Redes neuronales y moneda digital Serie de comercio cuantitativo (2) - Aprendizaje y capacitación intensivos Estrategia de comercio de Bitcoin
El autor:FMZ~Lydia, Creado: 2023-01-12 16:49:09, Actualizado: 2024-12-19 21:09:28
Redes neuronales y moneda digital Serie de comercio cuantitativo (2) - Aprendizaje y capacitación intensivos Estrategia de comercio de Bitcoin
1. Introducción
En el último artículo, presentamos el uso de la red LSTM para predecir el precio de Bitcoin:https://www.fmz.com/bbs-topic/9879, como se mencionó en el artículo, es solo un pequeño proyecto de capacitación para familiarizarse con RNN y pytorch. Este artículo introducirá el uso de aprendizaje intensivo para entrenar las estrategias comerciales directamente. El modelo de aprendizaje intensivo es OpenAI PPO de código abierto, y el entorno se refiere al estilo de gimnasio. Para facilitar la comprensión y las pruebas, el modelo PPO de LSTM y el entorno de gimnasio para backtesting se escriben directamente sin usar paquetes listos. PPO, o Optimización de Políticas Proximales, es una mejora de optimización de Policy Gradient. Gym también fue lanzado por OpenAI. Puede interactuar con la red de estrategias y dar retroalimentación al estado y las recompensas del entorno actual. Es como la práctica del aprendizaje intensivo. Utiliza el modelo PPO de LSTM para hacer instrucciones, como comprar, vender o no operar directamente de acuerdo con la información del mercado de Bitcoin. La retroalimentación es dada por el entorno de backtest. A través de la capacitación, el modelo se optimiza continuamente para lograr el objetivo de ganancia estratégica. Leer este artículo requiere una cierta base de aprendizaje intensivo en Python, pytorch y DRL. Pero no importa si no puedes. Es fácil de aprender y comenzar con el código dado en este artículo.www.fmz.comBienvenido a unirse al grupo QQ: 863946592 para la comunicación.
2. Datos y referencias de aprendizaje
Datos de precios de Bitcoin provenientes de la plataforma de comercio de FMZ Quant:https://www.quantinfo.com/Tools/View/4.html¿ Qué pasa? Un artículo que usa DRL+gym para entrenar estrategias comerciales:https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4¿ Qué pasa? Algunos ejemplos de cómo empezar con pytorch:https://github.com/yunjey/pytorch-tutorial¿ Qué pasa? Este artículo aplicará directamente el modelo LSTM-PPO:https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py¿ Qué pasa? Artículos sobre la PPO:https://zhuanlan.zhihu.com/p/38185553¿ Qué pasa? Más artículos sobre DRL:https://www.zhihu.com/people/flood-sung/posts¿ Qué pasa? Este artículo no requiere instalación, pero es muy común en el aprendizaje intensivo:https://gym.openai.com/.
3. LSTM-PPO
Para una explicación en profundidad de PPO, puede aprender de los materiales de referencia anteriores. Aquí hay solo una simple introducción a los conceptos. El último número de la red LSTM solo predijo el precio. Cómo comprar y vender en función del precio predicho tendrá que realizarse por separado. Es natural pensar que la salida directa de la acción comercial será más directa. Este es el caso del Gradiente de Política, que puede dar la probabilidad de varias acciones de acuerdo con la información del entorno de entrada s. La pérdida de LSTM es la diferencia entre el precio predicho y el precio real, mientras que la pérdida de PG es - log § * Q, donde p es la probabilidad de una acción de salida, y Q es el valor de la acción (como la puntuación de recompensa intuitiva). La explicación es que si el valor de una acción es mayor, la red debe ser una clave para reducir la pérdida. Aunque PPO es más complejo, su principio es mucho más similar.
El código fuente de LSTM-PPO se muestra a continuación, que se puede entender en combinación con los datos anteriores:
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
# Hyperparameters of the model
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # It can also be changed to GPU version.
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
# Output the probability of each action. Since LSTM network also contains the information of hidden layer, please refer to the previous article.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
# Value function is used to evaluate the current situation, so there is only one output.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
# Prepare the training data.
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) # Trained both value and decision networks at the same time.
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. El entorno de backtesting Bitcoin
Siguiendo el formato de gimnasio, hay un método de inicialización de restablecimiento. Step introduce la acción, y el resultado devuelto es (próximo estado, ingresos de la acción, si termina, información adicional).
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks # Initial number of Bitcoins
self.initial_balance = initial_balance # Initial assets
self.current_time = 0 # Time position of the backtest
self.commission = commission # Trading fees
self.done = False # Is the backtest over?
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) # Standardized approach, simple yield normalization.
self.mode = all_data # Whether it is a sample backtest mode.
self.sample_length = 500 # Sample length
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
# action is the action taken by the strategy, here the account will be updated and the reward will be calculated.
done = False
if action == 0: # Hold
pass
elif action == 1: # Buy
buy_value = self.balance*0.5
if buy_value > 1: # Insufficient balance, no account operation.
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: # Sell
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # The reward for each turn is the added revenue.
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Varios detalles notables
- ¿Por qué la cuenta inicial tiene moneda?
La fórmula para calcular el rendimiento del entorno de backtest es: rendimiento actual = valor de la cuenta corriente - valor actual de la cuenta inicial. Esto significa que si el precio de Bitcoin disminuye y la estrategia realiza una operación de venta de monedas, incluso si el valor total de la cuenta disminuye, la estrategia debería ser recompensada. Si la backtest toma mucho tiempo, la cuenta inicial puede tener poco impacto, pero tendrá un gran impacto al principio. El cálculo del rendimiento relativo asegura que cada operación correcta obtendrá una recompensa positiva.
- ¿Por qué se tomó una muestra del mercado durante la formación?
La cantidad total de datos es de más de 10.000 K-líneas. Si ejecuta un bucle en su totalidad cada vez, tomará mucho tiempo, y la estrategia se enfrenta a la misma situación cada vez, puede ser más fácil de sobreajustar. Tomando 500 barras a la vez como prueba de retroceso. Aunque todavía es posible sobreajustar, la estrategia se enfrenta a más de 10.000 posibles comienzos.
- ¿Qué pasa si no hay moneda ni dinero?
Esta situación no se considera en el entorno de backtest. Si la moneda se ha agotado o la cantidad mínima de negociación no se puede alcanzar, entonces la operación de venta es equivalente a la no operación en realidad. Si el precio disminuye, de acuerdo con el método de cálculo del rendimiento relativo, todavía se basa en el rendimiento positivo estratégico. El impacto de esta situación es que cuando la estrategia juzga que el mercado está disminuyendo y la moneda restante de la cuenta no se puede vender, es imposible distinguir la acción de venta de la acción no operativa, pero no tiene ningún impacto en el juicio de la estrategia en sí en el mercado.
- ¿Por qué debo devolver la información de la cuenta como estado?
El modelo PPO tiene una red de valor para evaluar el valor del estado actual. Obviamente, si la estrategia juzga que el precio aumentará, todo el estado tendrá un valor positivo solo cuando la cuenta corriente tenga Bitcoin, y viceversa. Por lo tanto, la información de la cuenta es una base importante para el juicio de la red de valor. Se observa que la información de la acción pasada no se devuelve como estado. Considero inútil juzgar el valor.
- ¿Cuándo volverá a no operar?
Cuando la estrategia juzga que los retornos traídos por la transacción no pueden cubrir la tarifa de manejo, debe volver a no operar. Aunque la descripción anterior utiliza estrategias repetidamente para juzgar la tendencia del precio, es solo para facilitar la comprensión. De hecho, este modelo PPO no predice el mercado, sino que solo da la probabilidad de tres acciones.
6. Adquisición de datos y formación
Al igual que en el artículo anterior, el método y el formato de adquisición de datos son los siguientes: período de una hora K-line del par de operaciones BTC_USD de Bitfinex Exchange desde el 7 de mayo de 2018 hasta el 27 de junio de 2019:
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Debido al uso de la red LSTM, el tiempo de entrenamiento es muy largo. Cambié a una versión de GPU, que es aproximadamente tres veces más rápido.
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 # Record total profit
profit_list = [] # Record the profits of each training session
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Resultados y análisis de la formación
Después de una larga espera:

En primer lugar, echemos un vistazo al mercado de datos de formación.
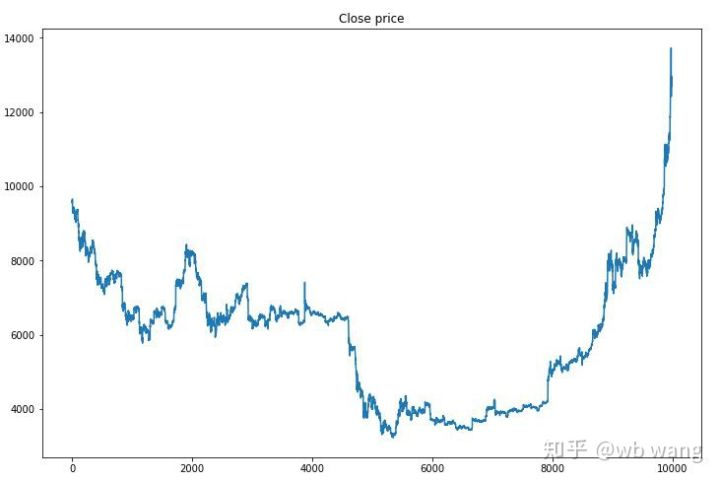
Hay muchas operaciones de compra en la etapa inicial de la capacitación, y básicamente no hay una ronda rentable. A mediados de la capacitación, la operación de compra ha disminuido gradualmente, y la probabilidad de ganancia también aumenta, pero todavía hay una gran posibilidad de pérdida.
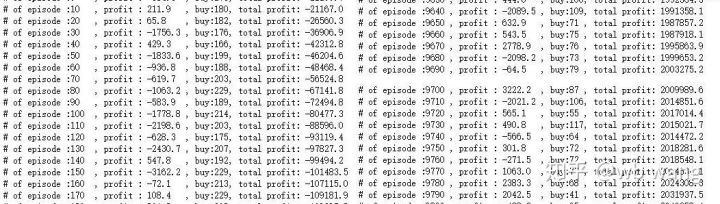
Limpia las ganancias de cada ronda, y el resultado es el siguiente:
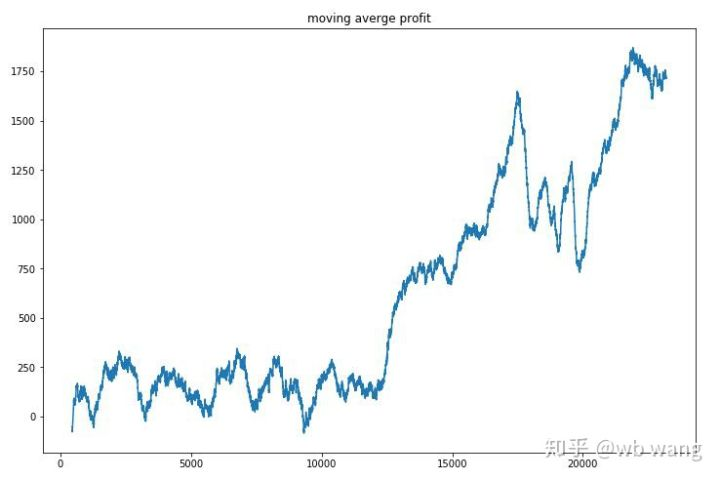
La estrategia rápidamente se deshizo de la situación de que el retorno temprano era negativo, pero la fluctuación era grande. El retorno no creció rápidamente hasta después de 10.000 rondas. En general, el entrenamiento del modelo era muy difícil.
Después de la capacitación final, deje que el modelo ejecute todos los datos de nuevo para ver cómo funciona. Durante el período, registre el valor total de mercado de la cuenta, el número de Bitcoins mantenidos, la proporción del valor de Bitcoin y los retornos totales. Primero es el valor total de mercado, y los rendimientos totales son similares a él, no se publicarán:
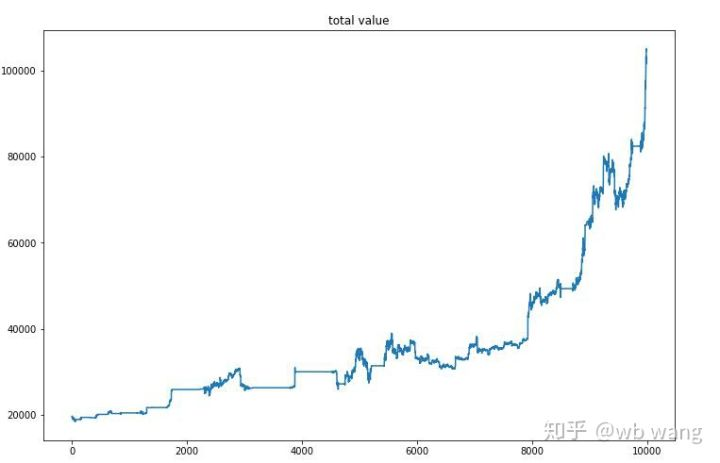
El valor de mercado total aumentó lentamente en el mercado bajista temprano, y siguió el aumento en el mercado alcista posterior, pero todavía hubo pérdidas periódicas.
Por último, echa un vistazo a la proporción de posiciones. El eje izquierdo del gráfico es la proporción de posiciones, y el eje derecho es el mercado. Se puede juzgar preliminarmente que el modelo está sobreajustado. La frecuencia de posiciones es baja en el mercado bajista temprano y alta en la parte inferior del mercado. También se puede ver que el modelo no ha aprendido a mantener posiciones a largo plazo y siempre vende rápidamente.
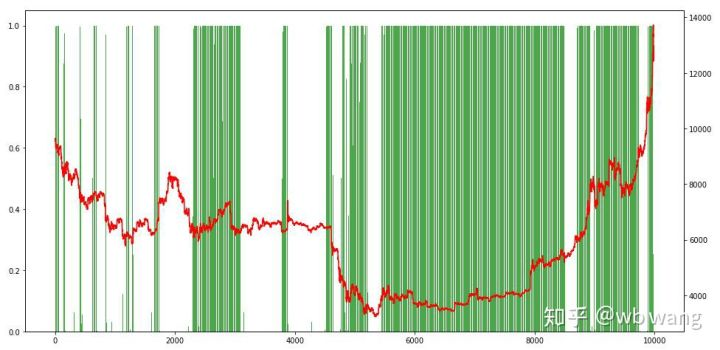
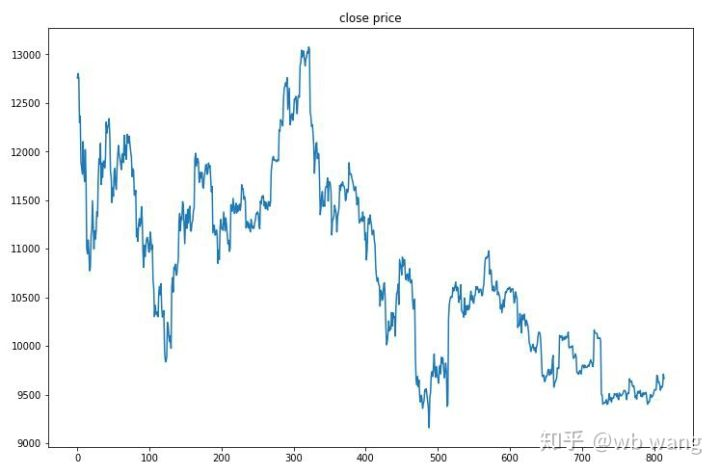
8. Análisis de los datos de ensayo
El mercado de una hora de Bitcoin desde el 27 de junio de 2019 hasta ahora se obtuvo a partir de los datos de prueba. Se puede ver en el gráfico que el precio ha caído de $ 13,000 a más de $ 9,000, lo que es una gran prueba para el modelo.
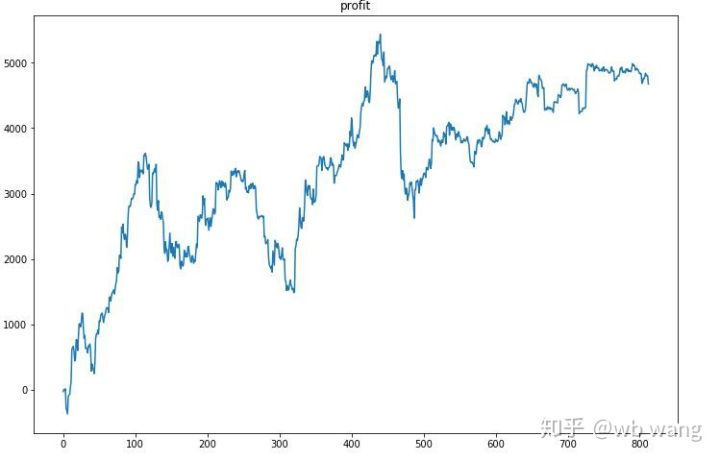
En primer lugar, el rendimiento relativo final se llevó a cabo de tal manera, pero no hubo pérdida.
Al observar la situación de la posición, podemos suponer que el modelo tiende a comprar después de una fuerte caída y vender después de un repunte.
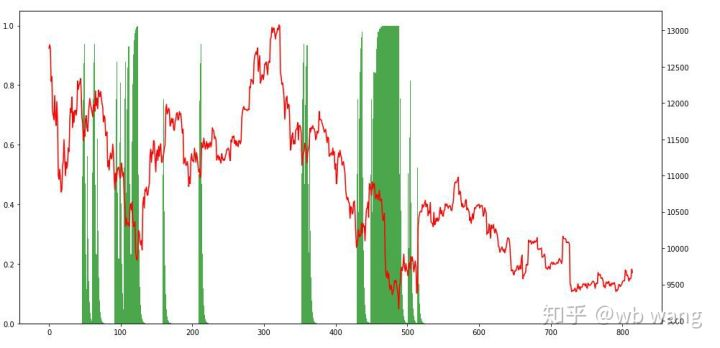
9. Resumen
En este artículo, un robot de comercio automático de Bitcoin es entrenado con la ayuda de PPO, un método de aprendizaje intensivo profundo, y se obtienen algunas conclusiones. Debido al tiempo limitado, todavía hay algunos aspectos que mejorar en el modelo. Bienvenido a la discusión. La lección más grande es que para el método de estandarización de datos, no use escalado y otros métodos, de lo contrario el modelo recordará rápidamente la relación entre precio y mercado, y caerá en sobreajuste.
Introducción a los artículos anteriores: Una estrategia de alta frecuencia que he revelado que una vez fue muy rentable:https://www.fmz.com/bbs-topic/9886.
- Introducción al arbitraje de lead-lag en criptomonedas (2)
- Introducción al conjunto de Lead-Lag en las monedas digitales (2)
- Discusión sobre la recepción de señales externas de la plataforma FMZ: una solución completa para recibir señales con servicio HTTP incorporado en la estrategia
- Exploración de la recepción de señales externas de la plataforma FMZ: estrategias para una solución completa de recepción de señales de servicios HTTP integrados
- Introducción al arbitraje de lead-lag en criptomonedas (1)
- Introducción al conjunto de Lead-Lag en las monedas digitales (1)
- Discusión sobre la recepción de señales externas de la plataforma FMZ: API extendida VS estrategia Servicio HTTP incorporado
- Exploración de la recepción de señales externas de la plataforma FMZ: API de expansión vs estrategia de servicio HTTP incorporado
- Discusión sobre el método de prueba de estrategias basado en el generador de tickers aleatorios
- Explorar métodos de prueba de estrategias basados en generadores de mercado aleatorios
- Nueva característica de FMZ Quant: Utilice la función _Serve para crear servicios HTTP fácilmente
- Tres modelos potenciales en el comercio cuantitativo
- Sistema de negociación intradiario en punto de convergencia
- 6 estrategias y prácticas simples para principiantes en el comercio cuantitativo de moneda digital
- Marco estratégico del intervalo verdadero medio
- Práctica y aplicación de la estrategia del termostato en la plataforma FMZ Quant
- Estrategia de negociación basada en la teoría de la caja, apoyando futuros de materias primas y moneda digital
- Estrategia de negociación cuantitativa basada en el precio
- Estrategia cuantitativa de negociación utilizando un índice ponderado por volumen de negociación
- Implementación y aplicación de la estrategia de negociación PBX en la plataforma de negociación FMZ Quant
- Compartición tardía: Robot de alta frecuencia Bitcoin con 5% de rendimientos diarios en 2014
- Las redes neuronales y la serie de comercio cuantitativo de moneda digital (1) - LSTM predice el precio de Bitcoin
- Aplicación de la estrategia combinada del índice de resistencia relativa de la SMA y del RSI
- El desarrollo de la estrategia de CTA y la biblioteca de clases estándar de la plataforma FMZ Quant
- Estrategia de negociación cuantitativa con análisis de impulso de precios en Python
- Implementar una estrategia de negociación cuantitativa de moneda digital de doble impulso en Python
- La mejor manera de instalar y actualizar para Linux docker
- Lograr estrategias equitativas equilibradas de posiciones largas y cortas con una alineación ordenada
- Análisis de datos de series temporales y pruebas de retroceso de datos de tick
- Análisis cuantitativo del mercado de divisas digitales
- Comercio de pares basado en tecnología basada en datos