Comparer les 8 algorithmes majeurs du machine learning
Auteur:L'inventeur de la quantification - un petit rêve, Créé: 2016-12-05 10:42:02, mis à jour:Comparer les 8 algorithmes majeurs du machine learning
L'article traite principalement des scénarios d'adaptation et des avantages et des inconvénients des algorithmes couramment utilisés.
Il y a tellement d'algorithmes d'apprentissage automatique, dans les domaines de la classification, de la régression, du regroupement, de la recommandation, de la reconnaissance d'images, etc. Il n'est pas facile de trouver un algorithme approprié, alors dans les applications pratiques, nous utilisons généralement l'apprentissage inspiré pour expérimenter.
En général, nous choisissons d'abord des algorithmes communs, tels que SVM, GBDT, Adaboost, et l'apprentissage en profondeur est en vogue aujourd'hui, et les réseaux neuraux sont également une bonne option.
Si vous vous souciez de l'exactitude, le meilleur moyen est de tester les algorithmes individuellement par la validation croisée, de les comparer, puis de modifier les paramètres pour s'assurer que chaque algorithme atteint l'optimisme, et de choisir le meilleur.
Mais si vous êtes simplement à la recherche d'un algorithme qui soit assez bon pour résoudre votre problème, ou si vous avez quelques astuces à utiliser, voici quelques astuces pour analyser les avantages et les inconvénients de chaque algorithme, en fonction des avantages et des inconvénients de l'algorithme.
- ## Les déviations et les inégalités Dans la statistique, un modèle est bon ou mauvais, et il est mesuré en fonction de la déviation et de l'écart, donc nous allons commencer par populariser la déviation et l'écart:
Déviation: décrite comme l'écart entre la valeur prévue (la valeur estimée) et la valeur réelle (la valeur réelle).
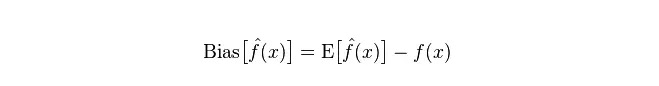
Divergence: décrit la portée de la variation de la valeur de prédiction P, la dissociation, est la différence de la valeur de prédiction, c'est-à-dire la distance de sa valeur attendue E. La plus grande différence de la différence, la plus grande dispersion de la distribution des données.
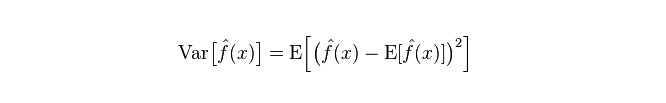
L'erreur réelle du modèle est la somme des deux, comme le montre le graphique suivant:
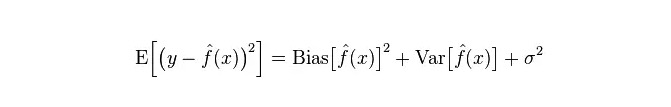
S'il s'agit d'un petit ensemble d'entraînement, un classificateur à forte déviation/déviation basse (par exemple, un simple Bayesian NB) a plus d'avantages que celui à faible déviation/déviation haute (par exemple, KNN) car le dernier est trop adapté.
Cependant, avec l'augmentation de votre train-set, la modélisation s'améliore sur les données initiales, et les écarts diminuent, ce qui rend les classificateurs à faible écarts/haut écarts progressivement plus performants (parce qu'ils ont une faible erreur d'approche), ce qui rend les classificateurs à haute écarts insuffisants pour fournir des modèles précis.
Bien sûr, vous pouvez également considérer que c'est une différence entre le modèle de génération (NB) et le modèle de détermination (KNN).
- ## Pourquoi dire que les simples Bayes sont des plus faibles?
Le contenu ci-dessous est à votre connaissance:
Tout d'abord, supposons que vous connaissiez la relation entre les ensembles d'entraînement et les ensembles de tests.
Mais bien souvent, nous ne pouvons que supposer que les ensembles de tests et les ensembles de formation correspondent à la même distribution de données, mais nous n'obtenons pas de données de test réelles. Pourquoi mesurer les taux d'erreur de test en ne voyant que le taux d'erreur de formation?
Étant donné que les échantillons de formation sont peu nombreux (ou au moins insuffisamment nombreux), le modèle obtenu par l'ensemble de formation n'est pas toujours vraiment correct. Même avec une précision de 100% sur l'ensemble de formation, cela ne signifie pas qu'il représente une vraie distribution de données.
De plus, dans la pratique, les échantillons de formation ont souvent une certaine erreur de bruit, de sorte que si l'on recherche trop la perfection sur le jeu de formation pour adopter un modèle très complexe, le modèle peut prendre toutes les erreurs dans le jeu de formation comme des caractéristiques de distribution de données réelles, ce qui donne une estimation erronée de la distribution de données.
Ainsi, il y a une grande confusion sur les vrais ensembles de tests (ce phénomène est appelé la conformité); mais on ne peut pas non plus utiliser un modèle trop simple, sinon le modèle ne sera pas suffisant pour décrire la distribution de données lorsque la distribution de données est plus complexe (ce phénomène se traduit par un taux d'erreur élevé même sur les ensembles de formation, ce qui est moins conforme).
L'hyperconformité indique que le modèle utilisé est plus complexe que la vraie distribution de données, tandis que l'hyperconformité indique que le modèle utilisé est plus simple que la vraie distribution de données.
Dans le cadre de l'apprentissage statistique, il y a un point de vue sur la complexité du modèle, qui est que l'erreur = Bias + Variance. L'erreur ici peut être comprise comme le taux d'erreur de prévision du modèle, qui est composé de deux parties, une partie est le biais causé par la modélisation trop simple et l'autre partie est l'espace de variation et l'incertitude causés par la modélisation trop complexe.
Ainsi, il est facile d'analyser une simple Bayesian. Sa simple hypothèse selon laquelle les données sont indépendantes est un modèle gravement simplifié. Ainsi, pour un modèle aussi simple, la plupart des cas de particules de biais sont plus grandes que les particules de variance, c'est-à-dire des particules de biais élevé et faible.
En pratique, pour que l'Error soit le plus petit possible, nous devons équilibrer les proportions de Bias et de Variance lors de la sélection du modèle, c'est-à-dire équilibrer les over-fitting et les under-fitting.
La relation entre les écarts et les différences et la complexité du modèle est plus claire à l'aide de la figure suivante:
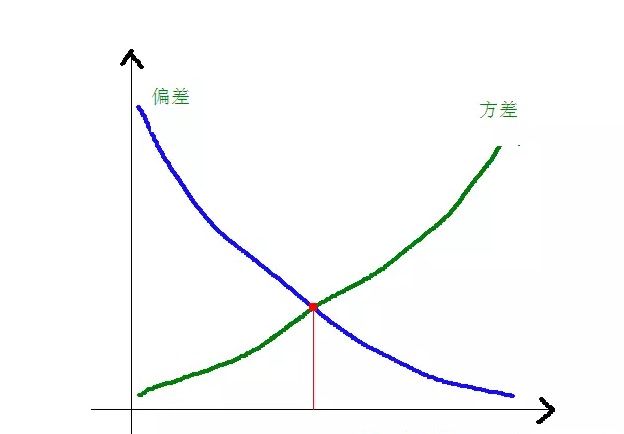
Au fur et à mesure que la complexité du modèle augmente, les écarts diminuent progressivement, tandis que les écarts augmentent progressivement.
-
Les avantages et les inconvénients des algorithmes courants
- ### 1. Le plus simple des Bayes
Les Bayes primitifs appartiennent aux modèles générés (sur les modèles générés et les modèles déterminés, principalement sur la question de savoir s'ils nécessitent une distribution commune), très simples, vous faites juste un tas de calculs.
Si l'hypothèse de l'indépendance conditionnelle (une condition plus stricte) est posée, le taux de convergence d'un classificateur Bayesian simple sera plus rapide que celui d'un modèle de détermination, comme la régression logique, de sorte que vous n'aurez besoin que de moins de données de formation. Même si l'hypothèse de l'indépendance conditionnelle de NB n'est pas posée, le classificateur NB continue de bien fonctionner dans la pratique.
Son principal inconvénient est qu'il ne peut pas apprendre l'interaction entre les caractéristiques, en utilisant l'expression R dans mRMR, c'est-à-dire la redondance des caractéristiques. Citant un exemple plus classique, par exemple, si vous aimez les films de Brad Pitt et Tom Cruise, il ne peut pas apprendre les films que vous n'aimez pas avec eux.
Les avantages:
Les modèles Bayesian primitifs sont issus de la théorie mathématique classique, avec une base mathématique solide et une efficacité de classification stable. Il est très performant pour les données de petite taille, il peut traiter des tâches multiclasses individuellement, et il est adapté à la formation en augmentation. L'algorithme est moins sensible aux données manquantes et plus simple, souvent utilisé pour classer le texte. Les défauts:
Il est nécessaire de calculer la probabilité antérieure. Le taux d'erreur dans les décisions de classification; Les données sont sensibles à la forme d'expression des données entrées.
- ### 2. La régression logique
Il existe de nombreuses méthodes pour normaliser les modèles (L0, L1, L2, etc.) et vous n'avez pas à vous soucier de savoir si vos caractéristiques sont liées, comme avec un Bayesian simple.
Vous obtenez également une bonne explication des probabilités par rapport aux arbres de décision et aux machines SVM, et vous pouvez même facilement utiliser de nouvelles données pour mettre à jour le modèle (en utilisant l'algorithme de dégradation en ligne, gradient descendant en ligne).
Si vous avez besoin d'une architecture de probabilité (par exemple, pour ajuster simplement les seuils de classification, indiquer l'incertitude ou obtenir des intervalles de confiance), ou si vous souhaitez intégrer plus de données de formation rapidement dans le modèle plus tard, utilisez-la.
La fonction sigmoïde:
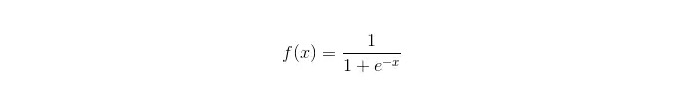
Les avantages: Il s'agit d'une solution simple et largement appliquée aux problèmes industriels. Le nombre de calculs est très faible, la vitesse est rapide et les ressources de stockage sont faibles. Les scores de probabilité d'un échantillon d'observation faciles; Pour la régression logique, la multilinéalité n'est pas un problème, elle peut être résolue avec la normalisation L2; Les défauts: Les performances de la régression logique ne sont pas très bonnes lorsque l'espace de caractéristiques est grand; Facile à mettre en place, généralement peu précis Ne peut pas gérer bien un grand nombre de caractéristiques ou de variables multiclasses; Il ne peut traiter que les deux problèmes de classification (le softmax dérivé sur cette base peut être utilisé pour plusieurs classes) et doit être linéairement divisible; Pour les caractéristiques non linéaires, une conversion est nécessaire.
- ### 3. Régression linéaire
La régression linéaire est utilisée pour la régression, contrairement à la régression logistique qui est utilisée pour la classification, et son idée de base est d'optimiser les fonctions d'erreur de forme minimale de multiplication par deux avec une dégradation de la gradiente.
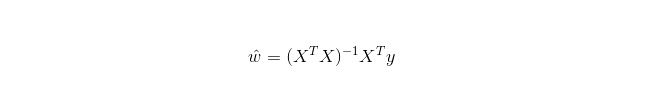
Dans LWLR (réduction linéaire par poids local), l'expression calculée pour les paramètres est:
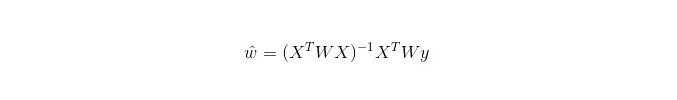
Ainsi, contrairement au LR, le LWLR est un modèle non paramétrique, car chaque fois qu'un calcul de régression est effectué, il est nécessaire de parcourir au moins une fois l'échantillon de formation.
Avantages: simple à mettre en œuvre, simple à calculer;
Les inconvénients: ne pas pouvoir s'adapter aux données non linéaires.
- ### 4. L'algorithme de voisinage le plus récent
Le KNN est l'algorithme le plus proche, dont les principaux processus sont:
1. 计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等); 2. 对上面所有的距离值进行排序; 3. 选前k个最小距离的样本; 4. 根据这k个样本的标签进行投票,得到最后的分类类别;Le choix d'une valeur K optimale dépend des données. En général, une valeur K supérieure lors de la classification réduit l'impact du bruit.
Une meilleure valeur de K peut être obtenue par diverses techniques d'inspiration, comme la vérification croisée. La présence de vecteurs de caractéristiques de bruit et de non-corrélation peut également réduire l'exactitude des algorithmes de proximité de K.
Les algorithmes proches ont des résultats de cohérence plus forts. Comme les données tendent à l'infinité, les algorithmes garantissent que le taux d'erreur ne dépasse pas deux fois celui des algorithmes bayésiens. Pour certaines bonnes valeurs de K, les algorithmes proches garantissent que le taux d'erreur ne dépasse pas celui de la théorie bayésienne.
Les avantages des algorithmes KNN
La théorie est mûre, l'idée est simple, elle peut être utilisée à la fois pour la classification et la régression. Peut être utilisé pour la classification non linéaire; La complexité du temps de formation est O ((n); Il n'y a pas d'hypothèses sur les données, la précision est élevée et il n'est pas sensible aux outliers. Les défauts
Le nombre de calculs est élevé. Problème de déséquilibre des échantillons (c'est-à-dire que certaines catégories ont beaucoup d'échantillons et d'autres ont peu); Il faut une grande quantité de mémoire.
- ### 5. Arbre de décision
Facile à expliquer. Il peut traiter les relations entre les caractéristiques sans stress et est non paramétrique, vous n'avez donc pas à vous soucier des valeurs exceptionnelles ou de la séparabilité linéaire des données (par exemple, un arbre de décision peut facilement traiter la catégorie A à l'extrémité d'une dimension x de la caractéristique, la catégorie B au milieu, puis la catégorie A apparaît à l'extrémité antérieure de la dimension x de la caractéristique).
L'un de ses inconvénients est qu'il ne prend pas en charge l'apprentissage en ligne, et que les arbres de décision doivent être entièrement reconstruits une fois que le nouveau modèle est arrivé.
L'autre inconvénient est la facilité de s'adapter, mais c'est aussi le point d'entrée pour des méthodes d'intégration telles que la forêt aléatoire RF (ou augmenter les arbres boostés).
De plus, les forêts aléatoires sont souvent les gagnants de nombreux problèmes de classification (généralement un peu mieux que les vecteurs supportés), elles s'entraînent rapidement et sont réglables, et vous n'avez pas à vous soucier de régler un tas de paramètres comme les vecteurs supportés, ce qui a été populaire dans le passé.
L'important dans un arbre de décision est de choisir une propriété à brancher, donc il est important de faire attention à la formule de calcul de l'augmentation de l'information et de la comprendre en profondeur.
La formule de calcul de la pile d'informations est la suivante:
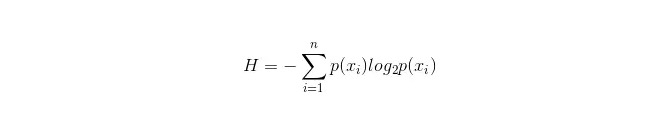
On peut calculer les probabilités p1 et p2 d'apparition de ces deux types d'échantillons dans l'échantillon global, respectivement, pour calculer le coffre d'information avant la branche des attributs non sélectionnés.
Une propriété xixi est maintenant sélectionnée pour brancher, et la règle de branchage est la suivante: si xi = vxi = v, brancher l'échantillon dans une branche de l'arbre; si elle n'est pas égale, dans une autre branche.
Il est évident que l'échantillon dans la branche comprend très probablement deux catégories, calculant respectivement les propriétés H1 et H2 de ces deux branches et calculant l'information totale H2 = p1 H1 + p2 H2 après la branche, alors l'information gagne ΔH = H - H
. En principe, en testant toutes les propriétés, on choisit l'attribut qui donne le plus d'avantages comme propriété de cette branche. Les avantages de l'arbre de décision
Les calculs sont simples, faciles à comprendre et explicatifs. les échantillons qui présentent des caractéristiques manquantes qui conviennent le mieux à un traitement; Il est possible de traiter des caractéristiques non pertinentes. Il est possible de produire des résultats viables et efficaces sur de grandes sources de données dans un temps relativement court. Les défauts
Les forêts accidentelles peuvent être considérablement réduites en cas de suradaptation. Le problème est qu'il n'y a pas de lien entre les données. Pour les données dont le nombre d'échantillons est incohérent dans les différentes catégories, les résultats de l'augmentation de l'information dans l'arbre de décision tendent à favoriser les caractéristiques qui ont plus de valeur numérique (ce défaut existe aussi si l'augmentation de l'information est utilisée, par exemple RF).
- ### 5.1 Adaptation
Adaboost est un modèle d'addition où chaque modèle est construit sur la base du taux d'erreur du modèle précédent, en se concentrant trop sur les échantillons qui ont été classés par erreur, et en se concentrant moins sur les échantillons correctement classés, ce qui permet d'obtenir un modèle relativement meilleur après plusieurs itérations.
Les avantages
Adaboost est un classificateur de haute précision. Il est possible de construire des sous-classificateurs par différentes méthodes, le cadre fourni par l'algorithme Adaboost. Les résultats calculés sont compréhensibles lorsqu'on utilise des classificateurs simples, et la construction des classificateurs faibles est extrêmement simple. C'est simple, sans filtrage de caractéristiques. Il n'est pas facile d'avoir des surajustements. Pour les algorithmes de combinaison tels que les forêts aléatoires et GBDT, voir cet article: Machine learning - synthèse des algorithmes de combinaison
Inconvénients: plus sensible aux outliers
- ### 6. Le SVM prend en charge les vecteurs
La haute précision offre de bonnes garanties théoriques pour éviter les surajustements, et même si les données ne sont pas linéairement indivisibles dans l'espace de caractéristiques d'origine, elles fonctionnent bien si elles sont données à une fonction nucléaire appropriée.
Il est particulièrement populaire dans les problèmes de classification de texte à très haute dimension. Malheureusement, la mémoire est très consommatrice et difficile à expliquer, l'exécution et le réglage sont également gênants, alors que le forêt aléatoire a évité ces inconvénients et est plus pratique.
Les avantages Il est possible de résoudre des problèmes à haute dimension, c'est-à-dire de grands espaces de caractéristiques. Il peut traiter les interactions de caractéristiques non linéaires. Il n'est pas nécessaire de se fier à l'ensemble des données. Il est possible d'améliorer les capacités de généralisation.
Les défauts L'efficacité n'est pas très élevée lorsque l'on observe beaucoup d'échantillons. Il n'existe pas de solution universelle aux problèmes non linéaires et il est parfois difficile de trouver une fonction nucléaire appropriée. Il est sensible aux données manquantes. Il est également judicieux de choisir le noyau (libsvm est livré avec quatre fonctions de noyau: noyau linéaire, noyau polynomial, noyau RBF et noyau sigmoïde):
Premièrement, si le nombre d'échantillons est inférieur au nombre de caractéristiques, il n'est pas nécessaire de choisir un noyau non linéaire, il suffit simplement d'utiliser un noyau linéaire.
Deuxièmement, si le nombre d'échantillons est supérieur au nombre de caractéristiques, il est possible d'utiliser un noyau non linéaire pour cartographier l'échantillon dans des dimensions plus élevées, ce qui donne généralement de meilleurs résultats.
Troisièmement, si le nombre d'échantillons et le nombre de caractéristiques sont égaux, le noyau non linéaire peut être utilisé, le principe étant le même que pour le second type.
Dans le premier cas, il est également possible de redimensionner les données avant d'utiliser un noyau non linéaire.
- ### 7. Les avantages et les inconvénients des réseaux de neurones artificiels
Les avantages des réseaux neuronaux artificiels: La classification est très précise. La capacité de traitement distribué parallèle, le stockage distribué et l'apprentissage sont puissants. Les neurones du bruit ont une robustesse et une tolérance d'erreur plus fortes, ce qui permet de s'approcher pleinement des relations non linéaires complexes. Il y a aussi une fonction de mémoire référentielle.
Les inconvénients des réseaux neuronaux artificiels: Les réseaux neuraux nécessitent un grand nombre de paramètres tels que la structure de la topologie du réseau, les poids et les valeurs initiales des seuils. L'incapacité d'observer le processus d'apprentissage entre les participants, la difficulté d'interpréter les résultats de sortie, qui peuvent affecter la crédibilité et l'acceptabilité des résultats; Il est possible que l'apprentissage dure trop longtemps et ne réponde pas à l'objectif.
- ### 8, K-Means est un groupe
J'ai déjà écrit un article sur le classement K-Means, et j'ai écrit un lien vers le blog: algorithme d'apprentissage automatique - classement K-means.
Les avantages L'algorithme est simple et facile à mettre en œuvre; Pour le traitement de grands ensembles de données, l'algorithme est relativement évolutif et efficace, car sa complexité est d'environ O ((nkt), où n est le nombre d'objets, k est le nombre de puces et t est le nombre d'itérations. L'algorithme essaie de trouver les divisions k qui permettent de réduire la valeur de la fonction d'erreur carrée. Les effets de classement sont meilleurs lorsque la couche est dense, sphérique ou conique et que la différence entre la couche et la couche est nette.
Les défauts Des exigences plus élevées en matière de type de données, adaptées aux données numériques; Il est possible de converger vers des minima locaux, mais il est plus lent pour les données à grande échelle. La valeur de K est difficile à choisir; Les valeurs de concentration sont sensibles aux valeurs initiales et peuvent entraîner des résultats de regroupement différents pour différentes valeurs initiales; Il n'est pas adapté à la découverte de boules de formes non coniques ou de boules de taille différente. Une petite quantité de ces données peut avoir une grande influence sur les moyennes.
Algorithme de sélection de référence
Dans un article qui a été traduit dans plusieurs langues étrangères, on a trouvé une simple astuce de sélection d'algorithmes:
La première chose à choisir est la régression logique, si elle ne fonctionne pas bien, on peut utiliser ses résultats comme référence et les comparer avec d'autres algorithmes.
Ensuite, essayez un arbre de décision (la forêt aléatoire) pour voir si vous pouvez améliorer considérablement les performances de votre modèle.
Si le nombre de caractéristiques et les échantillons observés sont particulièrement nombreux, l'utilisation de la SVM est une option lorsque les ressources et le temps sont suffisants (cette prémisse est importante).
En général:
GBDT>=SVM>=RF>=Adaboost>=Other... Eh bien, l'apprentissage en profondeur est très populaire, il est utilisé dans de nombreux domaines, il est basé sur des réseaux neuronaux, je suis moi-même en train d'apprendre, mais les connaissances théoriques ne sont pas très solides, la compréhension n'est pas assez profonde, je ne vais pas le faire ici. Les algorithmes sont importants, mais les bonnes données sont meilleures que les bonnes algorithmes, et la conception de bonnes fonctionnalités est très utile. Si vous avez un ensemble de données très volumineux, il n'y a probablement pas beaucoup d'impact sur les performances de classification, quel que soit l'algorithme que vous utilisez (à ce stade, vous pouvez choisir en fonction de la vitesse et de la facilité d'utilisation).
-
Les références
- Philosophie du trading dans les probabilités
- Où est-ce que vous devez entrer le mot de passe de votre fonds?
- BTCTRADE.com n'a pas été en mesure d'accéder à GetRecords
- Les prix des options sont très élevés, les options sont payantes et les options sont payantes.
- Analyse quantitative des stratégies de stockage
- L'apprentissage automatique amusant: le guide le plus simple
- Les lois sur le commerce de l'aluminium
- 7 algorithmes de tri couramment utilisés (communément utilisés)
- La stratégie de négociation à haute fréquence: le triangle de l'avantage
- 20 astuces pour développer une pensée créative
- Les investisseurs gagnants: le secret de la pensée contre-intuitive
- Un peu d'information sur les exigences de base des systèmes de négociation
- L'utilisation de l'indicateur ATR pour la magnitude réelle des fluctuations
- Y a-t-il une requête de code d'erreur robot?
- Les mathématiques de l'investissement sont intéressantes!
- Les mathématiques et le jeu (1)
- Réflexion sur le système homogène
- L'appareil qui contrôle la position de la formule de Kelly
- Une tendance à la négociation d'un vieil oiseau, des idées pour un système de négociation quantitative
- Pour des idées de stratégie de haute fréquence pour Bitcoin