Discussion sur la méthode de test de stratégie basée sur le générateur de tickers aléatoires
Auteur:FMZ~Lydia, Créé à partir de: 2024-12-02 11:26:13, Mis à jour à partir de: 2024-12-02 21:39:39
Préface
Le système de backtesting de la plateforme de trading FMZ Quant est un système de backtesting qui est constamment en itération, mise à jour et mise à niveau. Il ajoute des fonctions et optimise les performances progressivement à partir de la fonction de backtesting de base initiale. Avec le développement de la plateforme, le système de backtesting continuera d'être optimisé et mis à niveau. Aujourd'hui, nous discuterons d'un sujet basé sur le système de backtesting:
La demande
Dans le domaine du trading quantitatif, le développement et l'optimisation des stratégies ne peuvent pas être séparés de la vérification des données réelles du marché. Cependant, dans les applications réelles, en raison de l'environnement de marché complexe et changeant, s'appuyer sur les données historiques pour le backtesting peut être insuffisant, comme le manque de couverture des conditions extrêmes du marché ou des scénarios spéciaux. Par conséquent, concevoir un générateur de marché aléatoire efficace est devenu un outil efficace pour les développeurs de stratégies quantitatives.
Lorsque nous avons besoin de laisser la stratégie retracer les données historiques sur un certain échange ou monnaie, nous pouvons utiliser la source de données officielle de la plateforme FMZ pour le backtesting.
L'utilisation de données aléatoires est importante pour:
-
- Évaluer la robustesse des stratégies Le générateur de tickers aléatoires peut créer une variété de scénarios de marché possibles, y compris une volatilité extrême, une faible volatilité, des marchés tendance et des marchés volatils.
La stratégie peut-elle s'adapter à l'évolution de la tendance et de la volatilité? La stratégie entraînera-t-elle des pertes importantes dans des conditions de marché extrêmes?
-
- Identifier les faiblesses potentielles de la stratégie En simulant certaines situations de marché anormales (telles que des événements hypothétiques du cygne noir), les faiblesses potentielles de la stratégie peuvent être découvertes et améliorées.
La stratégie repose-t-elle trop sur une certaine structure de marché? Y a-t-il un risque de surajustement des paramètres?
-
- Optimisation des paramètres stratégiques Les données générées aléatoirement fournissent un environnement de test plus diversifié pour l'optimisation des paramètres de stratégie, sans avoir à vous fier entièrement aux données historiques.
-
- Compléter le vide dans les données historiques Dans certains marchés (tels que les marchés émergents ou les petits marchés de négociation de devises), les données historiques peuvent ne pas être suffisantes pour couvrir toutes les conditions possibles du marché.
-
- Développement itératif rapide L'utilisation de données aléatoires pour des tests rapides peut accélérer l'itération du développement de la stratégie sans compter sur les conditions du marché en temps réel ou le nettoyage et l'organisation des données qui prennent du temps.
Cependant, il est également nécessaire d'évaluer la stratégie de manière rationnelle.
-
- Bien que les générateurs de marché aléatoires soient utiles, leur importance dépend de la qualité des données générées et de la conception du scénario cible:
-
- La logique de génération doit être proche du marché réel: si le marché généré aléatoirement est complètement déconnecté de la réalité, les résultats des tests peuvent manquer de valeur de référence.
-
- Il ne peut pas remplacer complètement les tests de données réelles: les données aléatoires ne peuvent que compléter l'élaboration et l'optimisation des stratégies.
Cela dit, comment pouvons-nous "fabriquer" des données pour que le système de backtesting puisse les utiliser facilement, rapidement et facilement?
Idées de conception
Cet article est conçu pour fournir un point de départ pour la discussion et fournit un calcul de génération de ticker aléatoire relativement simple. En fait, il existe une variété d'algorithmes de simulation, de modèles de données et d'autres technologies qui peuvent être appliquées.
En combinant la fonction de source de données personnalisée du système de backtesting de la plateforme, nous avons écrit un programme en Python.
-
- Générer un ensemble de données de ligne K au hasard et les écrire dans un fichier CSV pour enregistrement persistant, de sorte que les données générées puissent être enregistrées.
-
- Ensuite, créez un service pour fournir un support de source de données pour le système de backtesting.
-
- Afficher les données générées de la ligne K dans le graphique.
Pour certaines normes de génération et stockage de fichiers de données de ligne K, les contrôles de paramètres suivants peuvent être définis:
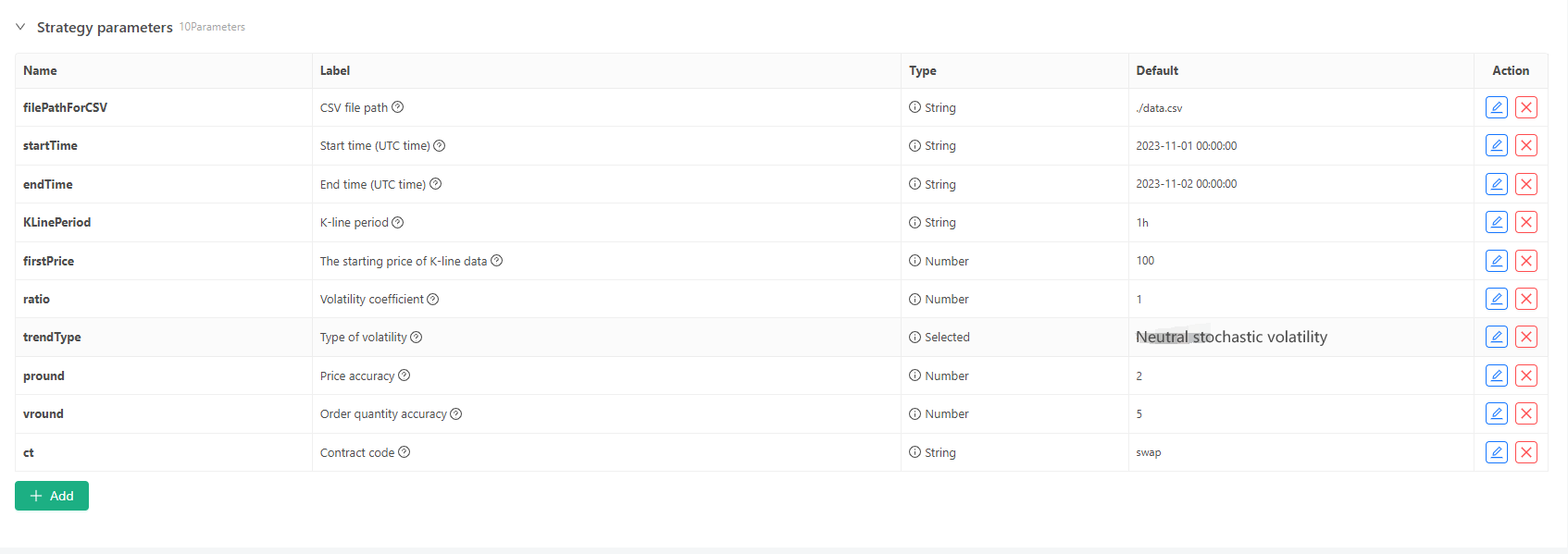
-
Mode de génération aléatoire de données Pour la simulation du type de fluctuation des données K-line, une conception simple est simplement faite en utilisant la probabilité des nombres aléatoires positifs et négatifs. Sur la base de cette conception simple, ajuster la gamme de génération de nombres aléatoires et certains coefficients dans le code peut affecter l'effet des données générées.
-
Vérification des données Les données générées sur la ligne K doivent également être testées pour déterminer leur rationalité, pour vérifier si les prix d'ouverture élevés et les prix de clôture bas violent la définition et pour vérifier la continuité des données sur la ligne K.
Générateur de tickers aléatoires du système de backtesting
import _thread
import json
import math
import csv
import random
import os
import datetime as dt
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
arrTrendType = ["down", "slow_up", "sharp_down", "sharp_up", "narrow_range", "wide_range", "neutral_random"]
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global filePathForCSV, pround, vround, ct
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("the custom data source service receives the request, self.path:", self.path, "query parameter:", dictParam)
eid = dictParam["eid"]
symbol = dictParam["symbol"]
arrCurrency = symbol.split(".")[0].split("_")
baseCurrency = arrCurrency[0]
quoteCurrency = arrCurrency[1]
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
priceRatio = math.pow(10, int(pround))
amountRatio = math.pow(10, int(vround))
data = {
"detail": {
"eid": eid,
"symbol": symbol,
"alias": symbol,
"baseCurrency": baseCurrency,
"quoteCurrency": quoteCurrency,
"marginCurrency": quoteCurrency,
"basePrecision": vround,
"quotePrecision": pround,
"minQty": 0.00001,
"maxQty": 9000,
"minNotional": 5,
"maxNotional": 9000000,
"priceTick": 10 ** -pround,
"volumeTick": 10 ** -vround,
"marginLevel": 10,
"contractType": ct
},
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is incorrect, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data.detail: ", data["detail"], "Respond to backtesting system requests.")
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
return
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
class KlineGenerator:
def __init__(self, start_time, end_time, interval):
self.start_time = dt.datetime.strptime(start_time, "%Y-%m-%d %H:%M:%S")
self.end_time = dt.datetime.strptime(end_time, "%Y-%m-%d %H:%M:%S")
self.interval = self._parse_interval(interval)
self.timestamps = self._generate_time_series()
def _parse_interval(self, interval):
unit = interval[-1]
value = int(interval[:-1])
if unit == "m":
return value * 60
elif unit == "h":
return value * 3600
elif unit == "d":
return value * 86400
else:
raise ValueError("Unsupported K-line period, please use 'm', 'h', or 'd'.")
def _generate_time_series(self):
timestamps = []
current_time = self.start_time
while current_time <= self.end_time:
timestamps.append(int(current_time.timestamp() * 1000))
current_time += dt.timedelta(seconds=self.interval)
return timestamps
def generate(self, initPrice, trend_type="neutral", volatility=1):
data = []
current_price = initPrice
angle = 0
for timestamp in self.timestamps:
angle_radians = math.radians(angle % 360)
cos_value = math.cos(angle_radians)
if trend_type == "down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "slow_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 0.5) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_down":
upFactor = random.uniform(0, 0.5)
change = random.uniform(-10, 0.5 * upFactor) * volatility * random.uniform(1, 3)
elif trend_type == "sharp_up":
downFactor = random.uniform(0, 0.5)
change = random.uniform(-0.5 * downFactor, 10) * volatility * random.uniform(1, 3)
elif trend_type == "narrow_range":
change = random.uniform(-0.2, 0.2) * volatility * random.uniform(1, 3)
elif trend_type == "wide_range":
change = random.uniform(-3, 3) * volatility * random.uniform(1, 3)
else:
change = random.uniform(-0.5, 0.5) * volatility * random.uniform(1, 3)
change = change + cos_value * random.uniform(-0.2, 0.2) * volatility
open_price = current_price
high_price = open_price + random.uniform(0, abs(change))
low_price = max(open_price - random.uniform(0, abs(change)), random.uniform(0, open_price))
close_price = open_price + change if open_price + change < high_price and open_price + change > low_price else random.uniform(low_price, high_price)
if (high_price >= open_price and open_price >= close_price and close_price >= low_price) or (high_price >= close_price and close_price >= open_price and open_price >= low_price):
pass
else:
Log("Abnormal data:", high_price, open_price, low_price, close_price, "#FF0000")
high_price = max(high_price, open_price, close_price)
low_price = min(low_price, open_price, close_price)
base_volume = random.uniform(1000, 5000)
volume = base_volume * (1 + abs(change) * 0.2)
kline = {
"Time": timestamp,
"Open": round(open_price, 2),
"High": round(high_price, 2),
"Low": round(low_price, 2),
"Close": round(close_price, 2),
"Volume": round(volume, 2),
}
data.append(kline)
current_price = close_price
angle += 1
return data
def save_to_csv(self, filename, data):
with open(filename, mode="w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["", "open", "high", "low", "close", "vol"])
for idx, kline in enumerate(data):
writer.writerow(
[kline["Time"], kline["Open"], kline["High"], kline["Low"], kline["Close"], kline["Volume"]]
)
Log("Current path:", os.getcwd())
with open("data.csv", "r") as file:
lines = file.readlines()
if len(lines) > 1:
Log("The file was written successfully. The following is part of the file content:")
Log("".join(lines[:5]))
else:
Log("Failed to write the file, the file is empty!")
def main():
Chart({})
LogReset(1)
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), ))
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), ))
Log("Start the custom data source service thread, and the data is provided by the CSV file.", ", Address/Port: 0.0.0.0:9090", "#FF0000")
except BaseException as e:
Log("Failed to start custom data source service!")
Log("error message:", e)
raise Exception("stop")
while True:
cmd = GetCommand()
if cmd:
if cmd == "createRecords":
Log("Generator parameters:", "Start time:", startTime, "End time:", endTime, "K-line period:", KLinePeriod, "Initial price:", firstPrice, "Type of volatility:", arrTrendType[trendType], "Volatility coefficient:", ratio)
generator = KlineGenerator(
start_time=startTime,
end_time=endTime,
interval=KLinePeriod,
)
kline_data = generator.generate(firstPrice, trend_type=arrTrendType[trendType], volatility=ratio)
generator.save_to_csv("data.csv", kline_data)
ext.PlotRecords(kline_data, "%s_%s" % ("records", KLinePeriod))
LogStatus(_D())
Sleep(2000)
Pratique dans le système de backtesting
- Créez l'instance de stratégie ci-dessus, configurez les paramètres et exécutez-la.
- Le trading en direct (instance de stratégie) doit être exécuté sur le docker déployé sur le serveur, il a besoin d'une adresse IP de réseau publique, afin que le système de backtesting puisse y accéder et obtenir des données.
- Cliquez sur le bouton d'interaction, et la stratégie commencera à générer automatiquement des données aléatoires.
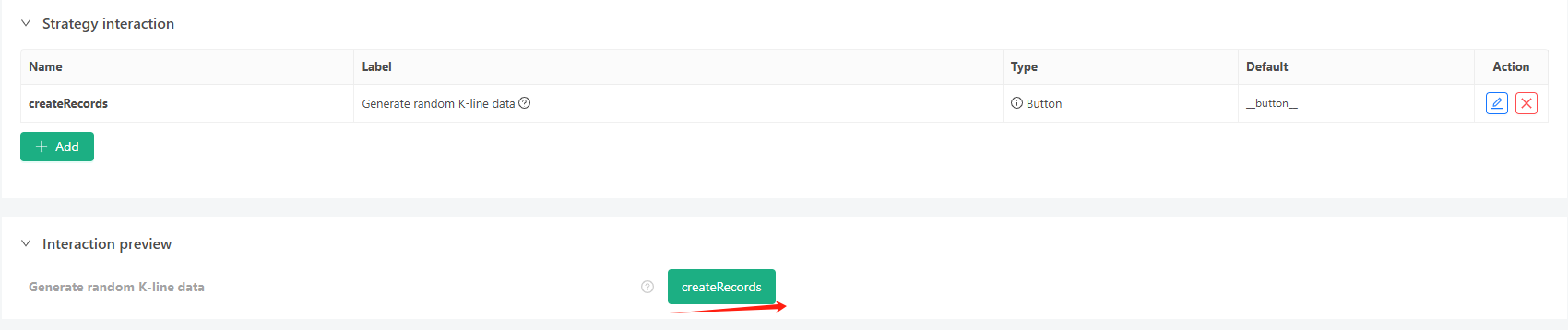
- Les données générées seront affichées sur le graphique pour une observation facile, et les données seront enregistrées dans le fichier local data.csv.
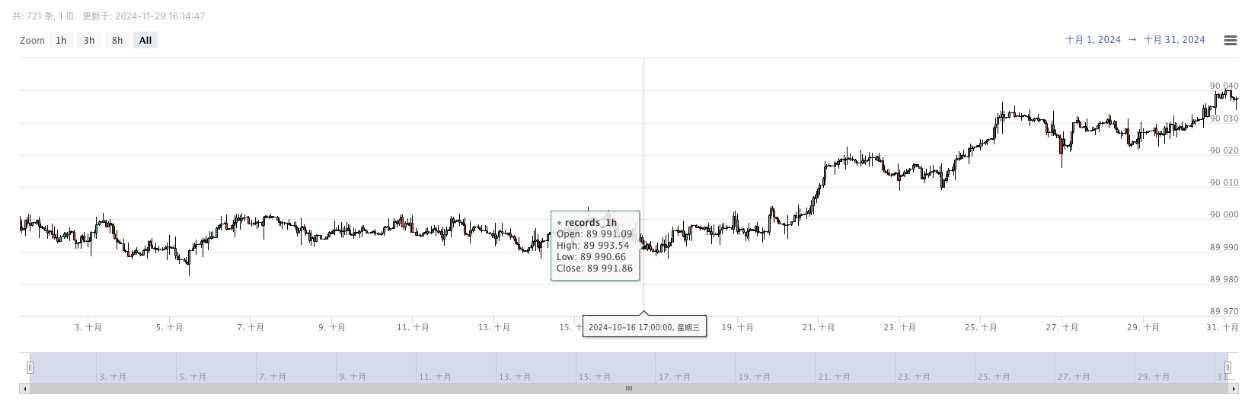
- Maintenant, nous pouvons utiliser ces données générées aléatoirement et utiliser n'importe quelle stratégie pour le backtesting:

/*backtest
start: 2024-10-01 08:00:00
end: 2024-10-31 08:55:00
period: 1h
basePeriod: 1h
exchanges: [{"eid":"Futures_Binance","currency":"BTC_USDT","feeder":"http://xxx.xxx.xxx.xxx:9090"}]
args: [["ContractType","quarter",358374]]
*/
Conformément aux informations ci-dessus, configurer et régler.http://xxx.xxx.xxx.xxx:9090est l'adresse IP du serveur et le port ouvert de la stratégie de génération de ticker aléatoire.
Il s'agit de la source de données personnalisée, qui peut être trouvée dans la section Source de données personnalisée du document API de la plateforme.
- Une fois que le système de backtest a configuré la source de données, nous pouvons tester les données aléatoires du marché:
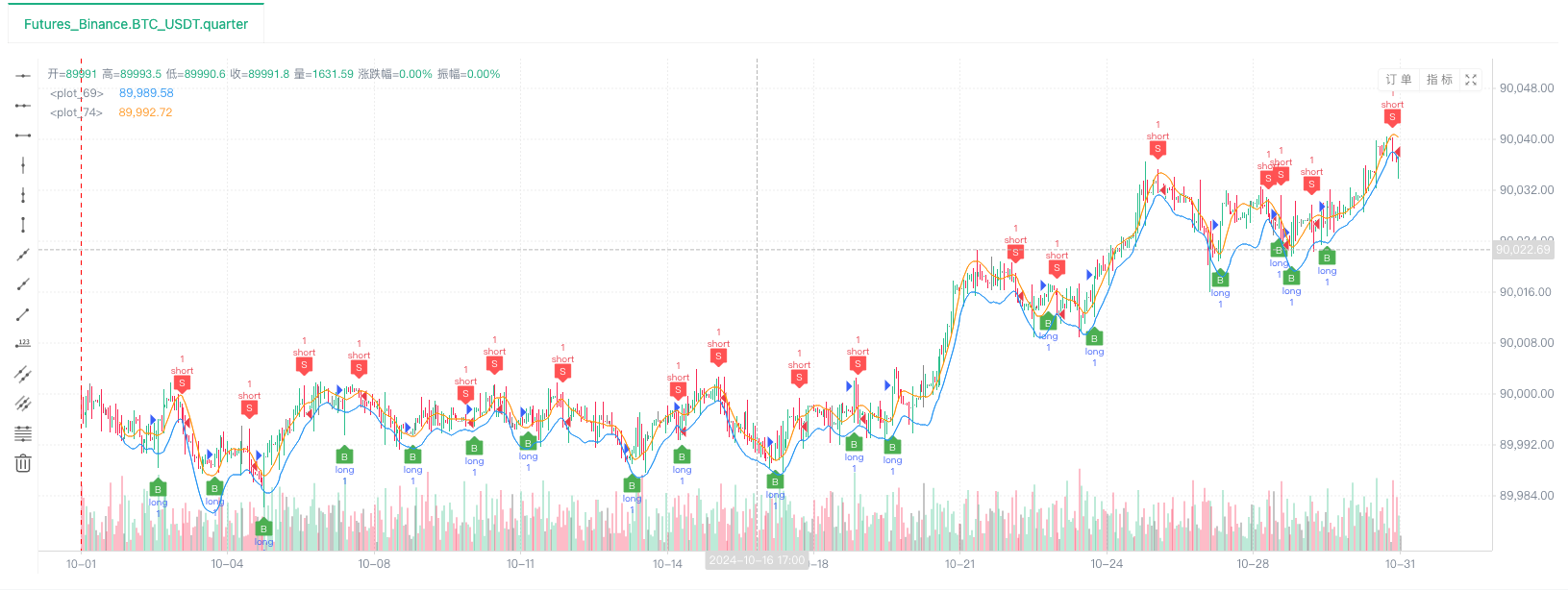
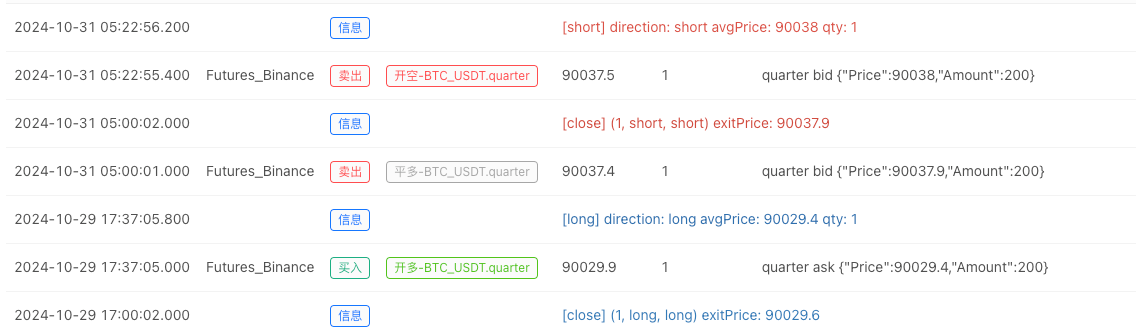
À ce moment-là, le système de backtest est testé avec nos données simulées
- Oh, oui, j'ai presque oublié de le mentionner! La raison pour laquelle ce programme Python de générateur de ticker aléatoire crée un trading en direct est de faciliter la démonstration, l'opération et l'affichage des données de ligne K générées. Dans l'application réelle, vous pouvez écrire un script Python indépendant, vous n'avez donc pas à exécuter le trading en direct.
Le code source de la stratégie:Générateur de tickers aléatoires du système de backtesting
Merci pour votre soutien et votre lecture.
- Pratiques de quantification de l'échange DEX ((1) -- dYdX v4 Guide d'utilisation
- Introduction à la suite de Lead-Lag dans les monnaies numériques (3)
- Introduction à l'arbitrage au retard de plomb dans les crypto-monnaies (2)
- Introduction à la suite de Lead-Lag dans les monnaies numériques (2)
- Discussion sur la réception de signaux externes de la plateforme FMZ: une solution complète pour la réception de signaux avec un service Http intégré dans la stratégie
- Exploration de la réception de signaux externes sur la plateforme FMZ: stratégie intégrée pour la réception de signaux sur le service HTTP
- Introduction à l'arbitrage au retard de plomb dans les crypto-monnaies (1)
- Introduction à la suite de Lead-Lag dans les monnaies numériques (1)
- Discussion sur la réception de signaux externes de la plateforme FMZ: API étendue VS stratégie intégrée au service HTTP
- Débat sur la réception de signaux externes sur la plateforme FMZ: API étendue contre stratégie de service HTTP intégré
- Une méthode de test stratégique basée sur un générateur de marché aléatoire
- Nouvelle fonctionnalité de FMZ Quant: Utilisez la fonction _Serve pour créer facilement des services HTTP
- Nouvelles fonctionnalités quantifiées par les inventeurs: créer facilement des services HTTP avec la fonction _Serve
- Guide d'accès au protocole personnalisé de la plateforme de trading quantique FMZ
- Stratégie d'acquisition et de suivi du taux de financement de la FMZ
- Stratégie d'acquisition et de surveillance des taux de financement FMZ
- Un modèle de stratégie vous permet d'utiliser WebSocket Market de manière transparente
- Un modèle de stratégie vous permet d'utiliser WebSocket sans heurts
- Guide d'accès au protocole général pour les plateformes de négociation quantitative pour les inventeurs
- Comment construire une stratégie de trading multi-monnaie universelle rapidement après la mise à niveau FMZ