Découvrez les avantages et les inconvénients des trois principales catégories d'algorithmes d'apprentissage automatique
Auteur:L'inventeur de la quantification - un petit rêve, Créé: 2017-10-30 12:01:59, Mis à jour: 2017-11-08 13:55:03Découvrez les avantages et les inconvénients des trois principales catégories d'algorithmes d'apprentissage automatique
Dans l'apprentissage automatique, les objectifs sont soit la prédiction, soit le regroupement. Cet article se concentre sur la prévision. La prévision est le processus de prévision de la valeur de la variable de sortie à partir d'un ensemble de variables d'entrée. Par exemple, en obtenant un ensemble de caractéristiques d'une maison, nous pouvons prédire son prix de vente. Nous avons divisé ces algorithmes en trois catégories: les modèles linéaires, les modèles à base d'arbres et les réseaux neuronaux, en mettant l'accent sur les six algorithmes les plus couramment utilisés:
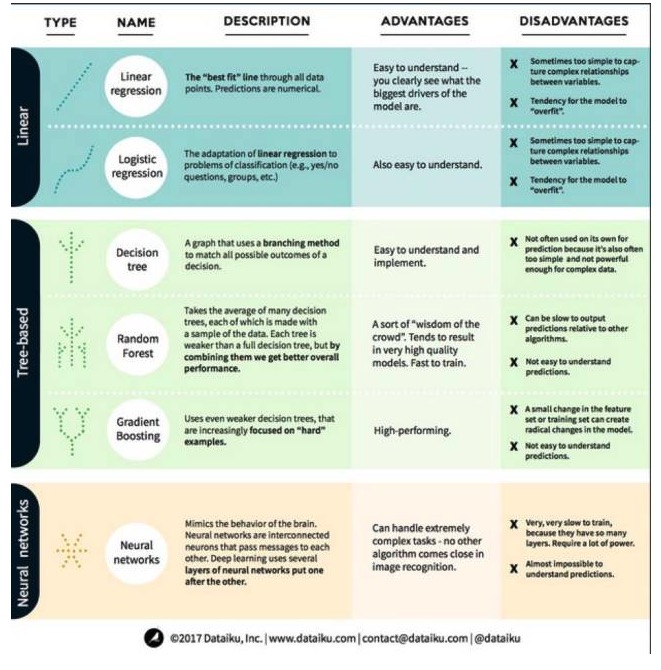
L'algorithme du modèle linéaire: le modèle linéaire utilise des formules simples pour trouver les lignes qui correspondent le mieux à un ensemble de points de données. Cette méthode, qui remonte à plus de 200 ans, est largement utilisée dans les domaines de la statistique et de l'apprentissage automatique. En raison de sa simplicité, elle est utile pour la statistique.
- ### ## 1. Régression linéaire
La régression linéaire, ou plus précisément la régression linéaire à deux facettes minimales, est la forme la plus standard du modèle linéaire. Pour les problèmes de régression, la régression linéaire est le modèle linéaire le plus simple. Son inconvénient est que le modèle est facilement sur-adapté, c'est-à-dire que le modèle s'adapte parfaitement aux données qui ont été formées au détriment de sa capacité à se propager à de nouvelles données.
Un autre inconvénient des modèles linéaires est que, comme ils sont très simples, ils ne prédisent pas facilement des comportements plus complexes lorsque les variables d'entrée ne sont pas indépendantes.
- ##### 2. La régression logique
La régression logique est l'adaptation de la régression linéaire aux problèmes de classification. Les inconvénients de la régression logique sont les mêmes que ceux de la régression linéaire. Les fonctions logiques sont très bonnes pour les problèmes de classification, car elles introduisent des effets de seuil.
Deuxièmement, l'algorithme du modèle d'arbre.
- ###############################################################################################################################################################################################################################################################
Un arbre de décision est une représentation de chaque résultat possible de la décision en utilisant la méthode de branche. Par exemple, si vous décidez d'acheter une salade, votre première décision sera probablement la variété de légumes crus, puis les légumes d'accompagnement, puis la variété de salade. Nous pouvons représenter tous les résultats possibles dans un arbre de décision.
Pour former un arbre de décision, nous avons besoin d'utiliser un ensemble de données de formation et de trouver l'attribut qui est le plus utile à l'objectif. Par exemple, dans le cas de la détection de la fraude, nous pouvons trouver que l'attribut qui a le plus d'impact sur la prévision du risque de fraude est le pays. Après avoir branché avec la première attribut, nous obtenons deux sous-ensembles, ce qui est le plus prévisible si nous ne connaissons que la première attribut.
- ##### 2 ## Les forêts aléatoires
Les forêts aléatoires sont l'équivalent de nombreux arbres de décision, où chaque arbre de décision est entraîné avec un échantillon de données aléatoires. Chaque arbre dans une forêt aléatoire est plus faible qu'un arbre de décision complet, mais en mettant tous les arbres ensemble, nous obtenons de meilleures performances globales grâce aux avantages de la diversité.
La forêt aléatoire est un algorithme très populaire dans l'apprentissage automatique aujourd'hui. La forêt aléatoire est facile à former et fonctionne plutôt bien. Son inconvénient est que la forêt aléatoire peut être lente à produire des prédictions par rapport à d'autres algorithmes, de sorte que la forêt aléatoire peut ne pas être choisie lorsque des prédictions rapides sont nécessaires.
- #### 3°, augmentation de la pente
Gradient Boosting, comme les forêts aléatoires, est composé d'arbres décisionnels à base de fraîcheur. La plus grande différence avec les forêts aléatoires est que les arbres sont entraînés un par un. Chaque arbre derrière est principalement entraîné par l'arbre devant lui pour identifier les données erronées.
La formation à l'élévation de gradient est également rapide et très performante. Cependant, les petites modifications apportées au jeu de données de formation peuvent modifier fondamentalement le modèle et, par conséquent, les résultats qu'il produit peuvent ne pas être les plus réalisables.
Troisièmement, les algorithmes de réseautage neural: le réseau neural est un phénomène biologique composé de neurones interconnectés dans le cerveau qui échangent des informations les uns avec les autres. Cette idée est maintenant appliquée au domaine de l'apprentissage automatique et est appelée ANN. L'apprentissage en profondeur est un réseau de neurones superposé.
Transférée de la plateforme du Big Data
- L'inventeur quantifie-t-il les transactions en bitcoins avec huobi et OKEX, ainsi que les transactions en USDT?
- Une fonction de retrait a été publiée, intégrée à la bibliothèque de transactions de crypto-monnaie.
- Comment calculer le potentiel financier maximal d'une stratégie en utilisant des données quantitatives de retour sur investissement, de fluctuation, etc.?
- Le démon de Shannon.
- Ce n'est pas la technologie qui est compliquée, c'est l'esprit humain!
- Bonjour, quelles sont vos recommandations concernant l'emplacement du serveur?
- Bitfinex est en train de fonctionner, merci de l'aider à analyser!
- S'il vous plaît, dites-moi sur quel point de temps les données obtenues lors de l'appel de l'API sont basées.
- Le code de la pièce est demandé.
- Pourquoi y a-t-il seulement quatre paires de transactions sur bitfinex: BCH_USD, BTC_USD, ETH_USD et LTC_USD?
- Une fois de plus, il y a eu une explosion de 5 000 dollars par pièce: faire plus de BTC, faire des contrats OKEX 1229 gratuits, un mois, 5 000 dollars par pièce!
- Le dernier mécanisme de surveillance
- Bug déposé: le bouton d'interaction sans paramètre par défaut lors de la création de la politique a échoué à être enregistré
- Le système de retouche ne peut-il pas sélectionner d'autres devises?
- S'il vous plaît traduire la page du plan d'achat
- Bitfinex a trois marchés, comment faire pour que les robots choisissent?
- L'option gagnant-gagnant sous la perspective dynamique
- Bitfinex contre-mesure et contre-monnaie ne sont pas compatibles
- Comment considérer l'efficacité de la déviation et de la fourchette en or?
- Bithumb a reçu des informations erronées sur son compte