Estrategia de negociación cuantitativa de media móvil exponencial con retraso cero adaptativa
El autor:¿ Qué pasa?, fecha: 2024-02-19 15:38:02Las etiquetas:
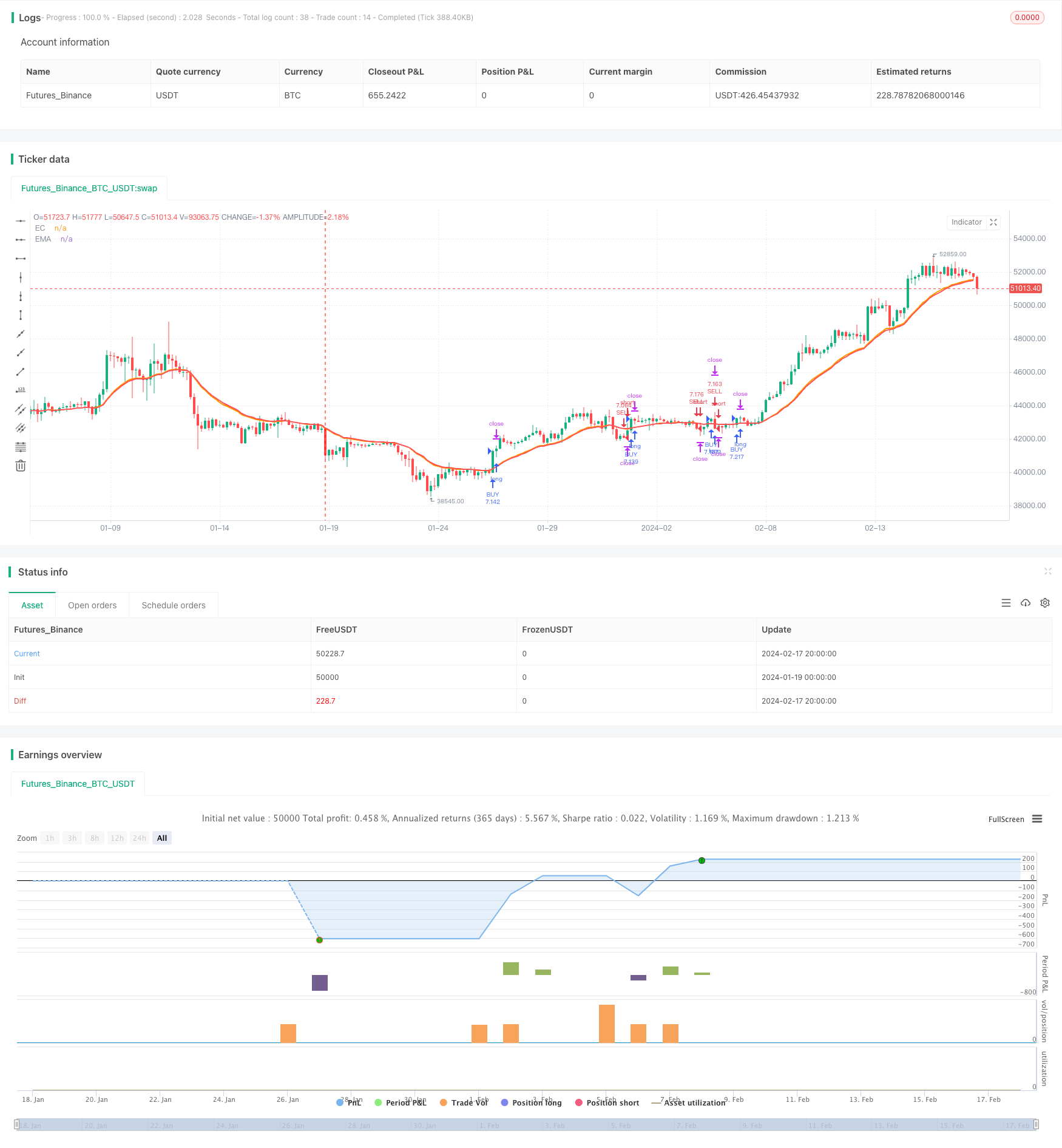
Resumen general
La estrategia de negociación cuantitativa de promedio móvil exponencial de retraso cero adaptativo es una estrategia de negociación cuantitativa desarrollada sobre la base de la idea de John Ehlers de promedio móvil exponencial de retraso cero (ZLEMA). Esta estrategia utiliza el promedio móvil exponencial como indicador de referencia e incorpora un método adaptativo de medición de frecuencia instantánea (IFM) para optimizar dinámicamente el parámetro de período del promedio móvil exponencial.
Estrategia lógica
La idea central de esta estrategia se origina en la teoría de filtros de retraso cero de John Ehlers. Aunque el promedio móvil exponencial es un indicador técnico ampliamente conocido, tiene inherentemente el problema del retraso. Ehlers introduce un factor de corrección de error en la fórmula de cálculo del promedio móvil exponencial para eliminar efectivamente el fenómeno del retraso, haciendo que la EMA de retraso cero sea más sensible en el seguimiento de los cambios de precios.
En la estrategia Adaptive Zero Lag EMA, utilizamos los métodos de medición de frecuencia instantánea para optimizar adaptativamente el parámetro de período del ZLEMA. El IFM consta de dos técnicas: el método Cosino y el método Inphase-Quadrature, que pueden medir el ciclo dominante de oscilación de precios. Mediante el seguimiento en tiempo real de los períodos óptimos calculados por estas dos mediciones, establecemos dinámicamente el parámetro de período del ZLEMA para adaptarse mejor a la condición actual del mercado.
Cuando la EMA rápida (ZLEMA) cruza la EMA lenta desde abajo, se genera una señal larga. Cuando la EMA rápida cruza por debajo de la EMA lenta, se activa una señal corta. Esto forma una estrategia de negociación similar al sistema de cruce de la media móvil.
Ventajas
La estrategia EMA Adaptive Zero Lag combina el filtro de retraso cero y la optimización del período de adaptación, con las siguientes ventajas:
- Elimina el retraso y hace señales más sensibles
- Parámetro de período de adaptación para una amplia gama de mercados
- Menos parámetros fáciles de probar y optimizar
- SL/TP fijo configurable para un mejor control del riesgo
Los riesgos
Esta estrategia también presenta algunos riesgos:
- El período optimizado de adaptación puede fallar en ciertos entornos de mercado
- Los ajustes inadecuados de SL/TP fijos podrían dar lugar a pérdidas excesivas o pérdidas de beneficios
- Las pruebas de optimización de parámetros insuficientes pueden conducir a un mal rendimiento en vivo
Para controlar estos riesgos, necesitamos probar completamente los parámetros en diferentes condiciones de mercado, ajustar el SL/TP adecuadamente y simular el entorno de negociación en vivo en backtests.
Direcciones de optimización
Todavía hay mucho espacio para optimizar aún más esta estrategia:
- Métodos alternativos de medición del período adaptativo, por ejemplo, MA ajustado a la volatilidad
- Condiciones de filtro adicionales como volumen, emparejamientos de MA, etc.
- Técnicas mejoradas de SL/TP, por ejemplo, paradas traseras o salida de candelabros
- Posición dinámica combinada con la gestión del riesgo
- Confirmación de marcos de tiempo múltiples para mejorar la calidad de la señal
A través de estos medios de optimización, existe el potencial de mejorar aún más la tasa de ganancia, la rentabilidad y las métricas ajustadas al riesgo de la estrategia.
Conclusión
La estrategia Adaptive Zero Lag EMA combina con éxito el filtro de retraso cero y la optimización del período dinámico. Con menos parámetros y fácil de operar, es especialmente adecuada para mercados de tendencia. Junto con el stop loss adecuado, el tamaño de la posición y otras técnicas de gestión de riesgos, se puede mejorar aún más su estabilidad y rentabilidad.
/*backtest
start: 2024-01-19 00:00:00
end: 2024-02-18 00:00:00
period: 4h
basePeriod: 15m
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT"}]
*/
//@version=3
strategy(title="Adaptive Zero Lag EMA v2", shorttitle="AZLEMA", overlay = true)
src = input(title="Source", defval=close)
Period = input(title="Period", defval = 20)
adaptive = input(title="Adaptive Method", options=["Off", "Cos IFM", "I-Q IFM", "Average"], defval="Off")
GainLimit = input(title="Gain Limit", defval = 10)
Threshold = input(title="Threshold", type = float, defval=0.05, step=0.01)
fixedSL = input(title="SL Points", defval=70)
fixedTP = input(title="TP Points", defval=5)
risk = input(title='Risk', defval=0.01, step=0.01)
//##############################################################################
//I-Q IFM
//#############################################################################
range = input(title="Max Period", defval=60, minval=8, maxval=100)
PI = 3.14159265359
imult = 0.635
qmult = 0.338
inphase = 0.0
quadrature = 0.0
re = 0.0
im = 0.0
deltaIQ = 0.0
instIQ = 0.0
lenIQ = 0.0
V = 0.0
P = src - src[7]
inphase := 1.25*(P[4] - imult*P[2]) + imult*nz(inphase[3])
quadrature := P[2] - qmult*P + qmult*nz(quadrature[2])
re := 0.2*(inphase*inphase[1] + quadrature*quadrature[1]) + 0.8*nz(re[1])
im := 0.2*(inphase*quadrature[1] - inphase[1]*quadrature) + 0.8*nz(im[1])
if (re!= 0.0)
deltaIQ := atan(im/re)
for i=0 to range
V := V + deltaIQ[i]
if (V > 2*PI and instIQ == 0.0)
instIQ := i
if (instIQ == 0.0)
instIQ := nz(instIQ[1])
lenIQ := 0.25*instIQ + 0.75*nz(lenIQ[1])
//##############################################################################
//COSINE IFM
//#############################################################################
s2 = 0.0
s3 = 0.0
deltaC = 0.0
instC = 0.0
lenC = 0.0
v1 = 0.0
v2 = 0.0
v4 = 0.0
v1 := src - src[7]
s2 := 0.2*(v1[1] + v1)*(v1[1] + v1) + 0.8*nz(s2[1])
s3 := 0.2*(v1[1] - v1)*(v1[1] - v1) + 0.8*nz(s3[1])
if (s2 != 0)
v2 := sqrt(s3/s2)
if (s3 != 0)
deltaC := 2*atan(v2)
for i = 0 to range
v4 := v4 + deltaC[i]
if (v4 > 2*PI and instC == 0.0)
instC := i - 1
if (instC == 0.0)
instC := instC[1]
lenC := 0.25*instC + 0.75*nz(lenC[1])
if (adaptive == "Cos IFM")
Period := round(lenC)
if (adaptive == "I-Q IFM")
Period := round(lenIQ)
if (adaptive == "Average")
Period := round((lenC + lenIQ)/2)
//##############################################################################
//ZERO LAG EXPONENTIAL MOVING AVERAGE
//##############################################################################
LeastError = 1000000.0
EC = 0.0
Gain = 0.0
EMA = 0.0
Error = 0.0
BestGain = 0.0
alpha =2/(Period + 1)
EMA := alpha*src + (1-alpha)*nz(EMA[1])
for i = -GainLimit to GainLimit
Gain := i/10
EC := alpha*(EMA + Gain*(src - nz(EC[1]))) + (1 - alpha)*nz(EC[1])
Error := src - EC
if(abs(Error)<LeastError)
LeastError := abs(Error)
BestGain := Gain
EC := alpha*(EMA + BestGain*(src - nz(EC[1]))) + (1-alpha)*nz(EC[1])
plot(EC, title="EC", color=orange, linewidth=2)
plot(EMA, title="EMA", color=red, linewidth=2)
buy = crossover(EC,EMA) and 100*LeastError/src > Threshold
sell = crossunder(EC,EMA) and 100*LeastError/src > Threshold
strategy.initial_capital = 50000
if (time>timestamp(2016, 1, 1 , 0, 0))
//LONG
balance = strategy.initial_capital + strategy.netprofit
lots = ((risk * balance)/fixedSL)*1
strategy.entry("BUY", strategy.long, qty=lots, oca_name="BUY", when=buy)
strategy.exit("B.Exit", "BUY", qty_percent = 100, loss=fixedSL, trail_offset=15, trail_points=fixedTP)
//SHORT
strategy.entry("SELL", strategy.short, qty=lots, oca_name="SELL", when=sell)
strategy.exit("S.Exit", "SELL", qty_percent = 100, loss=fixedSL, trail_offset=15, trail_points=fixedTP)
- Estrategia de combinación de indicadores Seguimiento de tendencias de avance
- Identificador de la etapa de acumulación y estrategia de negociación
- OBV, OCM y estrategia de negociación basada en la curva de Coppock
- Estrategia de las zonas de acción de los CDC
- Estrategia de negociación cuantitativa de múltiples factores
- Tendencia siguiendo una estrategia basada en una desviación suavizada
- Estrategia de negociación del oscilador de la nube Ichimoku
- Estrategia de red DCA de inversión media de doble fondo
- Assassin's Grid B
Una estrategia de negociación dinámica de la red - Estrategia de cruce de promedio móvil de varios marcos de tiempo
- Estrategia de los ladrillos de impulso
- Estrategia de negociación de inversión de ruptura de volatilidad
- Estrategia de negociación de patrones de velas
- Estrategia de negociación en pivote de supertendencia filtrada por ADX
- Estrategia de inversión de la media móvil de impulso
- Estrategia de negociación cruzada de promedio móvil de impulso
- Estrategia de sinergia de la tendencia de impulso
- Robot de negociación racional impulsado por la estrategia RSI
- La estrategia de detención del oscilador de momento dinámico
- Estrategia de negociación de Bugra basada en una media móvil cinética dual