Aplicación de la tecnología de aprendizaje automático en el comercio
El autor:FMZ~Lydia, Creado: 2022-12-30 10:53:07, Actualizado: 2023-09-20 09:30:09
Aplicación de la tecnología de aprendizaje automático en el comercio
La inspiración de este artículo proviene de mi observación de algunas advertencias y trampas comunes después de tratar de aplicar la tecnología de aprendizaje automático a problemas de transacción durante la investigación de datos en la plataforma FMZ Quant.
Si no ha leído mis artículos anteriores, le sugerimos que lea la guía del entorno de investigación de datos automatizados y el método sistemático para formular estrategias comerciales que establecí en la plataforma FMZ Quant antes de este artículo.
Las direcciones de estos dos artículos están aquí:https://www.fmz.com/digest-topic/9862yhttps://www.fmz.com/digest-topic/9863.
Sobre la creación del entorno de investigación
Este tutorial está destinado a entusiastas, ingenieros y científicos de datos de todos los niveles de habilidad. Ya sea que usted sea un líder de la industria o un principiante en programación, las únicas habilidades que necesita son una comprensión básica del lenguaje de programación Python y un conocimiento suficiente de las operaciones de línea de comandos (ser capaz de configurar un proyecto de ciencia de datos es suficiente).
- Instale el docker FMZ Quant y configure Anaconda
La plataforma FMZ QuantFMZ.COMEste conjunto de interfaces incluye herramientas prácticas, como consultar la información de la cuenta, consultar el alto, abierto, bajo, precio de recibo, volumen de negociación y varios indicadores de análisis técnico comúnmente utilizados de varios intercambios principales. En particular, proporciona un fuerte soporte técnico para las interfaces API públicas que conectan los principales intercambios principales en el proceso de negociación real.
Todas las características mencionadas anteriormente están encapsuladas en un sistema similar a Docker. Lo que tenemos que hacer es comprar o arrendar nuestros propios servicios de computación en la nube e implementar el sistema Docker.
En el nombre oficial de la plataforma FMZ Quant, el sistema Docker se llama sistema Docker.
Por favor, consulte mi artículo anterior sobre cómo desplegar un docker y robot:https://www.fmz.com/bbs-topic/9864.
Los lectores que quieran comprar su propio servidor de computación en la nube para implementar dockers pueden consultar este artículo:https://www.fmz.com/digest-topic/5711.
Después de desplegar el servidor de computación en la nube y el sistema de docker con éxito, a continuación instalaremos el artefacto más grande de Python: Anaconda
Para realizar todos los entornos de programa relevantes (bibliotecas de dependencias, gestión de versiones, etc.) requeridos en este artículo, la forma más simple es usar Anaconda.
Dado que instalamos Anaconda en el servicio en la nube, recomendamos que el servidor en la nube instale el sistema Linux más la versión de línea de comandos de Anaconda.
Para el método de instalación de Anaconda, consulte la guía oficial de Anaconda:https://www.anaconda.com/distribution/.
Si usted es un programador Python experimentado y si siente que no necesita usar Anaconda, no es un problema en absoluto. Asumiré que no necesita ayuda al instalar el entorno dependiente necesario. Puede omitir esta sección directamente.
Desarrollar una estrategia comercial
El resultado final de una estrategia de negociación debe responder a las siguientes preguntas:
-
Dirección: Determinar si el activo es barato, caro o valor razonable.
-
Condiciones de apertura de la posición: Si el activo es barato o caro, debe ir largo o corto.
-
Negociación de posición de cierre: si el activo tiene un precio razonable y tenemos una posición en el activo (compra o venta anterior), ¿debería cerrar la posición?
-
En el caso de las operaciones de inversión, el valor de las operaciones de inversión es el valor de las operaciones de inversión.
-
En el caso de las entidades financieras, el valor de la inversión se calcula a partir de la suma de los activos financieros de las entidades financieras.
El aprendizaje automático se puede utilizar para responder a cada una de estas preguntas, pero para el resto de este artículo, nos centraremos en la primera pregunta, que es la dirección del comercio.
Enfoque estratégico
Hay dos tipos de enfoques para construir estrategias: uno se basa en modelos; el otro se basa en la minería de datos. Estos dos métodos son básicamente opuestos entre sí.
En la construcción de estrategias basadas en modelos, comenzamos desde el modelo de ineficiencia del mercado, construimos expresiones matemáticas (como precio y ganancia) y probamos su efectividad en un largo período de tiempo. Este modelo generalmente es una versión simplificada de un modelo real complejo, y su importancia y estabilidad a largo plazo deben verificarse.
Por otro lado, buscamos patrones de precios primero e intentamos usar algoritmos en métodos de minería de datos. Las razones de estos patrones no son importantes, porque solo los patrones identificados continuarán repitiéndose en el futuro. Este es un método de análisis ciego, y necesitamos verificar estrictamente para identificar patrones reales a partir de patrones aleatorios.
Obviamente, el aprendizaje automático es muy fácil de aplicar a los métodos de minería de datos. Veamos cómo usar el aprendizaje automático para crear señales de transacción a través de la minería de datos.
El ejemplo de código utiliza una herramienta de backtesting basada en la plataforma FMZ Quant y una interfaz API de transacciones automatizada. Después de implementar el docker e instalar Anaconda en la sección anterior, solo necesita instalar la biblioteca de análisis de ciencia de datos que necesitamos y el famoso modelo de aprendizaje automático scikit-learn. No volveremos a repasar esta sección.
pip install -U scikit-learn
Utilice el aprendizaje automático para crear señales de estrategia comercial
- La minería de datos. Antes de comenzar, un sistema estándar de problemas de aprendizaje automático se muestra en la siguiente figura:
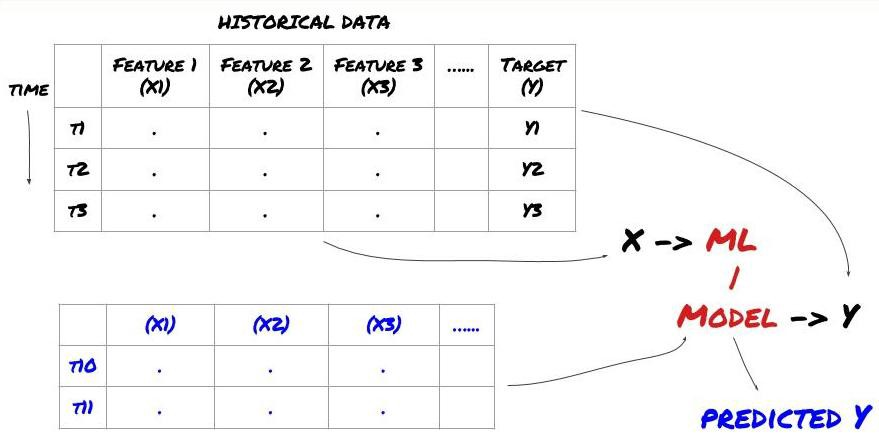
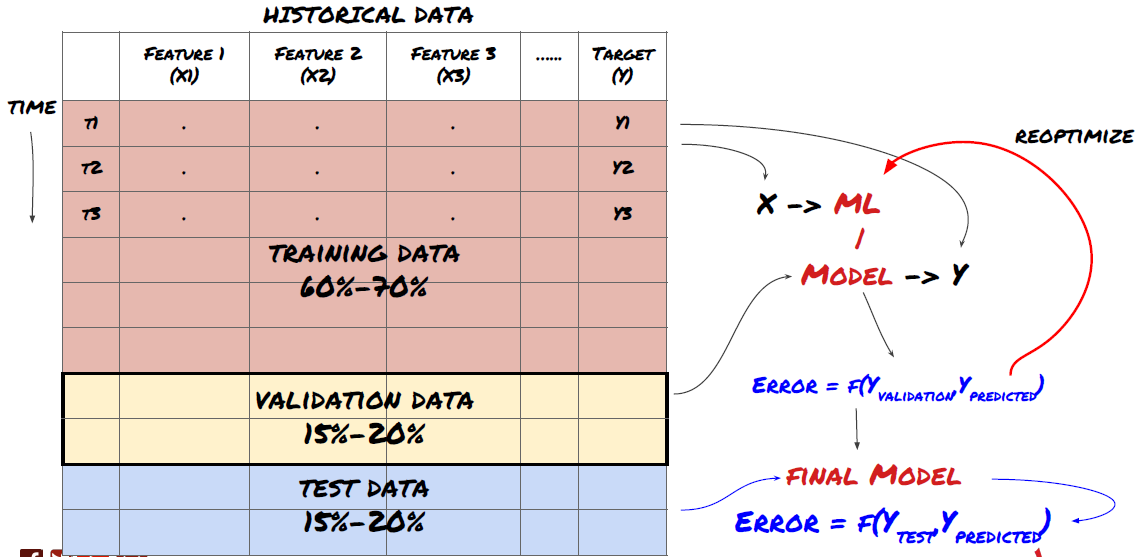
Sistema de problemas de aprendizaje automático
La característica que vamos a crear debe tener cierta capacidad de predicción (X). Queremos predecir la variable objetivo (Y) y usar datos históricos para entrenar el modelo ML que puede predecir Y lo más cerca posible del valor real. Finalmente, usamos este modelo para hacer predicciones en nuevos datos donde Y es desconocido. Esto nos lleva al primer paso:
Paso 1: Prepare su pregunta
- ¿Qué quieres predecir? ¿Qué es una buena predicción? ¿Cómo evalúas los resultados de la predicción?
Es decir, en nuestro marco de arriba, ¿qué es Y?
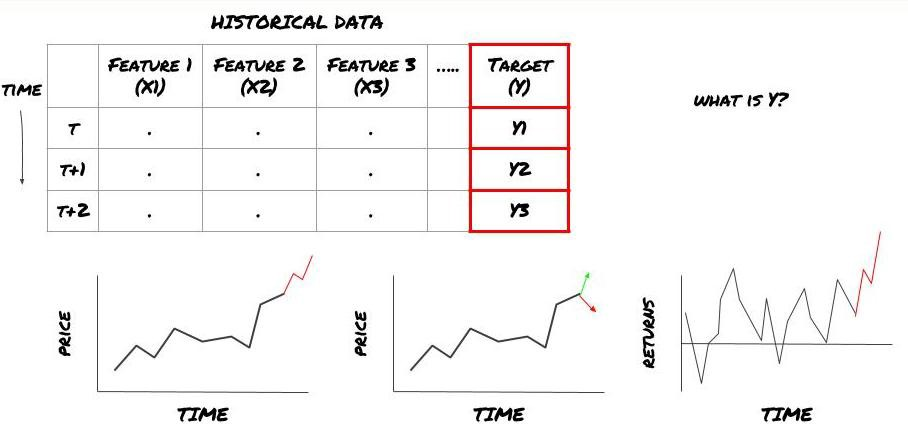
¿Qué quieres predecir?
¿Quiere predecir los precios futuros, los rendimientos futuros / Pnl, señales de compra / venta, optimizar la asignación de cartera y tratar de ejecutar las transacciones de manera eficiente?
Supongamos que tratamos de pronosticar los precios en la próxima marca de tiempo. en este caso, Y (t) = precio (t + 1). ahora podemos usar datos históricos para completar nuestro marco.
Tenga en cuenta que Y (t) se conoce solo en la prueba de retroceso, pero cuando usamos nuestro modelo, no conoceremos el precio (t + 1) del tiempo t. Usamos nuestro modelo para predecir Y (predecido, t) y compararlo con el valor real solo en el tiempo t + 1. Esto significa que no puede usar Y como una característica en el modelo de predicción.
Una vez que conocemos el objetivo Y, también podemos decidir cómo evaluar nuestras predicciones. Esto es importante para diferenciar entre los diferentes modelos de los datos que vamos a probar. Seleccione un indicador para medir la eficiencia de nuestro modelo de acuerdo con el problema que estamos resolviendo. Por ejemplo, si predicimos precios, podemos usar el error cuadrado de la raíz media como indicador. Algunos indicadores comúnmente utilizados (EMA, MACD, puntuación de varianza, etc.) han sido pre-codificados en la caja de herramientas FMZ Quant. Puede llamar a estos indicadores globalmente a través de la interfaz API.
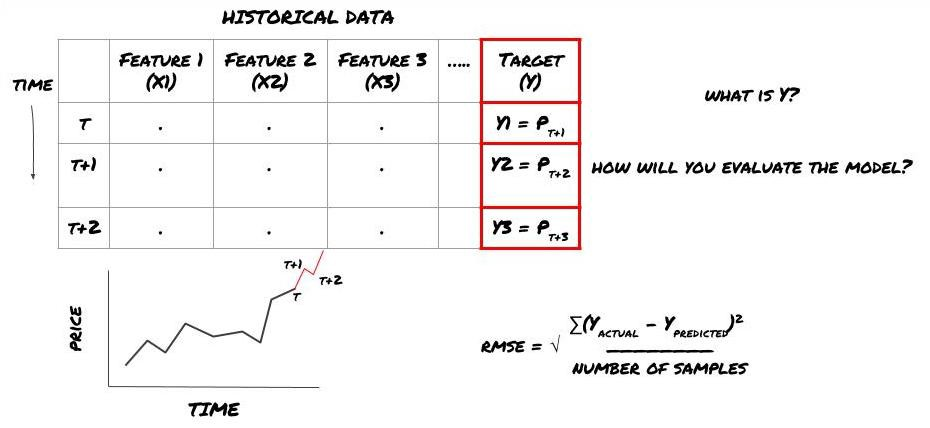
Marco ML para la predicción de los precios futuros
A efectos de demostración, crearemos un modelo de predicción para predecir el valor de referencia (base) futuro esperado de un objeto de inversión hipotético, donde:
basis = Price of Stock — Price of Future
basis(t)=S(t)−F(t)
Y(t) = future expected value of basis = Average(basis(t+1),basis(t+2),basis(t+3),basis(t+4),basis(t+5))
Dado que este es un problema de regresión, evaluaremos el modelo en RMSE (error cuadrado de la raíz media).
Nota: Consulte la Enciclopedia Baidu para obtener conocimientos matemáticos relevantes de RMSE.
- Nuestro objetivo: crear un modelo para que el valor predicho sea lo más cercano posible a Y.
Paso 2: Recopilar datos fiables
Recoge y limpia datos que pueden ayudarte a resolver el problema en cuestión.
¿Qué datos necesita considerar para predecir la variable objetivo Y? Si predice el precio, puede utilizar los datos de precio del objeto de inversión, los datos de cantidad de negociación del objeto de inversión, los datos similares del objeto de inversión relacionado, el nivel del índice del objeto de inversión y otros indicadores generales del mercado, y el precio de otros activos relacionados.
Debe configurar permisos de acceso a datos para estos datos y asegurarse de que sus datos sean precisos, y resolver los datos perdidos (un problema muy común). Al mismo tiempo, asegúrese de que sus datos sean imparciales y representativos de todas las condiciones del mercado (por ejemplo, el mismo número de escenarios de ganancias y pérdidas) para evitar sesgos en el modelo. También puede que necesite limpiar los datos para obtener dividendos, objetivos de inversión divididos, continuidades, etc.
Si utiliza la plataforma FMZ Quant (FMZ. COM), podemos acceder a datos globales gratuitos de Google, Yahoo, NSE y Quandl; Datos de profundidad de futuros de productos básicos nacionales como CTP y Esunny; Datos de los principales intercambios de divisas digitales como Binance, OKX, Huobi y BitMex. La plataforma FMZ Quant también limpia y filtra estos datos, como la división de objetivos de inversión y datos de mercado en profundidad, y los presenta a los desarrolladores de estrategias en un formato que es fácil de entender para los profesionales cuantitativos.
Para facilitar la demostración de este artículo, utilizamos los siguientes datos como el
# Load the data
from backtester.dataSource.quant_quest_data_source import QuantQuestDataSource
cachedFolderName = '/Users/chandinijain/Auquan/qq2solver-data/historicalData/'
dataSetId = 'trainingData1'
instrumentIds = ['MQK']
ds = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
def loadData(ds):
data = None
for key in ds.getBookDataByFeature().keys():
if data is None:
data = pd.DataFrame(np.nan, index = ds.getBookDataByFeature()[key].index, columns=[])
data[key] = ds.getBookDataByFeature()[key]
data['Stock Price'] = ds.getBookDataByFeature()['stockTopBidPrice'] + ds.getBookDataByFeature()['stockTopAskPrice'] / 2.0
data['Future Price'] = ds.getBookDataByFeature()['futureTopBidPrice'] + ds.getBookDataByFeature()['futureTopAskPrice'] / 2.0
data['Y(Target)'] = ds.getBookDataByFeature()['basis'].shift(-5)
del data['benchmark_score']
del data['FairValue']
return data
data = loadData(ds)
Con el código anterior, Auquan
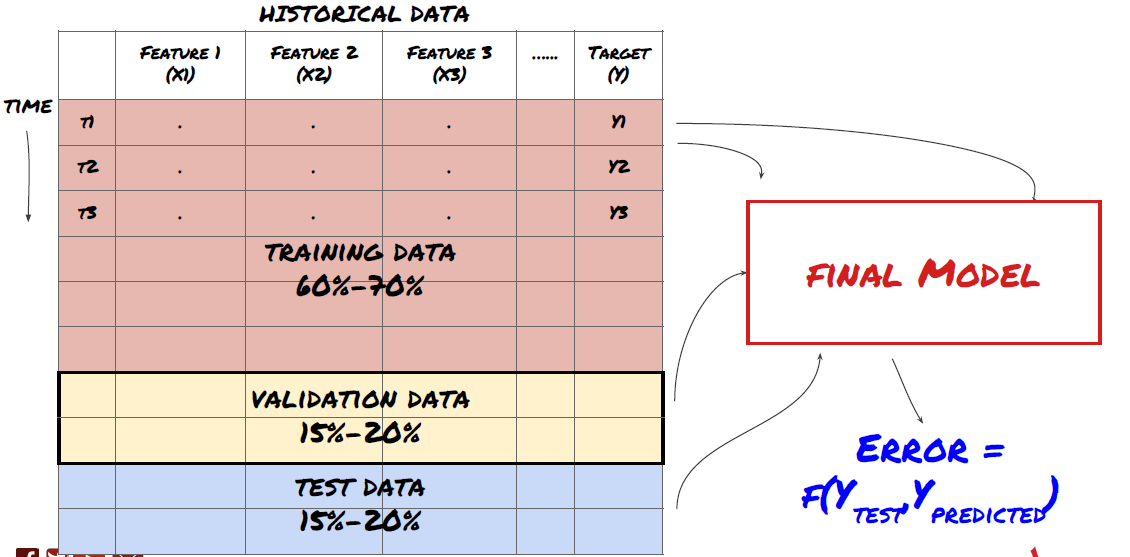
Paso 3: Dividir los datos
- Crear conjuntos de capacitación, verificación cruzada y probar estos conjuntos de datos a partir de datos.
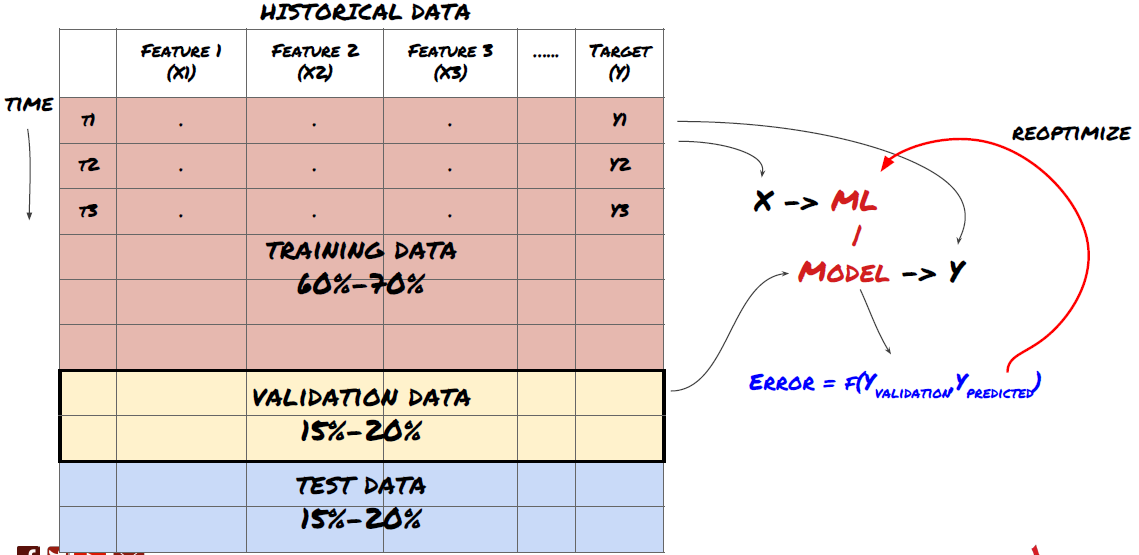
¡Este es un paso muy importante!Antes de continuar, debemos dividir los datos en conjuntos de datos de entrenamiento para entrenar a su modelo; conjuntos de datos de prueba para evaluar el rendimiento del modelo. Se recomienda dividirlos en 60-70% conjuntos de entrenamiento y 30-40% conjuntos de prueba.
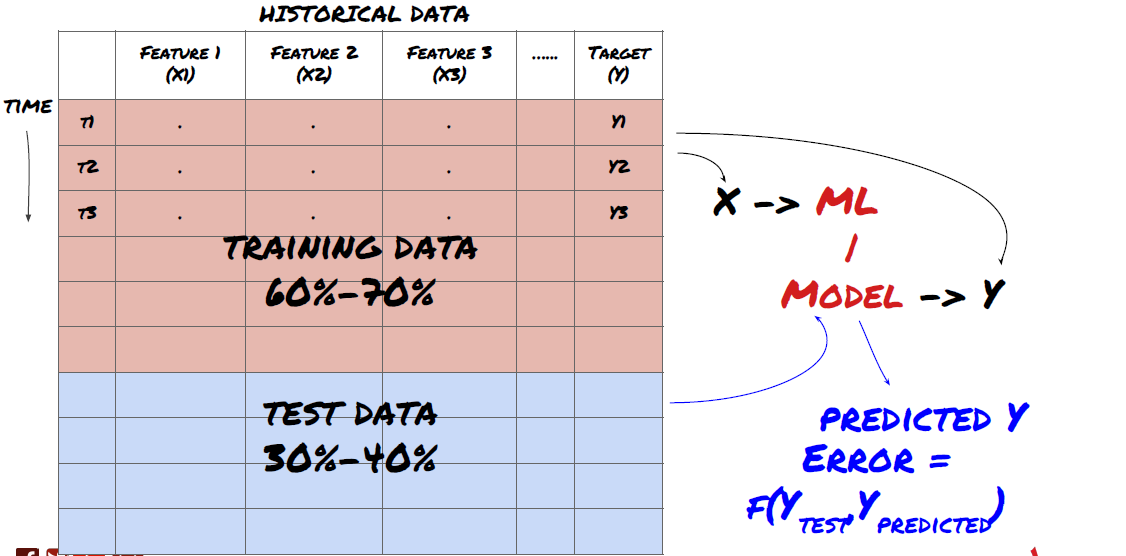
Dividir los datos en conjuntos de entrenamiento y conjuntos de ensayo
Dado que los datos de entrenamiento se utilizan para evaluar los parámetros del modelo, su modelo puede encajar demasiado en estos datos de entrenamiento, y los datos de entrenamiento pueden engañar el rendimiento del modelo. Si no retiene ningún dato de prueba individual y usa todos los datos para entrenamiento, no sabrá qué tan bien o mal se desempeña su modelo en los nuevos datos invisibles. Esta es una de las principales razones del fracaso del modelo de ML entrenado en datos en tiempo real: las personas entrenan todos los datos disponibles y están entusiasmadas con los indicadores de datos de entrenamiento, pero el modelo no puede hacer ninguna predicción significativa en los datos en tiempo real no entrenados.
Dividir los datos en conjuntos de formación, de verificación y de ensayo
Hay problemas con este método. Si entrenamos los datos de entrenamiento repetidamente, evaluamos el rendimiento de los datos de prueba y optimizamos nuestro modelo hasta que estamos satisfechos con el rendimiento, tomamos los datos de prueba como parte de los datos de entrenamiento implícitamente.
Para resolver este problema, podemos crear un conjunto de datos de validación separado. Ahora, puedes entrenar los datos, evaluar el rendimiento de los datos de validación, optimizar hasta que estés satisfecho con el rendimiento y finalmente probar los datos de prueba. De esta manera, los datos de prueba no se contaminarán, y no usaremos ninguna información en los datos de prueba para mejorar nuestro modelo.
Recuerde, una vez que haya comprobado el rendimiento de sus datos de prueba, no vuelva atrás e intente optimizar aún más su modelo. Si encuentra que su modelo no da buenos resultados, deseche el modelo por completo y comience de nuevo. Se sugiere que el 60% de los datos de capacitación, el 20% de los datos de validación y el 20% de los datos de prueba se puedan dividir.
Para nuestra pregunta, tenemos tres conjuntos de datos disponibles. Utilizaremos uno como el conjunto de entrenamiento, el segundo como el conjunto de verificación, y el tercero como nuestro conjunto de prueba.
# Training Data
dataSetId = 'trainingData1'
ds_training = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
training_data = loadData(ds_training)
# Validation Data
dataSetId = 'trainingData2'
ds_validation = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
validation_data = loadData(ds_validation)
# Test Data
dataSetId = 'trainingData3'
ds_test = QuantQuestDataSource(cachedFolderName=cachedFolderName,
dataSetId=dataSetId,
instrumentIds=instrumentIds)
out_of_sample_test_data = loadData(ds_test)
Para cada uno de ellos, se suma la variable objetivo Y, que se define como el promedio de los siguientes cinco valores básicos.
def prepareData(data, period):
data['Y(Target)'] = data['basis'].rolling(period).mean().shift(-period)
if 'FairValue' in data.columns:
del data['FairValue']
data.dropna(inplace=True)
period = 5
prepareData(training_data, period)
prepareData(validation_data, period)
prepareData(out_of_sample_test_data, period)
Paso 4: Ingeniería de características
Analizar el comportamiento de los datos y crear características predictivas
Ahora la construcción real del proyecto ha comenzado. La regla de oro de la selección de características es que la capacidad de predicción proviene principalmente de las características, no de los modelos.
-
No seleccione un gran conjunto de características al azar sin explorar la relación con la variable objetivo.
-
La poca o ninguna relación con la variable objetivo puede conducir a un sobreajuste.
-
Las características que seleccione pueden estar muy relacionadas entre sí, en cuyo caso un pequeño número de características también puede explicar el objetivo.
-
Por lo general creo algunas características intuitivas, comprobar la correlación entre la variable objetivo y estas características, y la correlación entre ellos para decidir cuál usar.
-
También puede intentar realizar análisis de componentes principales (PCA) y otros métodos para clasificar las características candidatas de acuerdo con el coeficiente máximo de información (MIC).
Transformación/normalización de las características:
Los modelos de ML tienden a funcionar bien en términos de normalización. Sin embargo, la normalización es difícil cuando se trata de datos de series temporales, porque el rango de datos futuro es desconocido. Sus datos pueden estar fuera del rango de normalización, lo que conduce a errores de modelo. Pero aún puede intentar forzar cierto grado de estabilidad:
-
Escalado: división de las características por desviación estándar o rango de cuartil.
-
Centrar: restar el valor promedio histórico del valor actual.
-
Normalización: dos períodos retrospectivos de lo anterior (x - media) /stdev.
-
Normalización regular: estandarizar los datos en el rango de -1 a +1 y volver a determinar el centro dentro del período de retroceso (x-min) / ((max min).
Tenga en cuenta que, dado que utilizamos el valor promedio continuo histórico, la desviación estándar, los valores máximos o mínimos más allá del período de retroceso, el valor de normalización normalizado de la característica representará diferentes valores reales en diferentes momentos. Por ejemplo, si el valor actual de la característica es 5 y el valor promedio para 30 períodos consecutivos es 4.5, se convertirá a 0.5 después de centrarlo. Después de eso, si el valor promedio de 30 períodos consecutivos se convierte en 3, el valor 3.5 se convertirá en 0.5. Esto puede ser la causa del modelo equivocado. Por lo tanto, la normalización es complicada, y debe averiguar qué mejora el rendimiento del modelo (si realmente existe).
Para la primera iteración de nuestro problema, creamos un gran número de características utilizando parámetros mixtos. Más tarde trataremos de ver si podemos reducir el número de características.
def difference(dataDf, period):
return dataDf.sub(dataDf.shift(period), fill_value=0)
def ewm(dataDf, halflife):
return dataDf.ewm(halflife=halflife, ignore_na=False,
min_periods=0, adjust=True).mean()
def rsi(data, period):
data_upside = data.sub(data.shift(1), fill_value=0)
data_downside = data_upside.copy()
data_downside[data_upside > 0] = 0
data_upside[data_upside < 0] = 0
avg_upside = data_upside.rolling(period).mean()
avg_downside = - data_downside.rolling(period).mean()
rsi = 100 - (100 * avg_downside / (avg_downside + avg_upside))
rsi[avg_downside == 0] = 100
rsi[(avg_downside == 0) & (avg_upside == 0)] = 0
return rsi
def create_features(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom3'] = difference(data['basis'],4)
basis_X['mom5'] = difference(data['basis'],6)
basis_X['mom10'] = difference(data['basis'],11)
basis_X['rsi15'] = rsi(data['basis'],15)
basis_X['rsi10'] = rsi(data['basis'],10)
basis_X['emabasis3'] = ewm(data['basis'],3)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis7'] = ewm(data['basis'],7)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['vwapbasis'] = data['stockVWAP']-data['futureVWAP']
basis_X['swidth'] = data['stockTopAskPrice'] -
data['stockTopBidPrice']
basis_X['fwidth'] = data['futureTopAskPrice'] -
data['futureTopBidPrice']
basis_X['btopask'] = data['stockTopAskPrice'] -
data['futureTopAskPrice']
basis_X['btopbid'] = data['stockTopBidPrice'] -
data['futureTopBidPrice']
basis_X['totalaskvol'] = data['stockTotalAskVol'] -
data['futureTotalAskVol']
basis_X['totalbidvol'] = data['stockTotalBidVol'] -
data['futureTotalBidVol']
basis_X['emabasisdi7'] = basis_X['emabasis7'] -
basis_X['emabasis5'] +
basis_X['emabasis3']
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
print("Any null data in y: %s, X: %s"
%(basis_y.isnull().values.any(),
basis_X.isnull().values.any()))
print("Length y: %s, X: %s"
%(len(basis_y.index), len(basis_X.index)))
return basis_X, basis_y
basis_X_train, basis_y_train = create_features(training_data)
basis_X_test, basis_y_test = create_features(validation_data)
Paso 5: Selección del modelo
Seleccionar el modelo estadístico/ML adecuado según las preguntas seleccionadas
La elección del modelo depende de cómo se forme el problema. ¿Está resolviendo supervisado (cada punto X en la matriz de características se asigna a la variable objetivo Y) o aprendizaje no supervisado (sin una asignación dada, el modelo intenta aprender un patrón desconocido)? ¿Está tratando con regresión (pronosticando el precio real en el tiempo futuro) o clasificación (sólo pronosticando la dirección del precio en el tiempo futuro (aumento / disminución))?

Aprendizaje supervisado o no supervisado

Regresión o clasificación
Algunos algoritmos comunes de aprendizaje supervisado pueden ayudarlo a comenzar:
-
Regresión lineal (parámetros, regresión)
-
Regresión logística (parámetro, clasificación)
-
El algoritmo K-Nearest Neighbor (KNN) (basado en casos, regresión)
-
SVM, SVR (parámetros, clasificación y regresión)
-
Árbol de decisiones
-
Bosque de la decisión
Sugiero comenzar con un modelo simple, como la regresión lineal o logística, y construir modelos más complejos a partir de ahí según sea necesario. También se recomienda que lea las matemáticas detrás del modelo en lugar de usarlo ciegamente como una caja negra.
Paso 6: Formación, verificación y optimización (repetir los pasos 4-6)
Utilice conjuntos de datos de formación y verificación para entrenar y optimizar su modelo
Ahora estás listo para construir finalmente el modelo. En esta etapa, realmente solo iteras el modelo y los parámetros del modelo. Entrena a tu modelo en los datos de entrenamiento, mide su rendimiento en los datos de verificación, y luego regresa, optimiza, entrena y evalúa. Si no estás satisfecho con el rendimiento del modelo, prueba otro modelo. Pasa por esta fase muchas veces hasta que finalmente tenga un modelo con el que esté satisfecho.
Sólo cuando tengas tu modelo favorito, luego pasa al siguiente paso.
Para nuestro problema de demostración, comencemos con una regresión lineal simple:
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
def linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test):
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(basis_X_train, basis_y_train)
# Make predictions using the testing set
basis_y_pred = regr.predict(basis_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(basis_y_test, basis_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(basis_y_test,
basis_y_pred))
# Plot outputs
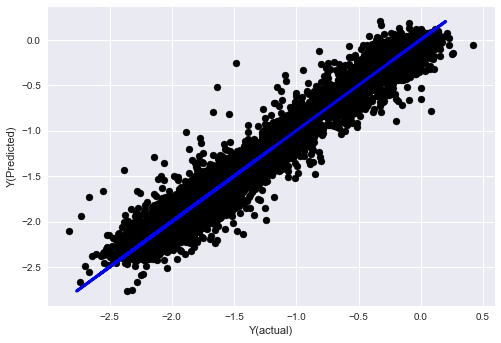
plt.scatter(basis_y_pred, basis_y_test, color='black')
plt.plot(basis_y_test, basis_y_test, color='blue', linewidth=3)
plt.xlabel('Y(actual)')
plt.ylabel('Y(Predicted)')
plt.show()
return regr, basis_y_pred
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train,
basis_X_test,basis_y_test)
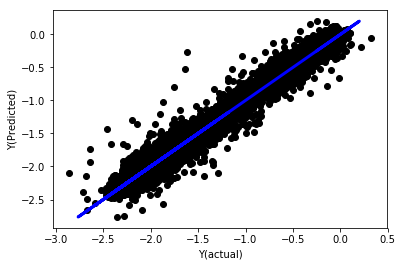
Regresión lineal sin normalización
('Coefficients: \n', array([ -1.0929e+08, 4.1621e+07, 1.4755e+07, 5.6988e+06, -5.656e+01, -6.18e-04, -8.2541e-05,4.3606e-02, -3.0647e-02, 1.8826e+07, 8.3561e-02, 3.723e-03, -6.2637e-03, 1.8826e+07, 1.8826e+07, 6.4277e-02, 5.7254e-02, 3.3435e-03, 1.6376e-02, -7.3588e-03, -8.1531e-04, -3.9095e-02, 3.1418e-02, 3.3321e-03, -1.3262e-06, -1.3433e+07, 3.5821e+07, 2.6764e+07, -8.0394e+06, -2.2388e+06, -1.7096e+07]))
Mean squared error: 0.02
Variance score: 0.96
Miremos los coeficientes del modelo. No podemos compararlos o decir cuál es importante, porque todos pertenecen a escalas diferentes. Intentemos la normalización para que se ajusten a la misma proporción y también aplicar algo de suavidad.
def normalize(basis_X, basis_y, period):
basis_X_norm = (basis_X - basis_X.rolling(period).mean())/
basis_X.rolling(period).std()
basis_X_norm.dropna(inplace=True)
basis_y_norm = (basis_y -
basis_X['basis'].rolling(period).mean())/
basis_X['basis'].rolling(period).std()
basis_y_norm = basis_y_norm[basis_X_norm.index]
return basis_X_norm, basis_y_norm
norm_period = 375
basis_X_norm_test, basis_y_norm_test = normalize(basis_X_test,basis_y_test, norm_period)
basis_X_norm_train, basis_y_norm_train = normalize(basis_X_train, basis_y_train, norm_period)
regr_norm, basis_y_pred = linear_regression(basis_X_norm_train, basis_y_norm_train, basis_X_norm_test, basis_y_norm_test)
basis_y_pred = basis_y_pred * basis_X_test['basis'].rolling(period).std()[basis_y_norm_test.index] + basis_X_test['basis'].rolling(period).mean()[basis_y_norm_test.index]
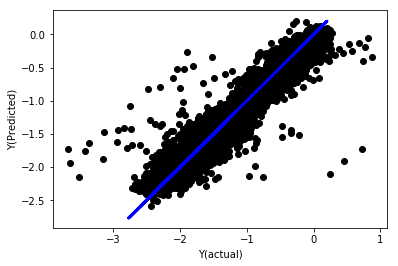
Regresión lineal con normalización
Mean squared error: 0.05
Variance score: 0.90
Este modelo no mejora el modelo anterior, pero no es peor. Ahora podemos comparar los coeficientes para ver cuáles son realmente importantes.
Veamos los coeficientes:
for i in range(len(basis_X_train.columns)):
print('%.4f, %s'%(regr_norm.coef_[i], basis_X_train.columns[i]))
Los resultados son los siguientes:
19.8727, emabasis4
-9.2015, emabasis5
8.8981, emabasis7
-5.5692, emabasis10
-0.0036, rsi15
-0.0146, rsi10
0.0196, mom10
-0.0035, mom5
-7.9138, basis
0.0062, swidth
0.0117, fwidth
2.0883, btopask
2.0311, btopbid
0.0974, bavgask
0.0611, bavgbid
0.0007, topaskvolratio
0.0113, topbidvolratio
-0.0220, totalaskvolratio
0.0231, totalbidvolratio
Podemos ver claramente que algunas características tienen coeficientes más altos que otros, y pueden tener una mayor capacidad de predicción.
Veamos la correlación entre las diferentes características.
import seaborn
c = basis_X_train.corr()
plt.figure(figsize=(10,10))
seaborn.heatmap(c, cmap='RdYlGn_r', mask = (np.abs(c) <= 0.8))
plt.show()
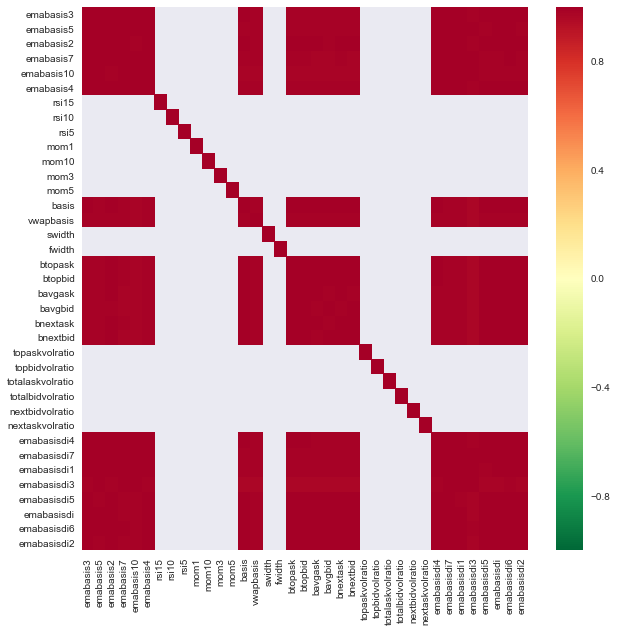
Correlación entre las características
Las áreas rojas oscuras representan variables altamente correlacionadas.
Por ejemplo, puedo descartar características como emabasisdi7 fácilmente, que son sólo combinaciones lineales de otras características.
def create_features_again(data):
basis_X = pd.DataFrame(index = data.index, columns = [])
basis_X['mom10'] = difference(data['basis'],11)
basis_X['emabasis2'] = ewm(data['basis'],2)
basis_X['emabasis5'] = ewm(data['basis'],5)
basis_X['emabasis10'] = ewm(data['basis'],10)
basis_X['basis'] = data['basis']
basis_X['totalaskvolratio'] = (data['stockTotalAskVol']
- data['futureTotalAskVol'])/
100000
basis_X['totalbidvolratio'] = (data['stockTotalBidVol']
- data['futureTotalBidVol'])/
100000
basis_X = basis_X.fillna(0)
basis_y = data['Y(Target)']
basis_y.dropna(inplace=True)
return basis_X, basis_y
basis_X_test, basis_y_test = create_features_again(validation_data)
basis_X_train, basis_y_train = create_features_again(training_data)
_, basis_y_pred = linear_regression(basis_X_train, basis_y_train, basis_X_test,basis_y_test)
basis_y_regr = basis_y_pred.copy()
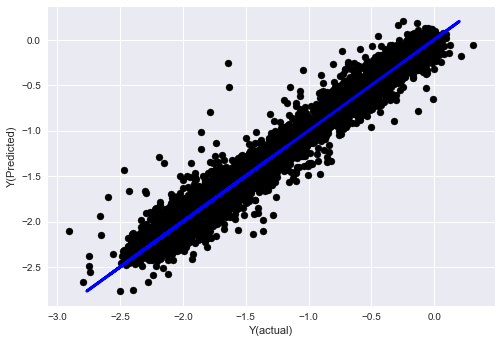
('Coefficients: ', array([ 0.03246139,
0.49780982, -0.22367172, 0.20275786, 0.50758852,
-0.21510795, 0.17153884]))
Mean squared error: 0.02
Variance score: 0.96
Mira, el rendimiento de nuestro modelo no ha cambiado. Solo necesitamos algunas características para explicar nuestras variables objetivo. Te sugiero que pruebes más de las características anteriores, pruebas nuevas combinaciones, etc., para ver qué puede mejorar nuestro modelo.
También podemos probar modelos más complejos para ver si los cambios en los modelos pueden mejorar el rendimiento.
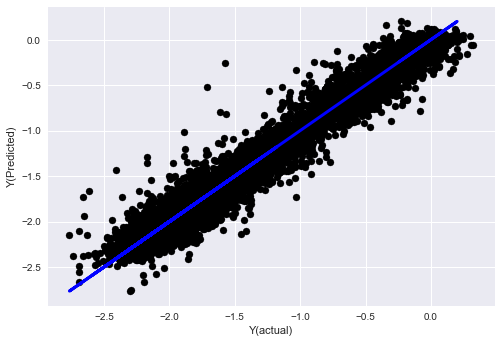
- Algoritmo de vecino más cercano (KNN)
from sklearn import neighbors
n_neighbors = 5
model = neighbors.KNeighborsRegressor(n_neighbors, weights='distance')
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_knn = basis_y_pred.copy()
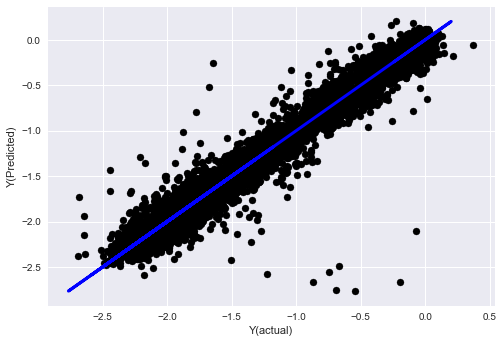
- El SVR
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1e3, gamma=0.1)
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_svr = basis_y_pred.copy()
- Árbol de decisiones
model=ensemble.ExtraTreesRegressor()
model.fit(basis_X_train, basis_y_train)
basis_y_pred = model.predict(basis_X_test)
basis_y_trees = basis_y_pred.copy()
Paso 7: Prueba posterior de los datos de ensayo
Verificar el rendimiento de los datos reales de la muestra
El rendimiento de los ensayos de retroceso en conjuntos de datos de ensayo (no afectados)
Este es un momento crítico. Ejecutamos nuestro modelo de optimización final desde el último paso de los datos de prueba, lo dejamos a un lado al principio y no hemos tocado los datos hasta ahora.
Esto le da una expectativa realista de cómo su modelo se ejecutará en datos nuevos y no vistos cuando comience a operar en tiempo real. Por lo tanto, es necesario asegurarse de que tiene un conjunto de datos limpio que no se utiliza para entrenar o verificar el modelo.
Si no le gustan los resultados de backtest de los datos de prueba, por favor descarte el modelo y comience de nuevo. ¡Nunca vuelva atrás o vuelva a optimizar su modelo, lo que llevará a un sobreajuste! (También se recomienda crear un nuevo conjunto de datos de prueba, porque este conjunto de datos ahora está contaminado; al descartar el modelo, ya conocemos el contenido del conjunto de datos implícitamente).
Aquí seguiremos utilizando la caja de herramientas de Auquan:
import backtester
from backtester.features.feature import Feature
from backtester.trading_system import TradingSystem
from backtester.sample_scripts.fair_value_params import FairValueTradingParams
class Problem1Solver():
def getTrainingDataSet(self):
return "trainingData1"
def getSymbolsToTrade(self):
return ['MQK']
def getCustomFeatures(self):
return {'my_custom_feature': MyCustomFeature}
def getFeatureConfigDicts(self):
expma5dic = {'featureKey': 'emabasis5',
'featureId': 'exponential_moving_average',
'params': {'period': 5,
'featureName': 'basis'}}
expma10dic = {'featureKey': 'emabasis10',
'featureId': 'exponential_moving_average',
'params': {'period': 10,
'featureName': 'basis'}}
expma2dic = {'featureKey': 'emabasis3',
'featureId': 'exponential_moving_average',
'params': {'period': 3,
'featureName': 'basis'}}
mom10dic = {'featureKey': 'mom10',
'featureId': 'difference',
'params': {'period': 11,
'featureName': 'basis'}}
return [expma5dic,expma2dic,expma10dic,mom10dic]
def getFairValue(self, updateNum, time, instrumentManager):
# holder for all the instrument features
lbInstF = instrumentManager.getlookbackInstrumentFeatures()
mom10 = lbInstF.getFeatureDf('mom10').iloc[-1]
emabasis2 = lbInstF.getFeatureDf('emabasis2').iloc[-1]
emabasis5 = lbInstF.getFeatureDf('emabasis5').iloc[-1]
emabasis10 = lbInstF.getFeatureDf('emabasis10').iloc[-1]
basis = lbInstF.getFeatureDf('basis').iloc[-1]
totalaskvol = lbInstF.getFeatureDf('stockTotalAskVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalAskVol').iloc[-1]
totalbidvol = lbInstF.getFeatureDf('stockTotalBidVol').iloc[-1] - lbInstF.getFeatureDf('futureTotalBidVol').iloc[-1]
coeff = [ 0.03249183, 0.49675487, -0.22289464, 0.2025182, 0.5080227, -0.21557005, 0.17128488]
newdf['MQK'] = coeff[0] * mom10['MQK'] + coeff[1] * emabasis2['MQK'] +\
coeff[2] * emabasis5['MQK'] + coeff[3] * emabasis10['MQK'] +\
coeff[4] * basis['MQK'] + coeff[5] * totalaskvol['MQK']+\
coeff[6] * totalbidvol['MQK']
newdf.fillna(emabasis5,inplace=True)
return newdf
problem1Solver = Problem1Solver()
tsParams = FairValueTradingParams(problem1Solver)
tradingSystem = TradingSystem(tsParams)
tradingSystem.startTrading(onlyAnalyze=False,
shouldPlot=True,
makeInstrumentCsvs=False)
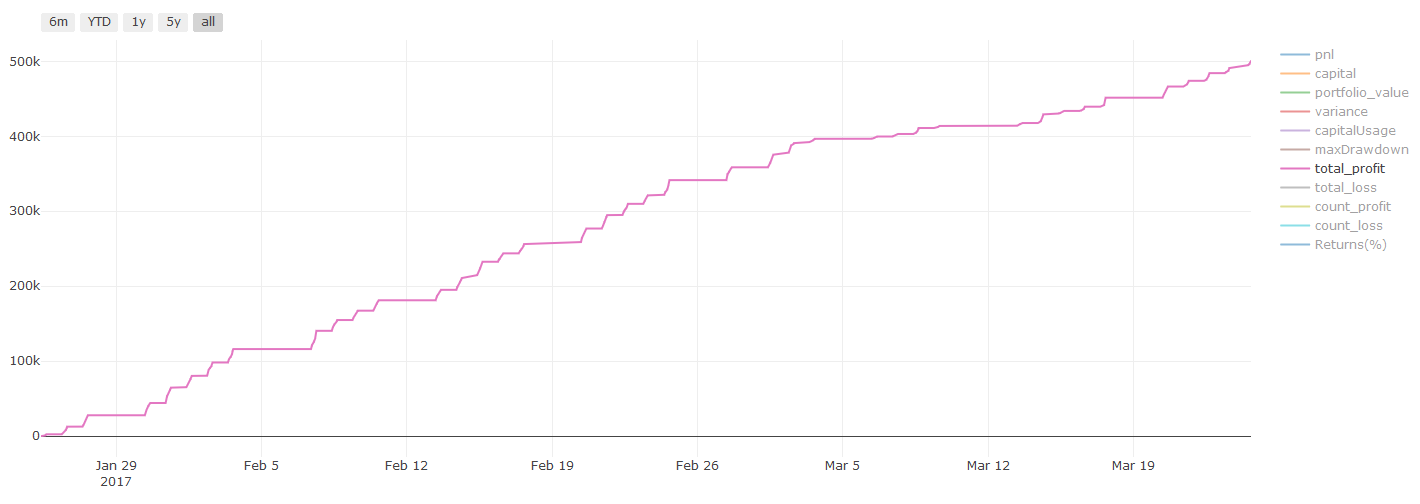
Resultados de las pruebas de retroceso, Pnl se calcula en USD (el Pnl no está incluido en los costes de transacción y otras comisiones)
Paso 8: Otros métodos para mejorar el modelo
Verificación del rodamiento, aprendizaje de conjuntos, embalaje y refuerzo
Además de recopilar más datos, crear mejores características o probar más modelos, hay algunos puntos más que puede tratar de mejorar.
1. Verificación en rodamiento
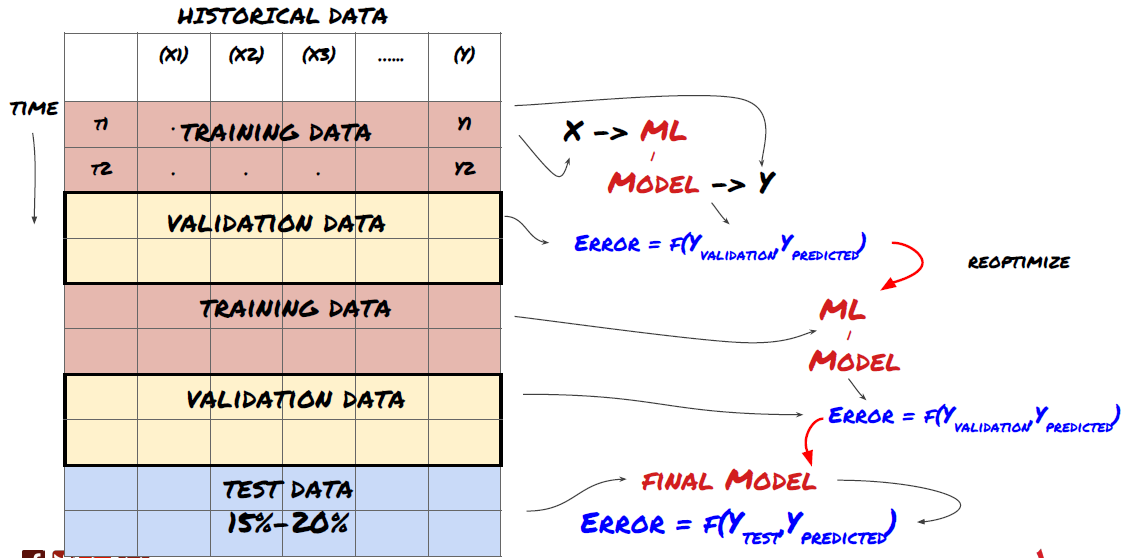
Verificación en rodamiento
Las condiciones del mercado rara vez permanecen iguales. Supongamos que tienes datos de un año, y usas los datos de enero a agosto para entrenamiento, y usas los datos de septiembre a diciembre para probar tu modelo. Puede que entrenes para un conjunto muy específico de condiciones del mercado eventualmente. Tal vez no hubo fluctuaciones del mercado en la primera mitad del año, y algunas noticias extremas llevaron a un fuerte aumento en el mercado en septiembre. Tu modelo no podrá aprender este modelo, y te traerá resultados de predicción basura.
Es posible que sea mejor probar la verificación progresiva, como la formación de enero a febrero, la verificación en marzo, la re-formación de abril a mayo, la verificación en junio, etc.
2. Aprendizaje conjunto
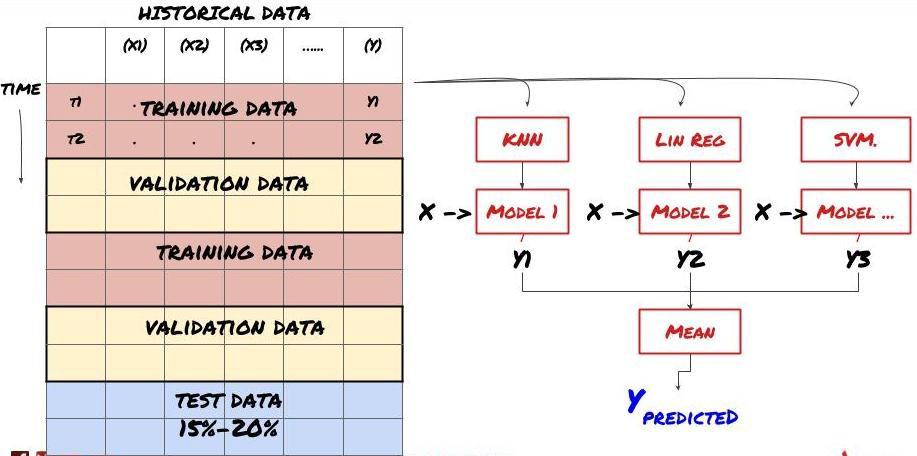
Aprendizaje conjunto
Algunos modelos pueden ser muy efectivos en la predicción de ciertos escenarios, mientras que los modelos pueden ser extremadamente sobreajustados en la predicción de otros escenarios o bajo ciertas circunstancias. Una forma de reducir errores y sobreajuste es usar un conjunto de modelos diferentes. Su predicción será el promedio de las predicciones hechas por muchos modelos, y los errores de diferentes modelos pueden ser compensados o reducidos. Algunos métodos de conjunto comunes son Bagging y Boosting.
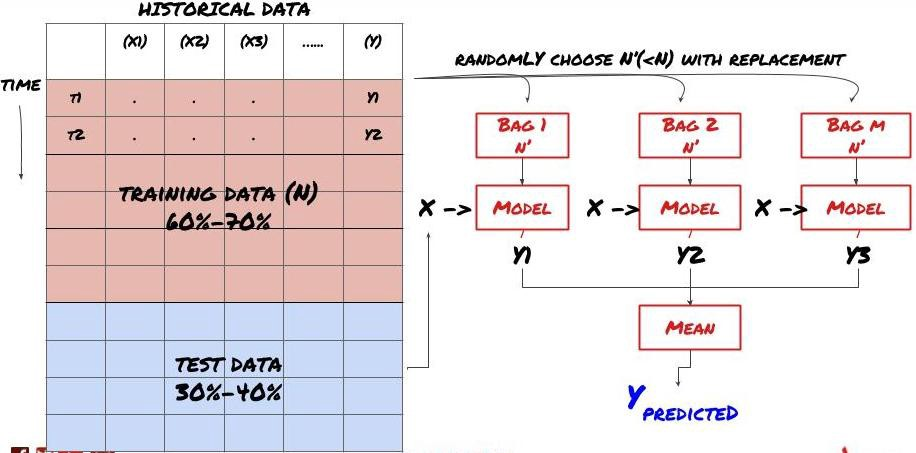
Envasado en bolsas
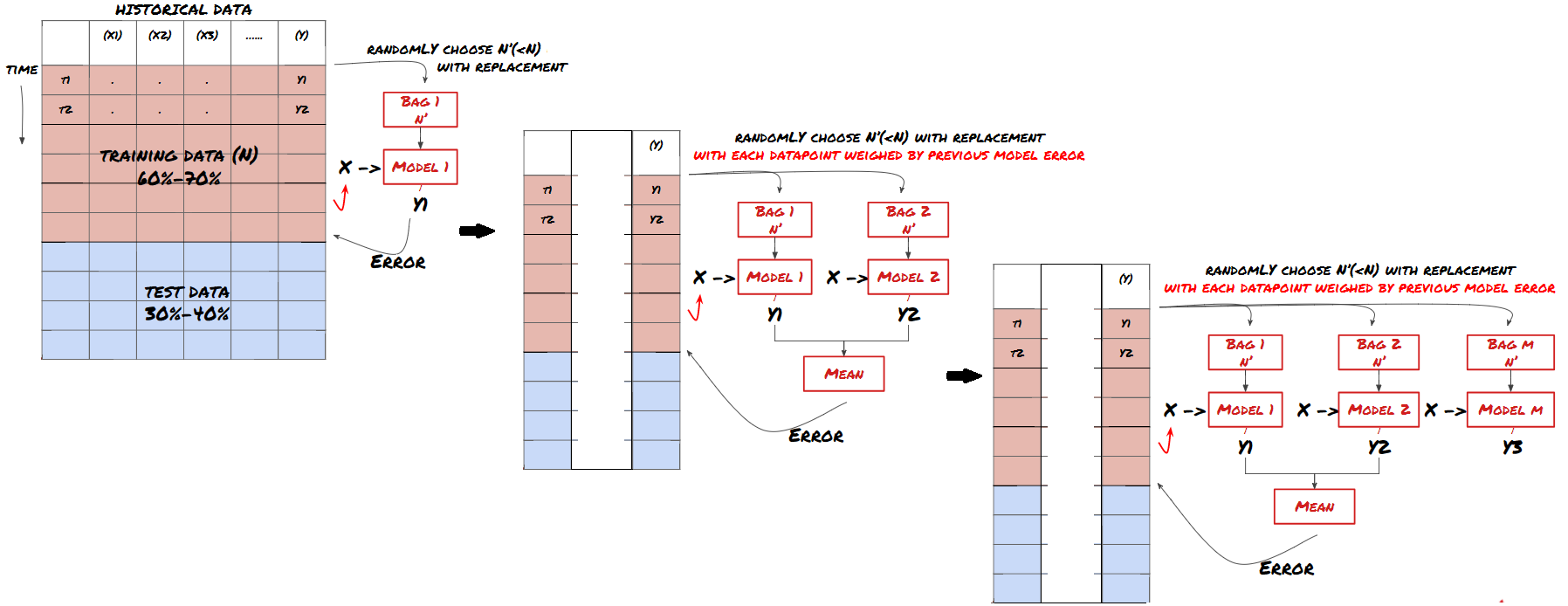
El impulso
Por razones de brevedad, omitiré estos métodos, pero puede encontrar más información en línea.
Intentemos un método conjunto para nuestro problema:
basis_y_pred_ensemble = (basis_y_trees + basis_y_svr +
basis_y_knn + basis_y_regr)/4
Mean squared error: 0.02
Variance score: 0.95
Hasta ahora, hemos acumulado mucho conocimiento e información.
-
Resolver su problema;
-
Recopilar datos fiables y limpiarlos;
-
Dividir los datos en conjuntos de formación, verificación y ensayo;
-
Crear características y analizar sus comportamientos;
-
Seleccionar el modelo de entrenamiento adecuado de acuerdo con el comportamiento;
-
Utilice los datos de entrenamiento para entrenar su modelo y hacer predicciones;
-
Verificar el rendimiento del conjunto de verificación y volver a optimizar;
-
Verificar el rendimiento final del conjunto de ensayo.
¿No se les ha pasado por la cabeza? Pero aún no ha terminado. Solo tienen un modelo de predicción confiable. ¿Recuerdan lo que realmente queríamos en nuestra estrategia?
-
Desarrollar señales basadas en modelos predictivos para identificar las direcciones de negociación;
-
Desarrollar estrategias específicas para identificar las posiciones abiertas y cerradas;
-
Ejecutar el sistema para identificar posiciones y precios.
La plataforma FMZ Quant (FMZ.COMEn la plataforma FMZ Quant, hay interfaces API altamente encapsuladas y perfectas, así como funciones de orden y comercio que se pueden llamar globalmente. No necesita conectar y agregar interfaces API de diferentes intercambios una por una. En el cuadrado de estrategia de la plataforma FMZ Quant, hay muchas estrategias alternativas maduras y perfectas que coinciden con el método de aprendizaje automático en este artículo, lo que hará que su estrategia específica sea más poderosa.https://www.fmz.com/square.
** Nota importante sobre los costos de transacción: ** Su modelo le dirá cuándo el activo seleccionado va largo o va corto. Sin embargo, no tiene en cuenta las tarifas / costos de transacción / cantidad de negociación disponible / stop loss, etc. Los costos de transacción generalmente convierten transacciones rentables en pérdidas. Por ejemplo, un activo con un aumento de precio esperado de $ 0.05 es una compra, pero si tiene que pagar $ 0.10 por esta transacción, obtendrá una pérdida neta de $ 0.05 eventualmente. Después de tener en cuenta la comisión del corredor, la tarifa de cambio y la diferencia de puntos, nuestro gran gráfico de ganancias anterior se ve así:
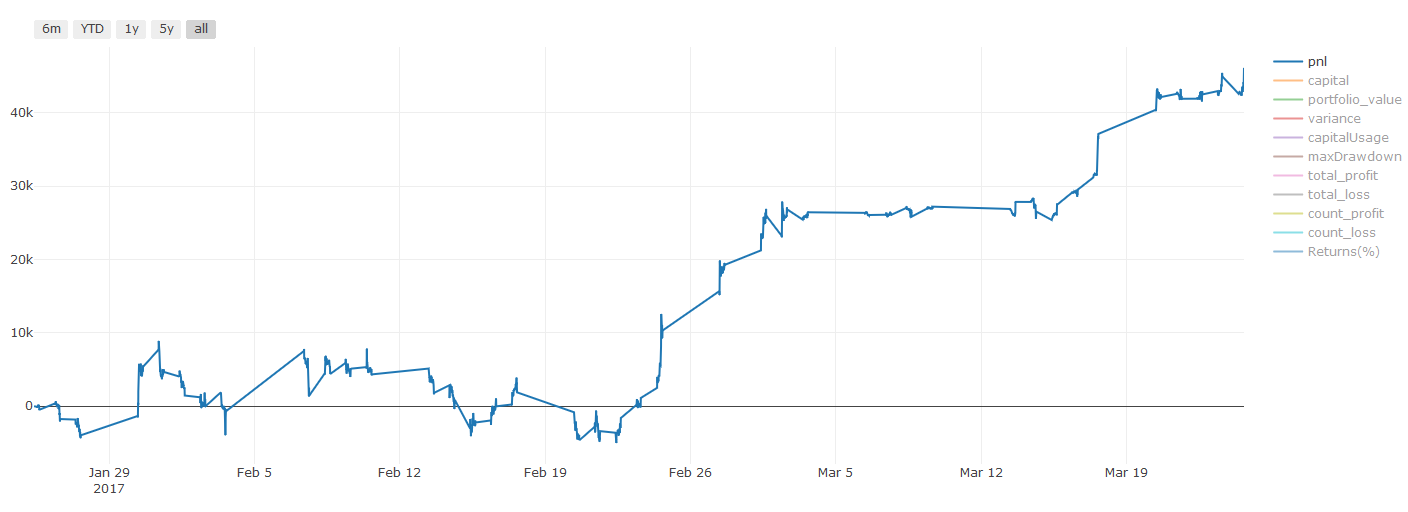
El resultado del backtest después de las tarifas de negociación y la diferencia de puntos, Pnl es USD.
Las tarifas de transacción y las diferencias de precios representan más del 90% de nuestro PNL!
Por último, echemos un vistazo a algunas trampas comunes.
Qué hacer y qué no hacer
-
¡Evitad el exceso de ajuste con toda vuestra fuerza!
-
No vuelvas a entrenar después de cada punto de datos: este es un error común que la gente comete en el desarrollo de aprendizaje automático. Si tu modelo necesita ser entrenado después de cada punto de datos, puede que no sea un modelo muy bueno. Es decir, necesita ser entrenado regularmente, y solo necesita ser entrenado con una frecuencia razonable (por ejemplo, si se hace una predicción intra-día, necesita ser entrenado al final de cada semana).
-
Evite el sesgo, especialmente el sesgo prospectivo: esta es otra razón por la que el modelo no funciona, y asegúrese de no usar ninguna información futura. En la mayoría de los casos, esto significa que la variable objetivo Y no se usa como una característica en el modelo. Puede usarla durante la prueba posterior, pero no estará disponible cuando ejecute el modelo en realidad, lo que hará que su modelo sea inutilizable.
-
Tenga cuidado con el sesgo de la minería de datos: ya que estamos tratando de realizar una serie de modelos en nuestros datos para determinar si es apropiado, si no hay una razón especial, asegúrese de ejecutar pruebas estrictas para separar el modo aleatorio del modo real que puede ocurrir.
Evite el ajuste excesivo
Esto es muy importante y creo que es necesario mencionarlo de nuevo.
-
El sobreajuste es la trampa más peligrosa en las estrategias comerciales.
-
Un algoritmo complejo puede funcionar muy bien en el backtest, pero falla miserablemente en los nuevos datos invisibles. Este algoritmo no revela realmente ninguna tendencia de los datos, ni tiene una capacidad de predicción real. Es muy adecuado para los datos que ve;
-
Mantenga su sistema lo más simple posible. Si usted encuentra que necesita un montón de funciones complejas para interpretar los datos, usted puede sobreajustar;
-
Divida los datos disponibles en datos de entrenamiento y pruebas y verifique siempre el rendimiento de los datos reales de muestra antes de utilizar el modelo para transacciones en tiempo real.
- Introducción al arbitraje de lead-lag en criptomonedas (2)
- Introducción al conjunto de Lead-Lag en las monedas digitales (2)
- Discusión sobre la recepción de señales externas de la plataforma FMZ: una solución completa para recibir señales con servicio HTTP incorporado en la estrategia
- Exploración de la recepción de señales externas de la plataforma FMZ: estrategias para una solución completa de recepción de señales de servicios HTTP integrados
- Introducción al arbitraje de lead-lag en criptomonedas (1)
- Introducción al conjunto de Lead-Lag en las monedas digitales (1)
- Discusión sobre la recepción de señales externas de la plataforma FMZ: API extendida VS estrategia Servicio HTTP incorporado
- Exploración de la recepción de señales externas de la plataforma FMZ: API de expansión vs estrategia de servicio HTTP incorporado
- Discusión sobre el método de prueba de estrategias basado en el generador de tickers aleatorios
- Explorar métodos de prueba de estrategias basados en generadores de mercado aleatorios
- Nueva característica de FMZ Quant: Utilice la función _Serve para crear servicios HTTP fácilmente
- Las redes neuronales y la serie de comercio cuantitativo de moneda digital (1) - LSTM predice el precio de Bitcoin
- Aplicación de la estrategia combinada del índice de resistencia relativa de la SMA y del RSI
- El desarrollo de la estrategia de CTA y la biblioteca de clases estándar de la plataforma FMZ Quant
- Estrategia de negociación cuantitativa con análisis de impulso de precios en Python
- Implementar una estrategia de negociación cuantitativa de moneda digital de doble impulso en Python
- La mejor manera de instalar y actualizar para Linux docker
- Lograr estrategias equitativas equilibradas de posiciones largas y cortas con una alineación ordenada
- Análisis de datos de series temporales y pruebas de retroceso de datos de tick
- Análisis cuantitativo del mercado de divisas digitales
- Comercio de pares basado en tecnología basada en datos
- Utilice el entorno de investigación para analizar los detalles de la cobertura triangular y el impacto de las tarifas de gestión en la diferencia de precios cubierta.
- Reforma de la API de futuros de Deribit para adaptarla a la negociación cuantitativa de opciones
- Mejores herramientas hacen un buen trabajo - aprender a utilizar el entorno de investigación para analizar los principios comerciales
- Estrategias de cobertura de divisas cruzadas en la negociación cuantitativa de activos de cadena de bloques
- Adquiere la guía de estrategia de moneda digital de FMex en FMZ Quant
- Enseñarle a escribir estrategias -- trasplantar una estrategia MyLanguage (Advanced)
- Enseñar a escribir estrategias -- trasplantar una estrategia MyLanguage
- Enseñarle a añadir soporte multi-gráfico a la estrategia
- Enseñar a escribir una función de síntesis de línea K en la versión de Python
- Análisis de la estrategia del canal de Donchian en el entorno de investigación