Créer un robot de trading Bitcoin qui ne perd pas d'argent
Auteur:La bonté, Créé: 2019-06-27 10:58:40, Mis à jour: 2024-12-24 20:16:45
Nous allons utiliser l'apprentissage renforcé de l'IA pour créer un robot de trading de devises numériques.
Dans cet article, nous allons créer et appliquer un algorithme d'apprentissage renforcé pour apprendre à fabriquer un robot de trading Bitcoin. Dans ce tutoriel, nous allons utiliser le gym d'OpenAI et le robot PPO de la base de données stable-baselines, une branche de la base de données OpenAI.
Merci beaucoup à OpenAI et DeepMind pour le logiciel open source qu'ils ont fourni aux chercheurs en apprentissage profond au cours des dernières années. Si vous n'avez pas encore vu leurs réalisations incroyables avec des technologies comme AlphaGo, OpenAI Five et AlphaStar, vous avez peut-être vécu l'année dernière en dehors de l'isolement, mais vous devriez les voir.
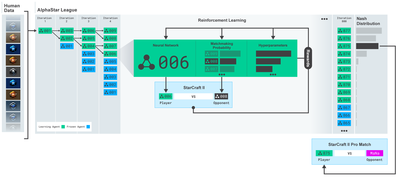
La formation AlphaStarhttps://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
Bien que nous n'ayons pas créé quelque chose d'impressionnant, il n'est pas toujours facile de faire des transactions quotidiennes avec un robot Bitcoin.
Ce que l'on obtient trop facilement n'a aucune valeur.
Nous devons donc apprendre non seulement à négocier nous-mêmes... mais aussi à faire négocier les robots pour nous.
Le projet

1.为我们的机器人创建gym环境以供其进行机器学习
2.渲染一个简单而优雅的可视化环境
3.训练我们的机器人,使其学习一个可获利的交易策略
Si vous n'êtes pas encore familiarisé avec la création d'environnements de gym à partir de zéro, ou avec la visualisation simple de ces environnements. Avant de continuer, n'hésitez pas à googler un article comme celui-ci. Ces deux actions ne seront pas difficiles même pour un programmeur débutant.
À l'entrée
在本教程中,我们将使用Zielak生成的Kaggle数据集。如果您想下载源代码,我的Github仓库中会提供,同时也有.csv数据文件。好的,让我们开始吧。
Tout d'abord, nous allons importer toutes les bibliothèques nécessaires. Assurez-vous d'installer avec pip toutes les bibliothèques que vous manquez.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
Ensuite, créons notre classe pour l'environnement. Nous devons transmettre un nombre de couches de données de pandas, ainsi qu'un initial_balance optionnel et un lookback_window_size, qui indiqueront le nombre de pas de temps observés par le robot à chaque étape. Nous définissons la commission de chaque transaction par défaut comme 0.075%, soit le taux de change actuel de Bitmex, et nous définissons les paramètres de la chaîne comme faux par défaut, ce qui signifie que notre nombre de couches de données par défaut sera parcouru par un épisode aléatoire.
Nous appelons également les données dropna (() et reset_index ((), en supprimant d'abord les lignes avec la valeur NaN, puis en réinstallant l'index avec le nombre de coups, car nous avons supprimé les données.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
Notre action_space est ici représenté par un groupe de 3 options (acheter, vendre ou détenir) et un autre groupe de 10 montants (un sur dix).2⁄10Pour les actions de vente, nous avons choisi de vendre le montant de la valeur de BTC. Bien sûr, les actions de détention ignorent le montant et ne font rien.
Notre observation_space est défini comme un ensemble de points flottants continus entre 0 et 1 de la forme de ((10, lookback_window_size + 1)); + 1 est utilisé pour calculer la longueur du temps actuel. Pour chaque longueur de temps dans la fenêtre, nous allons observer une valeur OHCLV. Notre valeur nette est égale au nombre de BTC achetés ou vendus et au total des dollars que nous avons dépensés ou reçus sur ces BTC.
Ensuite, nous avons besoin d'écrire une méthode de réinitialisation pour initialement l'environnement.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
Ici, nous utilisons self._reset_session et self._next_observation, nous ne les avons pas encore définis.
Les négociations
我们环境的一个重要部分是交易会话的概念。如果我们将这个机器人部署到市场外,我们可能永远不会一次运行它超过几个月。出于这个原因,我们将限制self.df中连续帧数的数量,也就是我们的机器人连续一次能看到的帧数。
Dans notre méthode_reset_session, nous réinitialisons d'abord le current_step à 0; ensuite, nous définissons les steps_left comme un nombre aléatoire entre 1 et MAX_TRADING_SESSION, ce que nous définissons au sommet du programme.
MAX_TRADING_SESSION = 100000 # ~2个月
Ensuite, si nous voulons parcourir les niveaux en continu, nous devons les configurer pour parcourir l'ensemble des niveaux, sinon nous définissons frame_start comme un point aléatoire dans le self.df et créons un nouveau niveaux de données appelé active_df, qui n'est qu'un morceau de self.df et qui est dérivé de frame_start à frame_start + steps_left.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
Un inconvénient important de parcourir les niveaux de données dans des tranches aléatoires est que nos robots auront plus de données uniques à utiliser pour une formation à long terme. Par exemple, si nous parcourons simplement les niveaux de données en séries (c'est-à-dire dans l'ordre de 0 à len (df)), nous n'aurons que les points de données uniques qui sont aussi nombreux que les niveaux de données.
Cependant, en parcourant au hasard des tranches de l'ensemble de données, nous pouvons créer des ensembles de résultats de transactions plus significatifs pour chaque étape de temps de l'ensemble de données initial, c'est-à-dire une combinaison de comportements de transaction et de comportements de prix vus précédemment pour produire des ensembles de données plus uniques.
Lorsque la longueur de temps après la réinitialisation de l'environnement de série est de 10, notre robot fonctionnera toujours simultanément dans le jeu de données et aura trois options après chaque longueur de temps: acheter, vendre ou conserver. Pour chacune de ces trois options, une autre option est requise: 10%, 20%,... ou 100% de l'ampleur spécifique. Cela signifie que notre robot peut rencontrer n'importe lequel des 10 cas sur 103, pour un total de 1030 cas.
Revenons maintenant à notre environnement de tranche aléatoire. Lorsqu'il est de 10 temps, notre robot peut être dans n'importe quelle longueur de temps de lén (df) dans le nombre d'unités de données. Supposons que la même sélection soit faite après chaque longueur de temps, ce qui signifie que le robot peut expérimenter un état unique dans les 30 secondes de n'importe quelle longueur de temps de lén (df) dans les 10 mêmes temps.
Bien que cela puisse être assez bruyant pour les grands ensembles de données, je crois que nous devrions permettre aux robots d'apprendre davantage de notre quantité limitée de données. Nous allons toujours parcourir nos données de test de manière séquentielle pour obtenir des données fraîches et apparemment fraîches en temps réel, dans l'espoir d'obtenir une compréhension plus précise de l'efficacité des algorithmes.
L'œil du robot observé
L'observation d'un environnement visuel efficace est souvent utile pour comprendre le type de fonctionnalités que notre robot va utiliser.

Observation de l'environnement visualisé par OpenCV
Chaque ligne dans l'image représente une ligne dans notre observation_space. Les quatre premières lignes de fréquence similaire en rouge représentent les données OHCL, les points orange et jaune en dessous représentent les transactions effectuées.
Si vous regardez de plus près, vous pouvez même créer un diagramme vous-même. Sous la barre de volume des transactions, il y a une interface de type Morse code qui montre l'historique des transactions. Il semble que notre robot devrait être en mesure d'apprendre pleinement des données de notre observation_space, alors continuons.
- Il est important d'étendre uniquement les données observées jusqu'à présent par le robot afin d'éviter les écarts transversaux.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
Prendre des mesures
Nous avons créé notre espace d'observation, il est maintenant temps d'écrire notre fonction d'échelle et d'agir comme prévu par le robot. Chaque fois que nous vendrons le BTC que nous détenons et que nous appellerons self.steps_left == 0 de notre heure de négociation actuelle, nous le vendrons.réinitialisersession ((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((())))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
Prendre une action de transaction est aussi simple que d'obtenir le prix actuel, d'identifier les actions à exécuter et le nombre d'achats ou de ventes.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
最后,在同一方法中,我们会将交易附加到self.trades并更新我们的净值和账户历史。
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
Nos robots peuvent maintenant démarrer un nouvel environnement, l'achever progressivement et prendre des mesures qui affectent l'environnement.
Regardez nos robots négocier
Notre méthode de rendu peut être aussi simple que d'appeler print ((self.net_worth), mais ce n'est pas assez amusant. Au lieu de cela, nous allons tracer un diagramme simple qui contient un graphique séparé de notre valeur nette et de notre valeur nette.
我们将从我上一篇文章中获取StockTradingGraph.py中的代码,并重新设计它以适应比特币环境。你可以从我的Github中获取代码。
Le premier changement que nous allons faire est de mettre à jour le self.df [
from datetime import datetime
Tout d'abord, nous importons la base de données datetime, puis nous utilisons la méthode utcfromtimestamp pour extraire les chaînes UTC de chaque fil de temps et strftime, en les formatant en: Y-m-d H:M.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
Enfin, nous avons modifié le self.df [
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
Nous pouvons maintenant regarder nos robots négocier des bitcoins.

Nous utilisons Matplotlib pour visualiser nos transactions avec le robot
Les étiquettes vertes représentent l'achat de BTC, les étiquettes rouges représentent la vente. Les étiquettes blanches en haut à droite représentent la valeur nette actuelle du robot et les étiquettes en bas à droite représentent le prix actuel du bitcoin. Simple et élégant.
Temps d'entraînement
Une des critiques que j'ai reçues dans un article précédent était le manque de vérification croisée, qui ne divisait pas les données en ensembles de formation et en ensembles de test. Le but était de tester l'exactitude du modèle final sur de nouvelles données qui n'avaient jamais été vues auparavant. Bien que ce ne soit pas l'objectif de cet article, c'était très important.
Par exemple, une forme courante de vérification croisée est appelée vérification k-fold, dans laquelle vous décomposez les données en k groupes égaux, dont chacun utilise un groupe comme groupe de test et le reste comme groupe de formation. Cependant, les données de séquence chronologique sont hautement dépendantes du temps, ce qui signifie que les données ultérieures sont hautement dépendantes des données antérieures.
Lorsque cela est appliqué à des données de séquence chronologique, les mêmes défauts s'appliquent à la plupart des autres stratégies de vérification croisée. Ainsi, nous n'avons qu'à utiliser une partie de l'ensemble de l'ensemble de données comme un ensemble de formation, en commençant par les nombres de couches jusqu'à des index aléatoires, et le reste des données comme un ensemble de test.
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
Ensuite, puisque notre environnement est configuré pour traiter uniquement les nombres d'unités de données, nous allons créer deux environnements, un pour les données de formation et un pour les données de test.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
现在,训练我们的模型就像使用我们的环境创建机器人并调用model.learn一样简单。
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
Ici, nous utilisons des tableaux de tension afin que nous puissions facilement visualiser notre flux de tension et voir quelques indicateurs quantifiés concernant nos robots. Par exemple, voici un graphique des récompenses discountées pour de nombreux robots qui ont dépassé les 200 000 pas de temps:
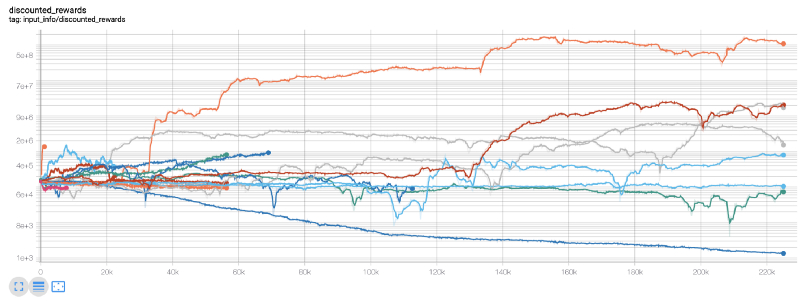
Il semble que nos meilleurs robots soient même capables d'atteindre 1000 fois l'équilibre sur 200 000 pas, avec une moyenne de 30 fois au moins!
C'est à ce moment-là que j'ai réalisé qu'il y avait une erreur dans l'environnement... Après avoir corrigé cette erreur, voici une nouvelle carte de récompense:
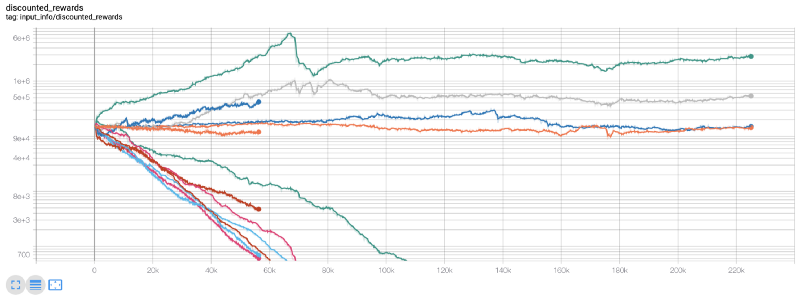
Comme vous pouvez le voir, certains de nos robots fonctionnent bien, les autres se décomposent d'eux-mêmes. Cependant, les robots performants peuvent atteindre au maximum 10 fois, voire 60 fois, le solde initial. Je dois admettre que tous les robots rentables sont formés et testés sans commission, il est donc peu pratique que nos robots gagnent de l'argent réel. Mais au moins, nous avons trouvé une direction!
Nous allons tester nos robots dans des environnements de test (en utilisant de nouvelles données qu'ils n'ont jamais vues auparavant) pour voir comment ils vont se comporter.
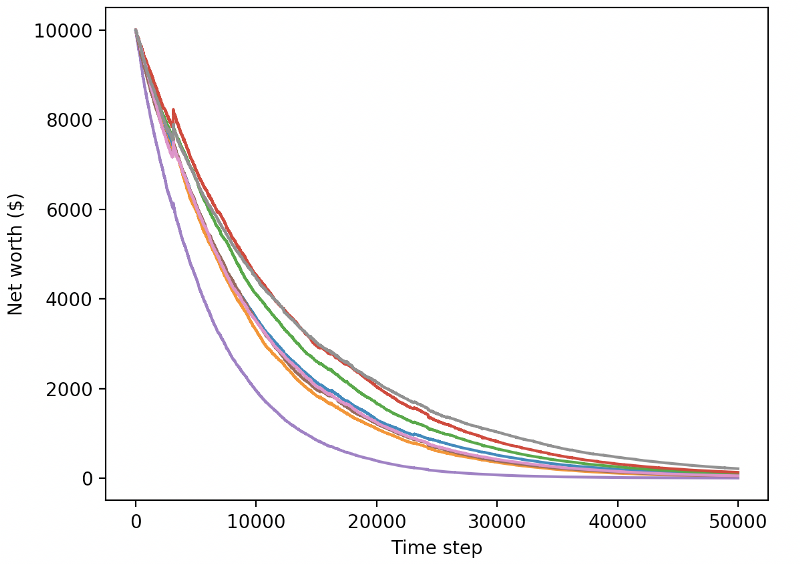
Nos robots bien entraînés sont en train de faire faillite en échangeant de nouvelles données de test.
Il est évident que nous avons encore beaucoup de travail à faire. Nous pouvons considérablement améliorer nos performances sur ce dataset en simplement basculant le modèle pour utiliser A2C sur une base stable, plutôt que le robot PPO2 actuel. Enfin, selon les suggestions de Sean O'Gorman, nous pouvons modifier légèrement notre fonction de récompense afin d'augmenter la récompense sur le net, plutôt que de simplement atteindre une valeur nette élevée et de rester là.
reward = self.net_worth - prev_net_worth
Ces deux changements à eux seuls permettent d'améliorer considérablement les performances des ensembles de données de test, et comme vous le verrez ci-dessous, nous sommes enfin en mesure de tirer parti de nouvelles données qui n'existaient pas dans les ensembles de formation.
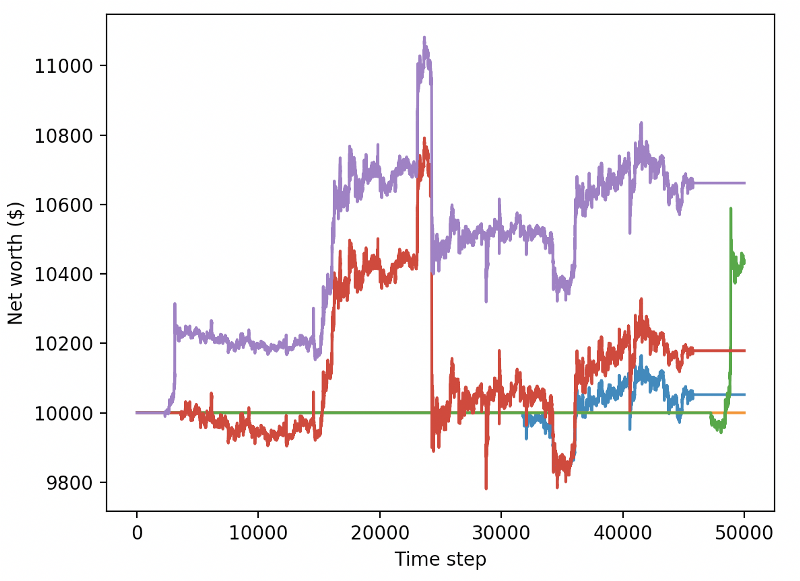
Mais nous pouvons faire mieux. Pour améliorer ces résultats, nous devons optimiser nos hyperparamètres et entraîner nos robots plus longtemps. Il est temps de faire fonctionner le GPU et d'allumer le feu!
À ce stade, l'article est un peu long et nous avons encore beaucoup de détails à considérer, nous avons donc l'intention de nous arrêter ici. Dans l'article suivant, nous utiliserons l'optimisation Bayesian pour délimiter les meilleurs paramètres pour notre espace de problèmes et nous préparerons à l'entraînement / test sur GPU avec CUDA.
Conclusions
Dans cet article, nous avons commencé à créer un robot de trading Bitcoin rentable à partir de zéro en utilisant l'apprentissage renforcé.
1.使用OpenAI的gym从零开始创建比特币交易环境。
2.使用Matplotlib构建该环境的可视化。
3.使用简单的交叉验证对我们的机器人进行训练和测试。
4.略微调整我们的机器人以实现盈利
Bien que nos robots de trading ne soient pas aussi rentables que nous l'espérions, nous sommes en train de progresser dans la bonne direction. La prochaine fois, nous nous assurerons que nos robots battront toujours les marchés, et nous verrons comment nos robots de trading traitent les données en temps réel.
- Pratiques quantitatives des échanges DEX (2) -- Guide de l'utilisateur des hyperliquides
- Expérience de la quantification sur les échanges DEX (2) -- Guide d'utilisation de Hyperliquid
- Pratique quantitative des échanges DEX (1) -- Guide de l'utilisateur dYdX v4
- Introduction à l'arbitrage au retard de plomb dans les crypto-monnaies (3)
- Pratiques de quantification de l'échange DEX ((1) -- dYdX v4 Guide d'utilisation
- Introduction à la suite de Lead-Lag dans les monnaies numériques (3)
- Introduction à l'arbitrage au retard de plomb dans les crypto-monnaies (2)
- Introduction à la suite de Lead-Lag dans les monnaies numériques (2)
- Discussion sur la réception de signaux externes de la plateforme FMZ: une solution complète pour la réception de signaux avec un service Http intégré dans la stratégie
- Exploration de la réception de signaux externes sur la plateforme FMZ: stratégie intégrée pour la réception de signaux sur le service HTTP
- Introduction à l'arbitrage au retard de plomb dans les crypto-monnaies (1)
- Système de négociation homogène adapté à la monnaie numérique et logiciel de négociation quantitative basé sur l'inventeur de l'algorithme KAMA
- FMZ inventeur de la plate-forme de mesure de la rétroaction
- Une simple démonstration de l'opération de l'appareil de mesure de la moyenne mobile.
- Le bâtiment de l'industrie révèle les transactions algorithmiques: les inventeurs utilisent des plateformes de quantification comme stratégie commerciale
- Calcul et application des indicateurs DMI
- Une stratégie de négociation intraday utilisant la régression de l'égalité entre SPY et IWM
- Application de l'indicateur technique Aaron dans les transactions quantitatives
- Exécution simultanée de la fonction Go enveloppée en bouteille en utilisant JavaScript pour mettre en œuvre des stratégies de quantification
- Les secrets de la survie: 19 professionnels partagent leurs conseils sur les transactions numériques
- L'application de l'appareil de démons de Shannon dans la monnaie numérique
- Développer une stratégie de CTA pour des gains absolus, de la quantification des transactions à la gestion des actifs
- Neuf règles de trading qui ont permis à un trader de passer de 1 000 $ à 46 000 $ en moins d'un an
- Introduction à l'inventeur de la transaction quantifiée - de la base à la réalité
- 5.5 Optimisation de la stratégie de négociation
- 5.4 Pourquoi nous avons besoin d'un test hors échantillon
- 5.3 Comment lire le rapport de performance de la stratégie
- 5.2 Comment effectuer un backtesting quantitatif du trading
- 5.1 Le sens et le piège du backtesting
- 4.6 Comment mettre en œuvre des stratégies dans le langage C++
- 4.5 Langue C++ Début rapide