La méthode de réflexion est plus importante que l'algorithme à haute fréquence
 1
2555
1
2555
La méthode de réflexion est plus importante que l’algorithme à haute fréquence
Ce qui a vraiment fait entrer le trading programmé dans l’attention du public, c’est l’événement qui a secoué le marché il y a deux ans, avec la hausse de plus de 5% en une minute, causée par une erreur de génération et d’exécution d’ordres dans le programme de trading haute fréquence de l’arbitrage ETF du courtier.
Depuis le coup d’état du 7⁄31 de la Bourse de Futures Financières de Chine, jusqu’à l’annonce par la Bourse de Shenzhen d’une série de mesures de restriction des transactions sur trois tranches de comptes, jusqu’à la récente modification de la transaction de la tranche T+0 en tranche T+1, les autorités de réglementation ont continué à surveiller les transactions procédurales.
Cet article a été écrit à la suite de l’article de l’utilisateur Wei Dong, qui a publié en août 2014 des informations sur les algorithmes les plus connus utilisés pour le trading d’amplification de fréquences.
Je ne suis pas d’accord avec l’idée que beaucoup de gens comprennent trop unilatéralement la chaîne de négociation quantifiée et l’assimilent essentiellement à un outil de création d’argent. La transaction est d’abord la transaction elle-même, avec sa propre signification économique, ignorer cela et la considérer simplement comme un jeu numérique pour ajouter de la valeur à l’argent, il est facile de se perdre.
Je ne pense pas non plus que les algorithmes eux-mêmes soient étranges, et que les meilleurs algorithmes soient morts, la vraie valeur centrale doit être la personne qui les maîtrise et les utilise. En fait, ce que je dis est également de l’information publique, mais même en connaissant les détails techniques, il n’y a pas beaucoup de gens qui peuvent vraiment bien le faire.
J’espère que cette réponse vous a aidé à avoir une meilleure compréhension de ce qu’est le trading quantitatif et à haute fréquence.
Tout d’abord, je pense que la plupart des gens pensent que les transactions à haute fréquence sont comme ceci:
Mais pour les transactions à haute fréquence, cette information est très grossière. Alors, pour ceux qui ne sont pas familiers avec le contexte, je vais vous expliquer ce qu’est un livre d’ordre.
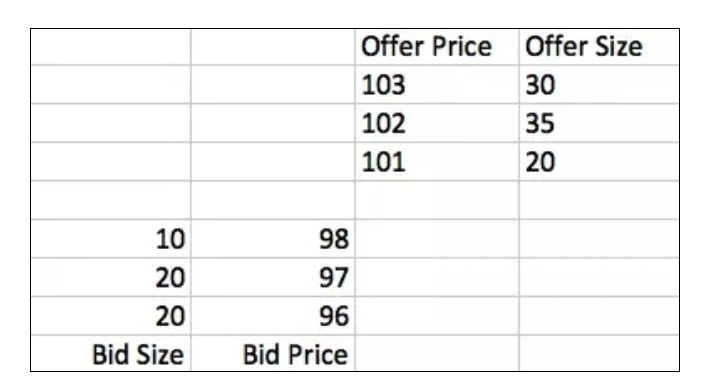
Le bid représente l’acheteur, l’Offer représente le vendeur, et cette feuille représente toutes les offres émises par les acheteurs et les vendeurs. Cette table est l’information la plus importante pour les transactions à haute fréquence. À tout moment, l’offre de l’acheteur est toujours inférieure à celle du vendeur.
Il y a deux situations, la première est que l’une ou l’autre des parties émet un ordre de marché, par exemple, un acheteur émet un ordre de marché de 10 et peut acheter 10 copies du vendeur au prix de 101. Après la réussite de cette transaction, le livre d’ordres devient comme ceci:
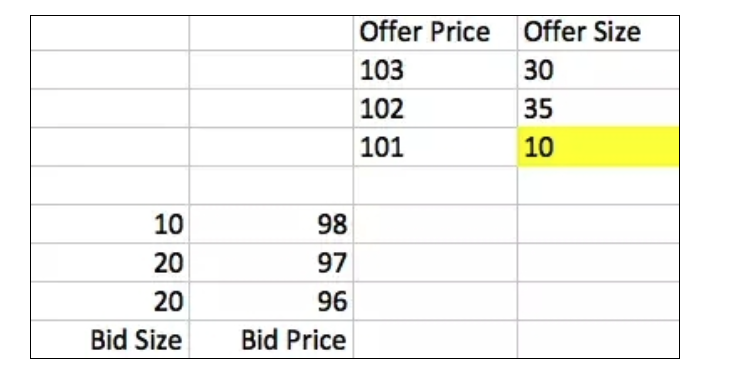
Deuxièmement, l’émission d’un bon de réduction au prix de la meilleure offre de l’autre partie produira le même résultat que dans le cas précédent.
Il est important de souligner que, bien que le véritable livre d’ordres n’existe qu’à l’intérieur de l’échange, et que toutes les transactions sont effectuées à l’intérieur de l’échange, l’échange transmet chaque offre et chaque prix de marché à tout le monde, de sorte que tous les acheteurs et les vendeurs peuvent eux-mêmes maintenir une structure de données identique, ce qui équivaut à un miroir du livre d’ordres de l’échange.
Pour vous aider à comprendre, j’ai utilisé une forme plus visuelle pour décrire le livre d’ordres:
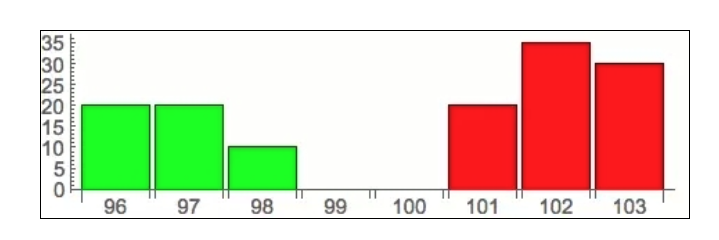
Le graphique correspondant au livre d’ordres au début de l’article devrait être clair: l’axe horizontal représente le prix, l’axe vertical le nombre de commandes, le vert l’acheteur et le rouge le vendeur. Cela a été fait pour introduire le sujet de cette discussion: les commandes de l’iceberg.
L’analyse fondamentale ci-dessus montre que les données de transaction dans les bourses sont complètement publiques, à tout moment sur le marché, qui veut acheter / vendre combien, tout le monde le sait, il n’y a pas de secret. Cela a un sens économique en soi, car seulement la démonstration de la demande d’achat et de vente attirera les commerçants potentiels à la négociation, donc un certain degré de publicité de sa propre demande sur le marché est nécessaire. Mais cela entraîne également une conséquence grave, une fois que quelqu’un veut acheter / vendre en grande quantité, le prix limite énorme qu’il émet sera directement visible à tous.
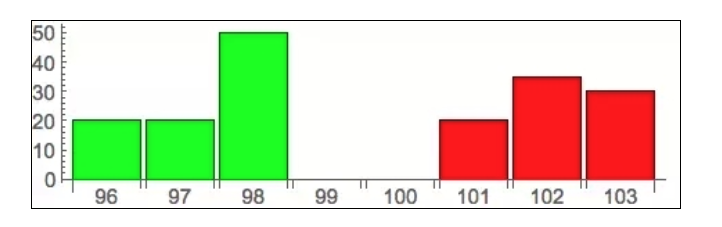
C’est très désavantageux pour lui, car tout le monde utilise cette information pour lui faire du mal. On juge qu’il y a beaucoup de pression sur le marché maintenant, donc il y a un grand nombre de personnes qui se précipitent pour faire de l’argent, et les prix montent rapidement, de sorte que ce que cette personne peut acheter au prix de 98 devient rapidement nécessaire pour acheter à un prix plus élevé. Pour résoudre ce problème, les bourses offrent un outil ciblé, appelé ordre d’iceberg. Les ordres peuvent être importants, mais seulement une petite partie est publiée, la plupart étant cachés, comme un véritable iceberg, invisible à tous, sauf à la bourse et à l’expéditeur lui-même.
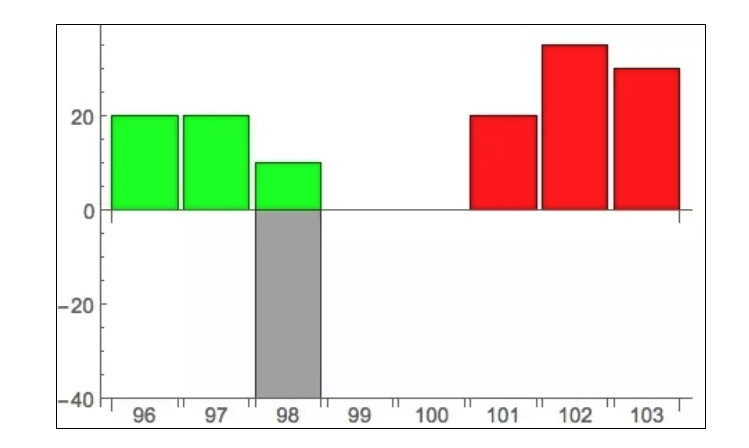
La zone grise est celle où les ordres d’iceberg sont cachés. De cette façon, les échanges n’avertissent les autres que lorsqu’une transaction correspondante est cachée, évitant ainsi que d’autres utilisent les informations affichées pour faire du Front running.
Il y a un avantage et un inconvénient à tout. Les ordres d’iceberg, bien que protégeant les intérêts des émetteurs, deviennent une règle injuste pour les autres acteurs du marché. Ceux qui ont un réel besoin de négocier peuvent perdre énormément en mal interprétant la situation.
Il y a d’abord un moyen le plus simple. Parfois, les ordres d’iceberg sont suspendus entre le prix d’achat optimal et le prix de vente optimal, comme ceci:
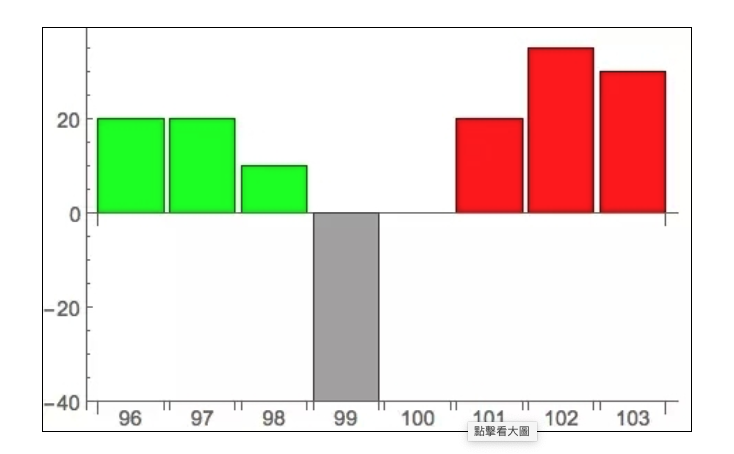
Dans ce cas, il existe une méthode de détection très simple, qui consiste à envoyer un ordre de limite de la plus petite quantité dans le spread, suivi de l’annulation de cet ordre. Dans cet exemple, par exemple, un ordre de limite de 99 est émis et ensuite annulé. Comme ce prix n’est pas lui-même lié à un prix d’achat évident (98), il n’y aurait pas de transaction sans l’existence d’un iceberg.
Pour faire face à ce type de perturbation, on n’attache généralement pas les ordres directement dans le spread. Au lieu de cela, on les attache avec les ordres limités normaux, comme avant, de sorte qu’après la transaction, il est difficile de deviner s’il s’agit d’un ordre limité normal ou d’un ordre d’iceberg.
Tout d’abord, il y a une pensée directe. L’existence d’un ordre d’iceberg reflète dans une certaine mesure le jugement d’un trader sur l’interprétation de la situation du marché qui a jugé nécessaire d’utiliser un ordre d’iceberg. Il est important de souligner que l’utilisation d’un ordre d’iceberg n’est pas sans coût, car vous masquez les besoins réels tout en dissimulant les attaquants potentiels.
Quel est le bon moment ? Il y a des données qui devraient être pertinentes, comme le spread des prix d’achat et de vente, le rapport entre le volume d’achat et le volume d’achat, etc. Sur ces données, vous pouvez faire une analyse de régression sur les données historiques et construire un modèle linéaire / non linéaire entre elles et les ordres d’iceberg. Ce modèle, formé par les données historiques, peut servir de détecteur d’ordres d’iceberg que vous pouvez utiliser pour négocier en temps réel.
Le modèle de base peut être défini comme: F{\displaystyle F}
Si vous voulez jouer à haute et profondeur, vous pouvez également faire des modèles avancés tels que HMM, SVM, réseaux neuronaux, etc., mais l’idée de base est la même: calculer la probabilité de l’existence d’un ordre d’iceberg par analyse de calcul.
Cette méthode, qui semble très avancée, a-t-elle réellement fonctionné ? Je pense que vous avez tous vu que cette modélisation n’est pas très précise. Comme un outil d’analyse de l’avenir pour indiquer dans quelles circonstances les ordres d’iceberg peuvent apparaître, c’est bien, mais comme un détecteur de transactions en temps réel, ce n’est pas très rassurant.
C’est pourquoi nous allons vous présenter une méthode qui a réellement séduit les joueurs à haute fréquence, dans cet article de Prediction of Hidden Liquidity in the Limit Order Book of GLOBEX Futures.
高频世界里,有一条永恒的建模准则值得铭记:先看数据再建模。如果你看了上面的介绍就开始天马行空的思考数学模型,那基本上是死路一条。我见过很多年轻人,
特别有热情,一上来就开始做数学定义,然后推导偏微分方程,数学公式写满一摞纸,最后一接触数据才发现模型根本行不通,这是非常遗憾的。
Il est probable qu’il trouvera que les règles de l’échange sont très intéressantes pour le traitement des ordres d’iceberg. Certaines bourses le font ainsi: une commande d’iceberg contient deux paramètres, V pour le nombre total d’ordres et p pour le nombre affiché publiquement. Par exemple, une iceberg avec V = 100 et p = 10, la quantité cachée est en fait 90.
Accomplissement de 10
La taille de l’offre la plus élevée du carnet de commandes -10
Nouvelle offre +10
Ces trois messages doivent apparaître en continu, et la différence de temps entre le troisième et le premier est très faible. La raison en est que, bien que les ordres d’iceberg aient des quantités cachées, chaque transaction ne peut avoir lieu que pour la quantité affichée (p), et une nouvelle quantité (p) est renouvelée à partir du reste de la quantité cachée une fois que p est épuisé. Ainsi, chaque personne qui reçoit des informations de la bourse peut toujours mettre à jour logiquement le livre d’ordres correctement, comme si les ordres d’iceberg n’existaient pas. Ainsi, une fois que cette règle est observée dans les données, nous pouvons déterminer avec une certaine certitude que des ordres d’iceberg existent sur le marché et que la valeur de p peut être déterminée! La question cruciale suivante est de savoir comment déterminer la valeur de V, c’est-à-dire combien de stocks restent de cet ordre d’iceberg. Cette question ne peut pas être résolue avec précision, car V et p sont déterminés par l’individu lui-même, et peuvent être des valeurs arbitraires. Mais on peut considérer deux points: premièrement, les deux valeurs sont des nombres entiers; deuxièmement, les humains ne sont pas des générateurs de nombres aléatoires parfaits, et les décisions suivent une certaine loi.
A partir de ces deux points, on peut construire un modèle de probabilité de V et de p, c’est-à-dire calculer la probabilité d’une combinaison de valeurs de ((V, p) donnée. Nous n’allons pas nous plonger dans l’analyse mathématique, les amis intéressés peuvent consulter le texte original.
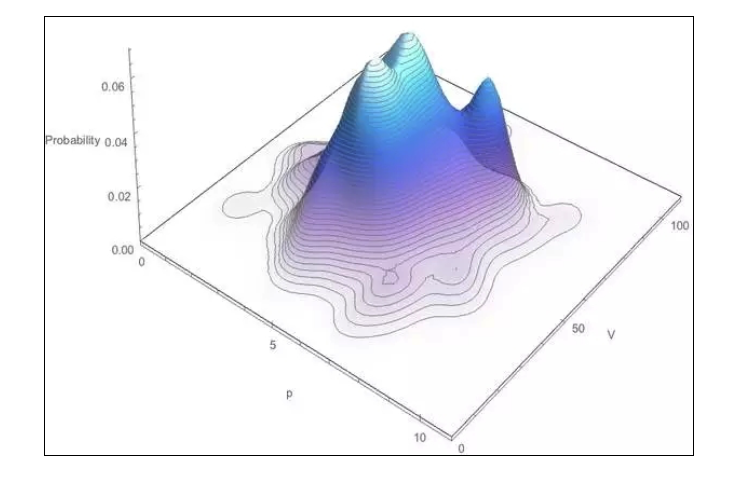
Ainsi, lorsque vous observez une valeur de p dans les données en temps réel, vous pouvez obtenir la fonction de densité de probabilité conditionnelle de la valeur de V correspondante, c’est-à-dire une coupe de la figure ci-dessus, par exemple (p = 8):
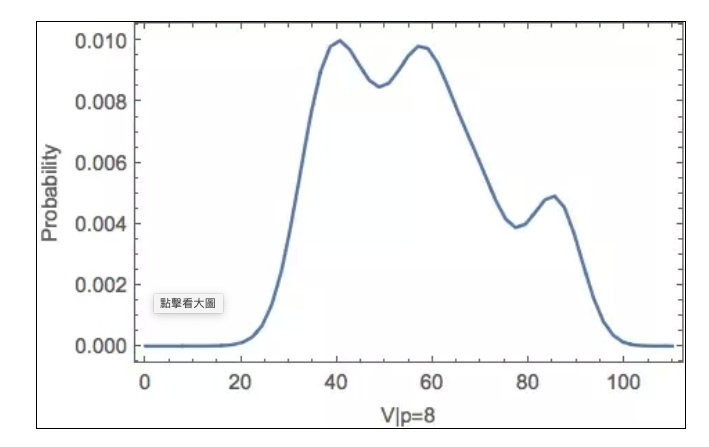
Ensuite, il est évident qu’il est facile de calculer la valeur la plus probable de V. Cette courbe fonctionnelle a également un rôle important pour vous aider à évaluer dynamiquement le stock restant, par exemple, lorsque vous observez que 5 copies de p ont déjà été consommées, vous pouvez déduire V> = 40 et, à partir du graphique ci-dessus, vous pouvez déduire une nouvelle valeur de V et un stock restant (V-5p).
En résumé, le cœur de l’algorithme consiste à déterminer l’existence d’un ordre d’iceberg en surveillant trois enregistrements connexes qui apparaissent de manière consécutive sur une courte période de temps dans des données en temps réel, tandis que la quantification de l’ordre d’iceberg est effectuée par un modèle de probabilité formé par des données historiques.
Je suis sûr que vous verrez aussi que ce n’est pas une machine à tricher. C’est juste une conjecture faite en utilisant des données publiques sur le marché. Et cette conjecture est basée uniquement sur la probabilité, et devrait davantage servir de référence. Cela a beaucoup de sens pour les fournisseurs de liquidité qui font des affaires sur le marché, ce qui leur permet d’éviter de subir des pertes en raison d’un mauvais jugement de la situation.
En fin de compte, l’algorithme ne s’adresse qu’à des échanges spécifiques. D’autres échanges peuvent ne pas utiliser la même méthode de traitement des ordres de montagne de glace. Ce qui est vraiment utile, c’est que cette approche de modélisation basée sur des données réelles ne vaut pas la peine d’utiliser des algorithmes spécifiques.
Ce petit algorithme vous montre le sommet de l’iceberg dans le domaine des transactions à haute fréquence. Il peut ne pas sembler très compliqué, mais je l’aime beaucoup. Parce qu’il montre clairement ce qu’on appelle d’abord la pensée, puis la quantification.
Si vous ne respectez pas ce principe, vous allez chercher des modèles avancés et vous vous attendez à ce qu’ils génèrent automatiquement des signaux de transaction, ce qui ne me paraît pas différent d’un rêve de fou. Malheureusement, ce rêve est trop tentant, et le monde ne manque jamais de lâches. Il faut le faire et l’apprécier.
Une photo de la scène de l’événement. Lien