Le manuel vous apprend à mettre à niveau la fonctionnalité de récupération des sources de données personnalisées pour le collecteur de transactions
Auteur:L'inventeur de la quantification - un petit rêve, Créé: 2020-05-07 17:43:54, Mis à jour: 2023-10-09 22:47:43
Le manuel vous apprend à mettre à niveau la fonctionnalité de récupération des sources de données personnalisées pour le collecteur de transactions
Article précédentLa main à la main vous apprend à réaliser un collecteur de transactionsEnsemble, nous avons mis en place un programme robotique de collecte de données de marché, et comment les utiliser ensuite? Bien sûr, pour le système de retracement, qui s'appuie sur la fonction de source de données personnalisée du système de retracement de la plate-forme de négociation quantifiée par l'inventeur, nous pouvons directement utiliser les données collectées comme source de données du système de retracement, de sorte que nous pouvons appliquer le système de retracement à n'importe quel marché sur lequel nous voulons retracer des données historiques.
Ainsi, nous pouvons mettre à niveau le collecteur de marché pour que celui-ci puisse également servir de source de données personnalisée au système de retouche.
Si vous en avez besoin, dépêchez-vous!
Prêt
La dernière fois, j'ai installé le programme hôte qui fonctionnait sur mon ordinateur MAC et j'ai lancé le service de base de données Mongodb. Cette fois, nous avons changé l'environnement d'exécution vers un VPS et nous avons utilisé le serveur Ali Cloud Linux pour exécuter notre programme.
-
base de données mongodb
Comme dans l'article précédent, il est nécessaire d'installer la base de données Mongodb sur un appareil exécutant le programme de collecte de données et d'ouvrir le service.
-
Installez Python 3 Le programme utilise le langage python3 et note que certaines bibliothèques sont utilisées, si ce n'est pas le cas, il faut les installer.
- le pymongo
- http
- - Je ne sais pas
-
Le gérant Il y a aussi des gens qui ont des problèmes avec la qualité de leurs produits, comme les fabricants, les fabricants, les fabricants, les fabricants, les fabricants, les fabricants, etc.
Il a été modifié pour être un "collecteur de données".
Le collecteur de donnéesRecordsCollecter (enseignement)Cette tactique. Nous allons y apporter quelques modifications: Avant que le programme n'entre dans le cycle de collecte de données, il utilise une bibliothèque de plusieurs threads pour exécuter simultanément un service de démarrage, qui est utilisé pour écouter les demandes de données du système de retouche de la plate-forme de trading quantifiée par l'inventeur. (D'autres modifications peuvent être ignorées)
RecordsCollector (mise à niveau pour une fonctionnalité de source de données personnalisée)
import _thread
import pymongo
import json
import math
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("自定义数据源服务接收到请求,self.path:", self.path, "query 参数:", dictParam)
# 目前回测系统只能从列表中选择交易所名称,在添加自定义数据源时,设置为币安,即:Binance
exName = exchange.GetName()
# 注意,period为底层K线周期
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# 连接数据库
Log("连接数据库服务,获取数据,数据库:", exName, "表:", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# 要求应答的数据
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
# 构造查询条件:大于某个值{'age': {'$gt': 20}} 小于某个值{'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("查询条件:", dbQuery, "查询条数:", exRecords.find(dbQuery).count(), "数据库总条数:", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# 需要根据请求参数round和vround,处理数据精度
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("数据:", data, "响应回测系统请求。")
# 写入数据应答
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("收集", exName, "交易所的K线数据,", "K线周期:", period, "秒")
# 连接数据库服务,服务地址 mongodb://127.0.0.1:27017 具体看服务器上安装的mongodb设置
Log("连接托管者所在设备mongodb服务,mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# 创建数据库
ex_DB = myDBClient[exName]
# 打印目前数据库表
collist = ex_DB.list_collection_names()
Log("mongodb ", exName, " collist:", collist)
# 检测是否删除表
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "删除:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "删除失败")
else :
Log(dropName, "删除成功")
# 开启一个线程,提供自定义数据源服务
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # 本机测试
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # VPS服务器上测试
Log("开启自定义数据源服务线程", "#FF0000")
except BaseException as e:
Log("启动自定义数据源服务失败!")
Log("错误信息:", e)
raise Exception("stop")
# 创建records表
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("开始收集", exName, "K线数据", "周期:", period, "打开(创建)数据库表:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# 首次写入所有BAR数据
for i in range(len(r) - 1):
bar = r[i]
# 逐根写入,需要判断当前数据库表中是否已经有该条数据,基于时间戳检测,如果有该条数据,则跳过,没有则写入
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# 写入bar到数据库表
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# 写入数据前检测,数据是否已经存在,基于时间戳检测
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# 增加画图展示
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
Le test
Configurer le robot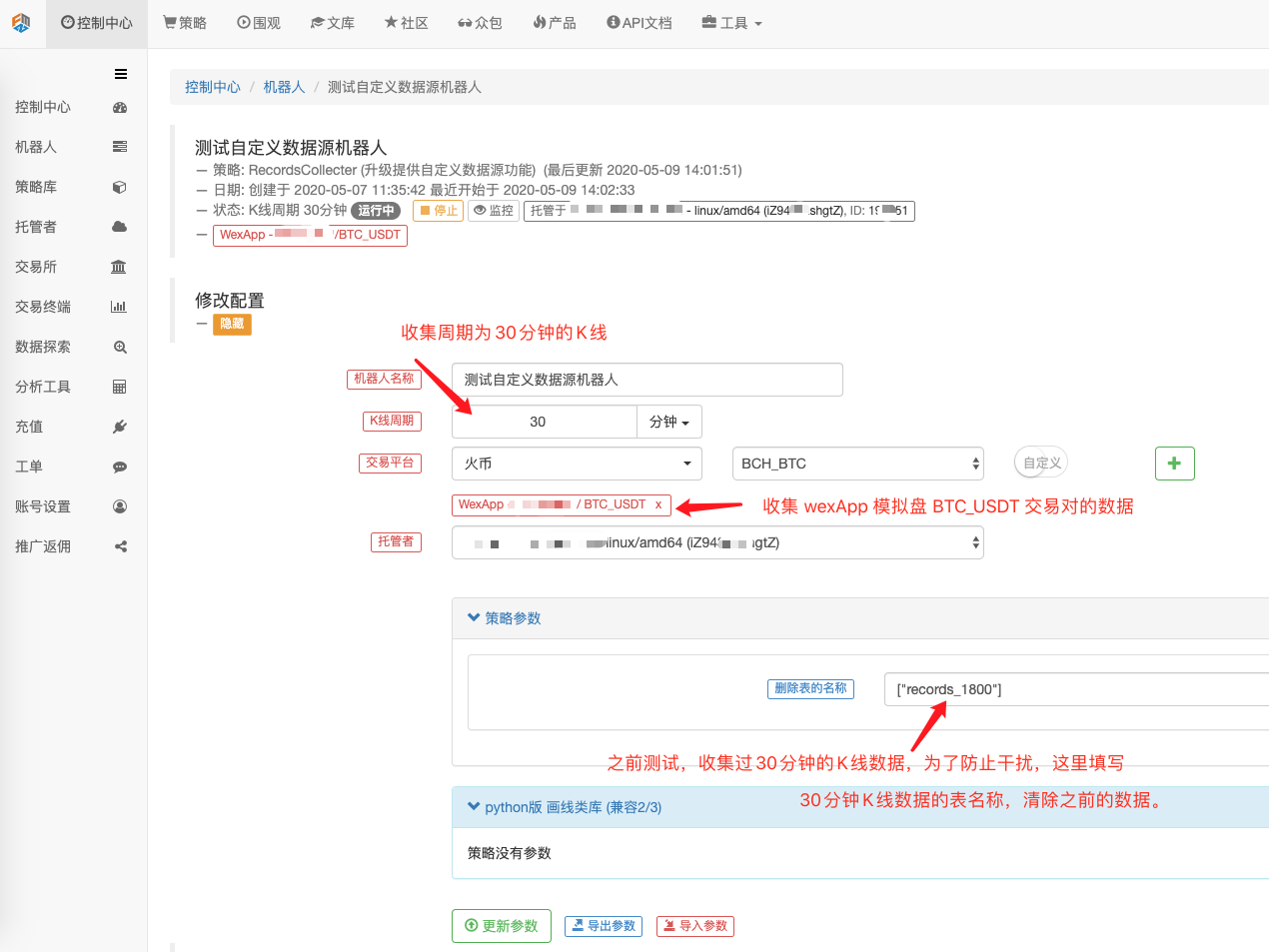
Il y a aussi des gens qui utilisent des robots, qui utilisent des collecteurs de données.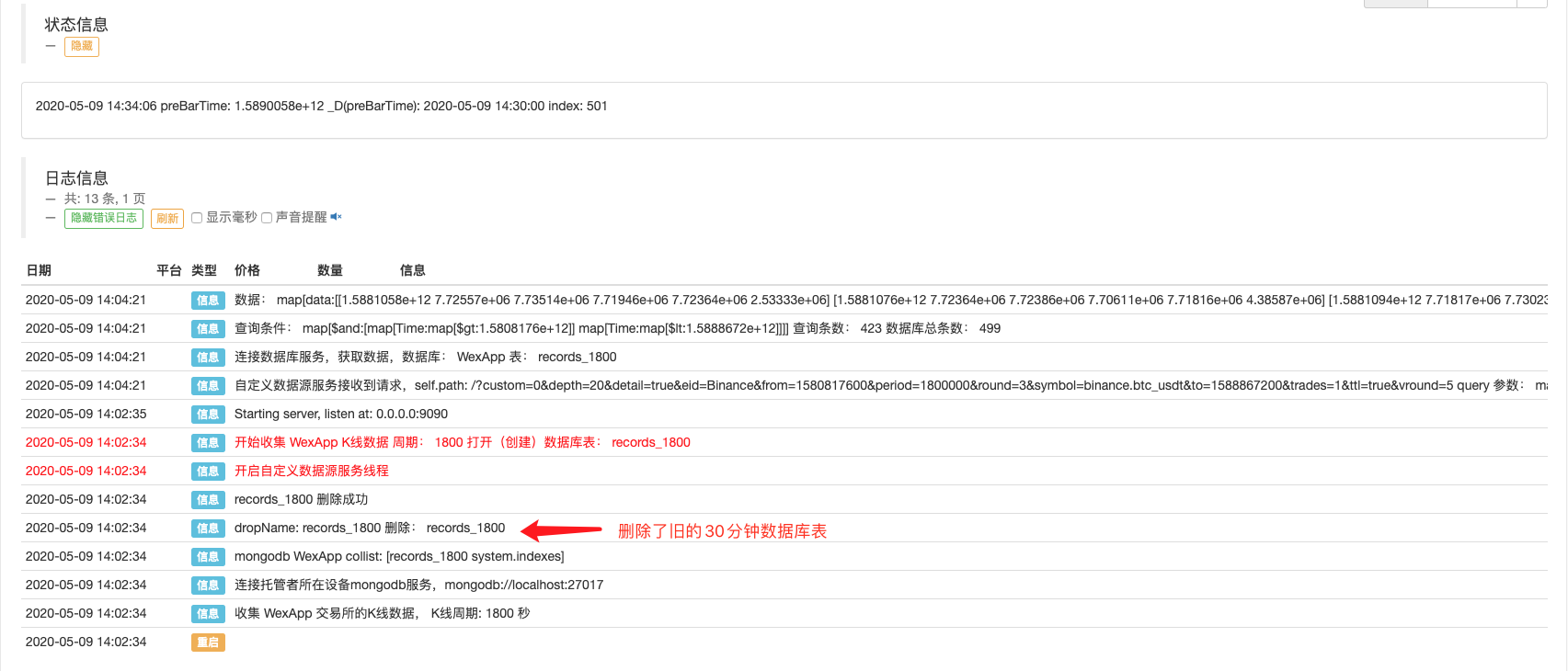
Si vous utilisez une stratégie de test, ouvrez une stratégie de test et réessayez, par exemple une stratégie de test comme celle-ci.
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords().length)
}
Configurer l'option de retouche, en définissant l'échange comme Binance, car la source de données personnalisée ne peut pas encore définir elle-même un nom d'échange, elle ne peut emprunter qu'une configuration d'échange dans la liste.
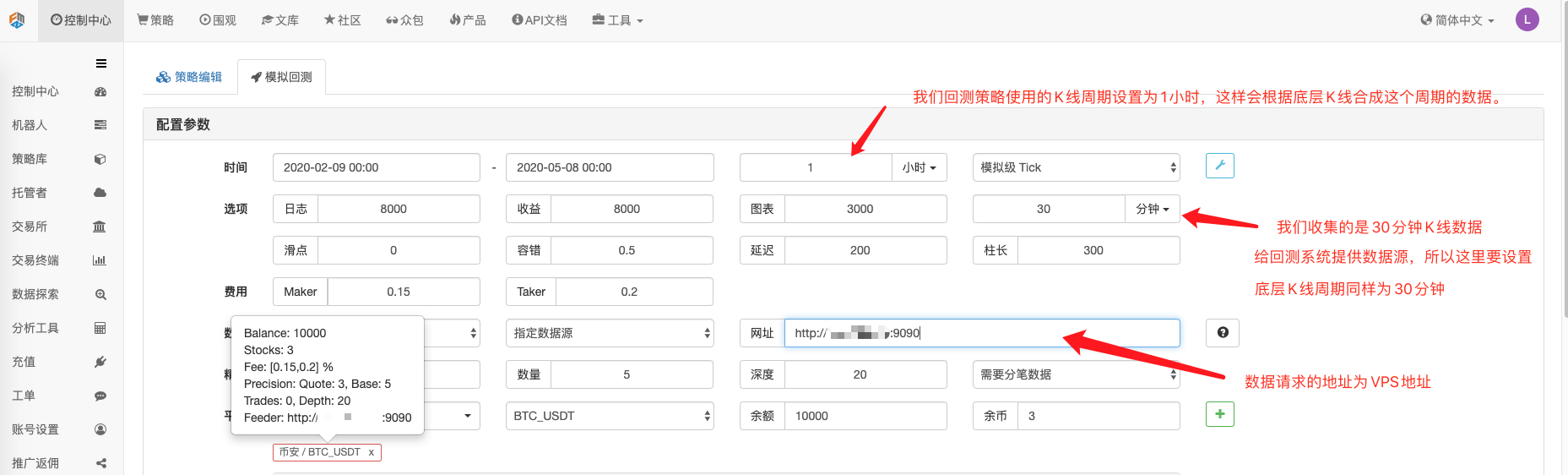
Si le graphique généré par le système de retouche de comparaison est identique au graphique de ligne K d'une heure sur une page d'échange wexApp, selon le recueillement de données personnalisées.
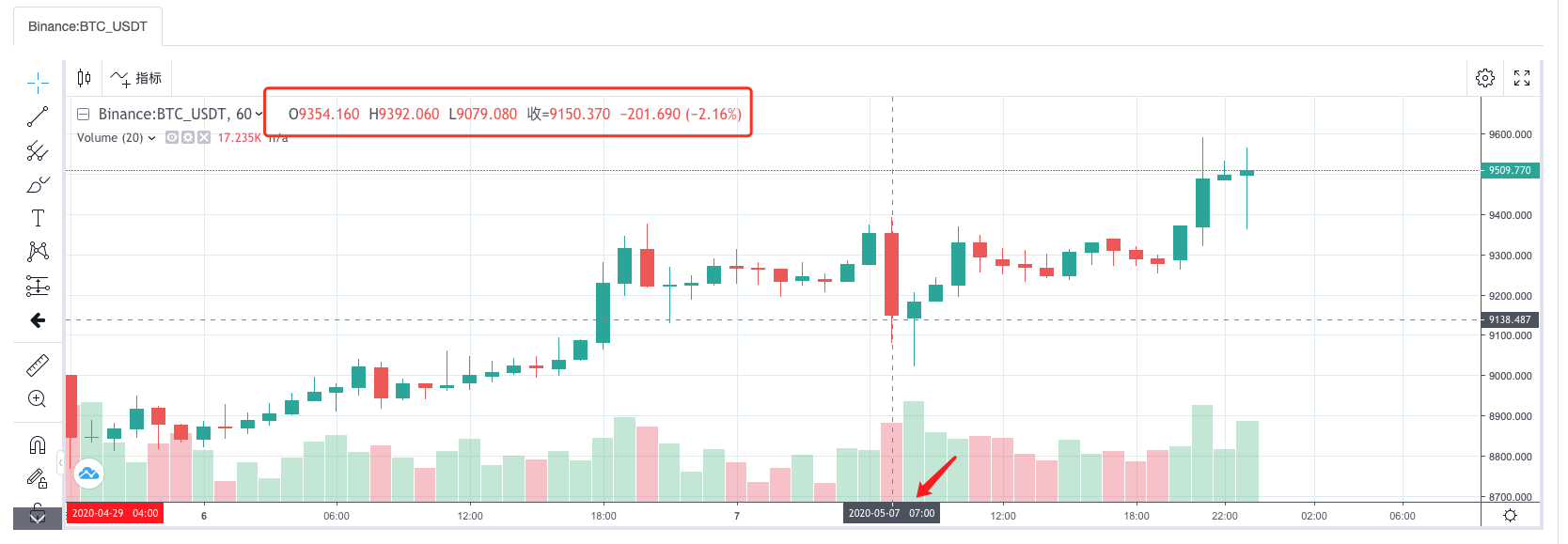
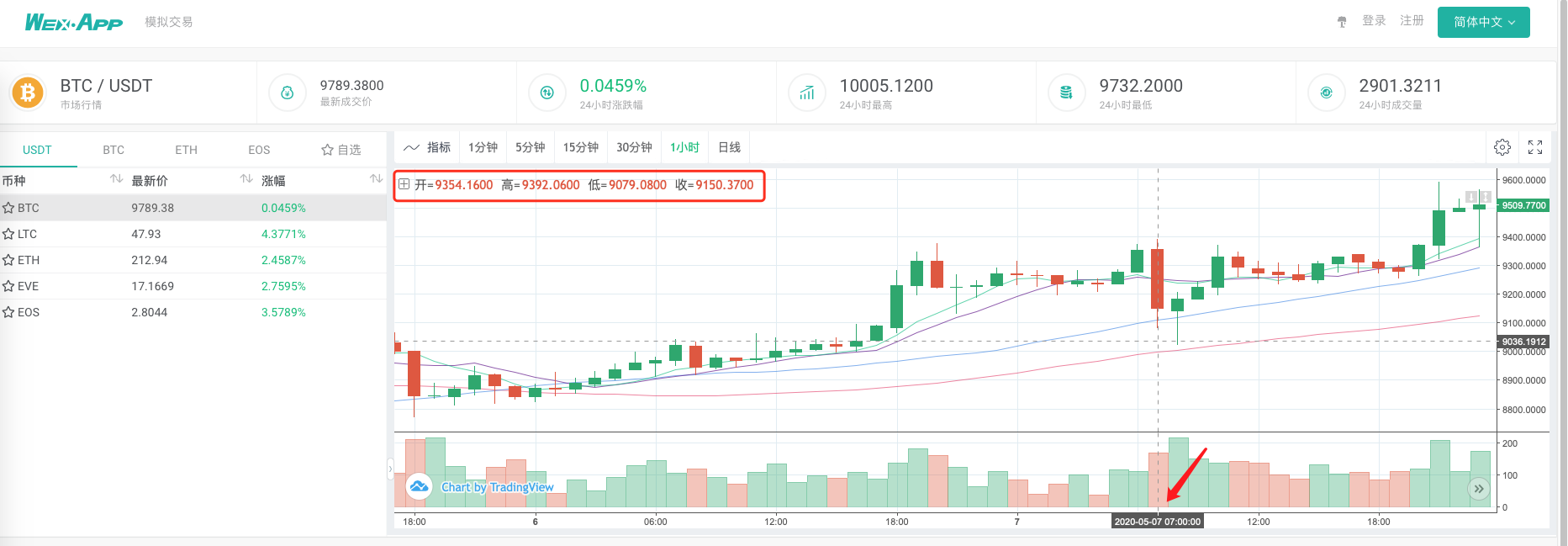
Cela permettrait aux robots sur le VPS de collecter eux-mêmes les données de la ligne K, et nous pourrions obtenir à tout moment les données collectées directement dans le système de retouche. En plus de cela, vous pouvez continuer à développer des fonctionnalités telles que la prise en charge des sources de données personnalisées au niveau du disque, la prise en charge de la collecte de données multivariées, de la collecte de données sur plusieurs marchés, etc.
Bienvenue dans les commentaires.
- Nouvelle fonctionnalité de FMZ Quant: Utilisez la fonction _Serve pour créer facilement des services HTTP
- Nouvelles fonctionnalités quantifiées par les inventeurs: créer facilement des services HTTP avec la fonction _Serve
- Guide d'accès au protocole personnalisé de la plateforme de trading quantique FMZ
- Stratégie d'acquisition et de suivi du taux de financement de la FMZ
- Stratégie d'acquisition et de surveillance des taux de financement FMZ
- Un modèle de stratégie vous permet d'utiliser WebSocket Market de manière transparente
- Un modèle de stratégie vous permet d'utiliser WebSocket sans heurts
- Guide d'accès au protocole général pour les plateformes de négociation quantitative pour les inventeurs
- Comment construire une stratégie de trading multi-monnaie universelle rapidement après la mise à niveau FMZ
- Comment construire rapidement une stratégie de trading monétaire universelle après la mise à niveau de FMZ
- Commerce de DCA: une stratégie quantitative largement utilisée
- Recherche sur la stratégie de couverture multi-monnaie des contrats à terme de Binance Partie 1
- Système de négociation de ligne de crocodile version Python
le wuzhentaoEt le service de source de données personnalisé n'a pas reçu la demande d'impression de ce journal.
le wuzhentaoQuand vous réessayez, sélectionnez les données personnalisées et commencez par les transactions par données que vous avez sélectionnées ci-dessous.
Le groupe ICS006Si vous collectez des données sur des paires de devises qui ne sont pas fournies ci-dessus, comment faire pour que les paires de devises de petites variétés, telles que DOT_USDT, ne puissent pas être personnalisées lors de la récupération?
ZltimLe sommet
Jamais plusSi vous choisissez une source de données personnalisée, est-ce qu'elle ne prend en charge qu'une seule paire de transactions?
L'inventeur de la quantification - un petit rêveIl est nécessaire d'exécuter sur le serveur le "collecteur de transactions" mentionné dans ce post.
le wuzhentaoSi vous avez des données personnalisées, les données ne sont pas affichées. Quel est le service que vous voulez?
L'inventeur de la quantification - un petit rêveAprès avoir utilisé la fonctionnalité de source de données personnalisée, vous devez également remplir l'adresse de service de la source de données personnalisée dans le bouton droit.
L'inventeur de la quantification - un petit rêveCe disque doit être exécuté sur un serveur doté d'une adresse IP externe pour permettre l'accès à la page du système de retouche.
L'inventeur de la quantification - un petit rêveVous n'avez pas encore compris ce que je veux dire, je veux dire que les données fournies par votre source de données personnalisée, par exemple, sont en fait EOS_USDT, mais sur FMZ, vous ne pouvez sélectionner que des paires de transactions telles que BTC_USDT, vous prenez ces données en fait EOS_USDT comme étant les données de BTC_USDT fournies par le système de contre-évaluation FMZ.
Le groupe ICS006Il y a un problème avec le fait que les gens ne comprennent pas ce qu'ils font, mais ils ne comprennent pas ce qu'ils font.
L'inventeur de la quantification - un petit rêveLe prix d'une transaction est le même que celui d'une transaction par nom, et le prix de la transaction par nom est le même que celui de la collecte de données.
L'inventeur de la quantification - un petit rêveLe programme de service peut écrire plusieurs transactions différentes sur les données fournies par la source de données, et le système de retouche appelle lui-même ce dont il a besoin.