Modelo de factores de las criptomonedas
 12
12183
12
12183
[TOC]

Marco del modelo factorial
Existen numerosos informes de investigación sobre el modelo multifactorial del mercado de valores, con una rica teoría y práctica. El mercado de divisas digitales es suficiente para la investigación de factores en términos de número de divisas, valor total del mercado, volumen de transacciones y mercado de derivados. Este artículo está dirigido principalmente a principiantes en estrategias cuantitativas y no implicará principios matemáticos complejos ni análisis estadísticos. Tomando como fuente de datos el mercado de futuros, se construye un marco de investigación factorial simple para facilitar la evaluación de indicadores factoriales.
Un factor puede considerarse un indicador y puede escribirse como una expresión. Los factores cambian continuamente y reflejan información sobre el rendimiento futuro. Por lo general, los factores representan una lógica de inversión.
Por ejemplo, el factor precio de cierre se basa en el supuesto de que los precios de las acciones pueden predecir los rendimientos futuros. Cuanto más alto sea el precio de las acciones, mayores serán los rendimientos futuros (o menores). Construir una cartera basada en este factor es en realidad una inversión. modelo/estrategia de rotación regular de posiciones para comprar acciones de alto precio. En términos generales, los factores que pueden generar consistentemente rendimientos excedentes suelen denominarse Alfa. Por ejemplo, los académicos y la comunidad inversora han verificado que los factores de capitalización de mercado y los factores de impulso son factores eficaces.
Ya se trate del mercado de valores o del mercado de divisas digitales, se trata de un sistema complejo. Ningún factor puede predecir por completo los rendimientos futuros, pero aun así tiene cierto grado de previsibilidad. El alfa efectivo (modelo de inversión) se vuelve gradualmente ineficaz a medida que se invierten más fondos. Pero este proceso generará otros modelos en el mercado, dando nacimiento a nuevos alfas. El factor de capitalización de mercado fue en su día una estrategia muy eficaz en el mercado de acciones tipo A. Basta con comprar 10 acciones con la capitalización de mercado más baja y ajustarlas una vez al día. La prueba retrospectiva de diez años a partir de 2007 arrojará un rendimiento más de 400 veces superior, mucho más que el de la mayoría de las acciones de la serie A. superando el mercado general. Sin embargo, en 2017 el mercado de acciones blue chips reflejó la ineficacia del factor de pequeña capitalización, mientras que el factor valor se volvió popular en su lugar. Por lo tanto, es necesario equilibrar y experimentar constantemente entre la verificación y el uso de alfa.
Los factores que buscamos son la base para establecer estrategias. Se pueden construir mejores estrategias combinando múltiples factores efectivos no relacionados.
import requests
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests, zipfile, io
%matplotlib inline
Fuente de datos
Hasta ahora, los datos de la línea K por hora de los futuros perpetuos de Binance USDT desde principios de 2022 hasta el presente han superado las 150 monedas. Como se mencionó anteriormente, el modelo factorial es un modelo de selección de moneda que apunta a todas las monedas en lugar de solo a una moneda específica. Los datos de la línea K incluyen datos como precios altos de apertura y precios bajos de cierre, volumen de operaciones, número de transacciones, volumen de compras activas, etc. Estos datos ciertamente no son la fuente de todos los factores, como el índice bursátil de EE. UU., las expectativas de aumento de las tasas de interés. , rentabilidad, datos on-chain, atención en redes sociales, etc. Las fuentes de datos menos populares también pueden revelar un alfa efectivo, pero los datos básicos de volumen y precios también son suficientes.
## 当前交易对
Info = requests.get('https://fapi.binance.com/fapi/v1/exchangeInfo')
symbols = [s['symbol'] for s in Info.json()['symbols']]
symbols = list(filter(lambda x: x[-4:] == 'USDT', [s.split('_')[0] for s in symbols]))
print(symbols)
Out:
['BTCUSDT', 'ETHUSDT', 'BCHUSDT', 'XRPUSDT', 'EOSUSDT', 'LTCUSDT', 'TRXUSDT', 'ETCUSDT', 'LINKUSDT',
'XLMUSDT', 'ADAUSDT', 'XMRUSDT', 'DASHUSDT', 'ZECUSDT', 'XTZUSDT', 'BNBUSDT', 'ATOMUSDT', 'ONTUSDT',
'IOTAUSDT', 'BATUSDT', 'VETUSDT', 'NEOUSDT', 'QTUMUSDT', 'IOSTUSDT', 'THETAUSDT', 'ALGOUSDT', 'ZILUSDT',
'KNCUSDT', 'ZRXUSDT', 'COMPUSDT', 'OMGUSDT', 'DOGEUSDT', 'SXPUSDT', 'KAVAUSDT', 'BANDUSDT', 'RLCUSDT',
'WAVESUSDT', 'MKRUSDT', 'SNXUSDT', 'DOTUSDT', 'DEFIUSDT', 'YFIUSDT', 'BALUSDT', 'CRVUSDT', 'TRBUSDT',
'RUNEUSDT', 'SUSHIUSDT', 'SRMUSDT', 'EGLDUSDT', 'SOLUSDT', 'ICXUSDT', 'STORJUSDT', 'BLZUSDT', 'UNIUSDT',
'AVAXUSDT', 'FTMUSDT', 'HNTUSDT', 'ENJUSDT', 'FLMUSDT', 'TOMOUSDT', 'RENUSDT', 'KSMUSDT', 'NEARUSDT',
'AAVEUSDT', 'FILUSDT', 'RSRUSDT', 'LRCUSDT', 'MATICUSDT', 'OCEANUSDT', 'CVCUSDT', 'BELUSDT', 'CTKUSDT',
'AXSUSDT', 'ALPHAUSDT', 'ZENUSDT', 'SKLUSDT', 'GRTUSDT', '1INCHUSDT', 'CHZUSDT', 'SANDUSDT', 'ANKRUSDT',
'BTSUSDT', 'LITUSDT', 'UNFIUSDT', 'REEFUSDT', 'RVNUSDT', 'SFPUSDT', 'XEMUSDT', 'BTCSTUSDT', 'COTIUSDT',
'CHRUSDT', 'MANAUSDT', 'ALICEUSDT', 'HBARUSDT', 'ONEUSDT', 'LINAUSDT', 'STMXUSDT', 'DENTUSDT', 'CELRUSDT',
'HOTUSDT', 'MTLUSDT', 'OGNUSDT', 'NKNUSDT', 'SCUSDT', 'DGBUSDT', '1000SHIBUSDT', 'ICPUSDT', 'BAKEUSDT',
'GTCUSDT', 'BTCDOMUSDT', 'TLMUSDT', 'IOTXUSDT', 'AUDIOUSDT', 'RAYUSDT', 'C98USDT', 'MASKUSDT', 'ATAUSDT',
'DYDXUSDT', '1000XECUSDT', 'GALAUSDT', 'CELOUSDT', 'ARUSDT', 'KLAYUSDT', 'ARPAUSDT', 'CTSIUSDT', 'LPTUSDT',
'ENSUSDT', 'PEOPLEUSDT', 'ANTUSDT', 'ROSEUSDT', 'DUSKUSDT', 'FLOWUSDT', 'IMXUSDT', 'API3USDT', 'GMTUSDT',
'APEUSDT', 'BNXUSDT', 'WOOUSDT', 'FTTUSDT', 'JASMYUSDT', 'DARUSDT', 'GALUSDT', 'OPUSDT', 'BTCUSDT',
'ETHUSDT', 'INJUSDT', 'STGUSDT', 'FOOTBALLUSDT', 'SPELLUSDT', '1000LUNCUSDT', 'LUNA2USDT', 'LDOUSDT',
'CVXUSDT']
print(len(symbols))
Out:
153
#获取任意周期K线的函数
def GetKlines(symbol='BTCUSDT',start='2020-8-10',end='2021-8-10',period='1h',base='fapi',v = 'v1'):
Klines = []
start_time = int(time.mktime(datetime.strptime(start, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000
end_time = min(int(time.mktime(datetime.strptime(end, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000,time.time()*1000)
intervel_map = {'m':60*1000,'h':60*60*1000,'d':24*60*60*1000}
while start_time < end_time:
mid_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
url = 'https://'+base+'.binance.com/'+base+'/'+v+'/klines?symbol=%s&interval=%s&startTime=%s&endTime=%s&limit=1000'%(symbol,period,start_time,mid_time)
res = requests.get(url)
res_list = res.json()
if type(res_list) == list and len(res_list) > 0:
start_time = res_list[-1][0]+int(period[:-1])*intervel_map[period[-1]]
Klines += res_list
if type(res_list) == list and len(res_list) == 0:
start_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
if mid_time >= end_time:
break
df = pd.DataFrame(Klines,columns=['time','open','high','low','close','amount','end_time','volume','count','buy_amount','buy_volume','null']).astype('float')
df.index = pd.to_datetime(df.time,unit='ms')
return df
start_date = '2022-1-1'
end_date = '2022-09-14'
period = '1h'
df_dict = {}
for symbol in symbols:
df_s = GetKlines(symbol=symbol,start=start_date,end=end_date,period=period,base='fapi',v='v1')
if not df_s.empty:
df_dict[symbol] = df_s
symbols = list(df_dict.keys())
print(df_s.columns)
Out:
Index(['time', 'open', 'high', 'low', 'close', 'amount', 'end_time', 'volume',
'count', 'buy_amount', 'buy_volume', 'null'],
dtype='object')
Inicialmente extraemos los datos de interés de los datos de la línea K: precio de cierre, precio de apertura, volumen de operaciones, número de transacciones y tasa de compra activa, y utilizamos estos datos como base para procesar los factores requeridos.
df_close = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_open = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_volume = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_buy_ratio = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_count = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
for symbol in df_dict.keys():
df_s = df_dict[symbol]
df_close[symbol] = df_s.close
df_open[symbol] = df_s.open
df_volume[symbol] = df_s.volume
df_count[symbol] = df_s['count']
df_buy_ratio[symbol] = df_s.buy_amount/df_s.amount
df_close = df_close.dropna(how='all')
df_open = df_open.dropna(how='all')
df_volume = df_volume.dropna(how='all')
df_count = df_count.dropna(how='all')
df_buy_ratio = df_buy_ratio.dropna(how='all')
Si observamos el desempeño del índice del mercado, se puede decir que es bastante sombrío, con una caída del 60% desde principios de año.
df_norm = df_close/df_close.fillna(method='bfill').iloc[0] #归一化
df_norm.mean(axis=1).plot(figsize=(15,6),grid=True);
#最终指数收益图
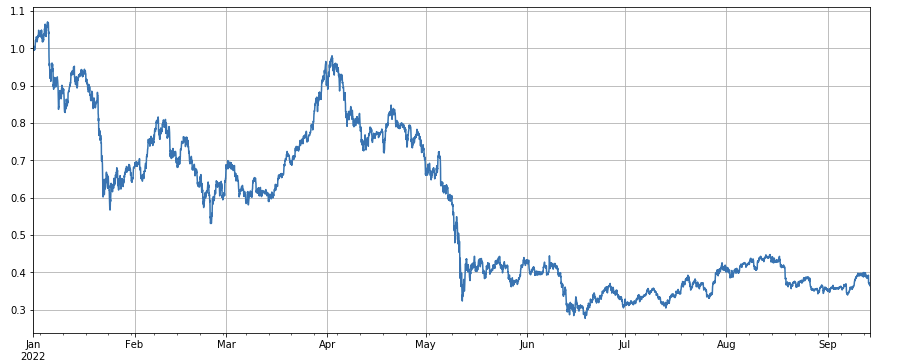
Determinación de la validez factorial
Método de regresión La tasa de rendimiento del siguiente período se toma como variable dependiente, el factor a probar se toma como variable independiente y el coeficiente obtenido por regresión es la tasa de rendimiento del factor. Después de construir la ecuación de regresión, usualmente nos referimos a la media absoluta del valor del coeficiente t, la proporción de la secuencia de valores absolutos del valor del coeficiente t mayor que 2, el rendimiento anualizado del factor, la volatilidad del rendimiento anualizado del factor, el ratio de Sharpe de El rendimiento de los factores y otros parámetros. Eficacia y volatilidad de los factores. Puede realizar una regresión de varios factores a la vez; consulte la documentación de barra para obtener más detalles.
IC, IR y otros indicadores El denominado IC es el coeficiente de correlación entre el factor y la tasa de rendimiento del siguiente período. En la actualidad, se utiliza generalmente RANK_IC, que es el coeficiente de correlación entre la clasificación del factor y la tasa de rendimiento de las acciones del siguiente período. IR es generalmente la media de la secuencia IC/la desviación estándar de la secuencia IC.
Regresión jerárquica En este artículo se utilizará este método, que consiste en ordenar los factores a probar, dividir las monedas en N grupos para realizar pruebas retrospectivas grupales y utilizar un período fijo para ajustar las posiciones. Si la situación es ideal, los rendimientos de N grupos de monedas mostrarán una buena monotonía, aumentando o disminuyendo monótonamente, y la brecha de rendimiento entre cada grupo será grande. Estos factores se reflejan en una mejor discriminación. Si el primer grupo tiene el mayor rendimiento y el último grupo tiene el menor, entonces opere a largo plazo en el primer grupo y a corto plazo en el último grupo. La tasa de rendimiento final es un indicador de referencia del ratio de Sharpe.
Operación de backtesting real
Según los factores, las monedas seleccionadas se dividen en 3 grupos según la clasificación de menor a mayor. Cada grupo de monedas representa aproximadamente 1⁄3. Si un factor es efectivo, cuanto menor sea la proporción de cada grupo, mayor será la rendimiento, pero también significa que los fondos asignados a cada moneda son relativamente grandes. Si las posiciones largas y cortas tienen un apalancamiento de 1x cada una, y el primer y el último grupo son 10 monedas respectivamente, entonces cada uno representa el 10%. Si una moneda que es subidas en corto, si se duplica la inversión el retroceso es del 20%; correspondientemente, si el número de grupos es 50, el retroceso es del 4%. Diversificar las monedas puede reducir el riesgo de cisnes negros. Entre en largo en el primer grupo (con el valor de factor más pequeño) y en corto en el tercer grupo. Si cuanto mayor sea el factor, mayor será el rendimiento, puede invertir las posiciones largas y cortas o simplemente hacer que el factor sea negativo o inverso.
El poder predictivo de un factor generalmente se puede evaluar de manera aproximada basándose en el rendimiento final del backtest y el índice de Sharpe. Además, también es necesario hacer referencia a si la expresión del factor es simple, insensible al tamaño de la agrupación, insensible al intervalo de ajuste de posición, insensible al tiempo inicial del backtest, etc.
En cuanto a la frecuencia de ajuste de posiciones, el mercado de valores a menudo tiene un ciclo de 5 días, 10 días y un mes, pero para el mercado de divisas digitales, dicho ciclo es indudablemente demasiado largo, y las condiciones del mercado en el mercado real se monitorean en en tiempo real, por lo que es difícil ceñirse a un ciclo específico. No es necesario volver a ajustar las posiciones, por lo que en el trading real ajustamos las posiciones en tiempo real o en períodos cortos de tiempo.
Respecto a cómo cerrar una posición, según el método tradicional, puedes cerrar la posición si no está en el grupo durante la siguiente clasificación. Sin embargo, en el caso de ajuste de posición en tiempo real, algunas monedas pueden estar en la línea divisoria y las posiciones pueden cerrarse de un lado a otro. Por lo tanto, esta estrategia adopta el enfoque de esperar cambios en la agrupación y cerrar posiciones cuando sea necesario abrir posiciones en la dirección opuesta. Por ejemplo, si se va en largo en el primer grupo, cuando la divisa en la posición larga se divide en el segundo grupo, Tercer grupo, puedes cerrar la posición y ponerte en corto. Si cierra posiciones en un período fijo, como todos los días o cada 8 horas, también puede cerrar las posiciones sin estar en un grupo. Puedes probar más.
#回测引擎
class Exchange:
def __init__(self, trade_symbols, fee=0.0004, initial_balance=10000):
self.initial_balance = initial_balance #初始的资产
self.fee = fee
self.trade_symbols = trade_symbols
self.account = {'USDT':{'realised_profit':0, 'unrealised_profit':0, 'total':initial_balance, 'fee':0, 'leverage':0, 'hold':0}}
for symbol in trade_symbols:
self.account[symbol] = {'amount':0, 'hold_price':0, 'value':0, 'price':0, 'realised_profit':0,'unrealised_profit':0,'fee':0}
def Trade(self, symbol, direction, price, amount):
cover_amount = 0 if direction*self.account[symbol]['amount'] >=0 else min(abs(self.account[symbol]['amount']), amount)
open_amount = amount - cover_amount
self.account['USDT']['realised_profit'] -= price*amount*self.fee #扣除手续费
self.account['USDT']['fee'] += price*amount*self.fee
self.account[symbol]['fee'] += price*amount*self.fee
if cover_amount > 0: #先平仓
self.account['USDT']['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount #利润
self.account[symbol]['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount
self.account[symbol]['amount'] -= -direction*cover_amount
self.account[symbol]['hold_price'] = 0 if self.account[symbol]['amount'] == 0 else self.account[symbol]['hold_price']
if open_amount > 0:
total_cost = self.account[symbol]['hold_price']*direction*self.account[symbol]['amount'] + price*open_amount
total_amount = direction*self.account[symbol]['amount']+open_amount
self.account[symbol]['hold_price'] = total_cost/total_amount
self.account[symbol]['amount'] += direction*open_amount
def Buy(self, symbol, price, amount):
self.Trade(symbol, 1, price, amount)
def Sell(self, symbol, price, amount):
self.Trade(symbol, -1, price, amount)
def Update(self, close_price): #对资产进行更新
self.account['USDT']['unrealised_profit'] = 0
self.account['USDT']['hold'] = 0
for symbol in self.trade_symbols:
if not np.isnan(close_price[symbol]):
self.account[symbol]['unrealised_profit'] = (close_price[symbol] - self.account[symbol]['hold_price'])*self.account[symbol]['amount']
self.account[symbol]['price'] = close_price[symbol]
self.account[symbol]['value'] = abs(self.account[symbol]['amount'])*close_price[symbol]
self.account['USDT']['hold'] += self.account[symbol]['value']
self.account['USDT']['unrealised_profit'] += self.account[symbol]['unrealised_profit']
self.account['USDT']['total'] = round(self.account['USDT']['realised_profit'] + self.initial_balance + self.account['USDT']['unrealised_profit'],6)
self.account['USDT']['leverage'] = round(self.account['USDT']['hold']/self.account['USDT']['total'],3)
#测试因子的函数
def Test(factor, symbols, period=1, N=40, value=300):
e = Exchange(symbols, fee=0.0002, initial_balance=10000)
res_list = []
index_list = []
factor = factor.dropna(how='all')
for idx, row in factor.iterrows():
if idx.hour % period == 0:
buy_symbols = row.sort_values().dropna()[0:N].index
sell_symbols = row.sort_values().dropna()[-N:].index
prices = df_close.loc[idx,]
index_list.append(idx)
for symbol in symbols:
if symbol in buy_symbols and e.account[symbol]['amount'] <= 0:
e.Buy(symbol,prices[symbol],value/prices[symbol]-e.account[symbol]['amount'])
if symbol in sell_symbols and e.account[symbol]['amount'] >= 0:
e.Sell(symbol,prices[symbol], value/prices[symbol]+e.account[symbol]['amount'])
e.Update(prices)
res_list.append([e.account['USDT']['total'],e.account['USDT']['hold']])
return pd.DataFrame(data=res_list, columns=['total','hold'],index = index_list)
Prueba factorial simple
Factor de volumen: simplemente comprar monedas con bajo volumen y vender monedas con alto volumen funciona muy bien, lo que demuestra que es más probable que las monedas populares caigan.
Factor de precio de transacción: posiciones largas en monedas de bajo precio, posiciones cortas en monedas de alto precio, el efecto es promedio.
Factor número de transacciones: el rendimiento es muy similar al volumen. Es evidente que la correlación entre el factor de volumen y el factor de número de transacciones es muy alta. De hecho, la correlación media entre ellos en diferentes monedas es de 0,97, lo que demuestra que estos dos factores son muy similares. Este factor debe tenerse en cuenta en cuenta.
Factor de momento 3h: (df_close - df_close.shift(3))/df_close.shift(3). Es decir, el aumento de 3 horas del factor. Los resultados del backtest muestran que el aumento de 3 horas tiene una característica de regresión obvia, es decir, es más probable que el aumento caiga en el siguiente período. El rendimiento general es bueno, pero también hay períodos más largos de retroceso y oscilación.
Factor de momentum de 24 horas: Los resultados del ciclo de reequilibrio de 24 horas son bastante buenos, con retornos similares al momentum de 3 horas y una caída menor.
Factor de cambio de facturación: df_volume.rolling(24).mean() / df_volume.rolling(96).mean(), que es la relación entre la facturación del día más reciente y la facturación de los tres días más recientes. Se ajusta cada 8 horas. Los resultados del backtest son relativamente buenos y el retroceso es relativamente bajo, lo que muestra que las acciones con un volumen de negociación activo tienen más probabilidades de caer.
Factor de cambio del número de transacciones: df_count.rolling(24).mean() / df_count.rolling(96).mean(), que es la relación entre el número de transacciones del último día y el número de transacciones de los últimos tres días La posición se ajusta cada 8 horas. Los resultados del backtest son relativamente buenos y el retroceso es relativamente bajo, lo que muestra que a medida que aumenta el número de transacciones, el mercado tiende a caer de forma más activa.
Factor de cambio del valor de transacción única: -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean()) , que es la relación entre el valor de la transacción del día más reciente y el valor de la transacción de los tres días más recientes, y la posición se ajusta cada 8 horas. Este factor también está altamente correlacionado con el factor volumen.
Factor de cambio de la tasa de transacciones activas: df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean(), es decir, la relación entre el volumen de compra activa y el volumen total de transacciones en el último día de la transacción. valor en los últimos tres días, ajusta la posición cada 8 horas. Este factor funciona bien y tiene poca correlación con el factor de volumen.
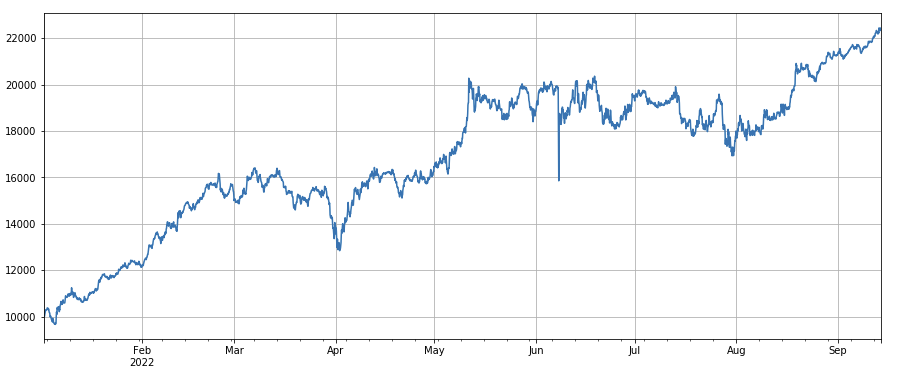
Factor de volatilidad: (df_close/df_open).rolling(24).std(), que tiene un cierto efecto al comprar divisas con baja volatilidad.
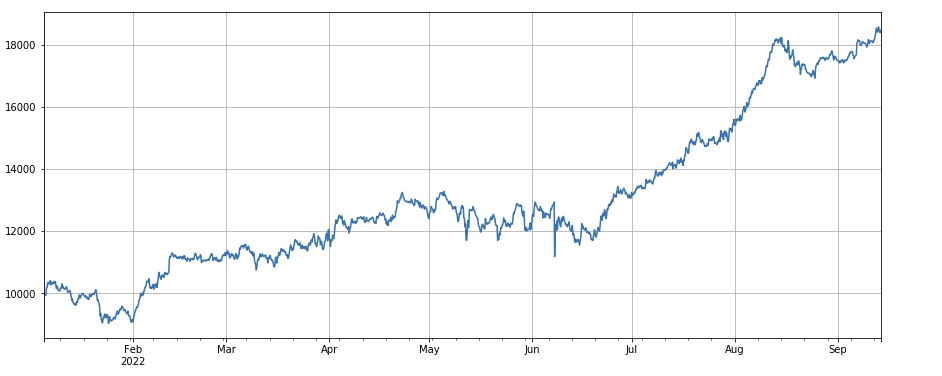
Factor de correlación entre el volumen de negociación y el precio de cierre: df_close.rolling(96).corr(df_volume), el factor de correlación entre el precio de cierre y el volumen de negociación en los últimos 4 días, el rendimiento general es bueno.
A continuación se enumeran algunos de los factores basados en la cantidad y el precio. De hecho, la combinación de fórmulas de factores puede ser muy compleja y puede no tener una lógica obvia. Puede consultar el famoso método de construcción de factores ALPHA101: https://github.com/STHSF/alpha101.
#成交量
factor_volume = df_volume
factor_volume_res = Test(factor_volume, symbols, period=4)
factor_volume_res.total.plot(figsize=(15,6),grid=True);
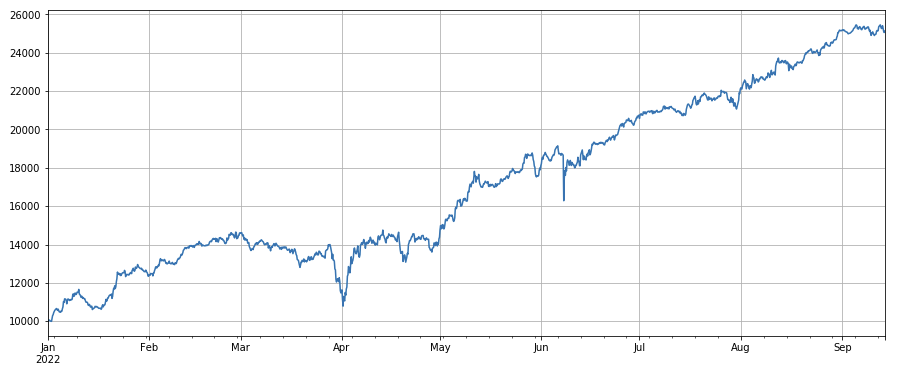
#成交价
factor_close = df_close
factor_close_res = Test(factor_close, symbols, period=8)
factor_close_res.total.plot(figsize=(15,6),grid=True);
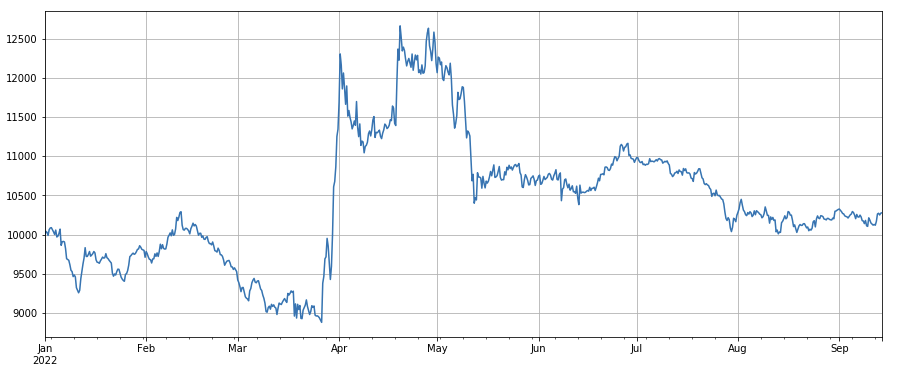
#成交笔数
factor_count = df_count
factor_count_res = Test(factor_count, symbols, period=8)
factor_count_res.total.plot(figsize=(15,6),grid=True);
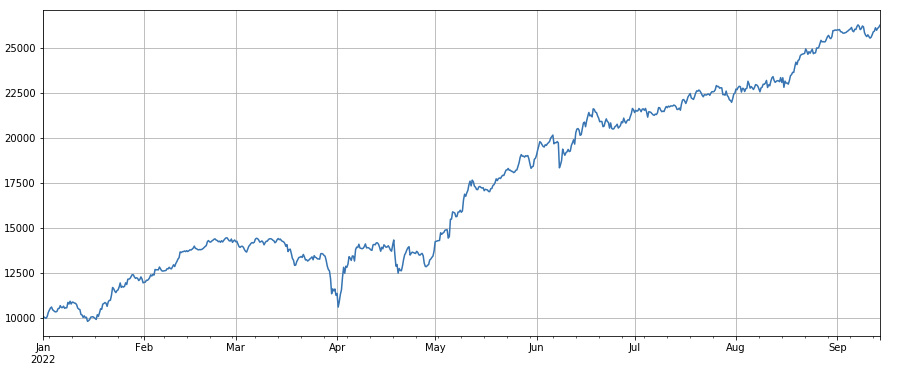
print(df_count.corrwith(df_volume).mean())
0.9671246744996017
#3小时动量因子
factor_1 = (df_close - df_close.shift(3))/df_close.shift(3)
factor_1_res = Test(factor_1,symbols,period=1)
factor_1_res.total.plot(figsize=(15,6),grid=True);
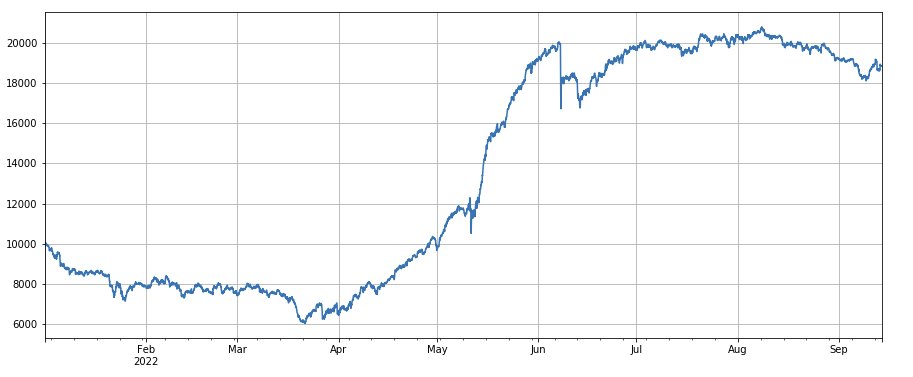
#24小时动量因子
factor_2 = (df_close - df_close.shift(24))/df_close.shift(24)
factor_2_res = Test(factor_2,symbols,period=24)
tamenxuanfactor_2_res.total.plot(figsize=(15,6),grid=True);
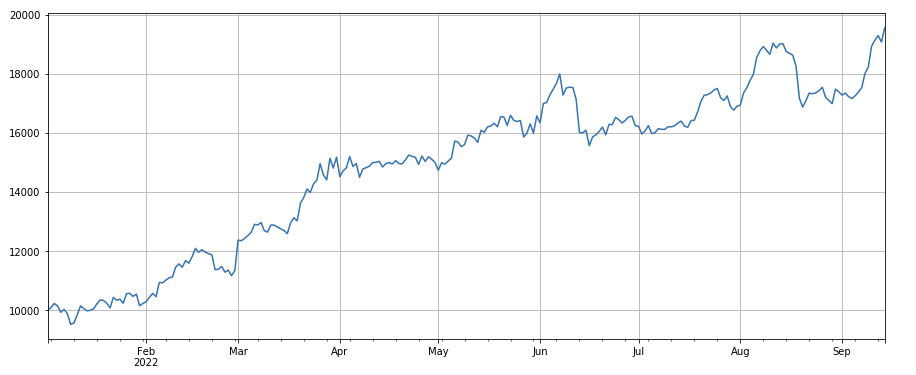
#成交量因子
factor_3 = df_volume.rolling(24).mean()/df_volume.rolling(96).mean()
factor_3_res = Test(factor_3, symbols, period=8)
factor_3_res.total.plot(figsize=(15,6),grid=True);
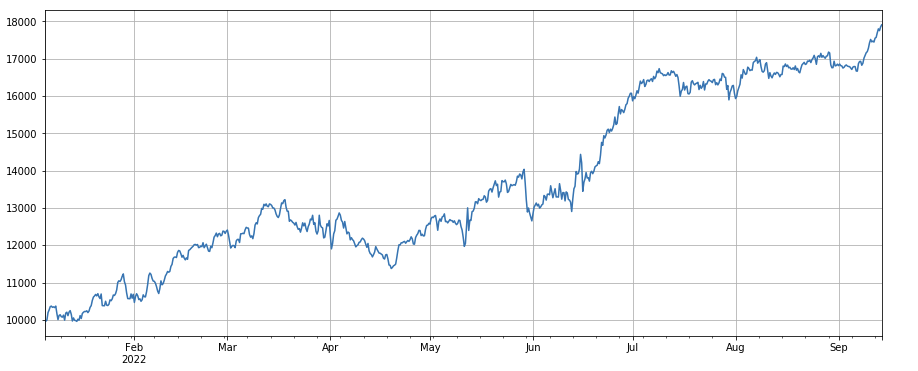
#成交笔数因子
factor_4 = df_count.rolling(24).mean()/df_count.rolling(96).mean()
factor_4_res = Test(factor_4, symbols, period=8)
factor_4_res.total.plot(figsize=(15,6),grid=True);
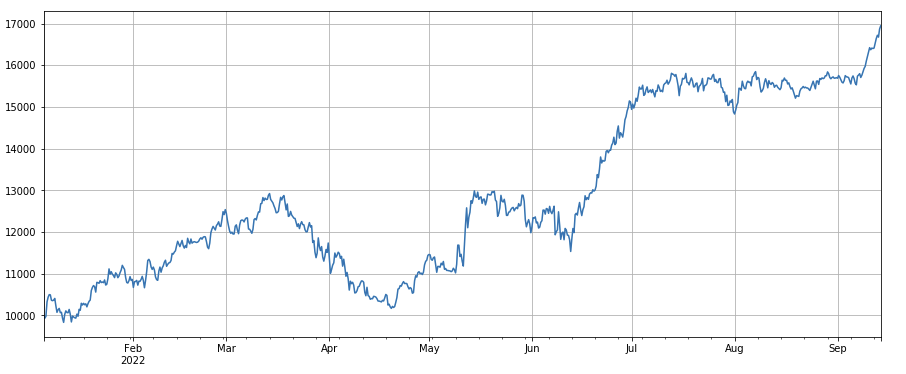
#因子相关性
print(factor_4.corrwith(factor_3).mean())
0.9707239580854841
#单笔成交价值因子
factor_5 = -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean())
factor_5_res = Test(factor_5, symbols, period=8)
factor_5_res.total.plot(figsize=(15,6),grid=True);
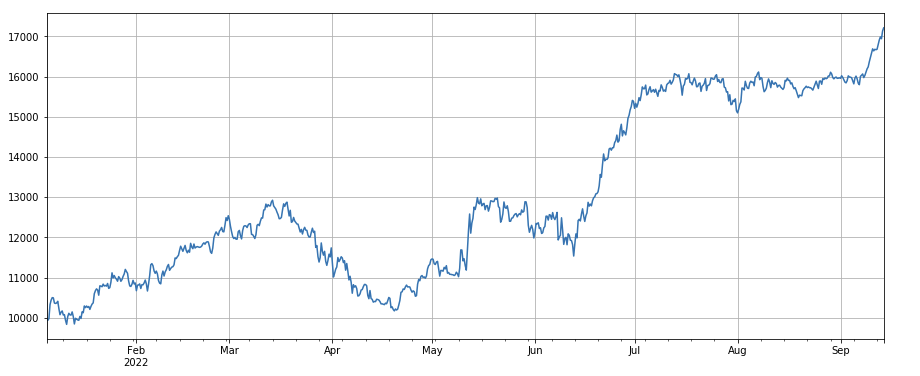
print(factor_4.corrwith(factor_5).mean())
0.861206620552479
#主动成交比例因子
factor_6 = df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean()
factor_6_res = Test(factor_6, symbols, period=4)
factor_6_res.total.plot(figsize=(15,6),grid=True);
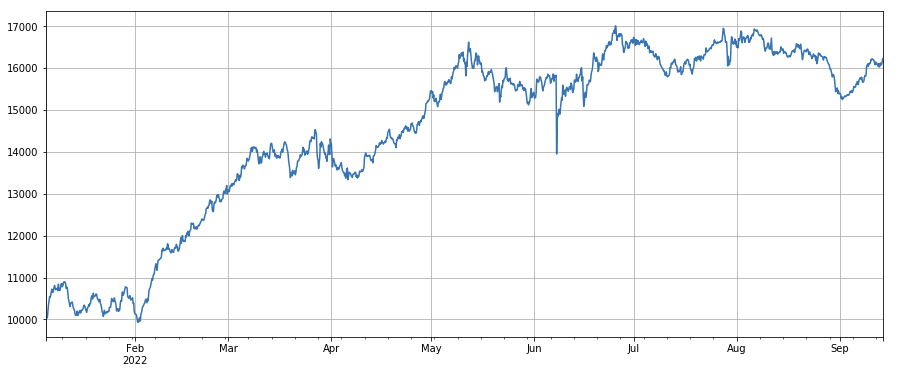
print(factor_3.corrwith(factor_6).mean())
0.1534572192503726
#波动率因子
factor_7 = (df_close/df_open).rolling(24).std()
factor_7_res = Test(factor_7, symbols, period=2)
factor_7_res.total.plot(figsize=(15,6),grid=True);
#成交量和收盘价相关性因子
factor_8 = df_close.rolling(96).corr(df_volume)
factor_8_res = Test(factor_8, symbols, period=4)
factor_8_res.total.plot(figsize=(15,6),grid=True);
Síntesis multifactorial
El descubrimiento continuo de nuevos factores efectivos es sin duda la parte más importante del proceso de construcción de una estrategia, pero sin un buen método de síntesis de factores, un excelente factor Alfa único no puede desempeñar su máximo papel. Los métodos comunes de síntesis multifactorial incluyen:
Método de igual peso: Todos los factores a sintetizar se suman con pesos iguales para obtener nuevos factores sintetizados.
Método ponderado de retornos históricos de factores: Todos los factores a sintetizar se suman de acuerdo con la media aritmética de los retornos históricos de factores en el período más reciente como ponderaciones para obtener nuevos factores sintetizados. Este método otorga mayor peso a los factores que tienen un buen desempeño.
Maximización del método ponderado IC_IR: el valor IC promedio del factor compuesto durante un período histórico se utiliza como una estimación del valor IC del factor compuesto en el próximo período, y la matriz de covarianza del valor IC histórico se utiliza como una estimación. de la volatilidad del factor compuesto en el próximo período. Es igual al valor esperado de IC dividido por la desviación estándar de IC, y se puede obtener la solución de peso óptima para maximizar el factor compuesto IC_IR.
Método de análisis de componentes principales (PCA): el PCA es un método de uso común para la reducción de la dimensionalidad de los datos. La correlación entre los factores puede ser relativamente alta y los componentes principales después de la reducción de la dimensionalidad se utilizan como factores sintetizados.
Este artículo se referirá manualmente a la ponderación de la validez factorial. El método descrito anteriormente puede referirse a:ae933a8c-5a94-4d92-8f33-d92b70c36119.pdf
Al probar un solo factor, el orden es fijo, pero la síntesis de múltiples factores requiere fusionar datos completamente diferentes, por lo que todos los factores deben estandarizarse y, generalmente, los valores extremos y los valores faltantes deben eliminarse. Aquí utilizamos df_volume\factor_1\factor_7\factor_6\factor_8 para la síntesis.
#标准化函数,去除缺失值和极值,并且进行标准化处理
def norm_factor(factor):
factor = factor.dropna(how='all')
factor_clip = factor.apply(lambda x:x.clip(x.quantile(0.2), x.quantile(0.8)),axis=1)
factor_norm = factor_clip.add(-factor_clip.mean(axis=1),axis ='index').div(factor_clip.std(axis=1),axis ='index')
return factor_norm
df_volume_norm = norm_factor(df_volume)
factor_1_norm = norm_factor(factor_1)
factor_6_norm = norm_factor(factor_6)
factor_7_norm = norm_factor(factor_7)
factor_8_norm = norm_factor(factor_8)
factor_total = 0.6*df_volume_norm + 0.4*factor_1_norm + 0.2*factor_6_norm + 0.3*factor_7_norm + 0.4*factor_8_norm
factor_total_res = Test(factor_total, symbols, period=8)
factor_total_res.total.plot(figsize=(15,6),grid=True);
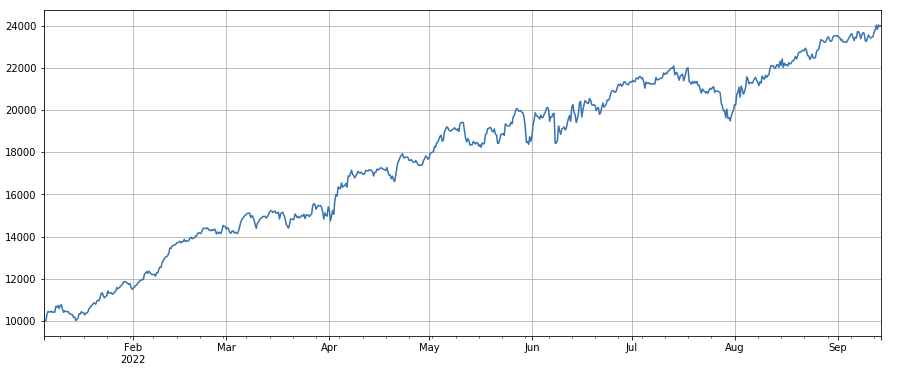
Resumir
En este artículo se presenta el método de prueba de un solo factor y se prueban los factores únicos comunes, y se presenta preliminarmente el método de síntesis de múltiples factores. Sin embargo, el contenido de la investigación de múltiples factores es muy rico. Cada punto mencionado en el artículo se puede ampliar en profundidad. Es un enfoque viable transformar esa investigación de estrategias en el descubrimiento de factores alfa. El uso de la metodología de factores puede acelerar enormemente la verificación de las ideas comerciales y hay mucho material de referencia disponible.
Dirección real: https://www.fmz.com/robot/486605