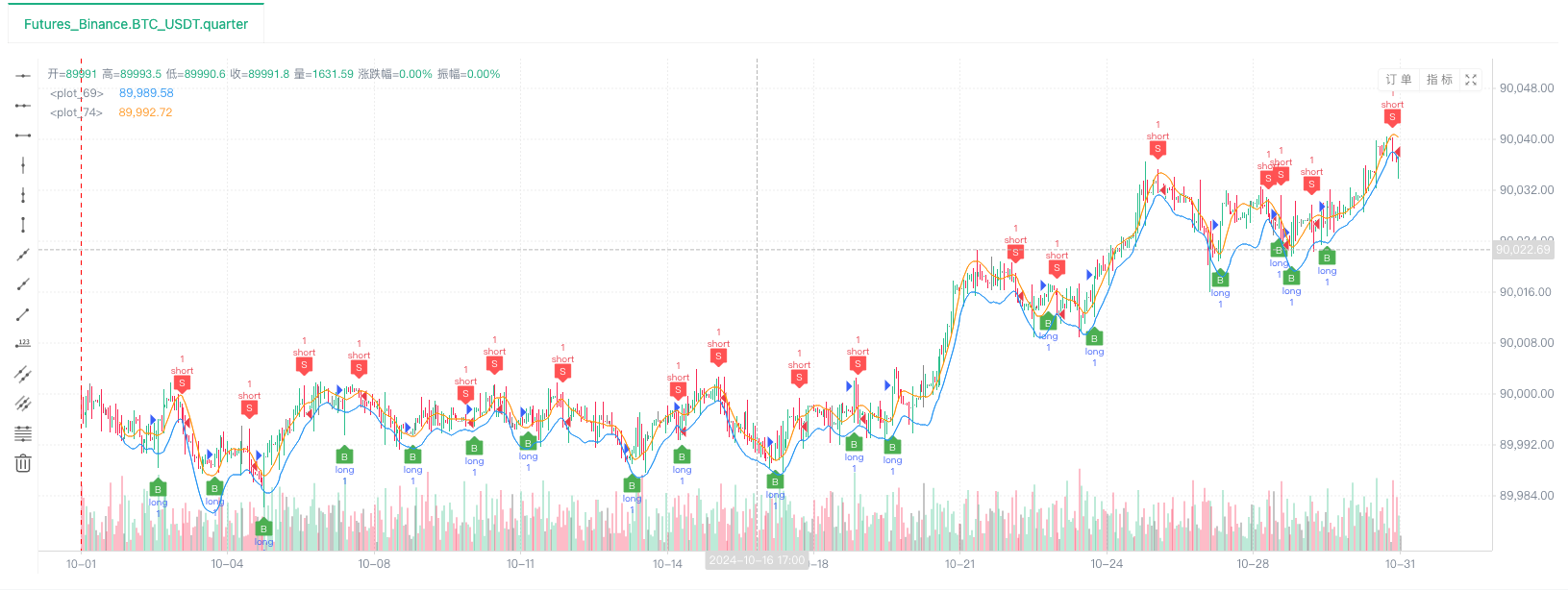
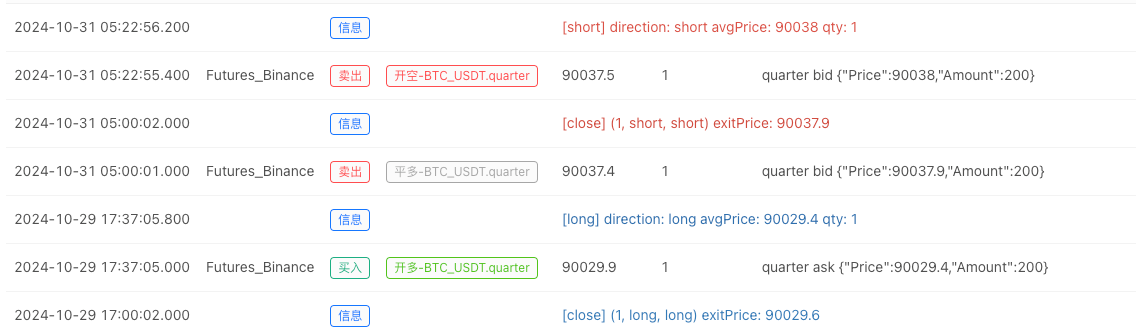
En este momento, el sistema de backtest se prueba con nuestros datos
- Oh, sí, casi me olvido de mencionarlo! La razón por la que este programa de Python de generador de ticker aleatorio crea una negociación en vivo es para facilitar la demostración, operación y visualización de los datos de línea K generados. En la aplicación real, se puede escribir un script Python independiente, por lo que no tiene que ejecutar la negociación en vivo.
Código fuente de la estrategia:Sistema de pruebas de retroceso Generador de ticker aleatorio
Gracias por su apoyo y lectura.
- Prácticas de cuantificación de las bolsas DEX ((1) -- dYdX v4 Guía de uso
- Introducción al conjunto de Lead-Lag en las monedas digitales (3)
- Introducción al arbitraje de lead-lag en criptomonedas (2)
- Introducción al conjunto de Lead-Lag en las monedas digitales (2)
- Discusión sobre la recepción de señales externas de la plataforma FMZ: una solución completa para recibir señales con servicio HTTP incorporado en la estrategia
- Exploración de la recepción de señales externas de la plataforma FMZ: estrategias para una solución completa de recepción de señales de servicios HTTP integrados
- Introducción al arbitraje de lead-lag en criptomonedas (1)
- Introducción al conjunto de Lead-Lag en las monedas digitales (1)
- Discusión sobre la recepción de señales externas de la plataforma FMZ: API extendida VS estrategia Servicio HTTP incorporado
- Exploración de la recepción de señales externas de la plataforma FMZ: API de expansión vs estrategia de servicio HTTP incorporado
- Explorar métodos de prueba de estrategias basados en generadores de mercado aleatorios
- Nueva característica de FMZ Quant: Utilice la función _Serve para crear servicios HTTP fácilmente
- Nuevas capacidades cuantificadas por los inventores: fácil creación de servicios HTTP con _Serve
- Guía de acceso al protocolo personalizado de la plataforma de negociación cuántica FMZ
- Estrategia de adquisición y seguimiento de la tasa de financiación de la FMZ
- Estrategias de captación y monitoreo de las tasas de fondos de FMZ
- Una plantilla de estrategia le permite utilizar WebSocket Market sin problemas
- Una plantilla de políticas que te permite usar el sector WebSocket sin problemas
- Guía de acceso a las plataformas de intercambio cuantitativo de los inventores
- Cómo construir una estrategia de negociación universal de varias monedas rápidamente después de la actualización de FMZ